
Abstract
Machine learning techniques, especially deep learning algorithms have been widely utilized to deal with different kinds of research problems in wireless communications. In this article, we investigate the secrecy rate maximization problem in a non-orthogonal multiple access network based on deep learning approach. In this non-orthogonal multiple access network, the base station intends to transmit two integrated information: a confidential information to user 1 (the strong user) and a broadcast information to user 1 and user 2. In addition, there exists an eavesdropper that intends to decode the confidential information due to the broadcast nature of radio waves. Hence, we formulate the optimization problem as a secrecy rate maximization problem. We first solve this problem by employing convex optimization technique, then we generate the training, validation, and test dataset. We propose a deep neural network–based approach to learn to optimize the resource allocations. The advantages of the proposed deep neural network are the capabilities to achieve low complexity and latency resource allocations. Simulation results are provided to show that the proposed deep neural network approach is capable of reaching near-optimal secrecy rate performance with significantly reduced computational time, when compared with the benchmark conventional approach.
Introduction
Recently, artificial intelligence(AI)–driven techniques for wireless communications have attracted increasing research attentions. 1 The beyond fifth generation (B5G) and sixth generation (6G) wireless networks will emerge AI-driven use cases, including automatic driving, Internet of Things (IoT), and tactile communications. Machine learning techniques are the specific methods to realize AI, which has the capability to learn from previous experience and make decisions to the environment.2,3 Machine learning technique is divided into various frameworks, including regression algorithms, deep learning, random forest, and so on. Deep learning or deep neural network (DNN) is one of the most widely utilized machine learning technique, which was developed to mimic the functions and organizations of human brains. 4
Multiple access techniques have been utilized in commercial wireless communication systems for a long history, from the first generation (1G) to 5G. Most wireless systems employ conventional orthogonal multiple access (OMA), for example, frequency division multiple access and code division multiple access, which is capable of serving only one user in a single orthogonal resource block. 5 Ultra-high data rate and massive connections are the basic demands of B5G and 6G wireless networks, as well as IoT networks. 6 Non-orthogonal multiple access (NOMA) is considered as a promising technique to meet these demands.7,8 NOMA exploits the successive interference cancelation (SIC) approach at the receivers to serve multiple users in the same wireless resource block.5,9
Security is a critical and important problem for wireless systems. Due to the broadcast characteristic of information carrier, wireless communications are more vulnerable to be attacked.10,11 Conventional security methods employ secret keys to encrypt and decrypt confidential messages, which rely on the ultra-high complexities of specific mathematical problems.11,12 The conventional encryption methods are proven to be safe; however, one issue may arise that there exist risks in the procedures of secret key distributions and exchanges, due to the fact that secret keys are transmitted in plain text.13,14 Physical layer security is a technique to address this issue, which is capable of introducing additional security for secret key distributions and exchanges. The concept of physical layer security was first proposed by Shannon, 15 then this research was push forwarded by Wyner and Csiszár.16,17 Theses work demonstrated that if the signal to noise plus interference ratio (SINR) or the signal to noise ratio (SNR) of the legitimate channel is larger than that of the eavesdropper’s channel, the eavesdropper cannot decode anything.
In the literature, most resource allocation designs are developed based on conventional convex optimization approaches.14,18–22 These methods employ iterative algorithms to obtain either optimal or sub-optimal solutions, which are high computational complexity and consume much time for computing. Therefore, it is challenging to deploy conventional resource allocation approaches to B5G and 6G systems, since they may not be able to meet the ultra-low latency demands of future wireless networks. Recently, deep learning–based resource allocation designs have drawn increasing research attentions. Zhou et al. 23 investigated the deep learning–based resource allocation design in a cognitive radio network. Luo et al. 24 studies the power minimization problem based on deep learning approach in a NOMA system. Sun et al. 25 propose a DNN approach for interference management over interference limited channels.
There are a large amount of machine learning techniques and compared with other techniques, deep learning has several superiorities: (1) deep learning can be treated as a universal function approximator, which already has been employed to deal with different resource allocation problems;6,23 (2) along with the mini-batch gradient descent algorithm, deep learning is capable of saving computational resources, since other machine learning techniques, like support vector machine, require to calculate all the data at the same time;26,27 (3) in comparison with conventional design, the deep learning–based design can provide the near-optimal results within very short time slots, when the DNN is well trained. 23
Motivated by the aforementioned aspects, in this article, we consider the secure transmission in a NOMA network, which consists of one base station, two users and one eavesdropper. The base station intends to send two information: one confidential information to user 1 and one broadcast information to user 1 and 2. It is assumed that the eavesdropper intends to wiretap the confidential information. Our aim is to maximize the secrecy rate of user 1 under the constraints of quality of service (QoS) of user 1 and 2. We first formulate the secrecy rate maximization problem and solve it by a linear fractional programming technique. Then, we obtain the training dataset through repeatedly running the simulation of this approach and feeding the training data into our DNN framework to process the training stage. When the training is finished, the weights of this DNN is determined and it establishes a mathematical relationship between the inputs and the corresponding outputs. We also generate a test dataset to evaluate the performance of the trained DNN. In particular, by comparing the performance of both schemes, we show that the DNN-based algorithm has the capabilities to reduce the computational time and achieve near-optimal performances. Our main contributions are summarized as follows:
To the best of our knowledge, none of the existing work has considered employing a DNN to design resource allocations for secure transmission in a NOMA network.
In this article, according to the characteristics of the power allocation coefficients in NOMA network, we employ the novel cross-entropy as the cost function. The existing work of deep learning–based resource allocation designs employ the mean square error as the cost function,6,23,24 and utilize a min–max function to incorporate the power constraints, which may introduce additional computational complexity. To address this issue, we employ the cross-entropy as the cost function, which has the capability to strictly satisfy the power allocation constraints.
We first formulate the secrecy rate maximization problem and solve this problem through conventional approach, which is exploited to generate the training dataset. Then, we train the proposed DNN with this dataset. Once the DNN is trained, we compare the secrecy rate performance and the computational time with the conventional approach. Finally, simulation results are provided to demonstrate that the proposed DNN approach can achieve near-optimal secrecy rate performance with significantly reduced computational time when compared with the conventional approach.
The rest of the content in this work will be formed as following: We present the system model in the “System model” section, whereas the resource allocation problem is formulated to maximize the secrecy rate and it is solved through conventional approach in the “Convex optimization–based approach” section. “The proposed DNN approach” section demonstrates the DNN-based resource allocation design. “Simulation results” section provides numerical results to evaluate the effectiveness of our proposed DNN approach and the conclusions are provided in the final section.
System model
In this work, we investigate a NOMA wireless network, which is shown in Figure 1. It is consists of four terminals: one base station, two users, and one eavesdropper. All the terminals are equipped with only one antenna. The base station intends to send confidential information to user 1, at the same time sends the broadcast information to user 1 and user 2. Due to the broadcast nature of wireless carrier, we assume that the eavesdropper tries to decode the confidential information. The channel state information (CSI) between the base station and user 1, user 2, as well as the eavesdropper can be presented as



where
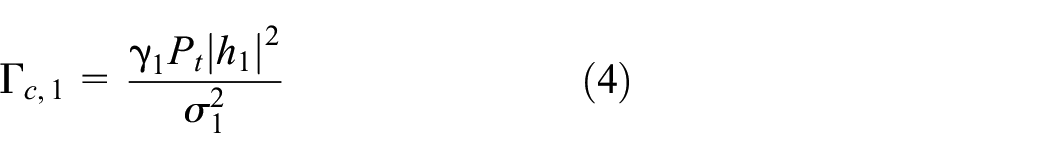
and

respectively. The achieved secrecy rate at user 1 is defined as


A NOMA network with one base station, two users, and one eavesdropper.
The SINR of decoding the broadcast information at user 1 and user 2 are expressed, respectively, as

and

The capacity of the broadcast information at user 1 and user 2 are expressed as

and

respectively.
Convex optimization–based approach
In this section, we formulate the secrecy rate maximization problem and present the conventional approach to solve it. This optimization problem can be formulated as
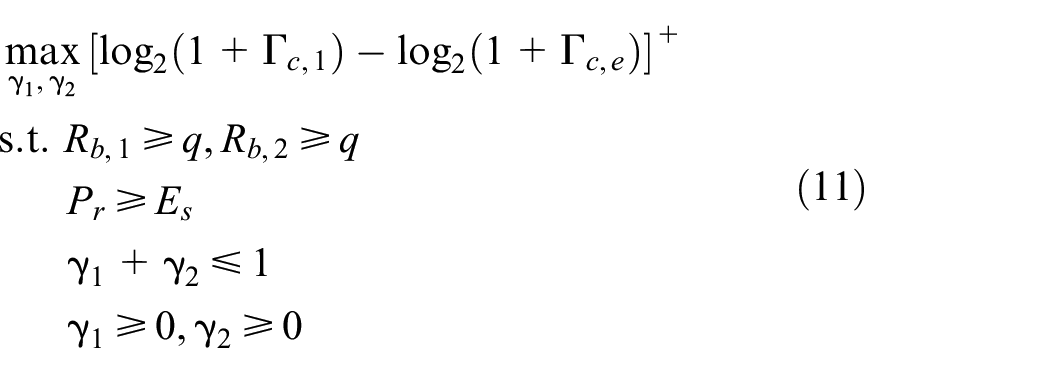
where

The problem in equation (12) is still non-convex due to the fractional constraint. To address this issue, we employ the Charnes–Cooper transformation,
30
which is utilized to recast linear fractional problems into tractable forms. The first step of Charnes–Cooper transformation is to introduce a slack variable; in our design, we employ

Then, the above problem can be reformulated as
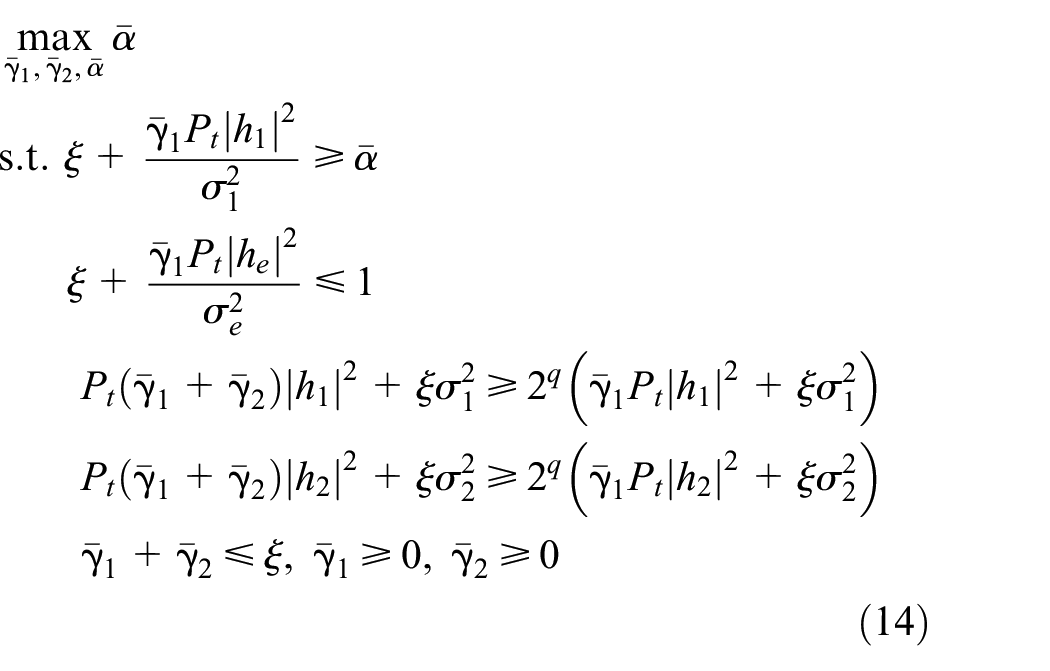
The problem in equation (14) is convex, and is proven equivalently to the original problem.
31
Note that the optimal solutions can be obtained through convex optimization tool box CVX.
32
When the problem in equation (14) is solved, the optimal power allocation coefficients can be obtained through
The proposed DNN approach
In this section, we present the proposed resource allocation design based on the DNN approach. We propose a full connected DNN to learn the relationship between the input channel parameters and the output power allocation coefficients to maximize the secrecy rate at user 1.
The proposed DNN is able to work and be robust to real-time scenarios, the reasons are: (1) we notice that all resource allocation optimization problems are solved by using different kind of algorithms, the fundamental works has shown that NNs are universal function approximators 33 and have the remarkable capabilities of algorithmic learning; 34 (2) prior works demonstrated that DNN techniques have the capability to substantially reduce the computational complexity and processing time for a variety of problems in wireless communications, that is, resource allocation optimizations,6,23,25 channel estimations, 35 and physical layer designs; 36 (3) the increased processing capability of computers due to recent advancements of processors and massively parallel processing architectures, which confirms the robustness of computers to process a huge amount of data within a very short time frame. 37
Note that for other resource allocation design scenarios, it is difficult to apply the proposed approach directly, due to the fact that different system models and optimization problems have different inputs and outputs. It only needs to modify the structure of DNN and then it can be utilized for other scenarios. Furthermore, a DNN technique cannot handle the optimization problems in dynamic environments efficiently; a reasonable method may be a combination of several machine learning techniques including DNN, reinforcement learning, or other algorithms. 6
As shown in Figure 2, our proposed DNN has three parts: the input layer, multiple hidden layers, and the output layer. In this work, the absolute value of channel coefficients


The full connected DNN.
The target of this DNN is to learn from the training dataset and determine its weights and bias to establish the mapping. In the training process, the DNN first performs the feed-forward calculations, which can be mathematically presented as


where

Assume the proposed DNN has

where

where
Lemma 1
To minimize the cost function, the back propagation–based gradient descent algorithm can be employed, where the ith layer weights
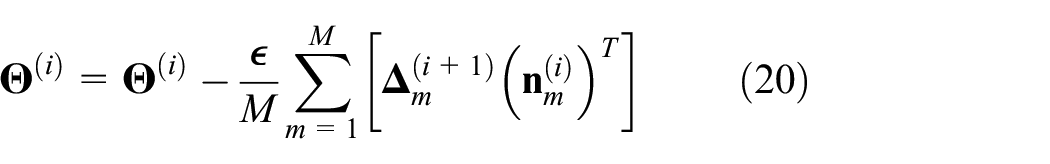

where
Proof
Based on the chain rule and the cost function


As it is easy to obtain
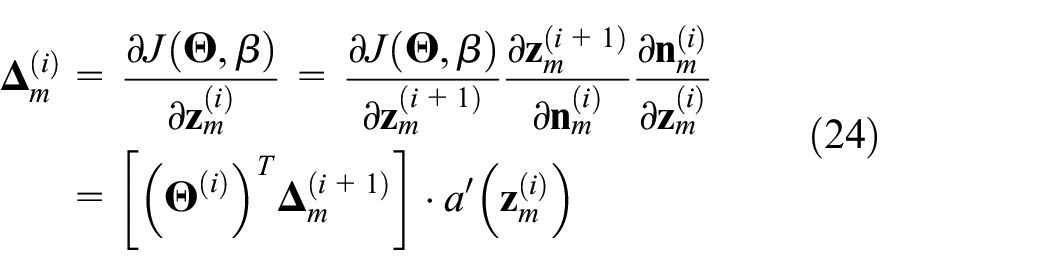
Based on the back propagation policy, the weights and bias of the DNN are updated one by one from the output layer to the input layer. Then, we consider the gradient descent algorithm and introduce the learning rate


which completes the proof of Lemma 1.
The implementation of the proposed DNN approach are divided into three parts: preparing, training, and evaluating. The detailed information of these parts are summarized in Algorithm 1.

Simulation results
In this section, we provide the simulation results to evaluate the proposed approach. The training, validation, and test datasets are obtained through running the simulation of conventional approach, where the size of these datasets are
Figure 3 depicts the cross-entropy obtained by training and validation datasets versus the number of training epochs. Both the curves first decrease as the number of epochs increases and then stay constant. Note that the validation dataset is utilized to calculate the cross-entropy only, it does not contribute to the training. The purpose of introducing the validation dataset in the training process is to observe whether over-fitting is occurred. When the DNN learns the training dataset very precisely, it may learn some noise as well. If we introduce additional dataset, the DNN may not be able to fit the additional data. 39 As seen in this figure, it is obvious that over-fitting does not happen. It is due to the fact that over-fitting happens when a machine learning model is more accurate in fitting a particular set of data but less accurate in additional data.2,26 The validation data do not participate in training process and can be seen as an additional data. Over-fitting occurs if the cross-entropy of the validation data increases while that of the training data steadily decreases. Therefore, the cross-entropy of the validation data remains constant confirming that over-fitting does not occur. Furthermore, for machine learning techniques, to reduce or avoid over-fitting is a critical problem. Over-fitting is a phenomenon that a model has nearly perfect performance on training data but poor performance on new data. 40 In general, regularization methods are employed to reduce the impact of over-fitting. As observed in Figure 3, over-fitting does not occur, and employing regularization methods also brings additional computational cost as provided in the work. 6 Hence, we do not consider regularization methods in our design.

The cross-entropy versus the number of training epochs obtained by training and validation datasets.
Next, Figure 4 presents the achieved secrecy rate versus transmit power obtained by conventional and DNN approaches, respectively. The QoS of the broadcast information is set to 5 bps/Hz. As shown in this figure, the achieved secrecy rates rise as the transmit power increases. In addition, the proposed DNN approach is capable of achieving a similar secrecy rate performance as the optimal solution. However, there is a performance gap between the optimal solution and our proposed DNN approach, which is because the training errors always existed.

The achieved secrecy rate versus transmit power obtained by conventional and DNN approaches.
Then, the achieved secrecy rate versus the QoS of broadcast information obtained by conventional and DNN approaches were provided in Figure 5. The transmit power is set to 30 dBm. As seen in this figure, the achieved secrecy rate declines as the capacity requirements of broadcast information increases. Similar to the previous figure, it is shown in this figure that the proposed DNN approach has a near-optimal performance and there also exists a performance gap between the conventional and DNN approach.
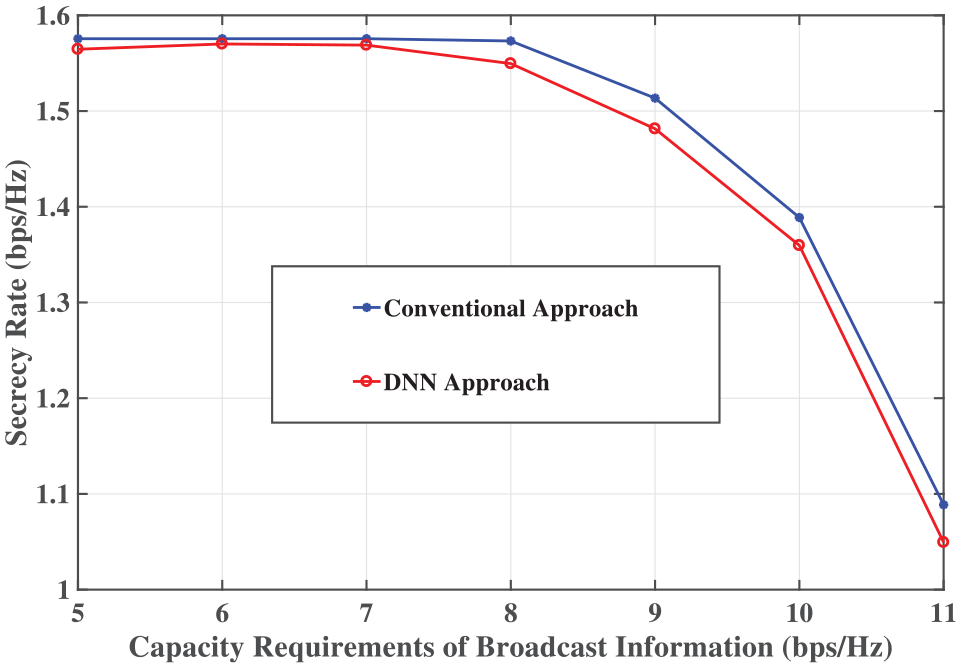
The achieved secrecy rate versus the QoS of broadcast information obtained by conventional and DNN approaches.
Next, Table 1 demonstrates the achieved secrecy rates of both approaches with different transmit power, whereas Table 2 presents the computational time of both approaches with different transmit power. These tables show a more detailed information of Figure 4. Note that the secrecy rate is obtained through averaging all 3000 results of the test dataset, whereas the computational time is the summation of 3000 results. In these tables, “Transmit power” means the maximum available transmit power at the base station, “DNN” stands for the results of our proposed DNN approach, “Conventional” means the results of conventional optimization approach, and “Ratio” is the ratio of “DNN” divided by “Conventional.” From the tables, it is obvious that our proposed DNN achieves no less than 95% of the optimal performance, while requiring no more than 1% of the computational time than the conventional optimization approach.
The achieved secrecy rates of both approaches with different transmit power.

DNN: deep neural network.
The computational time of both approaches with different transmit power.

DNN: deep neural network.
Next, Table 3 depicts the achieved secrecy rates of both approaches with different QoS demands of broadcast information, whereas Table 4 illustrates the computational time of both approaches with QoS demands of broadcast information. These tables show a more detailed information of Figure 5. The calculation methods of secrecy rate and computational time, as well as the definition of “DNN,”“Conventional,” and “Ratio” are same as those of Tables 1 and 2. In these tables, “QoS demands” denote the capacity requirements of broadcast information. As shown in these tables, the proposed DNN approach can achieve more than 97% secrecy rate performance with no more than 1% computational time in comparison with the conventional approach.
The achieved secrecy rates of both approaches with different QoS demands of broadcast information.

QoS: quality of service; DNN: deep neural network.
The computational time of both approaches with different QoS demands of broadcast information.

QoS: quality of service; DNN: deep neural network.
Then, Figure 6 presents the achieved secrecy rate against different number of hidden layers (left axis, red curve), as well as the computational time of the test dataset versus different number of hidden layers (right axis, pink curve). As seen in this figure, we can conclude that increasing the number of hidden layers affects only few of the secrecy rate performance, where the differences are within a range of 1%. This confirms that introducing number of hidden layers cannot bring much performance improvement. In addition, the achieved secrecy rates go up and down as the number of hidden layers rises; since the initial parameters of the DNN as well as the optimizer are randomly generated, different combinations may result in different performances. However, more hidden layer will introduce more computational time, as the presented by the pink curve. This is due to the fact that the computational complexity increases as the number of hidden layers rises.

The achieved secrecy rate (left axis) and computational time (right axis) versus number of hidden layers.
Finally, Figure 7 demonstrates the probabilities of the QoS constraints not satisfied in the test dataset versus different transmit power, whereas Figure 8 presents the probabilities of the QoS constraints not satisfied in the test dataset versus different capacity requirements. The results of these two figures are calculated by counting the total number of the non-satisfied constraints in the test dataset, then divided by the total number of QoS constraints of the same dataset. The simulation parameters of Figure 7 is the same as that of Figure 4, and the assumptions of Figure 8 is the same as Figure 5. As shown in Figure 7, the probability of the non-satisfied constraints is decreasing as the transmit power increases. In addition, from Figure 8, we can see this probability increases as the capacity requirement rises. Overall, for the aspects of constraints satisfaction, we can conclude that the proposed DNN approach is capable of satisfying more than 93% of the constraints. In particular, the DNN is a function approximator that can automatically find the relation between the input and output. During training process, the value of cost function is not able to reach zero. In other words, the training errors cannot be completely eliminated. Hence, the gap between the optimal solution and the output of the DNN may exist, because of which the QoS constraints cannot be strictly satisfied.

The probabilities of the QoS constraints not satisfied in the test dataset versus different transmit power.

The probabilities of the QoS constraints not satisfied in the test dataset versus different capacity requirements.
Conclusion
In this article, we proposed a DNN-based resource allocation design to maximize the secrecy rate in a NOMA network. We first formulated the problem and solved it through conventional convex optimization approach. Then, we developed the DNN-based approach, where the cross-entropy cost function is utilized to incorporate the power allocation constraint without additional operations. Simulation results were provided to evaluate the performance of our proposed DNN approach. We demonstrated that the proposed approach has the capability to achieve no less than 95% secrecy rate performance with no more than 1% computational time in comparing with the benchmark convex optimization approach.
Footnotes
Handling Editor: Yanjiao Chen
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Nature Science Foundation of China under Grant no. 62101080, in part by the Science and Technology Research Program of Chongqing Municipal Education Commission of China under Grant nos KJQN202100738 and KJQN202000703, in part by the Natural Science Foundation of Chongqing under Grant no. cstc2021jcyj-msxmX0017, and in part by the Research Start Up Funding of Chongqing Jiaotong University under Grant nos 2020020070 and XJ2021000501.