
Abstract
Multi-sensor data fusion method has been widely investigated in recent years. This article presents a novel fusion algorithm based on regional characteristics for combining infrared and visible light images in order to achieve an image with clear objects and high-resolution scene. First, infrared objects are extracted by region growing and guided filter. Second, the whole scene is divided into the objects region, the smooth region, and the texture region according to different regional characteristics. Third, the non-subsampled contourlet transform is used on infrared and visible images. Then, different fusion rules are applied to different regions, respectively. Finally, the fused image is constructed by the inverse non-subsampled contourlet transform with all coefficients. Experimental results demonstrate that the proposed objects extraction algorithm and the fusion algorithm have good performance in objective and subjective assessments.
Keywords
Introduction
Multi-sensor data-based techniques have the advantages of providing sufficient information and thus have drawn much attention in recent years. For example, in the fields of structural health monitoring (SHM), vibration signal analysis has been proved as an effective tool for condition monitoring and fault diagnosis.1–3 However, in some cases, single-sensor data-based SHM cannot provide enough information to accurately detect the operational condition of complex mechanical equipment. Therefore, it is of great importance to develop effective multi-sensor data-based signal processing techniques. Image fusion is a technique that extracts available information from two images or more to merge into an image showing more information about the scene. Infrared (IR) images are acquired mainly based on the spatial distribution of IR radiation of objects while visible (ViS) light images are obtained based on the light reflection of objects. At night or in the harsh climate condition, IR images can represent objects better than ViS images, but the resolution of IR images is relatively low and the visual effect is fuzzy. 4 Therefore, in order to obtain an image with clear objects and high-resolution scene, IR and ViS images should be combined to fuse. So far, the fusion of IR and ViS images has been widely applied in many fields such as concealed weapon detection 5 and helicopter navigation aid. 6
In recent years, many fusion methods have been developed. Most of these methods can be divided into two categories which are spatial domain fusion and transform domain fusion. Fusion methods in spatial domain are directly performed in pixel gray level 7 or color space, 8 such as linear weight method, principal component analysis (PCA) method, and pseudo color image fusion method. For methods in transform domain, source images are converted into a transformed representation, then different fusion rules are applied to different scales and resolutions, and finally the inverse transform is used to obtain the fused image. Traditional transform tools include the pyramid transform, wavelet transform, curvelet transform, and the non-subsampled contourlet transform (NSCT).9–11 However, a good fusion method not only relies on the transform but also depends on the fusion of coefficients in the transform domain. Traditional methods that adopt a single fusion rule have the disadvantage of dimming objects in the fused image.12–14
In this article, a fusion method for IR and ViS images based on regional characteristics is proposed. Our work differs from existing works in three aspects:
Objects are extracted from the IR image with methods of region growing and guided filter. Each object in the IR image is taken into account, and adaptive filtering is realized by improving the size of local window of guided filter. The proposed objects extraction method not only guarantees the integrity of objects but also avoids the introduction of the background.
Aiming at obtaining a scene with higher resolution and making full use of complementary information from IR and ViS images, the gradient map of the ViS image is computed and the gradient map is clustered. By combining the segmentation of the gradient map and the object image, the whole scene can be segmented effectively.
Image fusion is performed on the enhanced IR image and the region division map, which makes the fused image have clear objects and high-resolution scene.
The rest of this article is organized as follows: Recent fusion methods are introduced in section “Related works.” The fusion framework is given in section “The system overview.” The extraction of the objects region is described in section “Extraction of IR objects.” The segmentation of the scene is presented in section “Division of the scene.” The fusion rule is given in section “Fusion algorithm based on regional characteristics of the image.” Experimental results are performed in section “Experimental results and analysis” and conclusions are summarized in section “Conclusion.”
Related works
Up to date, most image fusion algorithms are performed in transform domain, and the tool of the NSCT is the most popular. The NSCT can implement multi-scale and multi-directional decomposition, respectively, based on a non-subsampled pyramid (NSP) and non-subsampled directional filter banks. The structure of the NSCT is similar to that of contour transform, but compared with contour transform, the NSCT retains multi-resolution and multi-direction information and provides translation invariance as well as elimination of the Gibbs phenomenon. Furthermore, it overcomes the limitation of the direction in traditional wavelet transform and variation in translation in contour transform and can effectively reduce the impacts of mis-registration in fusion results. Therefore, the NSCT is more suitable for image fusion. However, most NSCT-based image fusion algorithms mainly apply fusion rules of the independent pixel gray value and the independent window, which may influence the quality of the fused image. In particular, two main issues can result from such a fusion approach:
The contrast between objects and background is low.
Visual effect of the fused image is poor, and there is a loss of detailed information.
To solve the above problems, an increasing number of algorithms based on region division and object extraction are proposed. These algorithms apply different fusion rules to different regions of source images according to characteristics of different regions, which is of great help to improve the quality of the fused image. Sun et al. 15 combine region growing and the non-subsampled shearlet transform and propose the fusion method based on object extraction and adaptive pulse coupled neural network. This method applies the regional information to the fusion process, but it fails to concern the objects region for region division. Han et al. 16 feed the co-occurrence of hot spots and motion into a markov random field (MRF) model to generate the saliency map for the IR image, then source images are decomposed by wavelet transform, and low coefficients are fused by the method of weighted average and the choice of weighted coefficient is determined by the saliency map. This method depicts the salient foreground object clearly and the speed of fusion has been improved greatly; however, the edge of objects in the fused image is poor. Zhao et al. 17 identify regions-of-interest based on region saliency detection in both imagery frames, and then segment the images into target and background regions. Different fusion rules are adopted respectively in target and background regions. Although the quantitative fusion result is improved, the visual effect is still not very well. Yang et al. 18 propose a region fusion method based on watershed. The method improves the objective evaluation index of the fused image, but the segmentation method merely considers the global characteristics of source images without considering the local ones. Luo et al. 19 propose a fusion method based on structure similarity. The region map is generated from the structural similarity (SSIM) index between source images and the fused image. However, the region map is influenced by fusion rules of the initial fused image. Wang and Fu 20 and Xu et al. 21 have proposed novel algorithms using region growing and gray theory to extract IR object. However, these approaches consider only objects region while without characteristics of the scene. Wang and Du 22 proposed an algorithm based on image segmentation. After object segmentation, different rules are applied to objects region and background region. However, the disadvantage is that the robustness of the segmentation approach is not high, and the segmented object would include some background region.
The system overview
Figure 1 depicts the proposed system architecture with its main functional units and data flows. The functions of the key modules are as follows:
Extraction of IR objects: IR objects are extracted from the IR image based on approaches of region growing and guided filter.
Segmentation of the whole scene: first, the gradient map of the ViS image is calculated by Sobel operator. Second, the ViS image is divided into the smooth region and the texture region using K-means clustering on the gradient map. By combining the map of background division of the ViS image and the object image, the division map of the scene is obtained.
Fusion of images: first, region mapping is conducted on the enhanced IR image, the ViS image, and the IR image according to the region division map. Second, high-frequency and low-frequency direction subbands are obtained by the NSCT from source images. Third, according to the different characteristics of regions, different fusion rules are used to fuse the high-frequency and low-frequency subbands of source images, respectively. Finally, the fused image is obtained by the inverse NSCT transform.

Block diagram of the proposed method.
Extraction of IR objects
Location of the objects region
The significance of image fusion of IR and ViS images is to use the complementary information of both images to get a fused image that expresses objects and the whole scene accurately, which not only include clear objects but also the higher resolution scene. Therefore, the precise localization of IR objects is particularly important. Current methods of IR objects extraction are based on gray theory, 20 OTSU, 23 Renyi entropy, 24 and so on. These methods can extract small objects, but always include information from the background and cannot extract larger objects completely. To solve these problems, we combine region growing and guided filter to extract objects. The detail of the proposed method is as follows.
To improve the contrast of objects and the background, and get the clear edge of objects, the IR image is enhanced

where
The above process will enhance pixels whose gray values are greater than u and weaken pixels whose gray values are less than u; therefore, this process can greatly improve the contrast of objects and the background of the IR image. In order to avoid the enhancement of the background, it is shown by experiments that the most appropriate value of t is set between 1 and 2.
We introduce the region growing method to extract objects from the IR image which examines neighboring pixels of initial seed points and determines whether the pixel neighbors should be added to the region.
Step 1. Since objects in the IR image have larger thermal emissivity, the brightness of objects is always higher than the background. Considering multi-objects of the IR image and in order not to lose objects, select pixels with relatively higher gray value as seed points. The selection of seeds is as follows

where M is the max gray value of the IR image A, AV is the average gray value of the IR image A, and Z is the set of seed points of the IR image A.
Step 2. According to seed points of the IR image A, pixels in the corresponding position of the enhanced IR image A1 are regarded as the set of seed points Z1 of A1. The rule of the growth is as follows:
Record the max gray value of pixels in A1 as T, Take T as the threshold and apply it into the following growth formula

where
3. Traverse each seed point of Z1 and repeat Step (2), the initial object map

where

Extraction of IR objects: (a1)–(d1) source images; (a2)–(d2) the enhanced images of (a1)–(d1); (a3)–(d3) the initial object images IO; (a4)–(d4) the images IO1; (a5), (b5), (c5)–(b7), (d5)–(d8) the windows of the guided filter; (a6), (b6), (c8)–(c10), (d9)–(d12) the images filtered by (a5), (b5), (c5)–(b7), (d5)–(d8); (a7), (b7), (c11), (d13) the final object images IO2.
As shown in Figure 2(a4)–(d4),
Acquisition of the local region of objects
Guide filter 25 is an edge aware filter which filters the input image by taking into account contents of the guidance image. Guided filter is a local linear model between the guidance image I and the output image Q. The guided filter is used to obtain the local region of objects in this article. The definition is as follows


where
The enhanced IR image A1 retains good edge characteristics of IR objects, and therefore A1 is selected as the guidance image and
First, separate the region of each object in the object image

where L1 is the number of objects in the object image
Second, calculate the distance between each pixel in the object and its centroid

To obtain a filtered image including complete object, calculate the mean value of all
Third, according to the filtering formula (8), set
Extraction of objects
The method of region growing is used in

Then, the growth criterion is chosen as follows

where
Finally, all the object images are integrated to achieve the final object image
Division of the scene
The ViS image has an advantage of high spatial resolution, thus the ViS image can be divided into different regions according to different regional characteristics of the scene. First, the gradient map of the ViS image is calculated by the Sobel operator.
The Sobel operator horizontal gradient is
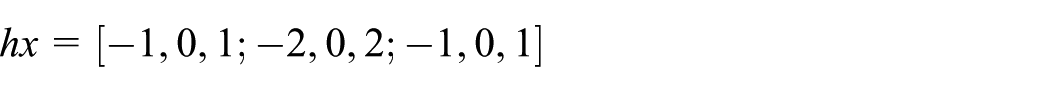
The vertical gradient is
Then the ViS image is filtered by hx and hy, respectively
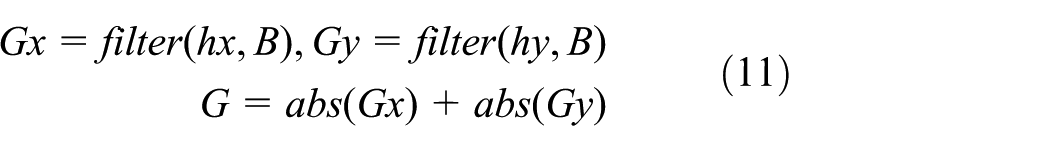
where Gx and Gy are the horizontal gradient and the vertical gradient of the ViS image B, respectively. G is the gradient map of ViS image B, in which the value of each pixel represents the gradient of each pixel in the ViS image. The greater the value represents the richer detailed information the current location has. Then, the K-means method 26 is used to cluster image G. According to the average gradient of each cluster, the ViS image is divided into the smooth region and the texture region.
Joining the object image and the scene divided image, an image which is divided into the objects region, the smooth region, and the texture region is achieved. The experiment results are shown in Figure 3(a5)–(k5), in which the black region represents the texture region, the white region represents the objects region, and the gray region represents the smooth region.

Region division results of images: (a1)–(k1) ViS images, (a2)–(k2) IR images, (a3)–(k3) IR object images, (a4)–(k4) region division results of ViS images, and (a5)–(k5) final region division images.
Fusion algorithm based on regional characteristics of the image
Fusion of the objects region
To enhance the contrast of objects and the background, the objects region of the enhanced IR image A1 and the objects region of the ViS image B are used to fuse. First, the local energies of low-frequency coefficients are calculated

where W is the size of the window and

where

where
Fusion of the smooth region
Since the information in the smooth region is not rich enough and the brightness information are the dominant regional characteristics, the following fusion rules are used


where
Fusion of the texture region
The texture region contains a great deal of edge, texture, and direction information. In order to extract more texture information and high-frequency information, local gradient energy of image (EOG) and local correlation coefficient are used to fuse low-frequency coefficients. EOG is defined as follows




where
Set

When
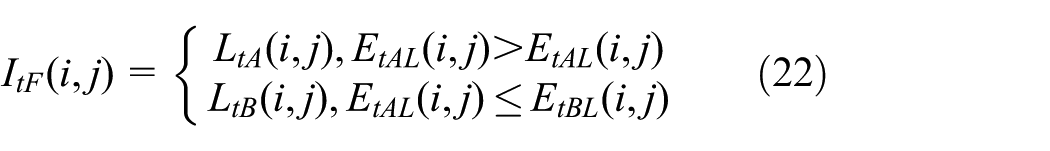
where
The sharpness 27 of point and local correlation coefficient are used to fuse high-frequency coefficients. Sharpness of point is the total weighted deviations between the point and its eight neighborhoods. It is a statistic of the variations’ degree of gray around each point in the image; the higher the value, the clearer the image. The fusion rules are as follows



Set
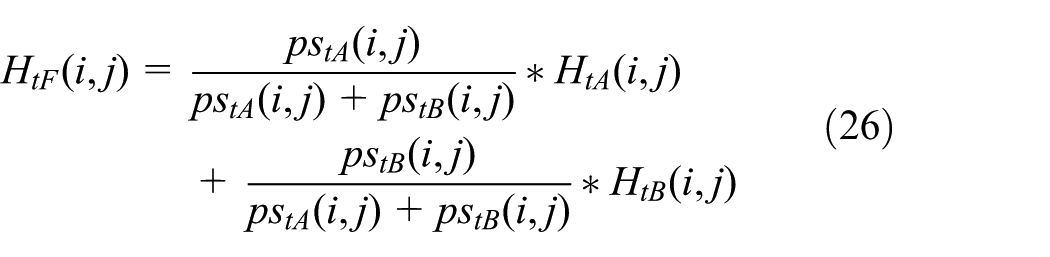
When

where
Experimental results and analysis
In this article, our experiment platform consisted of Core i5-3470 CPU at 3.20 GHz, with 8.0 GB memory, using MS-Windows 7, on which we ran MathWorks MATLAB R2013a software. Our experiments can be divided into two parts. First, we test our objects extraction algorithm. Second, the fusion algorithm is assessed.
Evaluation of the objects extraction algorithm
Our objects extraction algorithm is tested with 11 pairs of IR images. The ground truth data for each image are manually labeled with Adobe Photoshop CS3. We also compared it with two recent algorithms, which are based on gray theory 20 and Renyi entropy. 24 The algorithm based on gray theory takes the IR image as gray system which includes a part of the known information and part of the unknown information, and then the theory of gray correlation is applied to detect and extract the target of IR image. The algorithm based on Renyi entropy through finding out a threshold makes the sum of entropy of the segmented target image and background image reach maximum to extract object. As shown in Figure 4, although the algorithm based on Renyi entropy can extract the object, it has not considered the introduction of interference regions. The algorithm based on gray theory can extract smaller object of IR image, and its result is quiet impressive. However, when the object is large and the scene is sophisticated, this algorithm cannot extract the object completely. On the contrary, the proposed algorithm can not only extract object completely but also avoid the introduction of the background information.
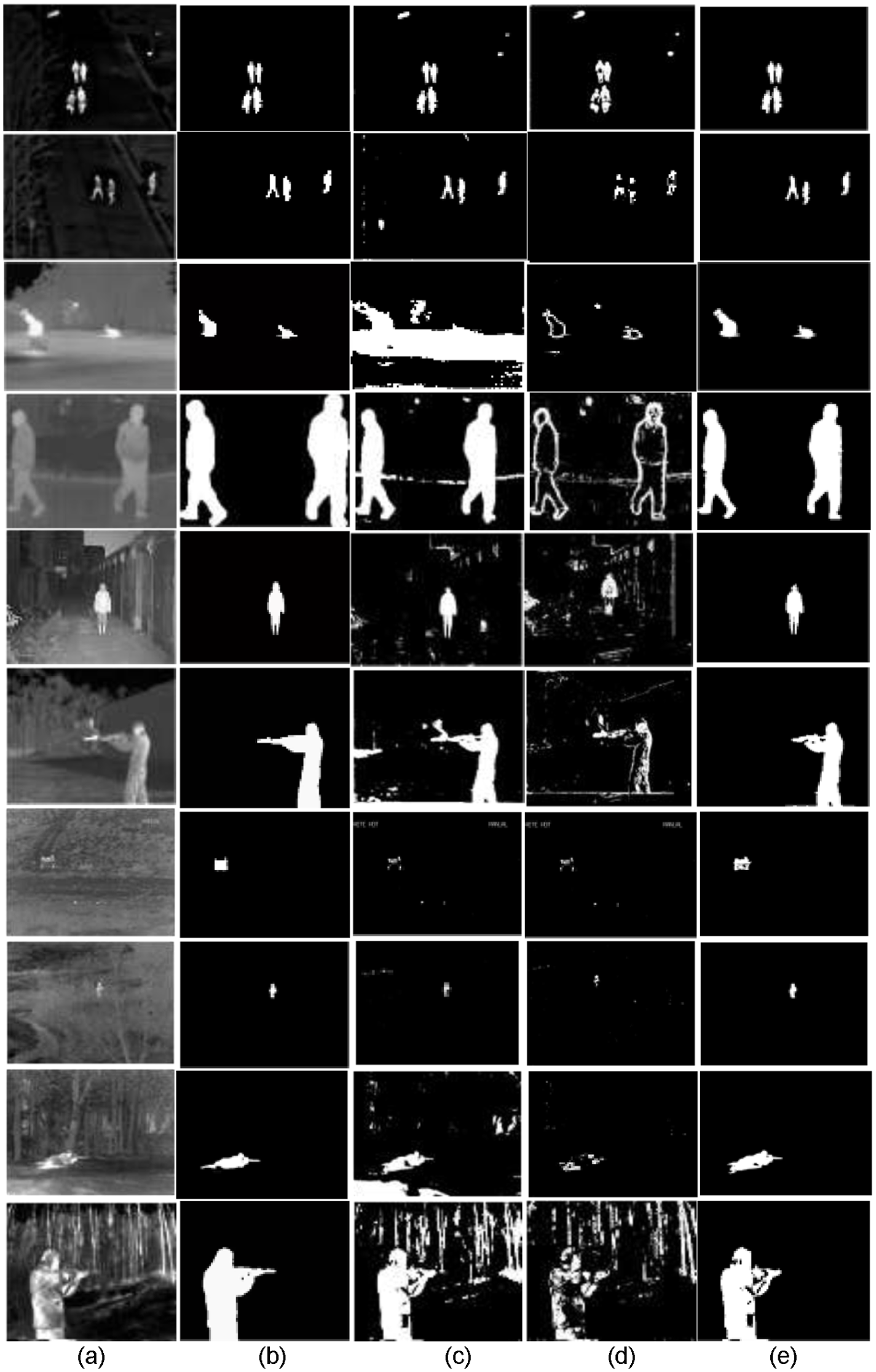
(a) The source IR image, (b) the ground truth image of (a), (c) the extraction result based on Renyi entropy, (d) the extraction result based on gray theory, and (e) the extraction result of our proposed method.
To evaluate the effectiveness of the proposed algorithm accurately and comprehensively, we also adopt objective evaluation criteria of mean precision and recall rate as well as the comprehensive evaluation index F-measure to evaluate the proposed algorithm. The precision, recall, and F-measure27–29 are given as follows


where TP is true positive, FP refers to false positive, and FN means false negative. Experimental results are shown in Table 1 and Figure 5.
Objective evaluation of different methods of object extraction.

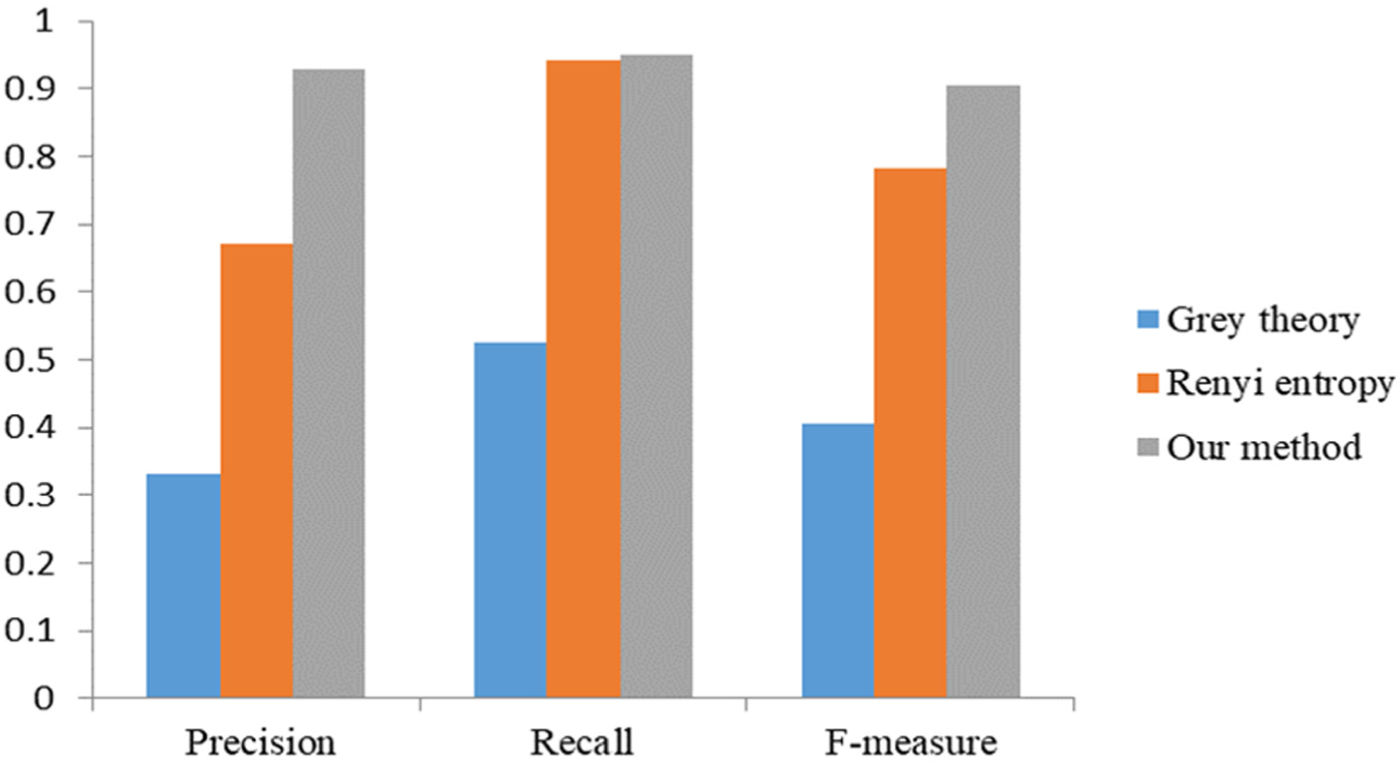
Precision, recall, and F-measure for different algorithms of object extraction.
Evaluation of the fusion algorithm
To validate the fusion effect, the proposed fusion algorithm is compared with several recently developed methods. The experimental results shown in Figure 6(a1)–(a4), (b1)–(b4), (c1)–(c4), (d1)–(d4), (e1)–(e4), (f1)–(f4) are fusion methods based on NSCT in recent years. It can be seen that the contrast between objects and the background is low and objects are blur. (a5)–(f5) are the results of applying the fusion rules of the objects region to the smooth region and the texture region. (a6)–(f6) are the results of applying fusion rules of the smooth region to the smooth region and the texture region. As can be seen from (a5)–(f5) and (a6)–(f6), a relatively complete objects region is achieved and the contrast of objects and background is enhanced, but the resolution of background is low. (a7)–(b7) are fusion results of our method, which include objects of higher contrast and the scene of higher resolution. In terms of visual effects, the fused image of the proposed method contains more details and obtains more salient information from source images, thus it can be seen that the proposed method has a better performance than other methods.

Fusion results of different fusion methods: (a1)–(f1) fused images of Bhatnagar et al., 12 (a2)–(f2) fused images of Chen et al., 13 (a3)–(f3) fused images of Achanta et al., 29 (a4)–(f4) fused images of Cao et al., 14 (a5)–(f5) fused images based on the fusion rule of the objects region, (a6)–(f6) fused images based on the fusion rule of the smooth region, and (a7)–(f7) fused images of the proposed method.
In order to further evaluate the performances of our algorithm, Tables 2–7 and Figure 7 show the comparison of different methods based on NSCT measured by objective criteria. In our experiments, objective evaluation criteria of entropy (E), spatial resolution (SF), average gradient (AVG), edge intensity (EI), and mutual information between the ViS image and the fused image (MI(V,F)) are selected to evaluate the proposed algorithm. It further proves the superiority of the proposed algorithm.
Objective evaluation of different fusion methods of the first image.

E: entropy; SF: spatial resolution; AVG: average gradient; EI: edge intensity; MI(V,F): mutual information between the ViS image and the fused image.
Objective evaluation of different fusion methods of the second image.

E: entropy; SF: spatial resolution; AVG: average gradient; EI: edge intensity; MI(V,F): mutual information between the ViS image and the fused image.
Objective evaluation of different fusion methods of the third image.

E: entropy; SF: spatial resolution; AVG: average gradient; EI: edge intensity; MI(V,F): mutual information between the ViS image and the fused image.
Objective evaluation of different fusion methods of the fourth image.

E: entropy; SF: spatial resolution; AVG: average gradient; EI: edge intensity; MI(V,F): mutual information between the ViS image and the fused image.
Objective evaluation of different fusion methods of the fifth image.

E: entropy; SF: spatial resolution; AVG: average gradient; EI: edge intensity; MI(V,F): mutual information between the ViS image and the fused image.
Objective evaluation of different fusion methods of the sixth image.
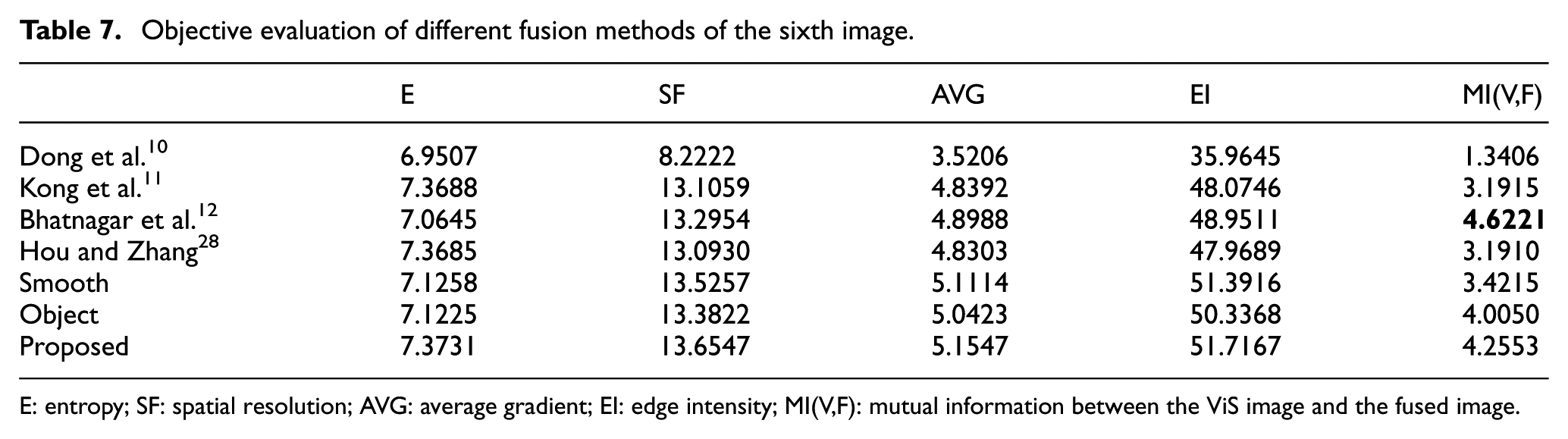
E: entropy; SF: spatial resolution; AVG: average gradient; EI: edge intensity; MI(V,F): mutual information between the ViS image and the fused image.

Objective evaluation of our proposed algorithm and other algorithms.
Conclusion
This article proposes a multi-sensor fusion method based on regional characteristics of the image. This is inspired by the fusion method based on object extraction. The major difference between traditional algorithms and our algorithm is that our algorithm takes the multi-objects and the introduction of the scene information into account. In order to enhance the contrast of the objects region and the background and get the scene with higher resolution, we fused the objects region of enhanced IR image and ViS image. The scene is divided into different regions according to different regional characteristics, and then different fusion rules are applied to different regions. This method not only retains the IR objects but also obtains the spatial domain information of source images effectively. Through the objective and subjective analyses, the experimental results show that the proposed method is superior to other methods.
Footnotes
Handling Editor: Zhi-Bo Yang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China under grant 61305040 and the Fundamental Research Funds for the Central Universities under grant JB161305.