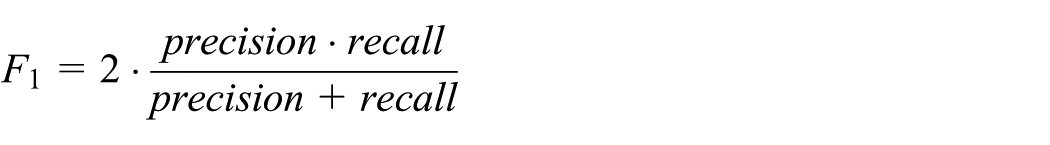This article proposes a framework for evaluating entity extraction problem over cyber-physical system data. As known by us, this article is the first work focusing on this problem, which is an important step for identifying entities in cyber-physical system data. Directed by the initial entities, utilizing the relaxation and verification techniques, provides a path expression–based solution for entity extraction problem, which has following characteristics. First, using path expressions, provides a condensed presentation for entity locations whose size may get very large when scaling up the data size. Second, requiring only one entity example to indicate the interests, using relaxation technique, can discover other similar entities automatically. Third, by adjusting the example given to , users can specify their own interesting entities and control the entities discovered by . Besides, utilizing the idea of sharing computations, by extending previous automaton techniques, an efficient implementation of is provided. Experimental results are reported, which show that can provide an effective and efficient solution to the entity extraction problem.
There have been lots of research interests on cyber-physical system (CPS for short) since it has been widely used in real applications and produced huge influence on the way of obtaining and exchanging information of the physical world. Typically, there are at least two kinds of nodes in CPS, sensors and actuators. The duty of sensors in CPS is to collect valuable information about the physical world and transfer the information to cyber side of CPS (e.g. a cloud computing platform for analyzing sensed information) by the universal network. The duty of actuators is to change the physical world based on the advices given by cyber side of CPS. Obviously, the cyber side of CPS plays a key role between CPS users and physical world, and it can help users analyze and understand the information obtained by sensors. Data collection and analysis have been identified to be the essential problems in CPS.1–3 Previous research works in CPS area mainly focus on the data collection and in-network computing. Recently, more and more research efforts in designing efficient and effective computing methods on cyber side for CPS have been made.
In typical CPSs, different nodes are connected through a universal network, and data collection is achieved by deploying different kinds of sensors in physical world and transferring sensor data in the network. Sensors will monitor the physical world, produce sensed data, and send the data to the network. Different kinds of sensors will produce different kinds of data which can describe the physical world from different aspects. Also, different sensors may produce data about the same object or place. For example, to monitor the weather in some place, one sensor is used to measure the temperature, while another sensor is used to measure the humidity. The network providing connection for sensor nodes is built on advanced communication techniques and organized independent from the deployment of sensor nodes. Also, the network connects sensor nodes with some computing center on cyber side which will process the data collected by sensors and provide useful information to users. Usually, the feedback can be made automatically by computing center or artificially by expert users and will be translated to commands which can be executed directly on actuator nodes. The feedback commands are distributed to the actuator nodes by the universal network. Finally, according to the commands received, the actuator nodes perform special actions to change the physical world.
An example of CPS topology structure is shown in Figure 1. Assume that the CPS is deployed in some building and the goal is to monitor the environment status of the rooms in the building. Each node in the graph represents some sensor node in the CPS, and the communication and management relations between nodes are represented by edges. The types of sensors are labeled on the nodes. In the conceptual view, at each time slot, each node will produce one data, and thus, the topology structure of CPS network is indeed the structure of CPS data. In this example, two entities in Figure 1 can be recognized by identifying the nodes labeled with infrared. Intuitively, each entity represents the sensors monitoring one room, and the entity information can be obtained by collecting all data of the nodes in every time slot. The key problem focused by this article is just how to extract such entities efficiently. Also, it can be found that the “anchor” node infrared in the above example is rather useful for extracting the entities.
CPS data topology example.
The typical system architecture of CPS as described above has many advantages such as high robustness and fine compatibility. However, such architectures cause more challenges for CPS data to be processed and understood on entity level by the processing center. Intuitively, the core problem of entity extraction for CPS data is to identify substructures of the whole topology structure of CPS such that the information generated by each substructure identified is related to the unique object or entity in physical world. Obviously, since one original goal of CPS is just obtaining information of the physical world, the entity extraction problem is essential for CPS. The challenges can be described as follows. (1) To extract entity information from CPS data, usually too much communication cost is spent since we do not know where the entities are distributed. (2) There might be many different communication methods which can find the entities, and proper ones should be selected to reduce the communication cost. (3) The coverage range of nodes and the topology structure of CPS data may vary, and we need to adapt those cases.
This article, to overcome the above challenges, focuses on the entity extraction problem. The entity extraction problem is divided into two parts conceptually, that is, discovering entity locations and the related attributes in CPS data. Intuitively, a location is an anchor node which is associated with an entity and describes it using information of nodes around, and it can be treated as the ID of the entity. The nodes providing descriptive information about the location node are attribute nodes. For example, considering the CPS data shown in Figure 1, the nodes labeled with infrared are locations which represent two rooms whose information is collected by the sensors, and the nodes around the left infrared node (e.g. temperature and Global Positioning System (GPS)) are attribute nodes. As known by us, there are still no research efforts on entity extraction problem for CPS data. The key idea of this article can be summarized as follows. First, we use expressions to represent entities in CPS data, and an initial set of entity expressions is generated manually or automatically. Then, more candidate entities are obtained with the help of expression relaxation techniques. Finally, the candidates are verified under the guide of entity attributes.
In this article, according to the idea introduced above, an entity extraction framework, (ath xpression-based ntity xtraction for short), is proposed. By utilizing path expressions, in , the mechanism to declare interesting entity locations and specify the characteristics of the interesting entities is provided. It is unreasonable to assume that all interesting locations can be specified by users because of the irregularity of locations; to solve this problem, taking the locations identified by the users as an initial set, can discover other interesting locations by extending the location set iteratively with the help of relaxation and verification techniques. The main challenges and contributions can be summarized as follows:
The first contribution is to propose the framework to investigate the feasibility and explore useful techniques for entity extraction of CPS data. In , path expression is used to specify the interesting entity locations and describe the characteristics needed by interesting entities.
The second contribution is to identify two main problems in framework. The first one is to discover the candidate locations in view of the irregularity of localizations. It means that, even for entities of the same kind (e.g. rooms monitored by CPS), many different representations are needed to cover their locations, but user specifications can only provide some of them; therefore, automatic techniques for discovering the remaining locations are required. The second one is the performance of, that is, to propose practical implementation of framework to provide an effective and efficient method for entity extraction problem.
The third contribution is a method of using relaxation techniques to adapt for the irregularity of localizations in . Given an entity location expression , relaxation technique can discover other candidate location expressions by extending using similar expressions, and the quality of generated candidate location expressions can be controlled by limiting the cost of relaxation operations.
The fourth contribution is to propose an effective and efficient solution for entity extraction problem. For the effectiveness, measuring functions for determining the interesting degrees of entity locations and location expressions are introduced. For the efficiency, an algorithm IMP2E is proposed based on the idea of sharing computations and reducing redundancies among queries.
The last contribution is to give a detail experimental study of IMP2E algorithm, which shows the effectiveness and efficiency of the algorithm on both synthetic and real data.
The following part of this article is organized as follows. In section “Preliminary,” some background knowledge are introduced. The framework and the formalization of entity extraction problem are described in section “The framework for entity extraction in CPS.” Two algorithms NAI2E and IMP2E are proposed in section “Algorithms for entity extraction of CPS data.” In section “Experimental evaluation,” the details of experimental results are introduced. The final parts are related work and conclusion.
Preliminary
Network model
A network can be represented by a graph , where the parameters can be explained as follows:
is the node set representing sensor nodes in the CPS network.
is the edge set representing the connection relation between nodes. If , we can know that and can communicate with each other directly. Obviously, is symmetric.
is another edge set which defines a tree over , which represents the topology structure of routing strategy in the network. Obviously, we have . Usually, we use to represent the root of which can be explained to be the processing center. For , is called parent of and is one child of .
is the set of node labels, which represents the different types of sensors.
is a function which defines a mapping from to . Intuitively, returns the type of given sensor.
Given a network , we use , , , , and to represent the elements in , respectively. Here, w.l.o.g., it is assumed that each node in CPS has sensing and acting abilities and can be sensor and actuator at the same time.
Entity-based data view and path expressions
On the physical side of CPS, the data obtained by each sensor are relatively independent. For example, suppose that there are two sensors and deployed in different positions of one room , and can measure the temperature and can measure the humidity value, and at time , the data obtained from and can be denoted by and , respectively. From the physical view of CPS, since and are different types of sensors and deployed in different positions, and are independent and two separated data.
However, on the cyber side of CPS, the data are expected to be explained based on real entities in physical world by end users. Continued from the example above, the CPS users are used to treating and to be the temperature and humidity values of the same room. That is, two independent data obtained from physical side belong to the same entity on cyber side.
Obviously, the construction of entity-based data view is a key problem of CPS which can improve the usability of data obtained from CPS. Still continued from the example above, a typical task is to return the information (temperature and humidity) of all rooms. Given the data from physical side, we need efficient methods to find all temperature and humidity pairs for the rooms.
In this article, we construct the entity-based data view based on the topology structure of CPS network. The intuitive idea can be explained by the following observations. First, if node is near node in , it is highly possible that they are used to monitor the same entity. Second, usually, the sensors are deployed in special strategies for the monitoring task, and the sensors of same entities are also distributed according to special rules in . For some special entity , we use routing paths on to represent the sensors related to . For example, the information obtained from room can be represented by , where means that starting from we can reach a b-type sensor through some a-type sensor. Obviously, according to the routing path information, it is easy to extract entity-based data view. However, real CPS may be composed of huge amounts of sensor nodes; it is impossible to enumerate all such paths, and we need to find a concise representation method for the routing paths.
Definition 1
Path expressions
Path expressions can be defined by the syntax . Here, belongs to the set , / means directly connecting two sub-expressions, and // means connecting two sub-expressions using a line of elements with arbitrary length.
In a tree , two nodes and satisfy “/” (“//”) relation if they have parent–child (ancestor–descent) relation, and the semantics of a path expression can be defined similarly by iteratively applying the two basic operations. Given query and node , , or is used to represent the nodes which can be reached from by matching path . Then, the entity can be represented concisely as follows.
Definition 2
Entities in CPS
Given a CPS network , we can use the following expression to represent and extract entities in CPS
where and are all path expressions. is called target expression, and s are called attribute expressions. We use target and attribute to represent them, respectively.
Intuitively, the entity representation in CPS is routing oriented, the sophisticated routing protocols are based on paths in network,4 and the information gathered in such networks can be treated to be organized based paths.2,5,6 Thus, the path expression can find sensor nodes which can collect information of some entity by forwarding and collecting messages to its children nodes, and the expressions can tell us how to find all kinds of information of the entity.
Path expression relaxation
Usually, the topology structure of CPS network is built by network protocols in randomized way; thus, the entities in CPS have similar path structures but not necessary same. To support efficient entity extraction from CPS data, we need the help of relaxation techniques for path expressions.7,8 Next, we will introduce the relaxation techniques used in this article.
The problem of path expression relaxation is to return a set of expressions with similar semantics of the given path expression. In this article, it is implemented by applying rewriting rules repeatedly over the given path. The rewriting rule set includes the following:
Axis relaxation: Replace one “/” operator in the path with “//,” denoted as .
Label relaxation: Replace one node’s label with another label available in the data, denoted as .
Star relaxation: Replace one node’s label with *, denoted as .
It should be noted that the rules used in this article are different from the ones in previous works of relaxation. Previous works focused on finding a variant q′ of original expression such that has non-empty result and . With that goal, was not considered by them because it cannot make sure that generated expression is larger than .
In the following part, the rule set composed of those three rules is denoted as ℜ. For path expression with length , , and ℜ, means replace the operator in position with “//,” means replace the label in position with , and means replace the label in position with *. Those three rules can be uniformed as the representation of triple operation executed on some expression, where is the rule, is the position is applied, and is the parameter of . When is not 2, the triple can be shortened as . A rule sequence is defined as where each for represents some triple (, , ).
Given and , it is denoted as if can be obtained by applying rules in one by one in order. It is denoted as , if can be obtained by applying one rule in ℜ at most once over . It is denoted as , if can be obtained by applying rules in ℜ multiple times over query . For a special expression , if , is said to be an extended path of . Denoted as , all extended paths of can be defined as .
The framework for entity extraction in CPS
In this section, a framework called for solving entity extraction problem in CPS will be introduced. Using the path expressions introduced above to represent entity locations and attributes, the problem can be solved step by step after answering the following questions. (1) What is entity and entity location in ? (2) How does represent the locations? (3) How can we find the entity locations and their attributes? After providing an overview of , the formal definition of entity extraction problem is stated finally.
Entity locations in CPS data
Generally, there are no universal definitions for entity and entity locations in CPS data; in this part, the meanings of those two concepts in this article are explained.
For CPS data, entity has no definitions formal enough to be directly used. Even worse, in general, there are no general definitions for entity, and different research areas usually use different definitions. (For example, in Wiki, entity is defined as something that has a distinct and separate existence. In a DBMS (database management system), entity is defined as a thing in the modeled world, and in a system, entity means a component.) In this article, an entity in CPS data is assumed to be a sub-tree fragment, whose nodes store the information about the corresponding real-world entity. Considering the CPS data shown in Figure 1 again, those sub-trees enclosed with dashed lines are entities stored in .
For a special entity in CPS , which actually means a sub-tree of , entity location is defined as the root node of the sub-tree. For example, for the entity shown in Figure 1, node 2 is the location of , it can be seen as the anchor node of entity , and the other nodes under it in represent the attributes of this entity.
Representing entity locations and attributes
Based on the explanation of entity location, the essential problem of entity extraction in CPS is to extract one set of interesting locations (nodes) in CPS data. In , path expression is used to provide condensed representations for entity locations. For example, for the data tree shown in Figure 1, the path expression/center/infrared may represent one room whose information (temperature, humidity, and so on) is monitored by the CPS. Although there may be a large number of nodes of same type, only one path expression is enough to cover all of those entity locations. Using path expressions to cover locations provides a method to present entities concisely and takes the advantage of sophisticated algorithms for path expression evaluation. Similarly, the attributes of entities can also be represented by path expressions as discussed above.
Extracting entities from CPS data
Since entity locations are represented by path expressions, the problem of extracting entities from CPS data is indeed the problem of discovering path expressions which can represent entity locations and attributes efficiently. The idea of this article can be summarized as following steps. First, some initial entities (represented by path expressions) of CPS data are generated by experts or processing center. Then, for each entity expression , the set of candidate extended entities, , is obtained by relaxing the expressions in . Finally, for each candidate entity expression , a verification procedure is run to determine whether is useful.
Generating initial entities
As discussed above, the concept of entities is general and subjective, and usually, it depends on how the CPS data are treated and organized by users. Therefore, we need some initial expressions of entities to tell the system which entities are interests of users. For general CPS, the initial expressions can be provided by expert users. For example, let us consider the data shown in Figure 1 again. Expert users can only select the attribute nodes of some entity they focus on and return the nodes to the system. Suppose that the left infrared nodes are selected. Initial entity expression can be built trivially by enumerating the path from root node to the attribute nodes and using the lowest ancestor node of those attribute nodes as the entity location. That is, ϕ = /center/infrared. It is easy to found that the target path refers to the interesting entity location, and attribute refers to the attributes which describe the entity from different aspects. In some cases, we can generate the initial entities automatically by utilizing additional information. For example, if the CPS is well deployed and the entities focused by users are highly related to the geographic locations, we can collect the initial entities by simply clustering nodes near enough in the geographic view.
Generating candidate entities by relaxation
Using only the naive strategy shown in generating initial entities, there may be interesting entities lost in practical applications. Suppose that the entity expression is found in the first step. Using , we can only extract entities locating at and containing two attributes nodes under paths and . However, because the construction of topology structure of CPS data is usually in randomized way, there may be entities of the same type locating at with attribute nodes , , and . In this case, the method shown above will lose those useful entities. Additionally, we cannot expect, in that case, expert users can provide all available entity expressions because either (1) the size of such expressions may be too large to be enumerated completely by users, or (2) users may have no enough knowledge about the CPS data to give complete specification.
To solve this problem, provides a mechanism to automatically discover the locations of those entities not covered by user specifications, even if users cannot specify enough entities, and the power of this mechanism can be adjusted by users. The idea of is using the relaxation techniques.
To complement the user specifications, relaxation techniques are utilized based on the following observation. In real CPS, although the same kind entities may exist under different incoming paths, it is usually that their incoming paths are similar on the syntax structures. Then, for a given entity expression generated by the first step, the idea is using relaxation techniques to discover the query with similar syntax structures as candidate entity expressions, which is expected to have similar semantic information too. The rules , , and shown in section “Path expression relaxation” are used in this article to guarantee that relaxed expressions are similar to the original one.
To adjust the power of relaxation, a threshold is used to limit the application of rewriting rules. Intuitively, if rewriting rules are allowed to be applied arbitrarily, given entity expression , all possible entity expressions can become the candidates, within which there may be entities totally “far” from such that they belong to different type from and users do not want them. Obviously, the more times the relaxation rules are applied, the less similar the relaxed expression is with original one. Therefore, to ensure that the distance between relaxed expression and the original one is within a certain range, a cost function is defined for the relaxation rules and used to define the distance between expressions. Given n-length entity expression and rules set ℜ, the cost of applying rules can be defined as for star relaxation operation and 1 for other cases. Based on the rule cost function, a distance measure for two path expressions and can be defined.
Definition 3
Distance
For path expressions and , and a rule sequence , s.t. , the distance between them is defined as the sum of COST for each rule applied in the rewriting sequence. More formally, , which is the cost of obtaining by applying to , can be defined recursively as follows
Since there are many rewriting sequences taking to , the sequence taking minimal cost for rewriting operations is considered to be the distance between two path expressions. Formally, the distance between and can be defined as .
Based on the relaxation techniques and distance introduced above, given path expressions for entity locations or attributes determined by user specification, can discover a set of candidate entities , which are syntactically similar to and possibly indicate the locations or attributes of the same kind entities interested by users. To control the quality of generated entities, a threshold can be given to limit the distance between generated expressions and , which means for , there should be .
Example 1
Let us consider the following example. Suppose that the path expression has been obtained to indicate the entity locations. Using relaxation, we can also find . However, without the limitation of threshold , expressions such as /r/* and /*/* can also be found, for which too many non-interesting entities will be extracted too. Setting the relaxation threshold as 1, those two expressions can be pruned because they are too “far” from .
However, even is limited, and some entity expressions which are not useful are still generated. Therefore, it is not enough to use only to control the quality of relaxed expressions, and further techniques will be introduced to solve such problems.
Verifying candidate entities
As shown in Example 1, even if the relaxed entity expressions generated by limiting the distance are not larger than , they still may bring non-interesting entities. Therefore, for each new candidate, further verifications for determining whether it is indeed useful are needed.
The intuitive idea can be explained as follows. In perfect cases, useful entities of same type will have same set of attributes, while in real applications useful entities will have similar set of attributes. Also, to simplify the discussions, it is assumed that the types of sensor nodes are determined by the node labels, and nodes with different labels will belong to different types. Next, a measure function is proposed to determine whether an entity is similar enough; then, based on , is proposed to determine whether an entity expression is useful enough.
Given an entity location and an initial entity expression , can be defined over and the attribute expressions attribute of as , where is the size of attributes of appearing in . is used together with a parameter , which is the threshold to determine whether entity is the kind described by the attributes of . In detail, if the value of is smaller than , the answer is negative; otherwise, the answer is positive.
For candidate entity expression , key rule , and CPS data , based on the and its parameter , the candidate entity measure function can be defined to measure the usefulness of for entity extraction problem as . is used together with a parameter , which is the threshold to determine whether a given expression is proper for the entity extraction problem. In detail, if the value of is smaller than , the answer is negative; otherwise, the answer is positive.
Formal definition of entity extraction problem in framework
The entity extraction framework of can be explained as follows. Given CPS data and initial entity expression set , is expected to automatically extract entities and return them to users. For each expression , relaxation module relaxes the entity location expressions generated by with constraint and then outputs the relaxed candidate location expressions. Then, given a relaxed expression and attribute expressions , taking parameters and , the verification module filters the expressions not satisfying out and returns the suitable expressions to users. The two modules, relaxation and verification, are essential procedures in , and they provide the solution to the entity extraction problem. Then, the entity extraction problem in can be formalized as the following definition.
Definition 4
Entity extraction problem
Given CPS data and an initial entity expression , also the three parameters, relaxation constraint , and for verification measure , the entity extraction problem is to return the set of entity expressions , such that for , (1) the distance between and , , is not larger than , and (2) the measure is not smaller than .
Essentially, the entity extraction problem is to find entity expressions most of whose results are similar to initial entities by utilizing relaxation in limited steps. To limit the using of relaxing operations, a parameter restricting the number of relaxation steps is utilized, and to guarantee the quality of expressions obtained further, verifications based on known information are utilized.
Algorithms for entity extraction of CPS data
In this section, the entity extraction algorithms of this article are introduced, which indeed implement the entity extraction of . First, a naive implementation is given as the baseline. Then, a method based on automaton techniques is provided.
Naive algorithm
A naive algorithm for entity extraction problem is shown in Figure 2. The main idea of NAI2E is to (1) enumerate all relaxed expressions by applying rewriting rules on the original expression with relaxing constraint and then (2) for each relaxed expression , evaluate over data tree , collect the information about locations extracted by , and determine whether is an interesting location expression.
NAI2E algorithm.
The details of NAI2E can be explained as follows. First, according to the initial entity expression , target expression describing the locations of entities and attribute expressions describing the attributes of the entity are generated (lines 1–2). Then, procedure ERELAX is invoked to obtain the relaxed expression set satisfying the constraint (line 3). Third, procedure EVer is invoked to filter out those expressions not satisfying (line 4). Finally, the result is returned (line 5). For procedure ERELAX, a FIFO (first-in first-out) queue is maintained to store the current relaxed expressions. First, is initialized to be empty, and target expression is inserted into the queue (lines 1–2). Then, following operations are executed until becomes empty (lines 3–12). (1) In each round, a expression in is polled (line 4). (2) For , relaxed expressions are obtained by trying all possible relaxing operations (lines 5–11). The relaxations having no effects are ignored (lines 8–9). If some relaxed expression has value not larger than , it will be inserted into (lines 10–11). Here, an abbreviated form of the triple relaxation is used (line 7), and if is , means the set is a valid label in . (3) is added to the result (line 12). Finally, relaxed expressions set is returned (line 13). For procedure EVER, the candidate expressions in are verified one by one, and the collection of expression evaluation results is used to compute the and values which are the measures for filtering the candidate expressions. For each expression , following operations are executed. First, a location set qres is obtained by evaluating on (line 2), and a counter is initialized to be 0 (line 3). Then, the value of each node is evaluated by evaluating expressions in attribute expressions , and by comparing with , counter recorded the number of satisfying nodes (lines 4–8). Finally, the value is computed and compared with to determine whether belongs to the final result (lines 9–11).
IMP2E algorithm
In this part, the IMP2E algorithm is proposed to solve entity extraction problem. Comparing with NAI2E, in the relaxation module, the number of candidate expressions generated is reduced by utilizing the normal form relaxations, and in the verification module, the cost is reduced by sharing the computation of multiple candidate expressions. An overview of IMP2E will be given first and then two procedures invoked by IMP2E will be introduced in details.
Overview of IMP2E
As shown in Figure 3, IMP2E algorithm can be divided into three parts. First, by given initial entity expression , the target expression and attribute expressions are generated (lines 1–2). Then, RERELAX is invoked to generate candidate expressions by relaxing operations (line 3). Here, by relaxing expressions into the standard forms, the redundant expressions in the candidates can be reduced. Finally, SEVER is invoked to verify all candidate expressions, and the result is returned (lines 4–5). Here, by sharing the computations between expressions, the efficiency of verification procedure is improved.
IMP2E algorithm, part a.
Reduced expression relaxation
According to the rewriting rules in ℜ, for special expression , the naive idea to find all relaxed expressions with constraints is to enumerate all possible rewriting sequences, just like in NAI2E algorithm. Such a simple strategy may produce redundant candidate expressions because for given expression and some relaxed expression , there may be several rule sequences which are able to transform to . For example, given as /a/b and as //*/c, considering the rule sequences defined as follows, obviously, both of these two different rule sequences can transform to . When relaxing expressions, such rule sequences let the relaxation procedure return redundant relaxed expressions
To avoid the redundant candidate expressions, a standard form of rule applying sequence is given. For rule triple , let , , and . A rule sequence , where the rules come from ℜ, is standard if (1) for , ; (2) for , if , then ; and (3) there is no such that , , and .
Following properties guarantee that the standard rule sequence can reduce the redundancy when relaxing expressions.
Proposition 1
For any expression pair and such that , there is one and only one standard rewriting sequence generating from .
Proposition 2
For any expression pair and such that , where is a standard relaxing sequence, we have . That is, standard rule sequence produces the shortest relaxing plan for given expressions.
Based on the properties above, procedure RERELAX shown in Figure 3 will generate the candidates by relaxing expressions according to the standard rewriting sequence.
Sharing expression verification
For given input parameters {\mathbb{C}}, , , , and , expression verification procedure is to determine whether a candidate expression satisfies the conditions defined by , that is, the ratio of nodes satisfying to all nodes of ’s result is not smaller than . Therefore, for each node , it needs to determine (1) whether satisfies the target expression , and (2) for some attribute expression , whether has descendent nodes satisfying . Let represent the value whether a node satisfies where integer , and represent whether a node satisfies where integer . Considering that trivially evaluating and is expensive, the idea of this article is to improve the efficiency by sharing the evaluations between those functions. For each , a corresponding automaton is built, and the computations between s are shared by merging states of the automatons. For s, the two strategies, TopDown and BottomUp, are considered.
In the following parts, first, the evaluation of is introduced; then, for evaluating s, a TopDown strategy and a computation sharing–based BottomUp strategy are introduced, respectively, and discussed; finally, the algorithm for verification module is given.
Evaluating target expressions
Since the expressions evaluated in this step are all produced by the relaxation module, expressions having similar structures are very common among them, which brings chance for us to share the computations. For example, for /a/b and relaxation constraint 1, expressions /a/a, /a/c, and /a/d can be generated, and the first step /a can be evaluated only once and shared among those expressions. To formalize this idea, an automaton-based technique for evaluating target expressions is introduced.
The procedure for evaluating target expressions is composed of three parts. (1) For each target expression , a nondeterministic finite automaton (NFA) is built using the method given by Diao et al.9 Briefly, the idea is to use the transformations shown in the following to build automaton. Each step of given expression is converted to the basic automatons first and then those basic automatons are linked together to form the . For the accept states of , an integer value is attached for indicating which expressions are accepted. (2) To share the redundant computations among expressions, different automatons of are merged into by combining same prefix of expressions using the techniques in the work by Diao et al.9 Besides, another merging strategy utilizing the characteristics of the relaxed candidate expressions is applied before the prefix-sharing techniques. Considering the expression /a/b/c and relaxation constraint 1, expressions /a/a/c, /a/d/c, and /a/e/c can be generated. Not only the prefix of those expressions but also the postfix can be shared. Such expressions having chance to share both prefix and postfix are very common in the expressions generated by relaxations and only using prefix-sharing techniques is not enough. Thus, a special merging strategy, Similar Automatons Merging strategy, for such expressions is utilized in this article, which can be explained using an example. Consider the three expressions generated by /a/b/c above, and they can be represented as just one regular expression , which can be identified by a single NFA. Such a technique can merge the automatons of those very similar expressions into a condensed one. After that, the produced automaton will be merged with others using prefix-sharing techniques. Additionally, when merging the automatons, the associated information about expression index in accept states is also merged, so in , each accept state has a set of expression indexes attached. (3) Finally, given the NFA generated above, by making a preorder traversal on tree , can be evaluated. For node , during the traversal, is assigned to 1 if accepts at , and is one of the associated expression indexes at the accepting state. There have been many sophisticated algorithms for this evaluation problem, and in this article, the lazy state method proposed by Diao et al.9 is used to evaluate the NFA .
Evaluating attribute expressions
To evaluate the attribute expressions , both TopDown and BottomUp methods are considered and discussed in this part.
TopDown-Evaluation. This strategy uses the similar idea of evaluating target expressions. Intuitively, for attribute expression and each node , to determine whether has is equivalent to determine whether is empty. It can be done by executing a preorder traversal and evaluating on the sub-tree . In detail, when visiting , automatons for evaluating attribute expressions in are initialized, and the states are attached to . Then, those automatons are evaluated when visiting the nodes in sub-tree . On some node, if the automaton for attribute expression accepts, the value of is set to 1. After all nodes in have been visited, all values of functions are assigned correctly. It will take expensive cost if values of all nodes in are calculated. To optimize the evaluation cost of attribute expressions, let us consider the function again. For some node, if is 0, has no effects on the value of . Therefore, when making the preorder traversal, only those nodes accepted by evaluate the automatons for attribute expressions. Such a strategy can reduce the size of nodes to be evaluated from to , where is defined as .
BottomUp-Evaluation. This strategy evaluates attribute paths when making a postorder traversal. The intuitive idea can be explained by following example. Given an attribute path , it is said a node satisfies this condition iff there is a path between and some leaf node such that is not empty when being evaluated on . If is processed in reverse order, that condition can be checked by evaluating the expression on the path between and the root node and detecting whether . In detail, when visiting a new leaf node during the postorder traversal, automatons of the reverse variants of attribute expressions are initialized, and the states are attached to the node. Then, when visiting an internal node, for each child node , each automaton is evaluated taking current node as input and states associated with as current states. After that, the union of all result states is attached to the current node. Thus, for some node , when visiting , all values can be computed by evaluating the automatons and checking whether its result states contain the accept ones. The computation sharing idea is reflected by the union operations of states. In fact, those states come from automatons for different branches, and it seems that they cannot be used by other automatons. However, because the attribute expressions are evaluated in an existential way, no matter which branch a state comes from, the current node can utilize it and continue the automaton evaluations. Following analysis will show what effects such a sharing strategy achieves.
Since neither of the two strategies can dominate the other one, in practice, to choose which one depends on the applications, essentially, depends on the values of the maximal size of open nodes and the selectivity of target expressions.
Algorithm for sharing query verification
To concatenate the evaluations of target and attribute expressions together and show how the related information is collected and compared with parameters and , the details of a BottomUp version of procedure SEVER are introduced in this part. The TopDown version is similar and omitted here. As shown in Figure 4, for given data , SEVER visits using a depth-first access method and processes the related nodes. Before that, initialization of related data structures is finished (lines 1–5). First, for target expressions set , the automaton is constructed (line 1–2). Then, for each attribute expression in , the automaton for the reverse variant is constructed (lines 3–4). Finally, for storing the result locating expressions is initialized using empty set (line 5). After that, nodes in will be processed one by one (lines 6–16). First, a states stack is initialized with the start state of (line 6), and for each target expression , two counters and are set to 0 (lines 7–8), where is the number of nodes satisfying and is the number of nodes satisfying both and . For the first meet of node , function PUSHINFO is called (lines 11–12). In PUSHINFO shown in Figure 5, the automaton is simulated by taking the label of node as input and the top element in as current state (lines 1–3), and the result states are pushed into (line 4), and for each target expression accepted in this step, the counter is increased by 1 (lines 5–6). Here, label returns the label of given element node, trans returns the states of automaton by running with the first parameter as current states and the second parameter as input, and accept returns the expressions attached to the accept states in given state set. For the second meet of node , the function POPINFO is called (line 14). In POPINFO as shown in Figure 5, the automatons are simulated. First, cStates is obtained from the top of , and current node and the label are initialized (lines 1–2). Then, if the current node is a leaf node, start states of automatons are attached to (lines 3–5). Otherwise, the states associated with the children nodes of are collected, and based on those, states automatons are simulated, and the result states are attached to . During the simulation, qCount is used to record the number of attribute expressions accepted (line 7). After the simulation of automatons, is calculated by qCountQ and compared with . If is not smaller than , for each accepted expression in cStates, the counter is increased by 1 (lines 8–17). Finally, for each expression in , the measure is calculated by formula and compared with , and the satisfying expressions are added into (lines 15–16). After all events are processed, the final result is returned (line 17).
IMP2E algorithm, part b.
Functions used by SEVER.
Remark 1
Obviously, the algorithm shown above depends on the parameters hardly. Intuitively, the parameters and control the quality of entities extracted and the parameter can adjust the ability of discovering entities with different structures. It is hard for users, even for experts, to decide the values of those three parameters. One possible solution is to use the feedback of the system to adjust the parameter values. The feedback can be organized based on entity quality measures or labels of experts. The entity quality measures used in the experiments can be utilized here. The labels of experts can distinguish “right” and “wrong” entities obtained by the algorithms. According to the experimental results, it is reasonable to design a method for selecting parameter values automatically using the idea of hill-climbing.
Experimental evaluation
In this section, an experimental study of the entity extraction algorithm on effectiveness and efficiency is reported.
Experimental setting
An area of is considered and sensor nodes are deployed in this area. Two different deployment strategies are considered to produce different types of CPS data. One strategy is that all nodes are randomly deployed in uniform way within this area, and the corresponding CPS data are called Type-I data. Based on the first strategy, the second one can be obtained by adding additional sensor nodes with different deployment method into the area. Added nodes are assumed to have enough powerful communication abilities, and they can communicate with each other in the range of . The CPS data with respect to the second strategy are denoted by Type-II data. It is easy to verify that Type-I data tend to have relatively large depth and regular structure, while Type-II data tend to have small depth and the fan-out of some nodes will be very large. The entity extraction algorithm, IMP2E, is implemented in JAVA, compiled in JDK 1.7, and all experiments were performed on a Windows 7 machine with Intel Core i5 Duo CPU with 2.4 GHz and 4 GB RAM. All experimental results involving the time cost were obtained by running algorithms 5 times and taking the average value.
Experimental results and discussions
Effectiveness
The effectiveness of the entity extraction algorithm referred in this article indicates its ability of extracting entities correctly. As usually did, precision and recall coefficients are used to measure the effectiveness. Besides, the F1-measure for combining them defined by
is also reported to comprehensively compare the performances of the algorithm under different settings. The three functions are often used in many fields (e.g. information retrieval10 and machine learning11) for measuring the performance of querying, searching, classification, and so on. The following factors affecting the algorithm performance are considered in this part: the relaxation constraint , the threshold , and .
Type-I data
For Type-I data, we generated 1M CPS data by adjusting the network simulation parameters. Entities are selected by users manually and the corresponding trivial rule is taken as the input of entity extraction algorithm. Fixing as 3 and adjusting and , the algorithm is run and the results are recorded. As shown in Figure 6(a), we have following observations about the precision results of Type-I data. (1) The two parameters and indeed affect the performance of the entity extraction algorithm, when they are changed from 0.1 to 1.0 and the precision of algorithm changed from 63% to 100%. (2) Precision of the algorithm can be improved by increasing either one parameter; when fixing one of the two parameters and increasing the other one, the precision ratio gets higher. (3) On the aspect of precision, Type-I data can be processed very well by setting proper parameters. As shown in Figure 6(c), we have following observations about the recall results of Type-I data. (1) The two parameters and indeed affect the performance of the entity extraction algorithm; when they are increased, the recall of the algorithm also increased. (2) Recall of the algorithm can be improved by relaxing either one parameter; when fixing one of the two parameters and decreasing the other one, the recall ratio gets higher. (3) On the aspect of recall, Type-I data can be processed very well by setting proper parameters. As shown in Figure 6(e), we have following observations for Type-I data on measure . (1) The performance of entity extraction algorithm can be affected by the two parameters, and the ratio ranged from 0 to 1. (2) For a fixed (or ) and increasing (or ), the ratio shows the up-then-down trend roughly. (3) The best ratio, that is, the best performance of algorithm, occurs when or . This means that, if the parameters are taken properly, the entity extraction algorithm can process Type-I data very well on the task described in the experiments.
Effectiveness performance when k = 3: (a) Type I + precision, (b) Type II + precision, (c) Type I + recall, (d) Type II + recall, (e) Type I + F1, and (f) Type II + F1.
Type-II data
For Type-II data set, 1M CPS data are also generated and same experimental settings are prepared. The precision, recall, and results are shown in Figure 6(b), (d), and (f), respectively. The observations can be summarized briefly as follows. (1) Over Type-II data, two parameters can affect the performance of algorithm on all those three measures. (2) When and become larger, both precision and recall ratio changes monotonically, but is a little different. When takes a small value and takes a large one, the performance still keeps very well. This is because Type-II data set is generated by randomized methods, different entities have very special substructures, and even if only a few attributes are utilized, they can still be distinguished well. (3) By setting parameters properly, entity extraction algorithm can process Type-II data set well.
Efficiency
Efficiency is measured by the time cost taken by the algorithm in this article. Usually, the efficiency of algorithm determines whether it can work in practical applications, especially when the data size gets large. In this part, four dimensions affecting the algorithm efficiency will be considered, data size, , , and .
Data size
For the dimension of data size, a series of combinations of the other three parameters is considered to test the performance of entity extraction algorithm when scaling the size of data. First, construct the data set with different sizes ranging from 10 to 100 MB. For Type-I data, the data sets are called to be I10M, I20M, and so on. For Type-II data, the data sets are called to be II10M, II20M, …, II100M. Then, for different parameter combinations , the entity extraction algorithm was run over those two kinds of data sets, and the time cost results are reported.
As shown in Figure 7(a), the time cost results of Type-I data set have following three observations. First, as the data size changes from 10 to 100 MB, the time cost increases linearly for all parameter combinations. Second, for the same setting of , when increases, the time cost gets larger, and this is because an increase in will let algorithm consider more relaxations which will take more time cost to evaluate those queries. Finally, for fixed , different combinations of nearly have no effects on the time performance of algorithm. As shown in Figure 7(b), the time performance of the algorithm over Type-II data has the similar observations. From the experimental results and observations above, it can be found that entity extraction algorithm scales well with data size under different combinations of the other three parameters.
Scalability to data size: (a) Type-I and (b) Type-II.
Relaxation constraint k
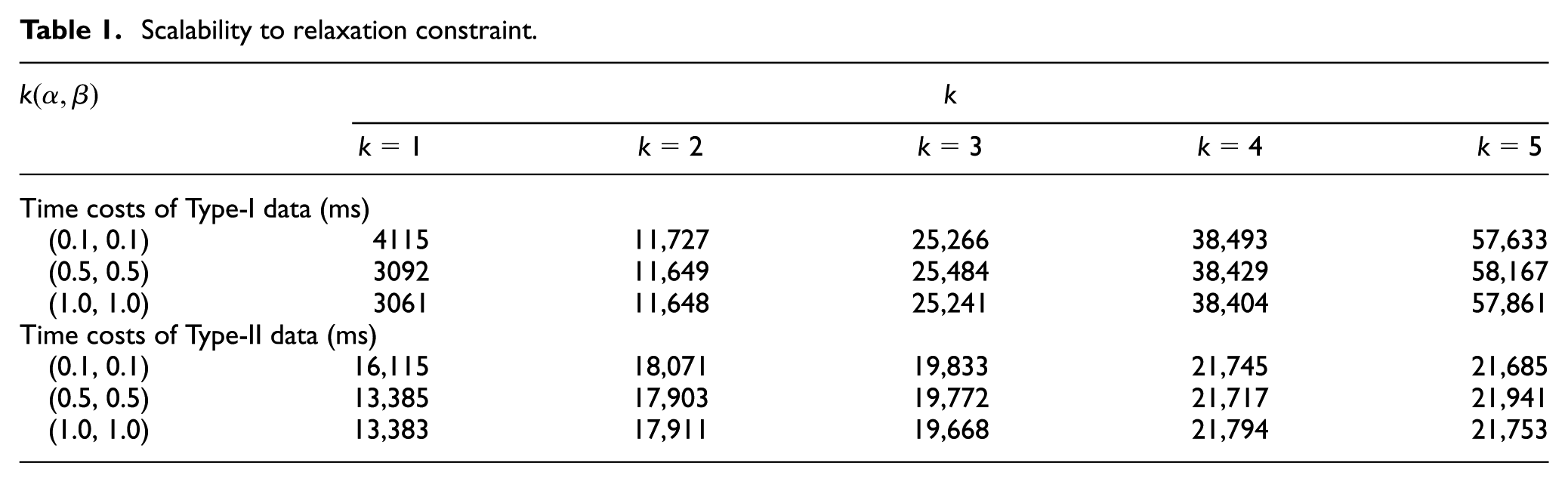
For the dimension of relaxation constraint , we fixed the data size and took several combinations of and then tested the scalability of the algorithm to . First, fix the data size as 50 MB, so the data sets I50M and II50M are used in this part. Then, for parameter combinations , the entity extraction algorithm was run for from 1 to 5 on I50M and II50M, and the time cost results are reported.
As shown in Table 1, the time cost results of Type-I data can produce following observations. First, as the constraint changes from 1 to 5, the time cost increases almost linearly for different combinations of . Theoretically, in the worst cases, the time cost increases faster than linear relation. However, in practical case, usually, most of expressions added by the relaxation using large produce only empty result and become invalid very early when evaluating them. Therefore, they do not have obvious effects on the algorithm performance. Second, for fixed , under different combinations of , the algorithms have similar time cost performance. As shown in Table 1, the results of Type-II data have similar observations. From the experimental results and observations above, it can be found that entity extraction algorithm is well scalable when increasing the relaxation constraint .
Scalability to relaxation constraint.
k
Time costs of Type-I data (ms)
(0.1, 0.1)
4115
11,727
25,266
38,493
57,633
(0.5, 0.5)
3092
11,649
25,484
38,429
58,167
(1.0, 1.0)
3061
11,648
25,241
38,404
57,861
Time costs of Type-II data (ms)
(0.1, 0.1)
16,115
18,071
19,833
21,745
21,685
(0.5, 0.5)
13,385
17,903
19,772
21,717
21,941
(1.0, 1.0)
13,383
17,911
19,668
21,794
21,753
Parameters and
In this part, both Type-I and Type-II data sizes are fixed as 50 MB. To study the effects of , several combinations of parameter and relaxation constraint are selected, increasing from 0.1 to 1.0, the entity extraction algorithm is executed and the time cost results are reported. As shown in Figure 8(a) and (b), as increases, the algorithm performances on the two data sets do not have significant change. Since is designed to affect the determination of whether an entity is interesting, whose result can hardly affect the time performance, the above observation is normal and expected. For , similar experiments are studied, and the results are shown in Figure 8(c) and (d). We have the similar observation that does not affect the efficiency performance significantly.
Scalability to and : (a) Type-I, (b) Type-II, (c) Type-I, and (d) Type-II.
Related work
CPS is thought to be the next generation paradigm of computing,12 which integrates the abilities of computational intelligence, communication, and control. Monitoring and controlling the world is the final target of CPS. To represent the physical world on cyber side, several kinds of methods appeared13 have proposed a model for describing the attributes of physical world from multiple dimensions; it supports the analysis of both local and global events,14 proposing a model for describing the physical entities from time and space views. Based on lattice theory, Tan et al.15 proposed a model for entity description which supports the compositions of different types of events. Based on the CPS data, the cyber side of CPS can achieve the intelligent management of CPS data, and lots of research work focus on this area. Based on the techniques of data management and wireless network, Kang and Son16 proposed a framework for data service which can integrate data management and network ability well. Loseu et al.17 consider the practical communication failure problem in CPS and propose a data management and analysis method supporting failure recovery. Besides the core problem of data management, Liu et al.18 identified other challenges of building the processing centers for CPS, including power management, network resource sharing, and so on. Also, Rao et al.19 and Parolini et al.20 proposed algorithms for power saving in data centers. For network management, the routing management problem is a key of CPS. For the selecting routing nodes problem in dynamic network settings, Lin21 proposed a practical method for network optimization which can decide the positions of routers and network connectivity by dynamic replacement of sensor nodes. By considering service priority of client nodes, Lin et al.22 proposed a simulation-based method to solve the router node replacement problem, Zhang et al.23 proposed a metric that can measure interference precisely among any set of paths in wireless sensor networks, even though these paths have some nodes or links in common, Zhang et al.24 proposed an efficient distributed algorithm to solve the MINimum-length-k-Disjoint-Paths (MIN-k-DP) problem in a sensor network. Entity based information management is a core problem of data management not limited to the area of CPS data management. One related area is entity identification which focus on how to extract entities from structured or non-structured data.25–27 In practical applications, more protocols28,29 are utilized in CPS to achieve efficient management of topology structures, which also needs further process of CPS data to extract entity based information and becomes another important motivation of this paper. The area of schema integration is also related to this paper, since it involves the problem of representing same entities using different organizations. To understand such different organizations, Spaccapietra and Parent30 extends the entity-relationship (ER) method to process the relationships between type, entity and attribute. Given the entities collected and the relations between them, sophisticated algorithms31–33 are proposed to distinguish entities. The relaxation techniques used in this paper also have been investigated very well. Fazzinga et al.34 considered the general definition for the relaxation problem, and proposed the concept of completeness for relaxation. Kanza and Sagiv35 considered the flexible and semi-flexible expression definition, which let the expressions can accept the complex schema of data. Koloniari and Pitoura36 considered the path expression relaxation problem. For the problem of security of the CPS and network resources consuming, Du et al.37 proposed an effective and efficient scheme that can defend such denial of service (DoS) attack on broadcast authentication. Yang et al.38 proposed a Polynomial-based Compromised-Resilient En-route Filtering scheme (PCREF), which can filter false injected data effectively and achieve a high resilience to the number of compromised nodes without relying on static routes and node localization. Zhang et al.39 proposed a Ring-based Privacy-Preserving Aggregation Scheme (RiPPAS) to resolve the data privacy problem in wireless sensor networks, and a publication method for histograms with outliers under differential privacy, Outlier-HistoPub, is proposed by Han et al.40 In practical applications,41,42 considering the security of implantable medical devices (IMDs), the writer designed a novel support vector machine (SVM)-based scheme to address the resource depletion (RD) attacks and the secure access control scheme based on basic biometric information of the patient and patient’s iris data. Smart grid is a new type of CPS that will provide reliable, secure, and efficient energy transmission and distribution. Lin et al.43 and Yang et al.44 proposed detection schemes to accurately identify attacks.
Conclusion
In this article, entity extraction problem is identified as an important problem to reduce the communication cost of extracting entities from CPS data. Based on the idea of using path expressions, a framework for entity extraction problem is proposed to explore the practical techniques. Using the relaxation and verification ideas, a formal definition of entity extraction problem is given in . An efficient automaton-based algorithm, IMP2E, is proposed as a practical implementation of . A detailed experimental study shows the effectiveness and efficiency of IMP2E on CPS data.
Footnotes
Academic Editor: Wei Yu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Grant No. 61502116) and the Fundamental Research Funds for the Central Universities (Grant No. HEUCFM160601).
References
1.
LiJChengSGaoH. Approximate physical world reconstruction algorithms in sensor networks. IEEE Trans Parallel Distr Syst2014; 25(12): 3099–3110.
2.
ChengSCaiZLiJ. Curve query processing in wireless sensor networks. IEEE Trans Veh Tech2015; 64(11): 5198–5209.
3.
ShiTChengSCaiZ. Adaptive connected dominating set discovering algorithm in energy-harvest sensor networks. In: Proceedings of the 35th annual IEEE international conference on computer communications (INFOCOM), San Francisco, CA, 10–14 April 2016, pp.1–9. New York: IEEE.
HeZCaiZChengS. Approximate aggregation for tracking quantiles in wireless sensor networks. In: Proceedings of the 8th international conference on combinatorial optimization and applications (COCOA’14), Maui, HI, 19–21 December 2014, pp.161–172. Springer International Publishing.
6.
HeZCaiZChengS. Approximate aggregation for tracking quantiles in wireless sensor networks. Theor Comput Sci2015; 607(3): 381–390.
7.
Amer-YahiaSChoSSrivastavaD. Tree pattern relaxation. In: Proceedings of the 8th international conference on extending database technology: advances in database technology (EDBT ’02), Prague, 25–27 March 2002, pp.496–513. London: Springer-Verlag, http://dl.acm.org/citation.cfm?id=645340.650237
8.
Amer-YahiaSLakshmananLVSPanditS. Flexpath: flexible structure and full-text querying for XML. In: Proceedings of the ACM SIGMOD international conference on management of data (SIGMOD ’04), Paris, 13–18 June 2004, pp.83–94. New York: ACM, http://doi.acm.org/10.1145/1007568.1007581
9.
DiaoYAltinelMFranklinMJ. Path sharing and predicate evaluation for high-performance xml filtering. ACM Trans Database Syst2003; 28(4): 467–516.
10.
BeitzelSM. On understanding and classifying web queries. PhD Thesis, Illinois Institute of Technology, Chicago, IL, 2006.
11.
LiXWangYYAceroA. Learning query intent from regularized click graphs. In: Proceedings of the 31st annual international ACM SIGIR conference on research and development in information retrieval (SIGIR ’08), Singapore, 20–24 July 2008, pp.339–346. New York: ACM, http://doi.acm.org/10.1145/1390334.1390393
12.
RajkumarRRLeeIShaL. Cyber-physical systems: the next computing revolution. In: Proceedings of the 47th design automation conference (DAC ’10), Anaheim, CA, 13–18 June 2010, pp.731–736. New York: ACM, http://doi.acm.org/10.1145/1837274.1837461
13.
TalcottC. Cyber-physical systems and events. In: WirsingMBanâtreJPHölzlM. (eds.) Software-intensive systems and new computing paradigms: challenges and vision. Berlin: Springer-Verlag, 2008, pp.101–115, http://dx.doi.org/10.1007/978-3-540-89437-7_6
14.
TanYVuranMCGoddardS. Spatio-temporal event model for cyber-physical systems. In: Proceedings of the 29th IEEE international conference on distributed computing systems workshops (ICDCSW ’09), Montreal, QC, Canada, 22–26 June 2009, pp.44–50, Washington, DC: IEEE Computer Society, http://dx.doi.org/10.1109/ICDCSW.2009.82
15.
TanYVuranMCGoddardS. A concept lattice-based event model for cyber-physical systems. In: Proceedings of the 1st ACM/IEEE international conference on cyber-physical systems (ICCPS ’10), Stockholm, 13–15 April 2010, pp.50–60. New York: ACM, http://doi.acm.org/10.1145/1795194.1795202
16.
KangKDSonSH. Real-time data services for cyber physical systems. In: Proceedings of the 28th international conference on distributed computing systems workshops (ICDCSW ’08), Beijing, China, 17–20 June 2008, pp.483–488. Washington, DC: IEEE Computer Society, http://dx.doi.org/10.1109/ICDCS.Workshops.2008.21
17.
LoseuVGhasemzadehHJafariR. Toward power optimization for communication failure recovery in body sensor networks. In: Proceedings of the 1st ACM/IEEE international conference on cyber-physical systems (ICCPS ’10), Stockholm, 13–15 April 2010, p.198. New York: ACM, http://doi.acm.org/10.1145/1795194.1795222
18.
LiuJZhaoFLiuX. Challenges towards elastic power management in Internet data centers. In: Proceedings of the 29th IEEE international conference on distributed computing systems workshops (ICDCSW ’09), Montreal, QC, Canada, 22–26 June 2009, pp.65–72. Washington, DC: IEEE Computer Society, http://dx.doi.org/10.1109/ICDCSW.2009.44
19.
RaoLLiuXIlicM. MEC-IDC: joint load balancing and power control for distributed internet data centers. In: Proceedings of the 1st ACM/IEEE international conference on cyber-physical systems (ICCPS ’10), Stockholm, Sweden, 13–15 April 2010, pp.188–197. New York: ACM, http://doi.acm.org/10.1145/1795194.1795220
20.
ParoliniLToliaNSinopoliB. A cyber-physical systems approach to energy management in data centers. In: Proceedings of the 1st ACM/IEEE international conference on cyber-physical systems (ICCPS ’10), Stockholm, 13–15 April 2010, pp.168–177. New York: ACM, http://doi.acm.org/10.1145/1795194.1795218
21.
LinCC. Dynamic router node placement in wireless mesh networks: a PSO approach with constriction coefficient and its convergence analysis. Inf Sci2013; 232: 294–308, http://dx.doi.org/10.1016/j.ins.2012.12.023
22.
LinCCShuLDengDJ. Router node placement with service priority in wireless mesh networks using simulated annealing with momentum terms. IEEE Syst J2016; 10(4): 1402–1411.
23.
ZhangKHanQCaiZ. DOAMI: a distributed on-line algorithm to minimize interference for routing in wireless sensor networks. Theoretical Computer Science. Epub ahead of print 6June2016. DOI: 10.1016/j.tcs.2016.05.043.
24.
ZhangKHanQYinG. OFDP: a distributed algorithm for finding disjoint paths with minimum total length in wireless sensor networks. J Combin Optim2016; 31(4): 1623–1641.
25.
SarawagiSBhamidipatyA. Interactive deduplication using active learning. In: Proceedings of the eighth ACM SIGKDD international conference on knowledge discovery and data mining (KDD ’02), Edmonton, AB, Canada, 23–26 July 2002, pp.269–278. New York: ACM, http://doi.acm.org/10.1145/775047.775087
26.
CochinwalaMKurienVLalkG. Efficient data reconciliation. Inform Sci2001; 137(1–4): 1–15.
27.
AnanthakrishnaRChaudhuriSGantiV. Eliminating fuzzy duplicates in data warehouses. In: Proceedings of the 28th international conference on very large data bases (VLDB ’02), Hong Kong, China, 20–23 August 2002. pp.586–597, http://dl.acm.org/citation.cfm?id=1287369.1287420
28.
QiuTLiuXFengL. An efficient tree-based self-organizing protocol for Internet of things. IEEE Access2016; 4: 3535–3546.
SpaccapietraSParentC. View integration: a step forward in solving structural conflicts. TKDE1994; 6(2): 258–274.
31.
PalopoliLSaccaDUrsinoD. Semi-automatic, semantic discovery of properties from database schemes. In: Proceedings of the international symposium on database engineering and applications (IDEAS ’98), Cardiff, 8–10 July 1998, p.244. Washington, DC: IEEE Computer Society, http://dl.acm.org/citation.cfm?id=551941.857554
FazzingaBFlescaSFurfaroF. XPath query relaxation through rewriting rules. IEEE T Knowl Data Eng2011; 23(10): 1583–1600.
35.
KanzaYSagivY. Flexible queries over semistructured data. In: Proceedings of the twentieth ACM SIGMOD-SIGACT-SIGART symposium on principles of database systems (PODS ’01), Santa Barbara, CA, 21–23 May 2001, pp.40–51. New York: ACM, http://doi.acm.org/10.1145/375551.375558
36.
KoloniariGPitouraE. Distributed structural relaxation of XPath queries. In: Proceedings of the IEEE 25th international conference on data engineering (ICDE ’09), Shanghai, China, 29 March–2 April 2009, pp.529–540. Washington, DC: IEEE Computer Society, http://dx.doi.org/10.1109/ICDE.2009.110
37.
DuXGuizaniMXiaoY. Defending DoS attacks on broadcast authentication in wireless sensor networks. In: Proceedings of the IEEE international conference on communications (ICC’08), Beijing, China, 19–23 May 2008, pp.1653–1657. New York: IEEE.
38.
YangXLinJYuW. A novel en-route filtering scheme against false data injection attacks in cyber-physical networked systems. IEEE T Comput2015; 64(1): 4–18.
39.
ZhangKHanQCaiZ. RiPPAS: a ring-based privacy-preserving aggregation scheme in wireless sensor networks. Sensors2017; 17(2): 300.
40.
HanQShaoBLiL. Publishing histograms with outliers under data differential privacy. Secur Comm Network2016; 9(14): 2313–2322.
41.
HeiXDuX. Biometric-based two-level secure access control for implantable medical devices during emergencies. In: Proceedings of the IEEE INFOCOM, Shanghai, China, 10–15 April 2011, pp.346–350. New York: IEEE.
42.
HeiXDuXWuJ. Defending resource depletion attacks on implantable medical devices. In: Proceedings of the IEEE global telecommunications conference (GLOBECOM 2010), Miami, FL, 6–10 December 2010, pp.1–5. New York: IEEE.
43.
LinJYuWYangX. On false data injection attacks against distributed energy routing in smart grid. In: Proceedings of the IEEE/ACM third international conference on cyber-physical systems, Beijing, China, 17–19 April 2012, pp.183–192. New York: IEEE Computer Society.
44.
YangQYangJYuW. On false data-injection attacks against power system state estimation: modeling and countermeasures. IEEE Trans Parallel Distr Syst2014; 25(3): 717–729.