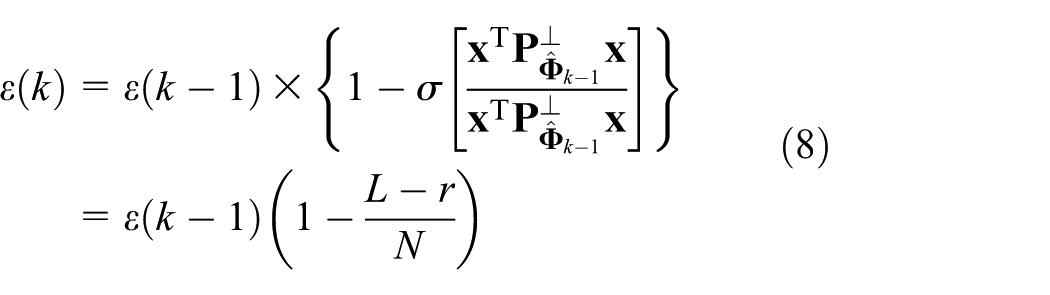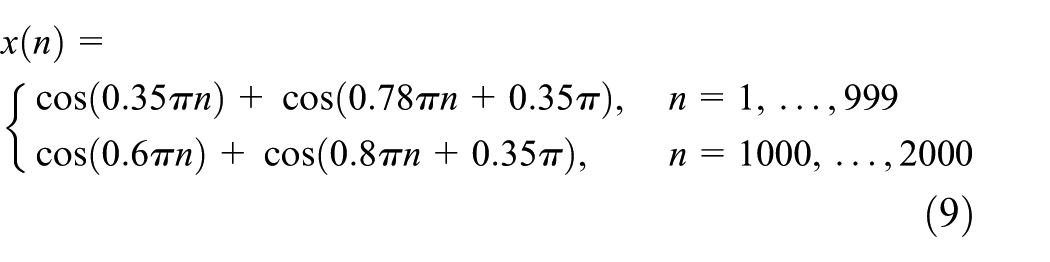This article introduces a new algorithm that constructs an efficient search strategy, called parallel search, for blind adaptive Karhunen–Loéve transform. Unlike anterior Karhunen–Loéve transform, the proposed algorithm converges quickly by searching for solutions in different directions simultaneously. Moreover, the process is “blind,” which means that minimal information about the original data is used. The new algorithm also avoids repeating the Karhunen–Loéve transform basis learning step in data compression applications. Numerical simulation results verify the validity of the theory and illustrate the capability of the proposed algorithm.
The Karhunen–Loéve transform (KLT), also called principal component analysis (PCA),1,2 is a well-known optimum transform for signal compression. Its basis functions are generated via a given signal covariance matrix.3,4 Recently, KLT has been widely used in many fields, such as communication,5,6 radar,7 sparse process representations,8–10 and distributed sensor networks.11
However, the KLT basis functions are data dependent, that is, as the signal varies, the learning process of the KLT basis function benefits from additional test data. Thus, the KLT basis functions are generated with a high computational cost while increasing the number of transmissions associated with each new basis function. As a result, the direct use of traditional KLT in data compression applications is limited.
Davila3 proposed a scheme for blind adaptive estimation of KLT basis vectors, which can be processed by both the sender and the receiver concurrently using the same initial conditions. It can also track the KLT basis vectors by only using knowledge about the low-dimensional KLT coefficients, while not requiring explicit knowledge about the actual signal. In this sense, it is a “blind” and “adaptive” estimation scheme for KLT basis vectors.
Let be an N-dimensional column vector of the signal frame to be transmitted. Its correlation matrix having rank has the eigenvectors denoted by whose columns are the KLT basis vectors. The traditional KLT coefficients are given by . In practice, the eigenstructure of most signals tends to vary considerably over time. So, the KLT basis matrix needs to be constantly relearned and retransmitted within the traditional KLT framework. Davila substitutes the rank-1 updating form of the correlation matrix for , that is
where . and are the estimates of the eigenvectors and eigenvalues of , respectively. is the identity matrix. Let be an stochastic matrix with independent and identically distributed (i.i.d.) Gaussian elements. The search direction vector is a white noise vector independent of . The iterative algorithm below shows the framework of the eigenvector estimates.
Note that if eigenvectors are merged by a search direction vector in each iteration, then the eigenvectors of can be tracked well. Davila3 proved that the algorithm is convergent with the rate . For the sinusoidal signal used in Davila,3 more than 300 iterations were needed to ensure that the mean squared error (MSE) between the original and recovered signals is less than when . If , then the conditions are better, but 100 iterations are still needed to ensure a precise reconstruction. A well-known fact is that the smaller the selected N is, the more the signal frames are generated and the more the cost is paid due to frequent transmissions. In addition, the numerous iteration times for convergence may lead to a large amount of information loss, especially for online tracking. In fact, there is a lot of room for the convergence rate to improve. Naturally, one could ask the following question: Can we design a new scheme that retains the blind and adaptive qualities while converging faster?
In this work, we develop a new scheme that can solve this problem by introducing a parallel search.
Blind adaptive KLT via parallel search
Algorithm
The proposed scheme shown in Algorithm 2 has a similar form to the blind adaptive Karhunen–Loéve transform (BAKLT) method shown in Algorithm 1. The key difference is that the search directions are distinct. This novel scheme merges the set of estimated eigenvectors with an N × (L – r)-dimensional matrix , the column vectors of which are called parallel search vectors, and each column of represents an independent search direction. Of course, if , then BAKLT is a special case of the proposed algorithm.
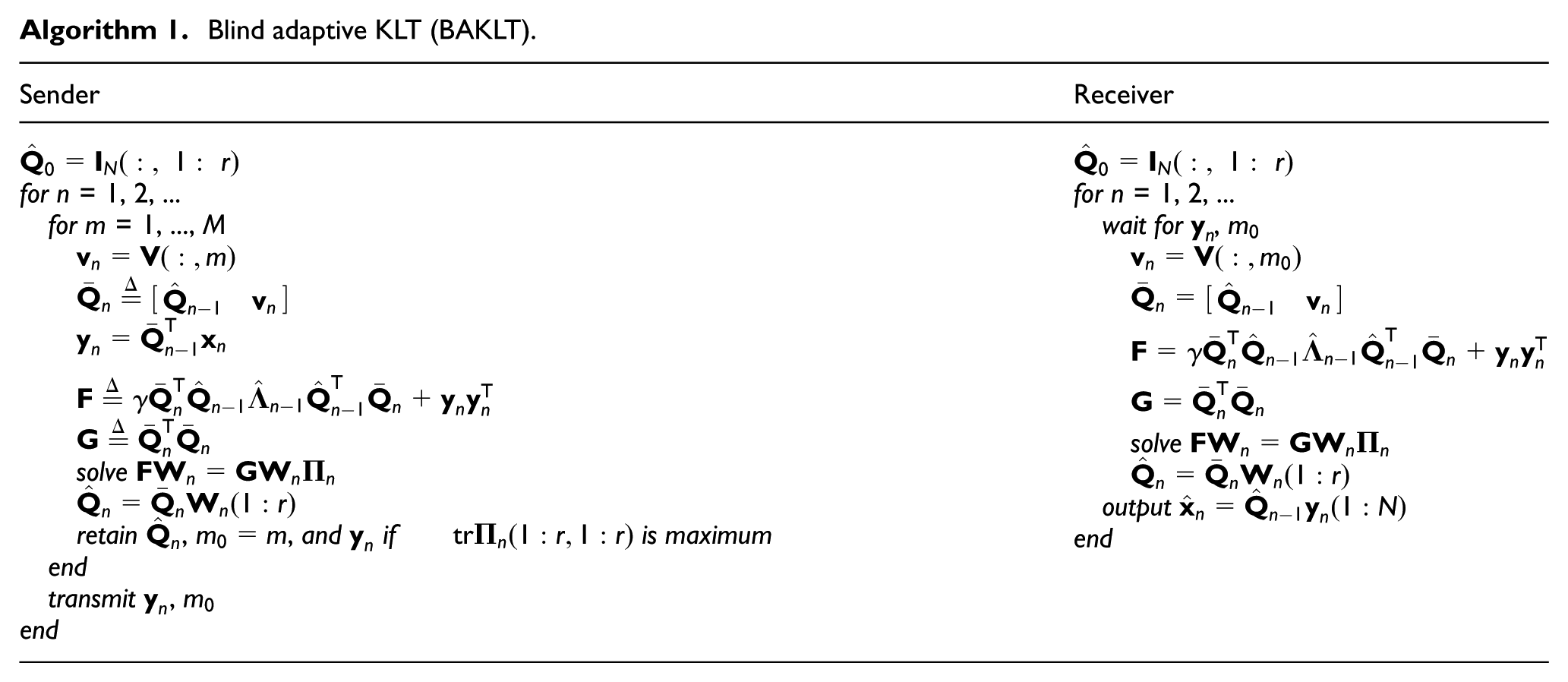
Blind adaptive KLT (BAKLT).
Sender
Receiver
for n = 1, 2, … for m = 1, …, M solve retain, , andifis maximum end transmit, end
for n = 1, 2, … wait for,
solve
output end
Blind adaptive KLT via parallel search.
Sender
Receiver
for n = 1, 2, … for m = L – r, …, M solve retain, , andifis maximum end transmit, , L end
for n = 1, 2, … wait for, , L
solve
output end
The colon (by itself) refers to all the elements in a row or a column of a matrix. Thus, means the column 1 through r of the matrix .
We demonstrate that the proposed algorithm is convergent and faster, while the proof is simpler.
Convergence
To measure the algorithm’s performance, the a priori MSE between the original and reconstructed data frames is estimated as
where ‖·‖ is the standard vector 2-norm. Since contains orthonormal vectors, then is the projection matrix onto . The expected value of the error in equation (2) can be written as
where is the orthogonal projection matrix. We can write
We note that the convergence rate correlates with the ratio between the number of parallel search directions and the signal length. Obviously, when , the error reduction ratio of BAKLT in Davila3 is . Thus, the bigger the frame length is, the slower the algorithm convergence is. The proposed algorithm increases the convergence rate to via parallel search, which is times faster than BAKLT.
Numerical experiments and results
In this section, we experimentally illustrate that the parallel search is a powerful approach for accelerating the convergence, when compared to BAKLT. In our simulations, the signal of interest is generated as in Davila,3 that is
when the algorithm is applied with and . The parallel search vectors are selected from an zero-mean Gaussian white noise codebook , which is shared by the sender and the receiver, to find the best search directions.
Estimation error
The major goal of the first experiment is to validate the performance of the algorithm (to recover a signal). In this experiment, the MSE is defined as in equation (2). To verify that the KLT basis vectors were indeed being tracked, the eigenvectors of the sample correlation matrix were computed and substituted for the matrix . The measure of the distance between the subspace spanned by the estimated KLT basis vectors in and the eigenvectors in is given by
where denotes the matrix Frobenius norm. and are the projection matrices onto the column spaces of and , respectively.
To ensure the accuracy of the calculation, the Multiprecision Computing Toolbox for MATLAB12 is used.
Figure 1 illustrates the signal reconstruction MSE results for different measurement lengths L using the parallel search method when N = 16. We can see that the proposed algorithm is convergent based on the number of iterations it completes. Under the same conditions, the more parallel the search directions are (i.e. the bigger the length L measurements are), the faster the MSE converges to zero. Thus, the parallel search method leads to a significant increase in convergence rate. Figure 2 shows the function. This demonstrates that the algorithm can indeed track the KLT basis vectors. Therefore, the changing trends of are similar to those of , as shown in Figure 1. Compared with BAKLT (i.e. ), the parallel search leads to different significant increases in convergence rate for different measurement lengths.
Mean squared error for signal reconstruction at different measurement lengths L using the parallel search method when . The parallel search method leads to a significant improvement of the convergence rate.
KLT tracking error for different measurement lengths L using the parallel search when .
To analyze the relationship between the convergence rate and measurement lengths L, another experiment is designed.
Convergence rate
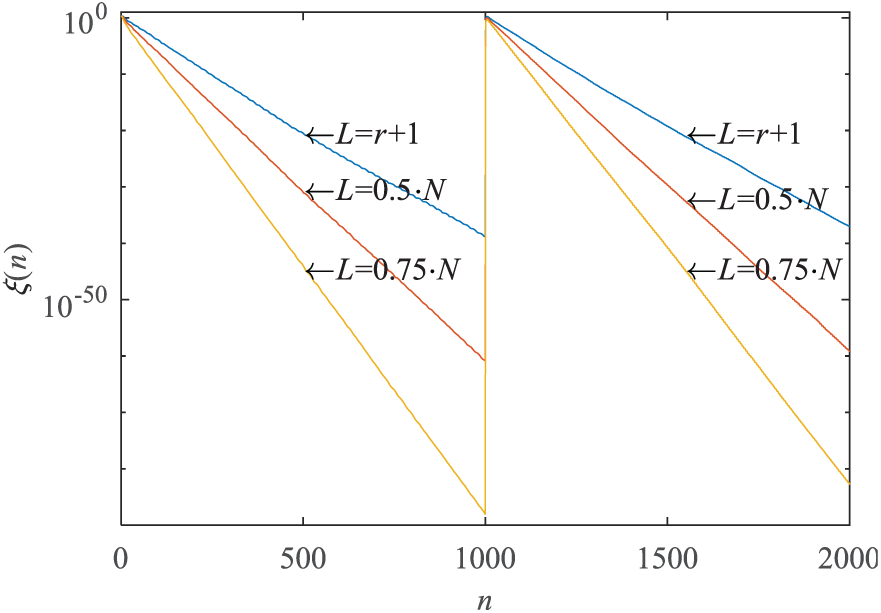
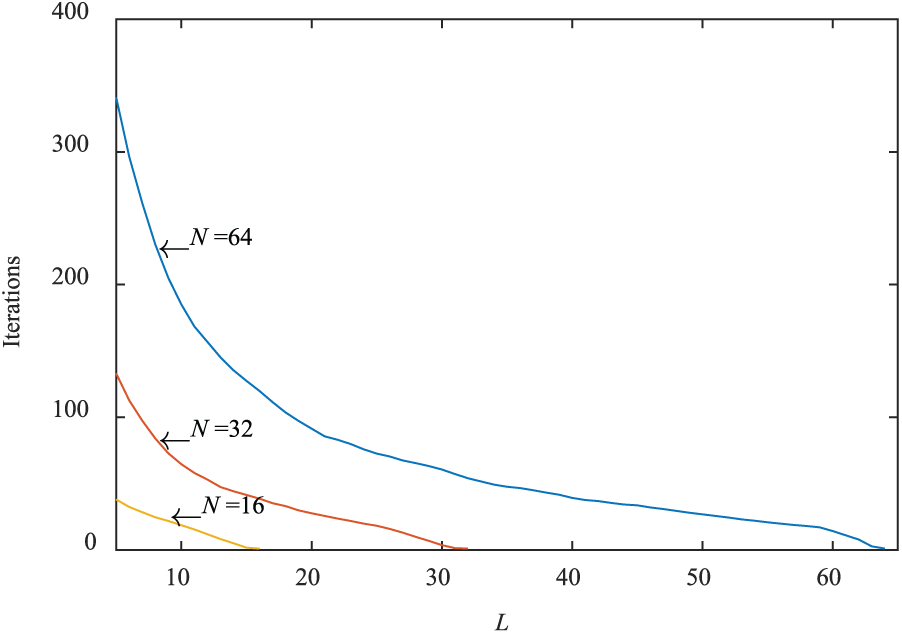
In this experiment, the parallel search algorithm is convergent when the MSE , between the reconstruction and the original signal, is smaller than 10−3 or when . The number of iterations needed for the parallel search to converge is compared to the signal frame length L when , respectively. The results are shown in Figure 3. Thus, the parallel search provides a considerable reduction in the number of iterations needed for convergence. When and corresponded to BAKLT, 341 iterations are needed for the process to converge because it searches in only one direction at a time. If and , only 54 iterations are required, which benefits from the parallel direction search in each iteration. In addition, the frame length N is inversely proportional to the recovered MSE. The convergence rate also varies inversely with N, which can be seen in the convergence analysis in section “Blind adaptive KLT via parallel search.” We note that the frame length N determines the frequency of transmission if the signal length is fixed, so N should not be too small a value. The parallel search method is useful when accelerating the convergence rate and improving the reconstruction accuracy. Our analysis shows that there is a trade-off between measurement length and convergence rate. The more parallel the measurements are, the faster the convergence rate is. In practice, a balanced selection process is needed, but the compression and convergence speed must also be taken into consideration. The blind adaptive KLT via our parallel search method may provide this additional choice.
The number of iterations for convergence versus different measurement lengths L using the parallel search process when , respectively.
Conclusion
In this article, we proposed a novel algorithm that constructs a fast and efficient search strategy for blind adaptive KLT. The algorithm, called parallel search, convergences quickly due to its reduced processing steps. We have proven that, for Gaussian white noise parallel search vectors, the convergence is dependent on the quantity , where N is the data frame length and r is the number of KLT basis vectors. Thus, the larger the term, the faster the convergence. In addition, the parallel search increases the convergence rate times compared to that of BAKLT. In practice, a workable balance can be found between the compression and convergence speed by adjusting the measurement lengths.
Footnotes
Handling Editor: Shinsuke Hara
Author’s Note
Author Wenbiao Tian is now affiliated to Signal and Information Processing Provincial Key Laboratory in Shandong, Naval Aviation University, Yantai, China.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China under Grant Nos 41606117, 41476089, and 61671016.
References
1.
SezerOGGuleryuzOGAltunbasakY. Approximation and compression with sparse orthonormal transforms. IEEE T Image Process2015; 24: 2328–2343.
2.
YilmazOAkansuAN. Quantization of eigen subspace for sparse representation. IEEE T Signal Pr2015; 63: 3576–3585.
3.
DavilaCE. Blind adaptive estimation of KLT basis vectors. IEEE T Signal Pr2001; 49: 1364–1369.
4.
TorunMUAkansuAN. An efficient method to derive explicit KLT kernel for first-order autoregressive discrete process. IEEE T Signal Pr2013; 61: 3944–3953.
5.
MatamorosJAnton-HaroC. Estimation of spatially-correlated random fields with compressed observations. IEEE T Wirel Commun2014; 13: 6542–6556.
6.
HanYShinWLeeJ. Projection-based differential feedback for FDD massive MIMO systems. IEEE T Veh Technol2017; 66: 202–212.
7.
AiXLuoYZhaoG. Transient interference excision in over-the-horizon radar by robust principal component analysis with a structured matrix. IEEE Geosci Remote S2016; 13: 48–52.
8.
PadPUnserM. Optimality of operator-like wavelets for representing sparse AR(1) processes. IEEE T Signal Pr2015; 63: 4827–4837.
9.
XiaoYGaoWZhangGet al. Compressed sensing based apple image measurement matrix selection. Int J Distrib Sens N2015; 11: 1–7.
10.
LiZXieJTuDet al. Sparse signal recovery by stepwise subspace pursuit in compressed sensing. Int J Distrib Sens N2013; 9: 798537.
11.
YanTLiuFChenB. Microscopy image fusion algorithm based on saliency analysis and adaptive m-pulse-coupled neural network in non-subsampled contourlet transform domain. Int J Distrib Sens N2017; 13: 711620.
12.
Advanpix. Multiprecision Computing Toolbox for MATLAB version 4.4.7.12739, 2018, https://www.advanpix.com