
Abstract
Voice over Long-Term Evolution enables reliable transmission among enormous Internet of Things devices, by providing end-to-end quality of service for Internet protocol–based services such as audio, video, and multimedia messaging. The research of covert timing channels aims at transmitting covert message stealthily to the receiver using variations of timing behavior. Existing approaches mainly modulate the covert message into inter-packet delays of overt traffic, which are not suitable for Voice over Long-Term Evolution, since most of the inter-packet delays of Voice over Long-Term Evolution traffic are of regular distribution, and any modification on inter-packet delays is easy to be detected. To address the issue, in this work, we propose a novel covert timing channel for the video stream in Voice over Long-Term Evolution, which modulates the covert message by deliberately dropping out video packets. Based on the two-dimensional mapping matrix, the blocks of covert message are mapped into dropout-packet sequence numbers. To recover the covert message, the receiver retrieves the sequence numbers of lost packets and identifies them to be translated into blocks of the covert message. To evaluate our scheme, the simulations with different packet loss rates are conducted to validate the undetectability, throughput, and robustness, finally, the results show that this scheme is effective and reliable.
Introduction
Internet of Things (IoT) has already been marked as the entry into the world of consumer electronic devices1,2 and Voice over Long-Term Evolution (VoLTE) allows these devices to make faster and effective transmission without any call drops. The first definition of the covert channel was composed by Lampson 3 in 1973, and covert channels are those “used for information transmission even though they are neither designed nor intended to transfer information at all.” Covert channels can leak information with the inspection systems like intrusion detection system or firewall, which monitors the communication with outside. According to the modulation entities, covert channels can be roughly divided into covert storage channels (CSCs) and covert timing channels (CTCs). A CSC is implied through direct or indirect writing to a specified storage location shared by the sender and receiver process. 4 Distinct from the CSCs, CTCs modulate a covert message into variations of target system resource, such as central processing unit (CPU) usage and response time.5–7
There have been diverse schemes of CTCs, such as Internet protocol covert timing channel (IPCTC), 4 JitterBug, 8 time-replay covert timing channel (TRCTC), 9 and model-based covert timing channel (MBCTC).10,11 Cabuk et al. 4 developed the first IPCTC and investigated a number of design issues. IPCTC uses a simple encoding scheme to transmit information, through which bits of covert message are sent to the receiver by controlling packet transmission during a certain time interval. 12 JitterBug is a different kind of CTC. Shah et al. 8 designed a special keyboard device, which adjusted the interval of packets containing typed information to modulate covert messages. Cabuk 9 later proposed a new CTC that replays inter-arrival sequences retrieved from legitimate traffic to modulate covert messages. Gianvecchio et al. 11 showed us a new method referred as MBCTC to construct CTC. By mimicking inter-packet delays (IPDs) produced by normal traffic, this scheme maintains its undetectability while modulating the covert message into IPD combinations. CTCs based on other Internet protocols (IPs) are also available for CTC researchers. Kogos et al. 13 searched proposed covert channels designed with hypertext transfer protocol (HTTP), such as adjusting the presence or absence of HTTP packets in a certain time interval to leak information or modulating a covert message into the relative distance between a current uniform resource locator (URL) and the root directory. For other scenarios, Archibald and Ghosal 14 proposed an MBCTC which is based on Skype; this scheme employees multiple IPDs to increase robustness.
Established with Long-Term Evolution (LTE), VoLTE abandons circuit switch technology used in the traditional voice call and transmits all the packets that are generated by the user equipment (UE) through Evolved Packet Core (EPC). 15 Analogous to Voice over Internet Protocol (VoIP) applications such as Skype, data of VoLTE are embedded into payloads of Real-Time Protocol (RTP). Compared with packets generated by other types of application, packets carrying VoLTE data deserve a higher priority in the LTE transmission network. 16 On the other side, packets of VoLTE are organized in a time regularity, for instance, IPDs between packets carrying audio data are 20 ms. 17 Another feature of VoLTE is that the packet is numbered with a unique auto-increasing sequence number during the communication. To the end, CTCs based on IPD adjusting and packet rearranging will violate the regularity of VoLTE traffic apparently. Thus, designing a new CTC for VoLTE is necessary.
One advantage of RTP used in VoLTE is that the lost packets are easy to be tracked with the sequence number field in the RTP header. To analyze the transmission regularity, we captured several streams of VoLTE using TCPdump on both sides of the UE. In current implementation of VoLTE, packets with different types of the payload are transmitted through different channels. 18 Furthermore, packets in VoLTE can be divided into three categories, which are packets carrying signaling information, packets carrying audio data, and packets carrying video data. 19 Furthermore, packets with audio data are generated and delivered through the baseband processor (BP), on which both packet length and IPD are arranged in determinate rules. 20 At the same time, packets with video frames are produced by the application processor (AP) which invokes TCP/IP protocol stack in the system kernel to accomplish, thus packets of video stream can be captured conveniently by tools like TCPdump. Hence, our research interest focuses on the video stream. In the experiment, packet loss events with one packet take up more than 40% of all events, and this CTC is developed based on the statistical result.
Inspired by these results, in this work, we propose a CTC scheme based on VoLTE video stream via dropping out packets which are numbered with target RTP sequence number. In particular, the covert message to be transmitted is transformed into the sequence numbers in our scheme, which means that a covert message is grouped into fixed length blocks, and mapped into three sequence numbers of RTP based on the mapping matrix. The covert message that to be delivered is subdivided into blocks with specified bit length; then each block is modulated into the corresponding segment of overt traffic. To represent data blocks with sequence numbers of dropout packets, a mapping matrix is designed to link them. Meanwhile, the parameters of this scheme are flexible, and optimizing the parameters for better undetectability, robustness, or robustness is feasible.
The main contributions of our work are summarized as follows:
A novel method is proposed to build the CTC over VoLTE.
A mapping matrix is utilized for the correlating the data blocks with the sequence numbers of lost packets.
Building a CTC via dropping out packets is proved to be feasible for VoLTE video stream.
The remainder of our paper is organized as follows: In section “Preliminaries,” we show the preliminaries of this CTC, such as VoLTE, RTP, and packet loss events in VoLTE. After that, we illustrate the designation of this scheme, including the system model, message grouping, data representation, and robustness method. Later, we demonstrate how to construct this CTC for the sender and receiver. Furthermore, we present the experiment’s results and analysis. Then, we review the related works about CTC and related schemes. Finally, conclusions and discussions are proposed to overview the CTC scheme briefly.
Preliminaries
VoLTE principles and features
The next generation mobile radio system, called LTE, is designed to boost data transmission rate and user capacity. Distinct from the circuit-switched technique used in the traditional telephone, the basic of VoLTE is the packet-switched network mechanism. 21 Via the all-IP technology utilized in LTE core network, VoLTE provides various types of multimedia services to users with common Internet-based protocols. 22 With the guarantee of LTE infrastructure, VoLTE can service more end users with a high-definition audio, and end-to-end delays in VoLTE can be reduced to 150 ms with one way. 23 According to the VoLTE standard, packets of VoLTE share QoS Class Identifier (QCI) of 1 or 2, which is higher than 8 or 9 of traditional VoIP applications such as Skype and WeChat. 24 That means, both jitter and packet loss rate in VoLTE are lower than VoIP applications; excessive modifications of IPDs or packet orders could be identified by the warden.
Another feature of VoLTE is that the payloads of VoLTE packets are not encrypted; thus, arguments like sequence numbers and timestamp are accessible. Since VoIP applications like Skype encrypt the entire payload of user datagram protocol (UDP) packets, acquiring the sequence numbers in the RTP header is technologically impossible. 25 This means that retrieving the sequence numbers of lost packets in VoLTE is practical, even if the received packets are out-of-order. Thus, we choose VoLTE as the overt traffic for this CTC based on packet dropout. Except for VoLTE scenario, this CTC scheme is also available for those having a random distribution of packet loss events and accessible sequence numbers.
Familiar with VoIP applications, VoLTE is designed to support multimedia streams, such as the video stream. However, streams in VoLTE video call are composed of three parts, the signaling stream, the audio stream, and the video stream (Figure 1). Besides, these streams are dealt through separate modules in the UE. In general, there are two processors in the modern UE, one is the AP used for executing most computing tasks including video processing and another is the baseband application (BP) embedded with LTE modem. 26 The audio stream which is coded by other modules is packaged into RTP packets; then they are forwarded by the LTE module in BP. Meanwhile, the video stream captured by AP module is delivered through the IP stack by the system kernel. Thus, packets generated by AP can be influenced by extra system processes compared to straightforward loads in BP. 27
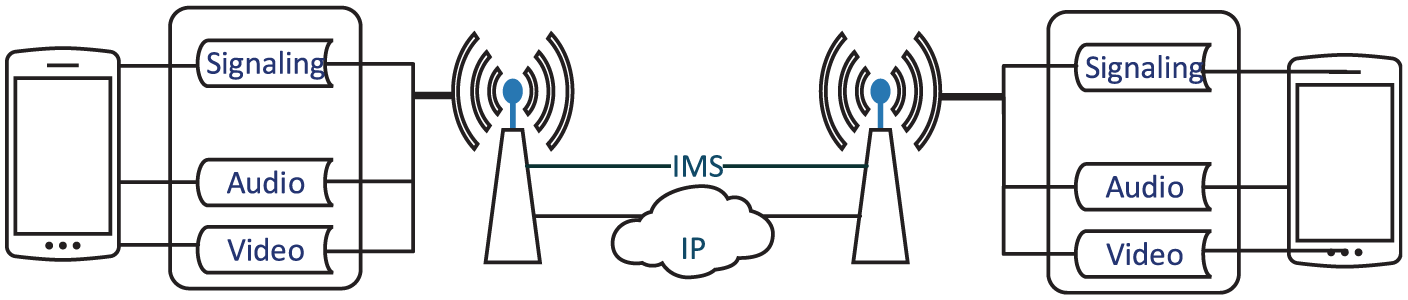
Three different channels of VoLTE traffic during the video call.
Thus, modulating a covert message into the video stream stealthily is more practical than into the audio stream. Covert channel designers have to mimic the time regularity of audio stream, which provides little space to operate. On the other hand, the video stream can be disturbed by other runtime noise; thus, it provides an opportunity to design a CTC without violating the regularity of VoLTE. On the other aspect, since the audio packets and the video packets are delivered through different channels with unequal UDP ports, the data are dealt separately and uncorrelated. Thus, building this CTC over the video stream of VoLTE has no correlation between the audio stream, metrics like undetectability, robustness, and throughput can be evaluated directly.
RTP in VoLTE
Real-time transport protocol (RTP) is the protocol employed by VoLTE, which provides end-to-end delivery services for data with real-time characteristics, such as interactive audio and video. 28 Built on UDP, RTP stream is not blocked during the communication. Thus, jitters and transmission delays of RTP packets are only under the influence of network condition rather than UE’s capacity. In addition, feeding back of transmission quality is also embedded into RTP, which is named as real-time transport control protocol (RTCP). By reporting network jitter and packet loss rate through RTCP payload, the sender could adjust transmission parameters to provide better service.
There are several parts in the RTP header, including the sequence number, timestamp, synchronization source recognition code (SSRC), packet length, marker, payload type, and so on. After receiving the invitation signaling, parameters for the VoLTE call are negotiated so that they can be supported by both sides. To identify a session, SSRC is introduced as a unique identifier, which varies if communication restarts. According to the negotiation information captured ahead of RTP streams, the payload type field is the identifier of different multimedia types.
Using tools like TCPdump, RTP packets are captured during VoLTE call. After analyzing payload types of captured packets, it is proved that only video stream with payload type of 115 can be captured through system kernel. Furthermore, to satisfy restrictions of max transmission unit (MTU) of intermediate network nodes, video frames are sliced into several RTP payloads that would not violate the MTU length. Thus, it is common that the packets of one video frame are sent in a very short period time, which results in the conflict at a higher possibility.
CTC for VoLTE
As mentioned above, packets of VoLTE are divided into three categories. However, the audio information of VoLTE is coded by adaptive multi-rate wideband (AMR-WB), which has a strict inter-frame interval restriction. Although the video channel is designed in the same way, the image process module of AP could be disturbed by the complexity of the captured image. Thus, compared to the definite data size of audio frames, video frames captured through the smartphone’s camera may vary from 20 to 70 KB, which results in the variation of the number of packets (NoPs) corresponding to the whole frame. 29
Except for the data path, packets of the audio stream are granted with the QCI of 1, which guarantees the packet loss rate lower than

The variation of packet lengths for video packets.
Furthermore, packet loss events which are caused by the network condition are supposed to be discrete. That is, packet loss events with more continuous packets take up a smaller percentage of total events. Corresponding to the captured result, packet loss events with not more than five consecutive packets take up almost 90% of the total. As shown in Figure 3, the cumulative distribution function (CDF) curve rises rapidly at the start of the horizontal axis, and then, the curve rises slowly until it reaches the maximum of the vertical axis. Inspired by the result, in this work, we propose a CTC scheme for VoLTE video stream via dropping out packets having target sequence numbers. To modulate a covert message into the target position, a mapping matrix is utilized to link the blocks of the covert message with the sequence numbers in RTP header. Other mechanisms like robustness method and demodulation algorithm will be introduced in section “Construction.”

The cumulative distribution function (CDF) of the number of packets (NoPs) of packet loss event. The marked vertical line corresponds to the percentage of packet loss events that have consecutive lost packets not more than 5.
System design
We first introduce the system model of this CTC. We then describe how to convert the covert message into RTP sequence numbers. The method that guarantees the transmission robustness is discussed in the last.
System model
The system model is shown in Figure 4, in which the sender is Alice and the receiver is Bob. The notations used in the figure are illustrated in Table 1. The overt traffic to be modulated is the video stream in VoLTE. For the sender, the covert message to be sent is grouped into blocks, according to the configuration of block length expressed as bl. Then, the data blocks noted as
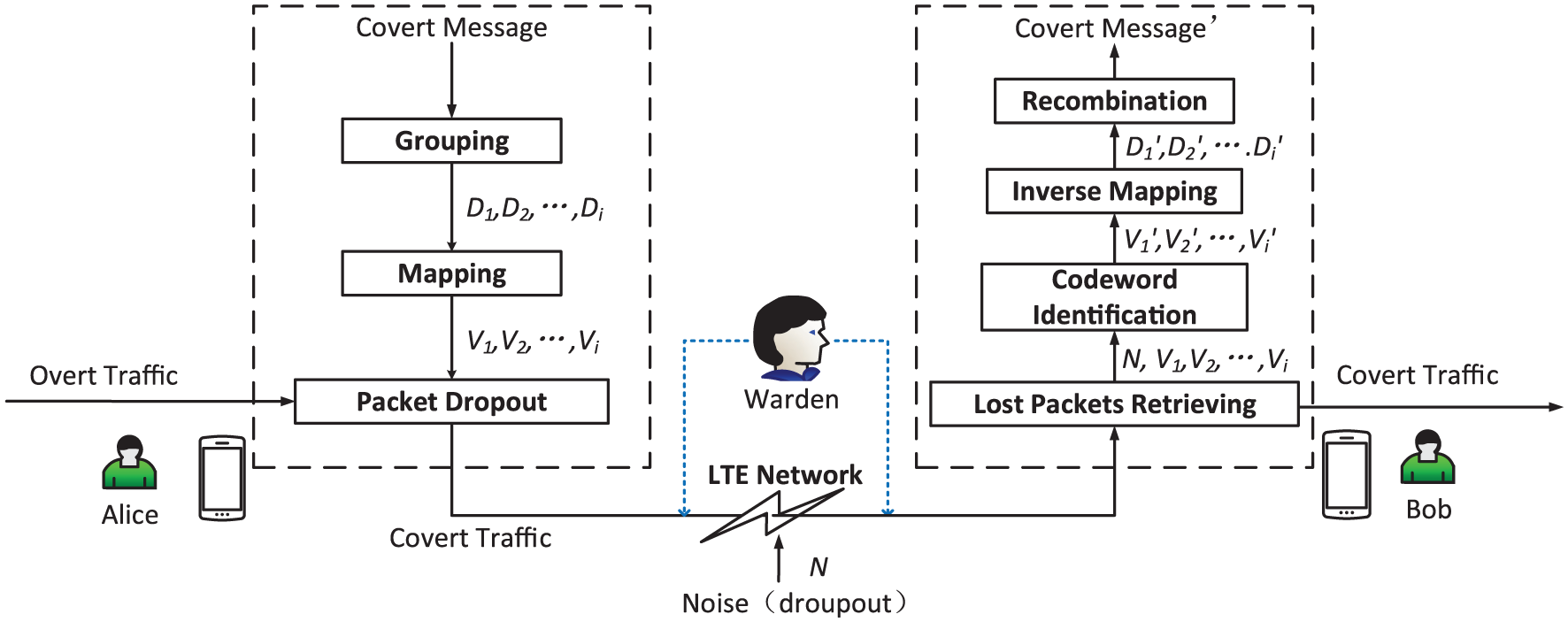
The system model of this CTC. The covert message is grouped into equal length blocks and converted into decimal integers. Then, the data block noted as
The notations and symbols.

RTP: Real-Time Protocol; LTE: Long-Term Evolution.
For the receiver, sequence numbers of lost packets should be monitored during the communication process. Depending on the configuration of
Data mapping
The key point of this CTC is how to represent a covert message with RTP sequence numbers of dropout packets. To solve this, two measures are taken in the proposed scheme. The first step is data grouping, which means that the transmission is not affected by the length of the covert message, and the covert message is grouped into equal length blocks and transmitted separately. The second step is the mapping matrix, which connects the data blocks and the sequence numbers.
Packets in the overt stream are divided into sequential parts, which correspond to the blocks in the covert message. That means, the receiver can restore equal length covert message without transmission control. By transmitting data blocks separately, bit error rates (BERs) of different blocks are independent even network condition varies randomly. Another feature of this scheme is that only packet dropouts of network noise can influence the demodulation result. Thus, transmission jitter and packet reordering have no influence on it.
In this proposed scheme, the length of blocks in the covert message expressed as
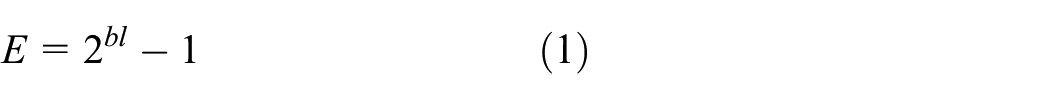

As aforementioned, the matrix is utilized to link the data blocks and the positions of packets. The number of columns and rows of the mapping matrix depends on the setting of
The relationship between



In the first stage, for the matrix
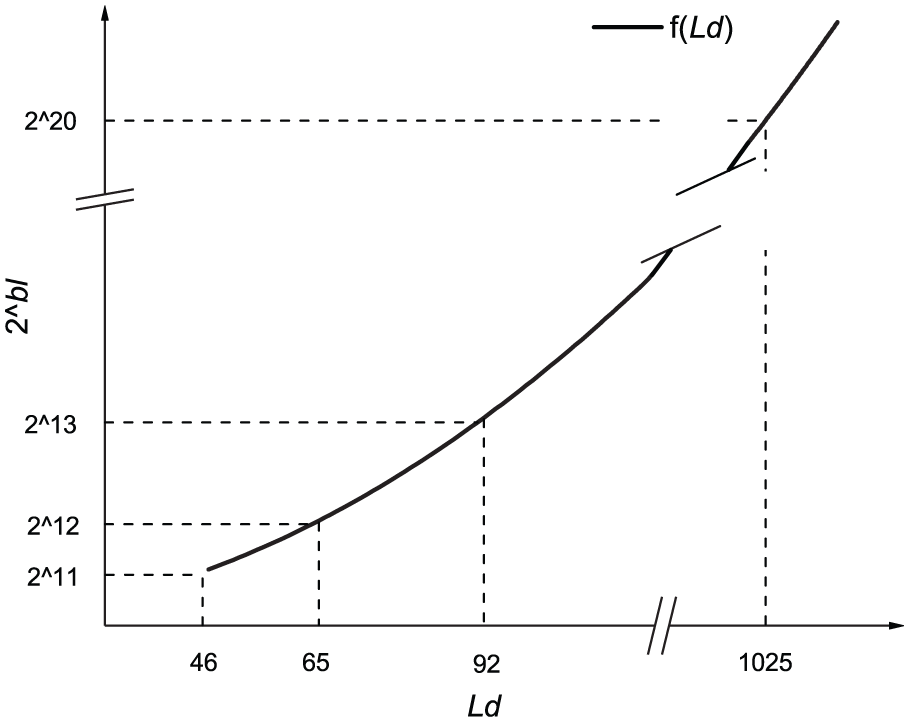
The relationship between
Generation of
Since this CTC scheme is built over VoLTE, which provides a guarantee of transmission delay time in an acceptable range. Thus, the receiver could retrieve the sequence numbers of lost packet timely, even if some of them are out-of-order. Benefited from that, this scheme is only effected by the lost packets in network noise rather than packet reorder.
To guarantee robustness, a packet noted as

Equation (6) shows the function used in the proposed scheme, where the
Construction
In this section, we illustrate the detail of modulation and demodulation. For the sender, the covert message to be transmitted is modulated into positions of dropped packets having target sequence numbers. For the receiver, by monitoring the packet loss events, sequence numbers of lost packets are retrieved. By referring the error detection information, codewords can be identified from sets of symbols. Then, through an inverse mapping procedure, the covert message is accessible to the receiver of this CTC.
Modulation
The procedure of modulation mainly aims at modulating the covert message into the overt traffic. As aforementioned, the covert message to be transmitted is grouped into equal length blocks, and the blocks are transformed into decimal format. By referring to the mapping matrix, the data blocks are mapped into three sequence numbers of video packets. Finally, packets having target sequence numbers are dropped out during the VoLTE call.
Data grouping
Before this process, the configuration of
Thus, each block could be modulated separately, and other methods like synchronization are naturally embedded into the segmenting mechanism. Benefited from this designation, both the sender and receiver could synchronize the transmission through referring to the variation of sequence number rather than the clock.
Data mapping
In this procedure, the grouped blocks are mapped into three positions noted as




Since the mapping matrix is an upper triangular matrix, calculating the
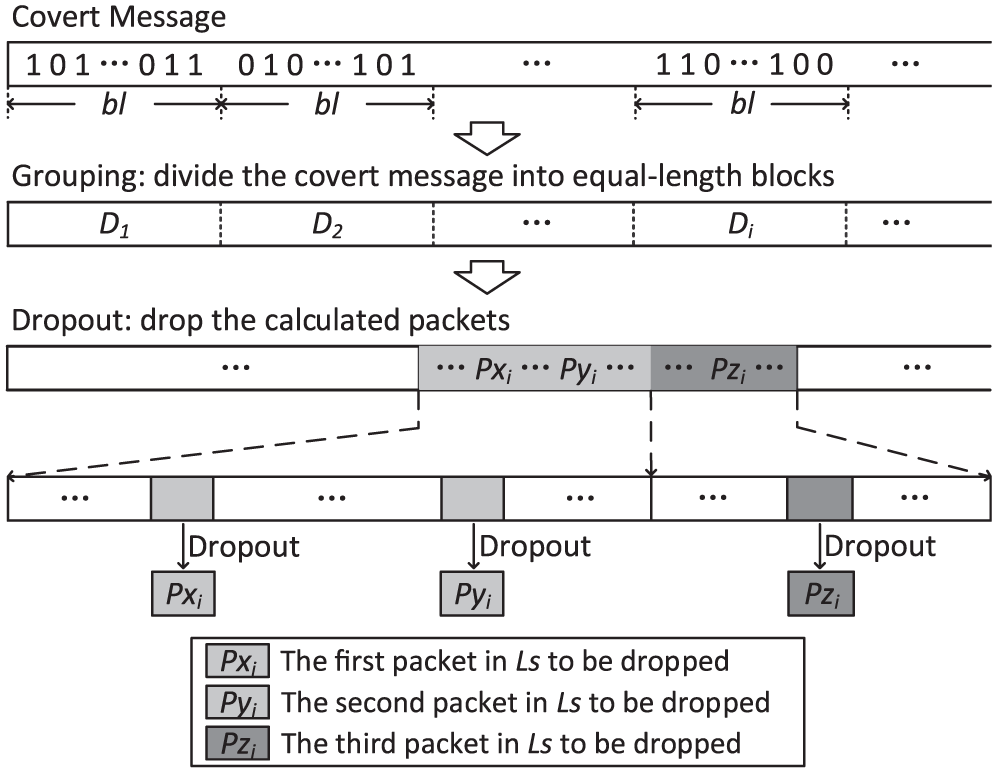
The procedures of data grouping and mapping. The binary covert message is grouped into equal length blocks showed as
Finally, based on the precise value of

A mapping matrix used in this CTC. Depending on the configuration, the number of lines and columns are set to
Now, codewords of this CTC are generated. After dropping out the VoLTE packets having the sequence numbers in the RTP header, the covert message is modulated into the overt traffic.
Demodulation
In this section, we explain how to restore the covert message which is embedded into the sequence numbers of lost packets. The demodulation process mainly contains procedure of codeword identification and inverse mapping; other measures like lost packets’ sequence numbers retrieving and recombination are not the key point, so they are not illustrated particularly here.
Codeword identification
With retrieved RTP sequence numbers of dropout packets, the receiver should identify the real codeword from all the available symbols. Thus, the error detection information
The codeword identification procedure aims at retrieving the codeword sent by the sender from the symbols which are disturbed by the network noise. As shown in Figure 8, the retrieved RTP sequence numbers of lost packets are separated based on the range of
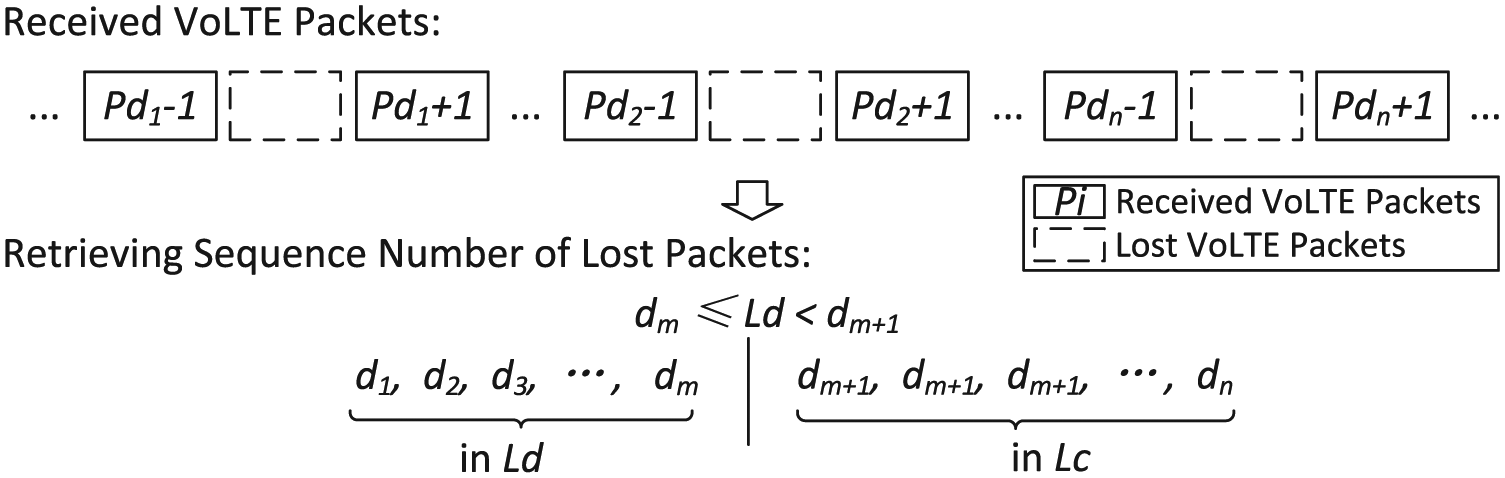
The procedure of separating the retrieved sequence numbers into different sets.

Inverse mapping
With the retrieved codeword, the next step for the receiver is converting the codeword into the original data. Since this step is the inverse operation of the mapping step on the sender side, the mapping matrix is also adopted.
The major operation of this step is calculating the corresponding
As the covert message is grouped into blocks and transferred separately. To get the entire message, the receiver should recombine all the blocks in the binary mode. After all the procedures mentioned above, a covert message is transmitted to the receiver by modulating it into the sequence numbers of dropout packets in VoLTE video stream.
Experiment results and analysis
In this initial exploration, our focus is whether we can build the CTC for VoLTE. To this end, we experimented with different configurations of
Undetectability
We calculate the CDFs of the NoPs in packet loss events and inter-packet numbers between loss events. We first calculate the statistical result of packet loss events, which includes the counts of consecutive lost packets and NoPs between adjacent loss events. The results are presented in Figure 9(a) and (b), which reveal the configurations’ effect on the distribution of packet loss events. Figure 9(a) shows that if the block length is shorter than 15, the line of covert traffic will reach 1 earlier than the overt traffic. Since only two packets are dropped in each

Results of the undetectability test under different
We also use a statistical shape test method, called Kolmogorov–Smirnov (K-S) test. The result of the K-S test reveals the similarity of two distributions, and if the p-value is lower than 0.05, it means that the two distributions are not identical.
32
Figure 9(c) shows the K-S test results of the distributions in Figure 9(a), and the reference dataset is the original distribution. In the results shown in Figure 9(c), if the configuration of
In summary, through the CDF shape test and the K-S test, this CTC scheme is stealthy if the configuration of block length is larger than 16. The conclusion is the same as the theoretical analysis, since the smaller the block length is, the smaller
Robustness
The transmission quality of this CTC is influenced by the lost packets introduced by the LTE network. With the higher packet loss rate, there will be more symbols to be identified in the codeword identify procedure of demodulation. To validate the quality of this CTC, the BER is measured with various noise levels designed to mimic the actual circumstances.
As shown in Figure 10, the results of BER are correlative to block length and packet loss rate. To simulate various scenarios, the packet loss rates are configured from 0.5% to 3.0% with 0.5% gap. In Figure 10, the horizontal axis is the values of the block length, the vertical axis indicates the results of bit error rate, and lines with different colors are used to indicate various noise level with different packet loss rate. Generally, the covert transmission will get worse with the increasing block length even under the same packet loss rate. Besides, even if the configuration of block length is the same, the result of BER is also sensitive to network condition, since the higher the packet loss rate is, the more symbols should be identified.

The bit error rate under different
However, although we have tried several ways to select packets that are really dropped by this CTC, the BER is almost the same. The reason is the poor signal-to-noise ratio. For example, if block length goes up to 20, the corresponding
Trade-off between metrics
By analyzing the experimental results, we have shown that BER can be reduced by decreasing block length. However, this also results in deteriorating undetectability. To balance the robustness, throughput, and undetectability, we sum up the performance of different block length in Figure 11. In the figure, the horizontal axis represents the value of block length, and the left vertical axis reveals the throughput while the right vertical axis reveals the BER and additional packet loss rate due to modulation (Figure 11).

Comparison of metrics under the different configuration of
According to the figure, with the increasing of the block length, the throughput and additional packet loss rate are decreasing through a similar tendency. As aforementioned, the CTC can be detected if the configuration of block size is lower than 16, so the best block length to be used is 16 to most of the scenarios. Besides, the larger value of block length behaves well in undetectability, especially for the scenarios with better network condition. However, the packet loss rate of VoTLE is not a fixed value, which could vary from 10% to almost zero. Therefore, the configuration of parameters depends on the actual network scenario, which means that a small value is suitable for scenarios with high packet loss rate, and a lager value for scenarios with low packet loss rate. In summary, if the network is getting worse, a smaller block length should be utilized to guarantee low BER and acceptable throughput. If the network is getting better, a bigger block length should be utilized to avoid detection.
Evaluation
With the analysis of experimental results mentioned above, this CTC scheme is proved to be effective with suitable configurations of parameters under stable network condition. At the same time, the state-of-the-art research of CTC over VoLTE is also proved to be feasible. Zhang et al. 17 proposed the CTC scheme via adjusting silence periods called silence-period based covert channel (SPCC). Zhang et al. 33 also proposed another CTC scheme achieved by packet rearranging over VoLTE called NoP-based gray code timing channel (NoP-GCTC) (Table 2).
Comparison between other CTC schemes over VoLTE and this packet dropout CTC.

CTC: covert timing channel; BER: bit error rate; SPCC: silence-period based covert channel; NoP-GCTC: NoP-based gray code timing channel.
With the comparison of throughput, BER under packet loss rate at 1%, and BER under packet loss rate at 2% between this CTC scheme and other CTC schemes over VoLTE, it is definite that this scheme achieves the same range of throughput compared to other schemes. In some scenarios, the robustness of this CTC is not as good as others. However, even if the received packets are out-of-order, the receiver of this CTC could retrieve the sequence numbers of lost packets definitely at the end of the communication. Thus, if the density of lost packets of network noise varies, the robustness of this scheme is acceptable in blocks with normal packet loss rate.
In the actual communication environment, a warden settled on the LTE network may appear as an active defending measure. However, no matter which side the warden is, the dropped packets are regarded as the result of transmission failure due to a wireless collision. As a consequence of this, this CTC is stealthy under the inspection of packets’ statuses, contents, and regularities. Even more, if the active warden drops packets randomly or consecutively, the influence is equivalent to the strengthening of the packet loss rate. Thus, the only effect is the aggravating of robustness on the receiver side. Meanwhile, a signal of packet loss rate exceeding the normal ranges is also noticeable. Therefore, this CTC scheme is stealthy and feasible under the monitoring of the warden.
Related work
A CTC can leak covert message via modulating target timing behavior. Most CTCs are established over end-to-end communication, like HTTP,13,34 secure shell (SSH), network time protocol (NTP), 35 or other TCP-based protocols. 36 With the rising popularity of instant message applications, CTCs are proposed for applications like Skype, 10 WeChat, and others. The classic CTCs include On–Off CTC, Jitterbug, IPD-based CTC, MB-CTC, and TRCTC. 14
The entities modulated by CTC can be various timing features. Cabuk et al. 4 proposed a CTC based on controlling the transmission behavior in a certain time. By setting a fixed time window before transmission, the sender can modulate the covert message via controlling packet transmission in the time window. 37 Liu et al. 38 proposed a model-based CTC using fountain code. With the help of fountain code, models shared by the sender and receiver can be updated through varied IPD distribution. Ahsan and Kundur 39 proposed a method to build a CTC using packet reordering, which adjusts the packets to the target sequence. El-Atawy et al. 40 proposed a robustness covert channel based on out-of-order packets, which modulates several bits of the covert message into packet combinations. Luo et al. 41 proposed a multi-stream-based CTC scheme, which maps the covert message into 10 kinds of packet combinations.
So, to enhance robustness, Houmansadr et al. 42 proposed an IPD-based CTC using robust code. Several coding algorithms are considered in the framework; thus, it can absorb features of different algorithms. Archibald and Ghosal 10 proposed a CTC scheme over Skype, and it guarantees robustness by mapping symbols to multi IPDs. Wu et al. 43 proposed a CTC scheme based on Huffman coding, which improves robustness with four kinds of error correcting codes. Sellke et al. 44 proposed a novel CTC method based on mapping L-bits to N-packets, which means that L-bits are modulated into N IPDs.
However, the features of overt traffic in those schemes are not familiar with VoLTE. CTCs over VoLTE should be designed with other modulation entities. Zhang et al. 17 designed a CTC over VoLTE via adjusting silence periods, which are the normal phenomenon during the end-to-end audio communication. By adjusting the packet sequence at the end of the silence period, blocks of a covert message can be modulated into the relative distance between the packets carrying an audio payload and the packets of silence insertion descriptor (SID). Zhang et al. 33 also proposed a CTC over VoLTE via packet rearranging; this scheme adjusts the number of RTP packets between RTCP packets to deliver a covert message. The experimental results showed that these schemes are stealthy under the current detection approaches like K-S test, Kullback–Leibler divergence test, and CDF test.45,46
By analyzing the captured VoLTE traffic, we discovered that most packet loss events of VoLTE are distributed randomly. Consequently, in this article, we design a new packet dropout–based CTC scheme, which modulates the blocks of a covert message by dropping out certain packets with target sequence number.
Conclusion
We have proposed a CTC over VoLTE video stream by dropping out target video packets. We also employ the two-dimensional mapping matrix to map the blocks of covert message and codewords, which consist of three packets to be dropped. By experiments that are based on the captured traffic, we have demonstrated that the scheme is efficient and acceptable. By adjusting the configuration of the block length, this scheme allows the trade-off between robustness, throughout, and undetectability. As the network condition of VoLTE is variable, this scheme is improbable with an adaptive configuration of block length and
Since this CTC utilizes the dropped packets as the covert message carrier, the inherent drawback of this scheme is that the demodulation accuracy aggravates if the packet loss rate exceeds the normal ratio. Besides, the throughput of this scheme correlates with the modulation cost. With the improving of the density of dropped packets, the performance can be enhanced to the corresponding level. However, to transmit the covert message stealthily, the configuration of block length should not be less than 16; thus, the max throughput of this scheme has an upper limit. This CTC scheme is also improvable in the aspect of robustness; methods like retransmission and error correction code can be utilized in the future improvement.
Footnotes
Handling Editor: Gary Leavens
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partly supported by the National Natural Science Foundation of China (no. U1636213), Beijing Municipal Education Commission under Grant (no. KM201510016009), Excellent Teachers Development Foundation of BUCEA (no. 21082717046), National Key R&D Program of China (no. 2016YFC060090).