
Abstract
Underwater sensor networks have recently emerged as a promising networking technique for various underwater applications. However, the acoustic routing of underwater sensor networks in the aquatic environment presents challenges in terms of dynamic structure, high rates of energy consumption, long propagation delay, and narrow bandwidth. Therefore, it is difficult to adapt traditional routing protocols, which are known to be reliable in terrestrial wireless networks. In this study, we focus on the development of novel routing algorithms to tackle acoustic transmission problems in underwater sensor networks. The proposed scheme is based on reinforcement learning and game theory and is designed as a routing game model to provide an effective packet-forwarding mechanism. In particular, our Q-learning game paradigm captures the dynamics of the underwater sensor networks system in a decentralized, distributed manner. The results of a performance simulation analysis show that the proposed scheme can outperform existing schemes while displaying balanced system performance in terms of energy efficiency and underwater sensor networks throughput.
Keywords
Introduction
Over 70% of the earth is covered with water in the form of rivers, canals, seas, and oceans. Therefore, underwater acoustic transmission has recently attracted much attention because of its significant abilities in distributed tactical surveillance, disaster prevention, mine reconnaissance, and environmental monitoring. Recent advances in communication technologies have led to the development of underwater sensor networks (USNs). Based on technologies that enable underwater exploration, USNs consist of sink nodes and autonomous micromechanical sensors. In USNs, spatially distributed sensors record water-related information; the sensors are connected wirelessly through acoustic signals in the underwater environment. Sink nodes on the surface collect data from the underwater sensors and transmit this information to a monitoring center via satellite for further analysis.1–3
Routing is a fundamental issue in any network. In wireless sensor networks, routing protocols play an important role in the efficient transmission of data from the source to destination nodes. In general, network performance is strongly related to the routing algorithm; therefore, considerable efforts have been made to find adaptive network routing protocols. Ground-based terrestrial sensor networks have been comprehensively investigated, and numerous communication protocols have been proposed for such networks.4–6 Although there are broad similarities between USNs and terrestrial sensor networks, certain characteristics of USNs mean that traditional routing concepts cannot be applied directly to the design of USN routing algorithms. To develop an effective USN routing algorithm, the high absorption factor, long propagation delay, limited bandwidth, and high bit-error ratio of the aquatic environment must be taken into account. 2
Existing routing algorithms can be classified according to their design objectives and routing scenarios. For instance, an algorithm may operate in either a static offline or dynamic online manner. In addition, operational methods can be classed as centralized or distributed paradigms. In general, it is not practical to use a centralized controller in large-scale sensor networks. Moreover, static algorithms cannot significantly improve USN performance under dynamically changing acoustic environments. Control decisions must be made in real time without any knowledge of future information. Based on these considerations, distributed and dynamic routing methodologies are best suited to large-scale USN operations.6,7
The aim of this article is to propose a new routing scheme for USNs by addressing various issues concerning the harsh underwater environment, most notably the energy efficiency, long propagation delay, dynamic topology changes, and node localization of aquatic operations. To overcome these issues, the proposed algorithm must balance the overall USN performance. In addition, for real-world USN applications, we focus on design principles such as feasibility, self-adaptability, and effectiveness in providing a desirable routing solution. Although several USN routing schemes have been proposed, no systematic routing study based on an integrated approach has been conducted. Existing research indicates that this is an extremely challenging issue.
In this study, we adopt game-theoretic learning algorithm to handle point-to-point routing decisions. Usually, game theory considers independent decision-making players who are attempting to reach a joint decision that is acceptable to all players under a given conflict/cooperation environment. In the proposed scheme, each sensor node is assumed to be a game player who makes routing decisions in a distributed online manner to adapt to the highly dynamic USN changes.
The main concept behind the proposed game is the extension of the well-known Markov decision problem to the multiplayer routing game model. To select the best strategy, each player in our game learns the routing environment according to a reinforcement learning algorithm. In particular, we demonstrate that insights from game theory can be used to derive a distributed Q-learning algorithm. In general, learning can be defined as the ability to make intelligent decisions by taking into account the past and present system states. 7
This article makes the following contributions: (1) we develop a novel routing scheme for USNs; (2) we integrate game theory and the Q-learning algorithm to handle routing decisions; (3) we adopt a distributed online approach to implement self-adaptability and real-time effectiveness; (4) we design a routing algorithm that balances contradictory requirements; and (5) the probabilities for routing decisions are initially determined based on the current USN condition. The significance of our proposed scheme lies in its responsiveness to current USN system conditions while considering the dynamic underwater environment. To the best of our knowledge, there has been very little research on game-based distributed learning algorithms for USN routing problems.
The remainder of this article is organized as follows: In the next section, we review some related routing schemes and their problems. Then, we define the routing game model and Q-learning mechanism implemented in this study before providing a detailed description of the proposed USN routing algorithms. In particular, this section provides fresh insights into the benefits and design of a learning game-based routing approach. For convenience, the main steps of the proposed scheme are then listed before we validate the performance of the proposed scheme by means of a comparison with some existing methods. Finally, we present our conclusion and discuss ideas for future work.
Related work
There has been considerable research into the design of USN routing protocols. The energy-efficient depth-based routing (EEDBR) scheme 3 performs energy balancing and reduces the number of sensor node transmissions in order to enhance the network. In this scheme, packets are transmitted between a sensor node and a sink by selected nodes. The selection of the nodes is based on depth and residual energy. The EEDBR scheme consists of two phases: knowledge acquisition and forwarding. During the knowledge acquisition phase, the sensor node shares depth and residual energy information with each of its neighbors. During the forwarding phase, the sender includes a list of forwarding nodes based on depth and residual energy. Unfortunately, some unnecessary forwarding means that the stability period of this scheme is short-lived and there is a high load on low-depth nodes.2,3
Depth-based routing (DBR) is a novel protocol for transmitting packets toward the sink. 8 Based on the depth information of each sensor, the DBR scheme forwards data packets greedily toward the water surface. Each data packet contains a field that records the depth information of its most recent forwarder, which is updated at every hop. On receiving a packet, the node checks whether its depth is less than that of the previous forwarder; if so, it forwards the packet; otherwise, it discards the packet. If there are multiple data sinks deployed at the water surface, DBR can naturally take advantage of them. The main advantages of the DBR scheme are as follows: (1) it does not require full-dimensional location information, (2) it can handle dynamic networks with high energy efficiency, and (3) it can take advantage of the multiple-sink network architecture without incurring additional overheads. 8
The cooperative depth-based routing (CoDBR) scheme 9 is a unique routing protocol for mission-critical applications. In this scheme, all nodes exchange depth information when the network is initialized. The source node registers its neighbors in a list. Relay nodes are selected based on the minimum-depth neighbors in the list, and data are transmitted through the established path to the sink. Cooperation is employed at the network layer, thus increasing the reliability and throughput of the network. In CoDBR, this high reliability and improved throughput is achieved at the cost of high end-to-end delay.2,9
The data gathering–based node coordination (DGNC) scheme 10 focuses on sparsely distributed USNs and a path-controllable autonomous underwater vehicle (AUV), with no time synchronization between the two. The DGNC scheme prolongs the lifetime of a sensor network using the AUV’s mobility to achieve the shortest wake-up time in the sensor nodes. In this scheme, the concept of received signal strength power control is used to modify the transmission power, which increases the communication reliability and decreases energy consumption. The DGNC scheme operates in two phases: connection and data transmission. Furthermore, the signal strength and signal-to-noise ratio (SNR) information provided by the acoustic modem can be used to apply adaptive power control during the transmission of data packets, thus conserving energy by obtaining a preferred communication position between the AUV and the sensor nodes.2,10
In the cooperative best relay assessment (COBRA) scheme, 11 a new best relay selection criterion is employed to minimize the one-way packet transmission (OPT) time, which is defined as the packet transmission time plus propagation delays. The COBRA criterion can take both the propagation delay and the channel state of every potential relay into account, enabling the overall OPT time to be minimized when the total power and outage probability limitations are satisfied. A best relay selection algorithm has been proposed based on the COBRA criterion. This algorithm requires only statistical information about the channel, rather than the instantaneous channel state. The COBRA scheme achieves improved results in terms of network throughput and delivery ratio but incurs high energy consumption.2,11
The void-aware pressure routing (VAPR) scheme 12 for USNs is an efficient anycast routing protocol for underwater data collection. In particular, the VAPR scheme uses surface reachability information to establish each node’s next-hop direction while taking advantage of geo-opportunistic forwarding. This approach is very robust to network dynamics such as node mobility and failure. The VAPR scheme does not require any additional recovery path maintenance and is not affected by the hop stretch caused by recovery fallbacks in existing solutions. Instead, the VAPR scheme exploits periodic beaconing to build directional trails toward the surface and features greedy, opportunistic directional forwarding for packet delivery. 12
The geographic and opportunistic routing with depth adjustment–based topology control for communication recovery over void regions (GDAR) scheme 13 is an anycast, geographic, and opportunistic routing protocol that routes data packets from sensor nodes to multiple sinks at the sea surface. The GDAR scheme uses location information of neighbor nodes and certain known sinks to select a next-hop forwarder set of neighbors to continue forwarding the packet toward the destination. To avoid unnecessary transmissions, low-priority nodes suppress their transmissions whenever they detect that the same packet has been sent by a high-priority node. When a node is in a communication void, the GDAR scheme switches to the recovery mode. This mode employs topological control by adjusting the depth of the void nodes, unlike traditional approaches that use control messages to discover and maintain routing paths along void regions. Therefore, the most significant aspect of the GDAR is its novel void node recovery methodology. 13
The energy-efficient and lifetime-aware routing (ELAR) scheme 14 is an innovative distributed routing protocol for USNs. In this scheme, the nodes learn the environment in order to take optimal actions and gradually improve the performance of the entire network. The ELAR scheme can easily be tuned to trade latency or energy efficiency for an extended lifetime and can thus be used in various applications. The major contributions of the ELAR scheme are (1) applying the Q-learning technique in a distributed routing protocol for USNs, (2) balancing the workload among sensor nodes for a longer network lifetime, (3) reducing the networking overhead for higher energy efficiency, and (4) learning the environment effectively to improve adaptability in dynamic networks. 14
The work by Sandeep and Kumar 15 provides a broad view of existing algorithms of clustering, coverage, and connectivity based on acoustic communication. This article also provides a useful guidance to the researchers in USNs from various other communication techniques’ perspective. Albarakati et al. 16 develop a set of underwater embedded system architectures that can handle different network configurations. The idea is to have dynamic architecture that will be configured based on network parameters to achieve best performance in terms of end-to-end delay and power consumption. Finally, an architecture is selected to match a given set of requirements including data rate, processing node capabilities, gathering nodes capabilities, and water depth. In Azam et al., 17 a new balanced load distribution scheme is proposed to avoid energy holes created due to unbalanced energy consumption in USNs. This scheme is specifically designed to solve the energy hole problem when a node does not find a forwarder node in the next corona to reach the sink.
Some earlier studies12–14 have attracted considerable attention while introducing unique challenges in handling the USN routing problems. In this article, we demonstrate that our proposed scheme significantly outperforms these existing schemes. Table 1 lists the advantages and disadvantages of the existing approaches.

EEDBR: energy-efficient depth-based routing; DBR: depth-based routing; CoDBR: cooperative depth-based routing; DGNC: data gathering–based node coordination; COBRA: cooperative best relay assessment; VAPR: void-aware pressure routing; GDAR: geographic and opportunistic routing with depth adjustment–based topology control for communication recovery over void regions; ELAR: energy-efficient and lifetime-aware routing.
Routing game model and Q-learning mechanism
In this section, we provide a brief introduction to the game theory model and general reinforcement learning mechanism, which form the theoretical basis of the proposed USN routing scheme. By adopting the Q-learning-based routing game, our scheme designs an anycast, opportunistic routing protocol to deliver packets from a sensor node to the sink node.
Routing game model
During the operation of a USN system, the sensor nodes make individual routing decisions by considering the end-to-end delay, hop count, packet error rate, and energy efficiency. Under dynamic acoustic conditions, the sensor nodes attempt to maximize their own profit in a distributed online manner based on the learning approach. In this study, we assume that the sensor nodes are game players that make rational routing decisions. Based on this assumption, we develop a new game model, known as the routing game, for the USN system. Formally, we define the routing game model
The array
Reinforcement learning mechanism
Reinforcement learning concerns how system agents should take actions to maximize their reward. Reinforcement learning algorithms establish a balance between the exploration of uncharted territory and the exploitation of current knowledge based on online performance. In game theory, reinforcement learning is used to explain how an effective solution may arise under bounded rationality. Therefore, there has been growing interest in research incorporating game theory and learning algorithms. Game theoretic learning algorithm has become an increasingly important area of research in recent years.7,14,18
The environment is typically formulated as a Markov decision process (MDP), which is, therefore, the basic concept of reinforcement learning. The MDP is a mathematical framework for modeling the decision-making process and is useful for optimization problems that are solved via learning algorithms.14,18 In the current scenario, the MDP consists of the set of states (
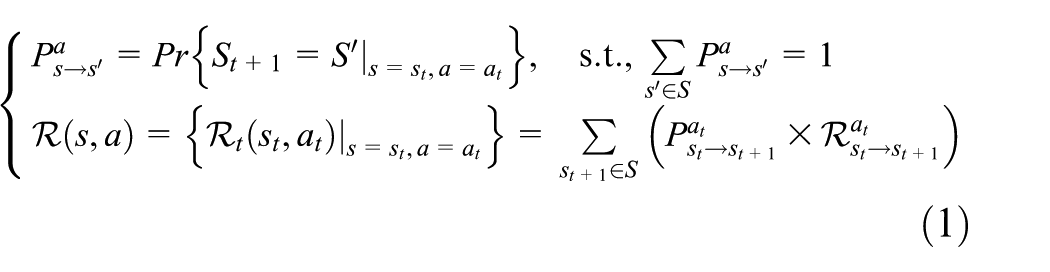
where
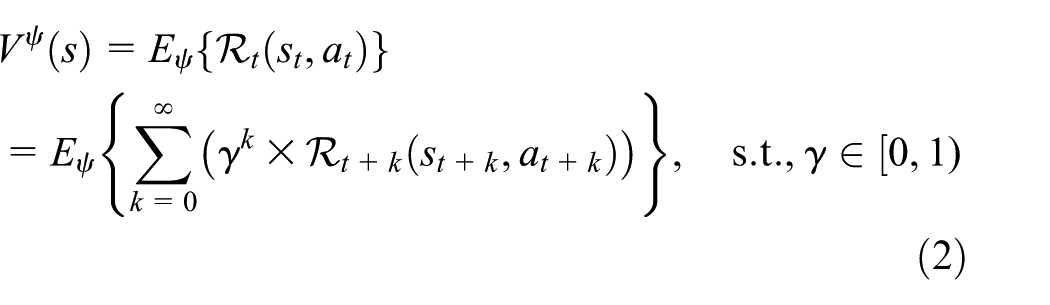
where

To solve equation (3), reinforcement learning algorithms can be used. In this study, we adopt a well-known reinforcement learning technique called Q-learning. Q-learning works by successively improving its evaluations of the quality of particular actions at particular states. In addition, Q-learning provides agents with the ability to learn to act optimally in Markovian domains by experiencing the consequences of their actions but does not require the agents to build maps of the domains.14,18 In the Q-learning algorithm, the value of state–action pairs is given by

According to equations (3) and (4), we can compute
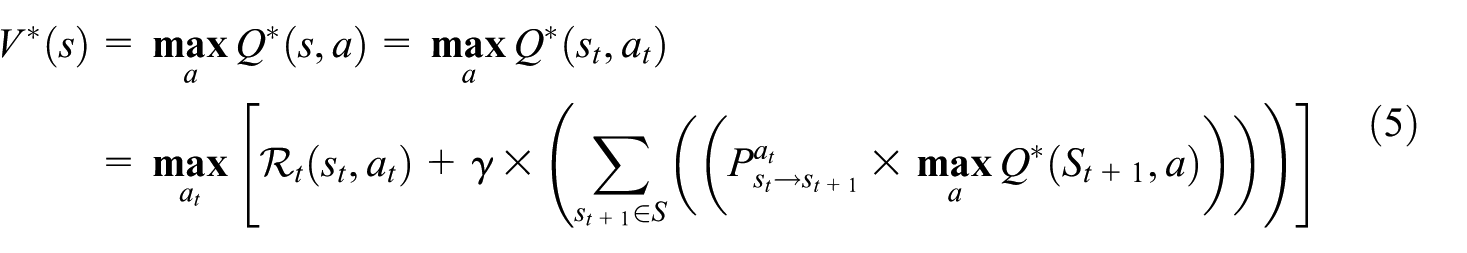
In equation (5),
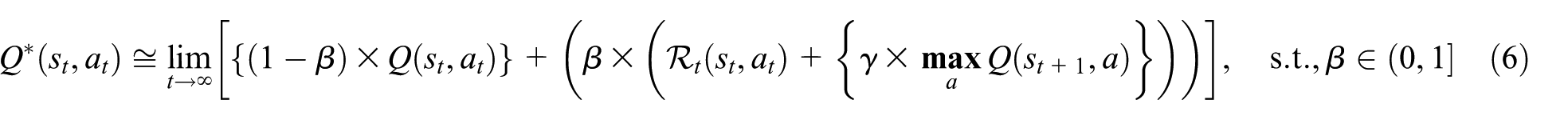
where
Proposed USN routing scheme
In this section, the proposed USN routing scheme is explained in detail. The scheme consists of configuration and routing algorithms. The configuration algorithm effectively forms the network topology based on the current network condition by considering the distance and energy status. The routing algorithm establishes the one-hop behavior for transferring routing packets.
Configuration algorithm for underwater network topology
The key concept of the configuration algorithm is to configure the sensor network topology. Each sensor node maintains routing information in a control_record for self-organizing and independent control. The control_record consists of two system parameters: path cost (
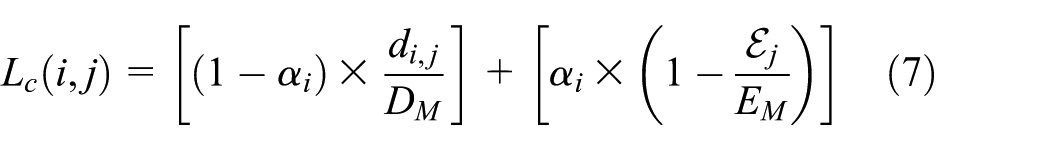
where
For the adaptive
During network topology formation, each individual node estimates the

where

When the proposed configuration algorithm has terminated, the virtual topology of the USN can be considered as a spanning tree structure that is rooted at the sink node while minimizing the
Routing algorithm based on the Markov routing game
In designing the USN routing algorithm, we consider the multiplayer MDP. Each sensor node is assumed to be a player, and the objective of player
By employing Q-learning, the main goal of the USN routing algorithm is to deliver the packet to the sink node with the maximum payoff. If the

where

where

Main steps of the proposed USN routing algorithm
USNs have gained popularity for their application to environmental monitoring, military surveillance, and disaster prevention. Although some USN routing work has been conducted, existing schemes are strongly specialized for specific control issues. Therefore, it is challenging to obtain balanced system performance. In this article, we discuss a new perspective on USN routing problems. Using the Q-learning-based routing game model, we design a novel USN routing scheme through a step-by-step interactive feedback process. This allows each sensor node to learn the current situation and determine the best routing path. After a sequence of routing actions has been performed, the current USN condition dynamically changes. During the routing operation, each node periodically updates the routing information, reevaluates the current strategy and selects one of its neighbor nodes for packet forwarding. In terms of practical operations, we can transfer the computational burden from a central system to distributed nodes. Therefore, our distributed learning-based routing scheme is implemented as a dynamic repeated game for opportunistic routing. While traditional optimal solutions generally exhibit exponential time complexity, our proposed scheme operates in polynomial time. The main steps of the proposed USN routing algorithm are described as follows (see Figures 1 and 2):
Step 1: Control parameters n,
Step 2: At the initial time, the sink node broadcasts the setup message. Within the power coverage area, message-receiving sensors individually estimate
Step 3: If a node has received multiple setup messages from reachable neighbor nodes, this node adaptively selects one of them to reach the sink node and initializes
Step 4: At every routing decision step, the individual sensor nodes statistically select the next relay node according to the probability distribution
Step 5: Based on the selected routing strategy, the values in
Step 6: At each time period,
Step 7: Using the Q-learning mechanism, each node’s routing strategy at time
Step 8: Based on the interactive feedback mechanism, the dynamics of our routing game cause a cascade of interactions among the game players, who make their opportunistic routing decisions in a distributed fashion.
Step 9: Under the relevant USN environment, individual nodes are constantly self-monitoring for the next routing game process; go to step 4.
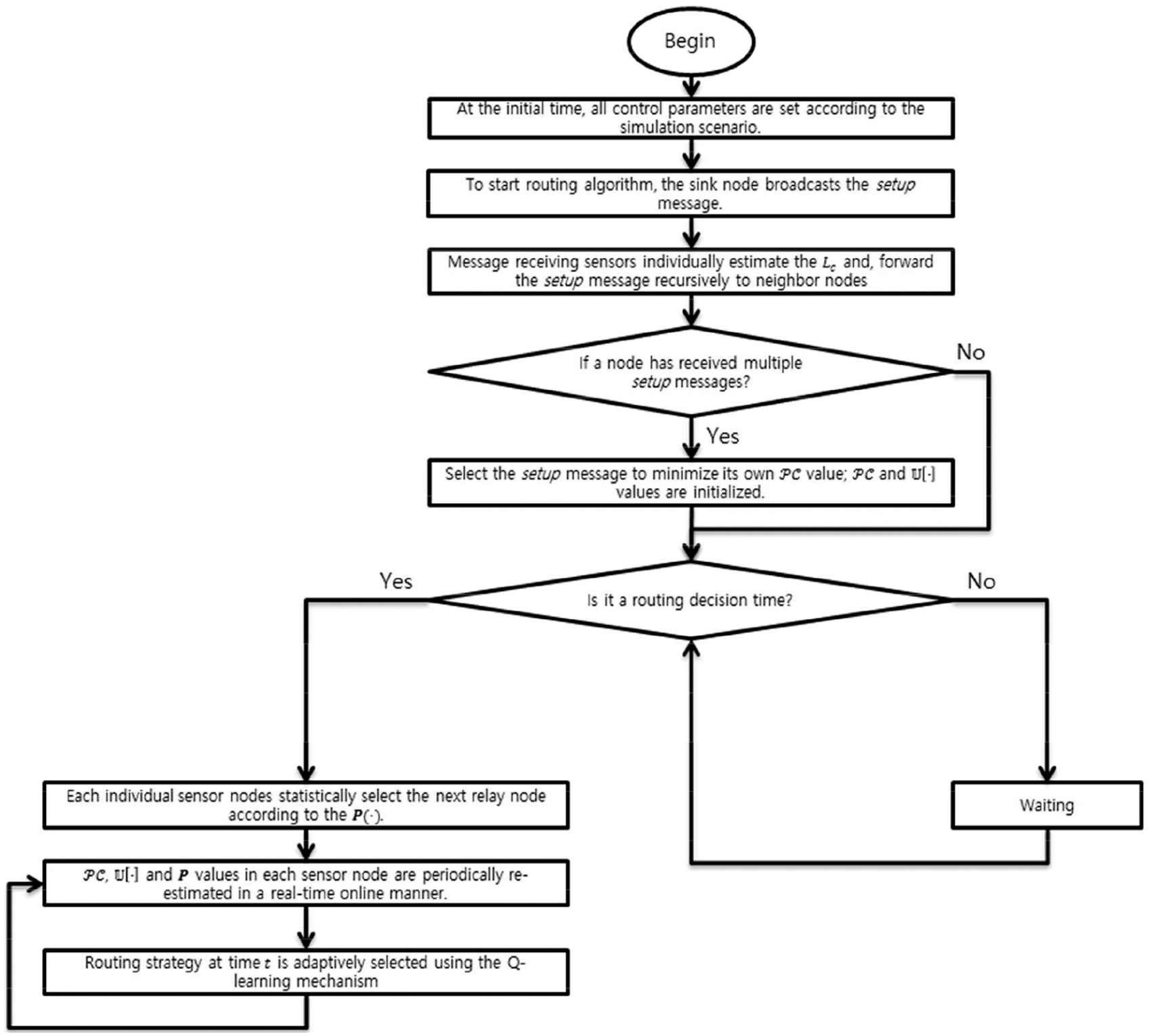
Flowchart of the proposed USN routing algorithm.

Pseudo code of the proposed USN routing algorithm.
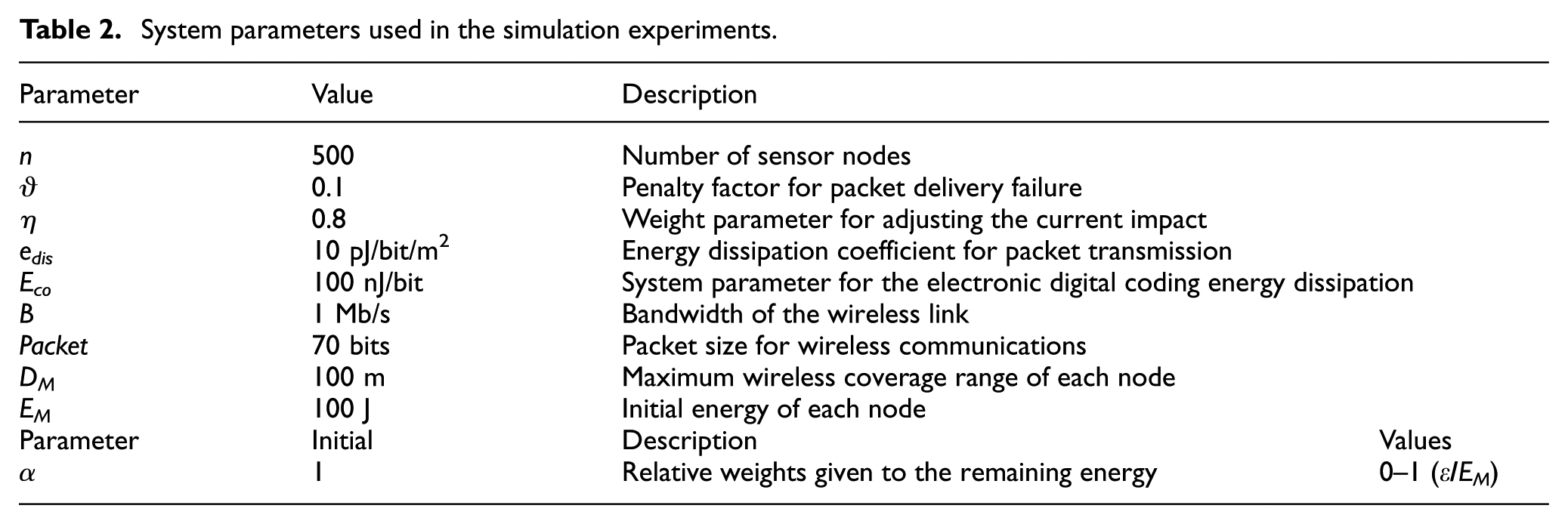
System parameters used in the simulation experiments.
Performance evaluation
In this section, we evaluate the performance of our proposed protocol and compare it with that of VAPR, 12 GDAR, 13 and ELAR. 14 Based on the simulation results, we confirm the superiority of the proposed approach. In this study, we have used the simulation tool MATLAB to develop our simulation model. MATLAB is one of the most widely used tools in a number of scientific simulation fields; high-level syntax and dynamic types of MATLAB are ideal for model prototyping. Our simulation results are achieved using MATLAB, which is widely used in academic and research institutions as well as industrial enterprises. To ensure a fair comparison, the following assumptions and system scenario were used:
A 500-node USN was used in which the nodes were distributed randomly in a three-dimensional (3D) region of size 1000 m ×1000 m × 1000 m.
No assumptions were made about the node dispersion or density in the acoustic field.
The maximum wireless coverage range of each node was set to 100 m.
The meandering current mobility model 19 was adopted to model the motility of each sensor node.
Rayleigh fading was used to model small-scale fading.
We used the carrier-sense multiple access (CSMA) media access control (MAC) protocol. In CSMA, when the channel is busy, a node waits for a predefined back-off period before attempting to sense the carrier again.
For reliability, we implemented automatic repeat-requests (ARQ) at the routing layer. After packet reception, the receiver sends back a short acknowledgment (ACK) packet. If the sender fails to hear the ACK packet, the data packet is retransmitted; the packet will be dropped after three retransmissions.
We used five sink nodes, each positioned at random on the surface.
Data packets were generated at the source node at a rate of λ (packets/s), and the range of the offered load was varied from 0 to 3.0.
At the start of the simulation, all nodes had an initial energy (
For simplicity, we assumed that the nodes were not affected by noise or physical obstacles.
The energy dissipation in the transmitter node (

where d is the distance between the transmitter and receiver nodes and
The energy dissipation for the receiver node (

Network performance measures obtained on the basis of 100 simulation runs are plotted as functions of the packet generation per second (packets/s).
Usually, Rayleigh fading is a statistical model for the effect of a propagation environment on a radio signal, such as that used by wireless devices. It is most applicable when there is no dominant propagation along a line of sight between the transmitter and receiver. If there is a dominant line of sight, Rician fading may be more applicable. Rayleigh fading is a special case of two-wave with diffuse power (TWDP) fading. One of the limitations for the Rayleigh fading is its simplicity of assumption about dynamic wireless environments. In our simulation, we adopt the Rayleigh fading model for simplicity.
To demonstrate the validity of our proposed method, we measured the normalized energy consumption, network throughput, end-to-end delay, and packet loss ratio. Table 2 shows the system parameters used in the simulation. To emulate the USN system and ensure a fair comparison, we used the system parameters given in Table 2.
Figure 3 compares the packet loss ratio of each scheme. Packet loss is measured as the percentage of packets lost relative to the total number sent and is a key factor in USNs in terms of network operation. As the packet generation rate increases, the resultant network congestion results in increased packet loss. All schemes exhibit a similar trend; however, the proposed scheme outperforms the existing methods, particularly in heavy traffic load situations. In our scheme, packets are forwarded under an interactive environmental feedback mechanism, which guarantees a lower packet loss ratio than in other schemes.

Packet loss ratio.
Figure 4 presents the normalized energy consumption per node for each scheme. Energy consumption increases with the packet generation rate, which is intuitively correct. In USNs, the main factor contributing to energy consumption is the communication distance. Therefore, it is important to determine the multiple-hop shortest path. Based on the online learning scheme, each node in our method is able to select the most energy-efficient routing path. Therefore, the proposed scheme attains superior energy efficiency to other schemes, from low to high traffic load intensities.
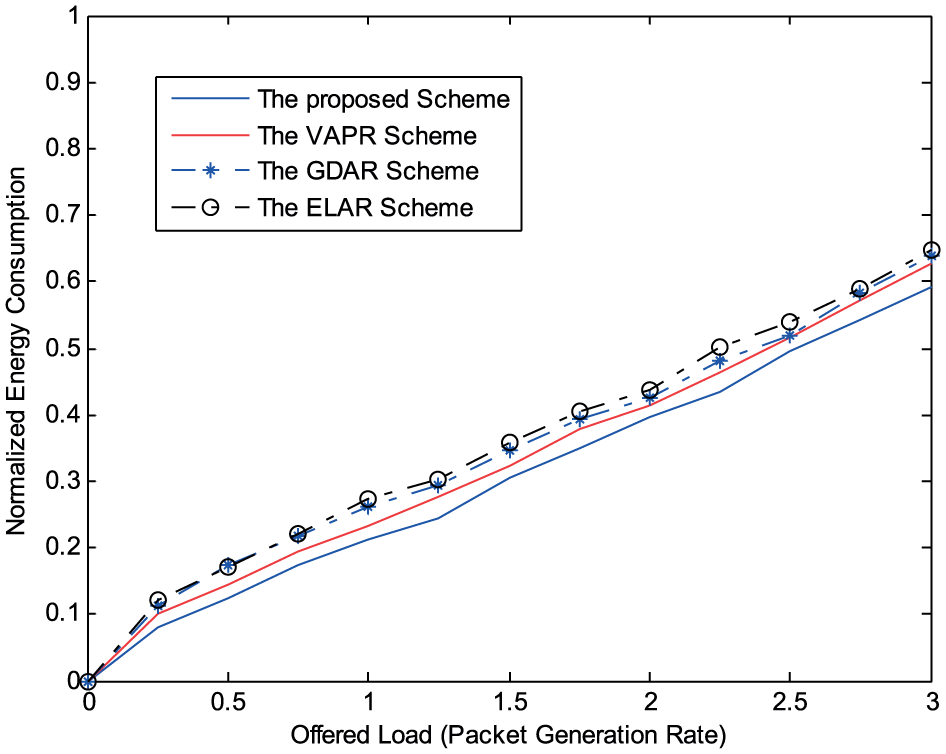
Normalized energy consumption.
Figure 5 compares the network throughput. In this study, network throughput is defined as the ratio of data packets received at the sink node to the total number of data packets generated. The gain in network throughput achieved by the proposed scheme is a result of the effective feedback paradigm of employing an iterative learning model and the algorithm design for obtaining synergistic and complementary features. Therefore, the proposed scheme achieves superior network throughput performance to the existing schemes, which were designed as one-sided protocols and do not respond to current USN conditions.

Network throughput.
The curves in Figure 6 indicate the normalized end-to-end packet delay. In general, as the packet generation rate increases, the packet delay increases linearly with the traffic load. At every period, each node in our scheme makes routing decisions in a distributed learning manner, reflecting changes in the network environment. Therefore, our approach reduces the packet delay more effectively than the other schemes.
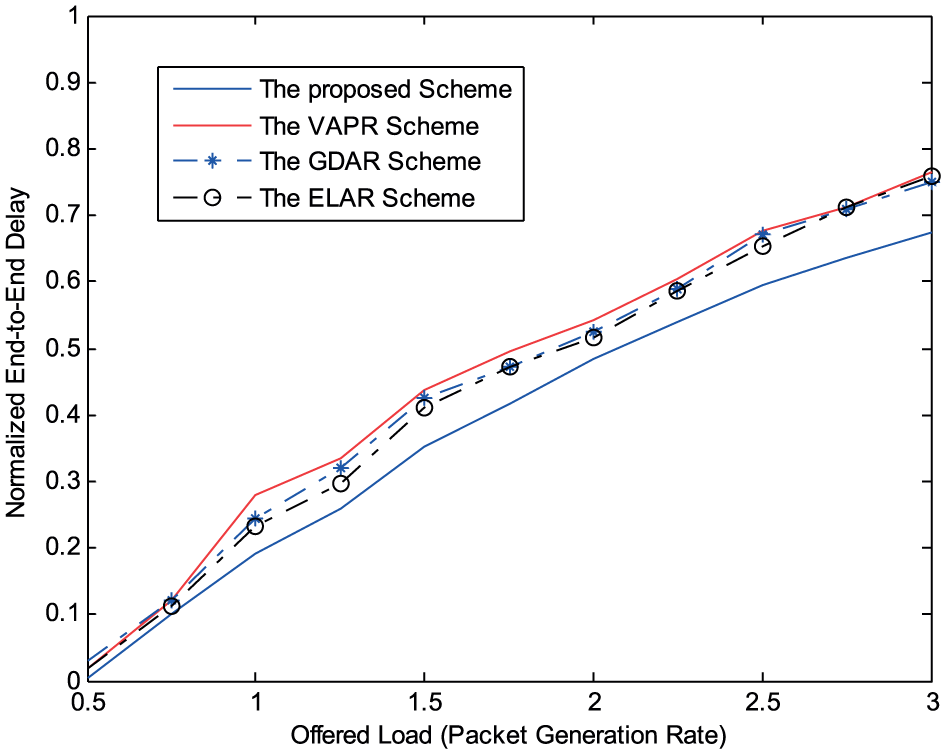
Normalized end-to-end delay.
The simulation results shown in Figures 3–6 demonstrate that the proposed scheme, which uses a Q-learning-based routing game model, can monitor the current USN conditions and adapt to highly dynamic environments. In particular, the sensors in our approach acquire information from the environment, gain knowledge, and make intelligent decisions in a self-adapting manner. The simulation results indicate that the proposed scheme generally exhibits superior performance to the existing schemes. Our approach also attains an appropriate balance of performance, something that the VAPR, 12 GDAR, 13 and ELAR 14 schemes cannot offer.
Summary and conclusion
USNs have recently attracted considerable attention because of their significant capabilities for acoustic monitoring and resource discovery. USNs encompass a wide range of applications, from long-term measurements to imminent threats. In this article, we have presented a learning game approach to USN routing problems. Our major goal is to develop an efficient USN routing algorithm that is suitable for harsh underwater communication conditions. Considering the unique features of USNs, we have integrated an interactive feedback mechanism and designed a routing game model based on the well-known Q-learning concept. In the proposed model, individual sensor nodes learn better routing strategies and make routing decisions dynamically for adaptive, opportunistic routing. Using online self-monitoring and distributed learning techniques, the proposed scheme dynamically adapts to the current USN situation and effectively maximizes the expected benefits. To demonstrate the validity of our scheme, we compared our model with existing schemes and demonstrated that our approach outperforms the existing schemes in a simulation environment.
Although we have achieved our goals of energy efficiency and increased throughput in USN management, we believe that there is further scope for improving the efficiency of the USN system. Issues for further research include the design and validation of new USN control schemes in the fields of big data mining, cognitive radio, and network security. In addition, our work could be extended to error tolerance by investigating the effects of MAC layer activities such as packet loss and retransmission.
Footnotes
Handling Editor: Hassan Mathkour
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Ministry of Science and ICT (MSIT), Korea, under the Information Technology Research Center (ITRC) support program (IITP-2017-2014-0-00636) supervised by the Institute for Information & Communications Technology Promotion (IITP) and was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2015R1D1A1A01060835).