
Abstract
With the rise in the use of Android smartphones, there has been a proportional surge in the proliferation of malicious applications (apps). As mobile phone users are at a heightened risk of data theft, detecting malware on Android devices has emerged as a pressing concern within the realm of cybersecurity. Conventional techniques, such as signature-based routines, are no longer sufficient to safeguard users from the continually evolving sophistication and swift behavioral modifications of novel varieties of Android malware. Hence, there has been a significant drive in recent times towards leveraging machine learning (ML) models and methodologies to identify and generalize malicious behavioral patterns of mobile apps for detecting malware. This paper proposes Deep learning (DL) based on new and highly reliable classifier, deep neural decision forest (DNDF) for detecting Android malware. Two datasets were used: Drebin and 2014 for comparison with previous studies, and TUANDROMD collected in 2021 for detecting the latest threats with advanced obfuscation and morphing techniques. We have also calculated the time-consuming and computational resources taken by our classifier. After conducting a thorough performance evaluation, our proposed approach attained impressive results on two datasets. The empirical findings reveal that the proposed DBN and DNDF models demonstrated exceptional performance, achieving an accuracy of 99%, a sensitivity of 1, and an AUC value of 0.98%. The metrics we obtained are comparable to those of state-of-the-art ML-based Android malware detection techniques and several commercial antivirus engines.
Keywords
Introduction
The year 2008 marked the initial release of the Android operating system (OS) as an open-source initiative in its present format. Since then, it has witnessed significant acclaim from users due to its ability to be tailored to individual preferences and its minimal hardware demands. In 2022, the number of active Android devices drew close to the staggering figure of 2,257.17 million, reaffirming its position as the most widely used operating system globally [1]. The growth of Android OS adoption is depicted in Fig. 1, which highlights the swift rate of expansion. The substantial expansion of Android’s user base can be attributed to its extensive integration into various technologies, such as mobile phones, the Internet of Things (IoT), Internet of Multimedia Things (IoMT), industrial IoT (IIoT), connected vehicles, and smart home appliances.
The substantial proliferation of the Android OS has resulted in significant security concerns. One particularly crucial challenge is the rise of malicious apps that contain or implant malware [2]. The Google Play Store is the primary source for Android users to access and download apps. Over the years, it has witnessed tremendous growth, with the number of apps available on the platform skyrocketing from a mere 16,000 in December 2009 to a staggering 2,257.17 million, by August 2022 [3]. The fast-paced expansion of the Google Play Store led to phases of inadequate security evaluations of the apps featured in the platform, thereby leading to numerous significant incidents where millions of users downloaded malware-infected apps [4, 5]. During these occurrences, the security measures on the Play Store may have faltered in detecting instances of malware or potentially unwanted programs. Alternatively, it is possible that these apps did not undergo the necessary screening process at all.
As per [4], the Google Play Store accounts for just 87% of the total Android apps downloaded. The remaining 13% of Android apps downloaded originate from various sources such as alternative markets, older apps backups, and direct downloads through browsers, among others. However, it is worth noting that these sources are typically considered unreliable. In numerous instances, attackers promote these non-Play Store downloads as a free edition of an otherwise paid app. Attackers also attempt to disguise their harmful apps as useful ones. In a more recent occurrence, attackers developed apps that could bypass the security protocols of the Google Play Store. While these apps may not contain malware upon installation, they are designed to secretly download and inject malware into Android devices later in time [6]. During the aforementioned occurrence, a banking trojan was spread through an app downloaded more than 300,000 times. According to a study cited in [7], only 35% of Android users carefully read all the permissions requested by an app before proceeding with its installation. According to the same study [7], only 77% of Android users have declined to install an app due to the permissions it requires, at least once. These statistics suggest a significant lack of user awareness regarding the potential risks of installing apps without thoroughly reviewing and comprehending the requested access permissions.
The security challenges above underscore the critical importance of developing a robust and dependable system for detecting malware. The malware detection solution must be capable of automatically learning and extracting intricate features from input data without requiring manual feature engineering. This can be particularly useful in the case of Android malware detection, where the malware may have sophisticated and constantly evolving behaviors that are difficult to capture using traditional handcrafted features.
To cope with the above challenges, this study presents a novel approach for android malware detection using four DL-based classifiers, including Convolutional neural networks (CNN), Autoencoder (AE), Deep Belief Neural network (DBN), and Deep neural decision forest (DNDF). Our research involved two different datasets Drebin 2014 [8] and TUANDROMD 2021 [9] to assess the effectiveness of our proposed approach against established benchmarks and to facilitate comparison with prior studies. Using an old dataset allowed us to compare our results with previous studies’ results. Using a new dataset provided an advantage in detecting the latest threats, as modern adversaries often employ advanced obfuscation and morphing techniques that render traditional methods ineffective. In addition to evaluating the performance metrics of the DL-based classifiers, we have also computed their respective training times and the required computational resources on both datasets. This analysis provides a comprehensive overview of the efficiency and scalability of the classifiers, which is crucial for practical deployment in real-world scenarios. To the best of our knowledge, there is a dearth of prior research that has conducted a comparative analysis of computational resources and time consumption among CNN, AE, DBN, and DNDF classifiers for the purpose of Android malware detection. Additionally, there is a lack of studies utilizing appropriate metrics to evaluate the performance of these classifiers on the given datasets. Our research contribution includes the following key points:
To develop four novel DL-based classifiers specifically designed for Android malware detection and classification, achieving promising results. This approach can serve as a foundation for further research in this domain, contributing to the advancement of the field. To compare the four DL-based classifiers in terms of accuracy, precision, recall, MAE, MSE, RMSE, R2 score, AUC, and sensitivity, as well as the time rate and computational resources required. This analysis provides insights into each classifier’s strengths and weaknesses and helps identify the most efficient and effective solution for Android malware detection. To evaluate the performance of the four classifiers on two different datasets, Drebin and TUANDROMD, shows the effectiveness of the classifiers on both old and new datasets and provides insights into the evolution of Android malware over time.
The paper is structured as follows: In Section 2, we provide an overview of the relevant literature. In Section 3, we outline the research design, including the methods employed for data collection and analysis. Section 4 presents the study’s findings. Section 5 is dedicated to analyzing the results, discussing their implications, and establishing connections to existing literature and research objectives. Finally, Section 6 concludes the study by summarizing the main findings, emphasizing the contributions of the study, and providing suggestions for further research.
The number of internet users worldwide between 2012 and 2022, categorized by operating system, is presented in the following data [1].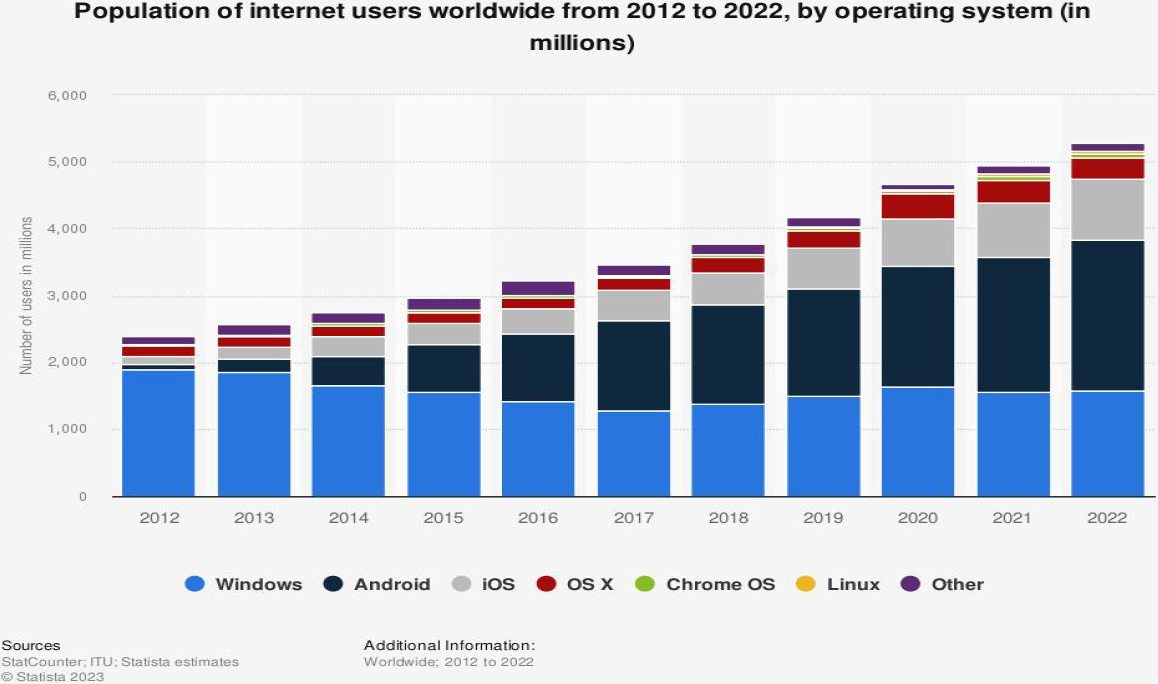
Background
The following section provides a brief introduction to Android apps and presents a review of the current literature on detecting malware in such apps. Android apps are distributed in the form of an Android Application Package (APK) file, which is a compressed archive file capable of being installed on IoT devices running on the Android platform. The APK creator employs the Android SDK’s dx tool to generate the dex file to transform the compiled Java class files. This tool merges, rearranges, and optimizes various class files to minimize size and enhance execution speed. The dex file, created by converting the compiled Java class files using the dx tool of the Android SDK, serves as the centerpiece of the APK. The Dalvik virtual machine is a crucial component of the Android platform that allows the interpretation and execution of APK files. These APKs contain sections containing vital information about all the classes in the file. To analyze the APK, this paper proposes using the classes.dex file, which serves as a representation of the APK.
Conventional approaches to detecting malware on android
There are three main types of approaches for detecting Android malware: static ,dynamic and hybrid detection, which are considered to be Conventional approaches. Static detection appraoch, such as those based on signatures, permissions, bytecode, and hybrid static analysis, examine static APKs for potential malicious features without requiring app execution. To create accurate and reliable signatures, signature-based methods rely on identifying particular character sequences or semantic patterns in the source file [10]. Because of their efficiency, commercial anti-malware products frequently utilize signature-based methods. Permissions serve as the initial security checkpoint for identifying malware on the Android platform. When it comes to detecting possible malware, the permission-based approach primarily scrutinizes the sensitive or dubious permissions that are requested by the software developer and declared in the AndroidManifest.xml file. Examples of permission-based methods include Kirin, developed by Enck et al. [11], and PUMA, developed by Sanz et al [12]. Within the dex bytecode file, there is a wealth of semantic information regarding appl behaviors, including API calls and data flows. The bytecode-based method involves the disassembly of dex files to analyze APKs. Examples of such methods include DroidAPIMiner [13] and MamaDroid [14]. Hybrid static analysis methods, like Drebin [8] and FlowDroid [15], use multiple files to extract various types of features and enhance detection accuracy. In conclusion, while static analysis methods are quick and effective, they may be ineffective against malware that has undergone code obfuscation or encryption [16].
The use of dynamic detection methods involves running APKs in isolated environments such as sandboxes, simulators, or virtual machines, and monitoring their behavior to determine if they are malicious [17]. By tracking their actions, it is possible to identify and prevent potential security threats. The TaintDroid system is a dynamic analysis tool for Android that operates at the system-wide level and detects malware by monitoring the movement of sensitive data [18]. In contrast DroidScope [19], reconstructs semantic information at both the Linux OS and Java Dalvik levels to perform dynamic analysis of APKs. These methods enable the identification and prevention of potential security threats in Android systems. Dynamic detection methods employ diverse features, including system calls, network traffic, user interaction, and system components, with the aim of identifying potential security threats. This approach is described in detail in [20]. Dynamic detection methods are highly effective in detecting potential security threats in Android systems, even when code obfuscation and encryption techniques are used. Dynamic methods can identify malicious behaviors that may be missed by static detection. This makes dynamic detection an essential tool for ensuring the security of Android systems, as noted in [21]. Despite its advantages, dynamic detection has limitations that must be considered. One issue is the low code coverage, which means that not all branches of an app can be tested. Consequently, hidden code sections that may be triggered at certain times or under specific circumstances could be missed. Additionally, dynamic detection methods are time and resource intensive, which can make them less practical in certain situations.
The hybrid detection approach combines both static and dynamic detection methods to achieve comprehensive analysis of Android APKs. This approach involves analyzing the files of static APKs and monitoring the behavior of the APKs during execution. Previous studies, as demonstrated in [22, 23, 24], have shown the effectiveness of this approach. Hybrid detection approach offer a promising solution for combating code obfuscation and encryption while also improving code coverage. By combining both static and dynamic detection techniques, this approach can effectively identify potential security threats in Android systems. However, the considerable time and resource consumption required for hybrid detection may limit its practicality in some deployment scenarios.
Android malware detection using ML-based algorithms
Traditional methods for detecting malware in Android systems have relied heavily on building up libraries of signatures and the expertise of analysts, which can be challenging to scale up to keep pace with the rapid growth of Android malware. Fortunately, ML-based technologies offer a promising approach for efficient and automated Android malware detection, providing a new perspective for addressing this challenge [25]. ML-based methods for detecting Android malware typically involve four key steps: constructing a dataset, performing feature engineering, training a model, and evaluating the model. Feature engineering is a crucial step that involves extracting informative and robust features to accurately characterize APKs. Commonly used features for characterizing APKs include features extracted from the AndroidManifest.xml file and classes.dex features, and features based on dynamic behaviors. The selection of relevant features is essential for ensuring the validity and effectiveness of the model. The AndroidManifest.xml file is a critical source of information about an APK. It provides crucial details such as the hardware requirements, requested permissions, APK components, and filtered intents. These details are vital for understanding the APK’s functionality and ensuring that it can run properly on the target device. This file is a crucial reference point for feature extraction in ML-based approaches to Android malware detection. By analyzing the AndroidManifest.xml file, it is possible to identify important characteristics of an APK that may be relevant to its security and potential risk.
As described in [26], key features for detecting Android malware are extracted by parsing the AndroidManifest.xml files. The APK’s classes.dex file can be converted into a Smali format file, which includes Dalvik commands comprising opcodes and operands. This transformation enables the extraction of critical features that can be used for ML-based detection of Android malware. In [27], n-gram features are extracted from the opcode sequences to train malware classification models, highlighting the importance of leveraging advanced features extracted from classes.dex files for ML-based detection of Android malware. For example, features such as control flow diagrams [28] and API dependency graphs [29, 30] can be extracted from disassembled classes.dex files to improve the accuracy and effectiveness of the detection models. These features provide a comprehensive representation of an APK’s behavior and potential security risks, enabling more precise identification of potential threats. As reported in the literature [31, 32], dynamic behavioral features that capture critical information about Android malware can be obtained by executing apps in an isolated environment. The following traits are encompassed within these characteristics: file operations, network operations, encryption operations, service initiation, phone calls, and system calls. The amalgamation of static and dynamic features has the potential to improve the detection efficacy of Android malware. Static features can be extracted from the APK’s code structure and functionality, while dynamic features can be collected by monitoring the APK’s behavior in a sandboxed environment. Integrating both feature sets into ML-based models enables more accurate and comprehensive identification of security threats. The selection of models in Android malware detection can vary from traditional ML-based approaches, such as Support Vector Machines (SVM) [8] and Random Forests (RF) [14], to more advanced DL-based models, such as CNN [33], DBN [34] and Long Short-Term Memory (LSTM) [35].
Android malware detection using cutting edge algorithms
In recent years, the increasing popularity of mobile devices has led to a surge in the number of Android malware attacks. To combat this issue, researchers have explored the use of DL-based techniques to develop more effective malware detection methods. These studies have proposed various DL-based architectures, such as CNN, LSTM, and RNN to detect Android malware.
Qamar et al. [36] conducted a review of papers published between 2013 and 2019, focusing on mobile malware attacks, detection techniques, and potential solutions highlighted five studies that utilized DL-based algorithms for detecting mobile malware. Among these studies, four utilized the CNN algorithm, while one utilized the Artificial Neural Networks (ANN) algorithm. The review indicated that DL-based techniques offer superior performance compared to traditional ML-based algorithms, but their computational complexity is higher, leading to higher computational costs. In a study conducted by Slan and Samet [37], malware detection research papers were classified based on various techniques. These techniques encompass a range of approaches, including signature-based, behavior-based, heuristic-based, model checking-based, DL-based, cloud-based, mobile-based, and IoT-based methodologies. This categorization provides a useful framework for understanding the various approaches to detecting malware and highlights the diversity of methods used in the field. They reviewed four papers that used DL-based approaches, including DBN, ANN, and convolutional layers, and incorporated features such as API calls, system calls, and hybrid features. However, their primary focus was not to analyze the DL-based techniques for malware detection. Pan et al. [38] conducted an SLR on Android malware detection, categorizing static analysis into four types. Under the Neural Network (NN) category, DL-based models were classified by the authors. They determined that static analysis is a reliable method for identifying Android malware. While their primary focus was on Android, this article reviews DL-based approaches for detecting mobile malware more broadly. Feizollah et al. [9] reviewed 100 papers on feature selection techniques for Android malware detection, finding that only 8 utilized feature selection algorithms. They categorized features into static, dynamic, hybrid, and application metadata. Android permissions were the most popular static feature 36%, and system calls were the most dominant dynamic feature. Nearly half of the papers that used dynamic features used network traffic data.
Methodology and experiments
The primary objective of this section is to gain a deep understanding of the methodology employed in the development of precise and resilient malware detection systems. To achieve this, a comprehensive overview of these vital aspects is presented, ensuring a thorough examination of their intricacies and significance.
Datasets description
Android apps are created using Java programming language and run on a customized version of the Java Virtual Machine. These apps are packaged in a Java Archive (JAR) file with the extension APK. Android app consists of four fundamental components: activities, services, broadcast receivers, and content providers. These components play pivotal roles in the structure and functionality of the app, contributing to its overall behavior and user experience. These building blocks are defined and specified in the app’s manifest file, which serves as a roadmap for the app’s functionality. The interaction and communication between these components are facilitated by a mechanism called intents, which act as messages to request an action or transfer data between them. Intents can also be filtered based on specific criteria, allowing the components to selectively respond to certain types of requests.
This study utilized two different datasets, namely Drebin [8] and TUANDROMD [39], to develop and evaluate DL-based models for Android malware detection.
Drebin dataset
Created by researchers at the University of Göttingen in Germany, consists of 5,560 malware apps and 9,476 benign apps. Each app is characterized by features such as permissions requested, API calls, and network traffic, among others. The Drebin dataset has been widely used in research on Android malware detection and evaluation, making it a well-known and commonly used dataset in the field.
TUANDROMD dataset
Created by Nguyen and Nguyen in 2021, contains 4,468 Android APK files, including 3,565 malware samples and 903 benign samples. Each sample is represented as an APK file and includes its corresponding metadata, such as the app name, version code, package name, and permission list. The dataset was collected in 2021 and is available for download from several online sources, such as Kaggle and Zenodo.
The volume of datasets
The volume of datasets
These datasets were partitioned randomly into three parts, where 80% was designated for training, 10% for validation, and the remaining 10% for testing. The training portion was utilized to train models, while the validation set was employed to refine and choose the most optimal model prior to its application on the testing set. These datasets provides a diverse set of samples, including various types of malware such as adware, spyware, and trojans, as well as benign apps. It serves as a benchmark for evaluating the performance of DL-based models for detecting Android malware, allowing researchers to develop and test new algorithms. The volume of the datasets presented in Table 1.
In this research, we employed various techniques to address the challenges of working with unbalanced datasets and ensure the quality and reliability of the Drebin and Tezpur University Android Malware Dataset (TUANDROMD). We discretized the data and applied class imbalance treatment techniques of undersampling and oversampling to balance the datasets. Specifically, we randomly undersampled the majority class and oversampled the minority class using the Synthetic Minority Over-sampling Technique (SMOTE) with the RandomUnderSampler and SMOTE algorithms from the imbalanced-learn library in Python. By implementing these techniques, we were able to improve the performance of our classifiers on these challenging datasets. The balanced datasets that resulted were employed to train and assess the classifiers, while the performance was evaluated using several metrics such as accuracy, precision, and recall. Furthermore, we removed variables with significantly poor quality from each dataset to preserve data integrity. Thirdly, we utilized data cleansing procedures to identify and rectify any inconsistencies and errors present in the datasets. One of the crucial steps we took was to remove duplicate samples using selected unique samples with a distinct combination of package name (
In addition to handling duplicate samples, we also addressed the issue of missing feature values by imputing the mean or median based on the distribution of the feature values. These measures were essential for improving the overall quality and reliability of the Drebin and TUANDROMD datasets, which is crucial for accurate training of DL-based models. By ensuring the quality and reliability of these datasets, we can develop more robust and accurate models that can be applied to real-world problems. It is essential to ensure data quality and reliability before conducting experiments, particularly when dealing with complex datasets such as Drebin and TUANDROMD datasets. Moreover, these measures can be applied to other similar datasets to ensure their quality and reliability, thus contributing to the development of more accurate and reliable models.
To ensure that all features in the Drebin and TUANDROMD datasets had an equal contribution to the analysis, we utilized the Minimax normalization method. Minimax normalization is a technique for scaling features that transforms numerical data into a predetermined range, typically ranging from 0 to 1. The technique is applied to each feature in the dataset to ensure that no feature dominates the analysis due to large scales or ranges. This normalization technique helps prevent inaccurate results from being produced. To ensure consistency between datasets, we utilized the Minimax normalization technique to standardize the numerical data to a common scale. This approach includes subtracting the feature’s minimum value from each data point and then dividing the outcome by the feature’s range. The Minimax normalization is given in Eq. (2).
The equation presented here involves four variables. The variable
The efficacy of the suggested techniques for identifying Android malware was assessed via statistical analysis and the computation of crucial metrics such as Pearson’s Correlation Coefficient (
The study provides equations for these metrics where
A combination of four DL-based algorithms, including CNNs, AE, DBN, and DNDF, resulted in a powerful ML-based model capable of detecting Android malware. The use of multiple algorithms allowed for a comprehensive analysis of the malware data, providing a more accurate and robust detection system. This approach highlights the potential of combining different DL-based techniques to improve the performance of ML-based models. The process began with tuning each DL-based algorithm,individually on the dataset. For CNN, we used it to extract features from an Android app’s raw bytecode and its static structure, such as the manifest file and resource files. The AE and DBN were used to perform unsupervised feature learning to capture patterns in the data indicative of malware. The DNDF was used to learn the relationship between the features and the presence of malware. Finally, the trained models were used to classify new, unseen apps as either benign or malicious based on the extracted features and learned dependencies. The proposed approach offers a comprehensive solution for detecting Android malware by leveraging the power of DL. The model is capable of extracting spatial as well as temporal features from the data, which enables it to identify patterns indicative of malware presence. This not only enhances the accuracy of the predictions but also helps in gaining a better understanding of the underlying factors contributing to malware development. The model was trained using two datasets, and to optimize its hyperparameters, the Adam optimizer and a validation dataset were utilized. The DL library Keras [40], written in Python, was utilized in our study.
CNN model’s architecture comprises of two 1D convolution layers with 32 filters and a kernel size of 4. The model also includes a global average pooling layer that performs spatial average pooling over the entire feature map. To avoid overfitting, a dropout layer with a rate of 0.2 is added after the second convolution layer. The fully connected layer with 256 hidden neurons follows the convolutional layers, and a ReLU activation function is applied. RMSprop optimizer is used with a learning rate of 0.001, and the model is trained for 100 epochs with a batch size of 32 and 100 steps per epoch. Additionally, a weight decay of 0.00005 is applied to the model, and the momentum is set to 0.9. Finally, the Adam optimizer is used to optimize the cross-entropy loss function.
AE architecture utilized in this research project includes an input layer with a shape determined by the number of features, followed by an encoding dimension of 32. The encoder layers consist of two dense layers with a ReLU activation function, and the decoder layers also include two dense layers with ReLU activation. The optimizer used for training is SGD, with a learning rate of 0.001. The model is trained for 100 epochs with a batch size of 32 and 100 steps per epoch. The loss function used is Binary Crossentropy, and the classification layer includes a dense layer with a sigmoid activation function. Overall, this AE model is optimized for efficient feature encoding and reconstruction while minimizing the loss function.
DBN architecture consists of an input layer with 64 neurons and two hidden layers, each with 64 neurons and ReLU activation. A dropout rate of 20% is applied to the hidden layers to prevent overfitting. The fully connected layer also has a ReLU activation function. The Adam optimizer is used with a learning rate of 0.001 and weight decay of 0.00005. The model is trained for 100 epochs with a batch size of 32 and 100 steps per epoch. The optimization function is Adam with a momentum of 0.9.
Comparative analysis of experimental parameter using for, CNN AE, DBN and DNDF training
Comparative analysis of experimental parameter using for, CNN AE, DBN and DNDF training
DNDF model consists of 10 decision trees, each with a depth of 5. The decision tree layers have 32 neurons each, with a dropout rate of 0.5 to prevent overfitting. The ReLU activation function is utilized in the fully connected layer, while the sigmoid activation function is applied in the output layer. The optimization of the model involves using the Adam optimizer, with a learning rate set to 0.001, a batch size of 32, and a total of 100 epochs, each consisting of 100 steps. The parameters of all the DL Based models are displayed in Table 2.
For the proposed model to achieve optimal performance, certain environmental prerequisites must be met
For the proposed model to achieve optimal performance, certain environmental prerequisites must be met
The performance of DL-based models was assessed on standard Android malware datasets using the Keras and TensorFlow libraries of Python. The models were subjected to statistical analysis to evaluate their impact, and the resulting data were analyzed accordingly. Table 3 displays the platform that was employed for detecting malware in Android apps. The effectiveness of the malware detection algorithms was assessed using standardized datasets of mobile malware. The Drebin dataset comprises 15,036 Android apps that belong to 179 distinct malware families, whereas the TUNADROMD dataset contains 4468 apps from 25 different malware families, as indicated in Table 1. For this study, both datasets were split into three subsets, with 80% allocated for training, 10% for testing, and 10% for validation. A random function was employed to separate the training and testing data, which were used to train the models in the fitting phase. During the subsequent testing phase, the proposed models underwent evaluation for accuracy, precision, recall and AUC using new data. The primary objective of this evaluation was to verify and establish the efficacy of these models in effectively detecting Android malware.
In this study, we introduce four DL-based algorithms, namely Convolutional Neural Network (CNN), Autoencoder (AE), Deep Belief Neural Network (DBN), and Deep Neural Decision Forests (DNDF), that are utilized for the purpose of detecting and categorizing malicious Android apps.
The table depicts the performance assessment and resource consumption of all proposed classifiers, including, accuracy (ACC), precision (PRE), recall (REC) training time (TT) in seconds, memory usage (MMU) in MB
The table depicts the performance assessment and resource consumption of all proposed classifiers, including, accuracy (ACC), precision (PRE), recall (REC) training time (TT) in seconds, memory usage (MMU) in MB
The CNN approach demonstrated its highly effective performance in detecting malicious apps on two datasets. The model’s performance is summarized in Table 4. After 100 iterations, the CNN model exhibited exceptional performance, achieving high training and validation accuracies. The model attained training and validation accuracies of 0.997 and 0.986 on the Drebin dataset. Similarly, on the TUANDROMD dataset, the model achieved training and validation accuracies of 0.996 and 0.991. Additionally, the model achieved low training and validation losses, with a training loss of 0.011 on the Drebin dataset and 0.014 on the TUANDROMD dataset, and a validation loss of 0.056 on the Drebin dataset and 0.018 on the TUANDROMD dataset. These results indicate that the model effectively learned the patterns in the training data and demonstrated the ability to generalize to unseen data with satisfactory accuracy. To avoid overfitting, it is essential to maintain a reasonable generalization gap between the learning and validation accuracies and losses. The CNN approach detected malware on both datasets, as indicated by the minimal number of FP and FN. This finding demonstrates the CNN approach’s ability to accurately classify instances of malicious attacks as positive and benign data as negative, with few instances of misclassification. Moreover, the CNN classifiers showed low memory usage, ranging from 578 to 634 MB, and fast execution times, ranging from 1.0 to 1.001 seconds. The outcomes demonstrate that CNN classifiers are highly adept at detecting Android malware and can be trained proficiently on varied datasets.
Performance comparison of AE algorithm regarding accuracy, cross-entropy loss, and CM, using drebin and TUANDROMD. Panels (a) and (b) show the accuracy, panels (c) and (d) Cross-entropy loss (e) and (f) show the confusion matrix, respectively.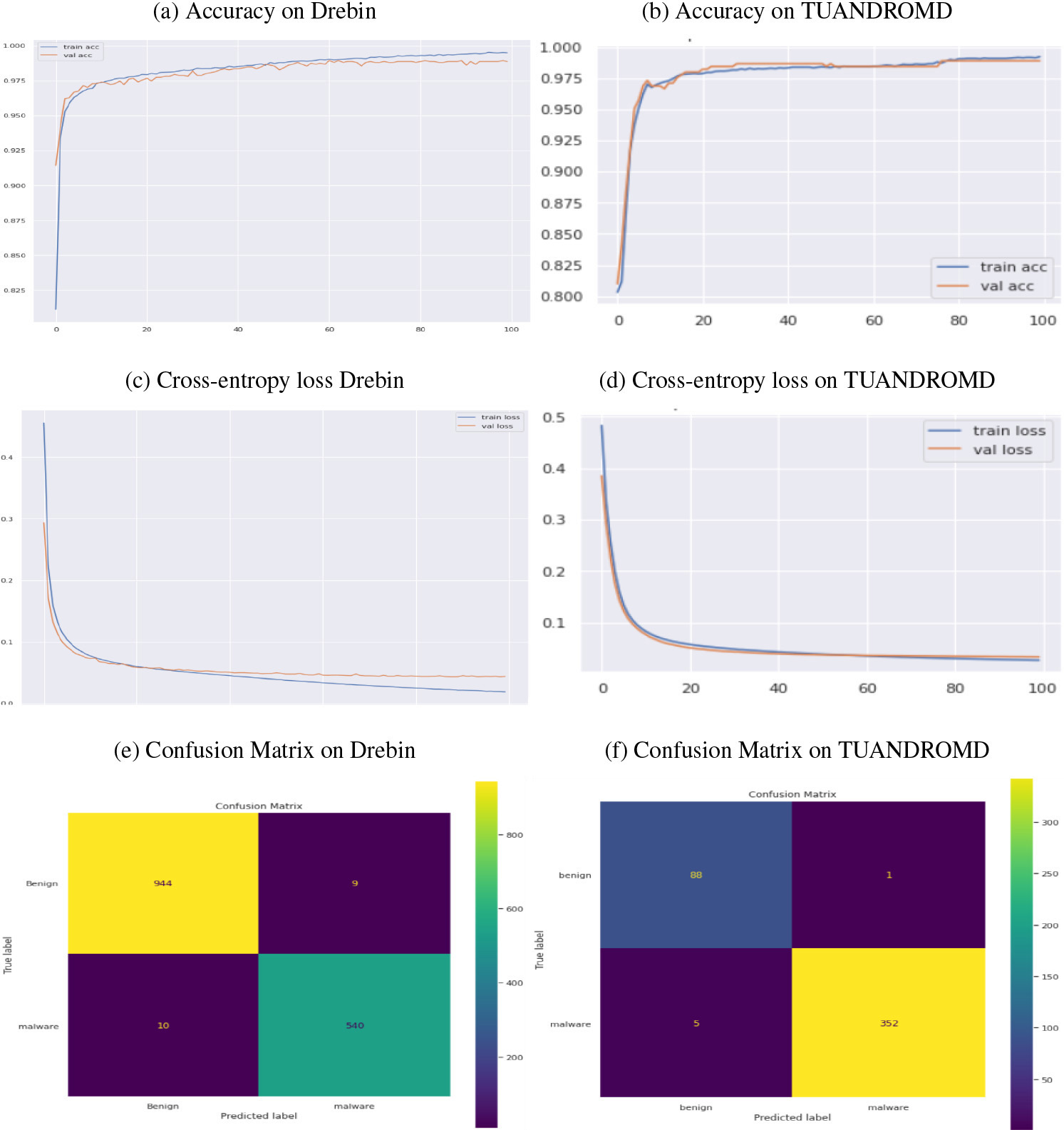
The performance of the AE algorithm in recognising malware was evaluated on two datasets, as depicted in Fig. 2a–f. The algorithm demonstrated exceptional performance on the TUANDROMD dataset, achieving high training and validation accuracies rates of 0.992 and 0.988, respectively, as plotted in Fig. 2a–b. Conversely, it achieved slightly lower accuracy rate on the Drebin dataset, with training and validation accuracy rate of 0.990 and 0.988, respectively. Additionally, the performance analysis revealed that the Drebin dataset exhibited a training loss of 0.018 and a validation loss of 0.043, indicating that the model effectively learned the patterns in the training data and generalized well to unseen data with reasonable accuracy. Similarly, the TUANDROMD dataset demonstrated a training loss of 0.026 and a validation loss of 0.033 as plotted in Fig. 2c–d, suggesting that the model learned the underlying patterns in the training data with high accuracy and successfully generalized to unseen data, as evidenced by the close proximity of the validation and training losses.
The performance of the AE approach was evaluated on both datasets and corresponding confusion matrices were generated, as plotted in Fig. 2e–f. Within the Drebin dataset, the approach successfully detected malware with minimal FP and FN instances. Most of the 540 apps in the dataset were labelled malicious, indicating that the AE classifier identified them as potential threats. Also, 944 instances were classified as TN and recognized as benign apps. In the TUANDROMD dataset, a significant portion of the normal data was classified as TN, accounting for 88 of the dataset’s apps. On the other hand, 352 apps were classified as TP, accurately identifying them as malicious attacks. This indicates that the AE approach effectively distinguished malicious and benign instances with fewer misclassifications. As a result, the AE algorithm exhibited better performance on the TUANDROMD dataset than the Drebin dataset.
Table 4 and Fig. 5a–b reveal high accuracy, precision, and recall scores for the AE classifiers on both datasets, ranging from 0.986 to 0.987 for accuracy, 0.981 to 0.985 for precision, and 0.983 to 0.997 for recall. Regarding resource consumption, the AE classifiers had a higher memory footprint than the CNN classifiers, ranging from 576 to 732 MB. However, the execution time on both datasets was similar to the CNN classifiers, ranging from 1.0 to 1.001 seconds. These findings suggest that AE classifiers effectively detect Android malware but may require more memory resources than CNN classifiers.
Performance comparison of DBN algorithm regarding accuracy, cross-entropy loss, and CM. Panels (a) and (b) show the accuracy, panels (c) and (d) cross-entropy loss, (e) and (f) show the confusion matrix, respectively.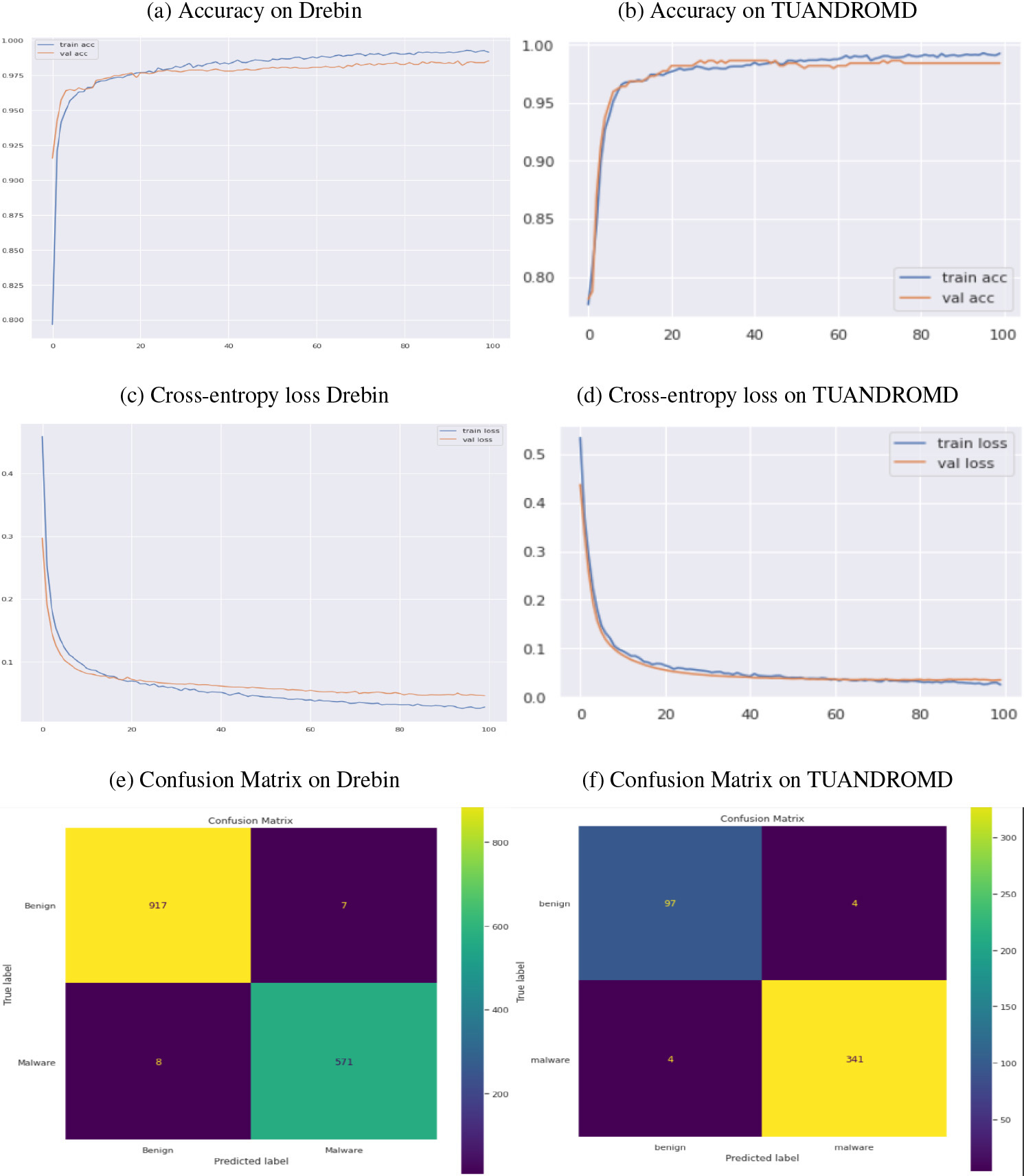
The proposed DBN approach successfully detected malicious Android apps within the Drebin and TUANDROMD datasets. The model’s performance was extensively evaluated, considering accuracy, cross-entropy loss, and the percentage of correctly classified samples for each epoch, as depicted in Fig. 3a–f. After 100 iterations, the DBN model achieved high training and validation accuracies on both datasets. On the Drebin dataset, the DBN model attained training and validation accuracies of 0.991 and 0.985, respectively. Similarly, on the TUANDROMD dataset, the model achieved training and validation accuracies of 0.992 and 0.984, as evident from Fig. 3a–b. The performance of the DBN model was assessed by analyzing the training and validation losses for both datasets, as shown in Fig. 3c–d. The results indicate that the model effectively learned the underlying patterns in the training data and demonstrated reasonable accuracy when generalizing to unseen data. Specifically, the DBN model achieved a training loss of 0.028 and a validation loss of 0.046 on the Drebin dataset. In contrast, the TUANDROMD dataset attained a training loss of 0.025 and a validation loss of 0.035.
The approach employed in detecting malware within both datasets proved highly effective, resulting in a low number of FP and FN. The confusion matrix of the DBN classifier on both datasets can be seen in Fig. 3e–f. Most of the 571 apps were classified as malicious within the Drebin dataset, while in the TUANDROMD dataset, 341 apps were correctly identified as TP and labelled as malicious. According to our research, the DBN method has demonstrated high accuracy in distinguishing between instances of malicious attacks, labeled as positive, and instances of benign data, labeled as negative, with minimal misclassification occurrences. This suggests that the DBN approach is highly effective in distinguishing between malicious and benign data. The approach successfully detected malware in both datasets, exhibiting low FP and FN. In the Drebin dataset, most of the 571 apps were classified as malicious, while in the TUANDROMD dataset, 341 apps were identified as TP and labelled as malicious. These findings of our study suggest that the DBN method has been proficient in precisely categorizing instances of malicious attacks as positive and instances of benign data as negative, with only a small number of misclassifications. Empirical evidence supports the effectiveness of the fused DBN model in detecting Android malware in both datasets. Figure 3c-d presents the performance metrics of the DBN classifiers on the Drebin and TUANDROMD datasets. The DBN classifiers achieved high accuracy, precision, and recall scores, ranging from 0.982 to 0.990 for accuracy, 0.986 to 0.988 for precision, and 0.987 to 0.988 for recall, as shown in Table 4. The memory usage of the DBN classifiers was moderate, ranging from 626 to 681 MB. Additionally, the execution time for both datasets was relatively fast, with a range of 1.0 to 1.001 seconds. These results suggest that DBN classifiers effectively detect Android malware and can be trained efficiently on diverse datasets.
The DNDF approach exhibits remarkable proficiency in detecting malicious apps within both datasets. A comprehensive evaluation was conducted, considering accuracy, cross-entropy loss, and the percentage of correctly classified samples for each epoch. After 100 iterations, the DNDF model achieved exceptional training and validation accuracies on the Drebin and TUANDROMD datasets. Specifically, it attained accuracies of 0.997 and 0.988 for the Drebin dataset and 0.996 and 0.997 for the TUANDROMD dataset, respectively. The performance of the DNDF model, highlighting its ability to detect malicious apps accurately, is depicted in Fig. 4a–b. The model’s effectiveness was evaluated by analyzing both datasets’ training and validation losses. The DNDF model demonstrated efficient learning of patterns in the training data, enabling it to generalize effectively to unseen data with reasonable accuracy. On the Drebin dataset, the model achieved a training loss of 0.011 and a validation loss of 0.047. Similarly, the TUANDROMD dataset attained a training loss of 0.012 and a validation loss of 0.008. Figure 4c–d depicts the model’s efficient learning and generalization abilities.
Performance comparison of DNDF algorithm regarding accuracy, cross-entropy loss, and confusion matrices, panels (a) and (b) show the accuracy, panels (c) and (d) loss (e) and (f) show the confusion matrix.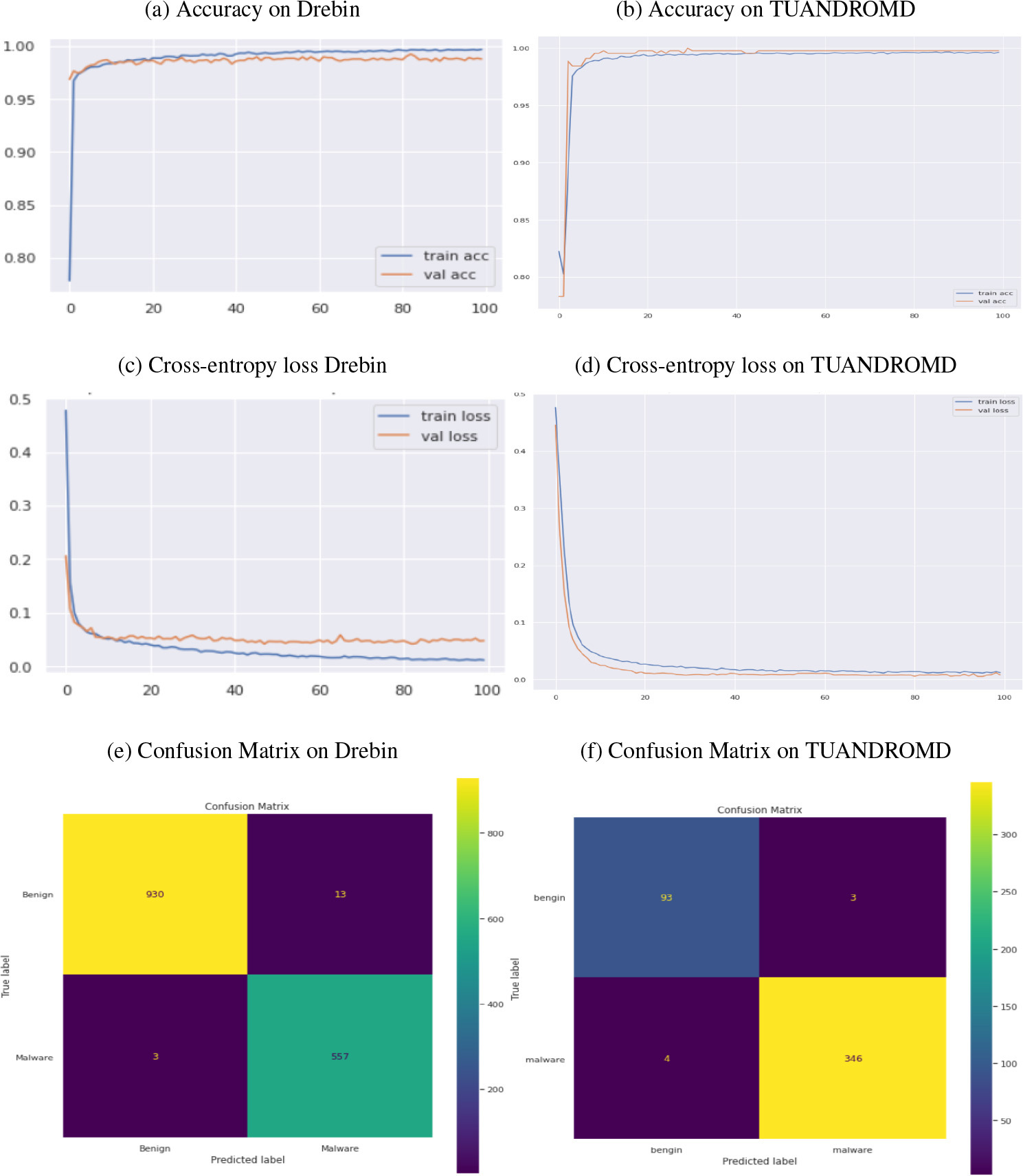
The plotted graph shows the performance evaluation of the proposed model based on precision, recall, sensitivity, MAE, MSE, RMSE, R2Score, and F1Score (a), (c), (e), and (g) on the Drebin, while (b), (d), (f) and (h), TUANDROMD dataset.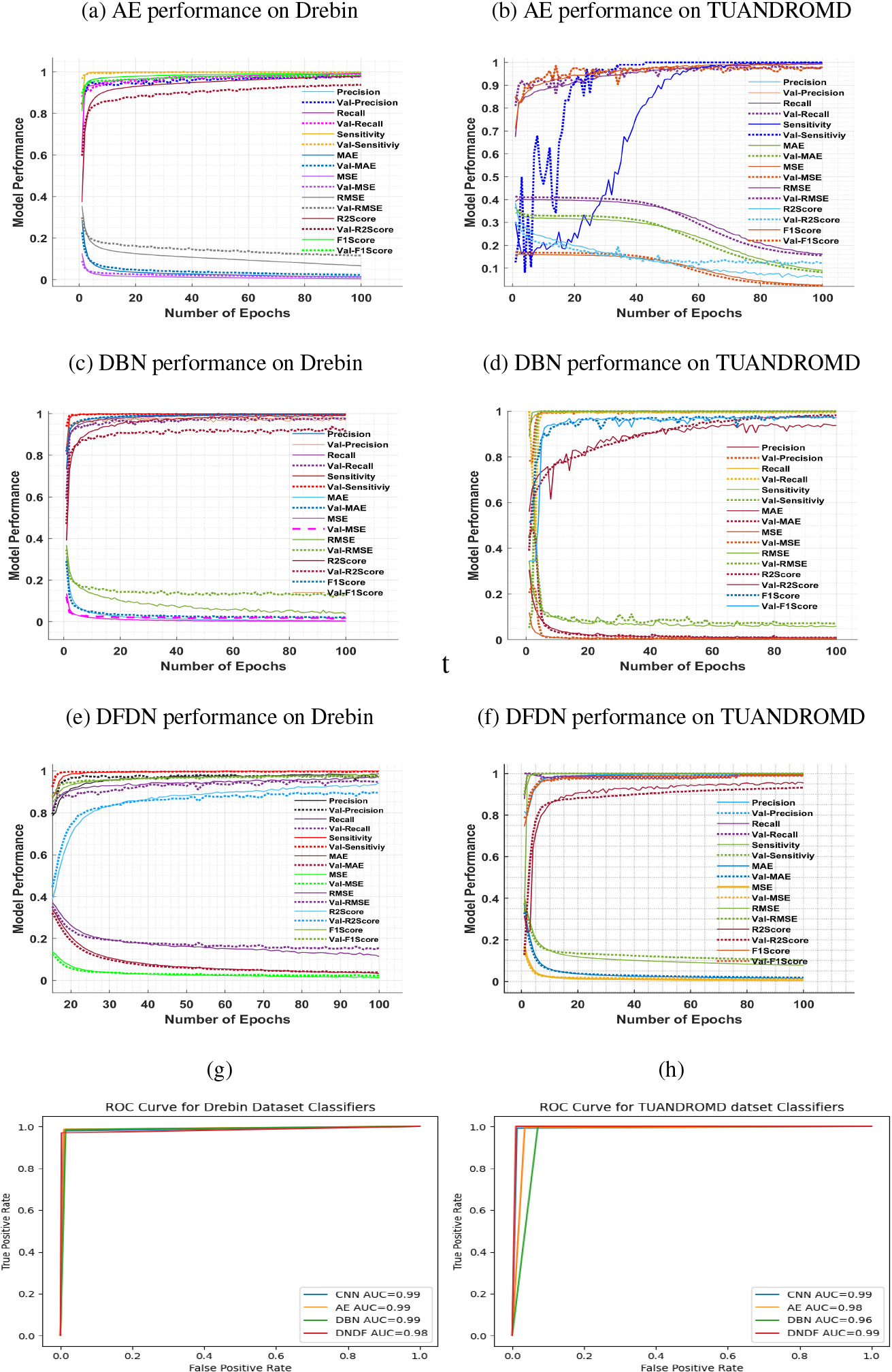
The DNDF approach was further evaluated by analyzing the resulting confusion matrices on both datasets. The approach demonstrated an impressive ability to detect malware in both datasets, with a minimal number of FP and FN, as depicted in Fig. 4e–f. Within the Drebin dataset, most of the 557 apps were classified as malicious, while 930 apps were labelled benign. Besides, in the TUANDROMD dataset, 346 apps were correctly identified as TP and classified as malicious, while only 93 apps were categorized as benign. The DNDF approach successfully detected malicious apps within the Drebin and TUANDROMD datasets, achieving high training and validation accuracies. Table 4 and Fig. 5e–f confirms the strong performance of DNDF classifiers on both datasets, with high accuracy, precision, and recall scores. Regarding resource consumption, DNDF classifiers exhibited a relatively low memory footprint, ranging from 578 to 645 MB. The execution time for both datasets was also relatively fast, ranging from 1.0 to 1.001 seconds. These results suggest that DNDF classifiers effectively detect Android malware and can be efficiently trained on various datasets. Figure 6provides a comprehensive overview of the resource consumption for all four classifiers, including both time and memory. Additionally, Fig. 5g–h illustrates the comparison of ROC curves for all proposed classifiers on both datasets. Based on the ROC curve values, it is evident that all four classifiers CNN, AE, DBN, and DNDF achieved high performance on both datasets. On the Drebin dataset, all four classifiers achieved a high ROC score of 0.99, indicating a very high TP rate while keeping the FP rate low. However, on the TUANDROMD dataset, the CNN classifier achieved an ROC score of 0.99, AE achieved 0.98, and DNDF also achieved 0.99. The DBN classifier achieved a slightly lower ROC score of 0.96 on the TUANDROMD dataset.
In the Android mobile malware analysis field, sensitivity analysis is a statistical approach that measures the impact of uncertainties in input data variables on the accuracy of malware detection models. This analysis helps researchers and analysts identify the most significant features that affect the detection model’s performance and optimize the model’s parameters and configuration. One way to evaluate how well a model performs is by measuring how each input variable affects the model’s output. Statistical measures such as MAE, MSE, RMSE, sensitivity, Area Under the Curve (AUC), and
The performance of a CNN classifier was evaluated on two datasets: Drebin and TUANDROMD. For Drebin, the classifier achieved an MAE of 0.0141, MSE of 0.0110, RMSE of 0.1050, and an
Comparison of MAE, MSE, RMSE,
score, AUC, and sensitivity scores for various models
Comparison of MAE, MSE, RMSE,
Comparison of memory consumption and time performance across four android malware classifiers.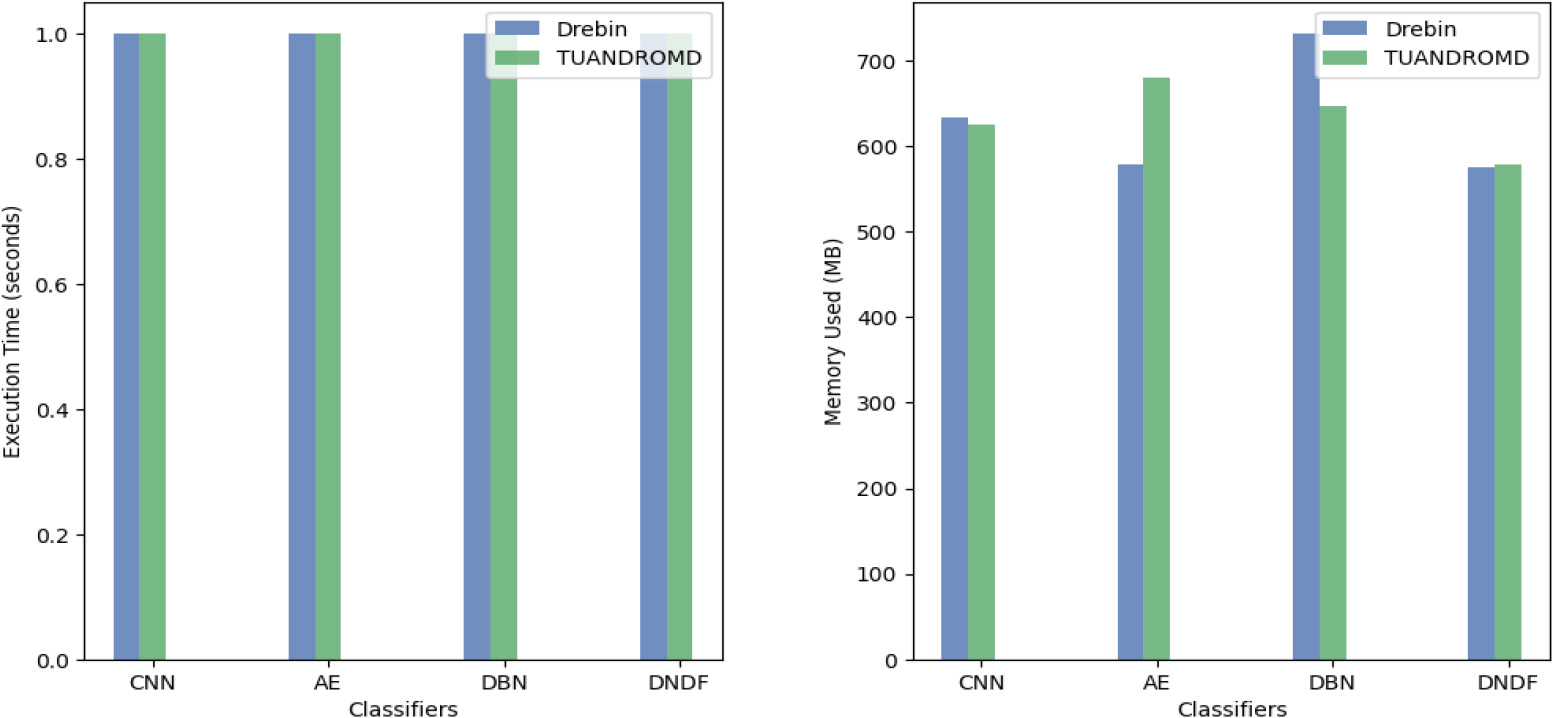
The AE performed well on both datasets, with slightly better results on the Drebin dataset. On the Drebin dataset, the model achieved an MAE of 0.0213, an MSE of 0.0104, and an RMSE of 0.1024, while on the TUANDROMD dataset, it achieved an MAE of 0.0218, an MSE of 0.0119, and an RMSE of 0.1093. The
The DBN classifier underwent an assessment of Drebin and TUANDROMD datasets. On Drebin, the model obtained an MAE of 0.0171, MSE of 0.0083, and RMSE of 0.0914. Conversely, on TUANDROMD, the model obtained an MAE of 0.0234, MSE of 0.0133, and RMSE of 0.1155. The
The efficacy of the proposed security system was assessed, with the drebin and other dataset serving as the basis of comparison to existing security systems
The efficacy of the DNDF classifier was evaluated on two datasets, Drebin and TUANDROMD. On Drebin, the purposed model attained an MAE of 0.0128, an MSE of 0.0098, and an RMSE of 0.0990, with an AUC of 0.98 and a sensitivity score of 1.0. The
The study yielded impressive results, showing exceptional performance metrics. The AUC value was a perfect 1.00, indicating a strong ability to differentiate between positive and negative classes, as depicted in Table 5. The accuracy rates achieved were 0.989 and 0.984, accompanied by perfect sensitivity as depicted in Table 4. Furthermore, the training time required was only 1 second, demonstrating efficiency. A comparison with other approaches, as shown in Table 7 revealed that the proposed system outperformed most state-of-the-art methods, despite being a DL model. Although the model described in Li et at. [55] achieved higher accuracy, it employed a multi-layer perceptron (MLP) with an excessively large number of features 93,324. As a consequence, this approach consumed significant computational resources and had a training time of approximately 5 seconds.
In contrast, our proposed model achieved slightly lower accuracy but with the significant advantage of requiring fewer computational resources, resulting in a speedy training of just 1 second. Typically, DL-based algorithms have a higher number of parameters that need to be optimized during training. They often demand more training data compared to traditional ML-based algorithms for achieving good performance. However, our proposed system has demonstrated exceptional performance measures, surpassing state-of-the-art approaches. The results indicate that the proposed classifiers are computationally efficient and have the potential to be deployed in mobile environments. All proposed classifiers showed inference times of less than 1.5 seconds, making them practical for real-time usage on mobile devices. Furthermore, the memory consumption and CPU/GPU utilization remained stable throughout the experiments, indicating efficient utilization of available resources by the classifiers.
Comparison of classifier performance in terms of accuracy, time, and computational resources
Comparison of classifier performance in terms of accuracy, time, and computational resources
Table 6 summarizes the performance comparison of various classifiers on different datasets for Android malware detection. Our proposed system, using DNDF classifiers, outperforms existing state-of-the-art approaches in terms of AUC. Additionally, our classifiers exhibit reasonable training times and memory usage. Overall, our system provides an effective and efficient approach for Android malware detection.
In this study, a security system was developed and designed, incorporating the use of CNN, AE, DBN, and DNDF algorithms. The research yielded highly promising results, and the following conclusions can be drawn based on these findings. To evaluate the effectiveness of our proposed system and enable comparison with previous studies, we employed the Drebin dataset and the TUANDROMD dataset. The Drebin dataset allowed us to benchmark against earlier research. In contrast, the TUANDROMD dataset provided an advantage in detecting modern threats that employ advanced obfuscation and morphing techniques, rendering traditional methods ineffective. The DNDF model exhibited the best performance on both the Drebin and TUANDROMD datasets, achieving the lowest values for MAE, MSE, and RMSE and the highest
In our future research endeavours, we will prioritize the development of a dependable cloud-based function for updating ML and DL-based models. We also aim to optimize the classifier by reducing its memory and processing requirements. Moreover, our focus will be on enhancing the classifier’s accuracy by integrating additional datasets and classifiers into our approach.
Footnotes
Conflict of interest
The authors declare that they have no conflict of interest.
Funding
The work presented in this paper has been supported by Beijing Natural Science Foundation (No. IS23054). The author would also like to thank Prince Sultan University, Riyadh, Saudi Arabia, and Lasbela university of Agriculture water and marine sciences for their support.