
Abstract
In the field of wireless sensor networks, the secure range query technique is a challenging issue. In two-tiered wireless sensor networks, a verifiable privacy-preserving range query processing method is proposed that is based on bucket partition, information identity authentication, and check-code fusion. During the data collection process, each sensor node puts its collected data into buckets according to the bucket partition strategy, encrypts the non-empty buckets, generates the check-codes for the empty buckets, and fuses them. Then, the check-codes and the encrypted buckets are submitted to the parent node until they reach the storage node. During query processing, the base station converts the queried range into the interested bucket tag set and sends it to the storage node. The storage node determines the candidate-encrypted buckets, generates the check-code through code fusion, and sends them to the base station. The base station obtains query results and verifies the completeness of the result with the check-code. Both the theoretical analysis and experimental results show that verifiable privacy-preserving range query is capable of protecting the privacy sensor data, query result, and query range, which also supports the completeness verification of the query result. Compared to existing methods, verifiable privacy-preserving range query performs better on communication cost.
Keywords
Introduction
In recent years, the emerging technologies such as Internet of things (IoT) technology, cloud computing,1–4 image recognition,5,6 and video processing7,8 have developed rapidly. The wireless sensor networks (WSNs), as one of key technology in IoT technology, have been widely applied in various fields, such as battlefield surveillance, environment monitoring, and health monitoring. Based on the traditional multi-hop sensor network, the two-tiered WSN 9 introduced the storage node (SM) as the intermediate; the architecture of its model is shown in Figure 1, in which the calculation, storage, and energy resources of the SM are sufficient, and it is responsible for collecting and storing the data from the adjacent sensor nodes and executing the query request from the base station (BS). Due to limited resources, the sensor node is only in charge of collecting data and sending it to the adjacent SM. The advantages of two-tiered WSNs mainly include the following: the sensor node only needs to submit the data to the adjacent SM, which can reduce the transmission energy consumption and extend the lifetime; the data are stored in the SM, and the sensor node does not need to store the data, which can reduce the manufacturing cost of the node; when the query command is executed at the BS, it only needs to communicate with the SM, which can improve the execution efficiency of query processing (QP).9,10

Model of two-tiered wireless sensor network.
The development and application of WSNs face various security threats, including disclosure of privacy and compromised data. Security problems are particularly more prominent in two-tiered WSNs because the SM not only stores a large amount of sensor data but also executes the query request from the BS, and due to the importance of its location, it is a primary target. Once the SM is compromised, the attacker can use the SM to spy on the data privacy in the network, for example, illegally obtain sensor data, QP results, and the query intentions of upper-layer user or application. In addition, the attacker can also use the SM to tamper with or falsify query results and data to mislead or disturb the upper-layer application or decision. Therefore, studying secure data QP technology with privacy protection and query result completeness verification has important realistic significance for two-tiered wireless networks.
Due to the universal application of range queries among current studies of QP technology for two-tiered WSNs, range QP technology with privacy-preserving and query result completeness verification has attracted a great deal of attention.11–22 However, current studies show deficiencies in terms of network communication cost, although the communication cost directly impacts the lifetime and application costs of the entire network. The objective of this article is to protect the privacy of sensor data, query results, and the query range and to verify the completeness of query results in two-tiered WSNs; thus, a verifiable privacy-preserving range query (VP2RQ) method based on bucket partition is proposed in this article.
The main contributions of this article include the following: (1) by introducing bucket partitioning and symmetric encryption technology, plaintext data can be hidden in encrypted buckets, and the Hash-based message authentication coding (HMAC) method can be used to build the check-code information that supports the completeness verification of the query result; (2) during the process in which the sensor node uploads data to the SM, fusion processing of the check-code is conducted in accordance with the bucket tag to reduce the communication cost of data. Thus, data collection (DC) protocol and QP-protocol are proposed to realize the VP2RQ; (3) under this protocol framework, efforts are made to analyze the privacy security, query result verifiability, and network communication cost of the VP2RQ method; and (4) experimental comparison and analysis are also conducted by comparing this method with the existing technology and methods from the perspective of the communication cost of the sensor node within the cell and the communication cost between the SM and BS. The theoretical analysis and experiment results show that compared with existing methods, VP2RQ has better performance in terms of communication cost efficiency.
In section “Related works” of this article, related studies are introduced. Related models and problem description are provided in section “Models and problem statement,” and the bucket partition method is introduced in section “Bucket partition mechanism.” In section “VP2RQ protocols,” the specific protocol content of VP2RQ is provided, and analysis of the security and communication cost is conducted. The experimental results and analyses are presented in section “Performance evaluation,” and the article is summarized in section “Conclusion.”
Related works
Researches on the secure range query technologies for two-tiered WSNs mainly include the following two types:
Secure range queries11–13 based on the bucket partition.23,24 These methods rely on same assumption: sensor nodes and the BS share the bucket partition strategy; that is, the mapping relation between the partitioned bucket intervals and the random tags is shared by the sensor nodes and BS and is unknown to the SM. The randomness of tags ensures the security of the bucket partition strategy. In Sheng and Li, 11 the bucket partition is first introduced in the VP2RQ method, denoted as S&L. In S&L, sensor nodes put their collected data into buckets according to the bucket partition strategy. For any bucket, if it is empty, a code is generated; otherwise, the bucket is encrypted. Then, the encrypted buckets and codes are submitted to the SM. When the BS applies a range query, it determines the smallest bucket set covered by the queried range and then sends the corresponding bucket tags as the query command to the SM. And, the SM returns the corresponding encrypted data and codes to the BS in accordance with the bucket tags in the query command. Finally, the BS obtains the query result by decrypting the encrypted data and verifies the completeness of the query result using the received codes. Because S&L requires generating one code for each empty bucket and transferring it to the SM, with the increase in the number of empty buckets, the communication cost of the sensor nodes rapidly grows in large-scale sensor networks. To reduce the communication cost of sensor nodes, an optimized method (denoted as NSC) based on a spatial–temporal crosscheck is proposed in Shi et al.12,13 This method uses the bitmap index to replace the codes in S&L, so that the communication cost of the sensor node is saved; however, the communication cost between the SM and BS is higher than that in S&L.
Secure range queries based on secure comparison.14–22 The basic idea of these methods is that the sensor nodes encrypt their collected data and generate the corresponding secure-comparing-codes, which can be used to compare the encrypted data. The encrypted data and the corresponding secure-comparing-codes are uploaded to the SM. When the BS processes a range query, it first transforms the queried range into the secure-comparing-codes and then sends them to the SM as a query command. Then, the SM can determine the qualified encrypted data that satisfy the query range by performing the secure comparison scheme between the corresponding secure-comparing-codes, and the SM returns the qualified encrypted data to the BS. After decryption, the BS can obtain the query result. In Chen and Liu,14,15 a secure range query method named SafeQ is proposed based on the prefix membership verification (PMV)25,26 mechanism. SafeQ utilizes the PMV coding technique, which can realize the secrete comparison between the collected data and queried range without their plaintext; in this way, SafeQ can determine whether the corresponding encrypted data satisfy the query range. To achieve the query result completeness verification, SafeQ introduces the neighborhood chain mechanism during data encryption and adopts the Bloom-Filter 27 to reduce the cost of the secure-comparing-codes. In Bu et al., 16 an efficient range query method named SEF is proposed. Order-preserving symmetric encryption is employed in SEF to preserve privacy. In addition, a novel data structure called the Authenticity & Integrity tree is proposed to preserve integrity, and the NAND flash is used for the first time to achieve high storage utilization and QP efficiency in this article. In Tsou et al., 17 a range query method named EQ is proposed for protecting data privacy and completeness. The EQ method presents an order encryption mechanism by adopting stream cipher to protect the privacy of data and uses a data structure of the XOR-linked list to verify the completeness of the query result. In Nguyen et al., 18 a novel model based on a d-disjunct matrix, an order function, and a permutation function is proposed to preserve the privacy of sensitive data and the completeness of result. In Yi et al., 19 a secure range query protocol named QuerySec is proposed, which uses the order-preserving function to realize the secret comparison between the collected data and the query range. By embedding the link watermarking information into the encrypted data block, QuerySec can realize the completeness verification of the query result. The performance evaluations of the QuerySec show that it is more efficient in terms of communication cost than SafeQ. ESRQ, which was proposed in Zhang et al., 20 also realizes an efficient range query by adopting Bloom-Filter to generate the encoding code for privacy-preserving and completeness verification. An extended version of ESRQ is provided in Zhang et al. 21 that expands the focus on collusion attacks on range queries in two-tiered WSNs. To reduce the communication cost during the query, secRQ is proposed in Dong et al., 22 as it has a very low false positive rate. secRQ adopts generalized inverse matrices and the distance-based range query mechanism to protect the security of data and proposes a mutual verification scheme to verify the completeness of the query result.
Comparing secure range query methods (1) and (2), we can observe the following: (1) in terms of security, the former mainly depends on the bucket partition strategy, while the latter depends on the complexity of the secure comparison functions; (2) if the same encryption is adopted, the encrypted data produced by the former are smaller than the latter; (3) in terms of the communication cost of sensor nodes, which affects the network lifetime, the former depends on the granularity of bucket partition and the distribution of collected data in buckets, while the latter relies on the quantity of the collected data items and the corresponding secure-comparing-codes.
Models and problem statement
Network model
We use a similar network model used in previous works,11–22 as shown in Figure 1. The network consists of multiple cells, while each cell consists of one storage node SM and n sensor nodes Γ = {s1, s2, …, sn}. The SM is a type of power node with sufficient computation, storage, and energy and is responsible for storing the data collected by all sensor nodes within its cell, and it is also responsible for executing the query requests from the BS and returning the query result. On the other hand, due to limited resources, the sensor node is only responsible for collecting data and sending it to the SM within its cell. The SM has the location information for all sensor nodes within its cell, while the sensor nodes have the location information of the SM and the neighbor sensor nodes within the scope of one hop, and the BS has the topological information for the entire network.
In a cell, with the SM as the storage node, the tree routing topology 28 between the sensor node and the SM is built in accordance with the TAG protocol. 29 When a sensor node uploads its collected data to the SM, it transmits hop by hop in accordance with the routing tree, which is finally gathered to SM. As shown in Figure 2, it is a routing tree with the SM as the storage node, and the data collected by sensor nodes s1, s2, and s3 within the epoch t are D1, D2, and D3, respectively; during the data uploading process, s2 and s3 would transmit D2 and D3 to the parent node s1; then, s1 combines the received D2, D3, and its own D1 and transmits it to the SM.

Tree routing based on TAG.
Range query model
A range query Q can be described by the following triple

where t, c, and [low, high] are the epoch number, network cell, and range, respectively. The query result of Q refers to all data in the range [low, high] collected by the sensor node within epoch t in cell c. Obviously, the above query only involves one epoch and one cell, and we name it atomic range query. A complicated range query involving multiple epochs and/or multiple cells can be divided into multiple atomic queries, and its query result is the union of the query results of those atomic queries. As a result, this article focuses on the atomic range query.
Problem statement
In two-tiered sensor network, the SM stores the data collected by all sensor nodes within its cell, and it is in charge of responding to the query requests from the BS, computing and returning the query result. If no protection is conducted, once the SM is compromised by malicious attackers, the collected data, the query results, and the query interests are threatened. Specifically, the attacker could manipulate the compromised SM for the following reasons:
To obtain the data collected by any sensor node at any moment within the cell and determine the query result in accordance with [low, high] to spy on the privacy of the collected data and the query result.
To obtain the query range [low, high] in the query command to spy on the privacy of upper-layer user’s query intentions.
To tamper or falsify the query result during QP and disturb the completeness of the query result to disturb and mislead the upper-layer application or decision.
Although the sensor node could also be captured, because the amount of data generated by a single sensor node is small compared to the entire network and although a few sensor nodes are captured, it will not have significant impact on the entire network. 7 Therefore, this article focuses on the protections measured for the situation where the SM is compromised. Similar to the existing works, 11 we also assume that the BS and sensor node can be trusted and that the SM cannot be trusted and it has the intention of spying on, destroying, or falsifying data.
To achieve a VP2RQ in two-tiered WSNs, efforts must be made to ensure that QP satisfies the following:
For data collected by any sensor node in the network and the query results, only the BS can obtain its value in plaintext, while the SM cannot.
For the query range [low, high] in the query command, because it reflects the query objective and intention of the upper-layer user, it is also the privacy information that requires protection. Therefore, it is necessary to ensure that the SM cannot obtain the real values of low and high.
The BS can verify the query result returned by the SM, which means any falsified or incomplete result caused by any malicious tampering or falsification will be detected.
In addition, this article adopts two metrics of communication cost to conduct a performance evaluation and analysis of the QP method:
Sensor node communication cost (CI). The communication cost generated by all sensor nodes to submit their collected data to the SM in the cell within an epoch.
QP communication cost (CQ). The communication cost generated between the BS and the SM to process one query, which includes the two parts of the BS sending the query command and the SM feeding back the query result.
Bucket partition mechanism
To realize the VP2RQ, this article introduces the bucket partition method, 23 which is used in QP for encrypted database.
Definition 1
Bucket partition. For a given domain
where [σi, σi+1) is a bucket, while α and β are the lower and upper bound of D, respectively.
Definition 2
Tag. For any bucket
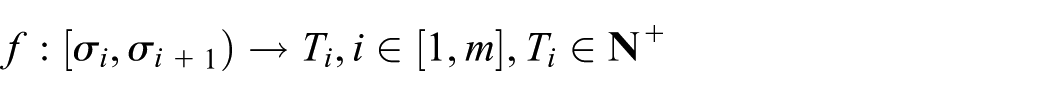
which satisfies the following

Ti is the corresponding tag of bucket [σi, σi+1), which could be a pseudo-random number in practice. For convenience of description, we use
For example, the domain [0, 30] shown in Figure 3 is divided into three buckets of [0, 10], [10, 20], and [20, 30], and the corresponding tags are T1, T2, and T3, respectively.

Example of bucket partition.
There are many schemes to realize a bucket partition, such as equi-width, equi-depth, and max-diff partitions. 23 And, Figure 3 shows an example of an equi-width partition. Bucket partition methods differ in terms of complexity, security, and space-time performance. Because the bucket partition strategy is not a focus of this article, we will not elaborate on it and refer to Hore et al. 24 for a related analysis and algorithm. To make our article easier to follow, we summarize the primary notations used in this article as shown in Table 1.
Primary notations.
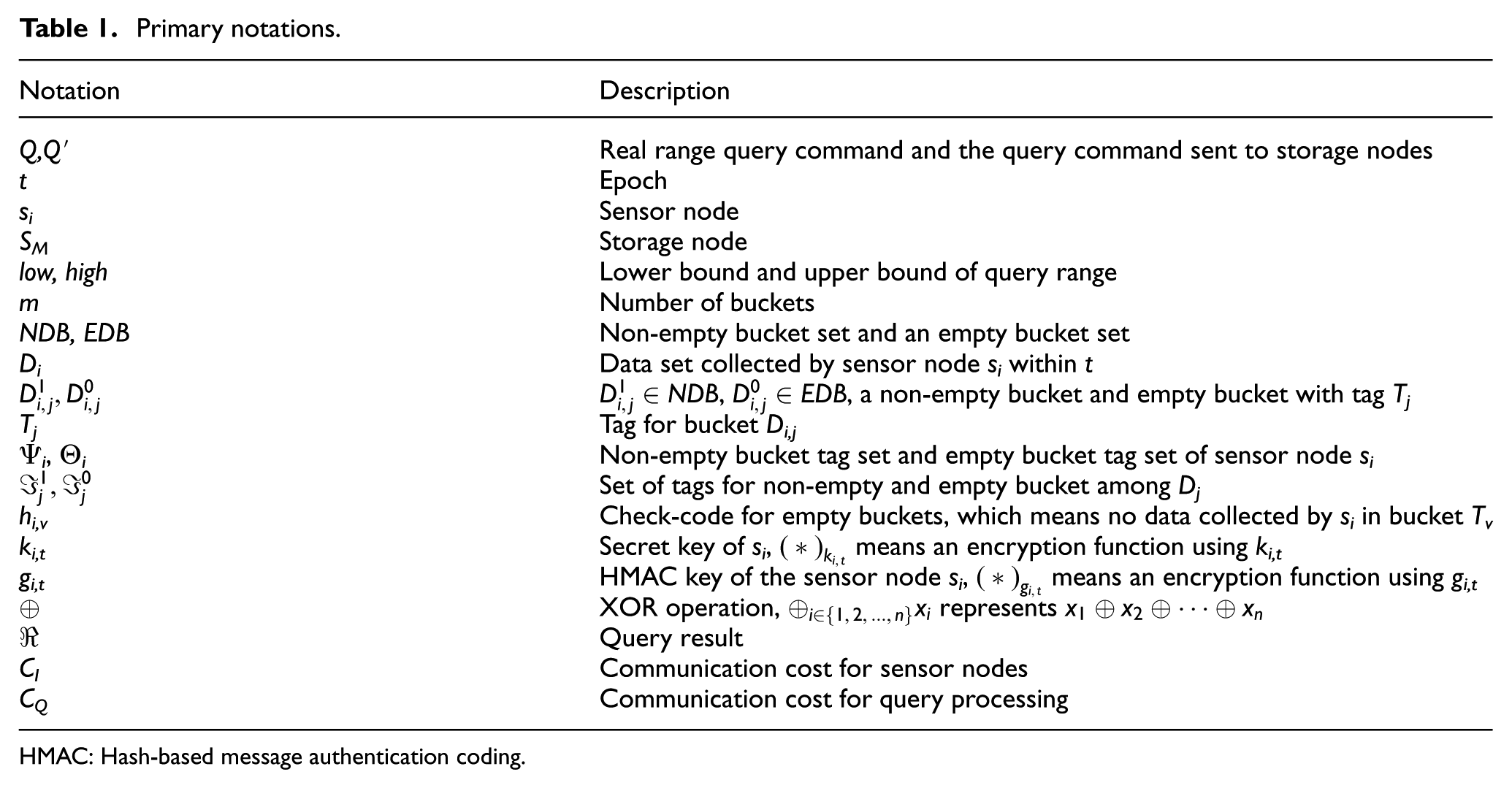
HMAC: Hash-based message authentication coding.
VP2RQ protocols
Definitions and assumptions
Assume that the domain of sensor data in the network is D, divide it into m buckets, and the corresponding tag set of various buckets is Ω = {T1, T2, …, Tm}.
Definition 3
For any range


For example, in the bucket partition example shown in Figure 3, the corresponding minimum coverage bucket set of [15, 25] is {[10, 20], [20, 30]], and the minimum coverage tag set is tag ([15, 25]) = {T2, T3}.
Assume that the data set collected by sensor node si within t is Di, and after the bucket partition, the data set in bucket Tj is denoted as Di,j. If Di,j ≠ ∅, it is called the non-empty bucket, which is denoted as
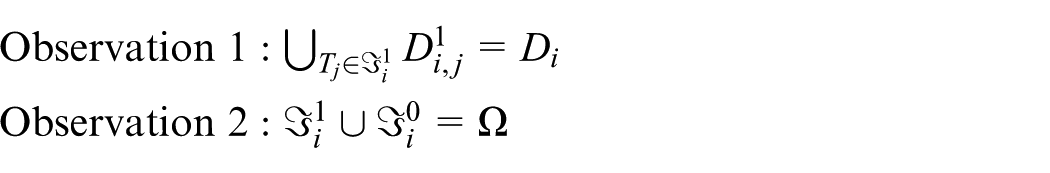
We assume that the bucket partition strategy is only shared by the sensor node and BS, while the SM has nothing about it. It is difficult for the SM to reverse deduce the corresponding range based on a given tag. In addition, ki,t and gi,t represent the encryption key and HMAC key of the sensor node si within the epoch t, respectively, ki,t = key1(id(si), t, ki,t−1) and gi,t = key2(id(si), t, gi,t−1). Here, key1 and key2 are different key generators, and the initial keys ki,0 and gi,0 and the key generators are only shared with the BS. The data encrypted using ki,t are denoted as
Next, to realize VP2RQ, we provide two core protocols: the first is the DC-protocol, in which the sensor nodes transmit the collected data to the SM for storage and the second is the QP-protocol, in which the BS and the SM cooperate to complete the query task.
DC-protocol
In the DC-protocol, the sensor node conducts a bucket partition to the collected data within each epoch and then encrypts the non-empty buckets and calculates the check-codes of the empty buckets. During the data submission route path from the sensor nodes to the SM, the check-codes within the same bucket are fused to reduce the communication cost. We provide details of the DC-protocol as follows.
According to the DC-protocol, we can see that the intermediate sensor node fuses check-codes uploaded by the child node and generated by itself that has the same tag; in this way, the number of check-codes that needs to be transmitted is reduced. In the meantime, the SM will also fuse all received check-codes in accordance with the tag to form the only check-code for each tag; and in this way, it can reduce the space storage cost in the SM.
In addition, it is easy to conclude that Properties 2 and 3 hold in accordance with Protocol 1:
Property 2. Within an epoch t, assume that the number of check-codes submitted by the sensor nodes si and sj are, respectively, ui and uj; if sj is in the path of si transmitting data to the SM, then 0 ≤ ui ≤ uj ≤ m, where m is the number of buckets that domain D is divided into.
Property 3. Within an epoch t, assume that the number of check-codes finally stored in the SM is u; then, 0 ≤ u ≤ m.
As shown in the above properties, in the path from any sensor node to the SM, the number of check-codes submitted by various nodes exhibits a non-decreasing trend, but they should not exceed the number of bucket partitions, and this is also the case for the number of check-codes stored in the SM.
Protocol 1. Data collection protocol (DC-protocol)
For any sensor node si, assume that its collected data set is Di. The following steps are applied by si.
Step 1. Conduct the bucket partition to Di. Assume that the non-empty bucket set and empty bucket set are NDB and EDB, we then have the following

Step 2. For any non-empty bucket

Step 3. In accordance with whether si is a leaf node, si constructs corresponding data information and transmits it to the parent node until it reaches the SM. The detailed process is as follows:
1. If si is a leaf node, assume that sj is the parent node of si; then, si generates and sends the following information to sj, in which id(si) refers to the ID of si

2. If si is the intermediate node, assume that its parent node is sj, and the set of its descendant nodes is

In which, ⊕ refers to the XOR operation, and
After receiving the data information transmitted from all sensor nodes in the cell, the SM gathers the encrypted buckets with the same tag and fuses the check-codes with the same tag to obtain the only check-code of this tag. Finally, the following data information is formed, which is stored

To clearly describe the DC-protocol, we give an example. Assume that the cell formed by sensor nodes s1, s2, s3, and the SM is as shown in Figure 4, and that the bucket partition strategy in Figure 3 is adopted. Within an epoch t, assume that the data collected by s1, s2, and s3 are {16, 24}, {5, 12}, and {6, 17}, respectively.
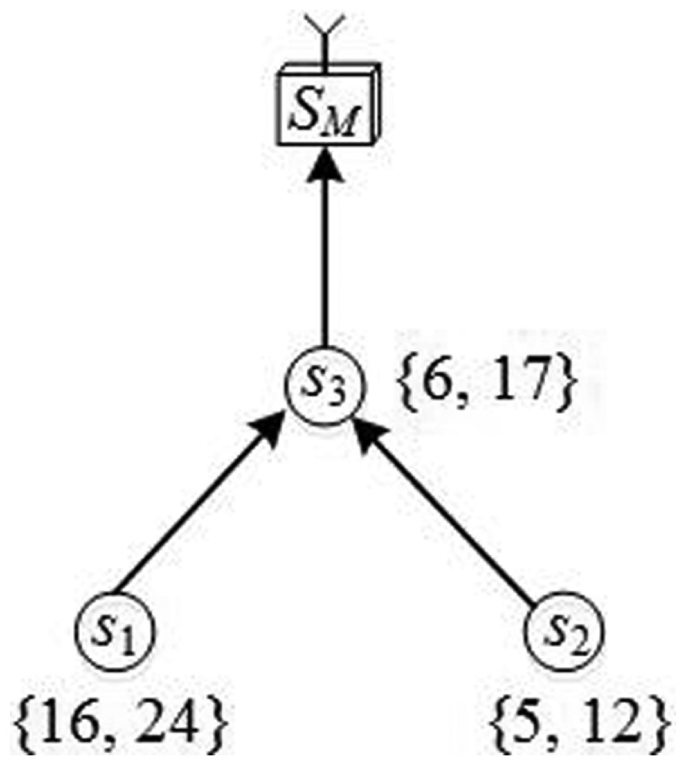
Example of DC-protocol.
According to the DC-protocol, s1, s2, and s3 transmit the following data information

Finally, the data collected and stored by the SM is as follows.

Protocol 2. Query processing protocol (QP-protocol)
Assume that the current query command is Q = (t, c, [low, high]); the BS cooperates with the SM to complete query processing as follows:
The BS calculates the corresponding interested bucket tag set tag([low, high]) of [low, high] according to the bucket partition strategy. It then constructs the secure query command Q′ = (t, c, tag([low, high])) and sends it to the SM, that is, as follows

After the SM receives the secure query command Q′, it first determines the candidate-encrypted buckets that satisfy the query requirement, t, all encrypted buckets whose tags are in tag([low, high]); then, it fuses all the corresponding check-codes into the only result check-code; finally, it generates the following message to submit to the BS

When receiving the response message from the SM, the BS utilizes the keys shared with sensor nodes to decrypt the encrypted buckets. Assume that the obtained plaintext data set is denoted as DQ. Then, we can determine the non-empty bucket tag set Ψ
i
of any sensor node si in tag([low, high]) where
Step 1. Obtaining the query result: The data set obtained from DQ that satisfies the requirement of [low, high] is the query result, which is denoted as; then

Step 2. Verifying the query result: The BS uses the decrypted data items and the HMAC key shared with sensor nodes to perform verification. Only if the following three conditions simultaneously hold, then ℜ satisfies the completeness requirement; otherwise, ℜ is abnormal:
1. Uniqueness. For the non-empty bucket
2. Coverability. All plaintext data items obtained from the received encrypted buckets are in the minimum coverage bucket of [low, high], that is, as follows

3. Correctness. For any sensor node si, if its empty bucket tag set Θ i is null, the result check-code must not exist in the response message; otherwise, the re-calculated result check-code should be completely consistent with hQ, that is, as follows

QP-protocol
Definition 4
Interested bucket tag set. Assume that the query range in query command is [low, high]; then, the minimum coverage bucket tag set tag([low, high]) is called the interested bucket tag set.
During QP, the BS first transfers the query range [low, high] into the interested bucket tag set and then sends the interested bucket tag set to the SM as the query command. The SM determines the candidate-encrypted buckets in accordance with the bucket tag set, fuses related check-codes, and then sends it to the BS. Then, the BS can determine the query result by decrypting the candidate-encrypted buckets, and the completeness of the query result can be verified by the received check-code. Detailed procedures are shown in Protocol 2.
From the QP-protocol, we can see that if all sensor nodes have data in each corresponding bucket of tag([low, high]), it is not necessary for the SM to return a check-code; otherwise, it only needs to return the only fused check-code. During the query result verification phase, the uniqueness condition is used to verify whether all non-empty buckets received by BS are unique; the coverability condition is used to verify whether all these non-empty buckets satisfy the range requirement of the query, while the correctness condition is used to check the correctness of the result check-code. Under the simultaneous effects of these three conditions, any abnormal query result caused by the malicious behavior of tampering or falsification will be detected.
Based on the example shown in Figure 4, we further discuss the QP-protocol. Assume that the query command is Q = (t, c, [15, 25]); the BS will determine the corresponding interested bucket tag set of [15, 25] to be {T2, T3}; then, it will construct the secure query command <t, c, {T2, T3}> and send it to SM; SM will return the candidate-encrypted buckets and the result check-code to BS, that is, as follows

After receiving the above message, the BS obtains the non-empty buckets with the tags of T2 and T3 generated by s1, s2, and s3 within t by decrypting the encrypted buckets, as shown in Table 2. Then, it can be determined that the query result is
Non-empty bucket with the tags of T2 and T3.

The BS verifies the completeness of ℜ by the following steps: first, it checks whether the formed non-empty buckets are unique; second, it checks whether all plaintext data {12, 16, 17, 24} obtained through decryption are within the corresponding minimum coverage buckets of tag[15, 25]), that is,
Protocol analysis
Security analysis
1. Privacy of sensor data
During the QP of VP2RQ, when the sensor nodes transmit the collected data to the SM, they first partition data into buckets and encrypt them where the keys are only shared with the BS. Since the bucket partition strategy is only shared by the BS and the sensor node, it is invisible to the SM. And before being submitted to the SM, all data items falling into the same bucket are encrypted as ciphertext blocks. The complexity of obtaining the sensor data for the SM is similar to cracking the encryption algorithm, and it is very difficult for the SM to obtain plaintext sensor data without knowing the bucket partition strategy and encryption key. Therefore, the privacy of sensor data can be preserved in VP2RQ.
2. Privacy of query result
The calculation of the query result is completed through the cooperation between the SM and BS. According to the interested bucket tag set tag([low, high]) in the query command, the SM sends all encrypted buckets whose tags belong to tag([low, high]) to the BS, and these encrypted buckets include the query result; then, the BS decrypts the received encrypted buckets to determine the final query result. Because the SM only involves encrypted data during QP, similar to (1), it is infeasible for the SM to obtain data items in the encrypted buckets that return to the BS; thus, it is hard to obtain the query result in plaintext. Therefore, we can see that VP2RQ can also preserve the privacy of the query result.
3. Privacy of query range
As indicated in the QP-protocol, we know that for the query range [low, high] in the query command, before sending the command, the BS will replace the plaintext range into the corresponding interested bucket tag set according to the bucket partition strategy. Without knowing the bucket partition strategy, it is very difficult for the SM to use the tag information to recover the query range. Therefore, we have that VP2RQ can ensure the privacy of the range of the query command.
4. Completeness verification of query result
It is very difficult for a compromised SM to break the completeness of query result without being detected by the BS since the encryption and HMAC keys of each sensor node change in every epoch and the SM has no idea of them. Any falsifying or tampering responses of the SM are checked by verifying the three conditions in the QP-protocol. For example, if the SM drops some candidate-encrypted buckets, the BS will detect it through the verification of uniqueness and coverability conditions. If the SM tampers with some candidate-encrypted buckets, the BS will check it through the verification of the coverability condition. Therefore, VP2RQ can verify the completeness of the query result.
Communication cost analysis
Since the SM has rich energy resources, while the sensor nodes are limited, the lifetime of the network totally depends on the energy consumption of the sensor node. We all know that the energy consumption of the sensor node mainly comes from communications, 30 so the communication cost of sensor nodes directly affects the lifetime of network. In addition, for the SM and BS, although they have rich energy resources, there is limited communication bandwidth between them. Less communication cost is preferable to improve the efficiency of QP. Therefore, the communication cost for QP between the SM and BS is also important for the entire network. We will analyze the network communication cost of VP2RQ from two perspectives: the sensor node communication cost CI and the QP communication cost CQ.
In accordance with the DC-protocol, each sensor node must transmit the following data to the SM: a node ID, a time epoch, some encrypted non-empty buckets, and their corresponding tags, as well as some check-codes for the empty buckets. Assume that there are n sensor nodes in the network, the length of node ID is lid, the length of the time epoch is lt, each node collects N data within each epoch, the range of sensor data is divided into m buckets, the length of a bucket tag is ltag, the probability of each bucket being empty is Pe, the length of a piece of ciphertext is lc, the length of a collected data item is ld, the length of the HMAC check-code is lh, and the average path between the sensor node and the SM is L hops. Then, the communication cost CI of sensor nodes is as follows.

According to the QP-protocol, in each QP, the BS will send the query command that contains the time epoch t and the interested bucket tag set tag([low, high]) to the SM. Then, the SM will return a response message to the BS, which has the time epoch, bucket tags, sensor node IDs, candidate-encrypted buckets, and result check-codes. Assume that the set tag([low, high]) contains δ tags; then, the probability of the corresponding bucket of each tag being empty is Pf. For each tag in tag([low, high]), there are λ sensor nodes generating non-empty buckets, and each non-empty bucket contains τ data items. Then, we have the following

Performance evaluation
We give the performance evaluation of CI and CQ of the proposed VP2RQ in this article through simulation and compare it with the existing methods S&L, 11 NSC,12,13 QuerySec, 19 and secRQ. 22 We realized the VP2RQ, S&L, NSC, QuerySec, and secRQ in the simulator. 31 Evaluations are performed on a PC with an Intel Core i3 (2.13GHz) CPU and 4 GB memory, Windows 7 64-bit operating system, Eclipse, and MATLAB. And, the Intel Lab Data set 32 is used.
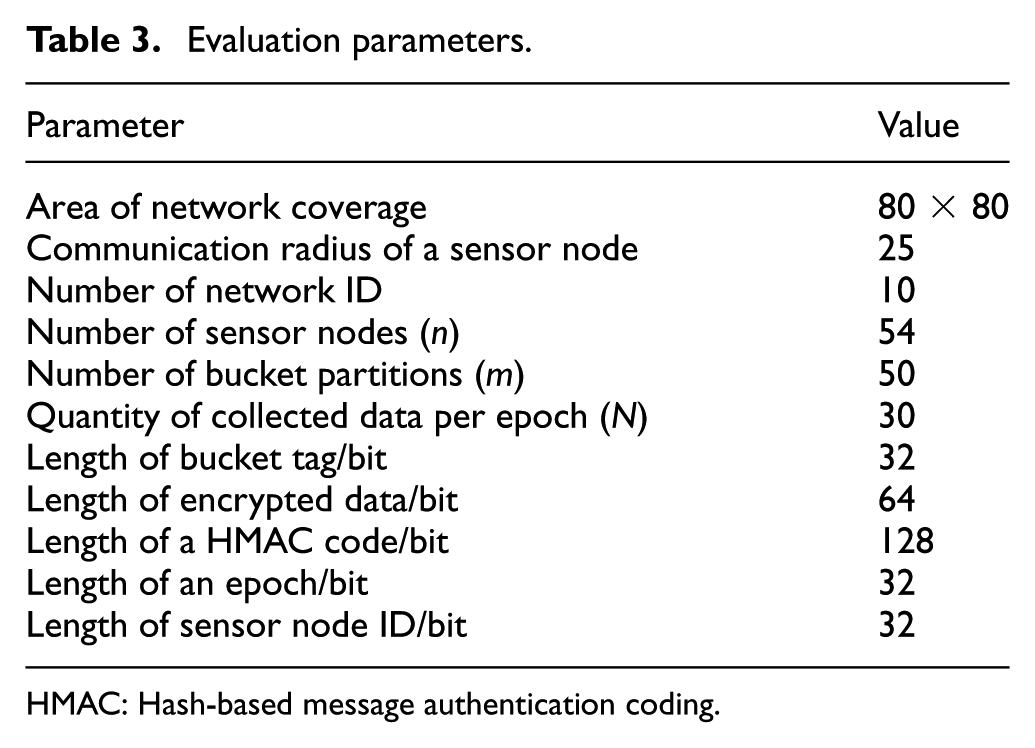
We assume that the length of a collected data item is 32 bits, and the equi-width bucket partition strategy and the Data Encryption Standard (DES) encryption algorithm are adopted. The default value settings of other parameters are shown in Table 3.
Evaluation parameters.
HMAC: Hash-based message authentication coding.
Sensor node communication cost evaluations
In each evaluation, 10 networks with random topologies denoted by different network IDs are generated. In each network, sensor nodes are randomly distributed. Then, we can determine the sensor node communication cost CI by obtaining the average measurement of these 10 networks:
CI versus network ID. Figure 5 shows that the CI of VP2RQ, S&L, NSC, QuerySec, and secRQ are all uniformly distributed in different networks. The CI of VP2RQ is significantly lower than that of the other four methods. Specifically, the average CI of VP2RQ is the lowest, and it is approximately 12.79%, 21.58%, 29.67%, and 30.58% of S&L, NSC, QuerySec, and secRQ, respectively. The reason is that each sensor node in VP2RQ only needs to generate one check-code for each empty bucket and fuse the check-codes with the same tag, which ensures that no more than m check-codes are uploaded by each sensor node. However, in the other methods, each sensor node needs to send more codes for the query result verification.
CI versus N. We vary the amount of data collected by a sensor node within one time slot N from 20 to 100 to test the impact of N on the performance of sensor nodes. As shown in Figure 6, CI of the five methods all grow with the increase in N. In particular, the CI of VP2RQ is obviously smaller than that of the others because the amount of encrypted data needed to be uploaded in the five methods all increase linearly with the increase in N, but the number of codes used for the result verification in VP2RQ is much smaller than in other methods.
CI versus m. We vary the number of buckets m from 20 to 100 to test the impact of m on the performance of sensor nodes. In accordance with Figure 7, we can see that with the increase in m, the CIs of QuerySec and secRQ remain the same, while the CI of VP2RQ, S&L, and NSC increase accordingly. Among these, S&L and NSC present significant increase, while the increasing trend of VP2RQ is not that obvious, and the CI of VP2RQ is the lowest among the five methods. The QuerySec and secRQ methods are irrelevant to the bucket partition, so the change in m does not have any impact on its CI, unlike the other four methods based on bucket partition, because the amount of sensor data remains the same, the number of empty buckets increases with the increase in m. In VP2RQ, the fusion of check-codes with the same tag can significantly reduce the number of uploaded check-codes; thus, VP2RQ is more efficient in CI than the other methods.
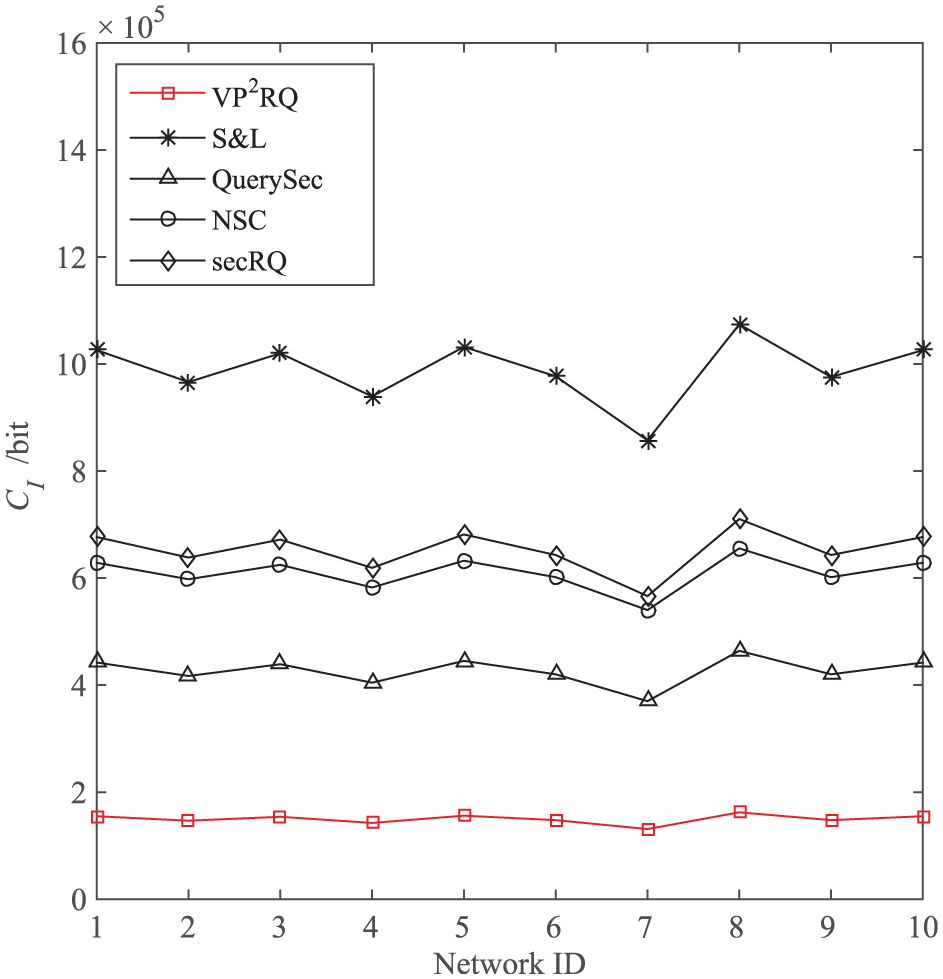
CI versus network ID.

CI versus N.
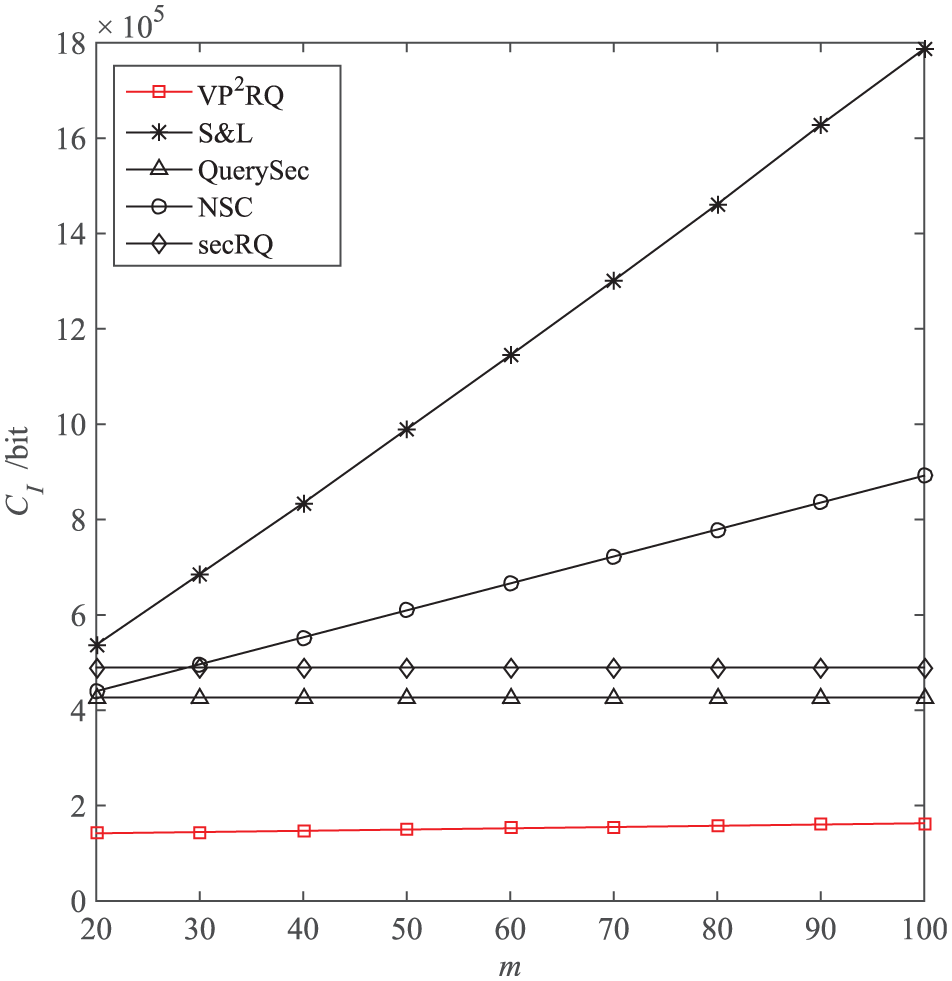
C I versus m.
QP communication cost evaluations
In this section, we focus on the communication cost CQ of QP in the methods of VP2RQ, S&L, NSC, QuerySec, and secRQ:
CQ versus N. Figure 8 reveals that the CQ of these five methods increases with N, among which VP2RQ and S&L are equal and lower than the others. The reasons for this are as follows. With an increase in N, the sensor data that satisfy the range query increase at the same time; then, the encrypted data returned by the SM increase in these five methods and CQ also increase accordingly. Furthermore, compared to QuerySec, NSC, and secRQ, both VP2RQ and S&L require the SM to upload the corresponding encrypted buckets whose tags are in the interested bucket tag set, and they only need to upload an extra code for verification of the query result; as a result, they have the lowest CQ.
CQ versus m. Figure 9 shows that the CQ of NSC also increases with m, and those of QuerySec and secRQ remain the same, while VP2RQ and S&L have the lowest CQ, first exhibiting a decreasing trend and then an increasing trend. The reasons for this are similar to those in Figure 7. For VP2RQ and S&L, when m is small, with the increase in m, the density of the bucket partition will gradually increase, and the union of the buckets whose tag are in the interested bucket tag set will increasingly get closer to the query range; therefore, the unqualified data embedded in the encrypted buckets and returned by the SM to the BS are reduced; thus, CQ decreases accordingly. While with further increase in m, the space to further reduce unqualified data becomes smaller, and the tag information uploaded with the encrypted buckets will increase; therefore, CQ gradually increases.
CQ versus cr. Here, cr is the coverage rate of the query range in the domain of the sensor data in the network. We set the lower bound of the query range to be equal with the lower bound of the domain and set the upper bound of the query range to change, which forms a different cr.

N’s impact on CQ.
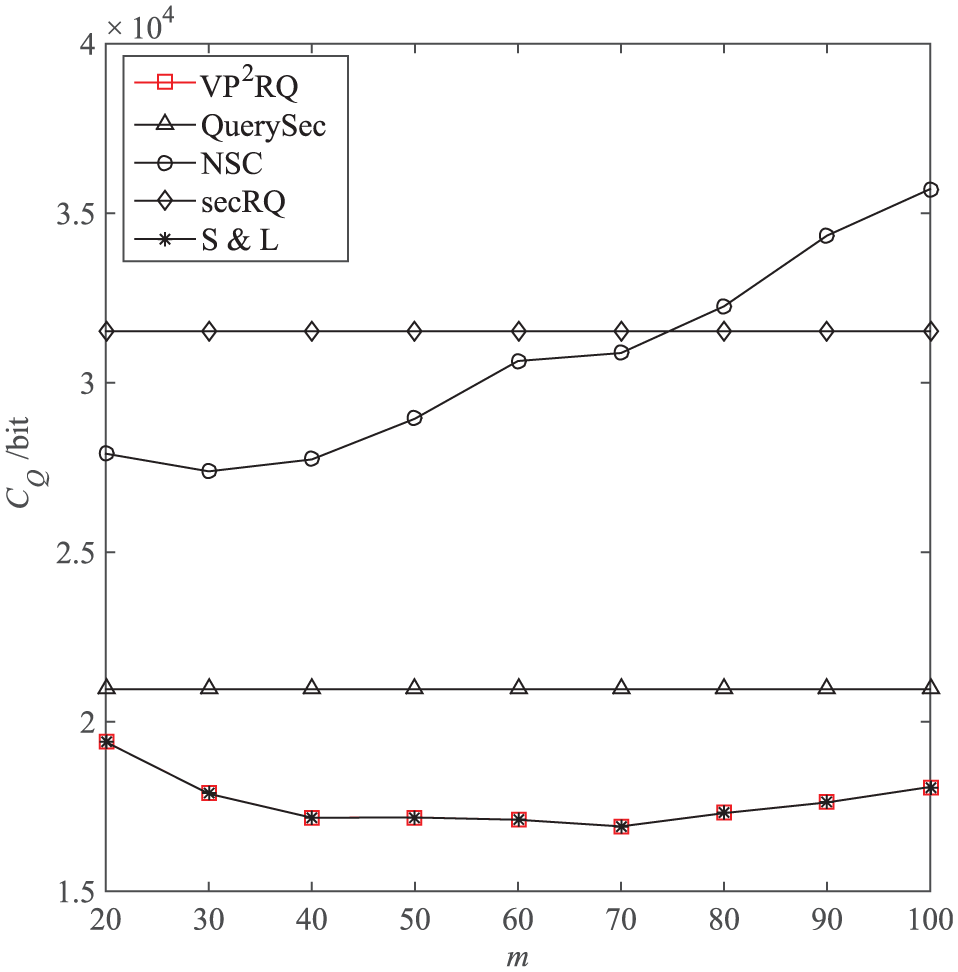
m’s impact on CQ.
As shown in Figure 10, we can see that before cr = 50%, the CQ of these five methods gradually increases with cr, and they are relatively small and close; but they experience rapid growth between 50% and 80%; and after 80%, they resume a gradual increase. In addition, before cr = 50%, the CQ of VP2RQ is slightly higher than that of QuerySec; but after cr = 50%, the CQ of VP2RQ and S&L is lower than those of QuerySec, NSC, and secRQ. The experiment phenomenon above is closely related to the distribution of sensor data in the whole domain, as shown in Figure 11. And, Figure 11 shows that the sensor data gradually increase in the first 50% part of the entire domain, but it is still very low; most data are concentrated between 50% and 80%; after 80%, once again, the sensor data gradually decrease; when cr is small, very few encrypted data satisfy the query requirement, so the CQ of these five methods is small. With the continuous increase in cr, the encrypted data that satisfy the query requirement rapidly increase. For reasons similar to those in Figure 9, the CQ of these five methods gradually increases with cr, and VP2RQ has the lowest CQ.
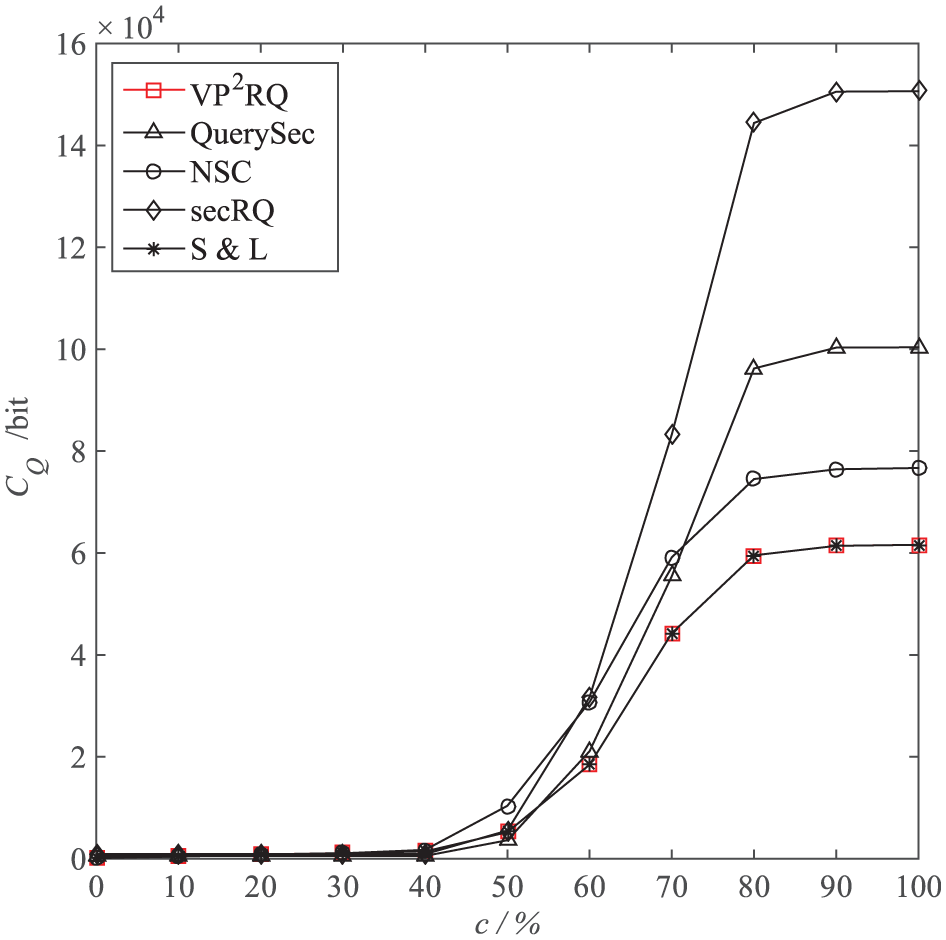
cr’s impact on CQ.

Distribution of sensor data.
The above experimental results show that CI and CQ in VP2RQ perform better than those in similar methods such as S&L, NSC, QuerySec, and secRQ. Therefore, the VP2RQ method proposed in this article shows better performance in prolonging the lifetime of sensor networks.
Conclusion
Verifiable privacy-preserving data QP is a significant issue commonly required in WSNs, and there is urgent demand for its application in various fields such as medical health, intelligent transportation, national defense, and military. It is also a hotspot problem in studies on WSNs. In this article, we propose an efficient VP2RQ method in two-tiered sensor networks. In this method, the DC-protocol and QP-protocol based on TAG routing, bucket partition, symmetrical encryption, information identity authentication, and check-code fusion are proposed to preserve data privacy and verify the completeness of query result. The theoretical analysis and experiment results show that VP2RQ can ensure the privacy security of the sensor data, query results, and query ranges, which also supports the completeness verification of query result at the same time; it also performs better than existing similar methods in terms of communication cost.
Footnotes
Academic Editor: Pardeep Kumar
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Natural Science Foundation of China under the grant nos 61300240, 61402014, 61572263, 61502251, 61472193, 61302157, and 61373138; the Natural Science Foundation of Jiangsu Province under the grant nos BK20151511, BK20141429, and BK20130096; the Project of Natural Science Research of Jiangsu University under grant nos 14KJB520027; CCF-Tencent Open Research Fund under grant no. CCF-Tencent RAGR20150107; the Fundamental Research Funds for the Central Universities under the grant no. NJ20160014; and Projects Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions and Jiangsu Collaborative Innovation Center on Atmospheric Environment and Equipment Technology.