
Abstract
With the popularization of Internet of things, its network security has aroused widespread concern. Anomaly detection is one of the important technologies to protect network security. To meet the needs of automatic and intelligent detection, supervised machine learning is widely used in anomaly detection. However, the existing schemes ignore the problem of data quality, which leads to the unsatisfactory detection effect in practice. Therefore, practitioners may not know which algorithm to choose due to the lack of review and evaluation of anomaly detection methods under low-quality data. To address this problem, we give a detailed review and evaluation of six supervised anomaly detection methods, as well as release the core code of feature extractor for pcap format traffic traces and anomaly detection methods for reuse. We evaluate the methods on two public datasets (one is a simulated network dataset and the other is a real Internet of things dataset). We believe that our work and insights will help practitioners quickly understand and develop anomaly detection schemes for Internet of things and can provide reference for future research.
Keywords
Introduction
With the rapid development of intelligent devices and network technology, the Internet of things (IoT) has been widely applied. Although zero trust security protection protocol has been deployed, 1 IoT still faces many challenges. As the IoT covers whole computer field, it has a wider attack surface. And it is constantly subject to traditional and emerging security threats. Anomaly detection, which aims to mine attack events in the IoT, is an important line of defense for network security. In the IoT, traffic can come at any time, including normal traffic as well as attack traffic, which is often used as data sources to detect network anomalies.
Network traffic–based anomaly detection has become a hot research field in recent years. As an automatic and intelligent technology, machine learning has been widely adopted for anomaly detection in the IoT security field. Many anomaly detection tasks of IoT cyberattacks can be transformed into supervised classification problems.2–6 The supervised machine learning is an inferring task from labeled training data. In training data, each instance consists of an input object (usually a vector) and a corresponding class value (also called a label). It analyzes the training data and generates an inferred output, which is a map of the input vector. An optimal solution will allow the algorithm to correctly determine the class labels of those newly arriving instances.
A major challenge for training supervised anomaly detection model is the need for high-quality data. The existing work shows superior performance because their data have been carefully processed. In practice, it is difficult to obtain high-quality data. Therefore, their effect may be far from satisfactory when actually deployed. Thus, we find a gap between research in academia and industry. First, to our knowledge, there is a lack of review of anomaly detection framework, methods and principles in the field of IoT. Developers have to take a lot of time to browse a lot of literature to understand the anomaly detection framework. Second, there is a lack of supervised anomaly detection methods for fine-grained comparison under low-quality data. Therefore, developers do not know which anomaly detection method is the most effective in practice.
To bridge this gap, we provide a detailed review and evaluation of supervised classifiers for IoT anomaly detection in the case of low-quality data. Meanwhile, we release the core code of feature extractor and anomaly detection methods. We firmly believe that our work can enable relevant practitioners to quickly start IoT anomaly detection methods and save time for development, as well as our insights can provide guidance for future work.
Specifically, we review six representative supervised anomaly detection methods in recent studies, such as logistic regression (LR), 7 support vector machine (SVM), 8 decision tree (DT), 9 naive Bayes (NB), 10 random forest (RM), 2 and multi-layer perceptron (MLP). 11 We also perform a fine-grained evaluation of these algorithms under low-quality data. We group low-quality data issues into the following three scenarios:
Missing category. Attack and protection are antagonistic and symbiotic. With preventive measures in place, attackers will change to bypass existing protections. As a result, new types of network attacks emerge in an endless stream. Therefore, unlike labeling text or images, some forms of attack do not appear when labeling the data. Thus, there is a lack of labels for evolutionary attacks.
Less labeled data. Data labeling is an extremely expensive task that requires not only expert domain knowledge, but also a lot of manual operations, which generally take a long time to perform. As such, there may be only a small amount of the data labeled manually, that is, low data.
Label assignment error. Due to time constraints or limited expertise, the labels provided may contain errors. For example, different types of attacks may be assigned the same category, normal events are labeled as attack events, and so on.
In summary, we make the following contributions in this article:
We provide a detailed review of commonly used supervised anomaly detection methods for automated IoT traffic anomaly detection.
We release an open-source toolbox for feature extraction and six supervised anomaly detection methods.
We conduct a fine-grained evaluation of benchmarking the effectiveness of anomaly detection methods under low-quality data.
Framework review
Figure 1 illustrates the overall framework for IoT traffic–based anomaly detection. The anomaly detection framework mainly consists of three components: network traffic collection, feature extraction, and anomaly detection.

Framework of anomaly detection. SVM: support vector machine.
Network traffic collection
Before analyzing network traffic, the acquisition of traffic data is the first step. There are usually two network traffic collection methods, that is, real network traffic collection and simulated network traffic collection.
Real network traffic collection usually uses specific collection software (e.g. Tcpdump 12 or Wireshark 13 ) to collect networks running in real environments (such as campus networks, enterprise networks, and IoT networks). Then the captured traffic data are analyzed and labeled for subsequent use. For example, Lopez et al. 14 analyzed and dissected a week’s worth of residential user traffic on a large telecom operator’s fixed broadband Internet access network and obtained an analysis of the security alerts generated by the intrusion detection system. Mirsky et al. 15 collected and analyzed a real Internet protocol (IP) camera video surveillance network. The collected real network traffic data may be unbalanced, thus it needs to take a lot of time for data preprocessing.
Simulated network traffic collection usually constructs the desired target network, and then injects abnormal events by simulating network attacks. For example, Hodo et al. 16 constructed a substation automation network. They simulated the communication between the substation slaves and the server based on the data obtained from the real substation and simulated the behavior of the system under attack. The traffic data collected by simulating the network are relatively balanced, but the simulated attack is also a known abnormal type. In addition, the simulated network traffic does not reflect the real network conditions.
For collected network traffic, a packet is the unit that provides network payload. Packet-based traffic is based on TCP (Transmission Control Protocol), UDP (User Datagram Protocol), and ICMP (Internet Control Message Protocol). Data packets carry a large amount of valuable data for network traffic analysis. Messages are hierarchically divided at the packet level, encapsulated into packets, and paired with addresses and headers, which is a process of encoding. It is then sent to the target address for decoding and execution. File headers guide packets through the network and can be used to identify and filter packets as they flow through the network using information such as IP address, port, and protocol number.
Feature extraction
After capturing network traffic, the next step is feature extraction, which transforms the traffic data into numerical vectors that machine learning can understand. In existing work, feature extraction for network traffic can be divided into two categories: packet-based feature vector and flow-based feature vector.
Packet-based features refer to the statistical features extracted at the traffic packet level, for example, the message length of each packet, the payload length of each packet, the value of TCP window length of each packet, and TCP flags. Nakahara et al. 17 selected the characteristics based on the packet, such as the number of packet and the length of packet, as the feature vectors to train a detection model.
Flow-based features are the feature vectors extracted at the flow level. A flow is defined by a quintuple that includes source IP address, destination IP address, source port, destination port and protocol. Therefore, a flow is a sequence of packets that has the same IP address, port, and protocol. Flow-based features can be flow duration, average number of bytes from server/client in each flow, average number of packets from server/client in each flow, and so on. Hafeez et al. 18 extracted flow-based features to train a deep learning model.
Due to the explosive growth of network traffic, packet-based feature extraction will produce more data, which will affect the operation efficiency of the detection model. Although flow-based feature extraction alleviates the problem of large amount of data to a certain extent, it will lose the detailed information at the packet level. Therefore, a lot of work combines packet-based and flow-based feature extraction. Liu et al. 19 combined them for training and traffic identification. To this end, we also develop a feature extractor for collected traffic in pcap format, which extracts both packet-based and flow-based feature. The statistics include common measurement indicators, such as mean and standard deviation. The flow chart of feature extractor is shown in Figure 2.
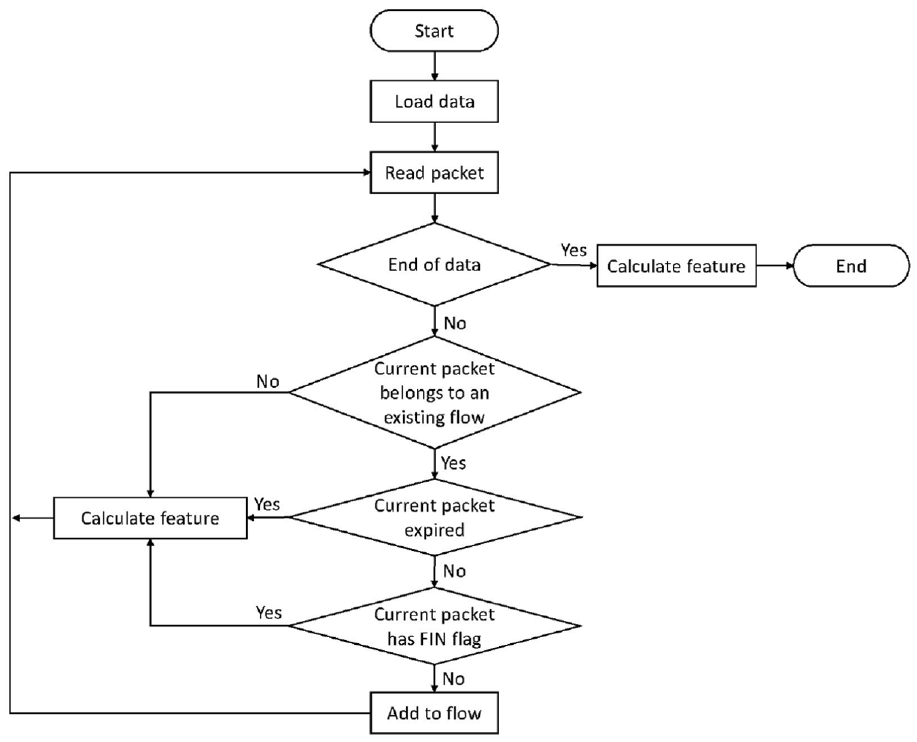
The flow chart of feature extractor. FIN: finished sending data.
The program of feature extractor is as follows. First, the pcap file of network traffic is loaded. Second, read the data packet. If it is not the end of the file, judge whether the current data packet belongs to an existing flow; otherwise, calculate the features and the program ends. Third, if the current packet belongs to an existing flow, judge whether the current packet has expired (e.g. the expired time is set as 30 s); otherwise, calculate the features and continue to read the packet. Fourth, if the current packet has not expired, judge whether the current packet contains a finished sending data (FIN) flag; otherwise, calculate the features and continue to read packet. Fifth, if the current packet does not contain the FIN flag, add the current packet to the existing flow; otherwise, calculate the features and continue to read the next packet. Until the end of file reading.
We write the feature extractor in C language and release the core code on github. 20 Readers can optimize on this basis and achieve the features they need for their own datasets.
Anomaly detection
After extracting the numerical feature vector, the machine learning algorithms can be used to train and generate the detection model with optimized parameters. The detection model then can be used to distinguish whether the incoming traffic is abnormal or not.
We will evaluate the performance of supervised machine learning algorithms under low-quality data. The evaluation algorithms will be described in detail in the next section.
Machine learning algorithms
Our goal is to cover a wide range of classification and learning algorithms with different implementation principles and examine their performance under low-quality data. Therefore, we will compare six representative supervised machine learning algorithms: LR, SVM, DT, NB, RM, and MLP.
Logistic regression
LR is one of the most popular algorithms because of its simplicity, effectiveness, and strong interpretability. The LR can be used for some common classification problems, such as spam filtering 21 and network anomaly detection. 7
When dealing with anomaly detection problems, LR can simply regard it as judging whether it is “0” or “1.” Training LR is to find the decision boundary, as shown in Figure 3.

An example of logistic regression.
The principle of LR is shown in Figure 4. It first sums the input feature vectors, and then passes through an activation function called sigmoid (if there is no such step, it is LR), whose definition is shown in equation (1). The output of LR is a probability value between 0 and 1. To predict which category a data belongs to, we can set a threshold (e.g. 0.5). To detect anomalies, the label of a traffic feature vector is abnormal if the output probability of LR is


The principle of logistic regression.
Support vector machine
SVM has been proven to be robust and efficient for many problems. 22 In the field of anomaly detection, SVM also solves a decision hyperplane.
From the perspective of linearly separable classification, SVM establishes an optimal decision hyperplane so that the distance between the two types of samples closest to the plane is maximized. Here we briefly review the SVM essential elements.
Consider
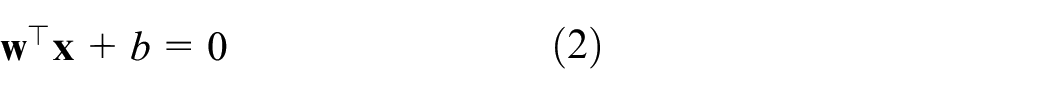
where

Then the following inequality holds

According to the principle of structural risk minimization, the optimization becomes a convex optimization problem

subject to inequality equation (4). To solve the above constraint optimization problem, Lagrange function is introduced and minimized
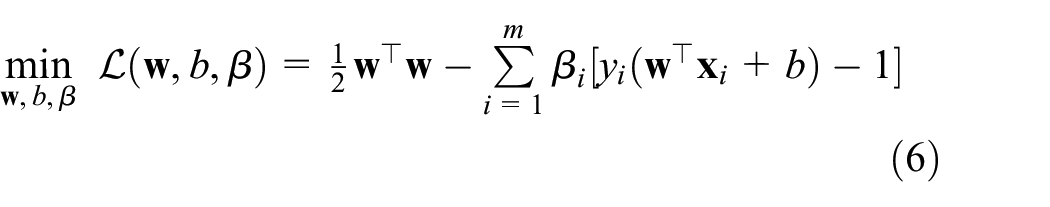
After finding the optimal filter

An example of anomaly detection using SVM. SVM: support vector machine.
Decision tree
DT constructs a top–down tree structure by learning a simple decision rule (If… then…, Else… then…) from the feature attributes of the training data. A DT consists of a root node, internal nodes, and leaf nodes. Starting from the root node, the feature with the largest information gain (gini, 23 entropy 24 ) is selected as the division feature. The process is performed recursively until the information gain is small or there are no features to divide.
The leaf nodes represent the decision value, that is, the category labels. Therefore, to judge the state of a traffic feature, you only need to find the final leaf node along the path according to the structure of the tree. And judge whether it is abnormal or not according to the state of the leaf node.
Figure 6 illustrates an example of DT with “gini” criterion, where there are totally 50 samples in the network traffic training data. The “value=[]” in each node means four classes and the corresponding quantity. When dividing the root node, the feature X[23] is selected as the best attribute. Therefore, the whole samples are split into two subsets according to the value of this attribute. The leaf nodes with “gini=0.0” denotes the final label with occurrence number.

An example of decision tree.
Naive Bayes
NB is a probability classifier that applies the Bayesian formula under the assumption that the features are strongly independent. In the anomaly detection classification work, we assume that the

Expanding equation (7), we can get

Assuming that the feature attributes

Since
Therefore, the goal of NB classifier is to get the maximum probability in each category, which is the decision result, that is, find

Random forest
RM uses a random way to build a forest. This forest consists of many DTs. And there is no relationship between each DT in the RM. In anomaly detection field, when a new sample arrives, each DT in the forest predicts which category the sample should belong to, and finally the results of all DTs are combined to get which category the sample belongs to.
As shown in Figure 7, the RM first random samples the training feature vectors (bootstrap samples). When constructing a DT, the best attribute to be split can refer to all or part of the features. Therefore, the input samples of each DT are different. As a result, each tree generated is unique. The advantages of randomness prevent over-fitting, and then finally taking the mean of all DTs for prediction also eliminates some errors.
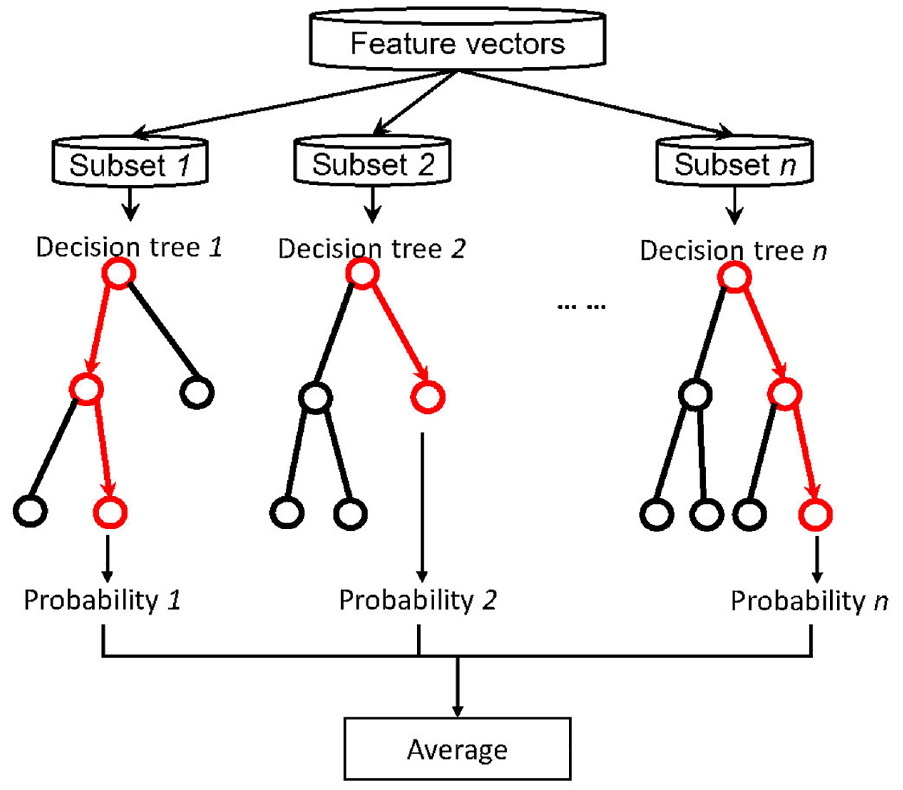
An example of random forest.
Multi-layer perceptron
MLP is a representative of deep learning network. In recent years, it has been widely used in the field of anomaly detection.25–27
Figure 8 shows a simple MLP network structure. MLP is a multi-layer neural network that can contain multiple hidden layers. Each layer has multiple neurons. Neurons between layers are connected by synapses, and each synapse represents a weight value. In the process of forward propagation, each neuron sums the input data and passes through an activation function (e.g. equation (1)). The output is the probability of different classes.

A simple example of MLP. MLP: multi-layer perceptron.
Training an MLP requires first building a loss function, which is the mean squared error between the output label and the true label. Training an MLP is the process of discovering the weights that minimize the loss function through back propagation (e.g. using gradient descent).
Evaluation study
In this section, we first introduce the datasets we use and the experiment setup for evaluation. Then we provide the evaluation results of the supervised anomaly detection algorithms under low-quality data.
Datasets
In our evaluation, two public network traffic datasets are used to examine the supervised learning performance under low-quality data:
KDDCup99 dataset is a classical dataset in the network traffic anomaly detection domain. It contains a standard set where a wide variety of attacks are simulated in a military network. 28 Among 4,898,431 entries generated, about 80% are abnormal. There are four major types of anomalies, including DoS, U2R (unauthorized access to local superuser privileges by a local unprivileged user), R2L (unauthorized access from a remote machine to a local machine) and Probe (surveillance and probing). In the evaluation, we ignore U2R anomalies due to too few samples. Although the data are outdated, it can provide some insights for future research.
Kitsune network attack dataset is generated on an IoT network, 15 which contains nine different attacks datasets. Each dataset is labeled as malicious (1) or not (0). For convenience, we only use Mirai and OsScan attacks for demonstration.
We randomly choose 80% of dataset as the training data and the remaining 20% as the testing data. To evaluate the performance of algorithms on low-quality data, we adjusted the data to simulate three scenarios:
Scenario 1: Missing Category. To simulate the missing category, we kick out an anomaly in the training dataset, leaving the test dataset unchanged.
Scenario 2: Less labeled data. We randomly select different proportions of the training dataset to form new training subsets.
Scenario 3: Label assignment error. We randomly reverse labels of different proportions in the training dataset.
Experiment setup
We implement the algorithms (LR, SVM, DT, Gaussian NB, RM, and MLP) by utilizing scikit-learn 29 and release the code on github. 30 For the multiple classification tasks, we implement the algorithms with one-versus-rest policy.
We conduct all our experiments on a Linux server, which is configured with 32G memory, 9T hard disk and 16 Intel Xeon E5-2630 central processing units (CPUs).
Metrics
We use the following metrics to report the evaluation results:
Precision: It calculates the proportion of predicted positive instance that are actually positive instance. It is expressed as:
Recall: It represents the ability of a detection model to identify positive instance, which is defined as:
F1-measure: It considers both precision and recall, and is defined as the harmonic average of the two metrics:
Performance comparison of scenario 1
We first evaluate the performance of machine learning algorithms in the case of missing classes in the training dataset. In practice, lack of attack knowledge is very common, since the attacks are constantly evolving with new types over time. When experts label the data, it is impossible to include all types of attacks.
In this experiment, we kick out the “probe” attack in the training data to deduce the detection model, and then use the well-trained model to test on the testing data with complete categories. Figure 9 shows the results of both algorithms for detecting different events under KDDCup99 dataset. In can be seen that although the training dataset is only lack of probe attack, it will also have a negative impact on the detection performance of all categories.

Performance in the case of missing DoS under KDDCup99 dataset. (a) Precision for normal. (b) Recall for normal. (c) F1-measure for normal. (d) Precision for DoS. (e) Recall for DoS. (f) F1-measure for DoS. (g) Precision for probe. (h) Recall for probe. (i) F1-measure for probe. (j) Precision for R2L. (k) Recall for R2L. (l) F1-measure for R2L. LR: logistic regression; SVM: support vector machine; DT: decision tree; NB: naive Bayes; RM: random forest; MLP: multi-layer perceptron.
Figure 9(a)–(c) show the detection performance for normal events. We can see that NB shows the worst performance. In the absence of class label information, LR, SVM, RM, and MLP are the most affected, reducing the F1-measure by up to 23%. Figure 9(d)–(f) show the results for detection DoS. Except SVM and DT, other algorithms are very stable. Figure 9(g)–(i) show the performance of detecting probe. Unfortunately, all algorithms cannot detect probe attack. Figure 9(j)–(l) show the detection results of R2L. The results are consistent with detecting normal events, and NB is the worst. The reason is that the data distribution may be different from that of Bayes hypothesis.
Figure 10 shows the results under Kitsune dataset. In the experiment, we use the Mirai attack for training the detection model, and use the OsScan attack as the new unknown attack for testing. We can see that although the detection of the new attack OsScan has a high recall, the precision and F1-measure are far from satisfactory, indicating that the supervised algorithms fail to detect new attacks without new labels.
Insight 1: The emergence of new attacks will reduce the detection performance of the model against known attacks.
Insight 2: The supervised detection model cannot effectively detect unknown attacks.

Performance in the case of missing DoS under kitsune dataset. (a) Precision. (b) Recall. (c) F1-measure. LR: logistic regression; SVM: support vector machine; DT: decision tree; NB: naive Bayes; RM: random forest; MLP: multi-layer perceptron.
Performance comparison of scenario 2
Unlike labeling images, everyone can do it. Labeling network attacks requires not only professional knowledge, but also a lot of time to complete manually. Therefore, usually only a small part of the data is labeled. In this part, we evaluate the performance under small proportion of labeled data. To achieve this, we randomly sample different proportions (e.g. 0.9, 0.7, 0.5, 0.3) from the training dataset to generate the training subsets. Figure 11 shows the corresponding results.

Performance in the case of small amount of labeled data under KDDCup99 dataset. (a) Precision for normal. (b) Recall for normal. (c) F1-measure for normal. (d) Precision for DoS. (e) Recall for DoS. (f) F1-measure for DoS. (g) Precision for probe. (h) Recall for probe. (i) F1-measure for probe. (j) Precision for R2L. (k) Recall for R2L. (l) F1-measure for R2L. LR: logistic regression; SVM: support vector machine; DT: decision tree; NB: naive Bayes; RM: random forest; MLP: multi-layer perceptron.
From the whole figure, we can draw two conclusions. First, the performance of all algorithms (e.g. Figure 11(b) and (j)) decreases with the reduction of labeled data. Second, the algorithms fluctuate greatly with the reduction of labeled data, whose robustness is poor. The reason is that the data-driven algorithms can deduce the stable optimal parameters only when there is enough training data.
Figure 12 shows the results of using less training data for kitsune dataset. In terms of F1-measure, DT and RM are more robust than other algorithms. However, their performance still declines with the reduction of the number of training samples.
Insight 3: Insufficient training data lead to the underdetermined parameters of the supervised detection model.

Performance in the case of small amount of labeled data under kitsune dataset. (a) Precision. (b) Recall. (c) F1-measure. LR: logistic regression; SVM: support vector machine; DT: decision tree; NB: naive Bayes; RM: random forest; MLP: multi-layer perceptron.
Performance comparison of scenario 3
When processing network traffic data, it is very common to have wrong labels. Whether it is real network traffic or simulated network traffic, noise will inevitably be introduced. In addition, the labeling work is completed manually by people, which cannot guarantee that the label is 100% correct.
To simulate the wrong labels, we randomly replace the labels of each category in different proportions (e.g. 2%, 4%, 6%, 8%, 10%) for the training dataset, while the testing dataset remains unchanged. The reported results are shown in Figure 13. Obviously, in the face of label errors, NB is the least robust. Affected by label errors, the performance of DT also decreases. Other algorithms have strong robustness with respect to label errors.

Performance in the case of wrong labels under KDDCup99 dataset. (a) Precision for normal. (b) Recall for normal. (c) F1-measure for normal. (d) Precision for DoS. (e) Recall for DoS. (f) F1-measure for DoS. (g) Precision for probe. (h) Recall for probe. (i) F1-measure for probe. (j) Precision for R2L. (k) Recall for R2L. (l) F1-measure for R2L. LR: logistic regression; SVM: support vector machine; DT: decision tree; NB: naive Bayes; RM: random forest; MLP: multi-layer perceptron.
Figure 14 shows the results of label errors for kitsune dataset. RM shows the best performance among all algorithms. DT and NB are the least robust.
Insight 4: Label errors also decrease the detection performance of the supervised detection model.

Performance in the case of wrong labels under kitsune dataset. (a) Precision. (b) Recall. (c) F1-measure. LR: logistic regression; SVM: support vector machine; DT: decision tree; NB: naive Bayes; RM: random forest; MLP: multi-layer perceptron.
Related work
Machine learning is a promising tool for automated and intelligent network traffic anomaly detection. Palmieri 31 effectively classified the previously unseen total traffic or single traffic as “normal” or “abnormal” traffic through LR. Abbasi et al. 7 used LR and artificial neural network to extract features and classify the IoT anomalies. The results show that using LR, the classification efficiency and accuracy are higher. Lei, 32 Ma et al., 33 and Davahli et al. 8 used SVM for network traffic anomaly detection problem. On each cluster of network traffic clustering, Muniyandi et al. 34 used the DT to learn the subgroups to refine the decision boundary. Ferrag et al. 9 used different classifier methods based on DT and rule-based concept to detect Internet of things attacks. Onah et al. 10 adopted NB for anomaly detection in fog computing. Alrashdi et al. 2 proposed an intelligent anomaly detection system for smart city based on RM. Niandong et al. 35 proposed a detection method of RM classification for power network anomaly detection. Teoh et al. 26 used the most advanced deep learning technology (e.g. MLP) for cyber security threads detection. Reddy et al. 11 uses dense stochastic neural network method to distinguish and classify abnormal behavior and normal behavior according to the types of attacks in the Internet of things.
A lot of work has been done to compare machine learning algorithms in the field of network security. Williams et al. 36 showed the impact of feature set reduction using consistency-based and correlation-based feature selection on the performance of NB, C4.5 DT, Bayes network, and NB tree algorithms. They also found that when the classification accuracy is similar, the computational performance is the difference. Anderson and McGrew 37 compared six machine learning for encrypted traffic. They focused on the impact of feature extraction on performance of algorithms and conduct coarse-grained testing on the impact of noisy labels. Different from the above work, we divided the data quality in fine-grained evaluation and studied their impact on machine learning algorithms so as to provide insights for future work.
Conclusion
Network traffic is widely used as a data source for IoT anomaly detection. In recent years, network traffic has exploded. To realize automation and intelligence, supervised machine learning technology is widely adopted in anomaly detection. Data quality is a key challenge for supervised machine learning. Practitioners do not know how to select the appropriate algorithm, because there is a lack of reviewing and comparing the performance of these methods under low-quality data. To bridge this gap, we provide a detailed review and algorithm evaluation. We test these methods on two public datasets in fine granularity and released the core code of feature extraction and anomaly detection methods for reuse, which avoids redesign and saves development time.
Footnotes
Handling Editor: Peio Lopez Iturri
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This paper is supported by the National Key R&D Program of China through project 2020YFB1005600; the Natural Science Foundation of China through projects U21A20467, 61932011, and 61972019; the Beijing Natural Science Foundation through project M21031; and the Populus euphratica found CCF-HuaweiBC2021009.