
Abstract
Wargaming is a key component of military strategic decision-making, providing a means to explore human decision-making processes. However, the military frequently depends on scarce wargaming expertise to ensure the quality of wargames. In this context, we examine the potential of large language models (LLMs) to produce useful texts that support wargaming activities. Contrary to previous studies unfavourably juxtaposing LLMs as decision-makers to their human counterparts, we focused on the potential use of these models for generating wargaming components. We conducted a study with wargaming experts to compare the effectiveness of human-created texts and LLM-generated texts across various tasks within the wargaming lifecycle. For all wargaming tasks for which the LLM-generated texts could be compared to the human-created texts, the LLM was able to match or even surpass human-level quality. This demonstrates that despite the dangers of LLMs when in the driving seat, even with minimal training, they can offer significant benefits in support of strategic wargaming, showing effective performance across multiple phases of the lifecycle. By reducing reliance on scarce wargaming expertise, LLMs can make wargaming more accessible. This allows the wargaming process to be more widely used within military strategic decision-making, ultimately enhancing the quality of human decision-making.
1. Introduction
In February 2022, when the Russian President Vladimir Putin ordered a full-scale invasion of Ukraine, most analysts believed that the Ukrainian government would quickly collapse in the face of the Russian military force. Russia’s strategy was based on the idea of a swift military operation that would encounter little resistance, decapitate Ukraine’s leadership, and seize major cities in a matter of days. This failed strategy represents a recent example of erroneous military strategic decision-making (MSDM), a complex process based on military intelligence and some form of scenario simulation typically referred to as wargaming. In general, the purpose of wargaming is to simulate the effects of complex MSDM, in order to obtain insights relevant for the formulation of tactics, as well as education and training. 1 Military interventions in modern history, such as those in Afghanistan, Iraq, Libya, and Syria, have been critiqued by some scholars as instances of strategic failures,2,3 and it is quite likely that next to the invasion of Ukraine, other events we are currently witnessing will provide additional instances.
The reason why MSDM does not always result in successful outcomes is due to it being a complex non-linear process with many uncertainties. Unlike, for example, decisions regarding operational efficiency, MSDM cannot be easily captured by means of quantitative models with the ability to forecast outcomes based on a limited number of known outcomes. Wargaming provides means to address the inherent complexity of military strategy, which makes it key to MSDM. It provides strategic military decision-makers with the possibility to explore unforeseen consequences 4 based on accurate data, diverse perspectives, a range of scenarios, and meaningful interactions between players. However, in practice, wargames are often conducted in a rush. Due to a lack of internal resources and experienced wargamers, military strategists typically depend on external providers to obtain wargaming insights. 5 Contrary to the goal of using wargames to discover new perspectives and innovative solutions, the resulting insights are limited and it has been pointed out that wargames suffer from a lack of imagination.
In this study, we explore the potential contribution of generative artificial intelligence (genAI), specifically large language models (LLMs), to improved wargaming capabilities of the military strategists. Since LLMs became widely available, several studies have explored their potential as decision-makers in military conflicts.6,7 Computer-based reasoning in wargames can result in nuclear outcomes, 8 something that is not likely to be the case when humans are involved. While it is possible to prompt LLMs to include more complex considerations including ethical preferences, 9 their outcome can be unexpected and include hallucinations. Moreover, when employed to simulate human players, they tend to escalate the conflict. 6 However, the design, development, and execution of wargames contain several other elements that could benefit from genAI. For example, they could be used to generate narratives, as well as means to overcome organisational biases in an attempt to identify black swan events. LLMs could thus increase the accessibility of wargaming and enhance the quality of wargames. Our research question is to what extent LLMs can perform specific tasks throughout the wargame lifecycle beyond player simulation, in support of MSDM.
2. Wargaming
Wargaming is a centuries-old proven method in dealing with the challenges of strategic decision-making.10,11 It allows for the investigation of the human decision-making process 12 not just in military settings but also in other areas that involve complex circumstances with several players, e.g., banking, trade, and disaster relief organisation. 10 It is also a valuable tool in the field of international relations, in general. Although theories of international relations must be able to explain phenomena and behaviour in the international and political realm and be able to aid policy, in practice, strategic decision-makers deal with all kinds of challenges, 13 such as incomplete information, dynamic scenarios, 14 and unbounded possibilities. Therefore, the decision-making in these domains often requires counterfactual logic, 15 enabling the generation of what-if scenarios. In fact, the generation of what-if scenarios is at the core of wargaming, emphasising its value for strategic decision-making.
We define wargames as a multi-agent dynamic simulation with predefined rules, in which human players are highly engaged through immersive and interactive scenarios that involve dilemmas, conflicting perspectives, and uncertainty. The players’ iterative decisions influence the unfolding events and the development of multiple narratives to derive insights informing decision-makers.16–18 Another fundamental element of wargames is control to ensure that the objectives of the game are met. These may have an educational, analytical, or planning purpose. An important component of the game is adjudication, which is the function of determining the potential outcomes of players’ decisions, selecting the one that is relevant, and then deciding what information to provide to the players. 19 Furthermore, wargames are used in a wider decision-making process. 17 Within that process, they are not a predictive tool, but they can be used to point out an ineffective plan. They allow for a better understanding of the array of possible outcomes. 1
The benefits of wargaming include the fact that players become engaged or immersed in a game (Perla and McGrady, 2011), 36 which allows them to both participate in and construct narratives. Wargames can also contribute to the required agility and resilience of military leaders. By exposing them to unexpected scenarios, it helps them become accustomed to handling surprises. This does not only prepare decision-makers to a specific situation but is also invaluable in the educational system of the military. 20 The development of wargaming can be used as an analytical method itself 10 and, when done correctly, wargames can provide insights into the beliefs rather than the decisions of players. They reveal the shortcomings of human decision-making 21 and represent a valuable research method in the field of international relations 16 and social sciences.22,23
There are multiple wargame categories, which can be placed on a continuum from a rigid to free ruleset. Rigid wargames are rule-based and rely heavily on calculations to resolve player actions. Matrix and seminar games are more open, both using story-telling to describe why something would happen, encouraging the exchange of ideas to gain understanding. 24 Because rigid games cannot incorporate the complexity, uncertainty, and ambiguity of strategic decision-making in rules and numbers, the more open-ended matrix games are more useful for the military strategic level.
The phases of the wargaming lifecycle can be defined as initiation, design, development, execution, and analysis, each containing numerous subtasks. The value of a wargame is in the analysis, while the execution depends on a rigorous design and development. One of the current shortcomings of matrix games is a lack of procedural and well-documented approaches to game design and development. 25 In general, matrix games require a considerable amount of experience and resources to develop and facilitate.
As in other fields, developments in data science are revolutionising military decision-making. When applying data science in the military decision-making process, strength and weaknesses of both humans and computers must be weighed in. 26 Clearly, humans outperform computers when it comes to tasks with high complexity. 27 Computers, however, do not suffer from fatigue, while human cognitive resources, such as attention, are easily depleted. They can process information much faster than humans. This is valuable, for instance, in the adjudication process in wargaming. In some high-level wargames, an adjudication team simply cannot adjudicate all the actions of all players in time because the time that high-level decision-makers have for the entire wargame is limited. AI-enabled adjudication could offer a solution by presenting adjudicators with a set of adjudicated actions, from which human adjudicators can choose to refine certain aspects (A.H. van der Hulst, February 2, 2024, p.c.). Air Commodore J.W. Westerbeek (Former Director Comprehensive Crisis and Operations Management Centre of NATO’s Strategic Headquarters.) (October 19, 2023, p.c.) also acknowledged the opportunities for data science when used for the analysis of the vast amount of data that can serve as input for military strategic wargames, which he considers as invaluable for NATO’s strategic headquarters’ transition into a warfighting command. In short, wargaming – and MSDM in a broader sense – may benefit from teaming up with AI, as pointed out in a recent overview. 28
Past research focused on the role generative AI could play as a wargaming agent, or in supporting a human agent, e.g., previous works29–31. This approach seems to deviate, however, from one of the basic tenets of both wargaming and international relations, namely that strategic decisions should be based on human reasoning. Importantly, AI-as-agent in the wider context of MSDM raises serious ethical concerns on issues like accountability, responsibility, and transparency. Therefore, in this study, we focused on the use of LLMs for other tasks in the wargaming lifecycle, addressing the scaling problem and limited resources available for wargaming.
3. Current study
Our research question is to what extent LLMs can perform specific tasks throughout the wargame lifecycle in support of MSDM. With that, we follow the recommendation to invest in narrow AI use cases for wargaming purposes. 28 We used an online survey to measure the differences in effectiveness scores of human-created texts (HCTs) and LLM-generated texts (LGTs) considering these tasks. Our assumption was that with suitable prompting, LGTs would be of higher quality than those generated by humans because they would be based on a more comprehensive body of knowledge.
We selected four tasks across the wargaming lifecycle to assess the performance of LLMs. In choosing these tasks, we prioritised activities centred on text generation. Accordingly, we excluded tasks that primarily require analytical reasoning (e.g., method selection) or quantitative analysis, in part because the state-of-the-art LLMs available at the time we designed the experiment did not perform well on such functions. At the same time, we deliberately prioritised tasks for which it was not clear a priori how LLM performance in this context would compare with human performance. This led us to exclude tasks such as text summarisation (e.g., during the wargaming analysis phase), where we expected LLMs to excel and therefore anticipated limited insight into comparative performance. We also excluded tasks related to decision support for wargaming agents due to the ethical concerns noted above. We, therefore, focused on the following tasks: 17
Our study contributes to the understanding of how AI performs in wargaming for other tasks than supporting or representing agents. In more general terms, it addresses the research gap considering the opportunities for data science in MSDM. 32 We also address the current dependency of high-level decision-makers on the scarce capacity of experience and expertise for the design and development of military strategic wargames. In addition, to the best of our knowledge, we are the first to provide a quantitative method for assessing the quality of wargaming texts and LLM performance in wargaming. This research may benefit not only the decision-maker at the military strategic level but also wargame designers, developers, and facilitators. Below, we first describe our research methods, followed by the results of the experiment, a discussion and conclusion. The survey was conducted in accordance with relevant guidelines and regulations.
4. Methods
4.1. Design
The experiment consisted of four sessions, where in three of the sessions, we explored the wargaming tasks Scenario, Briefing, and Adjudication. We compared the perception of LGTs for these tasks to those created by human experts in the original CONTESTED wargame (see Figure 1). In the fourth session, we asked the participants to evaluate LLM-generated Game Design, one related to a real-world event and the other one based on a fictitious scenario. For the LLM-generated material, we prompted ChatGPT in a specific manner that we tested through several iterations (see Annex A for more information on the prompts). To collect participant responses, we created an online survey distributed among wargaming experts, with two examples per task offered in a randomised manner. For the Scenario, Briefing, and Adjudication tasks, respectively, each participant was presented with one LLM-generated and one human-generated variant. For Game Design, the participant would evaluate one real-world and one fictitious-scenario variant. Participant judgement was collected with the help of the variable Effectiveness, which consisted of several subcomponents: Comprehensiveness, Fidelity, Immersion, and Relevance.
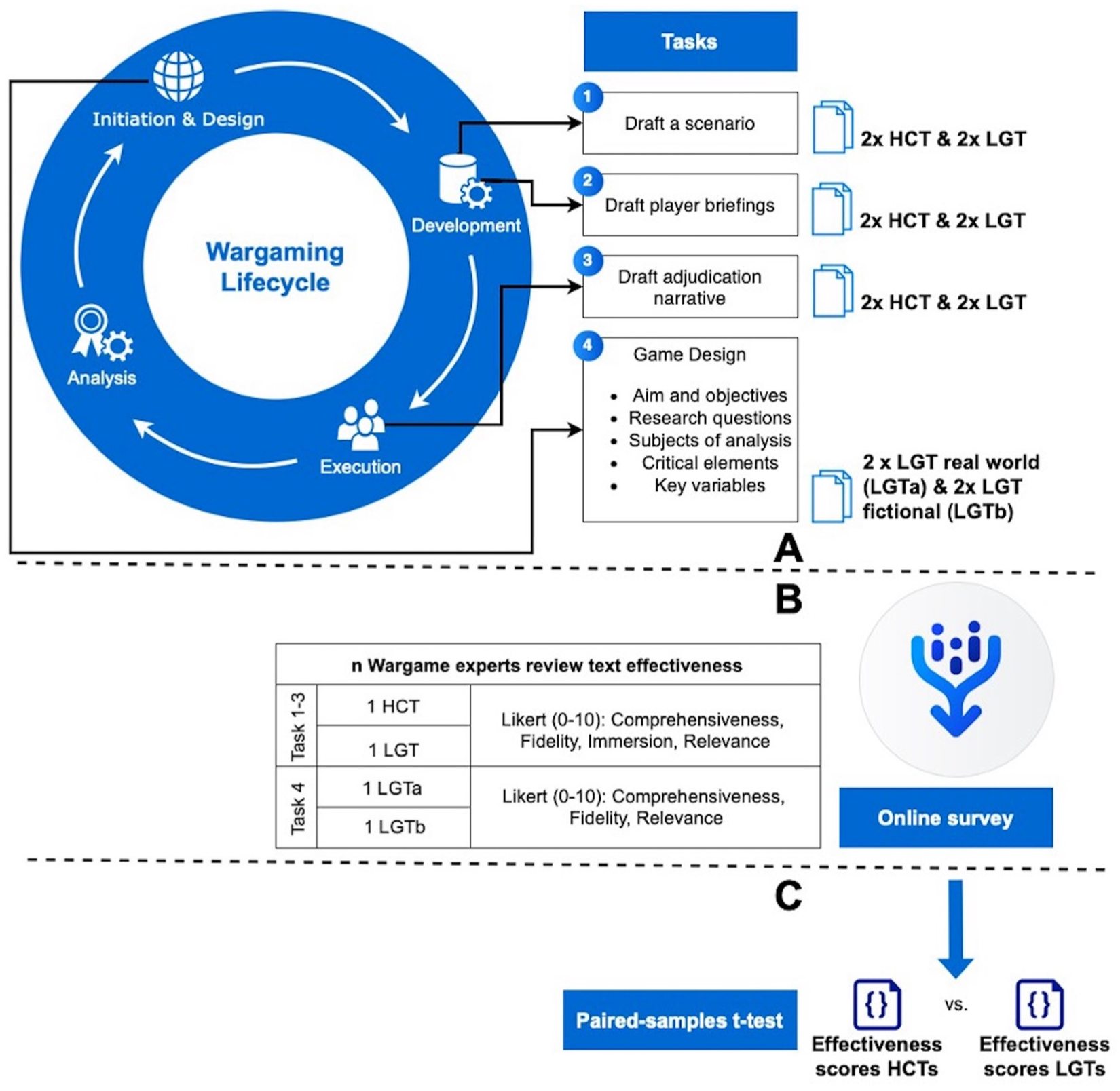
Overview of methods.
4.2. Participants
The survey was distributed with the help of two online fora, well known in the wargame community: https://groups.io/g/SimulatingWar and https://paxsims.wordpress.com/, in addition to the attendees of the MORS Wargaming in the Eastern Pacific Workshop in 2024. Of the 68 respondents who accessed the survey, 41 did not provide any response. The remaining 27 completed the survey, and their responses were included in the statistical analysis. All of these 27 participants stated that they had prior experience in wargaming, with 13 of them having over 10 years of experience.
4.3. Materials and instrumentation
The survey was administered with the Qualtrics software. Instructions and material were presented in English. To create the survey materials, ChatGPT 4.0 was used due to its capability to include retrieval-augmented generation (RAG), which allowed us to provide the LLM with contextual material. This material included a baseline example of the strategic matrix game CONTESTED, developed by the UK Defence Science and Technology Laboratory (DSTL). Given the experience and expertise of DSTL’s Defence Wargaming Centre, one of the organisations facilitating quality wargames to the military, it is reasonable to assume that the game is of sufficient quality. For example, CONTESTED was developed to mitigate some of the limitations of traditional matrix games, such as a high reliance on assumptions when both the players and the adjudicators lack knowledge on a certain issue. 33
We tasked the LLM to generate output for the following goals: (1) draft a scenario, (2) draft player briefings, (3) draft an adjudication narrative, and (4) a game design.
The fourth goal included formulation of the aim and objectives of a wargame, the research questions, subjects of analysis, critical elements, and key variables.
Prompt engineering, the practice of designing and structuring inputs, is crucial in acquiring accurate results using LLMs. We used RAG to let the LGTs be faithful to the principles and structure of the baseline examples, and also to provide additional information on real-world events. The prompts were improved iteratively. The length of the LLM outputs, for instance, could not be restricted by means of simple verbal instructions but required an explicit directive to the model to use a Python script to enforce the word limit. All prompts were tested repeatedly in new chats to avoid the bias of single-shot prompts. 34 The final versions of our prompts are presented in Annex A.
The subcomponents defined to measure effectiveness were the following:
This multi-item measurement of the dependent variable 37 was assessed to be valid by three independent wargaming experts we interviewed in preparation of the survey.
In scoring the items, participants were asked to use an 11-point Likert-type scale, reducing the chance for skewed distributions. 38 We used the following anchor points: 0 = not at all, 5 = acceptable, 10 = extremely. For the quantitative analysis, the survey responses were converted to a scale ranging from 1 to 11. In addition, participants were able to provide qualitative feedback for the texts they scored.
Prior to the statistical analysis of the results, we explored the relation between the subcomponents of the Effectiveness scale for each question in the survey separately. The reliability of the scale was very high with an average Cronbach’s alpha = .914 (Min = .789, Max = .964) for the four items measured on the tasks Scenario, Briefing, and Adjudication. The item ‘Immersion’ was not measured for the evaluation of the Game Design because the item addresses the involvement of players in the wargame. This concept is not relevant for the evaluation of the scope of the wargame as captured by the Game Design. The reliability of the scale on the remaining three items was high, with Cronbach’s alpha = .889 (Min = .789, Max = .939). For the purposes of the analysis, we thus averaged the scores for the scale subcomponents into a single value.
5. Results
To analyse the perceived Effectiveness of LLM-generated versus human-generated texts in the Scenario, Briefing, and Adjudication tasks, we ran three separate paired samples t-tests with the conservative Bonferroni correction for multiple testing.
For the Scenario task, there was no significant difference between the LGTs (M = 8.14, SD = 2.16) and HCTs (M = 7.61, SD = 1.98); t(26) = 1.751, p = .09, Cohen’s d = .337.
For the Briefing task, the LGTs scored substantially higher (M = 7.40, SD = 2.41) than the HCTs (M = 5.22, SD = 2.47), and this difference was statistically significant; t(26) = 4.723, p < .01, Cohen’s d = .909. This effect size suggests that participants clearly perceived the LLM briefings as more effective than the human briefings.
We found a similar effect for Adjudication, t(26) = 3.521, p = .02, Cohen’s d = .691, with LGTs (M = 8.09, SD = 2.43) outperforming HCTs (M = 6.94, SD = 2.35). This difference was significant at the unadjusted level (p = .02 with α = .05) but did not meet the Bonferroni-adjusted threshold (with α = .017). Considering the effect size (d = .691), we consider the effect to be marginally significant.
The average scores of perceived Effectiveness on LLM-generated Game Design did not significantly differ for the real-world and fictional scenarios, t(24) = .976, p = 0.34, Cohen’s d = −.195. The means for the two groups revealed a high average score for both (M RealWorld = 8.23, SD RealWorld = 2.45; M Fictional = 8.56, SD Fictional = 1.81).
6. Discussion
In this paper, we address the question to what extent LLMs could perform specific tasks throughout the wargaming lifecycle in support of MSDM. For all tasks for which the LGTs could be compared to the HCTs, the LLM was able to match or even surpass human-level quality. In fact, in two out of three tasks (Player Briefings and Adjudication) for which the LGTs were compared to the HCTs, the LLM was able to generate texts of higher quality. These outcomes are substantiated by the qualitative feedback provided by the survey respondents. One of them stated that the LLM-generated scenario ‘was easier to follow and quicker to read than the first [human-created] scenario as the allegiances were more explicitly outlined’. Another respondent implicitly advocated for iterative human–machine teaming by stating the text was ‘an excellent rough draft. Depending on the requirement, I’d probably add a little more detail’. Some LGTs were appraised as ‘much more compelling’, ‘rich’, ‘very believable’, and ‘very immersive’. Multiple respondents addressed the comprehensiveness of the texts. Examples hereof are ‘the coverage of the issues is excellent’, ‘the only bit I would add would be a few socio-cultural dynamics. These tend to be sidelined in wargames, so I’m not surprised that they were omitted’, and ‘[it] is a pretty thorough summary of the aims, objectives, and level of detail’. On the contrary, this comprehensiveness is judged by some as ‘over ambitious’, so that ‘it would not be possible to actually design a single wargame that addresses all of these issues.’
At least from the perspective of wargaming experts, LLMs could thus be employed to speed up the wargaming process, for example, by creating the adjudication narrative (which is typically quite time-consuming). It could also be used to generate an initial draft on the potential aim and objectives of a wargame, the research questions, subjects of analysis, critical elements, and key variables. Such draft can inspire and direct conversations in the initiation and design phase of the wargaming lifecycle. In future studies, one could explore the possibility of having an adjudicator choose the players involved in a specific action and share the outcome of the adjudication process via a human–machine interface, while pre-programmed prompts operate on the back-end of the software to generate a unique and engaging narrative. The results reported here were achieved without any extensive modelling and structured prompt engineering. In fact, too much contextual information provided with the prompt degraded performance. It is therefore recommended to contextualise the LLM per specific task. Clearly, an LLM specifically trained for wargaming tasks in combination with structured prompt engineering is expected to perform even more effectively, emphasising the promise these results hold.
7. Conclusion
In conclusion, LLMs offer significant potential for strategic wargaming. This study shows that LLMs perform effectively throughout various phases of the wargaming lifecycle, even when not specifically trained for wargaming purposes. We proved that a commercial LLM – provided with adequate context material and well-structured prompts but without extensive modelling and rigorous prompt engineering – can already match human performance in certain tasks. In most cases, the LLM texts surpass human-level quality.
This capability of LLMs is of key importance to MSDM. Although wargaming will never prevent all strategic failure, it is a critical activity in MSDM to prevent as much of it. Currently, however, wargaming capability at the military strategic level is scarce. Reducing the dependency on scarce wargame development expertise, the use of LLMs contributes to the accessibility of the wargaming tool. In turn, this accessibility allows for the exploitation of the wargaming potential for MSDM and thus ultimately enhances human decision-making.
Furthermore, the use of LLMs can expedite every phase of the wargaming lifecycle. This allows the generation of wargaming texts at the speed of relevance, often invaluable in military decision-making. Even when the quality of initial LGTs would be insufficient, this can be compensated through human–machine teaming. Wargaming texts can be enhanced iteratively through the interaction of human experts and LLMs.
Our research contributes to both wargaming and military studies by pointing out that the integration of AI in wargaming, and MSDM in more general terms, is not limited to its role as an agent; its capacity to support human decision-making and enhance human–machine teaming is equally promising. In addition, this study provides a first quantitative method for assessing the quality of wargaming texts and LLM performance in wargaming. This opens opportunities for further research, for example, considering the utility of LLMs for other tasks in wargame development, execution, and analysis. Could, for example, an LLM be used to analyse which possible biases and assumptions led to certain decisions, contributing to the understanding of how a series of events unfolded during the game? Moreover, researchers could assess whether an LLM, specifically trained for military strategic wargaming, actually impacts real-world MSDM by providing or enabling valuable insights.
In summary, we have demonstrated that LLMs are highly effective in generating useful texts for wargaming purposes. While this is promising for further research, the strategic importance of wargaming for military headquarters suggests that integrating LLMs into this domain is not only promising but also demands increased investment in this area.
Supplemental Material
sj-docx-1-dms-10.1177_15485129261438519 – Supplemental material for Effective and responsible use of large language models in strategic wargaming
Supplemental material, sj-docx-1-dms-10.1177_15485129261438519 for Effective and responsible use of large language models in strategic wargaming by Herwin Meerveld, Henry Brighton, Roy Lindelauf and Marie Šafář Postma in The Journal of Defense Modeling and Simulation
Footnotes
Acknowledgements
We thank Mike Bagwell, Rikki Parsons, and Adam Lyons from the UK Defence Science and Technology Laboratory for their contribution to this research by sharing insights into the research design and providing all the necessary material of the CONTESTED wargame. The authors take full responsibility for the study design, data collection and analysis, the preparation of the manuscript, and the decision to publish. This work should not be seen as an endorsement or promotion of any real-world conflict, as the authors value peace among all nations and peoples.
Ethical approval and informed consent
This study was approved by the Research Ethics Committee of the Faculty of Military Science of the Netherlands Defence Academy (approval no. 20250109EthComFMW-02) on January 9, 2025. All participants provided written consent to participate in the study.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The survey data will be shared upon reasonable request.
Supplemental material
Supplemental material for this article is available online.
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.