
Abstract
Localization is an essential service for numerous applications in wireless ad hoc networks. In particular, cooperative localization is a widely used technique for improving performance by utilizing information obtained from adjacent sensors. In general, distributed localization in ad hoc networks shows relatively low performance compared to centralized localization. This is partly due to the lack of information and partly because of error propagation. In this article, we propose a localization algorithm considering the location uncertainty of reference nodes. The proposed algorithm uses a dilution of precision, depending on the geometric deployment of reference nodes, as a representative value of uncertainty. The proposed algorithm estimates the position of a target node and re-estimates positions of reference nodes concurrently. Using the proposed algorithm, we can reduce the effect of accumulated error propagation and enhance the accuracy of estimated node positions. We verify the feasibility of the proposed algorithm and compare its performance with that of other localization schemes under several circumstances by performing simulations. The results show that the overall performance of the proposed algorithm outperformed that of other schemes.
Keywords
Introduction
Numerous applications require localization services in wireless networks. Location-based scheduling, tracking, and wide-area monitoring are examples of those applications. The global positioning system (GPS) is the simplest way of finding the position of nodes. However, it is unsuitable for indoor scenario where the GPS signal strength is weak. Moreover, it is not cost-effective to equip each sensor nodes with a GPS receiver. An alternative way of estimating a position of node is to use adjacent sensor nodes.
Sensor networks consist of a number of sensor devices, each of which is equipped with a processor that has low computational ability. Moreover, each device has a limited battery capacity. In this situation, localization algorithms that require excessive computational complexity and high power consumption are unsuitable. In general, localization schemes can be classified into a centralized scheme or a distributed scheme. One or a few central nodes collect measured values and process data for the centralized localization scheme. On the other hand, each node has its own computation ability and handles data from neighboring nodes by itself for the distributed localization scheme. Hence, a distributed localization scheme is more suitable for the sensor network localization.
Each node communicates over multiple hops to other nodes in distributed sensor networks. Sensor nodes estimate their positions based on the position of neighboring nodes. In that process, position errors generated from neighboring nodes are accumulated in the position error of the target node. The most intuitive method for reducing error propagation is to decrease ranging errors. Generally, high-resolution algorithms such as multiple signal classification (MUSIC), 1 estimation of signal parameters via rotational invariance technique (ESPRIT), 2 and the maximum peak-to-leaking ratio (MPLR) algorithm 3 can be applied to enhance the ranging performance. In the work by Chehri et al., 1 the MUSIC algorithm uses the orthogonality between the noise subspace and the signal subspace. In the work by Saarnisaari, 2 the ESPRIT uses the phase difference between two sub-arrays for time-of-arrival (ToA) estimations. In the work by He et al., 3 the MPLR calculates the phase offset using the MPLR, and it then correctly derives the time delay of the first path. However, these ranging techniques are out of the scope of our research. In this article, we focus on minimizing location errors within a given ranging errors. Previous research works on localization techniques that are suitable for ad hoc networks were reported in literature.4–6 Range-free localization algorithms7,8 find their position by obtaining information from neighboring anchor nodes without range measurements. On the other hand, in range-based algorithms,9,10 node positions are estimated using the measured distance. A number of range-based algorithms and their modifications have been proposed.11–15
Localization accuracy can be improved by selecting proper node combinations among neighboring reference nodes. Even when ranging error variations are exactly the same, the localization performance varies according to the geometry of the selected reference nodes set. Yang and Liu 11 proposed a confidence value that is related to the measured range. This confidence value is used to select anchor nodes in order to reduce estimation errors. In the work by Hadzic and Rodriguez, 12 Cramr–Rao lower bound (CRLB)-based utility functions were coupled with game theory to set the parameter for selecting the reference node. Wang et al. 13 selected a set of nodes that minimize the entropy of measurements. However, these schemes are still centralized approaches and are unsuitable for distributed networks.
Moreover, these schemes do not consider the position uncertainty of reference nodes. Generally, in a multi-lateration–based distributed localization approach, nodes for which their positions have already been estimated act as anchor nodes. Consequently, nearby nodes estimate their positions using information obtained from these nodes. In this procedure, it is assumed that the obtained node positions are accurate, and that they do not have position errors. However, the assumption accompanies an error propagation, which causes serious degradation with respect to a feasibility of a localization scheme. Therefore, it is more natural that the position of the reference nodes, which is estimated by other nodes, includes position errors in practical situations.
In order to consider the position inaccuracy of reference nodes, in the work by Ihler et al., 16 a sensor network localization problem is formulated as an inference problem and the non-parametric belief propagation (NBP) algorithm is applied. The position error of each node is treated as a belief, which is iteratively updated and exchanged with neighboring nodes. However, it is not guaranteed that the belief propagation technique converges in a network with loops. Furthermore, belief propagation techniques consider position errors but do not consider range measurement errors. In the work by Zhou et al., 17 the variational inference–based positioning (VIP) scheme, which uses a Wishart density to characterize the non-deterministic measurement accuracy, is proposed.
In this article, we propose a distributed localization scheme that considers both the range uncertainty and the position uncertainty of reference nodes. The dilution of precision (DOP) is used as the position uncertainty value of nodes. The DOP has long been used in GPS-related localization systems. 18 The DOP is the term used in the navigation field to specify the effect of a satellite geometry on the accuracy of a receiver location, and it has been mathematically proved by Yarlagadda et al. 14 We select a set of reference nodes that have a low DOP value. In other words, we choose a highly confident reference node set. Then, we estimate the position of target nodes and re-estimate the position of the reference nodes simultaneously. With the proposed localization scheme, we can reduce the overall location estimation errors. We verified the accuracy of the proposed localization scheme in several anisotropic node distribution scenarios.
The rest of the article is organized as follows. In section “Preliminaries,” we describe the system model, notations, and assumptions for the proposed localization scheme and problem. Then, in section “Node location uncertainty,” we explain the node location uncertainty and select a suitable concept of an uncertainty value. In addition, we explain the node selection scheme considering the node location uncertainty. In section “Probabilistic localization,” we present the principle of probabilistic localization, while in section “Proposed localization scheme,” we explain the procedure of the proposed localization scheme. Then, we verify the performance of our proposed algorithm by performing simulations, and we describe the simulation results in section “Simulation results.” Finally, we conclude the article in section “Conclusion.”
Preliminaries
Notations and assumptions
In this section, we define notations that are used in this article and describe assumptions used for modeling the system.
First, we assume a
We classified nodes into three types according to their role. First, an ordinary node represents a node that does not know its position. That is, an ordinary node is to be localized. Then, an anchor node is a node that knows its position confidently with the aid of a reliable source such as GPS or some pre-installed information. An anchor node thus assists other nodes with respect to localization. Finally, a reference node is a node that provides its position information to an ordinary node in order to estimate the ordinary node’s position. Both anchor nodes and localized ordinary nodes can be used as reference nodes.
We assume that a position error follows Gaussian distributions with an uncertainty value as its parameter. We further assume a channel that is time-invariant and that guarantees reciprocity. Therefore, if node
The proposed algorithm is not applicable only to any specific localization system (e.g. received signal strength indicator (RSSI), ToA, and time of flight (ToF)). On the contrary, our algorithm can be applied to any system provided that it is based on multi-lateration with measurement errors.
Node location uncertainty
We define the node location uncertainty in section “DOP.” Then, in section “Node selection considering location uncertainty,” we present the reference node selection scheme using this location uncertainty value.
DOP
A ranging is the first step in the node location estimation. The location of an ordinary node can be calculated from the range information using a multi-lateration scheme. Estimating an n-dimensional ordinary node position requires the coordinates of

where

The matrix
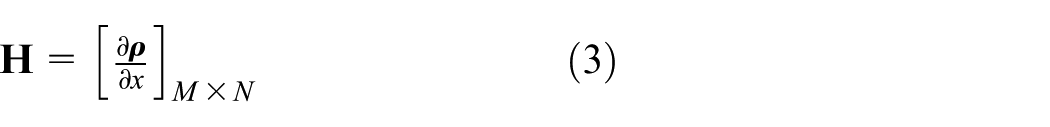
where M is the number of reference nodes used in range measurements, and N is the dimension of the coordinate components. Matrix
Since the distance measurement between two nodes does not affect the distance measurement between other nodes and every node uses the same measurement system, each component of

where
Then, the variances of a position error are functions of the diagonal elements of

Node selection considering location uncertainty
Figure 1(c) and (d) shows the DOP distribution of the near region around reference nodes whose geometric deployment is not co-linear or co-linear, respectively. The geometric deployment of selected reference nodes set is shown in Figure 1(a) and (b). The blue dots and the black dots in Figure 1(a) and (b) denote a reference node and an ordinary node, respectively. In Figure 1(c) and (d), the color represents the DOP value of each point. Localization is less accurate with changes in color from blue to red.
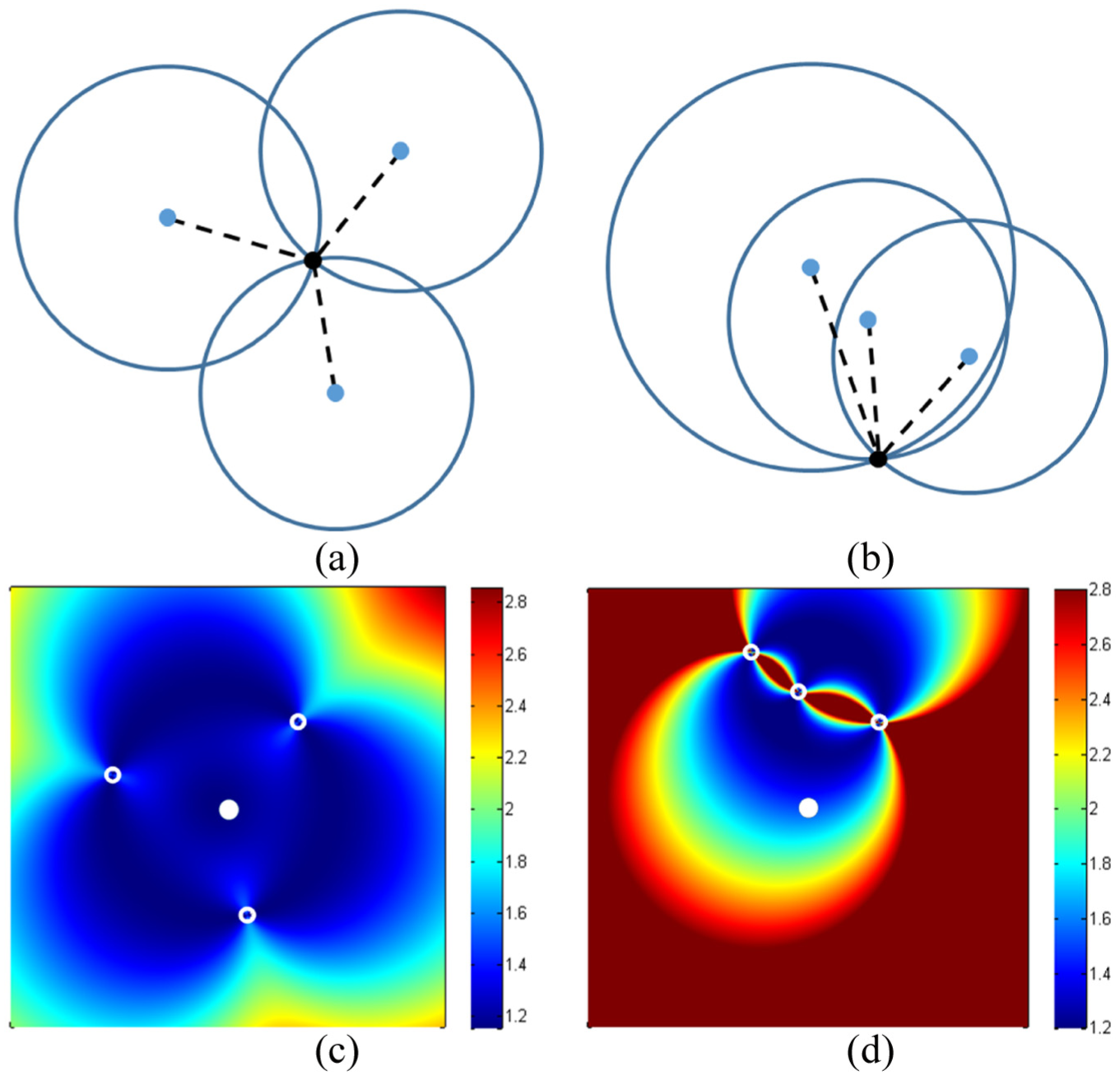
Impact of reference node geometry on the near-field DOP distribution: deployment of an ordinary node and reference nodes in (a) case 1 and (b) case 2. DOP distribution in (c) case 1 and (d) case 2.
The accuracy of the estimated position of an ordinary node is affected by the geometric deployment of reference nodes, as shown in Figure 1, even though all of the reference nodes have the same range measurements errors. In other words, it is necessary to find a set of reference nodes that have lower DOP values because estimated location errors depend on the geometric distribution.
Given a set of reference nodes
Probabilistic localization
A probabilistic approach is proposed by Ramadurai and Sichitiu, 15 where distance estimations are calculated from a received signal strength (RSS) and modeled as Gaussian random variables. Each node estimates its own position based on a probability density function obtained from neighboring reference nodes.
We adopt a probabilistic localization in our proposed localization scheme. We calculate the position of the ith ordinary node,

where

where
Figure 2 shows the probability distribution of a candidate ordinary node position in Figure 1. Nodes that are deployed in Figure 1(a) and (b) have a probability distribution as shown in Figure 2(a) and (b), respectively. We observe how geometric deployment affects the reliability of the estimated position from Figure 2. This result is expected, as discussed in section “Node location uncertainty.”
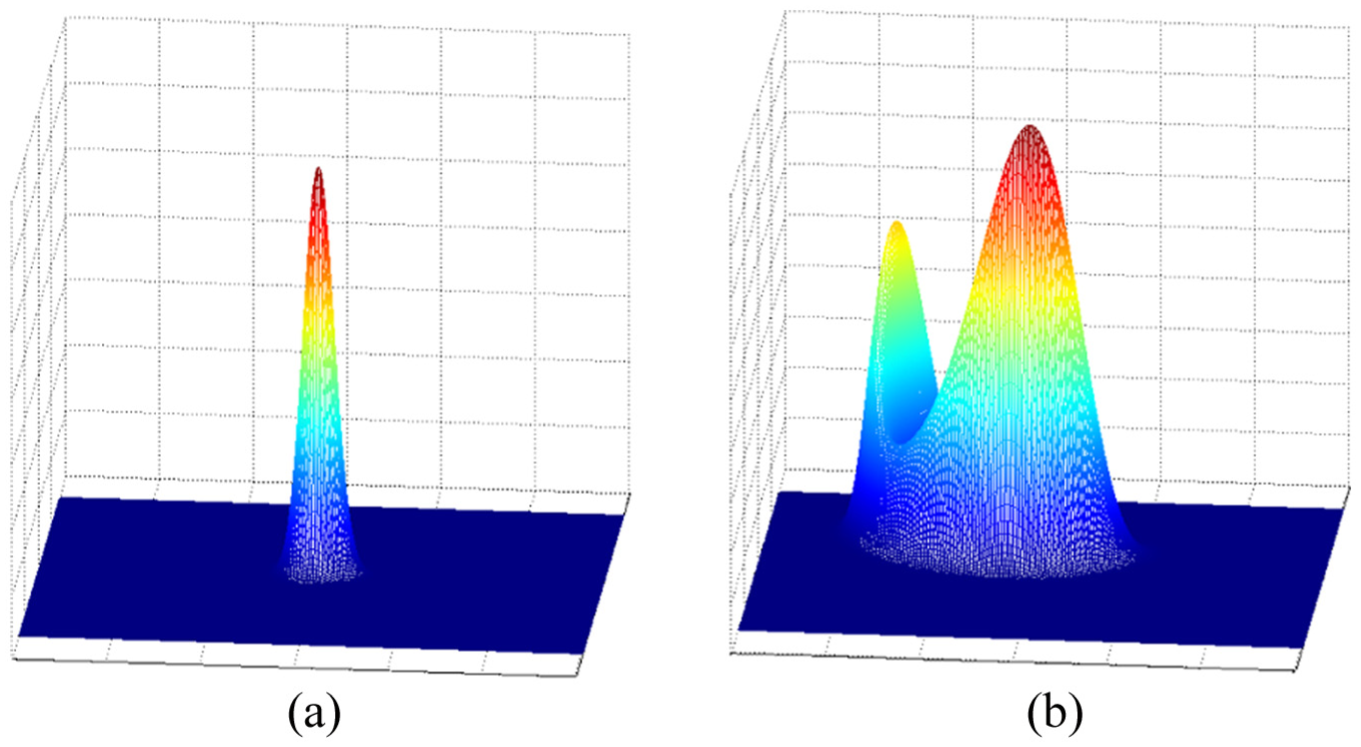
Probability distribution of a candidate ordinary node position: case of (a) Figure 1(a) and (b)Figure 1(b).
Proposed localization scheme
In this section, details of the proposed localization scheme are described. In section “DOP,” we explained the concept of DOP and its validity as a representative parameter of the position uncertainty. Then, in section “Probabilistic localization,” we describe the probabilistic localization, which is applied to our proposed algorithm.
In general, distributed localization schemes in ad hoc networks perform relatively poorly compared to centralized positioning schemes. This is partly due to a lack of information—a distributed localization scheme can only handle information from adjacent nodes—and partly due to accumulated errors.
The proposed algorithm uses a probability distribution function that includes not only the distance measurement uncertainty but also the position uncertainty of reference nodes. The probability function of the distance between a reference node and a target node is defined as equation (7). The candidate location probability function of a reference node

where
We combine equations (7) and (8) as follows

where
Equation (9) is the product of the probability density functions for the distance and reference node position. This consists of two parts:
Figure 3 shows a simulation result obtained upon applying the proposed localization method to one set of nodes, which consists of three reference nodes and one target node, among nodes constituting the distributed sensor networks. In Figure 3, it is assumed that one of the reference nodes is an anchor node that knows its true position without an error, and that other nodes (Ref. 1 and Ref. 2) know their estimated position with an inherent error. The position estimated with the proposed algorithm is closer to the node’s actual position than that with the least square algorithm. In other words, the proposed algorithm reduces the location ambiguity caused by inherent ranging errors. The cost function related to the probability distribution of the target node position in the case of reference nodes deployment in Figure 3 is shown in Figure 4.
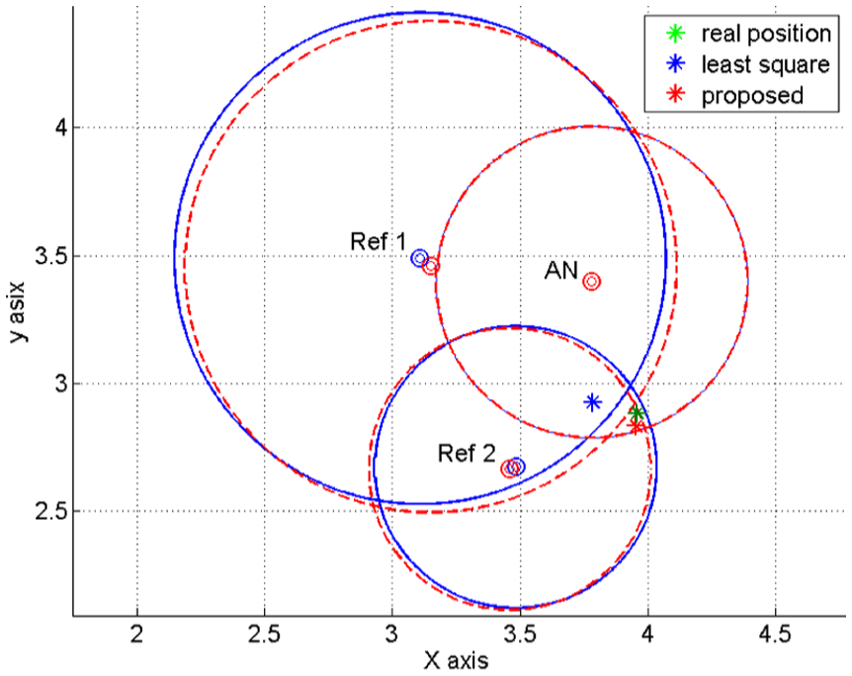
Original reference nodes position (denoted by blue dots) and their re-estimated position (denoted by red dots) along with the estimated target position in each case (denoted by a *).

The cost function (log scale) of the target node position.
The proposed scheme re-estimates the position of reference nodes in Figure 3. Figure 5 shows the location re-estimation result for a node whose position was estimated in Figure 3. The re-estimated position of the node is closer to its actual location after applying the proposed localization scheme. The estimated position of the node is used for the adjacent node’s location estimation process. During that process, the proposed algorithm calculates the re-estimated position of the node that acts as a reference node. Consequently, the estimated position of the node moves its true position. The more a node participates in the localization for its adjacent node, the better will be the estimated position of that node.

Example of a re-estimation process.
Simulation results
In this section, we examine the localization performance of the proposed algorithm. The main evaluation components are the position accuracy and accumulated error propagation. The anchor node ratio, coverage, number of nodes, and measured distance errors were modified depending on each scenario. The performance evaluation was conducted by comparing several schemes: least square, classical multi-dimensional scaling (cMDS), probabilistic localization without reference nodes re-estimation, and the proposed algorithm.
Simulation model
We verified the feasibility of our localization scheme. The performance of the proposed algorithm was evaluated in an
Performance analysis of the proposed algorithm
Comparison with other localization schemes
Figure 6 shows the estimated node positions of each localization scheme. In Figure 6, there are four anchor nodes of a total of 40 nodes in order to verify the overall performance. The communication range for one side of the entire space
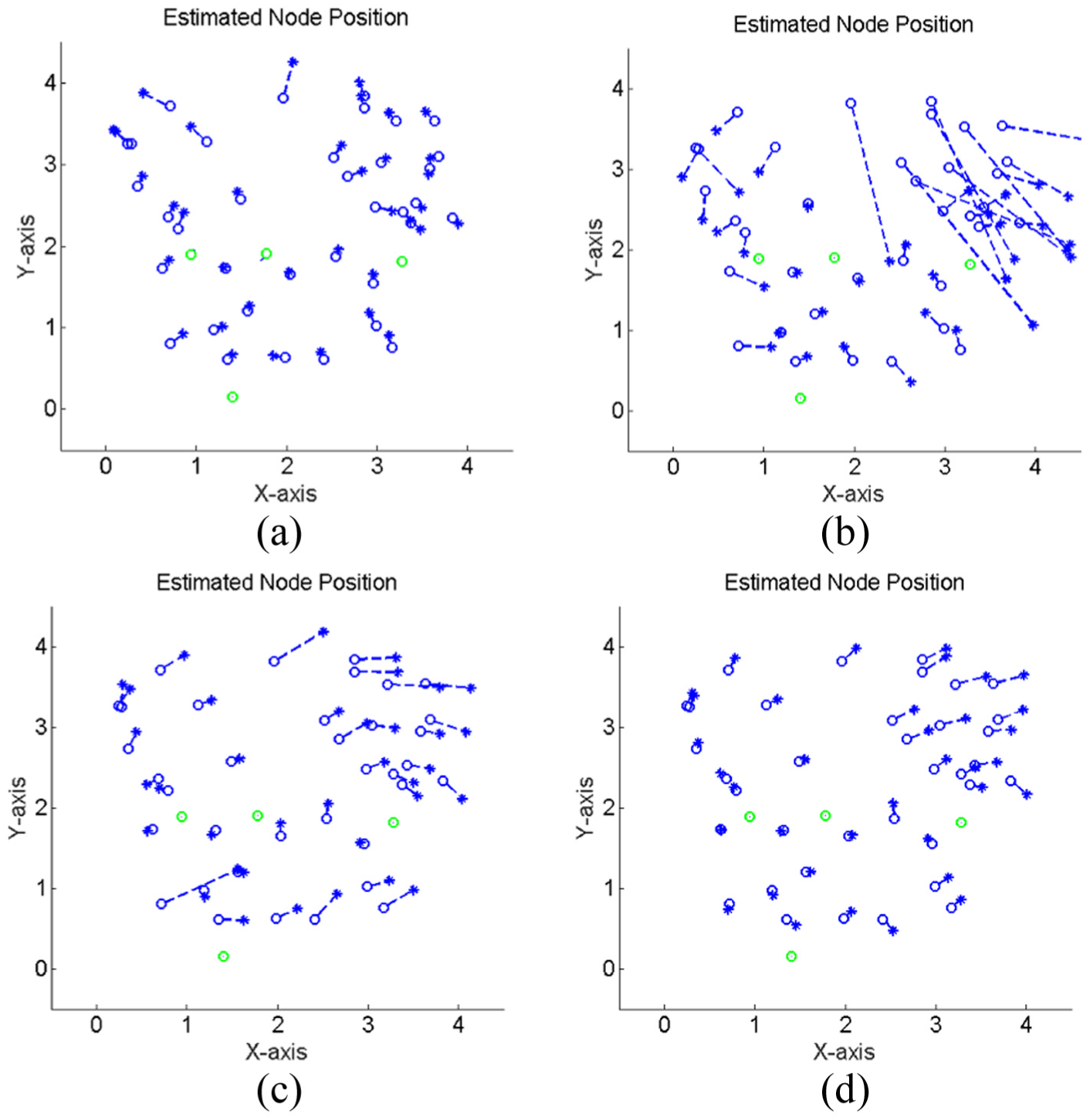
Comparison of the true position (o-marker) and the estimated position (*-marker) with other localization schemes: (a) cMDS, (b) least square, (c) probabilistic localization without re-estimation, and (d) the proposed algorithm.
In Figure 6(a), the cMDS scheme shows the best performance from among the four algorithms. This is because it is a centralized localization method that uses all available measurements in entire networks. Therefore, it provides better results than the distributed localization method, which has limited information regarding neighboring nodes. Instead, additional computational power is required. In Figure 6(b), we observe that the least square method performed poorly in the presence of heavy noise. In contrast, probabilistic localization schemes are robust in noisy environments. In Figure 6(c) and (d), the graph indicates tolerance in noisy measurement environments. In Figure 6(d), the process of re-estimating the position of reference nodes, which is not applied in Figure 6(c), is applied. The proposed algorithm reduces the estimated position errors to
Effect of the number of hops from anchor nodes
Figure 7 shows that the average position error increases with the distance of ordinary nodes to anchor nodes. The overall average position error is high owing to a low anchor node ratio. The communicable range ratio
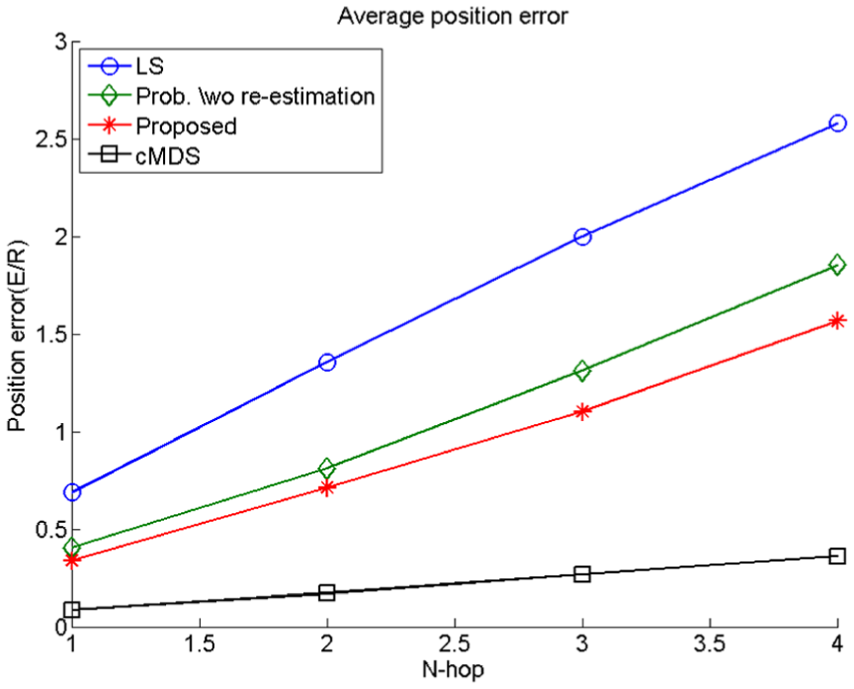
N-hop distance vs average position error.
Effect of the ratio of anchor nodes
In this scenario,
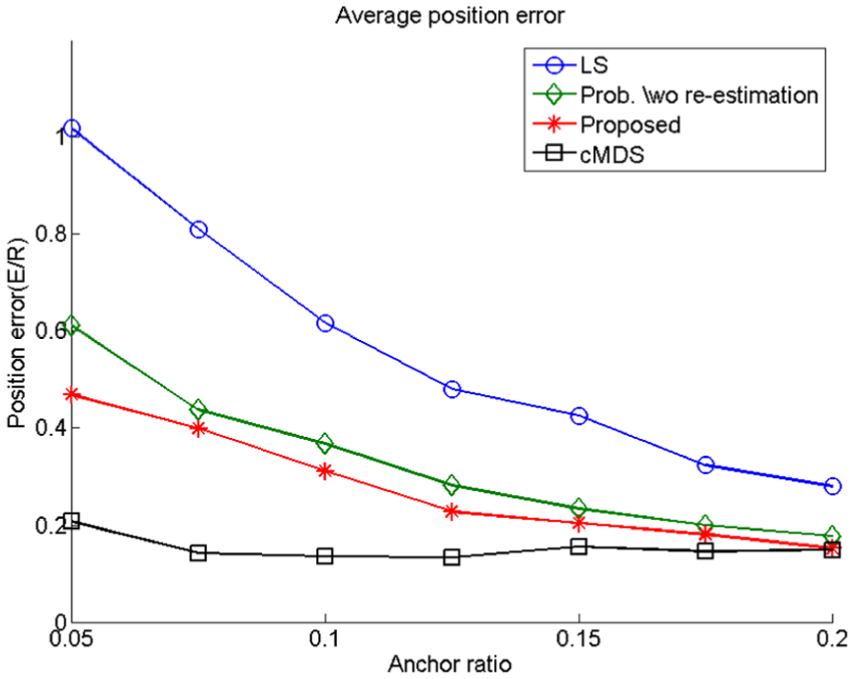
Effect of anchor node ratio on average position error.
Effect of the range measurement error
Figure 9 compares various schemes in terms of the distance error ratio. The cMDS, which is centralized localization, is not significantly affected by ranging errors. However, the position errors of the other algorithms increase proportionally, as shown in Figure 9. There is a 9.80% difference between the position errors of probabilistic localization scheme without re-estimation and that of the proposed algorithm. Below a certain distance-noise ratio
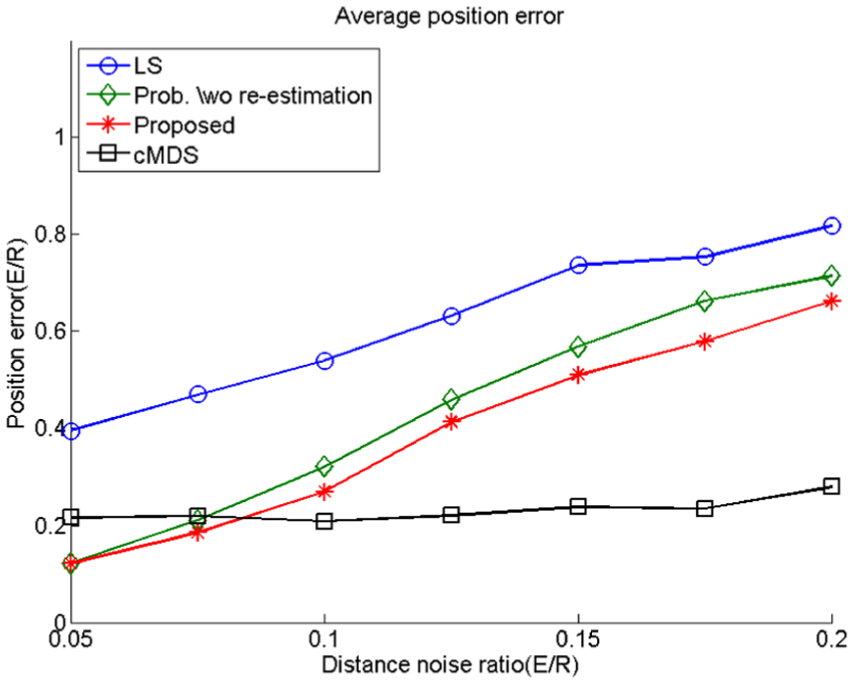
Effect of relative distance error on average position error.
Effect of the geometry of anchor nodes
In some cases, the proposed algorithm outperforms cMDS. The cMDS has a scaling process in its localization process. During that process, the transform matrix distorts coordinates of nodes in order to transform a relative coordinate to an absolute coordinate. This is mainly due to the geometry of the initial anchor node’s positions. In the case of biased or co-linear deployment, cMDS performs relatively poorly. In contrast, the proposed algorithm exhibits robustness to the initial anchor node deployment. These results are shown in Figure 10.

Effect of reference node geometry on the estimated node position: deployment of an estimated node position (a) cMDS and (b) proposed scheme. (c) Comparison between the true position (o-marker) and the estimated position (*-marker) with cMDS and (d) the proposed algorithm.
Conclusion
In this article, we proposed a localization algorithm that considers the location uncertainty of reference nodes based on multi-lateration for distributed wireless ad hoc networks. We adopted the DOP as an uncertainty value. The uncertainty value is used for node selection, estimating ordinary node’s positions and in the re-estimation of reference nodes locations. An important part of our algorithm is the reference node re-estimation based on the probability density function, including the location uncertainty of reference nodes. With the aid of this re-estimation process, the estimated node position approaches its actual position, and the overall performance improvement was verified in various simulated environments. The results demonstrate that the re-estimation process improves the estimation performance by more than 10% in terms of accuracy. Because the proposed algorithm relies exclusively on information obtained from neighboring nodes, its communication overhead is negligible. Moreover, the proposed scheme can be applied to various systems that are based on multi-lateration.
Footnotes
Handling Editor: Jianga Shang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been supported by the National GNSS Research Center program of Defense Acquisition Program Administration and Agency for Defense Development.