
Abstract
Industrial wireless networks are an important component of industrial cyber physical systems, and their transmission performance directly determines the quality of the entire system. During deployment, the nodes of an industrial wireless network can be deployed in only some specific regions due to physical environment restrictions in the factory; thus, occlusions are not always effectively circumvented and network performance is reduced. Therefore, this article focuses on the layout problem of the industrial backhaul network: a WiFi long-distance, multi-hop network. The optimization objectives were network throughput and construction cost, and the network delay was used as a constraint. For small networks, we propose a hierarchical traversal method to obtain the optimal solution, whereas for a large network, we used a hierarchical heuristic method to obtain an approximate solution, and for extremely large networks, we used a parallel interactive local search algorithm based on dynamic programming. Then, if the original network layout cannot meet the transmission demands due to traffic bursts, we propose a network bandwidth recovery method based on the Steiner tree to recover the network’s performance. Finally, the results of a simulation showed that the algorithms proposed in this article obtain an effective solution and that the heuristic algorithm requires less computing time.
Keywords
Introduction
As wireless communication technology has developed, wireless technologies based on protocols such as WirelessHART, 1 WIA-PA, 2 and ISA100.11a 3 have been widely applied in industrial cyber physical systems (CPS). 4 However, because of restrictions to capital, technology, and equipment, among others, there may be a situation in which multiple network technologies coexist in a given period, thus forming a heterogeneous industrial wireless control network.
IEEE 802.11–based long-distance WiFi networks (WiFi-based long-distance (WiLD) multi-hop networks) 5 can achieve long-distance signal transmission because the nodes incorporate high-power IEEE802.11 wireless cards and high-gain directive antennas. In addition, a single-hop link can be tens or hundreds of kilometers in length and feature high bandwidth, low cost, and wide coverage; therefore, it can provide backhaul access for the wireless network to achieve long-distance transmission of data.
This article considers the heterogeneous industrial monitoring network used in industrial CPS, as shown in Figure 1. The wireless network (such as WirelessHART, WIA-PA, or ZigBee) applied in each factory is considered a subnet of a heterogeneous network, and each subnet is connected via an industrial backhaul network6,7 through IEEE 802.11 long-distance WiFi to constitute the wide-area heterogeneous industrial monitoring network. A control command given by the general control center is transmitted to the control plant in the subnet through the backhaul network and the subnet gateway, in that order. Meanwhile, the backhaul network provides an interconnection between the industrial control network and the Internet.

A heterogeneous industrial monitoring network architecture in industrial CPS.
However, during the practical deployment of a network, WiLD nodes can be deployed in only specific regions due to physical environment restrictions in the factory. Meanwhile, a high tower cannot be erected in some factories, and an antenna can be erected only at the top of a building or existing lamp pole. As a result, the WiLD network’s antenna fails to effectively elude some occlusions, thus hindering the network’s transmission performance. Therefore, the layout of the network should be optimized. Figure 2 shows a partial map of Fushun Petrochemical Factory, China National Petroleum Corporation, in which the circled positions are metal tank areas or pipeline areas whose occlusion cannot be directly circumvented. In this case, it is necessary to consider the proper locations and number of nodes, the angle of the antenna, and other factors to optimize the network bandwidth and guarantee network performance.

Example of occlusion in the factory.
This problem can be included in the scope of facility location. It is most similar to the P-median problem in facility location but with the following differences:
The traditional P-median problem is used to determine the minimum sum of the weights from demand points to the facility location, whereas in the network model of this article, consideration is given not only to the weights from demand points (gateway node) to the facility (exchange board) location but also to the weights between facilities through which the traffic flow passes.
Only a single target, namely, the weighted distance, is considered in the traditional P-median model, whereas the model in this article targets the optimization of the overall bandwidth and system overhead to plan the deployment of network nodes.
Thus, in this article, we used a network architecture based on WiLD multi-hop networks to optimize the node layout of the industrial CPS. The optimization objectives were network throughput and construction cost, and the network delay was used as a constraint. The main contributions of the article are as follows:
We propose a hierarchical P-median optimization model based on the traditional P-median model. There are two methods in this model. First, for a small network, a hierarchical traversal method based on the hierarchical P-median optimization model was adopted to obtain the optimal solution. Second, for a large network, a hierarchical heuristic method based on the hierarchical P-median optimization model was used to obtain an approximate solution.
To cope with the situation when the original network layout cannot meet the transmission demands due to traffic bursts, we propose a network bandwidth recovery method based on the Steiner tree (BRM-ST) to recover the network’s performance.
A test was carried out via simulation, and a comparison was made between the result obtained using the algorithm proposed in this article and that obtained using the traditional genetic algorithm (GA)–based heuristic method. The result showed that the proposed algorithm obtains an effective solution and that the heuristic algorithm requires less computing time.
The remainder of this article is organized as follows. We summarize the related works in section “Related work.” We formulate the problem and provide the system model in section “System model and formulation of the problem.” Following the model description, two methods based on hierarchical P-median optimization model and a parallel interactive local search algorithm based on dynamic programming (PILS-DP) are proposed in section “Solutions.” In section “Network node deployment for traffic bursts,” we propose network node deployment methods for traffic bursts. The experimental results are given in section “Experiment and analysis.” Finally, section “Conclusion” concludes the article.
Related work
Numerous studies of facility location models have been conducted by domestic and foreign scholars. Maximum Covering Location 8 is often adopted when the decision-maker fails to satisfy all demands using the available resources (namely, fails to fully satisfy the demands under the given construction input and distance). Set Covering Location 9 is used to obtain the lowest possible facility construction cost while satisfying all demands under a given emergency deadline. The P-median model 10 determines the P facility locations and minimizes the weighted distance from the demand point to the facility (distance can also be expressed as traffic/transport time).
The traditional facility location problems include the p-center and p-coverage problems, which are NP-complete problems. 11 The existing research is more focused on the p-center problem. And some approximation algorithms such as branch-and-bound, 12 branch-and-price, 13 Lagrangian relaxation, 14 integral programming, 15 linear programming relaxation, 16 and randmized rounding 17 are widely used to solve the p-center problem and no capacity limits facility location problems. Besides, the GA, 18 neural network, 19 and simulated annealing 20 are used to solve the large-scale p-center problem.
The current wireless network connection recovery methods are roughly divided into two approaches: deploying new relay nodes to the failure nodes or failure regions to recover the connection and moving some of the original nodes to recover the connection.
The method of moving some original nodes to recover the connection does not require the deployment of new nodes, but it does require the nodes to be mobile.
For recovery through deploying new nodes, some heuristic methods have been proposed. A previous study 21 proposed a method in which the failure node’s neighboring positions are replaced to recover the network connectivity. However, this method cannot handle cases in which multiple nodes fail at the same time, and some nodes cannot move in some partitions.
In Lloyd and Xue, 22 the minimum spanning tree algorithm based on a single-tiered relay node placement (MST-1TRNP) uses the Kruskal or the Prim algorithm to find the minimum spanning tree. Then relay nodes are deployed along the edge of the tree based on the length of the relay nodes’ communication radius. However, this method has higher complexity, and the average node degree is low after recovery. To improve the average node connectivity, the simply Connected Spiderweb (1C-SpiderWeb) algorithm is proposed. 23 1C-SpiderWeb completes the relay node deployment by forming a network structure similar to a spider’s web. Although the average node connectivity increases, this approach requires a much higher number of relay nodes. A cell-based optimized relay node placement (CORP) 24 algorithm divides the network into units of equal size. Then, based on the grid positions in the partition, it deploys relay nodes to recover the connection. The network topology balances the network data transmission capacity and reduces the data transmission delay between partitions. However, the complexity of this approach is high, and it is not suitable for large-scale networks.
System model and formulation of the problem
The WiLD network is expressed as
Each node in the network is equipped with one or several directive antennas. Here, we assume that the antennas are of the same type and have an identical beam width

Antenna configuration diagram.
Occlusion is measured by the bandwidth of the received signal. Suppose
This article aims to determine the placement locations of WiLD nodes and the number and directions of their antennas in the network to reduce the influence of occlusion on the network and maximize the network throughput while satisfying the traffic delay condition and bandwidth demand and minimize the overhead.
Optimization objective
The optimization objective is to obtain the maximum and minimum values, namely,
Constraint
Real-time performance constraint
According to the analysis of Jintao et al.,
26
the delay of each hop is fixed when using the 2P MAC protocol, and we denote it as
Bandwidth demand constraint
The bandwidth provided by the transmission path of the traffic must meet the bandwidth demand of the traffic, namely,
Link capacity constraint
The total transmission bandwidth occupied by each traffic on each link should not exceed the bandwidth provided by this link. Thus,
Gateway node setting
For each gateway node M in the network,
Node setting constraint
If node
In conclusion, the optimization problem in this article can be considered a special type of the universal capacity limitation facility location (universal facility location) problem. The problem here differs from the universal facility location in that, in this article, traffic overhead is not only relevant to the node from the client side (gateway) to the location under selection, the overhead during the relay between exchange boards and from an exchange board to a data center node should also be considered. It has been proven that the universal facility location problem is a NP-hard problem; consequently, the problem in this article is also an NP-hard problem.
Solutions
Each directional antenna is replaced by an omni-directional antenna with the same transmission range. Point-to-point communication is adopted between nodes; therefore, the interference between nodes can be ignored. For each node, all nodes that can be connected to it when communicating at maximum power are considered to be nodes connected to this node. Thus, a topological graph of network connections can be constructed. The maximum bandwidth of an information transmission between two nodes connected with an edge is taken as the weight of that edge. According to the analysis of the network operation mode in the above section, the traffic flow bandwidth demand from the gateway node to the data center node is larger than the traffic flow bandwidth demand in the reverse direction. Therefore, if the bandwidth demand from a gateway node to the data center node can be fulfilled in the solution, the total bandwidth demand of the whole network is also satisfied.
The goal of the P-median model is to separately find proper locations for P facilities and designate for each demand point the given facility under the demand set of the given quantity and location. In addition, the P-median model identifies a set of candidate facility locations, thus obtaining the lowest transport cost between the facility and demand point. The traditional P-median model considers only the single-hop cost between each demand point and facility and is a single-hop single-objective model, whereas in the WiLD network, the end-to-end cost between two demand points should be considered, and it is therefore a multi-hop model. Both bandwidth demand and construction cost objectives are considered in this article; therefore, the proposed model is a multi-objective model. Consequently, to obtain a solution for the WiLD network, a hierarchical solution method based on the P-median model is presented in this article.
Hierarchical traversal solving method based on the P-median model
The total number of nodes in the network is N. Of these N nodes, M gateway nodes and a data center node must be deployed. Therefore, the total number of nodes in need of placement is
This algorithm is implemented by adding the restriction condition
The calculation of

Initialization
The traffic bandwidth passing through each link is
Construction of augmenting path
Judge whether there is an augmenting path between
Link bandwidth occupation adjustment
Set
Conduct reverse query for each node in each path along the selected augmenting path, in order, with
The input link of
There is no such point with residual bandwidth at the input link but without residual bandwidth at the output link before
There is residual bandwidth at the first section of the link on the augmenting path.
There is a path from
Then,

Regarding the calculation of
Algorithm complexity analysis
During the execution process for the algorithm, each P should include searching the augmenting path and adjusting the link bandwidth occupation. When searching the augmenting path via depth-first search, if the last node in the current path can be accessed with link bandwidth extension, the longest length of the augmenting path is N; that is, node
P-median model-based hierarchical heuristic solving method
To resolve the location problem of nodes when the network size is relatively large, a P-median model-based hierarchical heuristic solving method (P-HHM) is presented. First, let

The calculation process of the P-median-based heuristic solving method is as shown in Algorithm 4, and its main steps are as follows.

Construction of spinning tree
The bandwidth that can be provided by the link is taken as the link weight based on the traditional “kruskal” algorithm to obtain the largest bandwidth spanning tree with data center node
Deletion of nodes
Set
Bandwidth and overhead calculation
As the value of P decreases,
Complexity analysis of the algorithm
In the construction process of the spanning tree based on the traditional “kruskal” algorithm, traversing is required for
Parallel interactive local search algorithm based on dynamic programming
To resolve the location problem of nodes when the network size is relatively large, we propose a PILS-DP. The main ideas of this algorithm are as follows: the layout locations in the network are segmented according to geographic location; local searching is performed in each segment to obtain the optimal solution with boundary nodes under different conditions; and the globally optimal solution for the entire network is obtained by a dynamic programming algorithm based on the locally optimal solutions in each segment.
Network segmentation
Definition: cut set
Split the
Take the minimum hop count
Local search in each cut set
For each cut-set

Definition: the boundary nodes
In the cut set
In the process of local search, record the optimal solution in each situation that contains boundary nodes as the state variable in the feasible solution space during the period of inter-cut-set search.

Dynamic programming inter-cut-set search
The basic idea to solve the problem with dynamic programming is as follows.
The
In each phase, the feasible solutions are obtained by local search in the cut set for the different states (set to k, where
In each state
The index function of the cost measured in the
The optimal value of the index function is the optimal index function, denoted by
According to the overall optimal solution and the reverse solving ideas of dynamic programming, we get the decision
The complexity of the algorithm
A depth-first search is carried out in each cut set. In the worst case, it is not until the last node that the feasible solution is obtained when using the depth-first search method to search for the feasible solution satisfying the constraints. Thus, the total computational complexity of the search is
The time complexity of the dynamic programming algorithm is
Network node deployment for traffic bursts
When the original network layout cannot meet the transmission demands due to traffic bursts, we can recover the network’s performance by increasing the number of nodes or the number of antennas in some nodes to increase the network bandwidth and meet the traffic transmission demands. Thus, we propose a network BRM-ST. The basic idea of this method is that when the bandwidth is insufficient, we use the residual bandwidth that another path can provide to transmit; if we cannot find another path with sufficient residual bandwidth to meet the demands, we consider the link that cannot meet the bandwidth demands to be disconnected, and the network is partitioned. Then, we structure the network partition connectivity based on the Steiner tree 28 to meet the bandwidth transmission demands.
One possible approach is to select the node with the minimal cost path to the Steiner tree and add the node to the tree through the minimal cost path. However, the time complexity of iterating to find the possible paths is too high. To reduce the time complexity, we use the basic idea of the progressive increase in the Dijkstra algorithm to define the node search order and skip the feasible paths with higher cost to achieve a fast search. The algorithm mainly includes the following three stages: preparation, Steiner tree construction, and fast searching.
Preparation
The locations where nodes can be placed are assumed to have nodes equipped with omni-directional antennas and maximum power. When the transmission bandwidth of a link is less than the demand of the traffic burst, the link is seen as disconnected, and the network is partitioned. All partitions segi form the set D, ordered from large to small order according to distance (
Steiner tree construction
Define the path weight of the path
Using the Dijkstra shortest path tree (Dijkstra-SPT) algorithm,
10
we can get the minimum path weighted Steiner tree T rooted in
Fast searching
In the fast-searching stage, we introduce two variables
The minimum cost from node
The path weight set from
The recursion relation of

In the fast-searching stage, we search the node with minimum
Initialization. The current time delay constraint, Steiner tree

Choose the node with the minimum cost to T from Q. If multiple nodes are optimal, choose the node with maximum path bandwidth; denote it as
If
For each neighbor node
Then, delete
Finally, check the results and delete the duplicate nodes and antennas that can communicate in the feasible bandwidth to further reduce the number of node deployments.
The complexity of the algorithm
In the Steiner tree construction stage, we use the Dijkstra-SPT algorithm to establish the spanning tree. Thus, the complexity is
Experiment and analysis
This section describes a simulation experiment conducted to verify the performance of the algorithm proposed in this article. We used MATLAB to simulate the performance of our algorithms. A network is randomly generated in a 2 km × 2 km area, points in the network are randomly selected for the data center node and the gateway node, and traffic is sent to the data center node via the gateway node. The maximum transmission bandwidth and minimum network construction overhead of the network under different conditions are obtained by changing the maximum number of selectable point locations, the transmission power of the nodes, and the traffic bandwidth demand in the network. The maximum transmission bandwidth of traffic between nodes is set to 30 M. The bandwidth between nodes decreases linearly as the distance between the nodes increases. Because there is no similar algorithm that considers the same two objectives (network throughput and construction cost), we compare our algorithms’ results with the existing GA. We simulate the computation times, the maximum bandwidth provided under different numbers of selectable point locations, and the number of nodes required under different traffic bandwidth transmission demands and the maximum transmission bandwidth with these algorithms. In addition, a comparison is made between the P-HTM and P-HHM algorithms presented in this article and GA. Because as we know that this is the first article that considers two objects of nodes layout with IEEE 802.11 long-distance 2P MAC, there are no techniques available in the literature, and we just compare our methods with the traditional GA. The test results are shown in Figures 4 and 5.

Computing time of each algorithm under different optional locations.

Calculation results of P-HTM, P-HHM, PILS-DP, and GAs. (a) The maximum bandwidth provided under different optional locations. (b) The number of nodes required under different traffic bandwidth demands. (c) The number of nodes required under the different maximum bandwidth of nodes (traffic bandwidth demand is 120).
Figure 4 shows the computing time of each algorithm for solving the problem based on different numbers of selectable point locations. It can be observed from the figure that the computing times of the P-HHM and PILS-DP algorithms are lower than that of GA and that of the P-HTM is higher than GA. In addition, as the number of selectable point locations increases, the computing times of the P-HTM algorithm and GA algorithm increase rapidly, but that of the P-HHM and PILS-DP algorithms increase slowly. Figure 5(a) shows the maximum bandwidth that the network can provide under different numbers of selectable point locations. Figure 5(b) shows the number of nodes required for network transmission under different traffic bandwidth transmission demands. Figure 5(c) shows the total number of nodes required by network with different maximum transmission bandwidths that can be provided by each node when the transmission bandwidth demand of network traffic is 120. It can be seen from Figure 5 that the results from the P-HTM, P-HHM, PILS-DP, and GAs are basically identical. Therefore, the simulation result shows that an exact solution can be obtained via P-HHM and PILS-DP algorithms, which also take less computing time. While with the parallel computing feature, PILS-DP can further reduce the computing time.
To further verify the performance of the algorithm, a network is set up in Fushun Olefin Factory, Sinopec Group for a test, as shown in Figure 6. Plants and equipment in the factory are distributed within the scope of 1.5 km × 1.5 km, and occlusions include buildings, metal tanks, and pipelines in the factory. There are 14 points in the factory that can be selected to set up nodes, and two of the nodes should be connected to gateway nodes.

Actual node deployment in the factory.
A test is conducted under different bandwidth demands of two gateway nodes, and the required number of nodes is obtained by applying different algorithms, as shown in Figure 7. Figure 7 shows that the solution of the network model can be obtained via both the P-HTM and P-HHM algorithms.

Node number required under different traffic bandwidth demands in the factory (unit: M).
In transmission performance recovery experiments, we compare our proposed algorithm based on a Steiner tree with the traditional minimum spanning tree–based algorithm in terms of the number of relay nodes deployed and the average node degree when meeting the transmission demands, as shown in Figures 8–10.

The impact of the partition number on the number of relay nodes deployed.

The impact of the communication radius on the number of relay nodes required.
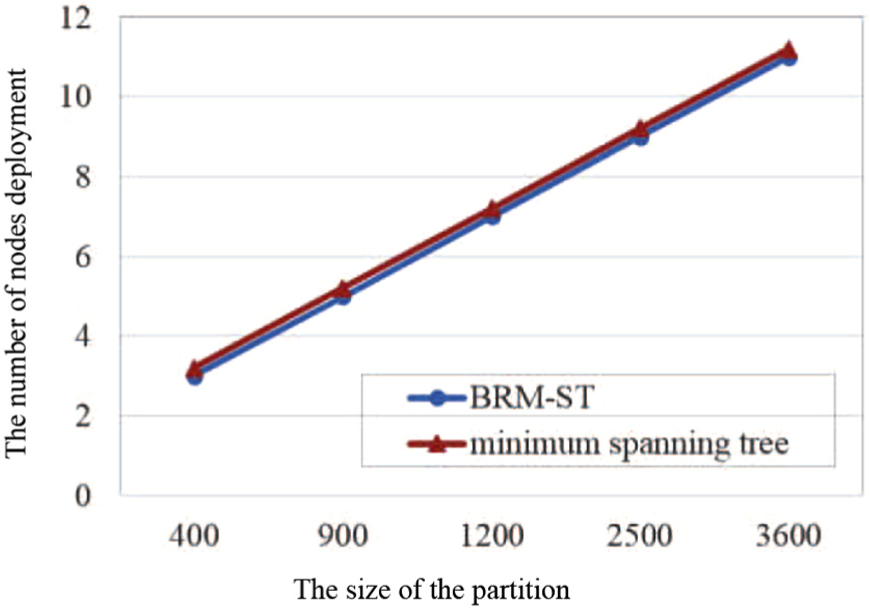
The impact of the size of the partition on the number of relay nodes required.
Figure 8 describes the impact on the number of relay nodes’ deployment of the partition number. We can see from the figure that with the increase in the number of partitions, the required number of relay nodes of the two algorithms increases. This trend corresponds to the actual situation. An increase in the number of partitions will lead to the use of more relay nodes when connectivity is recovered. However, we can also see clearly from the figure that the proposed BRM-ST algorithm requires fewer relay nodes than the traditional minimum spanning tree–based algorithm, and with an increase in the number of partitions, this advantage will be more obvious. This phenomenon occurs because with an increase in the number of partitions, the Steiner tree can connect a much higher number of partitions, which will reduce the number of relay nodes required.
Figure 9 describes the impact of the communication radius on the number of relay nodes required when the partition number is 9. We can see from the figure that as the communication radius increases, the number of relay nodes required is reduced. This trend also corresponds with the actual situation because with the increase in the communication radius, the number of relay nodes required will decrease when the path length is fixed. At the same time, we can see from the figure that the number of relay nodes required by the BRM-ST algorithm proposed in this article is less than that required by the algorithm based on the minimum spanning tree. Of course, this advantage is not obvious because the increasing communication radius will lead to a decrease in the path length.
Figure 10 describes the impact of the size of the partition on the number of relay nodes required when the partition number is 9 and the communication radius is 20 km. We can see from the figure that with an increase in partition size, the number of relay nodes required increases. This result occurs because the increase in partition size will lead to an increase in the distance between partitions, thus the number of relay nodes required will increase. We can also see clearly from the figure that the number of relay nodes required by the proposed algorithm BRM-ST is less than that by the algorithm based on the minimum spanning tree, and with the increase in the partition size, these advantages are more obvious. This result is because the sum of the distances required by BRM-ST is smaller than that by the minimum spanning tree, and with the increase in the partition size, this advantage will be more obvious.
Conclusion
The goal of this article is to solve the layout problem of the P-median model for a heterogeneous industrial monitoring network based on a WiLD multi-hop network architecture. The traditional P-median model cannot be applied to optimize a multi-hop network or a multi-objective network; thus, a hierarchical P-median optimization method based on the traditional P-median model was proposed in this article. The network node layout was optimized by taking the network throughput and construction cost as optimization objectives and using network delay as a constraint. To resolve the node location problem when the network size is relatively large, a PILS-DP is proposed. Then, when the original layout of the network cannot meet the transmission demands due to traffic bursts, we recover the network’s performance using a network BRM-ST. A simulation experiment was performed using a network constructed in a practical environment. Furthermore, we compared the solution obtained by the algorithms proposed in this article with that obtained by the traditional GA-based heuristic method, thus verifying the performance of the proposed algorithms.
Footnotes
Acknowledgements
The authors thank the 12th International Conference on Wireless Algorithms, Systems, and Applications (WASA 2017) for providing an opportunity to preliminarily present the deployment problem and its preliminary solution. The authors also thank the anonymous reviewers for their constructive advice.
Handling Editor: Suparna De
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (grant nos 61502474, 61501447, and 61233007) and Youth Innovation Promotion Association of the Chinese Academy of Sciences.