
Abstract
Human activity recognition has been gaining more and more attention from researchers in recent years, particularly with the use of widespread and commercially available devices such as smartphones. However, most of the existing works focus on discriminative classifiers while neglecting the inherent time-series and continuous characteristics of sensor data. To address this, we propose a two-stage continuous hidden Markov model framework, which also takes advantage of the innate hierarchical structure of basic activities. This kind of system architecture not only enables the use of different feature subsets on different subclasses, which effectively reduces feature computation overhead, but also allows for varying number of states and iterations. Experiments show that the hierarchical structure dramatically increases classification performance. We analyze the behavior of the accelerometer and gyroscope signals for each activity through graphs, and with added fine tuning of states and training iterations, the proposed method is able to achieve an overall accuracy of up to 93.18%, which is the best performance among the state-of-the-art classifiers for the problem at hand.
Keywords
Introduction
The past decade has opened up the development of a wide range of sensors and mobile devices with unprecedented characteristics. The exceptional efficiency, portability, and affordability of these devices naturally extended their availability to a more diverse number of people. 1 More specifically, the number of smartphone users worldwide is expected to catapult to 1.75 billion in 2014, having only reached the 1 billion mark last 2012. As a result, more and more people have come to rely on and interact with these devices as part of their normal daily lives.
These events bring about a great number of possibilities. On top of various applications using smartphone sensors such as Bluetooth-aided mobile phone localization and distributed range-free localization of wireless sensor networks, the use of sensors to recognize human activities has sparked a lot of research interest due to its promising applications in the areas of pervasive and mobile computing, surveillance-based security, ambient assistive living, and context-aware computing. 2 Activity recognition has also made its debut recently as the key component on several consumer products such as Nintendo Wii and Microsoft Kinect. 3 Although they were originally made for the purpose of gaming and entertainment, these systems have attracted additional applications, such as personal fitness training and rehabilitation, and have also brought about further research in human activity recognition (HAR).4,5
In addition to this, smartphone sensor technologies are developing at an incredible pace. Various context-related sensors are now normally embedded into mobile phones, such as Global Positioning System (GPS), Wi-Fi, Bluetooth, accelerometers, magnetometers, gyroscopes, barometers, proximity sensors, temperature and humidity sensors, ambient light sensors, cameras, and microphones. 6 With the unmistakable prevalence of the smartphone, together with its variety of readily available sensors, it is only natural to exploit such a mass-marketed device to be able to automatically recognize human daily activities without imposing inconveniences to the user. 7
Most research works in activity recognition have focused on using discriminative approaches such as support vector machines (SVM) and decision trees, neglecting the time-series component of sensor signals. Although these models are light-weight, they are systems that require the use of a rich set of features, which in turn increases computational costs, in exchange for algorithm simplicity.3,8–10 To take advantage of this inherent characteristic of sensor signals, particularly from the accelerometer and gyroscope of a smartphone, we propose a temporal probabilistic approach to activity recognition. A hidden Markov model (HMM) is a Markov chain with both hidden and unhidden stochastic processes. Thus, for the context of activity recognition, the unhidden or observable components are the sensor signals, while the hidden element is the user’s activity. There are several researchers to utilize HMM for activity recognition, but most of them are based on discrete HMM that only fits to the static images of data. However, since signals are inherently real-valued and it may incur loss of relevant detailed information to convert them to discrete values, 11 we exploited continuous hidden Markov models (CHMMs) for the task.
Activities are inherently hierarchical, 12 that is, a person has to be stationary in order for him to be considered standing (ST), or that a low-level activity like sitting (SI) is generally the position of a person who is doing a high-level activity like eating. We make use of this simple knowledge and employ a hierarchical architecture of CHMMs to recognize activities. This kind of system architecture also enables us to use different feature sets for different stages, of which random forest (RF) variable importance (VI) measures are utilized for feature selection. We show that RF VI measures are more accurate in identifying the most important variables (In the field of pattern recognition, the terminology of variable is interchangeably used with feature. In this article, we also use them several times with the same meaning.) compared to other feature selection methods, the hierarchical structure of the proposed method significantly improves activity classification performance and allows the usage of a varying number of states in the same subclass, as well as a varying number of training iterations for each activity of CHMM. Main contribution of this work lies in proposing a natural and maybe popular classifier architecture of CHMMs for better performance for this problem at hand.
Related works
One of the most cited works on HAR is the one by Bao and Intille. 13 Data were collected from 20 users, each wearing five biaxial accelerometers placed on strategic parts of the body. An accuracy of around 80% was obtained after classifying 20 different activities using simple decision trees and fast Fourier transform (FFT)-based features. The work also specifically indicated that the sensors placed on the individual’s thigh and dominant hand take the most important role in recognizing activities. Other recent works also reinforced this claim.14,15
In addition to Bao and Intilles’ work, there are several other studies which focused on using multiple accelerometers to perform activity recognition.16,17 However, this approach is evidently inconvenient and somewhat obtrusive to the user besides being less accurate compared to using only a single strategically placed accelerometer. 15
There are also some works which used a single tri-axial accelerometer. Using a single wrist-worn accelerometer, Chernbumroong et al. 18 recognized five basic activities with 13 time- and frequency-based features using decision trees. Another work placed the accelerometer on the subject’s waist to recognize six basic activities using k-nearest neighbors and naïve Bayes classifiers. 19 Sharma et al. 20 used neural networks, while Khan used the Wii Remote to classify basic activities. 4 These works have indeed achieved high accuracies with their proposed set of simple features and classifiers, but note that they did not include two basic activities that are a little bit more difficult to classify—upstairs and downstairs movements—a factor which had a considerable contribution to their high results. Rubaiyeat et al., 21 however, included the aforementioned movements and achieved lower accuracy than previous works by Chernbumroong et al. 18 and Gupta and Dallas. 19
Other earlier published works have already made use of commercially available devices such as smartphones. Yang 22 used a Nokia N95 mobile phone’s accelerometer with decision trees and HMM to classify six activities. Kwapisz et al. 23 used an Android smartphone’s single tri-axial accelerometer placed on the user’s pants pocket to recognize six basic activities using three different classifiers. However, the former also excluded upstairs and downstairs movements, while the latter failed to achieve high accuracy on upstairs and downstairs movements. It is interesting to note that the former particularly suggested the use of HMMs in order to capture more temporal correlations in the model. Moreover, this also shows that data from the accelerometer are not enough to efficiently differentiate between upstairs and downstairs movements.
Various other sensors were also investigated when used together with the accelerometer. Wu et al. concluded that the addition of the gyroscope is very beneficial, while Shoaib et al. fortified the claim that accelerometers and gyroscopes are not only efficient when used alone but also significantly improves classification performance when used on top of each other.
HMMs have been widely applied in the field of activity recognition in conjunction with multiple accelerometer sensors. Olguin and Pentland 26 made use of three tri-axial accelerometers placed on right-wrist, left-hip, and chest to classify eight basic activities (excluding upstairs and downstairs movements). Their system achieved around 92% overall accuracy and suggested to model each activity with a different number of hidden states. Travelsi et al. 27 considered an unsupervised learning approach using multiple HMM regression. They used three accelerometers placed on the chest, thigh, and ankle to recognize six activities, including upstairs and downstairs movement, and achieved around 91% classification accuracy. Mannini and Sabatini 28 obtained the data set gathered by Bao and Intille, extracted and used a sub-dataset to classify seven basic activities (including upstairs movement), and obtained a very high accuracy for CHMMs.
Khan et al. 29 applied a hierarchical neural network recognizer to classify 15 static, transitional, and dynamic activities using their proposed augmented feature vectors and obtained exceptionally high results. Our previous work, 30 involving the recognition of low- and high-level activities, successfully made use of hierarchical HMMs, albeit the difficulty in differentiating upstairs and downstairs movements. Multi-stage system architectures in conjunction with HMMs have also been successfully implemented in different application domains, such as attack and intrusion detection, gesture recognition, and smart home environments.31–33
Finally, our previous work, 34 which incorporates multi-staged CHMMs for activity recognition using the accelerometer and gyroscope, is extended through a more comprehensive experimentation and analysis method—CHMM states were varied in each subclass, and the effect of gradually increasing Baum–Welch (BW) iterations is examined.
The proposed method
The proposed method is composed of a hierarchical structure of CHMMs (as seen in Figure 1). This kind of architecture enables us to exploit the inherent hierarchical characteristics of activities, 12 while CHMMs are advantageous to use with continuous observation densities such as sensor signals. 24 Moreover, feature selection is performed through utilizing RF VI measures since RF VI works significantly well with continuous, possibly highly correlated variables. 25 The hierarchical structure also enables us to use different feature subsets for different subclasses while minimizing feature computation time.

The proposed hierarchical structure in conjunction with CHMMs.
Feature selection using RF VI measures
RF is an ensemble classification method pioneered by L Breiman. This technique is the result of combining bagging and random feature selection, creating a collection of simple decision trees, T = h(x,Θ k ), k = 1, …, K, where {Θ k } are independent, identically distributed random vectors, that perform the task of classification by voting for the most popular class at input x, that is

where p(c|v) is the average classification output of all the trees T, v is the bootstrapped data, and c is the class. The ensemble method can be used to obtain useful estimates, VI. 35
The first step to computing VI is fitting the training data into a RF model, followed by the computation of the out-of-bag (OOB) error at each data point in the forest. With the use of random data sampling, out-of-bagging is performed by leave-one-out cross validation, where data points are randomly permuted in an OOBY sample, to get the perturbed sample OOBYj. The error of variable Y is calculated through the perturbed and unperturbed samples, and the summation of their difference is averaged over the total number of trees in the forest, ntree, obtaining the VI of Y, given by
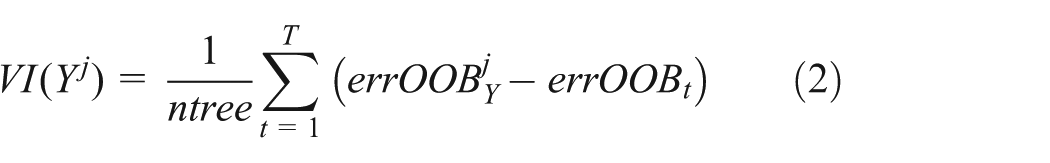
The scores are then normalized with the standard deviation.
Hierarchical CHMMs
HMM is a doubly embedded stochastic process, composed of an unobservable stochastic process (hidden) and another set of stochastic processes that produces the sequence of observations—which is the only avenue to be able to observe the hidden one. It is most suitable in modeling time-series data such as those that can be found in speech recognition and signal processing applications. 24
The problem arises when, in applications such as activity recognition through signals (or vectors) produced by sensors, observations are continuous. Although it is definitely possible to quantize these signals into discrete symbols, it is undeniable that there will be serious degradation after the quantization process. Therefore, for such applications, it is advantageous to use HMMs with continuous observation densities. 24
If the observed process {Yn| n ∈ N} is real-valued or vector-valued in a Euclidean space

The initial probability distribution π = {πi} is denoted by

while the state transition probability distribution A is indicated by the matrix {aij} where

For a CHMM, the observation probability distribution B corresponds to a family of parametric probability density functions (pdfs)

where

which is the same as a pdf. The parametric model for CHMM emission densities used in this work is the finite mixture of Gaussian pdfs, given by

where vik is the mixture coefficient for the kth mixture in state i and
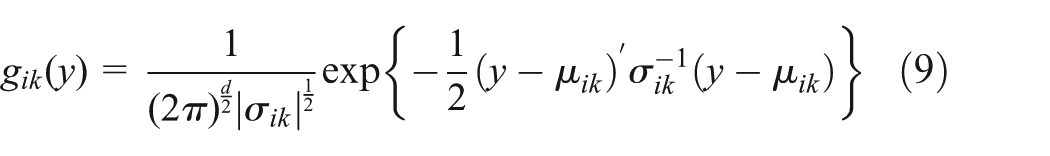
The mixture gains should satisfy the stochastic constraints


so that the pdf is properly normalized.
The proposed method is divided into two stages: the first level, which categorizes activities into Dynamic or Static subclasses, and the second level, which outputs the final activity class C = {Walking, W; Walking Upstairs, WU; Walking Downstairs, WD; Sitting, SI; Standing, ST; Laying, L}, where {W, WU, WD} ∈ Dynamic; {SI, ST, L} ∈ Static.
The BW algorithm is a special case of the expectation maximization (EM) algorithm, which is used to adjust the model parameters (A, B, π) in order to maximize the probability of a given observation sequence, O = O1O2…OT, given the model λ, that is, P(O|λ). Using the iterative procedure of the algorithm, we re-estimate the current model λ to find a new model

over
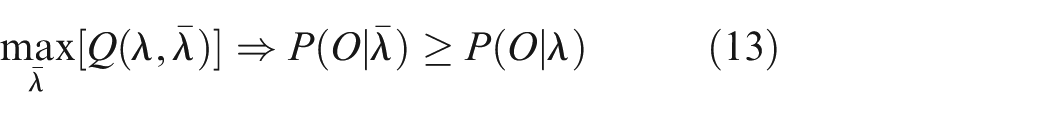
which yields an increase in likelihood. Iteratively, using
Figure 2(a) shows how the first-level CHMMs are trained. Acceleration and gyroscopic data are preprocessed, which include scaling and feature selection by RF, and fed to first-level CHMMs for training. CHMMs on this level have two states, corresponding to the number of classes or activities to be classified at a certain instance.17,19 A two-state CHMM is denoted by the pdf

where θi = (µi, σi) and i = 1, 2 (two states). All Dynamic training data are fed to the dynamic CHMM, while all Static training data are directed to the static CHMM. Thus, for each subclass e ∈ E, a resulting trained CHMM λe is created.

Training of (a) first-level and (b) second-level CHMMs.
Conversely, CHMMs on the second level will first have three states,17,19 but these states will be varied to examine its effect on classification performance. 26 Training for this level is also different from the first level such that CHMMs for Dynamic activities use a completely different feature subset from CHMMs for Static activities. For each subclass, we build a CHMM λed for each dynamic activity and λes for each static activity and estimate the model parameters (A, B, π) d and (A, B, π) s , respectively, that optimize the likelihood of the corresponding training observations (as seen in Figure 2(b)).
Given the trained models resulted from repeated iterations of BW, new data, which are processed to produce the same feature subset as the corresponding training data, are classified into Dynamic and Static subclasses on the coarse classification stage (as seen in Figure 3(a)). Thus, given a trained CHMM λe and a feature subset of new data OT, we estimate the likelihood of the observation OT belonging to first-level subclass e ∈ E. Using the relationship P(OT|λe) estimated across all CHMMs in this level, we select the activity with the highest probability given by


(a) First-level CHMMs for coarse classification and (b) second-level CHMMs for fine classification.
The forward–backward algorithm is used to compute P(OT|λe), as shown in Figure 4. Given a forward variable

which is the same as the probability of the partial observation sequence, O1O2…Ot and state Si at time t, given the model λe, P(OT|λe) can be computed by first initializing the forward probabilities as the joint probability of state Si and first observation O1
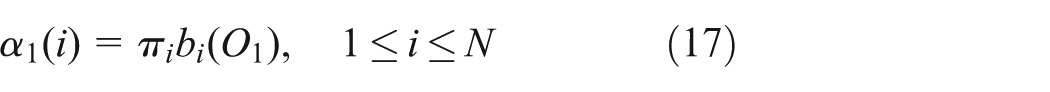
that is, the first row on every α table in Figure 4. The forward probability of reaching state Sj at time t + 1 from N possible states Si, i = {1, 2, …, N}, at time t is

where αt(i)aij is the probability of the joint event that O1O2…Ot are observed, and state Si is reached at time t + 1 via state Si at time t. The summation of these joint probabilities over all possible N states at time t is the probability of Sj at time t + 1, with all the previous partial observations included. The forward probability at time t + 1 can then be computed by multiplying the summed quantity by the probability accounting for observation Ot + 1 in state j, bj(Ot + 1).

The forward–backward algorithm for determining the class e of a given observation sequence Oseq.
Equation (18) is repeatedly performed for all states j at a given time t, and this process is performed recurrently for all t = 1, 2, …, T − 1. Thus, we arrive at the probability of the observation OT, given the model λe, given by

where αT(i) is the forward terminal variable at state i.
Once activities are categorized according to their respective subclasses on the first level, we then proceed to classify test data into their corresponding activity, C = {W, WU, WD, SI, ST, L}. 9 This is done by fine classification on the second level.
Given the test feature subset that was categorized in the previous level, now OTd and OTs, the forward–backward algorithm is again used to determine the activity with the highest probability ed* and es* for the dynamic and static subclasses, respectively (as seen in Figure 3(b)).
Experiments
HAR data set
The publicly available UC Irvine (UCI) HAR data set was used throughout our experiments. 9 This data set is composed of accelerometer and gyroscope normalized data values gathered from a Samsung Galaxy S II smartphone worn on the waist by 30 subjects performing a protocol of activities at 50 Hz. The data set also includes 561 features computed from 50% overlapped sliding windows, each window being 2.56 s in length. It is partitioned into 70% training data (from 21 subjects chosen randomly) and 30% test data (from the remaining 9 subjects).
Exploratory analysis and scaling
Figure 5 shows the correlation heat maps of accelerometer and gyroscope inertial values from subject 1. As can be observed from the graph, W is significantly different from WU and WD and thus can be easily separated during classification. However, WU and WD have very similar accelerometer correlation plots, while their gyroscope heat maps are noticeably different. This clearly illustrates the need for the gyroscope to distinguish between the two very similar activities.

Correlation heat maps of sensor inertial values for each activity.
From the heat plots of SI, ST, and L, it is evident that their acceleration values are enough to easily set them apart. We will see later that these simple observations will clearly manifest in the feature subsets derived using RF.
By considering equations (16)–(18), and knowing that each a and b term is usually significantly less than 1, one can observe that as t starts to become larger and larger (in the case of long observation sequences), αt(i) starts to head exponentially to zero. The only way to prevent this underflow phenomenon from happening is by scaling. 24
Examining the out-of-the-box HAR data set, values are normalized but not z-scaled, that is, the variables do not have a mean of approximately zero and a standard deviation of 1. Scaling is performed by extracting z-scores (standardized scores) for each variable Yn, given by

where z is the scaled value, µ is the mean of all data points in variable Yn, and σ is the standard deviation of all variable points.
Feature selection using RF VI
The whole feature data set, consisting of 561 variables, is fitted to an RF model 50 times to obtain the average VI measure for each variable per activity. 36 Predictors with VI values higher than the mean VI of all predictors are retained and ranked in descending order, producing a feature subset of Y1:m + 1 variables. Using CHMM as the wrapper algorithm, a combination of step-wise and 10-fold cross-validation procedure is performed to create multiple models λm, m ∈ M, starting from the two most important variables Y1:2 (which produces λ1) and ending with the feature subset including all Y1:m + 1 variables (which produces the final model λm as seen in Figure 6). The variables of the model with the least error rate are then adopted to become the feature subset for the coarse classification stage, F0. Figure 7 shows that the model with the lowest error rate was obtained after the addition of the 119th variable; thus, the first-level feature subset F0 consists of these 119 variables.

The step-wise cross-validation procedure.

Error rates of first-level CHMM per the number of features.
Upon examination of the resulting feature subset, it is apparent in the per-activity VI values that the features with high VI for Dynamic activities have substantially low VI for Static activities. Thus, it is clear that the separation of Dynamic and Static activities into subclasses is beneficial so as not only to boost classification performance but also to minimize feature computation cost by using fewer variables for each second-level subclass.
The second-level feature subsets, FD and FS, are derived from the first-level subset. As discussed earlier, FD should contain less accelerometer-based features (since gyroscope-based features are more beneficial for the Dynamic subclass) compared to the F0. By performing the same step-wise cross-validation procedure as F0 for each subclass, the resulting dynamic subset FD and static subset FS were produced, the former consisting of 95 less accelerometer-based variables, while the latter consisting of five accelerometer-based variables. Note that the majority of FD features and all five features of FS are time-based; this is important since total energy overhead when generating time-based features is significantly lower than when generating frequency-based ones, especially since the activity recognition platform is a smartphone with limited battery life. 37
To compare our feature selection method with other commonly used dimension reduction techniques, we derived feature subsets using correlation, 38 principal component analysis (PCA), 39 and step-wise linear discriminant analysis (LDA) 40 on the original feature data set. The resulting number of features for each method and the corresponding error rates obtained after applying it on two stage-continuous HMM (TS-CHMM) is shown in Table 1. RF VI measures achieved the lowest error rate, on top of having the lowest number of resultant features. This error rate, however, is not the final error rate of the proposed model, as will be discussed next.
Error rates of different dimension reduction techniques using TS-CHMM.

PCA: principal component analysis; LDA: linear discriminant analysis; RF VI: random forest variable importance.
RF VI measures use different numbers of features for dynamic (95) and static activities (5).
Model training and evaluation of results
First-level CHMMs are trained using feature subset F0 through two BW iterations. This produces perfect classification performance on test data for the first level. The second-level CHMMs are trained using subset FD for the dynamic subclass and subset FS for the static subclass. Given the resulting trained CHMMs, Figure 6 illustrates how the optimal class e* for each subclass is obtained using the forward–backward algorithm. Referring to equations (16)–(19), the reader will be able to follow the process flow of the forward algorithm until we arrive at a value for the probability of the test observation sequence Oseq = (O1O2…OT) with corresponding ground truth (class) e, given the model λ, that is, P(Oseq|λ). The output class e* given an observation sequence Oseq corresponds to the CHMM λe which produces the maximum probability among all CHMMs in the subclass.
We study the effect of varying number of BW iterations on the proposed hierarchical model. However, for the second level, the number of iterations was gradually increased from 1 to 70, while the number of states of the CHMMs remained unchanged (three states). Figure 8 shows the rise and fall of classification performance with an increase in the number of iterations. It can be concluded that there is definitely a peak performance that can be achieved with varying number of iterations, that is, the parameters of the model with peak performance are neither overfitted nor underfitted, and therefore is more generalized and robust to new data as compared to models fit with suboptimal number of iterations. Peak number of iterations for the dynamic subclass is 27, for the static subclass, 58, achieving a dynamic subclass accuracy of 92.44% and a static subclass accuracy of 93.38%, increasing the overall classification performance of the system on test data to 92.91%.

Classification performance trend on test data with an increase in the number of BW iterations (x-axis) under same-state conditions (three states).
Next, we investigate the effect of using CHMMs with different number of states as we vary the number of BW iterations on the dynamic subclass. For every scenario, the number of BW iterations has been derived by changing the iterations for W in intervals of 5 until 50, until we find the highest performance accuracy, and repeated the procedure on both WU and WD. As can be observed in Table 2, we can arrive at a more appropriate combination of number of states and iterations to gain better accuracy. 26 Modeling W with a two-state CHMM and WU and WD with three-state CHMMs gave the highest performance boost, as compared to the performance when we modify only the number of iterations. This also shows that WU and WD needed a more complex CHMM structure than W. In addition to this, it can be observed from the table that two-state CHMMs seem to need more BW iterations, while three-state CHMMs mostly give off optimal performance when trained around 25 times.
Overall accuracies of the dynamic subclass on test data when both number of states and iterations are varied.

BW: Baum–Welch.
Values are represented as x/y/z where x denotes the number of states, y denotes the number of BW iterations, and z denotes the accuracy.
We adopt the model with the highest classification performance in Table 2 and compare the proposed method with other commonly used HAR classifiers. Figure 9 shows the accuracies of different classifiers, with TS-CHMM achieving the highest overall classification performance of 93.18%.

TS-CHMM compared to other HAR classifiers.
The confusion matrix of the final model, along with its precision and recall measures, is shown in Table 3, which shows the number of data in each activity that are classified correctly and incorrectly. Referring to our previous confusion matrix in Ronao and Cho, 34 there is noticeable improvement in the recognition of WU and WD activities. Using a more appropriate number of states for each activity class results in an increase in overall accuracy of 2%.
Confusion matrix of the final TS-CHMM.

W: Walking; WU: Walking Upstairs; WD: Walking Downstairs; SI: Sitting; ST: Standing; L: Laying.
Additional experiment with USC-SIPI human activity data set
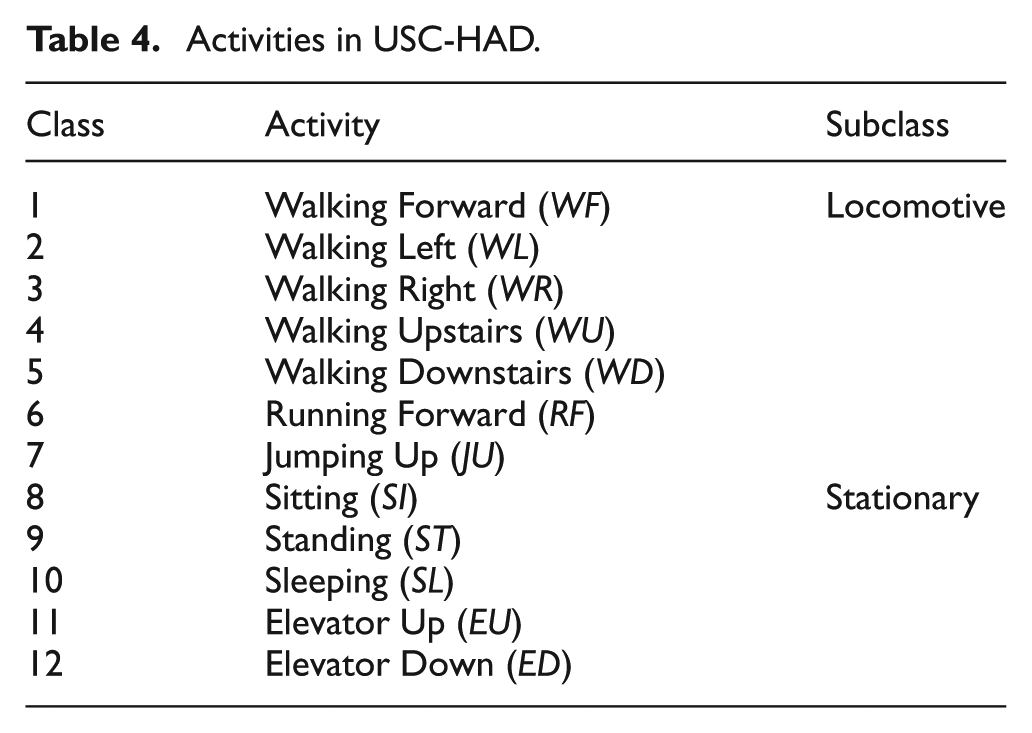
We used one more data set for experiments, called USC-HAD. 41 This data set is composed of raw accelerometer and gyroscope values gathered from a device called MotionNode worn by seven males and seven females. The subjects performed 12 activities for each five times with sampling rate 100 Hz. For each class, we select seven activities for locomotive and other five activities for stationary. Table 4 shows detailed activities.
Activities in USC-HAD.
We have processed the data set with co-efficiencies and FFTs, and finally got 104 features in total. Table 5 shows the features obtained after preprocessing. The data set is partitioned into 80% training and 20% test data.
Features of USC-HAD.

FFT: fast Fourier transform.
As a result of feature extraction using RF VI, first-level CHMM has 63 features and second-level CHMMs for locomotives and stationaries have eight and three features, respectively. Finally, we have obtained TS-CHMM with the highest accuracy of 67.07% as shown in Table 6.
Confusion matrix of the TS-CHMM for USC-HAD.

WF: Walking Forward; WL: Walking Left; WR: Walking Right; WU: Walking Upstairs; WD: Walking Downstairs; RF: Running Forward; JU: Jumping Up; SI: Sitting; ST: Standing; SL: Sleeping; EU: Elevator Up; ED: Elevator Down.
Figure 10 shows that TS-CHMM has better accuracy than other classification techniques, naïve Bayes, neural network, decision tree, and CHMM in most activities. In the comparison experiment, we adopt CHMM with 12 states per one activity, and neural network with 100 epochs. Table 7 shows the detailed overall accuracies in average and t-test results. TS-CHMM has better accuracy in significance levels compared with all the classification techniques. Compared with the experiments on the first data set, the performance in accuracy has deteriorated significantly. This may show that this data set is more difficult to recognize in terms of the number of activities and the quality of data. However, this does not diminish the superiority of the proposed method compared to the conventional methods in performance.

TS-CHMM compared to other HAR classifiers (USC-HAD data set).
Fivefold cross validation and t-test result (USC-HAD data set).

CHMM: continuous hidden Markov model; NB: naïve Bayes; NN: neural network; DT: decision tree.
Significant at level ***0.001; **0.01; *0.03.
Conclusion
We have shown the benefits of taking advantage of the inherent hierarchical structure of activities using a two-stage system structure in conjunction with CHMMs. This system architecture has also made way to the use of different feature subsets for different subclasses on the second level, as well as to the examination of the effect of varying the BW iterations only, and varying both the number of states and BW iterations for each activity class. We are convinced that more complex activities need to be modeled with more states compared to simpler ones, and CHMMs with less states need more training iterations than CHMMs with more states.
The proposed method is surely to consume some computational resources that might cause the battery consumption, even though it has been implemented to run inside the smartphone due to the powerful hardware of the recent version of smartphones. However, we can think of a couple of plausible solutions to address this issue: (1) offline computation from elsewhere but use the learnt results on-line on the phone, or (2) the computation is achieved on clouds but transmitted to the phone via communication. These solutions might raise some new issues, such as how to adaptively learn and update the results for (1) and how to reduce communication cost for (2).
In addition, we suggest considering a wider range of number of states and iterations while varying them so as to be able to investigate the behavior of CHMMs when used with very large number of states or trained with significantly higher number of iterations. Deriving more effective, energy-efficient features is also another direction for future work.
Footnotes
Academic Editor: Dr Stefano Savazzi
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Industrial Strategic Technology Development Program 10044828, Development of Augmenting Multisensory Technology for Enhancing Significant Effects on the Service Industry, funded by the Ministry of Trade, Industry and Energy (MI, Korea).