
Abstract
In this article, we propose the dynamic resources management model in a cloud computing environment. For monitoring the certain resource, we should utilize not only a cloud management module but also a network management module. However, it is difficult to check the duration time and to observe the digested information about the resources. To investigate these problems in a cloud computing environment, we designed and deployed the cloud service infrastructure based on open-source software, namely, CloudStack. The proposed model regularly stores the usage data for computing resources based on Hadoop and HBase. In addition, our model analyzes the raw data for virtual machines and makes an effective recommendation regarding the consumption of computing resources.
Introduction
The concept of a cloud computing is one of the emerging issues in the information technology (IT) industry.1,2 It enables users to migrate their data and computation to a remote location with minimal impact on system performance. 3 Typically, this provides a number of benefits which could not be realized. Whether using a specific application, a set of tools, or Web services, Clouds provide access to a potentially vast amount of computing resources in an easy and user-centric way. 4 We have investigated such an interface within grid systems through the use of the Cyberaide project. 5 There are a number of underlying technologies, services, and infrastructure-level configurations that make cloud computing possible. One of the most important technologies is the use of virtualization. 6 Then, Gulati et al. 7 discuss resource management challenges and techniques with the perspective of VMWare’s offerings. Some researchers also focused on the data center networking for seamless data transfer.8,9
Accordingly, major companies such as Amazon 10 and Google 11 have announced private or public cloud computing environments for fault tolerant and effective business environments. 12 Additionally, other companies such as HP, 13 IBM, 14 and Dell 15 are supporting hardware products and services related to cloud computing environment. 16
In spite of the appearance of such commercial software and hardware based on cloud computing environment, some users have continuously requested the development based on open-source software. First, CloudStack 17 from Citrix 18 is a well-known product based on open-source software and is distributed by Apache License. CloudStack already has several reference sites and includes such strengthens as extensibility and centralized management for resources in a cloud computing environment. Citrix has decided on license policies for CloudStack from the General Public License (GPL) to an Apache License. It provides more opportunities for open-source developers to join this project. Alternatively, many major projects are based on the OpenStack project. 19 In addition, many open-source developers have been attending to these projects to develop the newest technologies related to each topic. We choose CloudStack for constructing resource management model which is a stable and fast platform. OpenStack has a number of sub-projects, so it needs several debugging when installing the system. CloudStack can offer stable and fast development environment for complex and large project services based on Citrix’s practical skill.
In section “Cloud service infrastructure,” we describe a cloud service infrastructure which should be providing small- to mid-sized companies with detailed information on a cloud computing environment. Section “Resource management model” introduces some problems that may be found while a cloud service infrastructure is serviced, and the proposed approach is described in section “Experiments.” Finally, in section “Conclusion,” the contents of this article are summarized and future work is discussed.
Cloud service infrastructure
The proposed mobile log management model which is based on cloud infrastructure should be aggregating the sensed data from typical mobile devices. The collected data should be transported to cloud frameworks, and it is analyzed with Hadoop-based big data system. It could provide convenience to network availability of mobile devices. Moreover, we can obtain a sensed data from user activities easily. Because of these benefits, it can be utilized in mobile application development and marketing initiatives.
The proposed cloud infrastructure consists of about 60 server nodes based on the CloudStack project, which is open-source software with an Apache License, with additional storage servers, firewalls, and monitoring servers. Storage servers generally have a parallel architecture for supporting the integration when abnormal accidents are occurred. Firewalls support secure operation among virtual machines (VMs) and have additional operations such as port forwarding and network address translation (NAT) to protect a private network from attacks. Monitoring servers allow a system manager to completely observe the status of the VMs and network resources in the cloud service infrastructure (Figure 1).

Cloud service infrastructure.
A cloud service infrastructure has a Gigabit network capacity by default to communicate with server nodes including the cloud manager. Nevertheless, for the speed of a Gigabit network, it supports a 10-Gb network for communicating between server nodes and the storage servers, particularly to prevent a bottleneck problem from network congestion in advance.
Server node
The proposed approach has a cloud manager and 60 server nodes according to the guidelines of the CloudStack project. A set of server nodes in the cloud service infrastructure supports VMs created by the user, allowing available computing resources to be allocated within the required time. CloudStack supports various types of VMs, such as ESX, XenServer, KVM, BareMetal, and OVM, by default. However, XenServer is recommended as a type of VM in a cloud service infrastructure since we have to consider the stability of the system itself. Table 1 shows the hardware specifications of a server node.
Hardware specifications of server node.

HDD: hard disk drive; NIC: network interface card.
Storage server
The proposed approach has two storage servers for physically storing VMs created by users. First, the master storage server stores VMs and deals with the request for VMs from users in real time. Therefore, the master server has a network capacity of 10 Gb and multipath input/output (MPIO) capability to roll back the problems from the system or network as soon as possible (Table 2). Alternatively, a secondary storage server stores ISO files, templates, and VM snapshots to manipulate VMs easily using a network file system (NFS) technology.
Hardware specifications of storage server.

HDD: hard disk drive; iSCSI: Internet Small Computer System Interface.
Monitoring system
Users are generally able to activate and deactivate VMs using a cloud management console. As an aside, it does not have a monitoring capability and cannot control VMs operated by the user. Thus, the system manager has to rely on an additional monitoring tool such as a Multi Router Traffic Grapher (MRTG) 20 with a simple network management protocol (SNMP) to look into the status of VMs. The proposed monitoring tool is for observing the traffic load on network links.
Resource management model
Basically, the proposed management console, which is supported by CloudStack, is able to create, delete, copy, and paste VMs in a cloud computing environment. However, the system manager cannot monitor computing resources which are used by VMs, but does check the status of VMs such as the on/off status at the cloud management console. A network management tool based on SNMP is able to report the total status of the systems to the system manager, as well as detailed information on the current status of the VM selected by the system manager, such as the usage rate of the CPU, disk, and network. While a cloud service infrastructure has been serviced, we have found the possibility that the information generated by the network management tool can leverage the cloud management console and control the VMs and the other resources dynamically for autonomic process, which it has previously done statically. The proposed model is able to show detailed information on the VMs, such as MRTG. Additionally, the cloud management console is able to make a decision on the limitation of resources that VMs can use within the availability of the computing resources. If the current usage rate for a certain VM is very close to the limitation set by the system manager, it could generate a policy for the autonomous process using a snapshot image. It is stored in the secondary storage server without a system manager interrupt to allow stable service for a VM.
The purpose of the resource management model is to analyze raw data and report the statistical information regarding the VM usage amount for the computing resources within the limitation of the resources.
For an analysis of the current status, the raw data for a certain VM must be gradually and completely collected and stored in a kind of database. As an aside, MRTG does not save the raw data collected using SNMP, and thus, we have no choice but to design a log analysis framework separately. A resource management model makes use of a log analysis framework to collect and save the raw data from communication among VMs.
Log analysis framework architecture
For a log analysis framework, we decided to use a distributed file system based on the Hadoop distributed file system (HDFS) 21 and a database based on HBase 22 since HDFS guarantees extensibility based on Google file system (GFS) and HBase is a database on top of HDFS for NoSQL application.23,24 HDFS is the primary storage system used by Hadoop applications. 25
HDFS is suited for the storage of large files, and HBase provides fast record lookups (and updates) for large tables. Finally, a log analysis framework (in Figure 2) prepares the MapReduce programming model 26 to support various types of statistical analyses for the usage amount of computing resources.27,28

Log analysis framework architecture.
For a resource management model, HDFS based on Hadoop, makes use of 80 one-unit servers with CentOS 5.5 to create a distributed file system. Table 3 shows the hardware specifications of a one-unit server.
Hardware specifications of one-unit server.

HDD: hard disk drive; NIC: network interface card.
For a statistical analysis, a resource management model creates two tables for storing a set of user uniform resource identifier (URI) data per VM URI and a set of collected raw data for each VM server such as CPU, disk, and network usage data; they are described in Tables 4 and 5.
Set of user URI data per VM URI.

VM: virtual machine; URI: uniform resource identifier.
Set of raw data of VM server.

VM: virtual machine; URI: uniform resource identifier.
User scenario
The proposed approach suggests a process for resource management for maintaining stability of the mobile cloud services. Specific descriptions are separated into four steps, which are shown in Table 6.
Process of the resource management.

MRTG: Multi Router Traffic Grapher; VM: virtual machine.
First, a resource management model allows a system manager to check the current status with statistical analysis from the log analysis framework. In this case, the system manager no longer has to look into the graph from the network management system, as in MRTG, if they want to see the CPU status of a certain VM.
Second, a resource management model helps a system manager to generate a rule for the current limitation of available computing resources from the log analysis framework. For example, if the user requests and creates VMs using a quad core CPU initially, the system manager can decide to scale down from a quad core to a dual core for the number of CPUs based on the statistical report from the log analysis framework. Additionally, the resource management model provides an opportunity for the system manager to use a script allowing the cloud management console to scale the VMs up or down automatically based on a firewall policy.
Finally, the resource management model allows the system manager to generate a policy for emergencies in terms of the service stability of the VMs. For example, the system manager can guess how much computing resources a certain VM consumes at peak and idle times based on statistical information from a log analysis framework. Normally, this VM operates quite well; however, the usage rate of this VM may increase rapidly owing to some company events. In such a case, the system manager may be unable to anticipate this occurrence, and therefore the service from this VM may cease owing to network congestion, such as from a denial-of-service (DDoS) attack. The resource management model allows the system manager to avoid this situation by automatically scaling out the VM having a problem without the system manager’s order. Of course, the system manager has to take a snapshot of VMs that have a possibility of generating an accident in advance.
Experiments
The performance of resource management algorithm is done at the CloudStack made by the Citrix and makes deal with the basic disk input/output (I/O) performance of the VM which is created based on the guidance as shown in Table 7. This performance defines the block size of the data from 32 KB to 2 MB because the user data collected out of the mobile devices are relatively small generally.
Specifications of CloudStack.

H/W: hardware; VM: virtual machine; HDD: hard disk drive; OS: operating system.
This test is focusing on the benchmark the disk I/O such as sequential read, random read, sequential write, and random write because the frequency of the access of the disk is very high considering the number of the mobile devices. The other performance is for testing the basic performance of the Hadoop infrastructure. Hadoop is made and maintained by the Apache project. This evaluation makes use of the performance evaluation tool supported by Hadoop project and embedded in the source. We define the data scalability from 1 MB to 1 TB.
The overall performance of the CloudStack is very low because of the hardware specifications of the storage server as shown in Figure 3. The scalability of the hardware specifications is independent with the disk I/O performance if the CloudStack made by the Citrix with the poor storage server. The reason is that the CloudStack makes use of the additional storage server and the network switch to store the VM and move the necessary data immediately. We conclude that the Hadoop system based on the cloud environment needs not only the good performance of the cloud system itself but also the additional good storage server and network infrastructure.
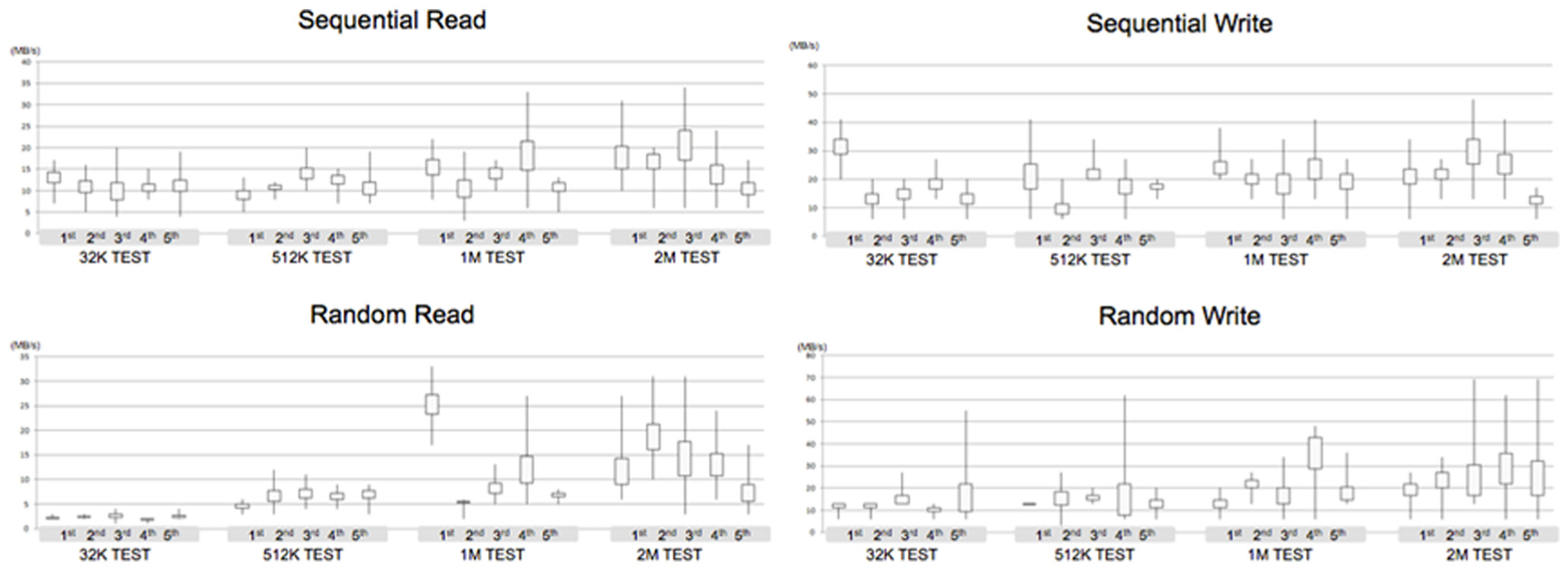
Performance of CloudStack.
Figure 4 describes the performance evaluations such as throughput, average I/O rate, and I/O rate standard deviation of the Hadoop infrastructure. The performance graph shows that there is no time increasing according with the data size. We conclude that Hadoop system is sufficient to deal with the big data.

Performance evaluations of Hadoop infrastructure.
Conclusion
In this article, a cloud service infrastructure deployed by Electronics and Telecommunications Research Institute (ETRI) is introduced and a resource management model with a log analysis framework is described. The cloud service infrastructure based on the CloudStack project is supporting the cloud services to small- to mid-sized companies in a practical manner and to investigate the possibility of cooperation between a cloud service infrastructure and network management system.
The proposed approaches are mobile log aggregation and analysis framework which are based on cloud environments. It provides high availability with duplicated log aggregations.
By the way, relational database (RDB)-based log analysis system is not proper to real-time processes. So, we designed the analysis architecture with NoSQL-based MongoDB for sensed data management. Due to the replica sets of MongoDB, we could improve the availability with fail-over policy. So, the proposed approach provides scale-out free for extending the mobile log management frameworks.
In order to performance evaluation, we applied the proposed resource management model to the mobile log collection system. Because we need to aggregate the various raw data in the mobile cloud environments. The next phase of this research is to finalize the development of this model to operate VMs at the cloud management console without the system manager’s interrupt. Additionally, we are going to survey a use case for cloud management and generate an experiment for the cloud service infrastructure.
Footnotes
Academic Editor: Antonino Staiano
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the Ministry of Science, ICT and Future Planning (MSIP, Korea).