
Abstract
Due to the combination of constrained power, low duty cycle, and high mobility, neighbor discovery is one of the most challenging problems in wireless sensor networks. Existing discovery designs can be divided into two types: pairwise-based and group-based. The former schemes suffer from high discovery delay, while the latter ones accelerate the discovery process but incur too much energy overhead, far from practical. In this article, we propose a novel efficient group-based discovery method based on relative distance, which makes a delicate trade-off between discovery delay and energy consumption. Instead of directly referring to the wake-up schedules of a whole group of nodes, efficient group-based discovery selectively recommends nodes that are most likely to be neighbors, in which the probability is calculated based on the nodes’ relative distance. Moreover, the sequence of received signal strengths are employed to estimate the relative distance for avoiding the effect of the node distribution. Extensive simulations are conducted to verify the effectiveness of the design. The results indicate that efficient group-based discovery statistically achieves a good trade-off between energy cost and discovery latency. Efficient group-based discovery also shows one order of magnitude reduction in discovery delay with a maximum of 6.5% increase in energy consumption compared with typical discovery methods.
Introduction
Wireless sensor networks (WSNs) are promising technologies that can be widely applied to many fields, 1 such as emergency rescue, biological detection, environmental measurement, and real-time monitoring. 2 Due to the energy constraints of nodes, the low duty-cycle mechanism is often adopted in WSNs, which saves the energy by listening briefly and shutting down radio most of the time. Such a mechanism makes it difficult for nodes to discover their neighbors because nodes have to listen the channel in an asynchronous manner. The problem will become even more challenging if nodes are mobile in the network.
Neighbor discovery in low duty-cycle WSNs has attracted extensive research attention. In such networks, each node periodically wakes up and sleeps. If nodes are within the communication range of each other, then they can communicate, such that a neighbor discovery is completed. Currently, there exist two types of discovery methods: pairwise-based and group-based. The pairwise discovery algorithms are achieved only when two nodes are simultaneously pre-scheduled to wake up. In group-based discovery methods, nodes can share their known schedules with each other, and the discovery process is a proactive and fast manner with energy overhead. In other words, traditional pairwise discovery algorithms focus on reducing energy consumption, while group-based discovery methods reduce discovery delay with increased energy consumption. The aforementioned algorithms don’t make a good trade-off between energy consumption and discovery delay, which are not suitable for practical applications. Thus, the need for a novel neighbor discovery method arises.
Facing the requirements mentioned above, we propose a relative distance based on group discovery scheme for leveraging the schedule reference mechanism such that the speed of neighbor discovery can be accelerated. Our relative distance design is motivated by calculating neighbor probability by means of the number of common neighbors two nodes have, which may underutilize the mobility of node. Although received signal strength (RSS) is not a good choice for physical distance estimation in many scenarios, 3 it does provide certain useful distance-related information in addition to indicating connectivity among neighboring nodes. Subsequently, we can determine the near–far relationship between two nodes and dynamically adjust duty cycle according to neighbor probability. Technically, the key novelty of efficient group-based discovery (EGD) is that it leverages knowledge in the neighbor tables of known neighbors to accelerate discovery of unknown neighbors, while effectively avoiding excessive reference operations.
The main contributions of our work are as follows:
Most of the previous works focus on scheduling designs for pairwise discovery with high discovery delay. We propose the EGD based on relative distance, which can reduce discovery delay with small overhead.
Using relative distance to indicate the proximity between two neighboring nodes, we can adjust the duty cycle such that the neighbor discovery efficiency can be improved and the discovery delay can be reduced.
The performance of the proposed design is evaluated by extensive simulation studies. The results show that EGD achieves better trade-off between discovery delay and energy consumption compared with existing works.
The remainder of this article is organized as follows: the related works are briefly discussed in “Related work,” while section “Network model” introduces the network model. The main design and theoretical analysis are described in section “System design.” The simulation results are presented in section “Evaluation.” Finally, section “Conclusion” concludes the whole article.
Related work
As a critical component of WSNs, neighbor discovery is a protocol that allows different nodes on the same link to advertise their existence to neighbors and learn about the existence of neighbors. Neighbor discovery algorithms of WSNs in low duty cycle have been studied, 4 and many results have been found. Typical low-duty-cycle neighbor discovery algorithms can be categorized into one of the following two classes: pairwise-based5–14 and group-based.15,16 In pairwise-based discovery algorithms, we can further divide into three types: stochastic-based protocols,5,6 quorum-based protocols,7–11 and deterministic protocols.12–14
Stochastic-based protocols, such as Birthday protocol, 17 set listening, transmitting, or sleeping in three states for sensor nodes. The probability principle of the birthday paradox guarantees that neighbor nodes can be found in a continuous time slot with high probability. However, the worst-case discovery latency cannot be guaranteed owing to the probabilistic characteristic of algorithm, 18 thereby causing a long tail on discovery probabilities over time.
Quorum-based protocols7–11 address unbounded discovery latency issues by ensuring overlapping active durations between pairwise nodes within a bounded time. These schemes construct
Deterministic protocols have been recently proposed to support asymmetric duty-cycle patterns and handle the global parameter problem, as these schemes allow sensor nodes to select one or multiple prime numbers to present its duty cycle. Disco 12 presents a new neighbor discovery method based on the Chinese Remainder Theorem. 21 In this protocol, each node chooses a pair of dissimilar primes, such that the sum of their reciprocals is equal to the desired radio duty cycle. Disco achieves discovery faster than quorum-based protocols for a given duty cycle, allows nodes to independently select their own duty cycle, and offers a provable upper bound on discovery latency. U-Connect 13 proposes a unified solution to the neighbor discovery problem, and this approach addresses the symmetric and asymmetric asynchronous neighbor discovery problems. U-Connect also presents the power-latency product metric and uses this metric to measure the performance of the system.
Group-based neighbor discovery proposes a selective reference mechanism based on spatiotemporal properties of neighborhood to significantly reduce discovery delay by proactively referring wake-up schedules among a group of nodes. 15 Nevertheless, only a small number of known schedules exist in the initialization phase of group formation. Nodes therefore cannot proactively wake up in time to verify the neighbor nodes, thereby leading to long discovery latency. An improved group-based neighbor discovery algorithm dynamically adjusts the active time of nodes by fully extracting the spatial properties, and it avoids unnecessary references. 16 The position distribution of nodes in some scenarios can be obtained or estimated in advance; thus, authors estimate the total number of nodes in a certain area to adjust the active time of these nodes.
Although neighbor discovery algorithms present good results and excellent performance, their energy efficiency can still be further improved and investigated.22,23 Given that they are not making good performance trade-offs, EGD presents the design of relative distance between neighboring nodes from their RSS orderings, which can effectively reflect the distance between two nodes. This unique design effectively reduces the reference overhead of the referring nodes.
Network model
We first define the network model and then generalize the assumptions on mobile sensor network such that nodes can discover each other without any infrastructure support in low-duty-cycle WSNs.
We assume that nodes are distributed with identical disk-shaped communication range. If a node is always in an active state, then the frequency transceiver of the node is in the state of listening. Supposing that the node does not receive any packets, the node can be in an idle listening.24,25 In particular, no information exists for broadcasting or transmission. Idle listening consumes a large amount of unnecessary energy. Thus, a node remains dormant most of the time at more than 95% and be in active state only briefly to sense and communicate. During the entire discovery process, the working status of sensor nodes is constantly switching between the active and dormant states with low-energy consumption. In the active state, a node can broadcast a packet and receive packets sent by neighbors, while the node turns off the module of receiving packets except for transmitting a packet in the dormant state. This way can effectively reduce the energy consumption of nodes, thereby prolonging the lifetime of nodes and the network. 26 According to the Chinese Remainder Theorem, every node selects two different primes to solve the issue of two nodes of the same prime. Consequently, the actual duty cycle is equal to the sum of two reciprocal prime numbers. For convenience, we assume that a node chooses one prime to present the duty cycle of this node. The maximal discovery latency between two nodes is equal to the product of two prime numbers chosen by the two nodes, and wake-up time slots of the two nodes will periodically or partially overlap. Thus, it ensures that any two nodes in a physical connection state can find each other in a certain time.
An example of a discovery process is shown in Figure 1. For arranging the working schedule of nodes, the working schedule of a mobile node is divided into continuous fixed length time slots in active or dormant state. The prime of node

Network model.
The hypotheses of the network model are as follows:
All sensor nodes have a unique ID number and a local counter based on time slot
Nodes are assumed to have the same transmission energy and channel frequency, and the communication coverage radius of the node is presumed consistent.
The switching energy consumption between different states is assumed to be small; thus, we can ignore the energy consumed by node state switching.
When nodes have common wake-up time slots and lie in each communication range, they can discover each other.
System design
We introduce our detailed design for acceleration of neighbor discovery in mobile applications.
Schedule reference mechanism of group-based discovery
For legacy pairwise discovery methods, neighbor discovery is passively achieved when two nodes are pre-scheduled to wake up at the same time and two nodes are all within the communication range of each other. Pairwise discovery methods focus on a pair of nodes. Different from pairwise discovery methods, nodes in group-based discovery actively share the working schedule of their existing neighbors with new node that they have recently discovered. Consequently, the newly discovered node can quickly become aware of the time scheduling of its surrounding nodes and actively verify whether it can communicate with those nodes at their wake-up time.
The principle of the schedule reference mechanism is simple. In the initialization phase of group formation, no node has one neighbor and knows the working schedule of its neighbor. Similar to pairwise discovery algorithms, the node is periodically switched between the active and dormant states according to its own working schedule. In the active state, sensor nodes can broadcast and receive messages sent by neighbors; meanwhile, the sensor nodes will turn off the broadcasting and receiving functions in the dormant state. When two nodes are in the active state and within the communication range of each other, they can discover each other and form a group. For example, when the third and first nodes wake up simultaneously according to their working schedule, the third node finds the first node and adds the first node to its neighbor table. Then, the first node will share its known neighbors (i.e. the second node) with the third node. The third node has been informed of the working schedule of the second node through the first node. Accordingly, the wake-up time of the third and second nodes becomes synchronous. In this condition, the third node proactively wakes up to determine whether the second node is the neighbor node. If yes, then they add each other to the neighbor table and form a larger group than before. This group of neighbor nodes then constantly expands, thereby completing the discovery of neighbor nodes.
Figure 2 shows the group-based discovery process. We consider sensor network with
At time
At time
At time 12, node

Group-based discovery process.
Schedule reference mechanism speeds up the discovery process by proactively referring working schedules among a group of nodes. The acceleration is mainly implemented from a temporal perspective. Node
Design: relative distance estimation
We present the main idea of calculating relative distance among neighboring nodes. Many existing methods only directly use RSS to estimate physical distance in several scenarios. Without loss of generality, we can evaluate the distance between objects
A simple example is shown in Figure 3 for ease of expression. In this example, the problem is to evaluate the distance between objects
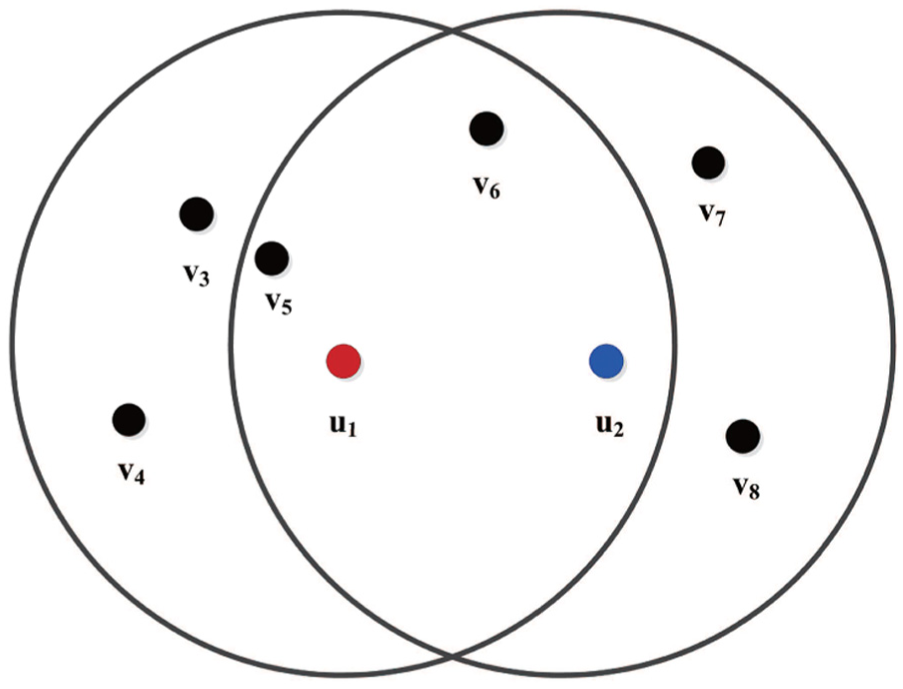
Example of evaluating the distance between two nodes.
RSS values from all their neighbors.

The neighbor pairs of objects
On the basis of the above-mentioned classification and explanation, we can evaluate and quantify the relative distance between objects
The relative distance between two neighboring nodes is equal to the ratio between the number of discordant pairs and the number of effective neighbor pairs, that is

where
Taking objects
Neighbor node recommendation using relative distance
We introduce an algorithm combining the above method and relative distance for computing the probability that the neighboring nodes
From equation (1), we obtain the relative distance


Neighbor probability of nodes
The neighbor probability of nodes

Combining the above two assumptions,
15
we can obtain the formula to present the probability of the two neighbor nodes
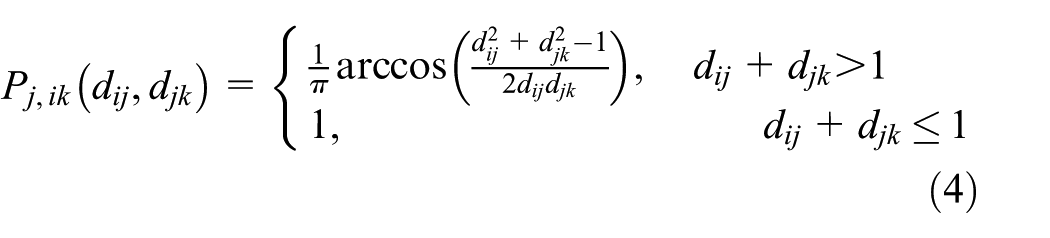
Our work presents a different design to calculate neighbor probability. By setting different threshold values for
Qualitative comparison: EGD versus Disco
EGD is a protocol based on schedule reference mechanism, in which nodes actively share the working schedule of their neighbors. In this scenario, upon discovering a new node, members of the group would gossip about their own neighbors with the new node, which would help the new node discover its neighbors more quickly. In other words, EGD usually has shorter discovery latency than Disco. In the following, we quantitatively compare the difference of discovery delay between EGD and Disco.
For Disco, it ensures that a pair of neighboring nodes

Then for Disco, the probability distribution function for node

where
For EGD, the probability distribution function of a new node

where
After node
Evaluation
Simulation setup
In the simulation, mobile nodes are distributed in an area of
Parameters of simulation environment.

Performance evaluation
To evaluate the system performance under different number of nodes, node velocities, and radio irregularities, we mainly use three metrics, namely, discovery probability, discovery delay, and energy consumption.
Effect of the number of nodes on system performance
The first set of simulation aims to study the effect of the number of sensor nodes on the system performance. Figure 5(a) shows that, as the number of nodes increases, the discovery delay of group-based discovery and EGD decreases whereas that of Disco increases. The reason is that group-based discovery and EGD profit from the increase in number of nodes as a large number of working schedules are shared among neighbor nodes. For the same reason, the discovery probability of group-based discovery and EGD steadily increases whereas that of Disco decreases as number of nodes increases (see Figure 5(b)). As shown in Figure 5(c), when number of nodes increases, the energy consumption of the three methods increases. More nodes means a large number of nodes proactively wake up to verify the recommended nodes. The trend of the numerical value reflects that the energy consumption of EGD is obviously lower than that of group-based discovery but significantly higher than that of Disco. Nevertheless, EGD can save more energy than group-based discovery under the same number of nodes. For example, with 91 nodes, EGD obtains a 5.72% higher discovery delay with a 20.25% lower energy consumption compared with advanced group design.

Effect of the number of nodes: (a) number of nodes versus discovery delay, (b) number of nodes versus probability, and (c) number of nodes versus energy consumption.
Effect of average node velocity on system performance
Velocity of nodes has significant effects on the system performance in mobile sensor networks. 28 Hence, the second simulation attempts to investigate the influence of the average velocity on the system performance. Figure 6(a) and (b) shows that the discovery probability and discovery delay of the three designs decrease as node velocity increases. This result is attributed to the duration that two nodes are physically within the communication range of each other and shortens when node velocity increases. Consequently, the discovery delay of the three designs decreases. With the increase in velocity, the number of common neighbor nodes of EGD changes faster than that of group-based discovery. Therefore, the discovery delay of EGD is significantly higher than that of group-based discovery. Figure 6(c) shows that the energy consumption of the three algorithms increases with the increase in node velocity. The energy loss of Disco and EGD design remains stable whereas that of group-based discovery significantly increases with increasing node velocity. This result is due to the fact that EGD discards considerable useless reference information as nodes move far from the group. At about 2 m/s, the discovery delay for EGD is about 1.15 times higher than advanced group discovery, while the discovery probability is about 30.84% shorter. Additionally, the energy consumption for EGD is about 20.98% shorter than advanced group discovery. In general, EGD achieves good energy-delay trade-off.
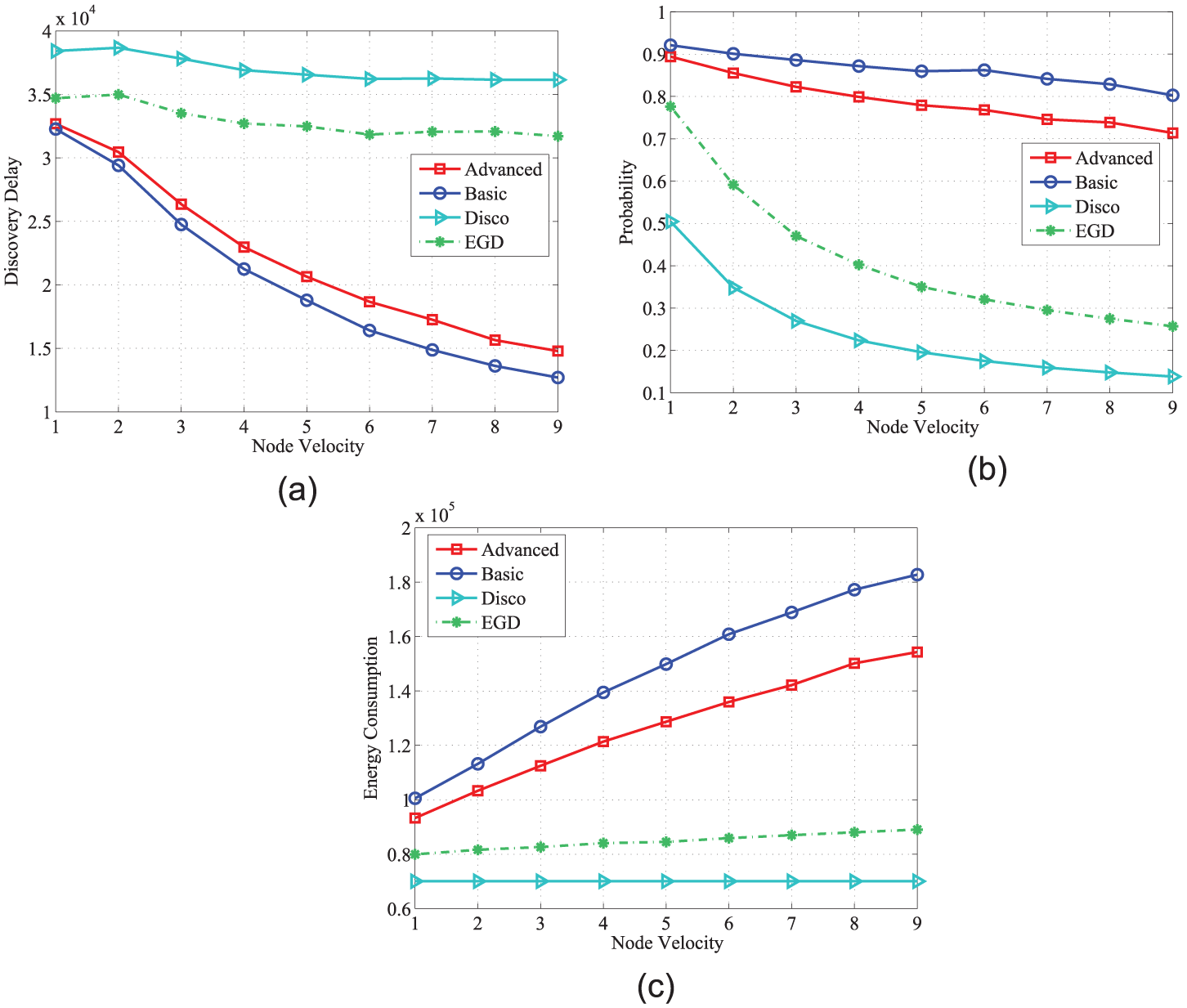
Effect of average node velocities: (a) node velocity versus discovery delay, (b) node velocity versus probability, and (c) node velocity versus energy consumption.
Effect of radio irregularity on system performance
For convenience of description, we assume that the communication radius of node is a unit disk. We then study the effect of radio range irregularity on the system performance. 29 In the simulation, the radio range irregularity of node broadcast changes from 0% to 90%. Radio range irregularity is defined as the maximum range variation per unit degree change in the direction of radio propagation. When radio range irregularity is 90%, the communication range of a node can belong to any value between 10 and 100 m.
Figure 7(a) shows that the discovery delay of all the three schemes increases with the increase in degree of radio irregularity. However, the discovery delay of Disco is higher than that of group-based discovery and EGD. The reason is that, when a referring message in group-based discovery and EGD is lost, other referring messages informed by neighbor nodes in a short period still exist. However, for Disco, nodes have to wait for the next wake-up slots to discover neighbor nodes.

Effect of radio range irregularity: (a) radio irregularity versus discovery delay, (b) radio irregularity versus probability, and (c) radio irregularity versus energy consumption.
As shown in Figure 7(b), the discovery probability of the three discovery methods decreases as the degree of radio irregularity increases. This result is due to the fact that such increase decreases the accuracy of neighbor estimation using a fixed communication radio between two nodes. Regarding energy consumption, Figure 7(c) shows that the energy consumption of group-based discovery and EGD decreases whereas that of Disco remains stable when the degree of radio irregularity increases. Compared with group-based discovery, EGD has a few redundant reference messages; hence, its energy loss is significantly lower than that of group-based discovery. The simulation results prove that EGD can achieve good results in reducing energy consumption while improving discovery probability.
Evaluation of designs
Energy efficiency and low discovery latency are the key metrics involved in evaluating neighbor discovery protocols in the context of mobile sensor networks. In order to perform a holistic evaluation of EGD and Disco, we consider the power-latency (

The power-latency product has been widely adopted to evaluate many neighbor discovery algorithms like Quorum, 7 Disco, 12 and U-connect. 13 . Similar to these classical works, we adopt the above metric to evaluate the performance.
Figure 8(a)–(c) shows that EGD improves the system performance with small overhead compared with Disco. When the number of nodes is 104, the value of

Comparison with Disco: (a) number of nodes versus power-latency product, (b) node velocity versus power-latency product, and (c) radio irregularity versus power-latency product.
Evaluation of node distribution
In order to investigate the impact of different node distributions, in Figure 9, we show the system performance under both uniform node distribution (random waypoint mobility model) and nonuniform node distribution (hotspot mobility model). For hotspot mobility model, it mimics the behavior of people moving from a point of interest to another and stopping for a certain time at each point of interest before moving to the next one.

Impact of node distribution on system performance.
Evaluation of recommended probability thresholds
EGD and advanced group discovery accelerate the discovery process by proactively referring working schedules among a group of nodes. We study the recommended success rate of these nodes under different recommended probability thresholds. Threshold reflects how many neighbors are required to be recommended. A high value of threshold indicates a large number of neighbor nodes need to be recommended. However, this condition does not mean the recommended success rate is high, as not all recommended nodes are neighbors of referring nodes. Thus, studying the recommended success rate in group discovery algorithms is necessary.
In low-power mobile sensor networks,
30
one node recommends all its neighbor nodes to the newly found neighbor node; however, recommended nodes are not all neighbors to the new node. Therefore, we use the recommended success rate

where

Recommended success rate under different thresholds.
Conclusion
In this article, we introduce EGD, a novel scheme based on group discovery schemes for the acceleration of neighbor discovery process. The key insight into accelerating the discovery process is that known neighbors can help a node learn unknown neighbors indirectly by schedule reference mechanism. To avoid energy overhead caused by redundant reference messages, neighbor probability calculated by relative distance enables nodes to adjust their own duty cycle with more accurate value. We design the relative distance on the basis of RSS ordering instead of directly mapping the RSS values to distances. Numerous simulations proved that EGD method improves recommended accuracy and further increases energy efficiency.
Footnotes
Academic Editor: Miltiadis Lytras
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported, in part, by the Fundamental Research Funds for the Central Universities (Grant No. 2017XKQY080).