
Abstract
With the expansion of underground infrastructure in the urban areas, positioning in such scenario becomes a crucial problem for the ubiquitous urban positioning applications. The visual odometry algorithm can provide an accurate position reference for ground applications. However, it encounters robust estimation problems in the underground because automatic feature matching from the underground structures is difficult and errors are quite frequent. In this article, we present a novel structure-aware sample consensus algorithm to solve the robust estimation problem in stereo visual odometry. Features from the rigid structure provide a static reference and are more likely to be inliers, based on which we introduce a structure feature-guided sampling procedure instead of the random sampling procedure as used in random sample consensus. With this novel procedure, the structure-aware sample consensus gains more possibility to generate a correct motion model and performs as a robust estimator for the underground visual odometry algorithm. The experiments with both synthetic and real-world data show that structure-aware sample consensus outperforms the random sample consensus and its variants in robustness, while maintaining a lower computational cost. In addition, the structure-aware sample consensus–based visual odometry algorithm maintains the same performance level of robustness and accuracy for both ground and underground scenarios, which makes the algorithm applicable for ubiquitous urban positioning systems.
Keywords
Introduction
In recent years, vision-based localization techniques have been well developed for ground mobile applications such as autonomous vehicles and mobile mapping systems.1,2 While modern urban development and expansion have increasingly shifted to underground infrastructures to relieve ground traffic loads, expanding the application of the ground platform to underground is imperative for ubiquitous positioning systems. According to the recent researches, both direct3,4 and feature-based (indirect) visual odometry (VO)5,6 provide accurate motion estimation results. Enframing feature matching, motion estimation, and nonlinear refinement, feature-based VO achieves good invariance to the illumination and view point changes, which makes it more suitable for the underground applications. Nonetheless, developing a feature-based VO solution for positioning applications in underground infrastructure remains non-trivial because the visual structures and appearances are notably different from the ground environment. Specifically, the major restrictions introduced by underground infrastructure are the poor illumination conditions, featureless structures, and repetitive structures, which create challenges for feature-matching techniques, for example, scale-invariant feature transform (SIFT), 7 speeded up robust features (SURF), 8 and oriented FAST and rotated BRIEF (ORB). 9 Consequently, the matching results underground are contaminated with a large portion of wrong matches. These wrong matches, which are called outliers, have a severe negative effect on the positioning accuracy, since commonly used optimization techniques, such as least squares regression, can produce arbitrary bad model estimates in the presence of a single outlier. 10 Therefore, the robust estimation is indispensable for the VO algorithm, and this problem has been well studied in recent years; among which the most widely used, particularly in computer vision, is random sample consensus (RANSAC). 11
The RANSAC scheme is a remarkably powerful technique for robust estimation. One compelling reason of its widespread adoption is its ability to tolerate a tremendous level of contamination, which provides a reliable parameter estimation even when well over half the data consist of outliers. While robust, the standard RANSAC has its own problem in balancing the robustness and efficiency. Regarding the situation in underground VO application, which suffers a high-ratio outliers, RANSAC can select the inliers but in an exhaustive manner because of its inherent random nature in the sampling process. Recent studies about the computational efficiency and robustness improvement have helped drive forward the state-of-the-art and introduced massive real-world applications.12–15 Although recent efforts have focused on improving the RANSAC algorithm, relatively less attention has been paid to discover other clues from the environment to improve the performance.
In this article, we exploit the constructional attribute of the rigid underground infrastructure to detect the structure features and guide the sampling process to achieve a robust and efficient motion estimation. As shown in Figure 1, some image features are part of the rigid structure, and their inter-point Euclidean distances in three-dimensional (3D) space are constant. Based on this observation, we first check the pairwise Euclidean rigidity constraint and then formulate a vertex covering problem to select the structure features. These structure features are more likely to be the inlier matches and provide a static real-world coordinate reference for the motion estimation algorithm. After the structure feature election, a structure-aware sample consensus (SASAC) algorithm is proposed to efficiently guide the sampling process to generate a correct motion model. When applying SASAC, the sample procedure begins sampling in the group of structure features with a higher inlier ratio and then moves to the normal image feature group. Thus, the SASAC has a higher possibility to find the correct motion model than the RANSAC. Therefore, within the same number of iterations, the SASAC is more robust than the RANSAC, particularly in cases with a high outlier ratio.

The structure features come from the static structures and objects. And these structures are rigidly connected to each other, which makes their Euclidean distances constant in 3D space.
To apply SASAC in a VO scheme, the 3D positions of the corresponding features should be recovered before motion estimation. This task is trivial for the observations of stereo cameras, RGB-D cameras and LiDAR which can recover the depth directly. Due to the limited space, we will focus on the stereo-camera case in this article, but our method can be extended to the above applications. The performance of SASAC-based stereo-VO algorithm is evaluated by the underground data collected using our own mobile platform and the ground data from the KITTI dataset. 16 The main contributions of this work are twofold:
To achieve robust and efficient stereo-VO in the underground environment, we propose a SASAC algorithm to estimate the motion in the presence of rigid structures. Although our algorithm emphasizes on solving the underground robust motion estimation problem, it also works with the ground data and is able to remove the outliers from the moving object.
To evaluate the performance of the algorithm, we collected our own dataset with a self-designed unmanned vehicle. The ground truth was obtained by the total station with a measurement accuracy of millimeter. To contribute to the community, we will make this underground dataset with the ground truth available to the public.
In the remainder of this article, related works are discussed in section “Background.” Section “Structure feature definitions and detection” describes the primary structure feature definition and selection scheme. In section “Structure-aware sample consensus,” we describe the SASAC method and prove the robustness and efficiency theoretically. Then, the performance of SASAC and other comparisons are evaluated with both synthetic and real-world dataset in section “Experiment.” Finally, we conclude the work and discuss about the further improvements in section “Conclusion and discussion.”
Background
The RANSAC algorithm
11
was originally presented as a robust estimator for model fitting in the presence of outliers. It operates in a hypothesize-and-verify manner by repeatedly sampling the subsets of the input data to hypothesize the model parameters. Each hypothesized model parameter is scored by other data points and the hypothesis that obtains the best score is returned as the solution. To ensure with the confidence

where
In fact, the low inlier case exists in several situations such as wide-baseline matching and VO applications in underground scenarios, and several researches have been proposed to solve this problem in the latest literature. Some researches17,18 focus on improving the matching performance to provide matches with higher inlier ratio. However, these methods result in a reduced set of matches, which is not practical in our case, since the featureless structure in the underground can barely provide useful features. Other researches apply the branch-and-bound-based methods19,20 to provide an optimal solution to the robust estimation problem. But it comes with a significantly higher computational cost and is not applicable for VO algorithms. Our work focuses on incorporating the prior information from the environment and guiding the sampling to generate models that are more likely to be correct. This procedure can significantly improve the robustness and efficiency of the RANSAC, particularly for cases with high outlier ratios. This simple procedure has been applied in several ways in the RANSAC literature. A detailed review of some prominent works is shown here.
The progressive sample consensus (PROSAC) algorithm 21 measures the similarity of putative matches and preferentially generates hypotheses based on matches with high similarity. This algorithm assumes that putative matches with high similarity are more likely to be inliers. This assumption is proven to be valid in their initial work, and the algorithm achieves significant computational savings because good hypotheses are verified early in the sampling process. However, the quality scores are not always helpful: in the scenarios with repetitive artificial structures, the gains obtained with PROSAC are less significant. 22
The group sample census (GroupSAC) algorithm 23 uses an observation that inliers are often more similar to one another. The goal of GroupSAC is to separate data points into a number of similar groups according to some criterion such as image segmentation. Then, it assumes that the largest, more consistent clusters tend to have a higher inlier rate. As in PROSAC, the sampling scheme begins by testing a small subset of the most promising groups and gradually expands this subset to include all points. GroupSAC is shown to improve the sampling efficiency; however, as a part of the algorithm, the grouping stage can be exhaustive.
Both GroupSAC and PROSAC share the same idea of a starting sample in the relatively high inlier ratio group. However, their work is based on the assumptions derived from observation, which have not been proven to be universally applicable. 24
In this study, we use the Euclidean rigidity constraint to select out the structure features as the high inlier rate group. Compared with PROSAC and GroupSAC, the Euclidean rigidity constraint is more restricted and practical in the urban scenario with rigid structures, particularly in the underground or indoor environment. In addition, the Euclidean rigidity constraint is motion invariant and can be checked before the motion estimation. Thus, stereo-VO applications can integrate our algorithm without many changes while attaching the ability to work in the indoor or underground situation.
Structure feature definitions and detection
In the urban scenarios, we observe that the man-made structures, for example, underground facilities, buildings, and bridges are rigidly constructed. With this observation, we first recover the 3D position of the structures and then check the inter-point Euclidean distances between pairs of the 3D point. Given two pairs of corresponding 3D points from the rigid structures
Euclidean rigidity constraint for structure feature detection
In the case of stereo cameras, two identical cameras have parallel axes pointing in the same direction at right angles to the stereo base. With respect to an XYZ coordinate system located in the left perspective center, the 3D position of a point

where

where

Considering the 3D point uncertainty
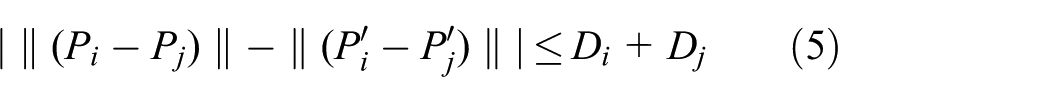
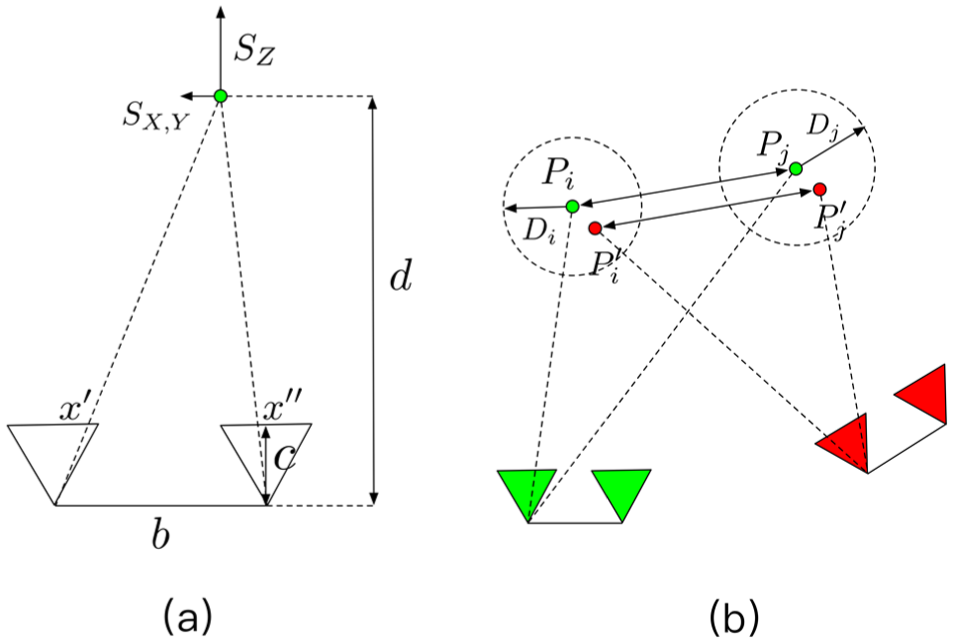
In the case of stereo camera, the 3D points have measurement uncertainty. (a) 2D illustration of the stereo triangulation model and the measurement uncertainty in XYZ direction. (b) Considering the uncertainty
Thus, the definition of the structure features are derived as follows:
Definition 1
Two pairs of corresponding features
With the structure feature definition, we can easily check the pairwise consistency of two features. If two features are inconsistent with the rigidity constraint, at least one of them is not a structure feature. After checking the pairwise consistency of all features, we remove those non-rigid features and wrong-matched features to obtain a group of structure features. This problem can be summarized as follows.
Problem 1
For sets of features with known pairwise consistency, find the largest subset
To solve this problem, a graph is built with all features as vertices and edges that connect the inconsistent ones. Finding the largest subset is equivalent to remove as few vertices as possible while eliminating all the edges. An example is shown in Figure 3: after checking the pairwise Euclidean rigidity constraint, a graph is built on the left. By removing the minimal vertex cover {2,5}, all edges are eliminated, such that {1,3,4,6} are consistent with one another. This is known as the vertex cover problem, which is a nondeterministic polynomial (NP)-complete problem. 26 This problem has been extensively discussed in the previous work.27,28 In this article, we use a combination of factor-2 approximation and branch-and-bound approach 29 to solve the vertex cover problem and remove the vertices that are non-rigid features and wrong-matched features. The algorithm can be summarized as follows.

In the graph, the vertices correspond to the features, if two features cannot satisfy the Euclidean rigidity constraint, they are linked with an edge. To find a group of structure features, all the edges should be removed.

After the structure feature detection, the structure features are used to guide the sampling process rather than estimate the motion directly. Because the structure feature detection algorithm cannot efficiently handle a large number of features, estimating the motion with only the structure features can lead to degeneracies. For example, if the sampled structure features are from the same plane, there can be an infinite number of solutions. So, we propose a more efficient method to use the structure features and set safeguards against degeneracies.
Structure-aware sample consensus
The stereo-VO algorithm is a sequential process of motion estimation with the images of the real-world scene. Take two sequential image pairs for example, and feature points are extracted from the images and matched with some feature detector, for example, SIFT. 7 In the first pair, the triangulation procedure projects the 2D image features to the 3D points in the world coordinate. And in the second pair, a motion estimation algorithm, for example, Perspective-Three-Point (P3P), 30 can estimate the camera pose (rotation and translation) with the 3D–2D correspondences. Since the feature extraction and matching are automatically performed, there is a certain portion of wrong correspondences. For scenarios in the indoor or underground infrastructures, this portion increases due to the repetitive structures and poor illumination. To address this situation, we will first introduce our preprocessing strategy and then illustrate the guided scheme in this section.
Preprocessing: 3D bucketing
Theoretically, checking the Euclidean rigidity constraint of the 3D points will reveal the clue of structure features. However, as previously specified, it is exhaustive to check all the feature points. In addition, when the points are close to one another, the chances of falling into the degeneracies increase. To reduce the computation cost and set safeguards against degeneracies, we present a 3D-bucketing algorithm to obtain a sparse subset of 3D points with a uniform distribution. The 3D-bucketing algorithm is outlined in Algorithm 2.

Then, the pairwise Euclidean rigidity constraints of the sparse 3D points are checked, and the vertex covering problem is solved to detect the structure features. The 3D-bucketing preprocessing reduces the computation burden of the pairwise Euclidean distance calculation and the structure feature detection, which is an important prerequisite for the SASAC-based VO algorithm.
Guided sampling
After the structure features are verified, we present SASAC, a variant of RANSAC that gains additional efficiency by exploiting the properties of the structure features. Our SASAC is based on the hypothesis-testing framework in the RANSAC, except for a guided sampling procedure. Since the structure features are selected, the original image features are subdivided into two subsets: the structure feature subset with high inlier ratio and the common feature subset with low inlier ratio. Assuming that the sample size is
The sampling process starts with

With the known knowledge that the structure feature group has a higher inlier ratio, SASAC bias the sampling with a view toward preferentially generating hypothesis that are more likely to be correct. Thus, the SASAC are more likely to meet the termination criteria and stop early before the computation budget is exhausted. This guided sampling strategy have a dramatic effect on the efficiency and robustness of SASAC, especially in the low inlier ratio cases.
In the sampling process, it is crucial to make the correct number of trials for each configuration

The possible sample sets
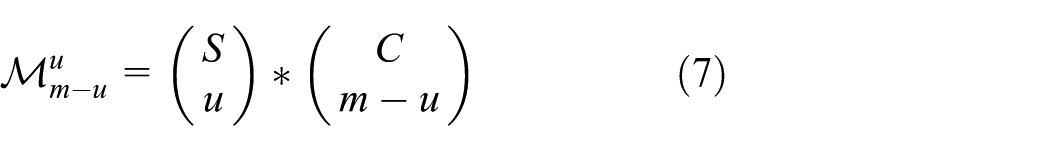
where
Termination criteria
Since SASAC samples in a fashion were similar to PROSAC,
21
we use the same termination criteria in our implementation. First, we check the non-randomness in the case that an incorrect model is accidentally supported by outliers and selected as the final solution. More precisely, the probability that the model is supported by random points should be smaller than a certain threshold
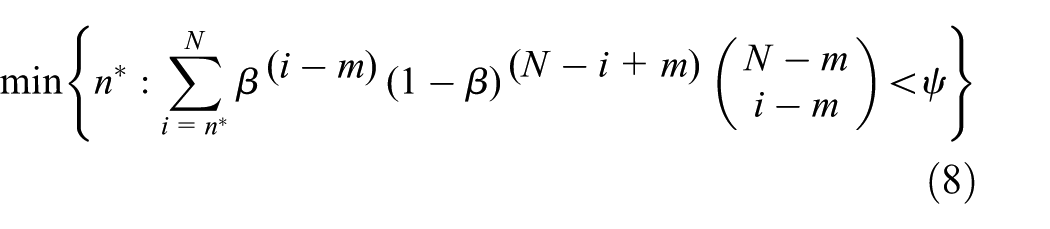
where
Another termination condition is the maximality constraint, which defines how many samples must be drawn to ensure the confidence in the sample that does not contain an outlier. The confidence should be smaller than a given threshold
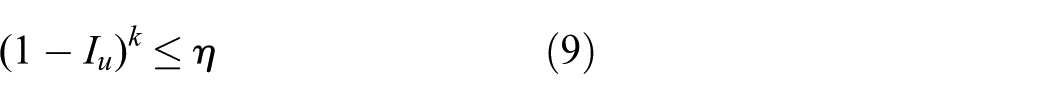
where
SASAC-based VO
The SASAC is integrated in the stereo-VO scheme to perform a robust motion estimation. Assume that the features have been detected and matched, the SASAC-based stereo VO is summarized in Algorithm 4.

In the algorithm, the minimal sample size
Experiment
Our algorithm was tested in C++ on a PC with an Intel i7 2.2 GHz CPU. We evaluated the performance of the SASAC and other comparisons using both synthetic and real-world data. Since our algorithm focuses on solving the VO problem in the underground environment and no related public dataset was available to us, we collected our own dataset together with the ground truth in an underground garage.
Synthetic data evaluation
For the simulation, random problems were generated in the following manner. The position of the first stereo-rig was fixed to the origin of the world frame, and its orientation was set to identity. The position of the second stereo-rig was randomly set so that the translation distance does not exceed 2.0 m. We bounded the rotation so that none of the Euler angles exceeded 0.5 rad (30°), which generated random motion estimation problems that would appear in the practical scenarios. In total, 200 random points were created with a uniformly varying depth of 5.0 m to the origin of the first stereo-rig. Then, noises with a mean of 0.5 pixel were added to the measurement in the camera frame. Outliers were added by randomly projecting the points into a false camera center.
Comparisons were given by the standard RANSAC scheme with different settings. They were the RANSAC-100 and RANSAC-1000 which will stop when reaching the maximal iteration of 100 and 1000. We also included the result obtained from the RANSAC-optimum with known inliers, which only samples in the inlier group and presents the optimum result that the RANSAC can achieve for a certain outlier level. The termination criteria were identical for the SASAC and the comparisons.
We ran 1000 random experiments with outlier levels of 10%–80% to evaluate each algorithm. The rotation errors were expressed in terms of the axis-angle representation of the difference between the ground truth and the estimated rotation. The translation errors were expressed as the difference of the ground truth and estimated translation with scale. To compare the performance of the sample and consensus scheme, the result came from the P3P algorithm directly, and no further nonlinear refinement was performed.
The mean error in rotation and translation are shown in Figure 4(a) and (b). As the results show, in both rotation and translation estimations, our SASAC solution outperforms the RANSAC-100 solution when the outlier ratio reaches 60%. With outlier ratios larger than 60%, the large estimation errors in RANSAC-100 indicate that after 100 iterations, the random sampling process could not promise to find one outlier-free sample set. To achieve comparable results with SASAC, the RANSAC scheme requires 1000 iterations, which is exhaustive in computation.

The performance of each algorithm is evaluated with outlier ratio from 10% to 80%. (RANSAC-100) and (RANSAC-1000) denotes the standard RANSAC with maximal iteration of 100 and 1000. (RANSAC-optimum) presents the RANSAC samples in the inlier group. SASAC is the method we proposed in this article: (a) mean error in rotation, (b) mean error in translation, (c) the success estimation rate, and (d) required interaction.
Our SASAC maintains a mean rotation error of 0.0024 rad with the outlier ratio varying from 10% to 70%, and this result is close to the optimum of the RANSAC algorithm. However, when the outlier ratio approaches 80%, our algorithm occasionally fails because all the features happen to be outliers after the 3D bucketing. Theoretically, this failure rate is lower than 1% if we sample 20 cubes in the 3Dbucketing, whereas the theoretical failure rate of the RANSAC-100 and RANSAC-1000 are 85.2% and 20.16% in the 80% outlier ratio case, respectively.
To further analyze the successful estimation rate, we calculate the successful estimation over the 1000 simulations and show the results in Figure 4(c). The experiment results match the theoretical analysis that the RANSAC-100 cannot robustly estimate the motion with outlier levels larger than 50%. Both RANSAC-1000 and SASAC can robustly estimate the motion with outlier levels ranging from 10% to 70%; however, when the outlier level reaches 80%, our SASAC is still able to robustly estimate motion with the successful estimation rate of 97%, while the rate of RANSAC-1000 is 86.8%. As this experiment shows, the SASAC is more robust than the RANSAC-based methods, when the data is contaminated with high-ratio outliers.
Since the performance of RANSAC-1000 is comparable to SASAC, it is indispensable to analyze the computation efficiency of these algorithms. The non-randomness threshold
Real data evaluation
To further evaluate the performance in the real-world scenario, we installed sensors, computer hardwares and actuators on a prototype mobile platform for data collection. As shown in Figure 5, the platform was built on an unmanned electric vehicle platform. Considering the low light condition underground, two high-intensity LEDs were mounted on the front providing additional illumination. For the vision sensors, the platform has a stereo camera rig that consists of two rigidly mounted digital cameras.

The data collection platform designed for underground and indoor data collection.
These two cameras were simultaneously triggered by the interval signal from the control unit at a frequency of 2 Hz. Before the data collection, the stereo camera system was calibrated, and the images were rectified according to the calibration results.
The dataset was collected in an underground garage because this environment is inevitable for driving cars in the urban scenario but challenging for the motion estimation because of the limited illumination and repetitive artificial structures. Since the GPS does not work underground, we collected ground truth with vision marks instead. Firstly, vision marks were tagged on the walls in the garage, and their 3D position were measured with total stations. Then we ran a structure-from-motion (SFM) program with these accurately measured 3D points, and obtain the camera poses from the SFM results. To confirm the accuracy of the camera poses, we measured some other 3D points with total station and projected them into the image coordinate according to the camera poses. The mean re-projection error is less than 1 pixel, so these camera poses are qualified in accuracy to be refered as the ground truth. According to our review, no similar open access underground dataset with ground truth was found, and we would like to make this dataset available to the community.
Then, the performance of the SASAC was evaluated with this underground garage dataset. For further analyses, it was also evaluated with the ground dataset from KITTI. 16 For experimental comparison, we configured our SASAC to compare the performance against the following:
RANSAC: The standard RANSAC algorithm, 11 which denotes the baseline for comparison.
GroupSAC: Efficient variant of the RANSAC with the grouping process, which uses progressive numbers of groups to boost the sampling procedure. 23 In the experiment, we employ the widely used graph-based model 32 to segment the image and group the features.
PROSAC: RANSAC with nonuniform sampling based on decent ordering data by feature-matching quality, which provides an efficient sampling process. 21
In all the real data experiments, our SASAC implementation followed the Algorithm 4, and we only changed the preprocessing strategy for the comparisons and maintained the other process same for all the algorithms. For GroupSAC, we ran the segmentation algorithm and grouped the features according to the segmentation results. For the PROSAC, the features were decent ranked with their matching score. Since the true inlier ratios (along with the ground truth inliers) were unknown for the experimental data, we first set up
First, the evaluation was performed with the underground datasets, and the results are tabulated in Cases A–C in Table 1. The outlier ratios were 58.8%–76% in the dataset, which becomes a challenging dataset for robust estimation algorithms. The table lists the number of features, the ground truth inliers, the detected inliers, the motion estimation error (in millimeter), number of iterations and the total runtime (in milliseconds). The detected inliers from SASAC are shown in the image in the first column. As the results show, the SASAC consistently produces accurate solutions with successfully detected inliers, while maintaining almost the lowest runtime. Although the standard RANSAC can estimate the motion with a low inlier ratio in the experiment, the algorithm requires 369–990 iterations to obtain the exact result, which is costly in computation. Particularly in Case B, where the outlier ratio reaches 76%, RANSAC requires 990 iterations and costs 873 milliseconds to pick out the inliers and estimate the motion, whereas our SASAC requires 80 iterations, which is magnitude fewer than the RANSAC. For the PROSAC, which is faster than the RANSAC, but the accuracy is worse than those of the other methods. This difference is mainly because of the points sampled by PROSAC are often poorly distributed in the space, and the highest ranking points are typically spatially very close to one another, which generates degenerate solutions. In SASAC, this effect is mitigated by our 3D-bucketing strategy, which incurs a small additional computational cost but provides a much more uniformly distributed dataset. Another reason is that the quality score used by PROSAC is actually point-wise evidence, whereas the structure features used by SASAC reveals the correlation between the rigid structure and is shown to provide a stronger evidence. We also find that in our experiment, matching features with high quality scores are not guaranteed to be inliers because of the repetitive textures, but the structure features selected by SASAC do belong to inlier feature group.
Results for inlier detection and motion estimation in underground and ground dataset.

The table lists the number of correspondences (
In some cases, the GroupSAC requires fewer number of iterations, and the overall performance is comparable with SASAC, but applying segmentation as preprocessing is too costly in computation, which makes the GroupSAC the most computationally expensive algorithm among the comparisons. In addition, in case C, when there is a non-rigid moving object, the GroupSAC takes samples from the moving object group and the results are less accurate. In this case, the SASAC begins sampling with the static structure features and easily abandons those non-rigid moving features.
For the overall performance with the underground dataset, the RANSAC and GroupSAC algorithms estimate the motion in a computationally expensive manner, whereas the SASAC achieves comparable results at a small fraction of the computational cost. Compared with the PROSAC, the SASAC uncovers stronger evidence of the features, which leads to a more accurate and robust result. Although it improves the performance, SASAC only acquires a small additional computational cost, which makes our SASAC more suitable for indoor applications with limited computation resources.
We also evaluated the performance with the ground KITTI dataset 16 in cases D and E. Since the matching quality becomes better in the ground case, all the algorithms work well in this situation. The results show that the SASAC also reduces the sampling iteration; however, considering the preprocessing, the running time is nearly the same as that of the RANSAC. The PROSAC performs slightly better than the SASAC in the efficiency since the quality score is more significant in the ground scenario. As shown in case D with a moving car in the image, SASAC can eliminate the features from the moving object and deliver an accurate result. However, when the moving object becomes larger, for example, a moving truck, our structure feature detection algorithm may wrongly defines the moving object feature as the structure feature. This is mainly because the structure feature detection algorithm select the largest subset of features that are consistent with the rigidity constraint. In the case of large rigid moving object, the features from the rigid moving object satisfy the Euclidean rigidity constraint and form a subset of rigid features, when this subset becomes larger than the static feature subset, our algorithm considers the moving object feature subset as the structure feature.
Then, the RANSAC PROSAC GroupSAC and SASAC were integrated into a vision-based VO scheme, and their position accuracies are evaluated with both underground and ground datasets. The integrated VO algorithm is based on the LIBVISO2, 33 and we maintained the maximal iteration at 200 which is the default setting in LIBVISO2. The VO results in the underground are shown in traces in Figure 6(a)–(c). As the results show, in the underground dataset, the SASAC achieves a better position accuracy than the RANSAC, PROSAC, and GroupSAC.

Performances of RANSAC, PROSAC, GroupSAC, and SASAC in VO algorithm. The ground truth in the underground is obtained by the total station, and the KITTI data ground truth is measured by the GPS and IMU. (a) Visual odometry results of the undergorund dataset lap 1, (b) visual odometry results of the undergorund dataset lap 2, (c) visual odometry results of the undergorund dataset lap 3 and (d) visual odometry results of the KITTI dataset.
During the experiment, we further discover that the top-ranked features in PROSAC often lie on the same surface in the scenario. Particularly when there is a large portion of plane structure in the center of the image, all sampled features in PROSAC are all from this plane, which generates a degenerate solution and affects the position accuracy. For the RANSAC-based VO, the RANSAC algorithm sometimes fails to elect the correct model and causes a motion estimation failure. When the failure occurs, the VO algorithm assumes that there is a linear movement and takes the motion parameter from the last frame. Thus, the overall performance of RANSAC is less accurate than SASAC. With correct segmentation, the GroupSAC achieves a comparable result as the SASAC; however, it requires magnitude more time for computation.
For the ground dataset, these algorithms achieved comparable results. The numerical analysis is performed with the same evaluation metrics as KITTI, 16 and the results are shown in Table 2. A comparison of the position accuracy in the ground and underground scenarios shows that the SASAC and GroupSAC maintain the same level of position performance in both scenarios, whereas the RANSAC and PROSAC show a lower accuracy in the underground scenario. Although the GroupSAC is accurate in both scenarios, it is too slow for the real-world applications. Thus, the VO results show that by integrating SASAC, the standard stereo-VO algorithm can be applied to the underground with the same level of position accuracy and computation cost as in the ground scenario.
Position accuracy of RANSAC, PROSAC and SASAC.

SASAC: structure-aware sample consensus; RANSAC: random sample consensus; PROSAC: progressive sample consensus.
The position accuracy is evaluated by averaging the relative position error at fixed distance.
Conclusion and discussion
In this article, we have designed a robust structure-aware sample scheme to solve the stereo-VO problem in an underground environment. To robustly estimate the motion, we use the Euclidean rigidity constraint to detect a group of structure features and then guide the sampling process with these features. Compared with the existing methods, our method can robustly estimate the motion in the underground scenarios, which usually suffers from high outlier ratio effects. The performance of the SASAC and the comparisons are evaluated in both synthetic data and real-world data. The underground experiment results show that our method has advantages in robustness, accuracy and efficiency compared with the RANSAC and its variants. The SASAC-based VO algorithm achieves the same level of positioning accuracy in both ground and underground scenarios. As a second contribution of this work, we have collected an underground garage dataset with the ground truth. Since there are fewer open underground datasets than the ground datasets, we would like to make our datasets available to the community for further research (https://github.com/lizhengning/Underground-Garage-Dataset).
In this study, the definition and detection of structure features is derived pure geometrically, and in some situation, for example, with large moving object, it may wrongly select a subset as the structure feature. Besides the scope of this study is limited in the stereo-camera case, since the depth should be recovered before structure feature detection. Therefore, we will focus on discovering more high-level and applicable clue about the structure features in the future work. With the recent development of deep learning, we believe that the clue of the structure feature can be learned by a deep neural network in training procedure. And in inference procedure, the trained network can efficiently divide the the structure features. Combining the learning-based structure feature selection method, the SASAC scheme can be applied in more VO applications, for example, monocular VO.
Footnotes
Handling Editor: Haosheng Huang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key Research and Development Program of China (grant nos 2016YFB0502102 and 2016YFB0502104), Natural Science Foundation of China (grant nos 41771481 and 41371333) and Shanghai International Corporation Program (grant no. 14530722400).