
Abstract
In order to reduce the time complexity of situation element acquisition and to cope with the low detection accuracy of small class samples caused by imbalanced class distribution of attack samples in wireless sensor networks, a situation element extraction mechanism based on deep auto-encoder network is proposed. In this mechanism, the deep auto-encoder network is introduced as basic classifier to identify data type. In hierarchical training of the auto-encoder, a training method based on cross-entropy loss function and back-propagation algorithm is proposed to overcome the problem of weights updating too slow by the traditional variance cost function, and the momentum factors are added to improve the convergence performance. Meanwhile, in the stage of fine-tuning and classification of the deep network, an active online sampling algorithm is proposed to select the sample online for updating the network weights, so as to eliminate redundancy of the total samples, balance the amounts of all sample types, and improve the classification accuracy of small sample. Through the simulation and analysis of the instance data, the scheme has a good accuracy of situation factors extraction.
Keywords
Introduction
The wireless sensor network (WSN) integrates a variety of technologies. It can support some applications more intelligently and flexibly than traditional networks. Therefore, it has a wide range of applications, such as battlefield sensing, environmental monitoring, and intrusion detection. With the deep research and gradual application of WSN, the security is a major problem, and a good security defense mechanism can prevent the leakage of important military or technological information. The inherent openness of WSNs and storage mode of the sensor nodes make the network vulnerable to various attacks, but most research on the security problems of WSNs concentrates on key management 1 and node reliability. 2 Administrators cannot understand the network’s status comprehensively due to lack of effective security mechanism. Network security situational awareness3,4 emerged. It was proposed by Tim Bass in 1999. It has been applied to the architecture, data fusion, knowledge representation, and other fields. By analyzing and understanding the attack data of whole network, it can initiatively assess and predict the status of the network in real time, which provides a basis for the administrator to defense attacks actively.
Network security situation element acquisition 5 is the premise of the situation assessment and prediction. It refers to acquiring the elements which have an impact on the network, finding the attacks 6 and then forming situation elements through statistical analysis. Its core is to identify abnormal data from massive multi-source heterogeneous data and determine the type of attack. However, acquiring situational elements in WSNs needs to solve the following three problems: (1) the limited energy of sensor nodes limits the processing capacity of the nodes, (2) the wide distribution of sensor nodes and the characteristic of wireless multi-hop make WSN more vulnerable, which seriously affects the accuracy and timeliness of the attack recognition, and (3) the categories of the collected attack data for learning distributed imbalance, which makes it difficult to detect the attack behaviors of small class sample.
In this article, aiming to address the above challenges, we propose a new hierarchical situation element acquisition model. It combines the clustering structure 7 of WSNs. The data processing is set on the cluster heads and the sink nodes, and the data are collected on the ordinary nodes. It sends the security information collected on the sensing nodes of each part to the corresponding cluster heads by the thought of parts to whole. It completes the aggregation of the information on the cluster head layer, which gets the part situation elements through analysis and then uploads them to the sink layer for aggregate analysis. In this model, we use the improved deep auto-encoder network to learn the characteristics of the attack data and obtain the classification rules. First, in order to reduce the time complexity, cross-entropy (CE) is used as the cost function in place of the traditional mean-square error (MSE) in the hierarchical training stage of deep learning, which further improves the convergence performance by increasing the momentum factors. Second, in order to solve the problem of a low accuracy of small class samples caused by the imbalanced numbers and improve the overall classification accuracy, an active online sampling (AOS) algorithm is applied to the classifier to select samples online and update network weights.
This article is organized as follows. Section “Related work” introduces the related works. Section “Situation element acquisition model” introduces the hierarchical acquisition model. Then, section “Layered training rule based on CE-BP” introduces the greedy layerwise training rule of deep network. In section “Fine-tuning and classification based on AOS-softmax,” we introduce the AOS algorithm which is used in the softmax classifier. Section “Algorithm flow” summarizes the algorithm flow. Section “Simulation and analysis” analyzes simulation and evaluates performance. Finally, we make some concluding remarks.
Related work
Network security situational awareness is an active defense mechanism, which is initiative, dynamic, and able to learn. Therefore, the research on situation element acquisition is focused on the artificial intelligent algorithm. Some results have been obtained by now. Dain and Cunningham 8 combined data mining method with expert knowledge to obtain a suitable clustering, which can meet the requirement of real time. But there is a problem of overlearning in this method, and its property of generalization and anti-noise is poor. Guo et al. 9 proposed back-propagation (BP) neural network model based on particle swarm optimization to obtain the situation elements, which got higher classification accuracy. But the BP algorithm is time-consuming to deal with large amounts of data. In order to improve the detection efficiency of large data, YH Liu et al. 10 adopted the distributed neural network algorithm in large-scale network intrusion detection. It has a high detection accuracy for great data samples but a low classification accuracy for small class samples. El-Khatib 11 proposed a method which combines filter and wrapper model to select features from intrusion data and then using neural network to classify the data after feature selection. Although this model can reduce the redundant data and training time, the detection rate is not high. Z Liu et al. 12 mainly adopted the attack graph method to analyze the network security vulnerabilities and proposed a generation method of complex network attack graph. However, the situation factors extraction in this article is incomplete and there are too much redundant data. Considering the attack data is changing all the time, Y Yang et al. 13 extended the growing hierarchical self-organizing map (GHSOM) neural network model which could learn the new attacks on the basis of learned knowledge and avoid repetitively learning. However, the simulation results show that the classification accuracy of small class sample is low when the distribution of training sample is imbalanced. At the same time, the research works about situation element acquisition in WSN are relatively fewer. Hence, we propose a model of situation element acquisition for WSNs. It can effectively identify network attacks and solve the problem that the learning rules are biased toward the frequent records.
Situation element acquisition model
WSN has a wide range of distribution and multiple nodes. The power supply of sensor nodes generally relies on battery, which leads to a limited energy. Therefore, in order to reduce the energy consumption of the terminal nodes, the hierarchical situation elements extraction model is adopted, and the structure is shown in Figure 1.
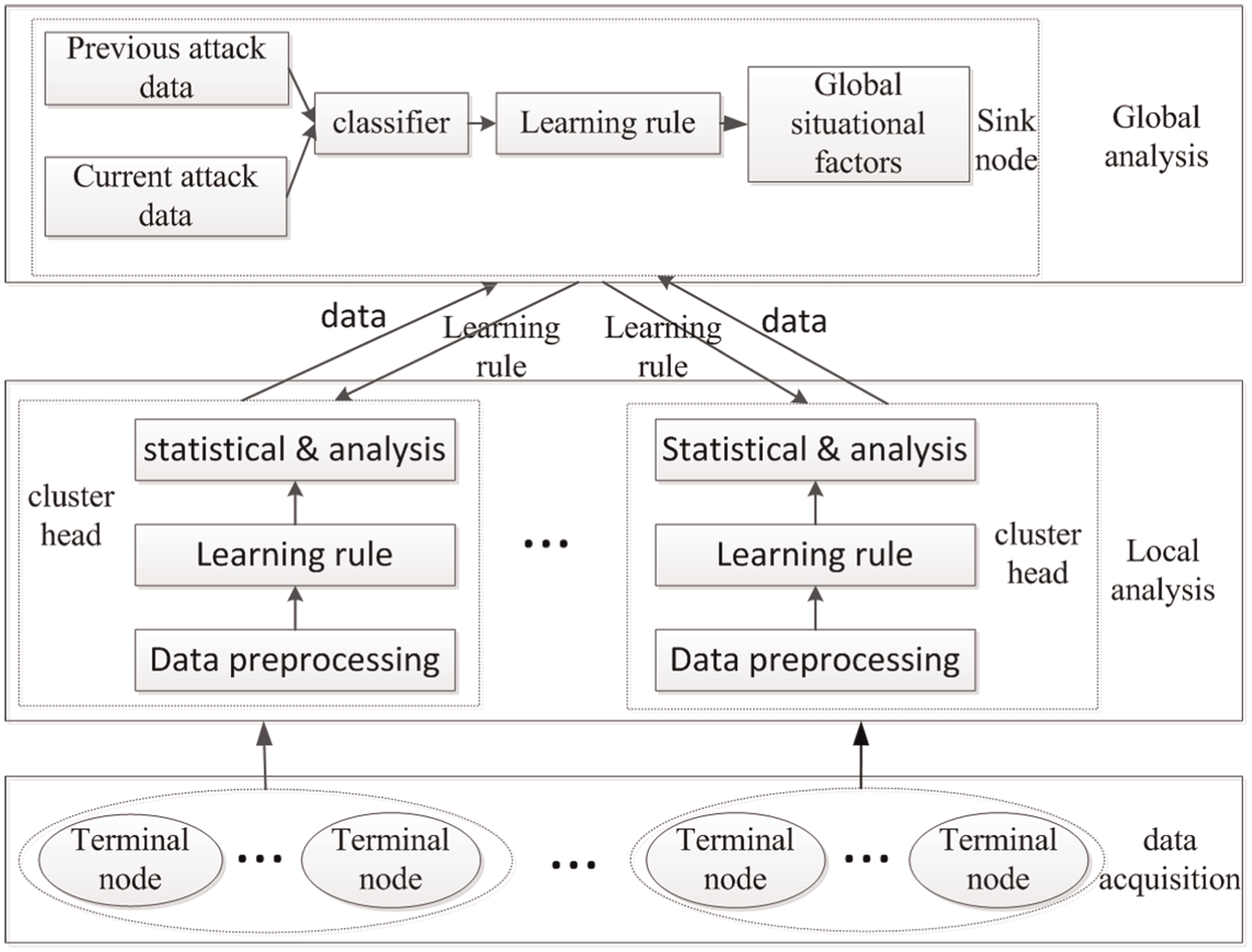
The framework of hierarchical situation element acquisition.
The terminal nodes are responsible for collecting the security log information, environmental information, alarm information, and other security information that affect the operation. Then, the nodes upload the collected data to the cluster heads.
The cluster heads gather their security data and the attack data of the terminal nodes for processing. After learning, it uploads the gained local situation elements to the sink node in which learning rules are provided by sink nodes.
The sink layer needs to complete two tasks. The first one is to analyze the large amount of collected security data and learn the attack types and then inform the learning rules to the cluster layer. The second one is to get the global situation elements according to its own information and the local situation elements.
This framework can not only get the global situation elements but also extract real-time situation elements of each part. It earns each part’s information based on the result of network security situation awareness so that when threats appear, it can quickly find the corresponding places.
Considering the advantage of deep learning 14 on large data processing, the improved deep learning network is applied in the classification and learning of preprocessed information. Thus, the corresponding rules are concluded and the situation elements are generated after statistical analysis. It is shown in Figure 2.

Deep auto-encoder network.
Deep auto-encoder network is composed of several layers of auto-encoder network and a layer of softmax network.15,16 Among them, multi-layer auto-encoder networks stack to be stacked auto-encoder network (SAE), so as to learn the characteristics of the input data by layer.
The training process of deep learning is divided into two steps: first, unsupervised training for each layer can separately ensure that as much information as possible is kept after the eigenvector maps to the different eigenspace and then the network value produced by training will be the initial value; second, high-level eigenvector obtained from the last layer of auto-encoder networks acts as the input of softmax layer to take the supervised training, and meanwhile fine-tune the whole network. With this training method, abstract features more capable of representing the implicit characteristics in the bottom layers can be learned, and thus, the appropriate eigenvalues are used in pattern classification. According to some recent studies,17,18 deep model has better results than shallow model on the nonlinear function approximation problem.
From the structure and training process of deep learning, the classification accuracy and training time are related to their methods. Therefore, considering the requirement of network security real-time awareness and the unbalanced attack data, a hierarchical training rule combined with CE and BP algorithm is designed in the hierarchical training of auto-encoder network. The method of AOS algorithm sampling is applied to select the samples for updating network weights during the training and fine-tuning of softmax.
Layered training rule based on CE-BP
The challenge of deep features extracted from the collected security information is the layered training of SAE. Training rule of each layer will be introduced in detail as follows.
Auto-encoder is one of the SAE’s core components, composed of the encoder, decoder, and activation function

Auto-encoder network structure.
The input



where
Before confirming the weights updating rule, set an appropriate loss function. And the CE function is adopted in this article. Assume that the input sample set is
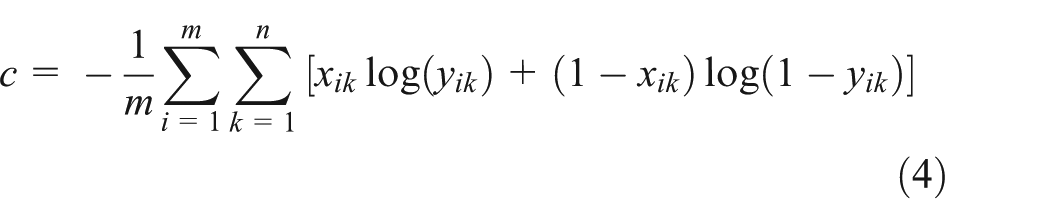
where

Seek out the optimal solution of equation (5) by the gradient descent method and calculate the partial differential of the loss function with reference to the parameters
Assuming

The sensitivity of hidden layer can be obtained from the reconstruction layer

In the equation,


where
Fine-tuning and classification based on AOS-softmax
Imbalance of categories is shown in the attack data collected during a certain period of time. If training by the traditional network of softmax, it will lead that more large samples are trained than small samples. So, it gets a low accuracy of small class samples’ classification and wastes training time because of the redundant data. So, we propose an algorithm of AOS in this article. It will dynamically select samples for training softmax network and fine-tune the deep network by analyzing the amount of data information.
Softmax classifier
The softmax network is a supervised classifier, and it acts as the last layer of deep auto-encoder network. Softmax keeps the sum of the outputs from each unit equal to 1, so the output can be the conditional probability. And the probability of the input belonging to the

where
AOS algorithm
Oversampling20,21 and undersampling 22 are often adopted to solve the problem of sample imbalance. Such methods usually copy the small samples till the number is same as that of large samples or reduce the number of large samples, which easily causes data redundancy or loss of partial information. 23 Later on, the method of active learning24,25 is adopted in the sampling. It trains the classifier through selecting the samples for deciding boundary, which works very well. Taking that into consideration, an algorithm of AOS is designed to solve the problem of sample imbalance. It samples by the thought of active learning combined with the distribution of samples, selects the samples for fine-tuning according to the amount of each data information, and removes redundant data and keeps more useful data.
Supposing the situation elements are classified into
The probability
When
When
When
It is easy to conclude that the first case is able to acquire the correct category, so the training should emphasize the samples of second and third cases. Because of the forward propagation of the softmax network, define the function of confidence as follows

From the equation (11), the bigger

The equation above will solve the problem of data redundancy but not the problem of samples’ unbalanced distribution. Because of the wide gap between the large samples and the small samples in the attack data, to improve the probability of small samples being selected with a promise of meeting the accuracy of the classification for large samples, redefine the selection function as follows

In this function,
Compare
Through the analysis above, it can be concluded that:
Under the current number of iterations, the samples wrongly classified by the network will be used for updating the network weights.
Under the current number of iterations, among the correctly classified samples, those with lower confidence are more probable to be selected to update the network weights.
Under the current number of iterations, among the correctly classified samples, the selection function tends to small ones.
Under the current number of iterations, abandoned samples are still available for the next iteration.
When samples are seriously unbalanced, avoiding the value of selection function decreases by orders of magnitude for the large samples and ensures improving the classification accuracy of small samples without effects on that of large samples.
AOS is similar to undersampling because they both improve the classification accuracy of small samples by reducing the amount of large samples, and the difference is that the former samples online during the process of training; compared with active learning, undersampling takes the categories into account, but the active learning only considers the amount of information and determines the category after selecting a sample.
Network fine-tuning and classification combined with AOS-softmax
Supervised training is adopted in the stage of classification and fine-tuning in the deep network and it is a key part of network learning. In this article, the learner is constructed according to the algorithm of AOS and the network after initialization. When the output vectors of the last layer of auto-encoder network act as the input of softmax network for iterating, from the results of forward propagation, it selects vectors by the AOS algorithm and determines whether the vector is going to take part in the later iterations and update the network weights or not.
The AOS algorithm in softmax network is as follows. In the algorithm,

Algorithm flow
In this article, we mainly use CE instead of MSE loss function in the deep network’s hierarchical training stage. With the BP algorithm training every layer of auto-encoder network, we put forward a kind of AOS algorithm applied in softmax network training and fine-tuning. Let us assume that the deep network is made up of K layers in auto-encoder network. The algorithm flow chart is shown in Figure 4.
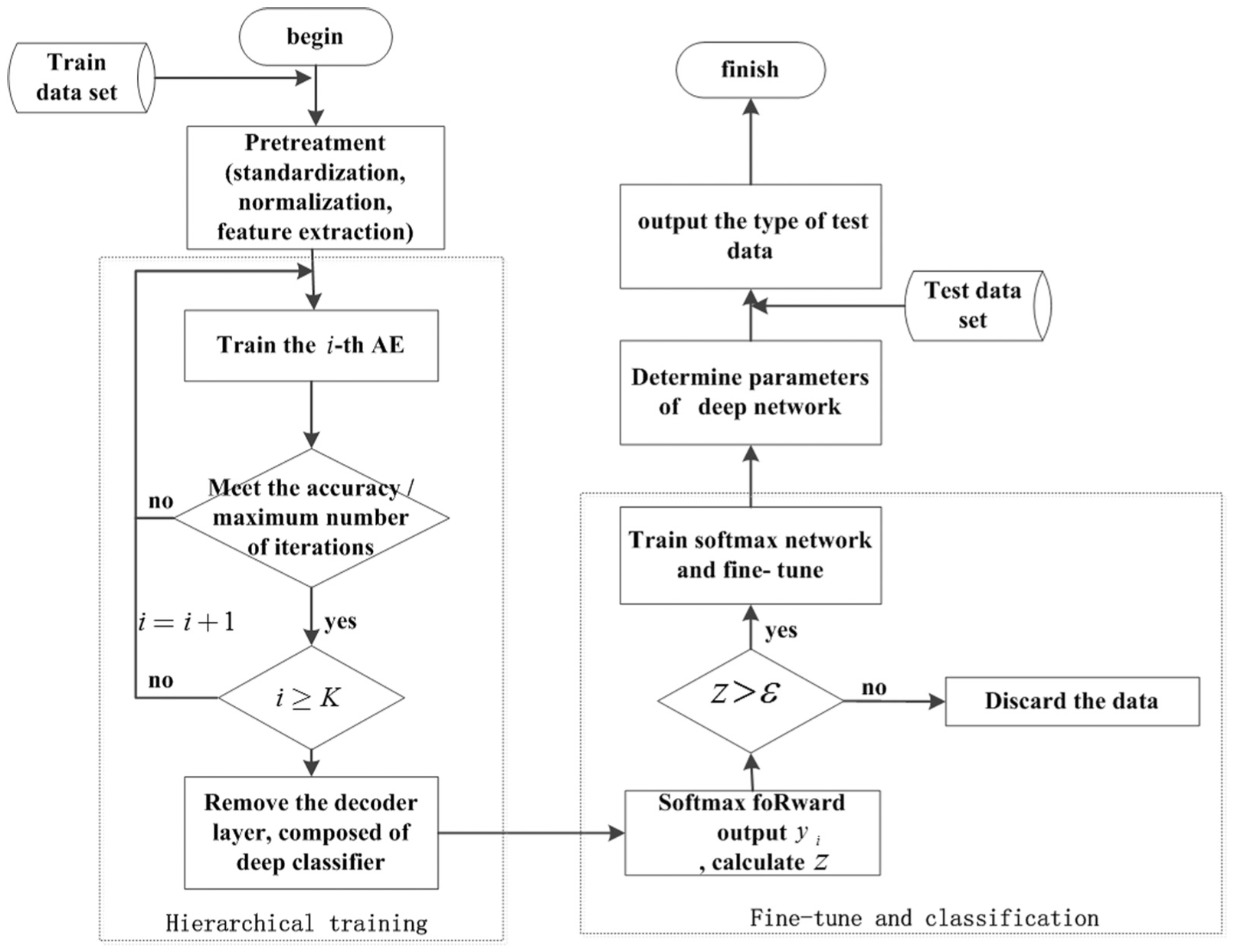
Flow chart of situation factors acquisition algorithm.
Simulation and analysis
In this article, data set of knowledge discovery in databases (KDD) cup99 26 is adopted to verify the performance of situation element. KDD cup99 has a complete training data set containing 4,999,000 pieces of connection records, and each record is made up of 42 properties, of which the last property describes this record is a normal connection or some kind of intrusion. Divide the attacks into four categories: denial of service (DoS) attacks, user-to-root (U2R) attacks, remote-to-local (R2L) attacks, and Probe attacks, the rest of normal data classified as normal. Some parameters setting of the deep learning is shown in Table 1.
Parameter setting.

Data pre-processing
Value standardization

where
Value normalization
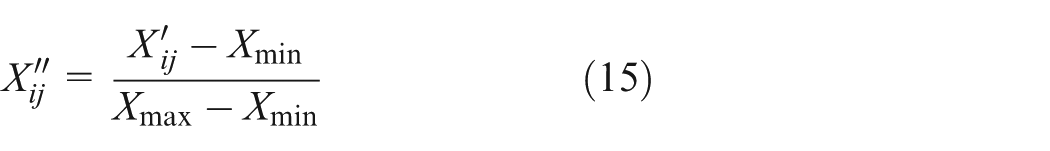
where
According to a certain proportion, randomly select data from the 10% data subset of the KDD cup99 set as the training data. Then, select data from KDD cup99 test subset in the same way. Data are shown in Table 2.
Experimental data.

DoS: denial of service; U2R: user-to-root; R2L: remote-to-local.
Feature selection
Each datum in the KDD cup99 data set is composed of 41 features. However, large numbers of irrelevant or redundant features affect the detection results. Therefore, in this article, we use Fisher feature selection method to reduce data dimensionality, so as to improve classification efficiency and accuracy. The task consists of the following steps:
Step 1: Input data set, compute matrix number, and initialization matrix. W is used to store sorting results, n represents the number of features, and m is the number of categories.
Step 2: Calculate the average value of all the data of each feature from features 1 to N; calculate the variance of the mean value of each kind of data and the total samples under this feature and then add all the values as the inter class variance (temp1). Calculate the sum of the variance of the feature in all categories, which means the intra class variance (temp2).
Step 3:
Step 4: Sorting by the importance of features.
The simulation results showed that the method successfully brings 90% classification accuracy using only five features. But in order to not affect the classification accuracy while reducing redundancy, we selected 31 features to achieve 96% classification accuracy.
Simulation analysis
Network’s convergence
At first, we test the convergence of the deep network. The changing of the relative error’s updating frequency is shown in Figure 5. The figure shows that the error value is monotonically decreasing and the network is gradually convergent as the number of iteration is increasing.

The curve of relative error updating frequency.
The influence of deep network’s structure on results
Larochelle et al. 27 figure that it goes against classification when the sum of hidden layer’s nodes is too small or too large. The depth of the network is also important to the classification. Although an increase in layers enhances the modeling capability of the auto-encoder network and the performance of high layer discovers more abstract features, too many layers may weaken the ability of generalization. Lv et al. 28 have proved that three layers of auto-encoder network are enough to achieve good results, so this comparison is between the influences of the two-layer network and three-layer network on the accuracy.
Experiment (2) tests the influence on the results of data classification by the different layers and different numbers of hidden layer’s nodes, choosing the trainData1 as the training data and testData1 as the test data. The number of input dimension is 31. To determine the influence of hidden layer’s nodes number on the classification, change only the nodes and fix the other parameters. Considering the result’s discrepancy of each run, the experiment selects the maximum value of 10 times run. The final result is shown in Figure 6.

Accuracy of different network structures.
It is easy to see that results are best when the hidden layer nodes number is 20 both in the two-layer and three-layer auto-encoder networks. The reason is that all the properties are not suitable as the feature of KDD cup99 data set, and the vectors after feature extraction are more effective for data potential feature mining. Considering the timeliness and accuracy, the network structure is decided as 31-20-20-5.
The influence of AOS on the small sample
Through the comparison of the accuracy of U2R attacks in different ways, the influence of AOS algorithm on the small samples’ classification accuracy is tested. Choose the trainData2 as the training data and testData2 as the test data. The result is shown in Figure 7.

The influence of AOS on the situation element acquisition accuracy of small sample.
As shown in Figure 7, AOS is effective to situation element acquisition of small sample with different node numbers. It improves the accuracy of situation element acquisition for small samples.
Compare the accurate accuracy with that of other works
Through experiment (2), we decide that the number of hidden layers is 2 and the number of nodes is 20, with each layer adopting the gradient descent algorithm. Measure the network performance by the detection rate of each category and that of the whole. In order to effectively illustrate the performance indexes, we compare the results with our scheme, SAE (the deep auto-encoder network without AOS), QSSVM (quarter-sphere support vector machines), 29 and improved particle swarm optimization and radial basis function neural network (IPSO-RBF). 30 TrainData2 acts as the training data and testData2 acts as the test data. The result is shown in Table 3.
The accuracy of situation element acquisition in different algorithms (%).

SAE: stacked auto-encoder network; QSSVM: quarter-sphere support vector machines; IPSO-RBF: improved particle swarm optimization radial basis function; AOS: active online sampling; CE: cross-entropy; DoS: denial of service; U2R: user-to-root; R2L: remote-to-local.Significance of bold values is just to highlight the data of winner approach so as to make the comparison results more obvious.
Comparing the results, it is shown that the most accuracy of deep auto-encoder network is higher than that of QSSVM and IPSO-RBF, but the detective rate of U2R and R2L attacks is lower than other attacks because of less-trained sample. Our scheme reduces the ratio of the individual sample number after AOS, so it improves the detective rate of small sample. The detective rate of U2R attacks is only 77% because of the differences between the training samples are too large, while the detective rate of Probe sample falls by nearly 1%, the reason of which is that the similarity of Probe attacks and R2L attacks causes the fusion when testing the samples.
The time complexity analysis of algorithm
For the analysis of situation, awareness pays more attention to the timeliness; it needs to reduce the spent time with the guarantee of accuracy. The experiment explains the advantage of the program over time by comparing the time complexity of algorithm of the MSE-SAE, CE-SAE, and AOS-CE-SAE.
It can be seen from Table 4 that the deep auto-encoder network with AOS algorithm and CE function has an obvious advantage of the timeliness. The CE acts as the error function to update network weights avoiding the derivative operation for the activation function, so the network running time reduces more than a half. By the AOS algorithm selecting more useful data and removing similar eigenvector, it avoids repetition to reduce the number of input vectors for training softmax classifier and fine-tuning whole network, so it shortens the network running time.
The comparison of time complexity.

SAE: stacked auto-encoder network; AOS: active online sampling; CE: cross-entropy.
Significance of bold values is just to highlight the data of winner approach so as to make the comparison results more obvious.
Conclusion
On count of the security issue in WSNs, we propose a mechanism of situation element acquisition based on deep auto-encoder network in this article. Referring to the traditional structure of deep learning and taking the sigmoid function’s features into consideration, it combines the CE loss function and BP algorithm to update the network weights, so as to reduce the network’s convergence time and improve the classification accuracy. For the purpose of effectively improving the classification accuracy of the small class samples, it adopts the AOS algorithm when supervised training in the softmax classifier. It decides whether the sample is being used for updating the weights according to the real-time status of the network. The rule of selecting samples gives consideration to the unbalanced types and difficulty of each sample so that the improved network satisfies the small samples and the samples hard to classify. It also removes the data less useful for updating the network weights, which greatly reduce the training time. Through testing the data of KDD cup99, it has a good effect and verifies the validity of the situation acquisition model. During the next work, with the regard of network data changing constantly, we will apply the incremental learning to the situation element acquisition for improving the adaptability of network.
Footnotes
Academic Editor: Fei Yu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Key Projects of National Nature Science Foundation of China (No. 61271260) and the Natural Science Foundation of Chongqing Science and Technology Commission (No. cstc2015jcyj A40050).