
Abstract
Effective power management has become a key concern in the design of wireless sensor networks. Dynamic power management refers to strategies which selectively switch between several power states of a device during the runtime in order to achieve a tradeoff between power consumption and performance. In this article, we present a novel methodology that exploits current model-checking technology for automatic synthesis for dynamic power management. The generic system model for dynamic power management is modeled as a network of timed games. And the synthesis objectives are expressed as synthesis queries. Subsequently, automatic synthesis of power management strategies is performed by UPPAAL-STRATEGO with respect to the synthesis queries. Once a strategy has been constructed, its performance can be analyzed through statistical model-checking using the same tool. The modeling and synthesizing procedures are illustrated with a running example. Finally, the applicability of the methodology is assessed by synthesizing and evaluating a range of power management strategies for a concrete sensor node. Our methodology can be employed to help designers in constructing dynamic power management strategies for wireless sensor networks in practical applications.
Keywords
Introduction
Wireless sensor networks (WSNs) are one of the technologies that are gaining considerable attention. They are composed of distributed autonomous nodes which are capable of organizing themselves to establish a network and carry out reliable sensing. However, when considered individually, each node is a simple device. A wireless sensor node is typically battery-powered and therefore energy constrained. Thus, the reduction of power consumption is crucial to increase the lifetime of a sensor node. The problem of reducing power consumption of WSNs has been addressed in two different ways in the literature. First, a mass of energy-efficient communication protocols that take the peculiarities of WSNs into account have been proposed. Second, local dynamic power management (DPM) strategies are developed to reduce the power consumption within an individual node. In this article, we focus on the second approach and consider the individual sensor node as a power-managed device.
Numerous DPM techniques have been proposed,1–6 in order to achieve an optimal tradeoff between power consumption and performance in general battery-powered embedded systems. DPM refers to strategies which selectively switch between several power states of a device during the runtime in order to minimize power consumption, in the meantime guarantees the performance constraints or vice versa. 4 A device may have several operational states that are characterized by a service rate and a power consumption value. The power manager is a controller that controls the transitions between these operational states. The criterion used for making state transition decisions is called power management strategy. The design problem is to formulate a strategy for transitioning between states so as to maximize energy efficiency. The best known standard for low-power hardware and software design is ACPI (Advanced Configuration and Power Interface), 4 which introduces an abstract and flexible interface between the power-manageable components and the power manager. However, ACPI does not provide insight into constructing the power management strategy. The power-aware sensor model is similar to the system power model in the ACPI, which has been studied in Benini et al. 1
The previous works on constructing DPM strategy are based on analytical approaches, such as linear programming1,7 and reinforcement learning–based methods.3,8 The analytical approaches require a mathematical modeling of the system, which is an intricate process. Thus, their complexity results in poor usability that impedes them from practical usage. In addition, the analytical approaches are based on Markov models (Markov chain or Markov decision process), one key assumption made by the Markov models is that the transitions between the states follow the exponential distribution. However, the reality is not always the case, and it has been proven that potential errors would be made if the transitions between states were approximated using the exponential distribution. 9 The learning-based approaches demand a large number of training examples to construct the strategy which is time-consuming, and they require offline data collection.
Automatic synthesis is a recent research direction in the field of model-checking.10,11 In the setting of automatic synthesis, the controller is regarded as a controllable player, and the environment is regarded as another uncontrollable player (or a set of players). The specification is cast as a game objective that should be enforced by the controlled player at all the time. Thus, strategy synthesis is the process of constructing a winning strategy for the controller that will satisfy the desired objective in an adversarial environment. Benefit from the development of several tools (such as UPPAAL-TIGA, 12 UPPAAL-STRATEGO, 13 and PRISM-games14,15) is that strategy synthesis has been applied successfully to the real-life case studies.16–18
The scientific contribution of this article can be summarized as follows:
We present a novel methodology for DPM, which is based on current model-checking technology for automatic synthesis. It illustrates the applicability of automatic synthesis to the area of DPM. We illustrate the system modeling procedure and query formulating process, and show how UPPAAL-STRATEGO can be used to generate the optimal strategy. To the best of our knowledge, this is the first research effort in synthesizing power management strategies with model-checking technology.
The generic system model for DPM 1 is modeled in the form of timed games, and the modeling procedure is illustrated with a running example, so that other systems can be handled in a similar manner.
The strategy synthesis and evaluation queries are presented. The strategy synthesis queries are utilized for generating strategies, and they provide a flexible way to express the requirement of power-performance tradeoff. And the strategy evaluation queries are utilized for verifying and evaluating the generated strategies.
The applicability of the methodology is assessed by synthesizing and evaluating several power management strategies for a concrete sensor node. And the efficiency of the synthesized strategies is demonstrated by comparing them with realistic strategies.
Our methodology can be used to help designers in constructing effective power management strategies.
There are several advantages of our methodology. It assists in designing power management strategies with the recent branch of the UPPAAL tool suite, UPPAAL-STRATEGO, which supports for automatic synthesis of safe and near-optimal strategies using a combination of symbolic synthesis and reinforcement learning. Symbolic synthesis is exhaustive in state-space searching that guarantees the generated strategies are safe. And the learning algorithm uses a simulation-based method for learning near-optimal strategies for a given price metric. Afterwards, the synthesized strategies can be analyzed through statistical model-checking with the same tool, which avoids extensive simulation. Compared with the analytical approaches, our modeling procedure is more intuitive, that is, modeling the system with timed games is relatively easier than formulating that with mathematical formulas. The default uniform and exponential distribution are available in UPPAAL-STRATEGO. What’s more, one can encode any distribution into the model with the help of user-defined functions. UPPAAL-STRATEGO automatically utilizes the reinforcement learning approach to generate the optimal strategies and do not require additional tool support. In addition, the synthesized strategies can be analyzed with the same tool, which avoids extra prototyping and measurement using a specific simulator.
This article is organized as follows. In section “DPM,” we give a short introduction of the DPM problem. In section “Timed games, synthesis, and UPPAAL-STRATEGO,” we present the definition of timed games and synthesis, and then introduce the UPPAAL-STRATEGO tool. In section “Strategy synthesis for DPM with UPPAAL-STRATEGO,” we illustrate our methodology with a running example. In section “Sensor node case study,” we apply our methodology to a concrete sensor node. In section “Related work,” we review related work in the field of DPM and strategy synthesis. Finally, section “Conclusion” concludes this article.
DPM
DPM exploits the fact that certain devices may have several operational states that have different service rate and power consumption value, so they could be switched into low-power states during inactive periods to save energy. However, when a service request arrives, the device needs to be brought back into the active state, and this transition incurs additional latency. The low-power state saves more energy, but leads to higher transition latency at the same time. Therefore, it is an elaborate work to make decisions on when and which transition should be enforced.
The generic system model for DPM was originally proposed in Benini et al. 1 This model, as depicted in Figure 1, consists of four components: Service Requester (SR), Service Queue (SQ), Service Provider (SP), and Power Manager (PM). The SR represents the application that generates requests for the SP, for example, data transfer. The SQ stores requests that cannot be serviced immediately. The SP is the request-processing device (i.e. the sensor node in WSN) that is under power manager control. The PM issues state transition commands to the SP, based on observations of the system and the DPM strategy.

Generic DPM model.
It has been proven that DPM is an effective way for reducing the power consumption in computing systems.2,3 According to the level (e.g. component and system) that the DPM is applied, DPM can have different embodiments. And DPM can be classified into timeout, predicative, stochastic, and machine-learning approaches. Timeout strategy2,8 switches a device to a low-power state after it has been idle for a certain time period. Timeout strategy is easy to implement, but the drawback of this strategy is that it wastes power while waiting for the timeout to expire. Predictive strategies2,19,20 forecast the length of idle periods based on the history of past idle periods, and switch the device to a low-power state if the predicted idle period is longer than a certain threshold. Predictive strategies do address workload uncertainty, but an incorrect estimate can cause both performance and energy penalties. Both timeout and predictive strategies are heuristic in nature and, thus, do not provide mechanisms for controlling the power-performance tradeoff. 9 Stochastic strategies1,7,9 are based on stochastic models that can guarantee optimal results, and they do provide a flexible way to control the power-performance tradeoff. However, solving the stochastic optimization problem to find the optimal DPM strategy with linear programming is a complex process. Machine-learning strategies3,8 apply machine learning to learn the request arrival patterns for DPM; they perform well under various workload conditions. But these strategies require offline data collection and training of a classifier that is a time-consuming and complex work.
We present an alternative methodology to the above-mentioned problems, which is based on current model-checking for automatic synthesis. Benefit from the user-friendly interface of UPPAAL-STRATEGO 13 is that the power management problem can be formulated in a convenient manner, and the optimal strategies will be automatically obtained in the sequel. Our methodology provides a flexible way to control the power-performance tradeoff, and with the system model and queries as inputs, the optimal strategies are automatically generated without any complex calculation or data collection. In general, our methodology belongs to stochastic strategies since it is based on stochastic modeling of the system. However, model-checking technology is utilized for generating the optimal strategies instead of linear programming in our methodology, which reduces the complexity of the problem formulation and increases the scalability of our methodology.
Timed games, synthesis, and UPPAAL-STRATEGO
Let X be a finite set of real-valued variables called clocks. We define
L is a finite set of locations;
X is a finite set of real-valued clocks;
if
and if
UPPAAL
21
is an integrated tool environment for modeling, validation, and verification of real-time systems. UPPAAL-STRATEGO
13
is a novel branch of UPPAAL tool suite, which integrates UPPAAL and two branches UPPAAL-SMC
21
(statistical model-checking), UPPAAL-TIGA
12
(synthesis for timed games), and the method proposed in David et al.
22
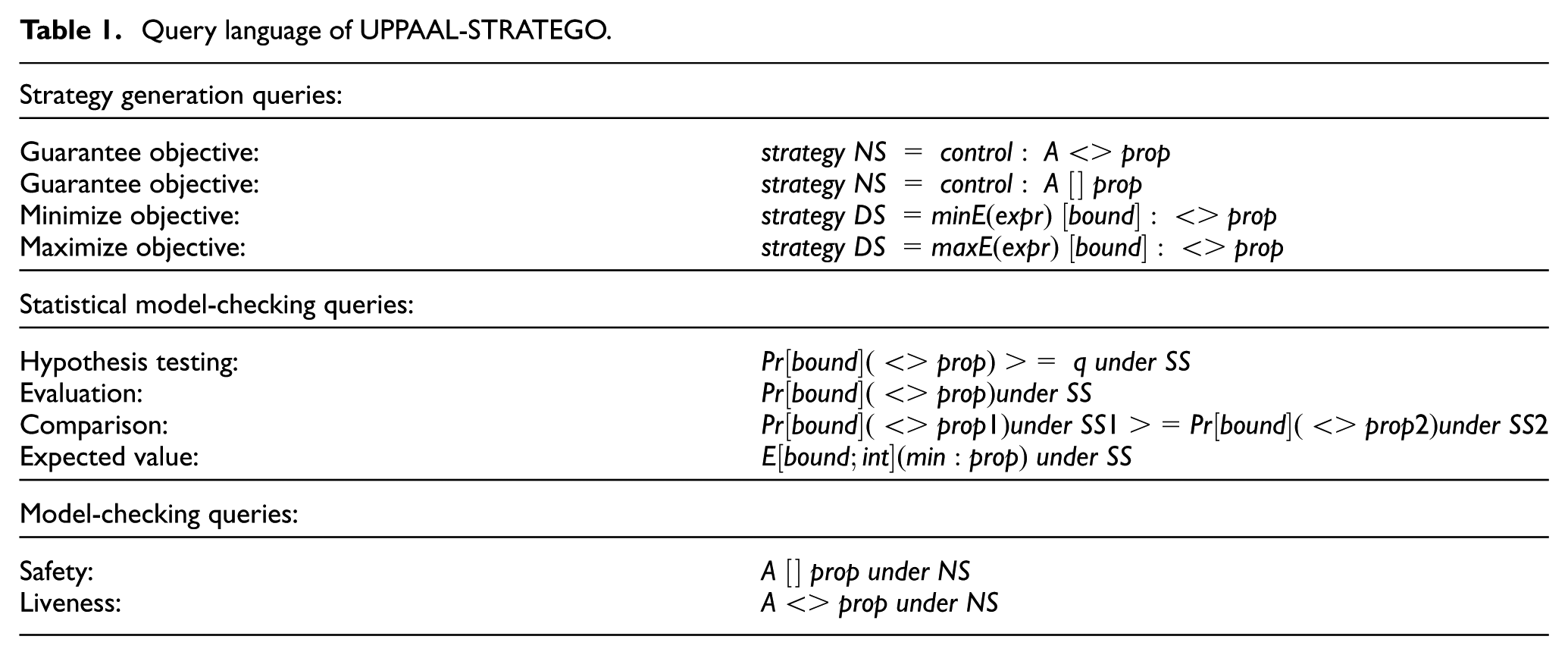
(synthesis for near-optimal schedulers) into one tool suite. UPPAAL-STRATEGO combines these techniques to generate, optimize, compare, and explore consequences and performance of strategies synthesized for stochastic timed games in an user-friendly manner. UPPAAL-STRATEGO comes with an extended query language (see Table 1), in which strategy assignment is expressed as
Query language of UPPAAL-STRATEGO.
Strategy synthesis for DPM with UPPAAL-STRATEGO
In this section, we use a four-state device power management problem as a running example to illustrate our methodology. We model the problem, explain the procedure, and show how UPPAAL-STRATEGO can be used to solve the problem.
Illustration of the methodology
In this subsection, we introduce our methodology briefly. The block diagram of our methodology is shown in Figure 2. What should be emphasized is that the shaded blocks represent manual steps, while white boxes are fully automated steps. That is, the translations of the description and specifications are done manually.

Block diagram of our methodology.
The idea of DPM strategy synthesis with UPPAAL-STRATEGO is to model the service requests arrival scenario and the WSN systems with timed games, and to leave the switching decisions between states open (modeled as controllable transitions in timed games). Then formulates the optimal objective as a synthesis query. Subsequently, UPPAAL-STRATEGO can be utilized to construct the strategy with respect to the synthesis query. Specifically, for a given service requests arrival scenario and sensor node configuration, UPPAAL-STRATEGO manipulates the controllable transitions to control the switching between the power states. After random simulations and reinforcement learning process, UPPAAL-STRATEGO provides a guidance to manipulate the controllable transitions so that the power consumption of the sensor node can be minimized, which is referred to as the optimal DPM strategy.
Our methodology requires three inputs: a system description, a strategy specification (specifies the strategic requirements, for example, minimizing the power consumption under performance constraints), and a performance specification. The system description provides the information needed to formulate the system model, such as the service rate and the power consumption value. The system is specified as a set of timed games that associated with the system parameters. Besides, the synthesis specifications are expressed as the synthesis queries. With the system model and queries as inputs, the tool automatically generates the strategy (if exists) and satisfies the requirement; otherwise, it reports the requirement cannot be satisfied.
Once a strategy has been constructed, it can be analyzed through statistical model-checking with respect to the strategy evaluation queries that translated from the performance specifications. With the results provided by the tool, further analysis and comparison can be accomplished.
Modeling DPM in UPPAAL-STRATEGO
We adopt the generic system model for DPM proposed in Benini et al., 1 which has been introduced in section “DPM”. In this subsection, we describe the modeling procedure of this model in detail. The modeling procedure is described through a four-state device, which has also been used as a case study in Qiu et al. 7 and Simunic et al. 9
The device has four states: Active, Idle, Standby, Sleep. The Active state is the only state that the device can provide service (with a service rate of 125), and Idle is the state that the device is active but has no request in the system. When the SP is in the Standby or Sleep state, it is inactive and working in a low-power model. The SP makes transitions automatically between the Idle and Active states. The transitions between the
Average power consumption for each state of the SP.

The average power consumption and the average times to translate between each pair of states are shown in Tables 3 and 4, respectively. In addition, it has been observed in Simunic et al.
9
that the transitions between the states of this device are best described using uniform distribution. And the transition times from the Sleep and Standby states into the Idle state have a deviation of
Average power consumption for state transitions of the SP.

Average transition times between the states of the SP.

The service requests arrival scenario has also been observed in Simunic et al.,
9
the requests inter-arrival time in the active state (the state where one or more requests in the service queue) follows the exponential distribution, and that follows the Pareto distribution during the idle periods. Specifically, the inter-arrival time in active state follows an exponential distribution with the mean value
Modeling the service requester
The SR generates requests according to the specific scenario, as shown in Figure 3. Initially, the SR stays in the Idle state, and the actual delay in this state is computed and stored into a clock delay. The function

Model of the service requester.
Modeling the service queue
The SQ is modeled as a timed game with a parameter QUEUESIZE that indicates the maximum length of the queue, as shown in Figure 4. Initially, the SQ stays in the Empty state until a request arrives, after that the SQ moves to the Queue state. Thereafter, with every arrival of a request, the variable count increases by 1 up to the capability of the queue. Whenever the number of enqueued requests exceeds the capability, the requests are lost, and the number of lost requests is recorded by lostCount. Whenever a request is fetched, count decreases by 1, until the queue is empty, and the SQ moves back to the Empty state. Note that the variable totalDelay records the total waiting time of all the requests, thus it has a growth rate equals to count that is the current number of requests in the queue.

Model of the service queue.
Modeling the service provider
The SP is modeled as a timed game, as shown in Figure 5, in which the solid lines indicate the controllable transitions that may be triggered by the PM, and the dashed lines indicate the uncontrollable transitions.
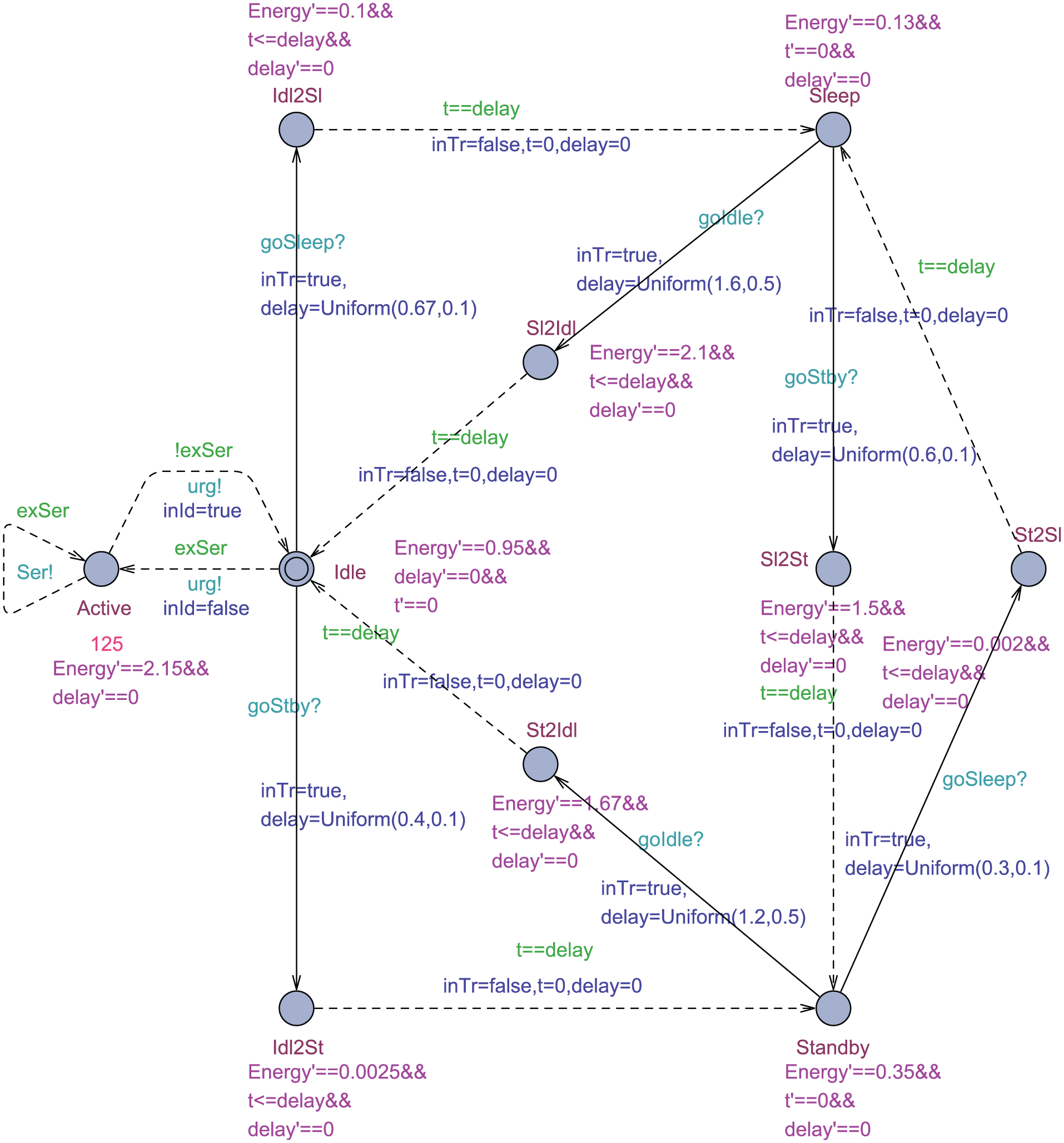
Model of the service provider.
As shown in Figure 5, the four operational states of the SP are modeled as locations in the timed game, and the transient states (
What’s more, each state is associated with a power consumption value. It represents the power consumption of the SP during the time it occupies the state. The automation has one continuous variable Energy which records the total amount of energy used by the SP.
Modeling the power manager
The PM controls the SP to translate between the low-power states by issuing a command

Model of the power manager.
Strategy synthesis with UPPAAL-STRATEGO
In this subsection, we introduce the synthesis queries in detail. Intuitively, the strategy synthesis should carry over an infinite time horizon. However, the reality is not exactly the case. The system lifetime is limited by the battery capability. This is the case of our assumption, where the time span of synthesis is a finite time window. Hence, we assume the system is not operating over an infinite horizon, but only over a finite time scope BOUND.
There are two kinds of constraints, namely, performance constraint and energy constraint, which may be involved in specifying the synthesis specification. We believe that, in order to devise an efficient power management strategy, the performance constraint should be considered, especially in sensor networks that strongly depend on an application. Performance constraint consists of three constraints including the service lost ratio, the average queue size, and the average waiting time in the queue. And the Energy constraint is represented by the energy consumption of the system by time BOUND. The constraints can be formulated with the following formulas with the variables in the model:
Energy consumption constraint:
Service lost ratio constraint:
Average queue size constraint:
Average waiting time in the queue constraint:
In which,
With the combination of the performance constraint and power constraint, we can formulate two kinds of the constrained optimal strategy synthesis problem: performance optimization under energy constraint and energy optimization under performance constraint. We only list out two queries in the following, other queries can be specified in a similar manner.
Minimizing the service lost ratio under the energy constraint

where
Minimizing the energy consumption under the average queue size constraint
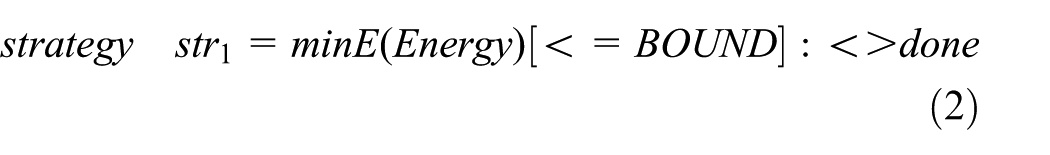
where
Strategy evaluation with UPPAAL-STRATEGO
Once a strategy has been constructed, it can be analyzed through statistical model-checking approach. We use the average queue size as the primary performance metric and the average power consumption as the power metric, and set the time horizon
The first question we could ask is what the probability that the synthesized strategy satisfies the desired constraint. We use the strategy generated with “minimizing the energy consumption, meanwhile, guaranteeing the average queue size is smaller than 1.0” as an example, that is
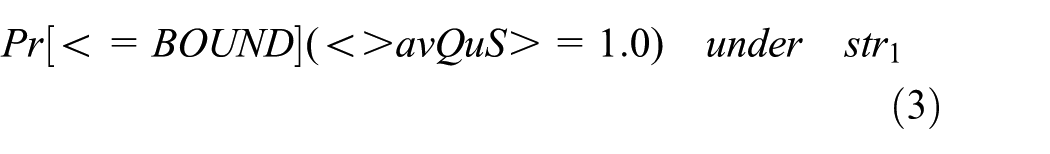
The probability is in the interval
In order to quantify the performance of the synthesized strategies, we compare them with the existing strategies. We modeled the following strategies for comparison, which have also been used in Benini et al. 1 and Qiu et al. 7
Timeout strategy: the PM switches the SP from Idle to Sleep after the SP has been in the Idle state for a time period
N strategy: the PM switches the SP from Idle to Sleep immediately after the SQ is empty. And the PM switches the SP from Sleep to Idle only after there are more than N requests waiting in the SQ. N is varied in the range of [1,10] during the experiments.
Greedy strategies: the PM switches the SP from Idle to the low-power states (Sleep or Standby state) immediately when the SP is in the Idle state and the SQ is empty, and switches the SP back to Idle after a request arrived.
In order to compare the strategies, we evaluate the performance metric and power metric under different strategies. We find the mean value of the metrics from a number of runs N(
Average power consumption:
Service lost ratio:
Average queue size:
Average waiting time in the queue:
The power-performance tradeoff curves for the DPM strategies are shown in Figure 7, and the average waiting time in the queue under the corresponding strategies is shown in Figure 8, note that the X-axis is log scaled. In addition, the service lost ratio is 0 under all the DPM strategies, thus we omit the corresponding figure here. This is because the service queue is long enough to buffer the requests until the SP can switch back to the Active state.

Power-performance tradeoff curves for the DPM strategies.

Average waiting time in the queue under the DPM strategies.
From Figures 7 and 8, we have the following conclusions. In most situations, the synthesized strategies outperform the existing strategies. The synthesized strategies provide a good power-performance tradeoff. And the existing strategies such as the timeout strategy cannot always provide a valid tradeoff. That is, in the experiments, decreasing the timeout threshold
Sensor node case study
We have illustrated our methodology with a running example. In this section, we demonstrate the applicability of the methodology to a concrete sensor node, which has also been used in Draeger et al. 23 Compared with the running example, the model of the sensor node has more transitions that can be controlled by the PM, and the service requests arrival scenario is different. In addition, the transitions between the states are assumed to follow the exponential distribution. We present this case system as a pilot study, so that other WSNs can be handled in a similar manner.
The sensor can operate in five different operational states, labeled,
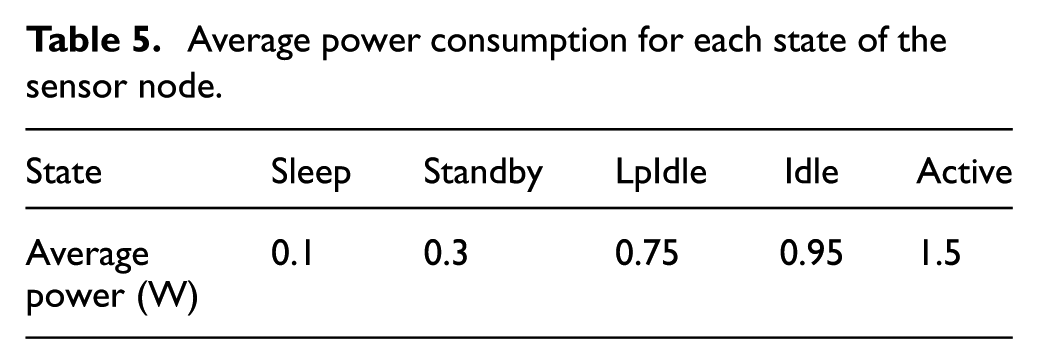
Average power consumption for each state of the sensor node.
Average transition times between the states of the sensor node.

What’s more, the service requests arrival scenario is obtained based on time-stamped traces measured on real machines and profiling. The SR has two states: Idle where no request is generated and Req where one request is generated per time step (1 s). The probabilities of the transitions between the two states are described with a matrix as follows

Note that the transitions between the states are assumed to follow the exponential distribution in Draeger et al., 23 we follow this assumption when modeling the SR, SP, and PM. According to the proposed methodology, the model of the SR, SP, and PM are shown in Figures 9–11, respectively, and the model of the SQ is the same as the one introduced in the third section.

Model of the service requester for the sensor node.

Model of the service provider for the sensor node.

Model of the power manager for the sensor node.
Apart from the simple strategies introduced in section “Timed games, synthesis, and UPPAAL-STRATEGO,” we add several realistic strategies for comparison. The involved strategies are the adaptive timeout strategy of Shih and Wang,
20
the predictive strategy of Hwang et al.,
19
the stochastic strategy of Benini et al.,
1
and the reinforcement learning strategy of Triki et al.
24
(“RL” in the figures). Note that we employ a heuristic timeout strategy instead of the original timeout strategy, so that multiple low-power states can be utilized. What’s more, since the capacity of the service queue is small, the service lost ratio could be a serious constraint. We add the “UPPAAL-Con” strategy in the experiments, which is generated with “minimizing the power consumption, meanwhile, guaranteeing the average queue size is smaller than Q and the service lost ratio is smaller than 0.005,” that is,
The power-performance tradeoff curves for the DPM strategies are shown in Figure 12; the average waiting time in the queue under the corresponding strategies is shown in Figure 13; and the service lost ratio under the corresponding strategies is shown in Figure 14 (the Y-axis is also log scaled in this figure).

Power-performance tradeoff curves for the DPM strategies upon the sensor node.

Average waiting time in the queue under the DPM strategies upon the sensor node.
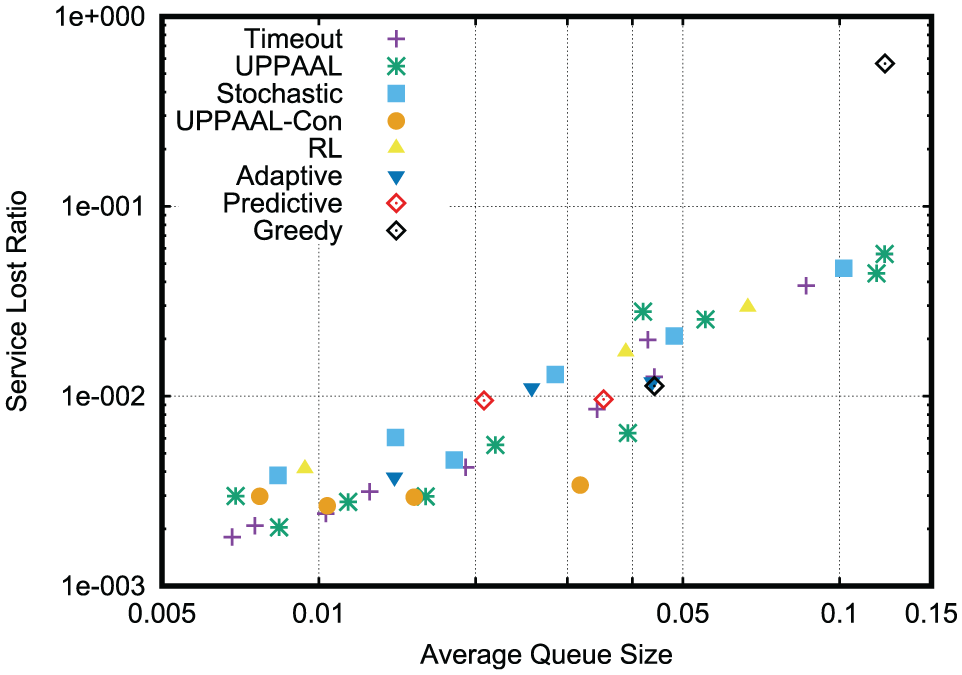
Service lost ratio under the DPM strategies upon the sensor node.
From the figures, we have the following conclusions. It can be observed that when the average queue size is small (smaller than 0.02), the performance difference among the DPM strategies is not obvious. This is because, in order to achieve the desired performance metric, the SP seldom moves to the low-power states (Standby and Sleep states). Thus, all the DPM strategies have a similar behavior. The synthesized strategies outperform the timeout strategies and the stochastic strategies, especially when the average queue size is bigger than 0.05. And the synthesized strategies have comparable performance to the realistic strategies. We remark, however, the realistic strategies do not take the performance constraints into account. That is, the corresponding strategy construction approaches do not allow the designer to automatically contain the performance constraints when constructing the strategies. Thus, the constructed strategies may violate the constraints. Note that UPPAAL-Con strategy has a higher power consumption than the remaining strategies when the average queue size is approximately 0.03. This is the consequence of the requirement of the service lost ratio should be smaller than 0.005. This is also the reason for the absence of the UPPAAL-Con strategy when the average queue size is larger than 0.04. Therefore, it can be observed that the service lost ratio under the UPPAAL-Con strategy is smaller than that under the remaining strategies when the average queue size is approximately 0.03. And as the average queue size increases, the service queue has a higher probability to be full that leads to a higher service lost ratio, thus there exists an obvious tendency in Figure 14.
Related work
Simunic et al. 9 provided a comprehensive assessment of state-of-the-art of DPM in WSNs. The aspects of power dissipation in a node are investigated, which consists of the power dissipated by the processor subsystem, communication subsystem, communication interfaces, and memory. Then, the strength and limitations of selective switching and dynamic scaling are investigated. Finally, some concerns in the implementation of the DPM techniques are proposed. This article presents a complete investigation of DPM in WSNs; our work is inspired by this article.
Benini et al. 1 proposed a stochastic model for the formulation of DPM policy optimization based on Markov decision process. The policy optimization is cast into a linear programming problem. This problem is solved in polynomial time by efficient interior point algorithms. They demonstrate the flexibility of the approach with three case studies belonging to different classes of systems.
Qiu et al. 7 formulated the system-level power management problem as an optimal policy selection problem based on the theories of continuous-time Markov decision process and stochastic networks. And the problem is solved by using linear programming and policy iteration. They solve the problem in continuous time domain instead of discrete time domain, which increases the accuracy. In addition, they consider the priority queue model that extends the scalability.
The above two articles deal with the DPM problem as an optimization problem, and solve this problem using linear programming. Linear programming is a reasonable way to solve this problem; however, it requires a mathematical model as an input, which is a complex and non-trivial work that limits its feasibility. In addition, they assume the transitions between the states follow the exponential distribution, that does not give an accurate representation of the real system.
Norman et al. 25 illustrated the applicability of probabilistic model-checking to the area of DPM analysis. They model the system with the PRISM language in the form of DTMC and CTMC. After that, the optimization problem is passed to the MAPLE symbolic solver. The policies are automatically constructed with the solver. Once a policy has been constructed, its performance can be analyzed with the PRISM model checker. Irani et al. 26 studied the adversarial modeling approach for power management, and stochastic model-checking for the evaluation of the effectiveness of DPM algorithms. In addition, Sesic et al. 27 extended the work of Norman et al. 25 with two different request priorities. Their works can be generalized to multiple request priorities and different queue length.
These works are similar to our approach; however, we apply the automatic synthesis approach to constructing the strategy, and they use an external symbolic solver to construct the strategy. They translate the results provided by the solver into the PRISM model in order to quantify the performance of the constructed strategies. By contrast, we employ only one tool to synthesize and evaluate the strategies, and no translation is required during the process.
Larsen et al. 17 illustrated the usability of UPPAAL-STRATEGO for automatic synthesis of the optimal yet safe controller. They demonstrated the applicability on an Adaptive Cruise Control problem. They model the system components in the form of stochastic-priced timed games. Afterwards, UPPAAL-STRATEGO is used for strategy synthesis and analysis.
Wognsen et al. 28 proposed a wear score function to compare and evaluate the relative impact of usage profiles on battery deteriorate. The system is modeled as a network of stochastic-weighted timed games. With the combination of wear score function with the system model, and then subjected to UPPAAL-STRATEGO for optimization using reinforcement learning. So that they examine the tradeoff between short-term dynamic payload selection and the operational life of the battery.
Larsen et al. 18 suggested a general and scalable methodology for controller synthesis for hybrid switched systems. They proposed an online synthesis methodology instead of offline synthesis, which periodically computes the controller only for the near future. What’s more, they propose and apply a compositional synthesis approach that improves the scalability. Finally, they demonstrate the applicability of the methodology with a case study to a floor-heating system of a real family house.
Applying model-checking for strategy synthesis has become a hot topic in recent years. These works are similar to our work, except that they deal with the different problems.
Conclusion
Optimizing power management is a critical issue in WSNs. In this article, we proposed a novel methodology for synthesizing near-optimal power management strategies for individual sensor node. The individual sensor node is regarded as a power-managed device. The generic system model for DPM was modeled in the form of timed games. And the synthesis objectives were expressed as the synthesis queries. Subsequently, a range of near-optimal strategies were constructed using UPPAAL-STRATEGO with respect to the synthesis queries. Once a strategy has been constructed, it was analyzed by the same tool. The methodology was illustrated with a running example, and its applicability was demonstrated by synthesizing a range of power management strategies for a concrete sensor node.
Our further work includes utilizing the online synthesis to extend the time horizon that can be handled. And it is possible to apply compositional synthesis to improve scalability. We are also considering applying our methodology to the systems that consist of multiple service queues and sensors. What’s more, investigating the impact of the local decisions made by a node upon the global WSN with statistical model-checking could be a potential research direction.
Footnotes
Academic Editor: Maio Jin
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the State Key Program of National Natural Science Foundation of China under grant no. 61332001, the National Natural Science Foundation of China under grant no. 61272104, and the Basic Research For Application Foundation of Sichuan Province under grant no. 2014JY0112.