
Abstract
This article introduces a time-selective strategy for enhancing temporal consistency of input data for multi-sensor data fusion for in-network data processing in ad hoc wireless sensor networks. Detecting and handling complex time-variable (real-time) situations require methodical consideration of temporal aspects, especially in ad hoc wireless sensor network with distributed asynchronous and autonomous nodes. For example, assigning processing intervals of network nodes, defining validity and simultaneity requirements for data items, determining the size of memory required for buffering the data streams produced by ad hoc nodes and other relevant aspects. The data streams produced periodically and sometimes intermittently by sensor nodes arrive to the fusion nodes with variable delays, which results in sporadic temporal order of inputs. Using data from individual nodes in the order of arrival (i.e. freshest data first) does not, in all cases, yield the optimal results in terms of data temporal consistency and fusion accuracy. We propose time-selective data fusion strategy, which combines temporal alignment, temporal constraints and a method for computing delay of sensor readings, to allow fusion node to select the temporally compatible data from received streams. A real-world experiment (moving vehicles in urban environment) for validation of the strategy demonstrates significant improvement of the accuracy of fusion results.
Keywords
Introduction
Detecting complex situations in real time typically requires simultaneous observations originating from several autonomous and multi-modal wireless sensor network (WSN) nodes. The problem, however, when employing ad hoc WSNs, is that the data transport times of even simultaneous sensor readings, acquired by distributed nodes, may not match temporarily even if the same communication path is used. This article focuses on communication between sensor and fusion processes, explores how readings from multiple distributed sensor nodes are consumed by the fusion node in real time and how data validity and simultaneity intervals affect the selection of temporally matching data for fusion process.
The purpose of the information produced by the WSN nodes at the edge of the network is to cater for the needs of the data users 1 deeper in the WSN. When used for situation awareness (SA) applications, the credibility of such information depends on timely processing of sensor data within the network and the temporal validity of data used.2,3 The users subscribe to situational information of interest, not from a central server but directly from nodes performing in-network data processing, 4 which are able to provide the requested SA information. The in-network processing nodes in turn subscribe to data from sensor nodes. The subscription contains information about what data should be provided, its expected refresh rate and can also specify the requirements for validity and simultaneity intervals. The WSN middleware for handling the subscriptions for exchanging SA information has been introduced in our previous work. 5
In this article, we consider the communication between asynchronous WSN nodes – meaning that clocks in different nodes are not synchronized and the start-up, data production and consumption processes in the nodes are activated independently from each other. The nodes in the network may employ different operating modes or duty cycling schemes and incorporate several heterogeneous sensors, with different modalities, characteristics and sampling frequencies. When a sensor node receives a subscription, it activates a periodic or event-based process for data production, the parameters of the process being dependent on the details of the subscription. Each WSN node may simultaneously service multiple active subscriptions and respectively run several processes for data production or consumption. The data produced by periodic execution of sensor processes (as subscribed by fusion processes) form data streams which can be intermittent 4 with elements not uniformly distributed in time with the possibility of some elements being sporadically delayed due to behavioural pattern of ad hoc WSN. As a result, some of the stream data elements may violate the required validity periods, 3 arrive out of order6,7 and can often have only partial temporal coverage. 8 This behaviour could be caused by several factors, such as the combined effect from the application of low data rate communication standard (e.g. IEEE 802.15.4, Bluetooth Low Energy or proprietary standards), ad hoc nature of WSN and an unpredictable, volatile – that is, disconnected, intermittent and low-bandwidth (DIL) – communication environment, 9 where WSN nodes operate. Therefore, the sensor readings used in the order of arrival as inputs for in-network data fusion and aggregation processes may not characterize the same situation. Hence, using always the freshest data from available streams may not be desirable. We suggest that only temporally and spatially compatible data should be fused and/or combined to infer new synthesized readings, and we propose a strategy for selection of temporally suitable data for improving the temporal consistency of input data for in-network processing. The strategy, implemented in the WSN fusion nodes’ middleware component as a default service, combines the use of temporal constraints 4 with a temporal alignment and selection algorithm and is customized for processing multiple streams of sensor data, which can be intermittent and arrive out of order. The mechanisms for data alignment, selection of suitable input data and verifying them against validity and simultaneity constraints are described using Q-modelling formalism. 10 Q-model allows to model the data streams in distributed systems (e.g. WSNs) and to analyse the delays of stream elements caused by periodic or sporadic activations of asynchronous processes in distributed systems (e.g. WSN nodes). As opposed to other methods that use time constraints and prefer freshest data first for time-sensitive WSN applications, the time-selective strategy allows fusion node to purposefully select temporally compatible data items from input streams.
An urban traffic monitoring experiment is used to demonstrate the enhancement of temporal consistency of input data for in-network data processing and a respective significant improvement in accuracy of data fusion results.
Section ‘Related work’ gives a short overview of the related work. Section ‘Modelling data streams and time-selective data fusion in WSN’ describes dataflows in ad hoc WSN using Q-model formalism, explains important theoretical notions to avoid ambiguity and introduces the alignment and selection algorithm. Section ‘Accumulated delays of the sensor readings’ describes the method for delay computation for the sensor readings and explains why it is necessary. Section ‘Experiment setup’ describes the experiment setup. Section ‘Results’ describes the results of the field tests, analysing the influence of time-selective strategy on in-network data processing, and section ‘Conclusion’ concludes this article and discusses some relevant aspects and future directions.
Related work
Timely handling of SA information collected by WSN requires distributed data fusion and aggregation by network nodes within the network. Instead of transporting all sensor data to a central server, we apply the paradigms of edge computation and in-network data processing. 4 The former is about performing as much computation close to the source of data as possible (either in sensor nodes or close to them) and the latter is about completing data fusion and aggregation within the network to mitigate bandwidth and energy scarcity, to increase solution resilience and the reliability of situation detection.
In most WSNs, the data acquired by sensors are processed in the same order as they arrive – even if the overall structure of the network and the definitions for detectable situations are known at design time. For example, Izadi et al. 11 present a data fusion approach which distinguishes low-quality input data from good-quality input data by assigning weights on sensor readings. The network delay is considered as one of the factors in the computation of weights, such that sensor readings with longer delays have lower influence on fusion result. This approach favours the freshest data and discards the opportunity to use delayed data that may be of high quality and better suitable for multi-sensor fusion. Other examples of prioritizing data freshness can be found in the papers that analyse quality-of-service (QoS) aspects in WSNs. A good survey of the state-of-the-art QoS techniques for delay handling and reliability mechanisms is provided in Al-Anbagi et al. 12 Similar overviews of WSN solutions for manufacturing and industrial control are given by Zhao 13 and Diallo et al. 3 The solutions described have reasonably good time-aware behaviour, that is, the ability to handle time-critical data and time-sensitive communication. However, the QoS aspects, such as real-time constraints and data freshness are considered most important in these surveys.
Another approach to guaranteeing timeliness in conventional WSN systems is to design them so that the delays caused by different communication paths meet the given deadlines. 14 Such strategy cannot cater for asynchronous nature of DIL and ad hoc WSN, where in-network data processing occurs with random and intermittent data bursts. Cheng et al. 15 present a method to modify the network structure in order to optimize the delays and to minimize the energy consumption. However, the structure of ad hoc networks is difficult to control by nature, hence the method suggested in Cheng et al. 15 may not applicable here. In order to provide better understanding of timeliness capabilities of WSNs,16,17 consider probabilistic methods for traffic flow aspects, such as end-to-end delay, jitter and throughput. Both works point out that in most practical cases, the worst-case bounds for end-to-end delay in WSNs are not applicable. We emphasize that in ad hoc sensor networks and especially in networks for collecting SA information, the data consumer must be able to analyse the validity of the data online 18 and to determine how long the data are usable. The time-selective strategy for in-network processing can handle more variability in end-to-end delays, but requires a means to compute the delays accumulated during the data transport through the network.
The main sources for timing non-determinism in contemporary WSNs include transmission delays, packet losses, queuing for transmission, nodes contest for radio frequency medium and clock drifts and jitters in individual nodes of the network. Transmission-related delays originating from send time, access time, propagation time and receive time are a well-researched area in traditional Ethernet-based networks. 19 In ad hoc WSN solutions, where time synchronization is not used, the transmission related non-determinism can be mitigated for low number of hops by applying contemporary transceivers (e.g. using IEEE 802.15.4 protocol), which allow for modifying the contents of a packet after packet transmission is started by utilizing delay computation method described in Maroti and Sallai. 20
Timing challenges in WSNs also include packet losses, which can happen due to dynamically changing network structure and unreliable wireless links. 12 The nodes may autonomously join or leave the network, interference from other sources may influence the wireless links (which may force the WSN to find different routing paths) and also mobile nodes must be considered. The delays can arise also from interactions where sending node is unable to transmit due to periodic activation, low duty cycle or other network scheduling policies, the resulting queuing delays for partner nodes are often ignored. Although the execution periods of the processes in network nodes may be highly deterministic, the messages are delayed and transmitted at non-deterministic times. This causes the end-to-end delays to be highly unpredictable, and the same applies to the order of data elements as packets may arrive out of order. Each time the system’s structure changes due to changing goals by users or the environment, the network must adapt to the changing interaction patterns and delays.
Another aspect complicating timing analysis in an ad hoc WSN is unpredictability of the data production by autonomous nodes. First, the traffic rates of produced data by sensor nodes depend on the application, sensor modalities and sensor process signal processing capabilities. For example, more intelligent and autonomous sensor nodes can avoid reporting altogether if the monitored situation is unchanged or report only as often as required by the rate of change of situation (i.e. monitoring environmental aspects may not need as high rate of reports as measuring current or voltage spikes, or tracking a mobile object). Second, nodes in WSN often apply duty cycling or other transmission scheduling policies to mitigate bandwidth and energy usage. 21 Doing these decisions autonomously according the current situation, regarding environment or local energy level adds unpredictability.
The problem of handling out-of-order data for sensor fusion is not well researched in scientific literature 22 and even less so in papers considering ad hoc WSNs. In area of multi-sensor data fusion, the related topic is called out-of-sequence measurements (OOSM). 22 OOSM can be caused by variable propagation times for different data sources or by heterogeneous sensors operating at multiple rates. The problem becomes especially relevant in large-scale networks consisting hundreds to thousands of measuring devices, as the complexity of network communication increases and communication delays of data packages get bigger. 23 In the area of multi-sensor data fusion, the solutions for this problem focus mostly on enhancing filtering algorithms (e.g. Kalman filter or particle filter) that cope with measurements arriving only a single or a few steps later.22,24 We consider those approaches not well suited for in-network multi-sensor fusion in ad hoc WSNs. The delays in such networks can be much more unpredictable and longer and approaches considering filtering and state estimation are computationally more complicated and resource demanding. 23 Some early examples that consider out-of-order arrival of data for in-network processing in WSNs are Shi et al. 25 and Xiaoliang et al. 26 While both papers consider OOSM filtering approach with discrete step delays, the former handles mixed and bounded delays from a single sensor and the latter deals with delays from multiple sensors with delay length of a single sensor data refreshing period. These approaches are still in their early stages and not yet suitable for DIL and ad hoc WSNs where multi-sensor fusion is considered.
A good overview of the existing data fusion techniques for WSN is given by Yadav et al., 27 but the listed works in given overview neither consider variable arrival delays in ad hoc networks or streams that may result in out-of-order arrival to the fusion node nor give sufficient attention to other timing characteristics other than freshness of data. Examples of distributed data fusion in WSNs are described in Bahrepour et al. 28 and Lai et al., 29 where events detected and sensor readings collected by individual sensor nodes are assembled by a fusion node. These works do not discuss the validity or simultaneity of the input data for the fusion algorithms.
Classical models for distributed systems often use abstractions at various levels to compensate for timing non-determinism. 30 Examples are lock-step synchronous models, 31 fixed or no drift in individual clocks 32 and/or delays with fixed bounds 33 (which essentially models a subset of synchronous systems). We consider the Q-modelling technique 34 for the analysis of ad hoc WSNs, as it naturally facilitates modelling of timing aspects of asynchronous communication and queuing delays across the communication paths through the network while considering the precision of data timestamps. The original purpose of the Q-model is to analyse time correctness of interprocess communication of a collection of loosely coupled, repeatedly activated and terminating processes, 10 where the purpose of the time-selective communication is that the input data for the consumer process should be exact from the desired time interval (not produced before or after that time interval – the freshest data are not always desirable). However, the time-selective communication on such autonomous and distributed real-time systems results in a situation where some of the execution sequences and data produced by them are discarded and some may be used as inputs to another process several times. 34
Modelling data streams and time-selective data fusion in WSN
This section defines and explains some important concepts, such as temporal alignment of data, validity time of a stream element and simultaneity interval for stream elements across streams from different sources. The section also introduces a time-selective data fusion strategy for WSN and gives a detailed overview of the algorithm for the temporal alignment of data and selection of compatible elements for data fusion.
Sensor readings arriving out of order
In order to illustrate the necessity for selecting temporally correct data from sensor data streams for data fusion, we describe a simple freezer example. Imagine a large freezer which has several spatially distributed temperature sensors inside. As using wired sensors in such an environment can be costly and difficult to deploy, WSN technology is used for convenience. All wireless nodes are considered asynchronous, that is, each node has its own individual clock that is not synchronized to the global reference. In this example, only the latest readings from each of sensors are fused to get an average. The fused value is reported to the user periodically. Neither sensor readings nor fusion results are stored in the fusion node. If the temperature rises equal or above zero, there is a risk of spoiled goods. The notion of data fusion in this example is an exaggeration and is used for consistency reasons. The example is illustrated in Figure 1. The white round markings on sensors time axis indicate sensor readings with normal delay. The black round markings indicate sensor readings with increased delay, and dashed line indicates the delay as it was expected by the designer of fusion algorithm. The computation and reporting of the averaged results take place at instances indicated by the ticks on fusion time axis.

Example with delayed sensor readings causing out-of-order arrival.
The cause for the increased delay, as depicted in Figure 1, could be a route change in the multi-hop network as goods are being stacked up on the radio path (similar increased delay could easily be caused also by network overload, etc.). Consider a situation where both sensors register a 0° value, but due to changed route, one of the sensor readings delay increases (now another WSN node relays its readings to the fusion node). If the fusion node does not consider variable delays and averages only readings according to their arrival, then the reported temperature never rises above −1.0° and the fact that the freezer temperature was zero for a short period of time is left unnoticed. It should be noted that even if there are no increased delays in the described freezer example, there is still a chance that the zero temperature would not be reported. As processes in this example are considered asynchronous, the fusion node execution and following reporting can happen between the arrival of two zero readings.
To mitigate such problems, we present a time-selective strategy. The fusion node should, during each of its algorithm execution, have access not only to the latest sensor readings but also preferably to an array or a batch of past readings from each distributed sensor. The storage size for the available past readings should be large enough to hold also readings as old as the longest allowed delay that can happen for fusion inputs for that particular network. Furthermore, it should be possible to align the arrived readings from different sensors to the fusion node’s time axis. This makes it possible for fusion process to select readings that are compatible in the temporal domain. The theoretical model for time-selective data fusion is discussed and analysed in the next section.
Modelling time-selective data fusion in WSN
We use Q-model
10
formalism to specify and model the WSN as a distributed communication system, consisting two main classes of components: processes and channels. Each interacting node in the WSN can execute several different processes p. The communication between the processes in different nodes across the WSN is modelled by a channel
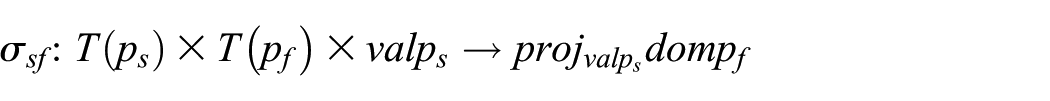
which, in the context of this article, conveys sensor process values to fusion process domain of definition. Here, the sensor process

where
The data usage between processes is time-selective. The data stream resulting from data produced by one of the processes is moderated by the channel function and transferred to another process. Formally, the channel function is expressed as
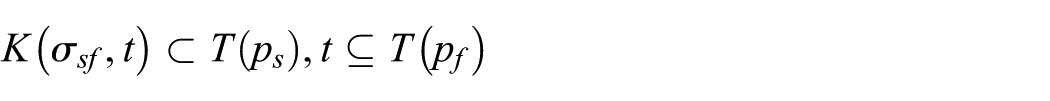
where the number of stream elements conveyed by channel or rather temporal span of the accessible elements received by fusion process is defined as time interval

Overview of processes and channels.
For example, for the fusion process

where

The oldest feasible element (denoted with variable
Regarding the feasibility of alignment and selection of temporally suitable sensor readings for fusion process, the memory buffers for storing the sensor readings from different channels should be large enough to cope with the delays caused by the nature of ad hoc DIL WSN.
Temporal validity interval of input data
This section discusses the importance of temporal validity intervals of input data for fusion node and how the value of validity interval of sensor readings affects the selection of temporally compatible inputs for the data fusion in WSN. The necessity of checking and ensuring the sensor data validity has been discussed in our earlier papers,4,35 where it has been explained how every sensor reading has temporal and spatial validity intervals associated with it. These intervals depend on several aspects, for example, the validity area depends on the location of the WSN and on the properties of the phenomenon being observed, while the temporal validity interval depends both on the properties of the environment where the node is located and on the phenomenon being observed. The sensor node augments its output data, with the validity intervals, and verifies that readings are still valid before transmitting them. The fusion node in turn verifies that the validity intervals of the sensor readings upon their arrival do match with the constraints set on incoming data. The output of the fusion process is in turn again accompanied with the metadata which also contains respective validity intervals checked by the users of fused data.
It is difficult to determine the precise arrival time of data to the fusion node in an ad hoc WSN in advance. The temporal validity interval is used to set an upper bound on the transport and usability time of the sensor readings. When temporal validity interval expires before the sensor readings arrive to the fusion node, the readings are discarded. The temporal constraints employed by the fusion node are not necessarily related to the validity intervals of arriving data. The constraints can be stricter or more relaxed depending on the application and context (as decided online by the fusion node or at design time by the system designer). If the validity of arrived data satisfies the temporal constraints, it is stored in the fusion node memory, where it remains available so that the fusion process can select the suitable inputs at the right time. Figure 3 describes a timestamp and a validity interval for a sensor reading on a fusion node timeline. The timestamp

Timestamp and a validity interval.
The validity interval for a single sensor reading with timestamp

where
Fusion requires overlapping validity of stream elements
Validity intervals of individual data elements can be used for grouping data and selecting data elements with overlapping validity intervals. Figure 4 depicts four sensor readings, their timestamps and validity intervals. The

The opposite situation can be observed in case of

Overlap of validity intervals.
The feasibility analysis of fusion of stream elements requires us to consider some necessary design decisions – for example, assigning periodicity of sensor reading, defining validity intervals for sensor readings, managing clock jitter in sensor nodes, maintaining average traffic speed between network nodes and defining the length of simultaneity interval that enables data fusion.
Simultaneity interval
The simultaneity interval serves a dual role – it enables to convey and evaluate the actually achieved synchronicity in a network and, if necessary, to compare it with the required synchronicity; and it provides a design parameter for assigning validity intervals for individual sensor readings in order to achieve feasible fusion of those readings. In general, the simultaneity interval specifies a set of events (e.g. sensor readings) that can be considered ‘simultaneous’ within some window of tolerance and can be used for fusion, and it is a period of time that elapses from the occurrence of the first of a group of events until the occurrence of the last event of the same group.
10
A simultaneity interval for two sensor readings with timestamps

For example, if fusion process receives four sensor readings as inputs with the delays of
As design goal or rather a requirement for simultaneity of sensor readings (more precisely the observed situations that the sensor readings represent), we define the simultaneity constraint
In practice, the simultaneity constraint is first chosen on the basis of application and second on the basis of the precision of computed delays of sensor readings. The computation of delay of sensor readings is discussed in section ‘Accumulated delays of the sensor readings’. The sample application used in this article is the detection of moving vehicles. The choice of simultaneity constraint will influence the precision of the position estimate of the detected vehicle. For example, if
Alignment and selection of compatible elementsfrom streams
The basic idea of the alignment and selection algorithm is to group the available readings from different sensors by temporal characteristics (such as validity intervals
Figure 5 shows three steps of the alignment and selection process of compatible data from sensor streams. Figure 5(a) represents the received stream elements by the fusion node. The arrival order of the stream elements from different sensor nodes is not known in advance as sensor nodes run asynchronously. The incoming stream elements are received by middleware component at the fusion node. The middleware performs a validity check 18 and projects the stream elements to the node’s local time domain. The black filled squares in Figure 5(b) and (c) depict temporally compatible stream elements. When the fusion process executes and requests for inputs, the data alignment and selection algorithm aligns the stream elements from different sensors in the fusion node time domain as depicted in Figure 5(b). The selection of temporally compatible elements from streams is depicted in Figure 5(c).

Example of alignment and selection of temporally compatible elements: (a) sensor data streams, (b) data stream alignment and (c) data fusion.
The process of selection of temporally compatible elements is described by Algorithm 1. The algorithm takes m number of streams as inputs. Each stream

In practice and in the test described in section ‘Experiment setup’, only set D with the smallest simultaneity interval
Accumulated delays of the sensor readings
In order to process the sensor readings in a time-sensitive manner and to align them on a common reference time, the processing node must be able to compute the delays of its inputs with certain required precision. There are two aspects to consider here, first, how the timestamp of the observed situation is computed by the sensor data acquisition process and, second, how the delays are computed and projected to the fusion node local time axis.
The former problem may not be trivial in the case of low-cost sensor nodes. In ad hoc WSN, it is not feasible that a sensor reading is transmitted from each single sample. In most cases, multiple sensor samples, called a frame, are either aggregated (averaged, summed, etc.) or processed into a single sensor reading for the entire frame period. Due to limited computational resources in low-cost sensor nodes, it may not be always feasible to compute the exact time instant of the actual situation from the sampled frame, so a start of the frame is considered as the process activation instant
For the latter problem, the classical methods align sensor data to a common reference with the help of time synchronization algorithms.36,37 However, applying classical methods, where all data are collected via gateway (sink) to a central server outside of WSN, may lead to significant communication overhead and is not optimal in ad hoc networks. Other methods to align data without synchronizing the WSN nodes include, for example, alignment based on causal dependencies, 38 where authors use vector clocks. We consider the system of vector clocks inefficient because of two specific reasons. First, the size of a timestamp is proportional to the number of nodes in the network, and second, using vector clocks requires additional communication between the sensors in order to establish the causal relations between the sensor readings.
Instead of traditional synchronization methods in WSNs, which can lead to significant communication overhead,
37
we take advantage of existing TinyOS packet-level delay computation service,
20
which allows to mitigate considerably the timing indeterminism for transmission-related delays (send time, access time and receive time) for a single hop. Its main advantage over other synchronization methods is its lightweight nature. Each node computes the accumulated delay for the data and passes this temporal information along with the transmitted data. The packet-level delay computation method supported by TinyOS operating system allows the communication stack to automatically convert the sending node local time to the receiving node local time by appropriately modifying the time value within the packet after its transmission is started. The sending node converts the time value within the packet to a delay
Experiment setup
This section describes the field experiment carried out to demonstrate the application of time-selective data fusion in WSN. Eight microphone array sensor nodes were used to record 30 min of acoustic signals by the side of an urban road with moderate traffic. The same sensor nodes were then set up in laboratory conditions where they, instead of recording signals, now read the previously saved acoustic data and treated it as if it were directly received from their analogue-to-digital converter (ADC) modules. This way, it was possible to repeatedly play through the same 30 min of situations with different experiment configurations to compare and analyse the results.
As stated above, the sensors used for the experiment are microphone array sensors. Each array consists of six microphones which enable sensors to compute an angle of arrival (AoA) of sound sources using a time-difference-of-arrival method. The sensor nodes are based on BeagleBoneBlack development boards for running sensor processes and an IEEE 802.15.4-compliant 2.4 GHz transceiver (based on Atmel ATmega256RFR2) for wireless ad hoc networking. The fusion nodes are implemented using only Atmel ATmega128RFA1 microcontroller-based platforms. The more detailed overview of the hardware is given in our previous work. 4
Sensor node placement for the experiment is depicted in Figure 6. Two fusion nodes A and B were used, with node A receiving messages from the four sensors on the left and node B receiving messages from four sensors on the right. Both fusion nodes transmit their results to a single gateway, not depicted in the figure. For brevity, the results from the two distinct clusters A and B are presented together as results from a single network.

Sensor node placement for vehicle detection.
Sensors were placed next to the road in order to detect passing vehicles. A total of 92 vehicles, of which 2 were buses, 2 were motorcycles, and the rest were passenger cars, passed by the sensors during the 30 min. The speed limit at this stretch of road is 50 km/h. Sensor sampling speed for each microphone was 20 kHz and measurement frame length, used in AoA processing, was 136.5 ms. As a result, approximately seven AoA calculations were done per second by a single node. Before transmitting the results, the sensor node was able to check the temporal validity of readings (described in Ehala et al. 4 ) and to transmit only the valid results to fusion nodes at an interval determined by the data subscription agreement between sensor and fusion nodes.
For the experiment described in this article, the sensor node sending period was 1000 ms. In between the sending periods, the seven sensor readings that the sensor node was able to sample covered 955.5 ms, and the sampling of frames (sensor process) is asynchronous with the sending period. At the end of each sending period, the sensor node assembled the available valid readings into a batch of single payload and transmitted it to the fusion node. In order to process all received readings, the fusion process execution period was also chosen to be 1000 ms. The different execution times of sensor, sending and fusion processes, for the experiment setup are illustrated in Figure 7. The delay arising from periodic activation at any fusion process execution instant can be computed by formula

The figure illustrates how the number of transmitted values depends on the validity intervals. Note that all processes are asynchronous.
However, when no vehicles are near the sensors, the AoA calculations end with a negative result, meaning that no vehicle is detected – in Figure 7, these cases are illustrated as empty slots at the sensor process executions. Negative results are never sent to the fusion node. If previous AoA estimation results which are still valid at the sending time and no new AoA estimations have been computed, then the old results (within the validity interval of 2000 ms) are retransmitted to the fusion node. This means that some sensor readings could be used more than once by the fusion process. When validity time of buffered readings expires and there are no new positive results, nothing is sent to the fusion node.
In order to monitor what happens in the network during different runs of experiment, all sensor and fusion nodes logged their activity by writing different log messages to serial port. This way, the execution timesets for all processes, delays and other temporal parameters which cannot be otherwise extracted from the wireless processing environment could be recorded for analysis. Several single-board computers (Raspberry Pi 2) collected these messages and timestamped them upon arrival. The single-board computers kept their own clocks synchronized via the network time protocol (NTP), so that all log records were comparable (WSN nodes themselves were not synchronized).
Location estimation by fusion nodes
Individual microphone array sensors alone can estimate the direction to a sound source from their position, but cannot effectively determine the distance to it, and therefore also the location of the source. A location estimate can be established, however, by several sensors in the same area by combining their direction estimates. Special fusion nodes are dedicated to this task, although in principle any network node can take up this task, if it has the necessary resources. The fusion process is depicted in Figure 8.

Estimating the location of sound source.
First, data are collected from all sensor nodes, which have detected a sound event. The data include the location of the sensor node (geographical coordinates), the measured direction estimate – the AoA of the sound (a geographic bearing) and metadata such as the sensor sensing range and a timestamp indicating the delay (or age) of the direction estimate. Based on the age of each direction estimate, compatible sound event instances are found and analysed together. Next, AoA beams are formed along all the direction estimates and intersection points of these beams are found. Due to the discrete nature of AoA calculation procedure and other inaccuracies of input data, all the beams will very seldom intersect in a single point. Rather, a cluster of intersection points emerges and the scattering or dispersion of this cluster determines whether the result should be considered a valid location estimate or not. From this cluster, a single geographical coordinate can be computed, which is a weighted average of the intersection points in the cluster. It is also checked that intersection points fall within the field of view of the involved sensors. Intersection points out of range of the sensors are not considered.
The resulting cluster of valid intersection points provides a basis for analysing the effectiveness of the fusion process. When the inputs to the fusion node are not acquired simultaneously, the resulting cluster of intersection points is more scattered as depicted in Figure 9(a). Figure 9(b) illustrates how applying time-selective data fusion strategy leads to improved fusion precision. In this case, provided the fusion node has access to streams of sensor readings that cover the vehicle passing, the alignment and selection algorithm should be able to select more compatible inputs for fusion.

Fusion result without data alignment (a) and expected improvement with data alignment and selection (b).
In order to compare the experiment results, two separate parameters are used for analysis. These are simultaneity interval
Experiment configurations
The experiments are carried out the same way as the WSN would have been deployed in real world by replaying the recorded data streams at every sensor node. The WSN nodes use their radio transceivers to exchange the data as they would if they were deployed in the field. The two different configurations of experiments are listed in Table 1.
Experiments, their configurations and parameter varied.

The first experiment configuration is about using the freshest data first. This configuration does not use the temporal alignment and selection algorithm. The purpose of the experiment is to demonstrate the naive version of data collection from WSN, where each sensor node periodically transmits a result to the fusion node, which consumes the data in their order of freshness.
The second experiment configuration applies the temporal alignment and selection algorithm, so that the temporarily compatible input data for fusion algorithm are selected from available inputs according to the similarity of the computed delays. This experiment configuration requires that the fusion process at every execution has access to a stream of sensor readings from each sensor process. In the current experiment, due to the limited memory in the fusion node, a solution was implemented where instead of storing the stream elements on fusion node, the sensor node transmits a batch of readings in each of its packets. As the maximum length of IEEE 802.15.4 physical layer frame is 127 bytes, it was possible to transmit a maximum of seven sensor readings (accompanied by appropriate metadata) in a single batch.
Both experiment configurations compute the delays of sensor readings using the same method as described in section ‘Accumulated delays of the sensor readings’. The only difference is how the delay information is exploited. Without the alignment and selection algorithm, no simultaneity constraint is applied and the delays of sensor readings are only checked against validity constraints (the same validity constraint is applied both on sensor node before transmission and on fusion node side upon receival of data). The sensor readings with longer delays, which did not satisfy the validity constraints, were not used for fusion. With the alignment and selection algorithm the inputs are projected and aligned to fusion node time domain and only temporally most compatible inputs are selected and passed to the fusion algorithm, provided they satisfy the simultaneity constraints. During all experiment runs, all execution periods for both sensor and fusion processes were set to 1000 ms. The data validity intervals for fusion inputs are subject to different validity constraints during first the experiment, and during the second experiment, the validity constraint for fusion inputs is fixed to 2000 ms.
The difference between the two experiment configurations is illustrated by Figure 10, which depicts a sample set of sensor streams as inputs for fusion process. In the figure, the streams from different sensor nodes have been projected onto fusion node time domain and aligned according to their respective delays. If the fusion process starts to consume the sensor readings by the freshest data first from each stream, then the length of simultaneity interval

An example of stream elements aligned on fusion nodes time axis before single fusion execution.
Results
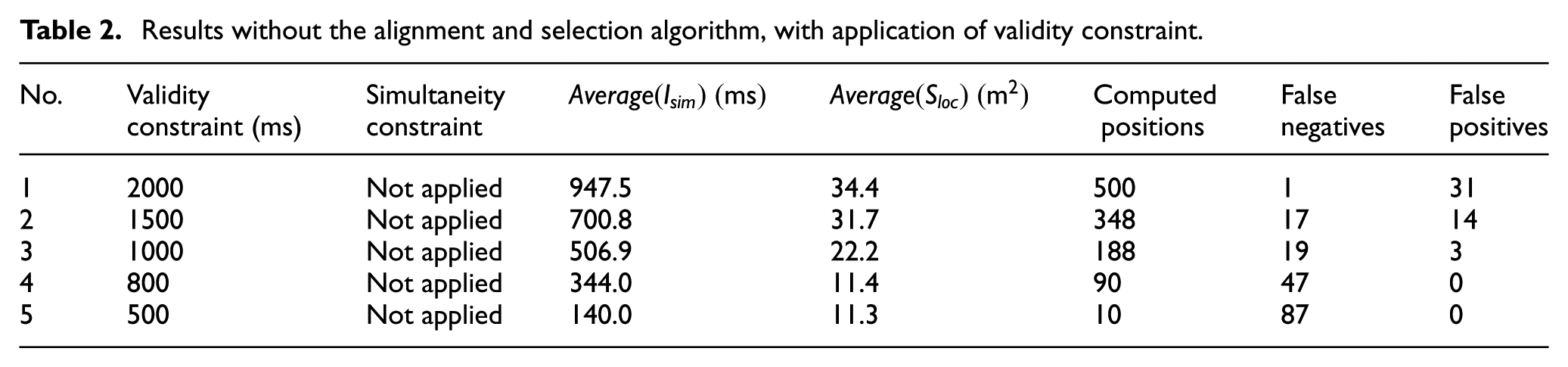
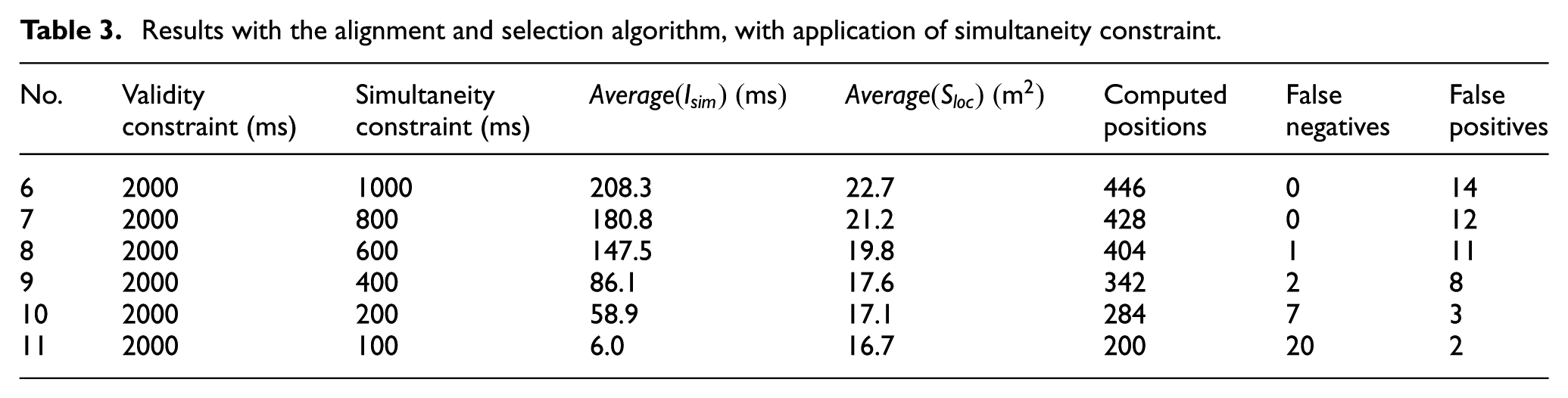
This section presents the results of a total of 11 experiments. The results for the first five experiments are presented in Table 2. During these experiments, the temporal alignment and selection algorithm and simultaneity constraint were not applied. The results of the application of temporal alignment and selection algorithm on stream elements and the use of different simultaneity constraints are presented in Table 3. In both tables, column no. 4 contains measured average simultaneity intervals for fusion inputs (a measure of temporal consistency of inputs) and column no. 5 contains average rectangular area of intersection points, which represents the precision of fusion result (a position of a passing vehicle). The results for
Results without the alignment and selection algorithm, with application of validity constraint.
Results with the alignment and selection algorithm, with application of simultaneity constraint.
During the first five experiments presented in Table 2, the fusion node consumed the arrived inputs as freshest data first, in the same order as they arrived. A considerably long average simultaneity interval achieved can be explained by periodic and asynchronous execution of ad hoc WSN nodes. Furthermore, the allowable age for the freshest available sensor reading for transmission depends on the validity interval. With validity being longer than sensor process execution period, the sensor node was allowed to transmit or retransmit older values. The experiments 1–5 show that when the value of validity constraint is reduced, the values of

Sensor delays measured on fusion node time axis.
The average for all delays of sensor readings received by the fusion node is 1357.7 ms. Altogether, the fusion node A received 9157 sensor readings. It can be observed that (due to periodic execution) the majority of the readings fall into an interval between 500 and 2000 ms. The reason why there is ca. 200 ms delay before the first readings arrive to the fusion node must be, in addition to the sensor sampling time, fusion node’s asynchronous and periodic execution. The readings that have been delayed more than 2000 ms are most likely the ones that were retransmitted due to no new valid readings. The theoretical maximum of a delay due to periodic execution and retransmission can be up to 3000 ms (validity time added to delay caused by periodic execution of processes). Longer delays must have been caused by network and environment induced uncertainties (or other real-world unpredictable causes).
The rest of the experiments (6–11) in Table 3 show how averaged values for simultaneity interval and area of location estimation are influenced by alignment and selection algorithm together with different values for simultaneity constraints.
The experiment indicates a correlation between simultaneity constraint and the area of average location estimation. The lower the simultaneity constraint, the smaller the area, that is, the precision of position estimation improves. However, the same side effect as during the first five experiments without the temporal alignment and selection algorithm is present. Stricter simultaneity constraint filters out the actual vehicle detections with lower precision (larger values of
Experimental results of the two different experiment configurations (freshest data first vs time-selective strategy) clearly show that time-selective approach achieves considerably better results than the configuration which uses only validity constraints and prefers the freshest data first.
Choosing a good criterion for WSN performance is not trivial. One possibility is to use accuracy as a criterion. In statistical tests, the accuracy can be measured by formula
With the first experiment configuration (the freshest data first approach), the best results are with validity constraint being 1000 ms, which is the first threshold, where the number of false positives is three. However, the number of false negatives is too high, 19 false negatives out of 92 vehicles leaves 20.7% of vehicles undetected. In total, this leaves only 73 vehicles detected with 185 correct positions. The average precision of positions was
The second configuration shows much better results. The outcome of simultaneity constraint of 200 ms gives three false positives and less than 7.6% of false negatives. In total, 85 vehicles of 92 were detected with 281 correct positions. The average precision of positions was
In conclusion, with the same number of false positives in experiments 3 and 10, the second experiment configuration with time-selective algorithm showed significantly less false negatives (decreased by more than six times). Experiment 10 also improves the
Conclusion
Various situations exhibit physical phenomena which can be observed and measured with individual sensors practically simultaneously. The parallelism in the observation process is important, as it is otherwise difficult to combine these measurements during a fusion process later. We do not consider global clock synchronization feasible in an ad hoc WSNs, neither is the data transport time deterministic in such networks. The in-network data processing nodes receive packets out of order and with time varying delays, in addition sensor nodes themselves are unreliable. The purpose of this article was to show that using a time-selective strategy for in-network processing improves the temporal consistency of input data for SA information acquired in ad hoc WSN. To demonstrate the improvement, we used distributed autonomous sensors for detection of moving vehicles in an urban street. By applying the time-selective data fusion strategy, the fusion algorithm is able to select temporally compatible data from the arriving streams of sensor data. The data which satisfy simultaneity constraints have a higher probability for describing the observed situation accurately. After alignment and selection of temporally compatible data, the data still need to be checked against spatial constraints. As the data fusion considered in this article computes the position from distributed observations, the spatial check is done by the fusion process. Spatial constraints were briefly discussed in our earlier paper, 4 and an idea of combining of temporal and spatial constraints has been discussed in Mõtus et al. 39 This area is a topic for a separate research paper.
We also consider the time-selective strategy generic enough to be applied in ad hoc WSNs regardless of media access control and link layer protocols. Furthermore, we consider that it is worth to research whether the time-selective data fusion strategy improves the effectiveness of filtering-based multi-sensor multi-lag OOSM approach for WSNs.
Footnotes
Handling Editor: Jose Molina
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially funded by the project SMENETE (Smart Environment Networking Technologies), which is funded by the European Regional Development Fund within the framework of EU Smart Specialisation programme 2014–2020 and the Estonian IT Academy program.