
Abstract
Distributed geographic information system is a typical service-intensive application which has to store massive data in lots of storages and server for a large number of users. Due to the slow network input/output, replicas can be used to improve system performance. Since all data have the relationships of long-term stability as well as short-term bursty, a comprehensive method which considers not only static replicas and its placement strategy but also dynamic replicas and its selection strategy can achieve more significant improvements and are proposed in this article. First, a general dynamic correlation representation model of all data is designed and implemented. And then replica selection strategies for static copies and dynamic copies are proposed based on their relationships. Also, a comprehensive data placement strategy for all data and all replicas is defined to realize load balance. Finally, the performance of the proposed method has been proved through a series of comparative experiments, and the simulation results demonstrate that the proposed algorithm can meet the requirements of distributed geographic information system in all aspects, including different dataset, different access modes, and different data scales and can achieve an average local storage hit ratio of about 11.55%–45.22% higher than the other methods.
Keywords
Introduction
As a typical data-intensive services’ system, 1 geographic information system (GIS) has been widely used in all kinds of fields, especially in land and resources’ investigation, weather forecast and disaster prediction, and urban and road traffic planning. 2 Due to the massive datasets which have to be stored in all storage nodes of GIS as well as a large number of users who will access all data stored in GIS by network, distributed GIS is an important solution which can be used to provide such services, and in which the data are split into amount of smaller pieces (or chunks) based on the pyramid model and each piece is stored as a single file in a single node or some nodes as replicas and those pieces are called tiles 3 such as Google Earth. Replication strategies, as a kind of typical information service technologies which are widely used in lots of information systems, 4 can also be used by distributed GIS to ensure data availability and data security and improve the performance of the quality of service (QoS) for distributed GIS.
On one hand, replication strategies can be used to ensure data security in most of the storage system which distributed all stored data and their replicas in different storage nodes to realize data loss prevention (DLP). 5 Reliable checkpoint storage strategy (RCSS) proposed a replication method to realize reliability, availability, and QoS or cloud computational grids by replicating all checkpoints. 6 RCSS considers the efficiencies not only for data storage but also for data recovery when certain computing nodes fail. Proactive replica checking for reliability (PRCR) 7 and multi-objective optimized replication management (MORM) 8 are the other two methods which are always used by cloud storage system. PRCR provided a kind of cost-effective data reliability management mechanism to ensure reliability of the massive cloud data with minimum replication, and MORM considered much more factors influencing replication strategy and optimized its strategy using an improved artificial immune algorithm. Meanwhile, bandwidth-availability-based (BAB) proposed a replication algorithm to realize bandwidth availability in peer-to-peer (P2P) system, 9 and energy-effective adaptive replication strategy (E2ARS) is mainly to save energies for cloud storage by switching and using different storage nodes.
On the other hand, due to the slow disk input/output (I/O) speed as well as the slow network I/O speed or the variable network connectivity, replication strategy can also be used to speed up the response time for users and improve the QoS in information system. In this case, replication strategy will select part of data and then store them in different storage nodes which can offer high bandwidth service or simply keep them in high-speed cache to provide quick response to users. Cluster-based replication placement (CBRP) 10 designed fixed data replica as well as temporary data replica to improve the performance of load balance. CBRP finds the critical value of triggering replication strategy by computing the historical access frequency of replicas and then it predicts the number of access requests for the next period of time to decide and change the number of predicts. Bandwidth hierarchy replication (BHR) and a modified version of BHR (MBHR) 11 proposed similar methods to minimize the access cost as well as utilize network and storage resources as expeditiously as possible. BHR and MBHR select the best node with the highest access frequency to store replica so as to reduce the access data from remote websites. Replication strategy based on correlated patterns (RSCPs) mined the data access patterns by computing their correlations in data grids and then decentralized replicas to improve response time, reduce the bandwidth consumption, and maintain reliability. 12
Furthermore, Hamrouni et al.13,14 give some detailed introductions and summary about data replication and replica selection (RS) strategies in data grids, and the results show that the replication strategy not only has to consider the selection of appropriate data as the replicas due to their high access frequencies but also has to find the best locations to store data due to the different network I/O speed; 15 the first strategy is called as RS strategy and the second one is called as replica placement (RP) strategy. Thus, the key to replication strategy is to select appropriate data based on RS strategy and then store them in appropriate storage nodes or high-speed cache based on RP strategy to provide quick response to users’ access which will be discussed in related works.
This article is organized as follows. Section “Related works” introduces the related works about RS strategies and RP strategies. A brand-new combination replication strategy for data-intensive services based on both data’s characteristics and storage nodes’ capabilities is presented in section “Combination replication strategy.” The results of the experiments are presented and discussed in section “Simulations and experiments.” Finally, section “Conclusion and future works” shows a conclusion of this article and discusses our next works in the future.
Related works
Selecting appropriate data as replicas for RS is to find the most suitable subset of data which will be used by applications repeatedly and simultaneously. As an algorithm similar to RS, prefetching strategy is also designed to find some appropriate data in advance based on applications’ requirements which is always used in distributed GIS, such as Google, 16 networked geographic information systems (NGISs), 17 and NASA 18 and have deeply improved system performance.
Hilbert curve–based prefetching (HCBP) is a typical prefetching algorithm which uses several prefetch strategies, such as the Hilbert curve strategy, to predict application’s next requirement assuming that users’ access behavior to geospatial data has spatial locality. 19 Retrospective adaptive prefetch (RAP) is another prefetching algorithm which predicts application’s next possible requirements using a heuristic method and then selects its corresponding data as a caching replica. 20 Also, RAP is based on some assumptions, such as stable applications’ behaviors, which show that the application’s behavior will not change in a short period, and otherwise RAP will start a brand-new process. Another kind of famous method is Markov chain model which constructed a Markov chain model by setting recently accessed data as an initial status and the access probability of its all neighboring data as the state transition matrix. Examples of such algorithms include basic Markov model, 21 prefetching based on previous k movements (PKM), 22 and Zipf–Markov model. 23 Basic Markov model used several kinds of Markov chain model to make prediction, such as denoting browser center or browsed data as the transfer status and even using high-order Markov model. PKM uses Markov chain to predict the next objects to prefetch by monitoring the previous k movements, and a graph named as “neighbor selection Markov chain” is used to help its predictions. Zipf–Markov model also uses Markov chain model to prefetch an optimum data by mining the characteristics of the user’s navigation path based on Zipf distribution.
However, all those methods mentioned above only considered the neighboring data based on their current status and cannot meet the requirements of the whole system (for load balance or quick response of whole system) and so can mainly be used for predicting single-user behavior. Thus, some researches are proposed to find the optimum choice among all data so as to meet the global requirements. Examples of such strategies include distributed high-speed caching based on spatial and temporal locality (DCST), 24 ordinary least squares (OLS), 25 artificial neural network (ANN), 26 and Zipf model. 27 Zipf model quantitatively analyzed the relationship between the total hit ratio and the size of cache buffer and then obtained an approximate formula to express this relationship based on their distribution parameter of basic Zipf’s law or Zipf-like law. Furthermore, DCST also uses this approximate formula to estimate the number of hot data which will be used repeatedly and then tally the popularities of all data so as to judge which data should be selected as replica based on the election scheme of the US Congress. OLS and ANN are another kind of global prediction methods which make predictions based on geographic features. OLS uses a linear combination of the geographic features and an OLS regression estimator to predict user’s next behaviors, and ANN uses ANN to train and obtain a prediction model and then uses the model to prefetch data. Meanwhile, spatial–temporal attribute prediction (STAP) is designed to prefetch spatiotemporal data for smart city system by analyzing the characteristics of historical access requests. 28
As another important aspect of replication strategy, placing replica (RP) into appropriate location is also been discussed. Dynamic computation correlation data placement (DCCP) 29 and access pattern–based distributed storage algorithm (APSA) 30 are two typical methods. DCCP distributed all stored data which have high dynamic computation correlations to the same data center considering not only the I/O load but also the capacity of data centers. One of the main aims of DCCP is to reduce data transfer rate among remote storage nodes and then to improve the performance of computations. Thus, the hot data will be stored in all storage nodes based on their relationships. APSA also distributed all stored data which have high access correlations to different data center so as to realize concurrent access, and similar to DCCP, all hot data stored are distributed to different nodes so as to balance the access service based on APSA.
Although the above-mentioned algorithms have achieved lots of good results in their own fields, there exist some disadvantages which still need to be further considered. On one hand, with the change in hot topics, some hot data which have high popularities will probably not be requested frequently in the future and so simply selecting those hot data as replicas cannot always meet the requirements of dynamic system. Meanwhile, fixed data distribution strategies can also not meet the dynamic requirements when the hotspot changed, and the large number of data migration among all storage nodes will deeply affect the performance of GIS to adjust data placement strategies synchronously. On the other hand, there exist some intrinsic laws31,32 which can be used to find the dynamic relationships among each other, and then their dynamic relationships can be used to predict which data will be requested repeatedly and which data will be requested simultaneously on the next step. 33
Based on the above analyses, our model which is called as a dynamic RS and RP strategy (DSP) will propose a new comprehensive method considering both RS and RP strategy where data’s dynamic popularities developed from a prefetching method 31 are computed and their dynamic relationships are mined based on their different historical access records. Then some data will be selected as static replicas and placed into storage nodes based on their long-term stable relationships, and some data will be selected as dynamic replicas and placed into high-speed cache buffer based on their short-term bursty relationships.
Combination replication strategy
Preliminary concepts
Although replication strategy can be used to solve the problems of data availability, data security, and system performance improvement, algorithm strategy will be completely different according to different aims. Thus, we will mainly focus our research on system performance improvement in this article and try to find all data’s intrinsic correlations so as to place data and their replicas into storage nodes or high-speed cache to improve users’ access performance.
Deeming that data correlations’ mining is the key step in our proposed strategy which will decide whether appropriate data can be found and appropriate locations can be used, data correlations should be well described and should accurately track the changes in data relationships. For this reason, we give the preliminary concepts used in data correlations’ mining and also give the strategy of processing the massive dataset in distributed GIS.
Hotspot data
The fact is that there exist a large amount of data stored in distributed GIS, and considering and using all those data to compute and therefore to find an appropriate subset as replicas is a typically computing intensive application and is hard to get an optimal forecast result. But another fact is that the access to data in distributed GIS is extremely imbalanced and just a small part of them will be requested repeatedly31,32 and so the hotspot dataset will be a small subset of all data.
According to the Hotmap model, 31 the requests to geospatial data satisfy a Zipf’s law which can be stated as follows

where
First,
Then for

where
Finally, computing the popularities of all data based on
Fission
Based on the analyses above, selecting appropriate data (RS) for replication strategy is to find the most suitable subset of data which will be used by applications repeatedly and simultaneously. Thus, if a certain data
Conflict
To realize the load balance, the data which are requested simultaneously have to be stored separately in different locations based on the requirements of RP strategy. Similarly, if a certain data
Static replicas
The static replicas are the replicas which will be stably stored in storage nodes. The static replicas will be adjusted only after hotspot data’s long-term relationships are changed.
Dynamic replicas
The dynamic replicas are the replicas which will be temporarily stored in high-speed cache buffer. The dynamic replicas will be replaced continuously due to the changes in their short-term bursty relationships.
Based on the above preliminary concepts, the aim of DSP can be transferred to get a stable RP strategy for data itself and its static replicas based on all hotspot data’s long-term relationships, and at the same time get a dynamic RS strategy for dynamic replicas based on all hotspot data’s short-term bursty relationships.
Dynamic correlations’ expression mode
Without loss of generality, let

where
Thus, considering the whole investigation time

where

where
Static replicas’ selection and data placement strategies
Based on the definition of fission, equations (4) and (5) can be used to compute the total fissions for all hotspot data H. Thus, we can compute and obtain all data fissions based on a long time

from which we can find the largest
For simplicity, assume that each static replica will have only one copy. For example, if data
Let

where
Data placement strategy is to place all data into all storage nodes, so as to realize load balance. Thus, we have to place the data which will be accessed simultaneously in different nodes to improve concurrency and also place the data which will be accessed repeatedly in different nodes to balance the system load. Let

which indicates whether data
Based on the RP strategy

and then the total average conflicts of all storage nodes can be stated as follows

Since the RP strategy is to find a strategy to realize load balance, the problem can be transferred to find a placement strategy minimizing their difference of average conflicts as much as possible, which can be represented as follows

where
The pseudo code of multi-objective optimization algorithm procedure.

For the static replicas with largest fissions, the data and its corresponding static replica (which is relabeled as new label) will also have the largest conflicts. Therefore, based on the optimal data placement strategies, the data and its corresponding static replica will be placed separately into different storage nodes and the data which have higher conflicts will also be placed separately into different storage nodes.
Dynamic replicas’ selection strategy
Due to the slow disk I/O speed (considering to get data from local storage node) or network I/O speed (considering to get data from remote storage nodes), the dynamic replicas’ strategy is to find the data which will be accessed immediately or in the near future when a certain data are being requested, and then select them as copies and store them in high-speed cache in advance so as to improve access performance.
Similar to static replicas’ selection strategy, we can compute and obtain all data’s conflicts based on a short time

from which we can find the largest element so as to select their corresponding data as the dynamic replicas when data
Simulations and experiments
Simulations’ design
To illustrate the performance of the proposed algorithm in this article, a typical earth observation system similar to Google Earth and NASA World Wind is designed which is called as GlobeSIGht. 32 The application will take SRTM90 data (the 90-m resolution global terrain data files from the Shuttle Radar Topography Mission) as terrain Flythrough, where the size of each SRTM90 data is about 44 kB and the cache size of each node is about 200 MB–2 GB. 24 Thus, each node can cache about 4000–40,000 data which can be used to guide the selection of cache buffer size in simulations.
There are two parts of access sequence, one is for training and therefore to compute and find the dynamic correlations’ expression mode for RS strategy and RP strategy, and another is used to prove the validity of the model. Also, to use enough information to accurately mine data relationship, training data accounted for 20% of the whole access sequence and testing data accounted for another 80%.
For simplicity, each server has one local storage node, and also all of them are connected by 100 Mbps switching Ethernet network. Obviously, distribution parameter
All contrasting experiments are measured as the average local storage hit ratio (LSHR) which represents the average response speed of all servers, where local storage data include dynamic replicas and static replicas which can be obtained with a smaller access cost than that of obtaining data from remote storage nodes by network.
Meanwhile, the contrasting experiments will be made among pure active dynamic copy (ADC) strategies (such as DCST 24 and STAP 28 algorithms), pure passive dynamic copy (PDC) strategy (such as least recently used (LRU) which is widely used by distributed GIS 16 ), pure static copies and data placement (SCP) strategies (such as DCCP algorithm 29 ), and DSP strategy which is proposed in this article. ADC and PDC algorithms will store all data in all storage nodes randomly and then ADC will obtain and store dynamic replicas in high-speed cache according to the behaviors of the users, but PDC will only save the currently accessed data and never prefetch data from storage nodes proactively. SCP algorithm will store related data in different storage nodes in advance and then obtain data from local storage node or remote storage nodes based on their locations. SCP algorithm will never use dynamic replicas. DSP will also store related data in different storage nodes and then synchronously predict and obtain dynamic replicas from storage node in advance when a certain data are being requested. Due to the limited cache buffer size, all ADC, PDC, and DSP methods will use LRU strategy to delete data from high-speed cache buffer so as to save cache space.
Experimental results and discussion
To illustrate the performance of the proposed algorithm considering both static replication strategy and dynamic replication strategy as well as RP strategy, some contrasting experiments are conducted among SCP, PDC, DSP, and ADC, and all of them are scheduled based on their own strategies.
First, Figure 1 gives the contrasting performance of SCP, PDC, DSP, and ADC, measured as the average LSHR, where the number of servers is 10, the dynamic replication ratio of hotspot data is 12%, and the static replication ratio of hotspot data is 10%. In this experiment, all users’ requests to data are distributed to all servers evenly and each server will independently check whether the being requested data were stored in local storage node or high-speed cache and then the average LSHR for all servers can be calculated during each minute.

Comparative LSHRs obtained from different replication algorithms.
Also, their average LSHR and average response time can be calculated and are shown in Table 2, where the size of each SRTM90 data is about 44 kB.
Comparative performance of different replication algorithms.

SCP: strategy based on correlated pattern; PDC: passive dynamic copy; DSP: dynamic replica selection and replica placement strategy; ADC: active dynamic copy; LSHR: local storage hit ratio.
As shown in Figure 1 and Table 2, the performance of all algorithms can remain stable throughout the experiment, DSP can achieve a better performance, and the performance of LSHR is higher about 11.55%–45.22% than the others due to the contributions of RS strategy and RP strategy. Also, the average response time can be reduced to about 11.98%–27.63%.
In this case, PDC obtained the lowest performance due to its single data placement strategy and could not meet the requirement of short-term bursty characteristics of distributed GIS. Also, SCP and ADC can achieve almost the same performance in this situation and their performance difference is less than 5.03%, because the static replicas and data placement strategy which are used by SCP can find most of the data which will be requested repeatedly when replication ratio is very small, and at the same time, the dynamic replication strategy which is used by ADC is difficult to decide which data should be stored in high-speed cache due to the small cache buffer size.
With the increase in static replication ratio or dynamic replication ratio, the performance difference between SCP and ADC will also be changed and expanded due to their different strategies which will be described in the next set of experiments.
Obviously, different sizes of static replication ratio or dynamic replication ratio will provide different sizes of spaces to store data replicas. Thus, two contrasting experiments are constructed based on different ratios of static replication and dynamic replication to demonstrate the performance advantages of the proposed algorithm, and the contrasting experiment results are separately shown in Figures 2 and 3.

Comparative LSHRs obtained from different dynamic replication ratios.

Comparative LSHRs obtained from different static replication ratios.
Figure 2 gives the contrasting performance of different algorithms, where the dynamic replication ratio varies significantly from 6% to 42% and the static replication ratio remains as 5%. In this experiment, the performance of PDC, DSP, and ADC can all be improved based on larger dynamic replication ratio, and the performance of SCP has not changed even when the dynamic replication ratio is increased.
It is clear that PDC, DSP, and ADC all use high-speed cache to store dynamic replicas, and larger dynamic replication ratios indicate that more hotspot data can be stored in high-speed cache and therefore a high probability of hit local storage node can be obtained. But SCP never uses high-speed cache to store dynamic replicas and therefore the performance of SCP will remain stable throughout the experiment.
Further analysis indicates that the active dynamic replication strategies (ADC and DSP) can achieve a better performance than passive dynamic replication strategy (PDC) based on the same conditions. That is because active dynamic replication strategies can predict the future behaviors of users and then prepare data for users in advance. Furthermore, DSP can closely track the behaviors of users and so it can achieve the best performance even when the dynamic replication ratio is very small. But the performance advantage of DSP will be gradually reduced when the dynamic replication ratio is large enough, because the accuracy of predictions is not so important when most of hotspot data can be stored in high-speed cache. At the same time, ADC will only save part of hotspot data as dynamic replications to save cache space and so further expanding the size of dynamic replication ratios is no more useful for ADC when the dynamic replication ratio is already big enough.
Similarly, Figure 3 gives the contrasting performance of different algorithms, where the static replication ratio varies significantly from 1% to 10% and the dynamic replication ratio remains as 12%. As shown in Figure 3, the performance of SCP and DSP can be improved based on larger static replication ratio, and the performance of PDC and ADC has not changed even when the static replication ratio is increased.
Apparently the increase in static replication ratio can lead to a noticeable performance improvement for SCP when the static replication ratio is small, but the performance changes in DSP are not pronounced. As mentioned above, the access to data in distributed GIS is extremely imbalanced and just a small part of them will be requested repeatedly31,32 and so a small number of replicas can bring lots of contributions for average LSHRs because those replicas will be requested repeatedly. But for DSP, those replicas have already been copied based on their dynamic replication strategy and so those small replicas cannot affect its performance deeply. Further observation can be used to find that the performance of DSP can also be improved noticeably with the expansion of static replication ratio continuously.
Meanwhile, to check the performance of all the above-mentioned algorithms under different number of server centers, a contrasting performance experiment is conducted, and the experimental result is shown in Figure 4, where the dynamic replication ratio is 12%, the static replication ratio is 5%, and the server centers’ number varies significantly from 2 to 20.
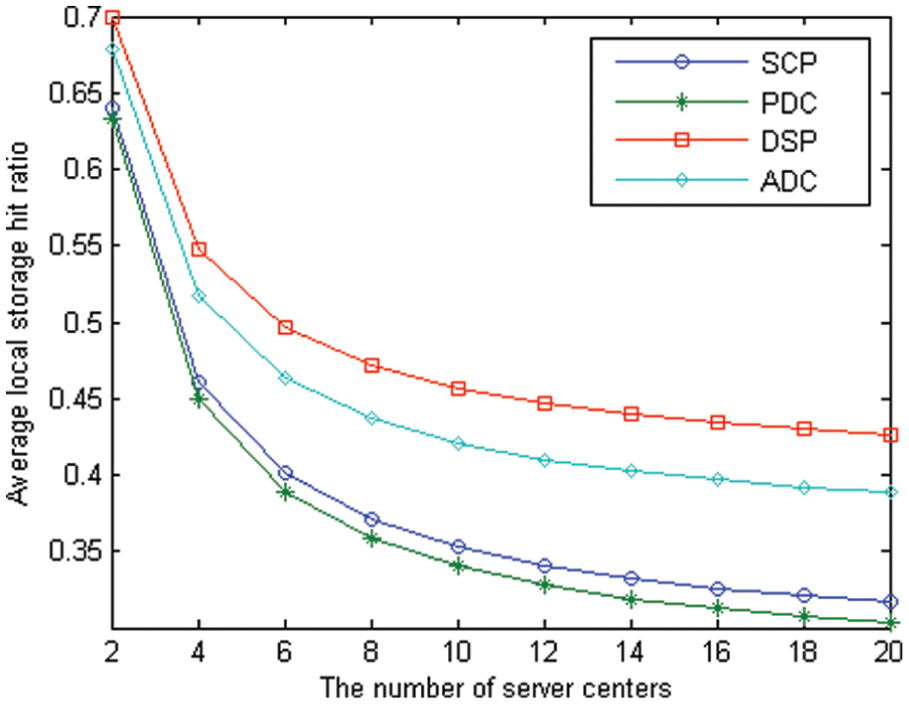
Comparative LSHRs obtained from different server centers’ number.
Similar to the above analysis, DSP can remain its best performance, but the performance of algorithms will decrease with the increase in server centers’ number. It is clear that more server centers indicate that less data will be stored in local storage node. Thus, more data have to be obtained from remote storage nodes by the network and then the performance of average LSHR will inevitably be reduced. Observing from Figure 4, the results indicate that some active dynamic replication strategies, such as DSP and ADC, have well-average LSHR performance and also have lower degradation rate than that of other methods when the numbers of server centers are more than 10 and their performance differences are expanded with the increase in server centers’ number. The experimental results and simulations on distributed GIS prove the effectiveness of the proposed algorithm and show that it can be used in large-scale distributed GIS and will gain more performance advantages.
Since distributed GIS is a typical data-intensive services system, lots kinds of dataset which have different scales will distributed stored in their storage nodes. The proposed method is designed for all kinds of geospatial dataset and can meet as well as automatically adapt their different requirements. Thus, two contrasting experiments are processed based on different datasets and different scales of dataset to prove the adaptability and the performance advantages of the proposed algorithm, and also the contrasting experiment results are separately shown in Figure 5 and Table 2.

Comparative LSHRs obtained from different datasets.
Figure 5 gives the contrasting performance of SCP, PDC, DSP, and ADC, all measured as the average LSHR, where the number of servers is 10, the dynamic replication ratio of hotspot data is 12%, and the static replication ratio of hotspot data is 7%. And the dataset of the right column is NLT Landsat-7 32 and the dataset of the left column is SRTM90, which are the two typical geospatial terrain datasets in distributed GIS. The access mode to NLT Landsat-7 is more concentrated than the access mode to SRTM90, and the degree of access concentration is higher about 29.5%. Also, users’ access mode to same dataset will be changed when the hotspot regions changed and so the access mode to SRTM90 which is used by Figure 5 is also more concentrated than Figure 1, and the degree of access concentration is higher about 25%.
Thus, the above-mentioned contrasting experiment and the first contrasting experiment can be combined to demonstrate the adaptability of the proposed algorithm in different datasets or in different access modes. Similar to the first experiment, DSP can achieve the best performance in different datasets and different access modes. It is clear that a more concentrated access mode indicates less hotspot data and then smaller replication ratio will lead to obtain higher enough performance. As shown in Figures 5 and 1, due to the different access modes, the performance of DSP can also be further improved by about 33.4% and 21.2% with the increase in access concentration, respectively.
Meanwhile, Table 3 gives a contrasting experiment result to check the performance of all the above-mentioned algorithms under different scales of dataset, where the dynamic replication ratio of hotspot data is 12% and the static replication ratio of hotspot data is 5%.
Comparative performance of different replication algorithms.

LSHR: local storage hit ratio; SCP: strategy based on correlated pattern; PDC: passive dynamic copy; DSP: dynamic replica selection and replica placement strategy; ADC: active dynamic copy.
As shown in Table 3, the performance of all algorithms can remain stable throughout the experiment and the performance change rate is less than 1% when the scale of dataset is doubled. Also, DSP can remain its best performance under various scales and this result shows that the proposed method is reliable and can work in large scales of distributed GIS.
Furthermore, it appears that dynamic replication selection and replacement will lead to additional disk I/O, and Table 4 gives a contrasting experiment result to check the total disk access ratio of all the above-mentioned algorithms under different dynamic replication ratios, where the static replication ratio of hotspot data is 4% and the number of servers is 10.
Comparative disk access ratio obtained from different replication algorithms.

SCP: strategy based on correlated pattern; PDC: passive dynamic copy; DSP: dynamic replica selection and replica placement strategy; ADC: active dynamic copy.
As shown in Table 4, ADC can achieve better disk access ratio than do the other algorithms, but the performance advantage is very limited. Due to the lower cache buffer size (i.e. lower dynamic replication ratio), DSP must continually update the cached data so as to get higher LSHR to speed up the service. Comparing with Figure 2, SCP and PDC also need to read data from remote disk due to their lower LSHR performance. But DSP can achieve the best disk access ratio performance when the cache buffer size is large enough, because DSP can obtain a very high LSHR and need no more data prefetching dynamically due to their precise dynamic replicas selection algorithm.
Conclusion and future works
Instead of real-time reading data from remote storage on-the-fly, static replicas based on static replication strategy can store hotspot data in more storage nodes as well as dynamic replicas based on dynamic replication strategy can store the data which will be used immediately in high-speed cache, so as to improve the performance of average LSHR and thus to speed up the response time for users’ access.
This article proposed an enhanced combined algorithm for replication strategy based on users’ access behaviors which implied all data correlation as well as their popularities. 31 The proposed method which is called as DSP combination considered both static replication strategy and data placement strategy (RP) to store static replicas and all data in all storage nodes so as to improve the performance of load balance and also considered both dynamic replication strategy and replication selection strategy (RS) based on the prediction of users’ future behaviors to prepare data in advance.
Also, the performance of the proposed method has been proved through a series of comparative experiments, and the simulation results demonstrate that the proposed algorithm can meet the requirements of distributed GIS in all aspects, including different datasets, different access modes, and different data scales, and can achieve an average LSHR of about 11.55%–45.22% higher than the other methods.
Since the dynamic replication selection and replacement will lead to additional data access from disk, three strategies can be used to reduce the negative effect of service response time in real system: (1) replacing dynamic replicas can be scheduled in parallel with data transferring to avoid access disk latency; (2) using passive dynamic replication strategy to reduce the number of data prefetching when cache buffer size is small; and (3) dynamically adjusting the ratio between dynamic replication and static replication based on the requirements of disk access performance and users’ response time, since high static replication ratio can get a few of additional data accessing from disk as well as low LSHR performance.
Moreover, as mentioned above, the proposed method needs a large enough access sequence to train and obtain the correlation express model and then uses this model to make prediction. It is impossible for distributed GIS when the system is just been started. Thus, a kind of composite method which only uses the current status to make a prediction at the beginning and then uses access sequence to mine the relationship among data after obtaining enough information would be more effective which will be considered in our future works.
Footnotes
Acknowledgements
The authors thank Dr Hang Zhang for providing some experimental data.
Academic Editor: Pierre Leone
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the National Natural Science Foundation of China (grant nos 41671382, 41271398, and 61572372), LIESMARS Special Research Funding, and the Fund of SAST (project no. SAST201425). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the article.