
Abstract
Visual sensor networks have emerged as an important class of sensor-based distributed intelligent systems, where image matching is one of the key technologies. This article presents an affine invariant method to produce dense correspondences between uncalibrated wide baseline images. Under affine transformations, both point location and its neighborhood texture are changed between views, so dense matching becomes a tough task. The proposed approach tends to solve this problem within a sparse-to-dense framework. The contribution of this article is in threefolds. First, a strategy of reliable sparse matching is proposed, which starts from affine invariant features extraction and matching and then these initial matches are utilized as spatial prior to produce more sparse matches. Second, match propagation from sparse feature points to its neighboring pixels is conducted in the way of region growing in an affine invariant framework. Third, the unmatched points are handled by low-rank matrix recovery technique. Comparison experiments of the proposed method versus existing ones show a significant improvement in the presence of large affine deformations.
Introduction
Visual sensor networks have emerged as an important class of sensor-based distributed intelligent systems. Consisting of a large number of low-power camera nodes, visual sensor networks support a great number of novel vision-based applications, such as visual surveillance, camera calibration, three-dimensional (3D) modeling, and so on. 1 Image matching is one of the key technologies in visual sensor networks, and it is also a fundamental problem of many applications, such as 3D reconstruction, camera calibration, motion prediction, and image stitching. This problem is particularly challenging when there exist significant spatial transformations between wide baseline image pairs. The geometric deformations, such as translation, rotation, scaling, skew and stretch, can cause great matching ambiguity. So, the main difficulty is to find an invariant approach under various spatial transformations.
The simplest transformation is a small translation in one dimension. Traditional dense two-frame matching algorithms aim at computing disparity maps for these short-baseline images. 2 In this situation, the search space of disparity only contains one dimension, and matching confidence can be measured by the correlation of corresponding local patches. These algorithms can be broadly classified into two classes: global3,4 and local. 5
Matching becomes even more difficult in wide baseline cases. For the variation of camera poses and positions, the geometric transformation here is not only translation but also rotation and scaling, even including viewpoint distortion such as skew and stretch. Under these circumstances, images become quite different, and correspondences need to be searched in two dimensions; in addition, local texture is deformed, so matching by simply computing window correlation usually fails. Thus, dense matching tends to be a quite challenging task. There has been a large amount of work on wide baseline matching during the past decades. For example, algorithms based on plane sweep 6 first test a family of plane hypotheses and choose the best one for each pixel and then perform dense matching and depth map computation at the same time. A limitation is that cameras are required to be fully calibrated to construct those plane hypotheses. However, the camera poses and scene geometry are unavailable in many applications. Strecha et al. 7 make an evaluation of image-based 3D techniques with calibrated cameras/images.
For uncalibrated images, prevalent approaches are based on local invariant features. 8 SIFT 9 is the most popularly used feature in wide baseline matching. Difference of Gaussian (DoG) key points are first extracted and then SIFT descriptors are generated from local invariant regions centered at these key points. SIFT features are invariant to scaling and rotation and robust against various disturbances such as additional noise, change in illumination, and small affine distortion. Mikolajczyk and Schmid 10 proposed an affine invariant interest point detector. They first use an affine-adapted Harris detector to determine interest point locations and take multi-scale version of this detector for initiation. Then, the scale, location, and the neighborhood of each key point are modified by an iterative algorithm, which finally converges to an affine invariant point. Each key point is associated with an affine invariant support region, represented by a second moment matrix, which allows the generation of affine invariant descriptors for robust matching in wide baseline case. Similar local invariant features such as SURF, 11 ASIFT, 12 GLOH, 13 DAISY, 14 and Scale-Less SIFT 15 were also proposed. They are more or less invariant under different viewing conditions. However, the number of feature points is unpredictable. In low-texture regions, there may be very few features. Consequently, great matching ambiguity exists in these regions. Although sparse matching result is sufficient for object recognition, the number (or density) of reliable correspondences is quite important for applications such as 3D scene reconstruction and motion estimation.
To construct dense correspondences, a region growing framework was first presented by Otto and Chau 16 to process satellite images and was then extended by many researchers.17–21 In this scheme, some distinctive features like corners and salient regions are first extracted and matched as seed points. Then, a correlation-based region growing step propagates them into more ambiguous regions of the images. During propagation, the obtained high-confidence matches are used to guide nearby pixels for further matching. In this matching problem, the scene is usually assumed to be composed of piecewise-smooth, Lambertian reflection and textured surfaces. In the same surface, disparity variations and local pattern deformations are relatively small, so the propagation is effective. A deficiency is that the propagation often stops at object boundaries, and a region may be lost if no reliable seed match is found in this region. So, in order to produce dense matching, the initial matching result is quite important as well as the propagation strategy.
Besides, research on dense matching for image stitching 22 or matching across different scenes is also active in recent years, and much work has been done, such as SIFT flow, 23 deformable spatial pyramid matching, 24 DAISY filter flow, 25 scales propagation prior to matching, 26 and so on. However, it is not the topic of this article.
In this work, we introduce an affine invariant method to perform dense matching between two images of the same scene. This approach has two main steps. The first step extracts and matches a sparse set of affine invariant features: seed points and their affine invariant regions. Then, these initial matches are incorporated as spatial prior to generate more candidate matches. In this way, the number of reliable seeds apparently increases. In the second step, the obtained sparse correspondences are used to initialize a dense matching propagation process. Under the assumption that disparity variations and local pattern deformations change smoothly inside a smooth region, the disparity and affine transformation parameters of obtained reliable matches can be propagated to its neighboring pixels as initial guess and then refined. During iterative region growing, high-confidence matches are used to guide nearby pixels for further matching, thus nearly dense point-to-point matching is produced. Finally, in order to handle the remaining unmatched points, low-rank matrix recovery technique is utilized to complete dense matching.
The rest of this article is organized as follows: section “Sparse matching” introduces the sparse matching technique, in which the local spatial deformation is modeled by an affine transformation matrix associated with each match. Section “Dense matching based on region growing” discusses dense matching technique based on region growing and then a strategy of handling unmatched points is proposed in section “Handling unmatched points.” Finally, experimental results on real images are presented in section “Experimental results and analysis.”
Sparse matching
In this section, we introduce how to produce reliable sparse matches. First, some distinctive feature points are extracted, which should be robust over significant geometric deformations. Second, we explain how to increase the matching number as well as improve the accuracy. Each pair of correspondence is associated with an affine transformation matrix to model its local geometric deformation, which is used to guide further matching in dense matching.
Which feature to extract?
The proposed dense matching approach starts from the detection of sparse key points. Some methods extract edges or corners and then matched with correlation; others extract uniformed regions after segmentation and conduct comparison on shape or mean color. Several drawbacks are needed to be aware of, such as noise, illumination change, repetitive patterns, and geometric deformations. Recently, some local invariant features 8 have been reported to have good performance in sparse wide baseline matching. The most famous feature is SIFT, and others such as SURF, MSER, Harris-Affine, and Hessian-Affine are also widely used. We use Hessian-Affine detector to establish sparse matching, which is invariant to affine transformations. Compared with DoG detector, the response of Hessian is weak near contours and straight edges, where signal change is only in one direction. These points are less stable as their localization is more sensitive to noise or small changes in neighboring texture, so Hessian can avoid reaching maxima in these areas. An advantage over Harris detector is that Hessian detects blob-like features other than Harris corners, so the returned locations are more suitable for scale estimation as the filters for spatial and scale localization are similar. Using the Hessian-based detector, a large number of feature points can be extracted, which lead to a good coverage of the scene.
How to compare two corresponding regions?
Matching is performed by comparing the neighborhood texture of two candidate key points. There are two prevalent ways: one is to sample local image intensities around the key point and matching them using a similarity measure, for example, sum of absolute differences (SAD), sum of squared differences (SSD), and correlation functions. However, the similarity of image patches is sensitive to noise and affine changes or nonrigid deformations. Another is to compute a descriptor for the local image region. The descriptor needs to be highly distinctive and robust to variations under arbitrary viewing conditions. SIFT-based descriptors are reported to have the best performance under a variety of experimental conditions. 13
We adopt both techniques in the proposed approach. SIFT-like descriptor is extracted in the affine invariant region associated with each feature point. This region is determined by the second moment matrix M. Suppose

where
Let
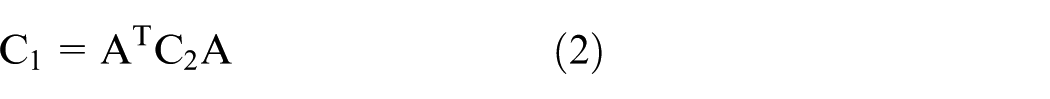
Thus, the local affine transformation can be computed as follows

where
In order to gain invariance over affine distortions, we normalize the image patches before matching and then measure their similarity. Given patch
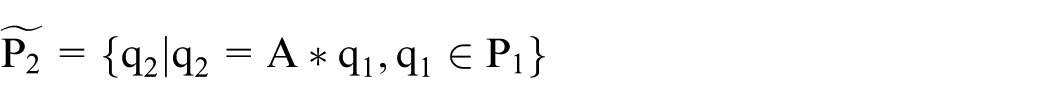
For a correct match,

The SSD can be replaced by SAD or correlation or other similarity functions. This process is illustrated in Figure 1.
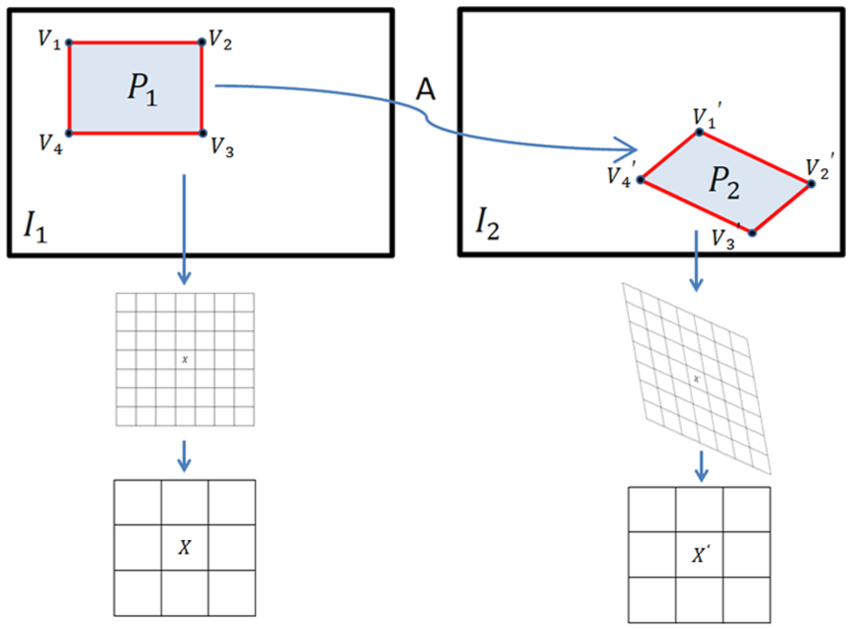
Illustration of affine normalization of local image patches.
Thus, the matching cost for a candidate match at point

Generate more matches
For sparse matching, we expect to obtain as many matches as possible, which need to be accurate and robust against affine deformations. After the Hessian-Affine features being extracted, the 128-dimensional feature vector and another 5 parameters (2 for location of the key point and 3 for the data of symmetric second moment matrix M in equation (1)) are used for sparse matching. Traditional methods compare feature similarities and then use nearest-neighbor strategy to perform matching. First-to-second nearest-distance ratio is often used to reduce false matches. But compared with the feature points that appear in both images, the matching number is relatively low (see Figure 2 first row).

Sparse key points detection and matching result. There are 1997 Hessian-Affine feature points in the left image and 1699 in the right, 299 matches in the top row, and 564 matches in the bottom.
As accurate and sufficient sparse matching result has great impact on the performance of dense matching, we designed an approach to generate more matches. First, initial matches are established through the comparison of feature similarities. The best candidate match for each key point is set to its nearest neighbor, which is defined as the one with minimum Euclidean distance for the 128-dimensional SIFT-like descriptor vector. We do not eliminate false matches with first-to-second distance ratio, as not considering the spatial relationship among key points will lead to the exclusion of many true matches. Instead, the obtained initial matches are ranked according to matching cost, as was described in section “How to compare two corresponding regions?” A threshold is set to select some reliable candidates as good seeds. Then, we incorporate these good seeds as spatial prior to produce more matches. Considering the spatial consistency between key points, those high-confidence matches are used to guide nearby pixels for further matching. At each iteration, the best seed (with lowest matching cost) is taken out from the set “good seeds” to produce more matches. We search for new feature points near the best seed and find its putative correspondences in the other view. If the putative match is reliable, then it is added into the set “good seeds.” New matches are generated iteratively, and the procedure stops when the set “good seeds” becomes empty.
In detail, suppose the coordinates of the best seed match are

But the true match of a key point needs also to be a key point, so here is a spatial error between the predicted position and the candidate matching position

Thus, the matching cost is calculated as follows

Candidates with high confidence (matching cost not beyond threshold

Generating more matches from seed match. The red point is a seed match, and blue points are new matches generated by the seed; the size of ellipses is determined by threshold
For a “best seed,” the search region where new matches are generated is determined by equation (4). On one hand, too small region is useless, as there may be no new key points existing in such area. On the other hand, if the region is too large, the local affine transformation may be inaccurate, as regions far away from the seed may violate the smoothness assumption. So, there should be a compromise in the selection of the region size.
Finally, all new generated matches need to be checked by computing local image correlation by equation (5). Matches with low correlation cannot be added to “good seeds,” as the corresponding local image patches are quite dissimilar. In this way, we obtained reliable and sufficient sparse matching result, and each match is associated with a local affine transformation matrix. The detailed procedure of sparse matching can be found in the supplementary file. It is shown in the second row of Figure 2 that the number of sparse matching has been significantly increased.
Dense matching based on region growing
In the previous section, a sparse matching technique was described. Each match is associated with an affine transformation matrix, which reflects its local structure. This section will focus on the second step: dense matching, the basic idea of which is based on region growing. We incorporate region growing in an affine invariant framework for match propagation. In order to handle the remaining unmatched points, low-rank matrix recovery technique is utilized to complete the dense matching.
Region growing
Region growing is originally an approach for segmentation, in which neighboring pixels with similar properties are merged together. A region growing algorithm usually has three steps: initialization, propagation, and termination. It starts at seed points with some specific attribute and then expands to neighbor regions iteratively. During the expansion, this attribute is spread to neighboring pixels with a growing rule. If the attribute of new pixel is not eligible, this pixel will not be merged into the region. The expansion terminates when all neighbors have been handled. Our goal is to construct dense matching, but many regions are not so distinctive to perform reliable matching, for example, low-texture regions. Based on the assumption that disparity varies slightly on smooth object surfaces, matching can be propagated from high distinctive regions to low distinctive regions. Sparse matching result obtained from feature matching is often used for initialization and then matching is propagated from these reliable seeds to neighboring pixels. At each iteration, the match with highest confidence is used to guide nearby pixels for further matching, and new potential matches are accepted carefully according to a matching cost function. In this way, more and more new correspondences are constructed, and matching result becomes denser and denser. Sometimes only one seed is enough to expand to the whole image. However, region growing will stop when comes across object boundaries or occlusions, or the geometric distortion is very severe. Therefore, sufficient properly located seeds are required to prevent bad propagation.
Affine normalization
In the wide baseline situation, there exists significant geometric distortion which bring about inaccuracy when performing dense matching. In Figure 4, we search for the correspondence of

Example on affine deformation.
We assume that the geometric distortion caused by viewpoint variations changes gradually on a smooth surface, and it can be approximated by local affine model. For a reliable seed match, for example,

Second, the corresponding quadrilateral

Corresponding patches after affine normalization.
Procedure of dense matching
We perform affine invariant dense matching in the way of region growing. The basic idea is to propagate reliable matching from low ambiguous regions to high ambiguous regions. Local affine invariant sparse matching is conducted first to produce seed matches for region growing. As a reliable affine match can give an initial guess of approximate disparity of their neighboring pixels, true match then can be searched from pixels adjacent to this predicted location. Matching is conducted by calculating the matching costs of normalized patches. The one with the lowest cost is selected, and if the cost is below a threshold
When performing region growing, reliable and distinctive pixels should be propagated first, for example, feature points are the most distinctive ones, so they are matched at the beginning. During propagation, we decide the priority of seeds with regard to its distinctiveness and robustness. The distinctiveness

Then, the priority of a seed match

In each loop, the match with highest priority is chosen for propagation. This suppresses propagation from unreliable matches or too uniform regions.
Region growing is based on the assumption that disparities and affine transformation change gradually on smooth surfaces. However, when matching propagates through a long distance, errors will accumulate and the affine transformation inherited from the initial seeds become more and more inaccurate. So, during propagation, this matrix should be updated once a new match is accepted. Suppose the affine matrix obtained from the last iteration is 2 × 2 matrix


Examples of region growing procedure for match propagation. Black areas are unmatched regions.
The procedure of match propagation terminates when there is no neighboring pixel to process. The dense matching procedure is presented in Algorithm 1. The input is a set of sparse matching correspondences, and the output is a quasi-dense matching

Handling unmatched points
Many applications (e.g. 3D reconstruction) require dense matching result, but there remain many unmatched points in the previous quasi-dense matching
Compressive sensing is a research hotpot in image processing and data analysis. According to the compressive sensing theory, 27 if the original data are low rank, and the error is sparse, then the corrupted data can be automatically correctly recovered. Low-rank matrix reconstruction28,29 is a typical application of this theory.
Suppose the original data are

where

where
In image processing, corrupted image (
Suppose


In this way, unmatched points are handled and “black holes” are repaired. Thus, the dense matching procedure is completed.
Experimental results and analysis
In this section, we test the proposed approach on real images. In section “Sparse matching step,” we show effectiveness of our sparse matching algorithm. In the second experiment (section “Dense matching step”), dense matching results of wide baseline images are demonstrated.
We implemented the proposed method in MATLAB and tested it on a laptop running Windows 7 with Intel Core i5 central processing unit (CPU) and 6-GB RAM. The images are collected from public dataset (e.g. INRIA on the web) and from our laboratory dataset. The latter are obtained by handheld cameras without calibration. Geometric distortion is significant in the test images, including large displacement, rotation, scaling, and some viewpoint changes. For evaluation, we designed some controlled experiments and calibrated the cameras used indoor; therefore, we can compute the depth map of the indoor scenes. Figure 7 lists some image pairs taken by a calibrated binocular vision system.

Sample images taken by a calibrated binocular vision system. Top row: images taken by the left camera. Bottom: images taken by the right camera. Each column corresponds to an image pair.
Sparse matching step
The first step of our method is to extract and match distinctive feature points. We extract the Hessian-Affine feature for sparse matching. SIFT-like feature vectors are computed in the affine invariant regions of each key point. Initial matching is conducted by matching these features with the nearest-neighbor strategy. However, compared with the number of feature points (e.g. in Figure 2, 1997 feature points in the left image and 1699 in the right), the number of matching points is relatively small (299 matches). So, we need to generate more seed matches for dense matching. We perform an experiment to show parameter influence in sparse matching. It reflects the effects of threshold
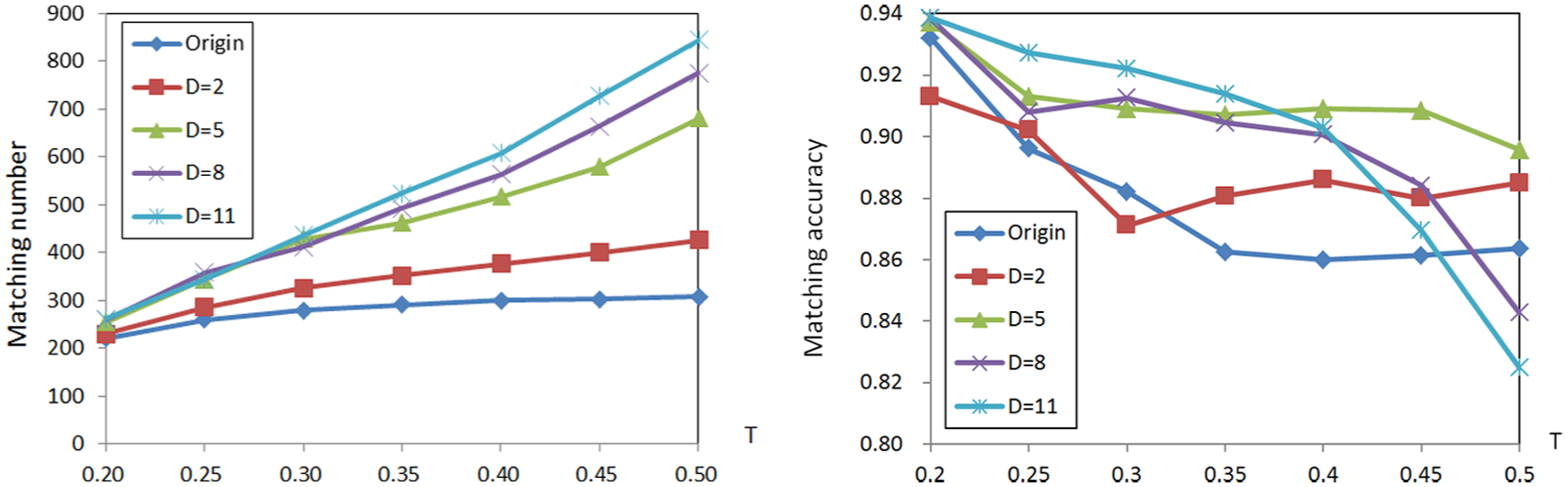
Matching number and accuracy with different parameters.
For comparison, the original sparse matching result is also presented. Figure 8 shows that when
Dense matching step
In this subsection, we illustrate the proposed dense matching algorithm with the example of an indoor scene. For this purpose, we work with the uncalibrated images shown in Figure 2. First, 564 seed matches are obtained in the sparse matching step. Each pair of match is associated with an affine transformation matrix to describe the local structure.
During dense matching, the threshold for accepting a new match is set to
Finally, we utilize the low-rank matrix recovery technique to handle unmatched points. The quasi-dense matching result (Figure 9(a)) obtained from region growing is regarded as corrupted data. We take the disparity map in X and Y dimension as input, respectively, and then conduct low-rank and sparse decomposition. The rank of the recovered disparity matrix is 406, which is much lower than the original rank of 570. In the end, the dense matching result (Figure 9(b)) is obtained, where most unmatched points are eliminated. This result is much better than Figure 9(a).

Comparison results (a) before and (b) after low-rank matrix recovery.
We compared our method (denoted AF) with a recent approach, 32 which is a rotation and scale invariant dense matching algorithm (denoted RS). For an image pair, we choose the right one as reference image and the left one as target image and then put the corresponding pixel in the reference image on the target image, as illustrated in Figure 10. Compared with the RS approach, the proportion of good matches is higher in AF case. Images with known homography are used for evaluation. To examine the matching result, we compute the Sampson distance with ground truth obtained from known homography. 31 In Figure 10, the matched pixels are colored according to their Sampson distance. Those inaccurate matches (with Sampson distance above 5) are in red color and the occlusions are in black (see Figure 10(a) and (b)). The number of good matches (Sampson distance below 5) is 235,347 for RS method and 251,506 for AF. In Figure 10(c) and (d), the pixel intensities represent the Sampson error; black area means low error and white area means high error. The values of Sampson distance over 5 are suppressed to 5, with intensity value equal to 1.0. Figure 11 demonstrates that the matching result of AF is denser and more accurate than RS method. The reason is that we use Hessian-Affine features to perform sparse matching and conduct dense matching in an affine invariant way, while RS method has only rotation and scale invariance. To gain invariance in wide baseline matching, local image patches are required to be normalized to eliminate the inaccuracy introduced by geometric deformation. The affine transformation matrix in this article has four parameters, versus two parameters in RS, so our approach can describe the local geometric deformation more accurately. Thus, the dense matching result is more reliable.

Matching result from the “graff” image pair: (a and c) obtained with RS method and (b and d) obtained with our method. (a) and (b) are dense matching result, and red pixels represent inaccurate matches. (c) and (d) are Sampson distance, in which bright pixels represent positions with high Sampson error and dark means low error.

Matching number under several Sampson values.
We also compare our method with Kannala and Brandt’s 18 quasi-dense matching algorithm, which is denoted as KB. It is shown in Figure 12 that our dense matching result is much denser. One reason is that in KB approach, propagation often stops at object boundaries during region growing, and the absence of reliable seed points leads to unmatched regions. If no match or only poor sparse matches are found in a region, this region may be lost in dense matching, because no new reliable correspondences could be established due to the poor initial seeds. To solve this problem, we present a method to generate sufficient seed matches based on the original sparse matching result. Thus, the seeds can cover more regions and the matching result is denser. In addition, matching in KB is not conducted in low distinctive regions, for example, the black area between two buckets (see Figure 12(b)). In our approach, when performing region growing, a propagating order is set according to the distinctiveness of seed matches; we first match high distinctive regions and then match low distinctive regions, using the matched points to reduce matching ambiguity. Finally, as an application, we calibrated the cameras and computed a depth map of the scene, which is shown in Figure 12(d). Moreover, Table 1 gives the comparison in matching speed with other methods. From Table 1, we can see that the running time of the proposed method is acceptable. More results can be found in the supplementary file.

Comparing the matching speed of our approach with other methods.

Conclusion
In this article, we proposed an affine invariant approach for dense wide baseline matching. The significant geometric deformation in images introduces difficulty in dense matching. We designed a sparse-to-dense framework to handle this problem. In the stage of sparse matching, in order to get sufficient seed matches, we incorporate initial matching points as spatial prior to produce more correspondences. Dense matching is conducted by region growing, wherein matching extends from high distinctive regions to low distinctive regions, and finally completed by low-rank matrix recovery technique. The proposed approach has affine invariance and can deal with images obtained from handheld cameras without calibration. Experimental results demonstrate that the proposed approach is effective to obtain dense and reliable correspondences.
Footnotes
Academic Editor: Ting Zhu
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by National Natural Science Foundation of China under grant no. 61175014 and no. 51209134.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.