
Abstract
Smart phone and its applications are used more and more extensively in our daily life. Short delay of arriving data is important to these applications, especially to some time-sensitive ones. To reduce transmission latency and improve user experience, a dynamic decentralized data replica placement and management strategy which works in edge nodes is proposed in this article. It studies the location, access frequency, latency improvement, and cost spent on placing replicas on edge nodes to seek a balance between cost spent for storage and reduced latency. Specifically, dynamic and decentralized replica placement strategy algorithm has load guarantee for edge nodes to avoid overload; it dynamically create or delete data replicas on edge nodes according to the request frequency. Dynamic and decentralized replica placement strategy is decentralized to relieve transmission cost. Experiment results show that dynamic and decentralized replica placement strategy algorithm in edge computing environments can greatly reduce transmission latency, balance edge nodes load, and improve system performance. Dynamic and decentralized replica placement strategy also considers the cost spent for storage, and it pursues a balance between many factors.
Introduction
In the past decades, computer has almost changed the lifestyle of human beings. Nowadays, many new technologies and devices are emerging and developing very fast, such as Internet of Things (IoT), smart devices, wireless network, and cloud computing. They have made a continuous impact to our daily life and work. Many new smart applications, such as smart city, smart campus, and smart transportation, are appearing every day. They often need to exchange data with cloud server instantly.1,2 These interactive activities bring much transmission and calculation load to network and data center. Although the network has got great improvements over the last decades, it can never meet the needs. Cloud centers and network can provide neither acceptable transfer rates nor response times for applications.3,4 To obtain good performance of applications, replication mechanism is always used to reduce file transfer time and bandwidth consumption.5–8 Many companies choose to buy storage services on edge nodes to place replica to keep better response times and transfer rates. So, it is necessary to pay more attention to the strategy which is used to decide when and where to place a replica; a good strategy could get a great improvement of latency with less cost.
In this article, we concentrate on a special case in which requests are growing exponentially, the data are time-sensitive, and distances between some end users are not far. Several real-life cases are indicated from example 1 to example 3. Example 1 (Figure 1): Decades of students are having class in the same classroom; assume that they need to watch the same video as their teacher asked. They connect to the cloud center and ask for the same data at the same time, the data center should serve every user, process the same requests, and send them the same data. Example 2: Hundreds of people are in the same meeting in several buildings, they ask cloud center for the same video data continuously. Example 3: A short video is very popular in recent days; many end users ask cloud center for this video, and the computing task is very heavy if the cloud center serves every user. In these scenarios, end users need the same data, their requests are time-sensitive, and they asked data almost at the same time, so, it is really a hard and boring work to cloud center. Moreover, many requests need a large amount of data and they are latency-sensitive applications. As we know, data centers are often located near the core network; the applications and services will suffer terrible round-trip latency, when the user receives the data, maybe it is not useful. Even it is useful, the obtaining process is really a waste of resource both for the data center and the network.

Replica placement model in cloud-edge environment.
So we span our sight to edge nodes which ones are in close proximity of end users. In this case, if end users can get the data from edge nodes rather than data center, both the request latency and load of data center will be reduced. Of course, if we put data replicas on all edge nodes, we can get the shortest latency, but it is a waste of resource and almost unrealistic. However, as shown in Figure 1, if we place the replica on critical edge nodes (e.g. node B), we can achieve the goal of reducing the load of data center and reducing the latency at low cost. So, when and where to place a data replica needs to be studied; we expect to spend the least cost in exchange for the biggest gain.
Overall, the contributions of this article are as follows. (1) We proposed a dynamic and decentralized replica placement strategy (DDRP) which is also multi-objective optimized. This decentralized algorithm can make decision much faster than centralized algorithm because it does not need to do a complicate computation to get a global optimal solution; (2) we compared DDRP with other strategies with regard to several metrics; the results showed DDRP could reduce more latency with less cost. The rest of this article is organized as follows. Section “Related works” analyzes the related works. Section “Problem formulation” describes the problem formulation. Section “Strategy and algorithms” presents DDRP algorithm. Section “The simulation results and analysis” shows and analyzes the experimental results. Finally, section “Conclusion” concludes the article and gives some future work.
Related works
In recent years, many scholars have studied on replica placement. Many remarkable results have been achieved. Shao et al. 9 proposed a collaboration-aware data replica placement for IoT workflows in collaborative edge and cloud environments. Chen et al. 10 proposed a centralized data replica placement strategy for cloud environment. Naas et al. 11 proposed a runtime IoT data replica placement strategy in Fog architectures and the iFogSim framework with a heuristic solution. Khanli et al. 12 proposed PHFS which is a dynamic replication method; it considered how to decrease access latency in the multi-tier data grid. Cui et al. presented a data replica placement strategy which is based on genetic algorithm, and this strategy has better performance for scientific applications in cloud environment.
However, some of the existing strategies are centralized13,14 or static; 15 although they can yield optimal or near-optimal replica placement strategy by the collection of all replicas and all edge nodes status, the transmission of these controlling data causes a network overhead; the response time is also increased by the complex computation of optimal result. Moreover, the centralized methods also need a single point to be the central replica controller; if it is failure, the whole system failed. Centralized strategy is not popular now because it will take a heavier load to cloud center. There are also some decentralized algorithms.16–18 Chen is one of the earliest researchers tries to develop dynamic replica placement strategy. He proposed a dissemination tree for replica placing and data synchronizing. 19 Shen et al. proposed an algorithm which attempts to place replicas on traffic hubs on in a P2P system. Mansouri and Dastghaibyfard 20 introduced a Hierarchical data replication strategy (HDRS); it improved the performance in cloud computing, but did not take any cost considerations. The proposed strategy (DDRP) considers the cloud center load, and it is designed as a decentralized one.
In recent years, many scholars have paid more attention to replica placement strategy in Hadoop Distributed File System (HDFS) because Hadoop is a general platform for distributed storage and has been widely used in many enterprises.21,22 Carlos Guerrero et al. presented a strategy focused on virtualized Hadoop for a coordinated and simultaneous management of file replicas and virtual machines. Yang Liu et al. proposed a dynamic data placement strategy for new replicas to search a best location according to their hotness. This method can adjust data replicas stored on each node in a heterogeneous Hadoop cluster and also can reduce the response time of big data applications dynamically.
Wei et al. presented a cost-based dynamic replication management method called CDRM. It put replicas with the consideration of capacity and the blocking probability of edge nodes. But it did not span their sight into the volume of data.
Atakan Aral proposed a decentralized replica placement algorithm (D-ReP) for edge computing, and this work is the most similar work to ours. D-ReP is based on magnitude and location of user demand and storage price in attempt to reduce data access latency. The authors also provide a replica discovery method with which nearby replicas can be found quickly. It provides best effort latency improvement and cost reduction, but it has not concerned edge nodes load and real-time performance guarantees. 23
All the approaches mentioned above aimed at reducing system latency, providing better service to users. However, most of these strategies ignored the cost need to spend or the load of edge nodes. In this article, we focus on the ratio of cost we spend and latency we reduced to guarantee the cost we spend has high performance.
Problem formulation
The aim of our policy is to reduce transmission latency, save storage cost, and balance edge nodes load. The strategy wants to get an optimal value for every factor, but these three factors are not irrelevant, they have conflicts. For example, if replicas are placed on many edge nodes, the transmission latency tends to decrease, but the storage cost and edge nodes load tends to increase. So, we adopt cost-effective ratio to balance the trade-off between conflicting factors. The cost-effective value is the ratio of latency improvements and the cost we spend for storage.
In a real network environment, the situation tends to be more complex. The centralized strategy can get an optimal solution or a close to optimal solution, but the data center must know all replicas status on all edge nodes; the maintenance of the global list will increase much load to network because data center and edge nodes need to exchange much status information. Furthermore, the calculation of the optimal solution is also time-consumed. So, in this article, we adopt decentralized strategy; although it cannot get a global optimal solution, by the leverage of greedy idea, we can get a local optimal solution in a short time and we just need local topology network structure, so that we can meet the real-time requests of time-sensitive applications.
There are two kinds of nodes in our strategy. One is source data node which holds some data replicas, it is also called source node for the sake of brief; the other is edge node which request replicas from data source node, it is also called client node for short. A client node is a neighbor of a source node; when replicas are duplicated to it, it becomes a source node.
To a given source node, we assume that the below listed information in the current epoch can be known before:
1. Request number of each data replica from each client.
2. Transmission latency to each client node.
3. The unit storage cost of each client node.
Strategy and algorithms
The basic idea of DDRP strategy
The source node monitors requests it received from its client nodes. When the cost-effective value of placing a given replica on a client edge node is equal or bigger than the threshold, the source node sends a little virtual machine to the client node to test the system load. If the client node is not overload, the source node creates a replica on the client node, and then, the client node becomes a new source node. At the same time, the new source node notifies all of its neighbors about this replica so that its neighbors can get replicas from the new source node other than data center; by this way, both the transmission latency and the data center load are reduced. Every source node monitors its performance at a certain frequency. If it is overload, it will also duplicate data replicas to some edge nodes for offloading. If the requests of a given replica fade on a source node, the replica will be migrated to one of its client nodes.
In this strategy, the cost-effective threshold (CET) is the key to make the replica placement decision; if the application is sensitive to time, the value of CET should be small because more storage cost should be spent to reduce the latency, vice versa. The cost-effective value of the system can be changed according to the needs of the applications.
The notation definition of DDRP
Data set:
Source nodes set:
Client edge nodes set of current source node:
The neighbor nodes set to a given client node:
Requests set:


The main factors that will affect edge node performance are CPU utilization (
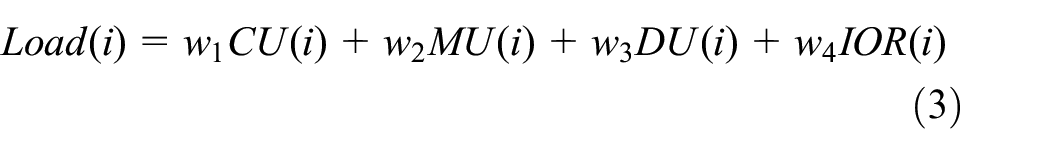
In the above equation,

The analytic hierarchy process is used to calculate the weight coefficients.
Cost-effective value
As mentioned above, cost-effective is a ratio, and it indicates the trade-off between latency improvement and storage cost to place a given replica

where
Discovery and retirement of replica
As we mentioned above, every source node in the system knows the data request number and storage cost of all its neighbor nodes, so we keep two tables on each source node: one is Neighbor Table (NT) which is used to store the neighbor nodes information, such as unit storage cost and latency; and the other is Replica Table (RT) which is used to store its replica information, such as replica ID, size, expire time, and stored node. Every client node will only keep one table, RT. When a data replica is created or deleted on node
So, when a client node
There are three cases that replica
To guarantee the service quality, node
An implement example of DDRP
We use an example to illustrate DDRP strategy. As shown in Figure 2. When node

Execution process of DDRP.

The simulation results and analysis
Settings of experiments
To evaluate the performance of our strategy comprehensively, we conducted decades of experiments with different settings to analyze and compare our strategy with four existing strategies. Some of them are single cloud without edge nodes. Some of them are Cloud-Edge systems. We used CloudSim to simulate the edge computing network and test our strategy in different scenarios (S1–S20), as shown in Table 1. The key parameters we have considered are listed in Table 2.
The settings of different scenarios.

CET: cost-effective threshold; NLT: node load threshold.
Key parameters of network simulation setting.

Since network latency and request number both cannot be predicted accurately, we set them to random integer values in a range. The epoch time is 10 in every scenario. First, we test our strategy with different number of edge nodes in S1–S10, and the results of LIR are shown in Figure 3(a); we can deduce that LIR do not have significant fluctuation with different edge nodes number. So, our strategy is stable, in the subsequent experiment, and we do not test our strategy with different number of edge nodes, jut set its value as 50. Then, we test the impaction of CET, and the result is shown in Figure 3(b); we can deduce that when CET is increasing, the LIR is decreasing, that means, if you seek high-cost performance, you will spend less cost, so the LIR will decrease.

The effects of different number and different CET values to LIR: (a) different edge nodes number and (b) different CET value.
Comparison of DDRP performance with PHFS, MORM, and HDRS
We compared DDRP with PHFS, MORM, and HDFS with different request numbers and data size, and the results are depicted in Figure 4. In Figure 4, we compared the average response time of four strategies. Multi-objective Optimized Replication Management strategy (MORM’s) value is much higher than the other three. Since it is static, the replicas are generated according to average latency and the computing resource of cloud center. DDRP, Predictive Hierarchical Fast Spread (PHFS), and HDRS are dynamic; they create replicas based on request numbers, so their values are close. DDRP’s value is little lower than the other two.
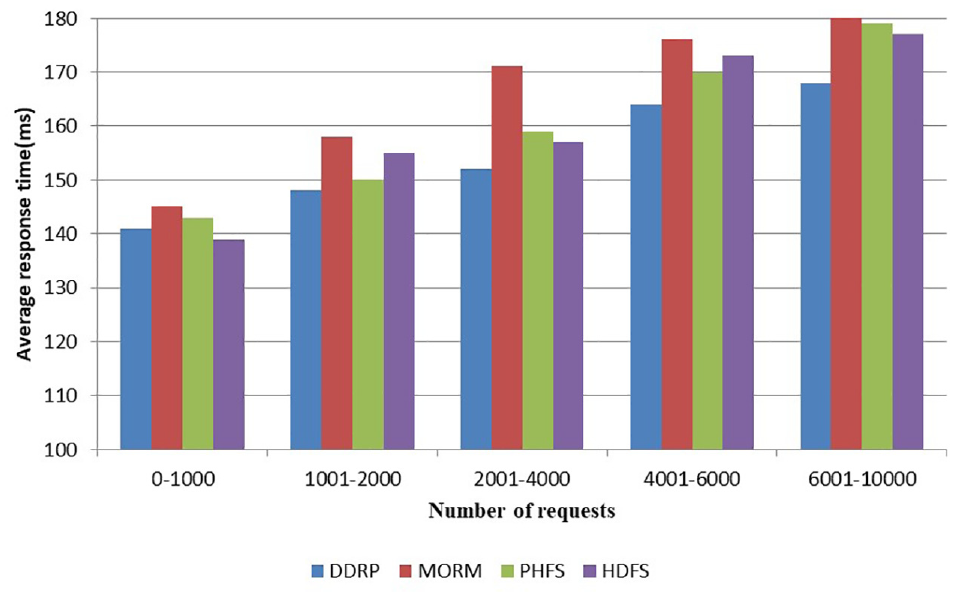
The average response time comparison of DDRP, PHFS, MORM, and HDFS.
Comparison of DDRP performance with D-Rep
We also compared DDRP with decentralized algorithm named D-Rep. D-Rep is a decentralized algorithm, it also considers cost and network latency as our strategy. We compared DDRP with D-Rep in different scenarios (S1–S20), as shown in Table 1. In our system, the storage and transmission cost is according to Amazon S3 price rules, the storage unit is 128 KB, the size of each data block is a random multiple times of 128 KB; there are 30 data blocks in every data center. To get more accuracy experiment results, we set the neighbor number as 25, 50, 75, and 100, respectively; for each node number, we run the simulated program 20 times and calculate the average value.
Figure 5 is the comparison of LIR cost between DDRP and D-Rep in S1–S5. These scenarios have different network delays, but other parameters are the same. The result indicates that DDRP can achieve lower LIR than D-Rep, especially when the network delay is serious. That means, DDRP performed better than D-ReP in bad network occasion, and it can spend less cost while reducing more latency.

Comparison between DDRP and D-Rep under different values of network latency.
In S6–S10, the request number is different. Figure 6 is the comparison between different ranges of request number; we can conclude that when the requests are bursting out, DDRP has more LIR and less cost.

The comparison between DDRP and D-ReP under different request numbers: (a) the LIR comparison and (b) the cost comparison.
In S11–S15, the network status is normal and the request number is normal too. We compared DDRP and D-Rep with different CETs, and the results are shown in Figure 7. When the CET value is between 0.5 and 2.5, LIR of DDRP is more than D-ReP, and cost of DDRP is much less than D-Rep, which means DDRP can reduce much latency with less cost.

The comparison between DDRP and D-ReP under different values of CET: (a) the LIR comparison and (b) the cost comparison.
In S16–S20, the network load is a little heavier, but it is stable. Figure 8 indicates the comparison results of DDRP and D-ReP with different node load thresholds; when the node load is less than 0.7, the LIR of DDRP is less than D-ReP, but the cost DDRP spent is much less than D-ReP, and, when the node load is equal or more than 0.7, the LIR of DDRP is much more than D-ReP, which means DDRP can be more effective when the edge node is overload.

The comparison between DDRP and D-ReP under different values of NLT: (a) the LIR comparison and (b) the cost comparison.
From all above experimental results we can conclude that DDRP algorithm can reduce transmission latency, balance edge nodes load, and get higher cost-effective value; it has better performance in request bursting out case and edge nodes overload case.
Conclusion
The network is everywhere and it has been used by everything. The edge-cloud application is becoming the mainstream of future software. So, the replica placement strategy is concerned by more researchers since it is a good solution of long latency and low performance of the system. In this article, we have done a lot of study on replica placement strategies in edge-cloud environment and proposed DDRP in which replicas are placed on edge nodes based on cost-effective value; DDRP has also considered the load of edge nodes because heavy load will not reduce system latency but may increase it. The experimental results indicated that compared to D-ReP, our strategy can get more latency improvement with less cost and edge nodes will not overload. In the future, we will continue extending DDRP with real-time performance guarantees.
Besides the development of edge intelligence, the replica placement strategy can be interconnected together with the distributed intelligence for offloading intensive tasks generated by a large number of end users to idle edge servers. In the future, we intend to apply replica placement principle to place distributed machine learning model on edge nodes to reduce the computing tasks on cloud and take full use of computing capabilities on edge nodes.
Footnotes
Handling Editor: Peio Lopez Iturri
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Jilin Provincial Department of Science and Technology (Grant No. 20210101185JC). The manuscript was also improved thanks to China Scholarship Council (CSC; Grant No. 2018(10038)) and Dr Liqiang Wang who is the director of big data laboratory in Computer Science Department of University of Central Florida.