
Abstract
The proven approach successfully recognizes the activity of daily living is a classifier training on feature vectors created from streamed sensor data. However, there is still room to improve feature extraction techniques in that the activity of daily living data are often nominal or ordinal. The ordinal data can be likely less discriminative due to the great uncertainty in level of measurement. This article provides a framework with novel activity of daily living primitive that introduces an enhanced feature selector with linear time complexity. The extension to traditional approaches is that the present framework considers the following: (1) defining activity of daily living primitives and constructing a primitive vocabulary, (2) reducing data when representing raw activity data, and (3) selecting an appropriate primitive set for each testing activity. The empirical results reveal that a pre-trained portable primitive vocabulary not only outperforms the existing baseline frameworks but also greatly facilitates the deployment and management of activity recognizers.
Keywords
Introduction
Activity recognition systems deployed in smart homes are characterized by the abilities of detecting human actions and their goals and thus providing them with the decent assistance. Such assistive technologies have been adopted nowadays by smart homes and healthcare applications in practice1,2 and have delivered promising results for offering either more caring services to an elderly resident3–5 or responsive assistance in an emergency situation. 6
Technology advances will continue to be more deeply integrated into our daily lives. There are various sensors to collect raw activity data stream in the field of daily activity recognition, and a huge amount of sensor data are certainly generated. Good examples are cameras, 7 wearable sensors, 8 and radio-frequency identification (RFID) sensors, 9 which often yield continuous data. Also, there are non-obtrusive and pervasive sensors that transparently distribute throughout the space to generate discrete sensor data of on-off type. The famous database Center for Advanced Studies in Adaptive Systems (CASAS), 10 collected by Washington State University (WSU) for a long time, contains abundant experimental data which has seen great application value in many research works.11,12
There are a lot of researchers who study deeply on proposing more powerful classifiers to improve the accuracy of activity recognition. These classifiers mostly derive from several mainstream ones, to name a few, native Bayesian (NB), 13 hidden Markov model (HMM), 14 support vector machine (SVM), 15 and conditional random fields (CRF), 16 and they characterize in different aspects, for example, NB has a remarkable advantage of recognition speed due to its simple calculation principle, while CRF has better contextual power than others. As classifier researchers known, the Weka is a collection of machine learning algorithms for data mining tasks, 17 which is possible to be applied to train activity models and recognize activities. By balancing advantages and disadvantages of all kinds of classifiers mentioned above, we choose CRF in Weka to be experiment classifier for activity model training and recognizing tasks.
Although obtaining the supply of CRF, under the same classifier ability condition, how to extract activity features always restricts recognition framework’s ability. Thus, the process of constructing activity features is another key part in recognition architecture design. According to the different types of sensor data, such as the continuous data recorded by accelerators, the discrete data collected by non-intrusive sensors, and video and audio data filmed by cameras, the features can be vectors, 18 events, 19 and spatial and temporal information. 20 By facing various activity data types, there are several corresponding ways in activity recognition field to extract features, which are as follows: (1) feature vector construction: by putting continuous data stream into sequence of time sliding windows, some researchers use statistical data in each window such as maximum, minimum, mean as feature elements which are gathered according to some particular assembly sequences. (2) Sensor event marking: if a sensor is triggered, that sensor event will be marked 1, otherwise, it will be marked 0. The marked results become features to be used for training and recognizing. (3) Position tracking: participant is tracked by cameras when he or she is executing activities, whose spatial information will be computed to set some spatial and temporal constraints as activity features.
However, the feature extraction techniques mentioned above, yet mainstream and promising, are largely more sensitive to scalar values of activities than ordinal ones. This issue may destroy the portability of activity recognition architecture because ordinal measurement can be erroneous in some cases. Unlike the available techniques, M Zhang and AA Sawchuk 21 proposed a concept of motion primitive to construct a bag of feature-based activity recognition framework for continuous sensor data (i.e. signals) instead of discrete ones (events). The difference is important as many statistical and data mining algorithms can handle one type but not the other. Though their motion primitives often lack real physical meaning, this framework can theoretically be an all-purpose tool in that it represents different activities by a “vocabulary” instead of scalar values. In this article, we are motivated to propose the idea of activity of daily living (ADL) primitive for smart homes that are associated with discrete data and to apply them to practice. We create an activity recognition framework based on ADL primitive (AR-ADLP) to recognize discrete home activities, thus to improve recognition accuracy and framework portability.
The remainder of this article is organized as follows. Section “Related work” introduces some related works. Section “Overview of AR-ADLP framework” gives an overview of AR-ADLP framework. Section “ADL primitive mining” details the processes of mining and modeling activities. Section “Activity pattern selection” presents the activity pattern selection method of testing data. In section “Experiments,” we report on experimental setting and results, and offer some discussions. Finally, in section “Conclusion,” we draw our conclusions.
Related work
In the field of non-video activity recognition, the mainstream feature extraction technologies to represent activity are classified into two categories: feature vector construction and sensor event marking. The former is usually applied to process continuous activity data, such as the data collected by accelerometer and gyroscope, 22 whereas the latter is often used in discrete sensor data which is always recorded through non-obtrusive and pervasive sensors. 23 Zhan et al. 24 extracted feature vectors to represent activities from continuous acceleration data over sliding windows. Sun et al. 25 extracted low-level signal features from accelerometer and Global Positioning System (GPS) data first, and then used Dirichlet process Gaussian mixture model (DPGMM) to map feature vectors. Finally, they demonstrated the effectiveness of their recognition method. However, for the discrete data collected in smart home environment, the methods of feature vector construction used in continuous data are usually not appropriate. The sensor event marking technology is more suitable to extract features and represent activities for discrete data. To name a few, Krishnan and Cook 19 characterized different activities using different window lengths of sensor events and added past contextual information into features, which leaded to better performance for daily activity recognition. Wen and Zhong 26 treated the activity patterns as the triggered sensor event sequences without specific sensor state values and proposed similarity measure algorithm to recognize daily activities which was able to achieve handsome recognition performance. Hong and Nugent 27 applied a sensor segmentation algorithm to part a stream of time series sensor events and inferred sensor segments to recognize with good accuracy.
The aforementioned works leveraged some extracted representative information as features to present activities, but the portability of the activity models is weakened because a lot of numerical and state values are involved in building their activity features. Some famous methods have this disadvantage, for example, in Bao and Intille’s 28 research, mean, energy, and frequency-domain entropy and correlation of accelerator values were calculated and used as activity elements. In the similar way, Stikic et al. 29 divided accelerometer data stream into a lot of time sliding windows and calculated the values of mean, variance, energy, and the like to construct 96-dimensional feature vectors to present activity. As another example, Zhang et al. considered mean, variance, correlation, and entropy as the basic features in their study. Features like zero crossing rate, mean crossing rate, and first-order derivative are also considered because these features have been successfully applied in similar recognition problems, while they innovatively included physical features. All these features are extracted from both three-axis accelerometer and gyroscope. 30 Although these representation activity methods achieved good results, unlike our approach, they had a common flaw—too many specific sensor values involved, which was the key of reducing portability. Once the sensor data supplier(s) is(are) changed, the activity models would have to be constructed again. However, less is known about this point in the field of activity recognition; based on this kind of consideration, we propose a novel method using pre-trained ADL primitives in order to improve recognition system’s portability.
In addition, most of previous researches moved activity features into classifier to train activity models directly without any other processes. Lee and Cho 31 calculated the difference between previous acceleration and current acceleration, average acceleration, and standard deviation of acceleration to be features, which were inputted into ME model to infer activities without any other operations. Tapia et al. 32 assumed that temporal information, in addition to which sensors fired, would be as activity features, and these features outputted the evidence entered into the nodes of the naive Bayesian network directly. Without special process after extracting features, there is still a lot of noisy data and unnecessary attributes in training classifiers, which may reduce recognition accuracy likely. As opposed to these works, we add an activity reduction module into recognition framework to delete data, what we think useless for recognition. In this reduction module, raw activity data represented by the corresponding primitive set includes some invalid data which are not involved in its primitive set. When finishing this step, the amount of activity labels trained and recognized can be reduced and the recognition accuracy will be improved deservedly.
Overview of AR-ADLP framework
We incorporate the concept of ADL primitive into traditional activity recognition framework to transfer the classical activity recognition into the problem of string matching, thus a novel recognition framework—AR-ADLP—is created.
Preliminary
To express more effectively, we first describe some terms such as home activity data, ADL primitive, and primitive judging threshold.
Definition 1. Home activity data
A smart home environment is based on the deployment of n binary sensors, and these sensors are organized in a sensor set:
Definition 2. ADL primitive
In the raw activity data, there are many sensor event pairs that are constituted by two successively triggered sensor events:
The aim of primitive judging threshold
AR-ADLP architecture
The essential components of the AR-ADLP framework are shown in Figure 1, where the arrows represent the steps of activity recognition. In point, AR-ADLP and ADLP have similar stages—training stage and recognition stage in the framework; however, the difference is that AR-ADLP extends ADLP with ADL primitive construction and data reduction.

Architecture of AR-ADLP framework.
During the training stage, the labeled training activity data are inputted into ADL primitive construction module to generate the primitive vocabulary by counting the event pairs that frequently co-occur in the labeled data streams. From this naive vocabulary, the data reduction procedure is invoked for an activity to choose its own primitives that are triggered more often by that activity. Through the process of data reduction, some primitive strings will be removed if they have less intersection with the data streams labeled as a concrete activity, so primitive strings can be transferred into relatively clean ones, which are trained to learn activity models in the final step.
In the recognition stage, we render the raw unlabeled data using the same method to build primitive sets. Next is the key part of this stage—pattern selection—which calculates similarities between the primitive set of testing data and all primitive sets of training data. Specifically, the distance of two sets is calculated by equation (1), which is used to calculate similarity as an element of equation (2). After similarity calculations, we select the training activity pattern with the maximum of similarities as the testing activity pattern. Finally, represented and reduced testing data can be recognized by referring trained activity models

where

where
There are two situations after calculating similarities, namely, successful match and unsuccessful match. Testing data can get a training activity pattern directly (i.e. we can get only one maximum of similarities), which we call successful match. If there are two or more maximums of similarities, we need to introduce equation (3) as a correction factor in order to operate unsuccessful match
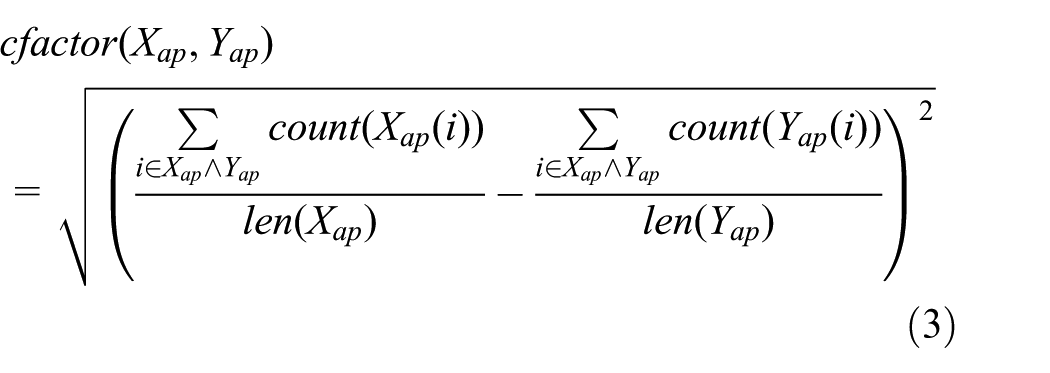
The value cfactor of Xap and Yap is smaller, the more similar they are. Equation (4) is extended to become a new similarity equation when encounter the unsuccessful match situation

In order to keep the form of testing data consistent with training data, after pattern selection module, the raw testing data are reduced using its selected primitive set. Last but not least, the usable testing data are inputted into CRF classifier with the activity models trained in the last stage, and we can get the final recognition results that can be evaluated by evaluation measures.
Based on the description above, the main points of AR-ADLP framework are primitive vocabulary construction and pattern selection in testing stage. In addition, compared to the traditional activity recognition framework, the framework we propose defines sensor event pairs as the basic activity elements, thus transfer the complex activity recognition problem into a string matching one. AR-ADLP is very different from Mi Zhang’s motion primitive. In Mi Zhang’s framework, the activity representation method is based on intuitive statistics simply ignoring temporal relationship between primitives. In contrast, AR-ADLP framework not only includes temporal relationship in ADL primitive design stage but also introduces a reduction module to decrease interference of noisy data and unnecessary attributes.
ADL primitive mining
In this section, we introduce the algorithms used in the process of ADL primitive mining. We exploit the method of how to mine activity features in order to construct ADL primitive, which can transfer the complex activity recognition problem into a string matching one, thus to decrease the difficulties of training and testing.
Algorithm 1 is introduced as the procedure of ADL primitive construction. The algorithm starts from an initial solution building a

We designed triggered successive sensor event pairs as primitives, which are pooled together to be a commonly used primitive vocabulary for all activities. For a concrete activity, a subset of the primitive vocabulary is selected by calling data reduction—Algorithm 2 that removes irrelevant primitives by checking whether a primitive occurs in the labeled data streams that represent that activity (Lines 6–8) and whether their occurrence (i.e. times(<sj, sj + 1>)) is over an expected threshold (Line 9).

Activity pattern selection
In this section, the procedure of activity pattern selection is organized to become Algorithm 3 in recognition stage, which plays a decisive role in whether unlabeled testing data can select activity pattern appropriately. This algorithm calculates similarities between a testing primitive set Xap and all elements of the set of training primitive sets

In Line 1, Algorithm 3 creates an array named simArray to record similarities, and the length of simArray is k that is same with the element number of set A. From Lines 2–4, k similarities between primitive set Xap and each element of A are calculated using equation (2) and recorded as simArray elements. If we cannot select the only one maximum from k similarities, what we call unsatisfied selection condition, these k similarities will be corrected using corrected factor (i.e. equation (3)) to become new k similarities using equation (4) and recorded in newSimArray (Lines 5–9). Otherwise, this situation is a satisfied selection condition. Finally, patternId is set at the serial number of the maximum of simArray or newSimArray (Line 10).
Experiments
Our experiments use activity database of daily living collected by Cook and Edgecombe 33 in WSU Apartment Test bed, and our recognition results will be compared with Cook’s results. In order to evaluate validation of AR-ADLP framework, we set two evaluation criteria, namely, the total activity recognition accuracy: rate and the standard deviation of activity recognition accuracy: srate. The former is to measure the chance of being correct of recognition framework we propose, and the latter is to measure the balance ability among various activities. In the rest of this section, we introduce two experiments in detail. The first experiment mentions of two aims to set proper values to experimental parameters, and the second one runs whole process of AR-ADLP framework to demonstrate its recognition performance.
Sensor data
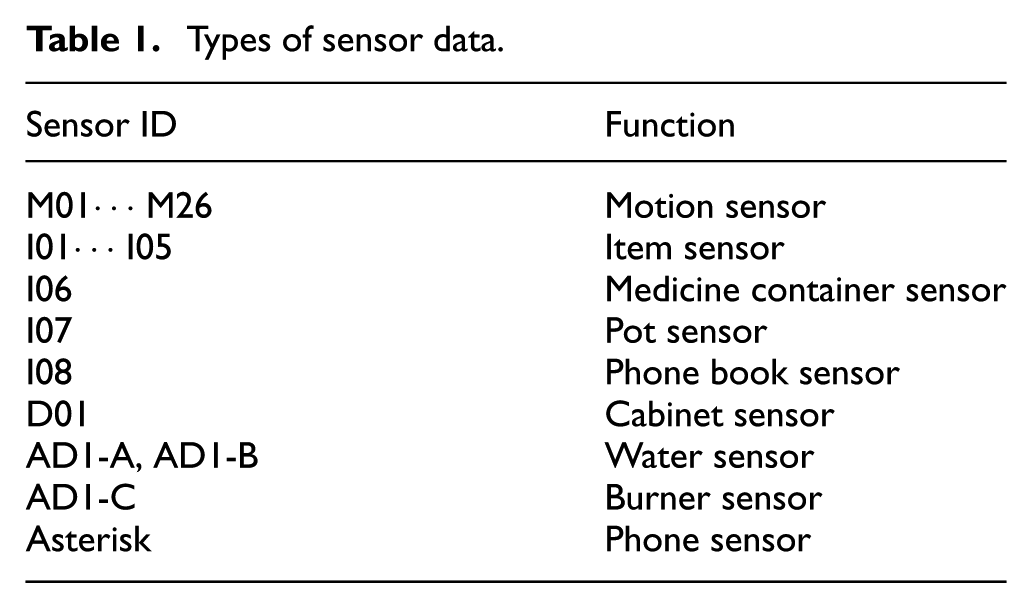
Various types of sensors provide user’s actions of different types, such as some motion sensors give us direct location information of users and some item sensors tell us whether users touch the objects. There are totally 39 sensors used in gathering raw experimental activity data, and their IDs and functions are summarized in Table 1.
Types of sensor data.
Evaluation metrics
In order to validate the effectiveness of AR-ADLP framework, we introduce two evaluation metrics, namely, the total activity recognition accuracy rate and the standard deviation of activity recognition srate as follows:
1. The total activity recognition accuracy rate reflects the comprehensive recognition ability of classifier. When we use this metric to evaluate, we divide activity labels recognized into two categories—correct recognition labels and incorrect recognition labels. The equation of rate is as follows
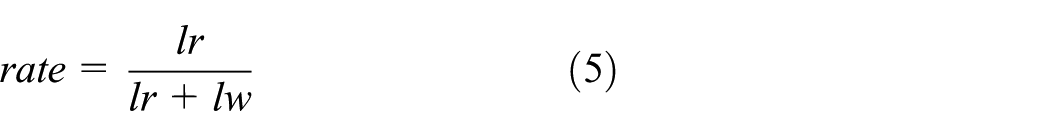
where lr stands for the number of correct recognition labels and lw stands for the number of incorrect recognition labels.
The total recognition accuracy is a value arranged from 0 to 1. The closer that rate is to 1, the more correct activity labels are recognized, that is, the better comprehensive recognition ability the classifier has. In our experiments, rate is the most important evaluation metric.
2. The standard deviation of activity recognition accuracy srate reflects the robustness of our framework in recognizing different activities. In order to determine srate, we need to calculate average recognition accuracy classrate of all activities, and then to calculate their standard deviation. The method of calculating classrate is shown in equation (6) and srate is shown in equation (7)

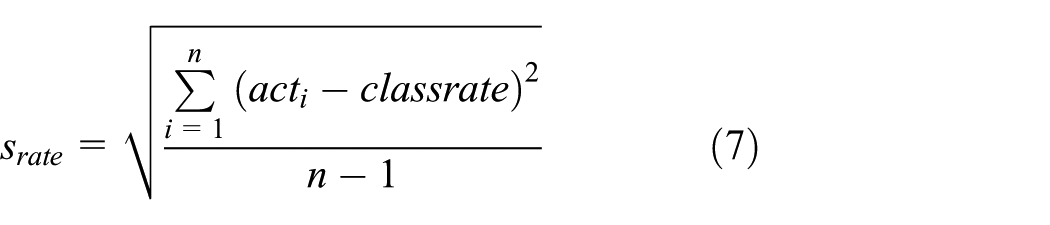
where n stands for the total number of activities and acti stands for the recognition accuracy of the ith activity. The less the value of srate, the more balanced recognition ability the framework we propose has on different kinds of activities.
Experiment 1: parameter selection
Before recognizing activities, we need to do some prepared work. In this experiment, we describe the detailed processes of determining the element number of ADL primitive and primitive judging threshold.
Parameter 1. The element number in a primitive
The essence of ADL primitive in smart home environment is successively temporal triggered sensor event combination. In order to ensure the effectiveness of primitives, their element number should be figured out appropriately. ADL primitive should include information as much as possible, so one primitive should consist of two or more sensor events. Given that the triple, quad, or other multi-tuple all can be extended by two-tuple, we decided that the two-tuple of successively triggered sensor events satisfying some conditions becomes an ADL primitive, that is, we set the element number in a primitive to two.
Parameter 2. Primitive judging threshold
When a participant is doing activity, he or she triggers one or a few sensors. The corresponding triggered sensor events may be vital or inessential on represent activities, so we need a judging parameter to select valid sensor events as primitive elements, and this parameter should be defined as primitive judging threshold: Jthresh. Some sensor events are necessary to complete activity, while others show participant’s paths or prepare to make target activities. And the sensors in the former group are triggered frequently, while the sensors in the latter group are triggered with fewer times but in relatively wide areas. We consider that the sensors in the latter group are unnecessary and should be deleted; by this way, the amount of activity data can be reduced.
According to the introduction about the primitive judging threshold Jthresh, the setting process needs three steps as follows: (1) we need to know about the occurrence number of each sensor event pair: times (
Taking the part of activity data in our experiment for example, we introduce the process of determining Jthresh in detail. Table 2 shows all sensor event pairs occurring in data and their corresponding occurrence times. The share of three times grades is shown in Table 3. According to these two tables, we set the upper bound of having the highest share: 10 as the primitive judging threshold, that is, sensor event pairs with occurrence times over 10 become primitives. The final result of primitives in this activity data part is shown in Table 4.
Sensor event pairs in the activity.

Occurrence time shares of sensor event pairs.

Selected sensor event pairs as primitives.

After selecting ADL primitives for vocabulary, each activity can pick out its own primitives to be a set and be represented in the form of the corresponding primitives in the remainder of recognition process. However, the nature of primitive is sensor event pair without actual meaning; in order to represent activity data stream in a natural and well-understood way, we give each primitive a physical meaning.
Through the between raw activity data streams and their primitive sets, we find that when user executes activities, there are some fixed action paths and featured sensors triggered. Let us take the activity “make a phone call” as an example to illustrate what we discover.
The primitive set of the activity “make a phone call” includes 12 primitives such as <M01, M07>, <M07, M08>, <M08, M09>, <M09, M14>, <M13, M13>, <M13, M14>, <M13, asterisk>, <M14, M13>, <M14, M14>, <M23, M01>, <I08, M13>, and <asterisk, M13>. Except for primitives <M13, asterisk>, <I08, M13>, and <asterisk, M13>, other primitives only involve some motion sensors, from which we can detect user’s moving path in house when he or she is making a phone call. For these primitives, we give them physical meaning of location points. The primitives <M13, asterisk> and <asterisk, M13> involve the phone sensor; combining the experimental activity setting, we give <M13, asterisk> the physical meaning of pick up the phone and <asterisk, M13> the physical meaning of hang up the phone. In the same way, since sensor I08 is the phone book sensor, we consider the physical meaning of primitive <I08, M13> to be the end of using phone book. Based on these primitives with physical meaning, we can infer and describe the execution process of the activity “make a phone call” as “the participant moves to the phone and uses the phone book, maybe looks up a special number, then picks up the phone to dial the number, and listens to the message, finally hangs up the phone.” When all primitives are given their physical meaning, we can represent execution processes of activities in the natural way just like the example of “make a phone call.”
Experiment 2: activity recognition
In order to evaluate the recognition performance of AR-ADLP framework objectively, we leverage cross-validation strategy to ensure experimental results’ academic rigor and reliability. And our recognition results are compared with the famous researcher Cook’s recognition accuracy using the same activity database.
In the cross-validation strategy, we divide all experimental data into four groups, three of them are set as training dataset and the remainder group is testing data, thus there are totally four iterations in the whole recognition process. During these four iterations, every group experimental data should be ensured to become the testing data one and only one time. The average of these four iterations’ results is considered as the experimental result to evaluate our framework’s recognition effectiveness. There are five activities to recognize, and their accuracy results (acrs) are shown in Table 5, in which each row stands for an iteration process and each column stands for an activity. Through these acrs, we get the best acr in the iteration one and average acr results by averaging all acrs.
Four iterations’ acrs of cross-validation strategy.

Figure 2 depicts the accuracy comparison of AR-ADLP framework (namely, the best and the average case, Cook’s recognition method with NB and HMM, and Zhang’s method with SVM). From this figure, we can see that acr in Zhang’s SVM method has the worst performance. This is because M Zhang and AA Sawchuk’s 21 framework works on a bag of features defined by the mean, standard deviation, root mean square, averaged derivatives, and mean crossing rate of continuous sensor data (or signals), but they are not well-defined on discrete sensor data (or events). So to have a better comparison, we will treat Cook’s recognition results as the baseline in next experiments.

Comparison of acrs of AR-ADLP framework and Cook’s method.
In Figure 2, the acrs of activities “wash hands” and “clean” in the best acr values are namely 3.75% and 0.94% higher than those in Cook’s HMM method, and the former has the same results with the latter in activities “make a phone call” and “eat,” which are all 100%. Although the acr in the activity “cook” of the best iteration is 0.19% lower than Cook’s HMM method, with respect to the average acr values, its acrs are 3.57% and 0.2% higher than Cook’s HMM in the activities “wash hands” and “clean,” and 0.33% and 1.38% lower in activities “cook” and “eat.” Overall, in terms of acrs, AR-ADLP framework achieves outstanding and satisfactory results.
Except for comparing acrs of each activity, we also need to compare rate and srate. Combining the cross-validation strategy, we get the results during four iterations shown in Table 6. From Table 6, we can see that the best recognition accuracy rate is achieved in the third iteration, although its recognition stability parameter srate is only a little below the first iteration’s srate. And through this table, we average rate and srate to compare with Cook’s recognition results, which are presented in Table 7.
rate and srate of AR-ADLP framework in four iterations.

Comparison of rate and srate in AR-ADLP group and Cook’s group.

We can see from Table 7 that rate and srate of AR-ADLP best group are both better than others; among these, AR-ADLP best group is 1.03% higher than Cook’s best accuracy (i.e. Cook’s HMM group) in rate and 8.03% higher than Cook’s NB group. Moreover, in terms of AR-ADLP average group, the rate is 0.27% better than Cook’s HMM group, and the srate is a litter below Cook’s group. That is to say, the AR-ADLP framework we propose has better performance on recognition accuracy, and outperforms Cook’s methods on the stability and robustness of recognizing different kinds of activities.
Confusion matrix is a useful table that presents both the class distribution in the data and the classifiers predicted class distribution with a breakdown of error types. We construct two confusion matrices (Tables 8 and 9) for recognition frameworks’ integrated activity reconstruction module (i.e. the experiment group) and not integrated one (i.e. the control group). Each row in a confusion matrix stands for the real activity label in testing data and each column stands for the recognized label. The element which is located in the ith row and the jth column stands for the number of activity label “i” that is recognized as activity label “j,” thus the “bold” elements stand for the number of activity labels recognized correctly.
Confusion matrix of labels recognized in the experiment group.

The significance of bold values empathize that how many activities are recognized correctly.
Confusion matrix of labels recognized in the control group.

The significance of bold values empathize that how many activities are recognized correctly.
Compared to the recognized situation of the control group, the experiment group indeed recognizes the less number of activity labels. So Tables 8 and 9 show that the control group not only has a higher true positives but also lower false positives if compared with the experiment group. If we consider the true negative rate (tnr), the control group tnr is lower if compared with that of the experiment group: it decreases from 0.32 to 0.16 for “make a phone call,” from 0.23 to 0.10 for “wash hands,” from 0.53 to 0.44 for “cook,” from 0.31 to 0.18 for “eat,” and from 0.42 to 0.29 for “clean.” So, we can conclude that the AR-ADLP framework not only improves the ability of recognition but also reduces the total number of activity labels needed to be recognized, thus to release burden of the whole recognition process.
Discussions
The goal of our experiments is to verify the recognition performance of AR-ADLP framework. All the tables and figures present that the results of rate and srate of our novel framework are both better than the best experimental situation of Cook’s methods and indicate that AR-ADLP framework has more accurate recognition and stronger robustness in various activities. In another aspect, we carry out to find actual physical meaning for each ADL primitive in real daily living, and by this way, represented activities can be easily understood.
The AR-ADLP framework is not a universal one but only suitable for smart environments that generate discrete data (events). The temporal attribute of an event can be used to determine the temporal relationship between events. This information can be useful for the ordering of event sequence in a timeline and also for the better presentation of discrete data. It is easy to incorporate them in a new smart home system because ADL primitives are the simplest temporal relationship. To do so, we first learn ADL primitives by counting events that co-occur often in annotated activity data. Then, we determine the primitives for a given activity through the process of data reduction. Then, events and the learned primitives are treated as features to train a specific classifier.
There are two less-than-ideal acrs of activity “cook” in our best and average groups which are slightly worse than Cook’s HMM method, but we cannot deny the effectiveness of AR-ADLP framework. Through our careful analysis, we think the high similarity between the primitive set of activities “cook” and “eat” leads to bad recognition results, that is, the trained classifier misjudges some primitives belonging to “cook” as primitives belonging to “eat.” This problem can be fixed through adding more information about sensor locations, and it will become the key point in our future research.
Conclusion
In this article, we propose a novel AR-ADLP. In doing so, we determine the definition of the primitive, construct the specific primitive set for each experimental activity, and represent activity data as the format of primitive strings.
According to our experimental results, AR-ADLP framework is good at improving activity recognition accuracy and facilitating deployment in other environment with pre-trained primitive vocabulary. Compared to the traditional recognition framework like Cook’s without ADL primitive, the total recognition accuracy and the standard deviation of activity recognition accuracy of our framework are both better, and the total number of activity labels needed to be recognized is less, which means that new framework has more powerful recognition ability, robustness, and less number of recognized activity data.
In the future, we would like to add some area density factors such as sensor locations in our recognition framework to fix the drawback of the situation where two activities have similar primitive sets.
Footnotes
Handling Editor: Jui-Pin Yang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (nos 61672122, 61402070, and 61602077), the Natural Science Foundation of Liaoning Province of China (no. 2015020023), the Educational Commission of Liaoning Province of China (no. L2015060), and the Fundamental Research Funds for the Central Universities (no. 3132016348).