
Abstract
In this article, I describe the
Introduction
The term “effect size” usually refers to the magnitude, and direction, of an association between two variables or the mean difference between two groups. Statistical tests that produce p-values indicate the probability that the observed result, or one more extreme, was due to chance alone. In contrast, effect sizes indicate the magnitude of the association between variables, or mean group difference. Such estimation is intended to help interpret the results and understand what they may mean in practical terms. For example, in a healthcare situation, an experimental treatment may result in a statistically significant difference in a symptom outcome between the experimental and control group. However, the treatment is unlikely to be useful in practice unless the magnitude of the difference is clinically meaningful—that is, one that makes a difference to the average quality of life of patients.
In relation to estimating a mean difference for a continuous outcome across groups, these methods are sometimes referred to as the “d” family. The average group difference described by an effect size could be applied to experimental data. In this situation, the mean value of an outcome of interest between a group of individuals randomized to either an experimental intervention or a control condition is compared and contrasted. In observational data, the mean value can refer to a mean intergroup difference in relation to a sociodemographic or other characteristic.
Effect sizes, relating to a mean group difference, can be described in the original metric of an outcome measure. However, these may not be easily interpretable. For example, the outcome may relate to an attitudinal questionnaire, with responses scored and summed according to a Likert scale. Some experts may understand what a difference of “five points” may mean in this situation, but many others would not. Thus, the term “effect size” often refers to such differences quantified in a standardized metric. The d family of estimators provides an effect size that is standardized according to the standard deviation (sd) (that is, square root of the variance) of the outcome of interest. All the d family of estimators assume that the outcome of interest is normally distributed, and thus, departure from this can introduce bias (Grissom and Kim 2001).
One of the most commonly used metrics of effect size is Cohen’s (1988) d. For Cohen’s d, standardization is performed according to the pooled SD for both groups being compared (see below). In general, the d family communicates effect size as the scaled difference between the means, divided by the SD of the outcome of interest. Here we see in the following equation that Cohen’s d is given by the difference in the means of the outcome between the two groups (
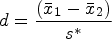
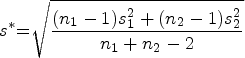
However, Hedges showed that Cohen’s d can be biased, especially when there are relatively small numbers of observations (for example, N < 20), and proposed a correction factor could be applied to d (Hedges 1981; Hedges and Olkin 1985). Let d represent Cohen’s d and m the summed total number of observations across groups (that is,
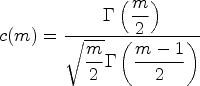
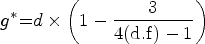
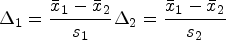
Irrespective of the method used, there are well-known rules of thumb for interpreting effect sizes. That is, effect sizes of 0.2 to 0.5 are usually regarded as “small/modest”, 0.5 to 0.8 as “medium sized”, and 0.8 or above as “large sized”. However, these interpretations will need to be contextualized. For example, in healthcare it is for stakeholders and experts (patients and clinicians) to agree on what magnitude of difference may be considered to constitute a clinically meaningful effect size. Moreover, from an economic perspective, cost effectiveness of an intervention may not be achieved even with an effect size that is classed as “large” in this context. Thus, it is important to understand the meaning and implications of an effect size within its specific substantive context.
Missing data may be present in both experimental design and observational studies. Analyzing data using listwise deletion may give biased results. It is also wasteful of the information available in the remaining values in the variables that are present in observations with one or more missing values. Thus, best practice when analyzing data with missing values is to use multiple imputation (van Ginkel et al. 2020; Sterne et al. 2009). This involves drawing plausible values for those missing from conditional probability distributions. These distributions are shaped by the relationship observed between the variables for which the values are nonmissing. These values are imputed for multiple datasets (usually five or more), and the results recombined. Such results are unbiased if the data are missing completely at random (that is, because of chance only) or missing at random (missing values depend on the observed values of variables) according to Rubin’s (1987) missing data mechanism classification. Indeed, even if the data are not missing at random (the missing values may depend on unobserved variable values), the results from multiply imputed data may be less biased than that derived from listwise deletion (van Ginkel et al. 2020). When recombining the results from multiply imputed data, one must account for the uncertainty introduced by the imputation process when deriving standard errors (SEs). Stata currently offers a wide range of analyses that work with multiply imputed data. These are invoked by using the command after the prefix
Rubin (1987) provided rules for how means and SEs (and hence confidence intervals) could be combined from results derived from multiply imputed datasets. Known aptly enough as “Rubin’s rules”, these are as follows.
To pool an effect estimate, such as the pooled mean difference
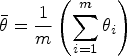
Pooling the SE for such estimates is more complicated and must account for the sampling variance both within and between the imputed datasets. The “within imputation variance” is the average of the mean of the within variance estimate. In effect, this is the squared SE calculated for each imputed dataset. This value reflects the sampling variance in each of the datasets generated by the multiple imputation process. Thus, as expected, this value will be relatively large in small samples and more modest in larger samples (Heymans and Eekhout 2019). It is given by the following equation, where VW is the within imputation variance:
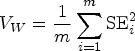
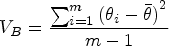
The miesize command
Syntax
varname is the outcome variable of interest. groupvar is a variable that defines the two groups that
The command returns a range of results in
Options
Stored results
If the

If the

All methods:
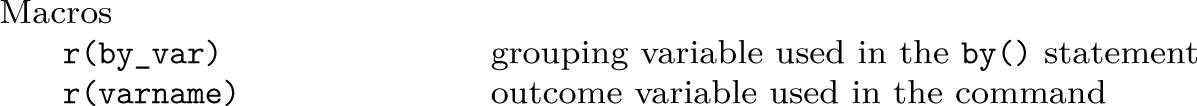
How to use miesize
The
The default for
where the varname is the outcome of interest and the groupvar is the group-identifying variable. Where a statistically significant difference between the variances for each group is present, it is likely to be more appropriate to use Glass’s Δ to report the effect size, rather than d or g. For Glass’s Δ, the two effect sizes (Δ1 and Δ2) are given relating to the SDs of the two groups. For experimental data, usually the SD for the control group is used when calculating Δ1. However, as stated earlier, for observational data, the choice of which of the group’s SDs to use appears arbitrary. For dummy-coded group variables (one or zero/absent or present), the group with “zero” status could be the one to have the SD used in calculating Δ1. However, in the absence of a compelling reason to consistently report a Δ value based on one or the other group’s SD, it has been recommended that both effect-size estimates (Δs) be reported for observational data (Kline 2013).
Example
For this example, an analysis of data used for evaluating the recruitment and selection process into UK-based general practice postgraduate medical training is used for illustrative purposes (Tiffin et al. 2024).
1
One aim of the analysis was to estimate effect sizes in relation to selection test scores for various demographic characteristics. Clearly, any substantial association with such personal qualities would influence the demographics of the population of doctors in training finally selected. In this context, there were complete data for the first stage of selection, which comprised a situational judgment test (SJT) and clinical knowledge assessment (the clinical problem solving [CPS] test). These scores are combined into a summed total that is used in the selection process. While all candidates had SJT and CPS scores, not all had received a standardized face-to-face selection center (SC) assessment. This was a special case of missing data by design. For some years, those who achieved only low combined scores on the SJT and CPS did not proceed to the SC stage. In addition, for some later years, candidates who had achieved relatively high combined SJT and CPS scores were exempted the face-to-face selection stage. Moreover, the face-to-face selection process was suspended completely during the COVID-19 pandemic. Overall, this means that SC scores were not present for around half the doctors in the sample with first-stage selection assessment scores. Thus, estimating the “true” underlying effect size for each demographic characteristic in relation to the scores for the face-to-face SCs required data imputation. This was performed in Stata using chained equations (Royston and White 2011). The estimates from the imputations stabilized after m = 5 imputations, but as a precaution, m = 10 imputed datasets were used. For this particular illustrative example, we will estimate the effect size of male gender on SC scores. Using the
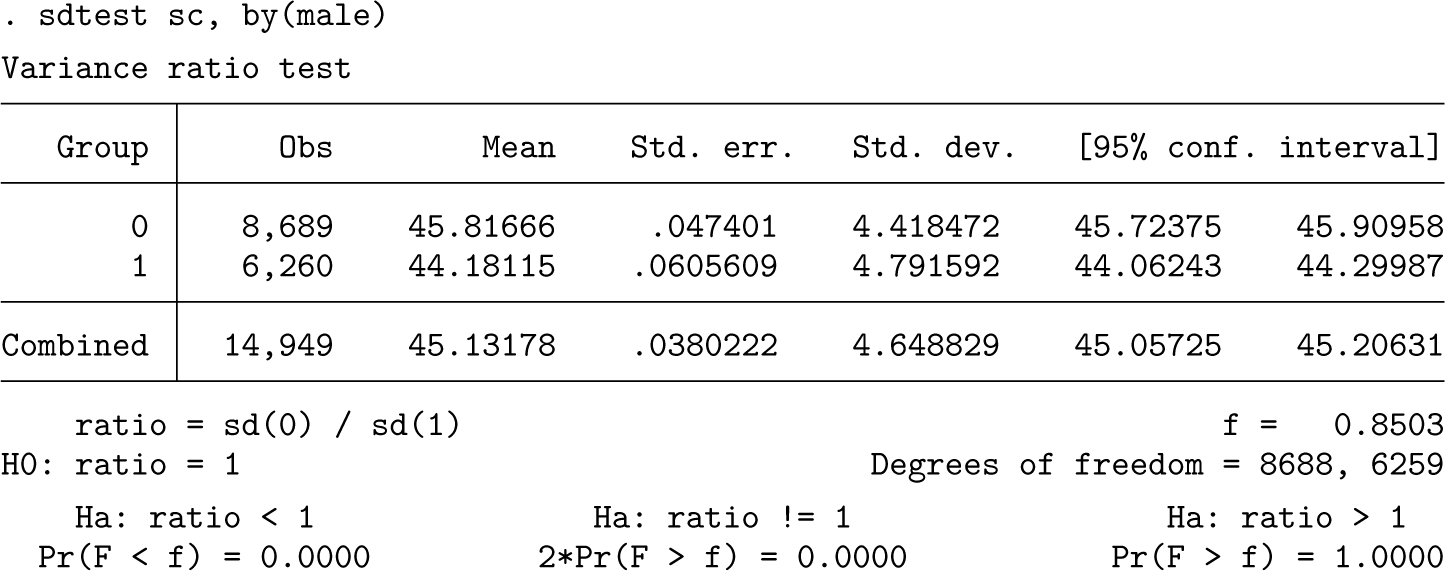
Because there is evidence of unequal variances between the groups, we will use Glass’s Δ to estimate the effect size using

As can be seen from the results, the effect size for male gender is around 0.40 (that is, commonly interpreted as “modest”). As expected, it varies slightly depending on whether the SD of the SC scores for males (0.40) or females (0.42) is used. We can compare our results with those obtained using the
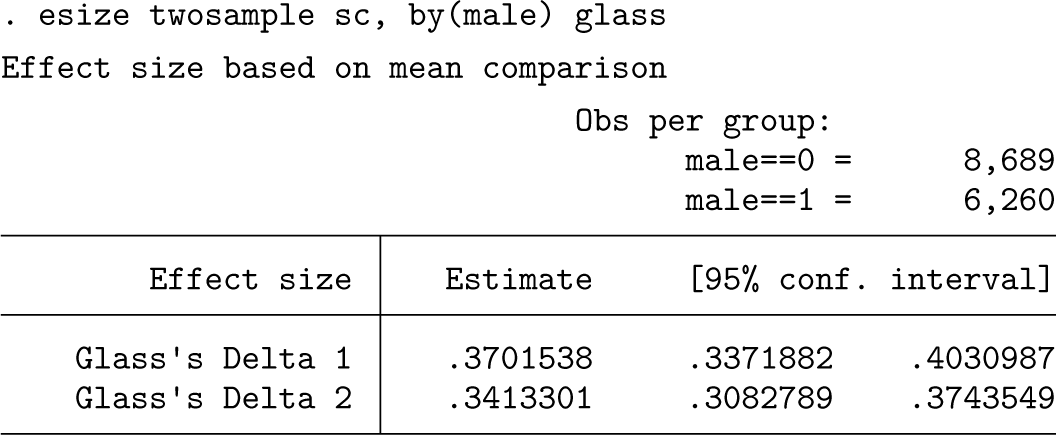
As might be anticipated, the effect sizes for gender are modestly smaller than those estimated from the imputed data. This is because certain candidates that scored either especially high or low on the first stage of selection tests will not have observable SC scores. Given that, in this sample, males, on average, achieve lower scores on the first- stage assessments, this will produce “indirect range restriction”. This in turn restricts the range of observable SC scores, especially for females. This effect attenuates the effect size observed, a well-recognized phenomenon in personnel selection studies. Indeed, multiple imputation has been shown to be one way of addressing this (Zimmermann, Klusmann, and Hampe 2017; Mwandigha 2017). Thus, the imputed values will offset this effect by simulating the unobserved SC scores. Note that, as expected, the confidence intervals for these effect sizes are slightly wider for the results derived by
Conclusions
The d family of effect size estimators calculates standardized mean group differences for continuous variables. The
Supplemental Material
Supplemental material
Supplemental material
Footnotes
5
Many thanks to Dr. Lewis Paton (the Hull York Medical School) for his feedback on an earlier version of this manuscript. I am also grateful to Drs. Nick Cox (Durham University) and Yulia Marchenko (StataCorp LLC) for feedback on an earlier version of the code for the
6
To install the software files as they exist at the time of publication of this article, type
Notes
About the author
Paul A. Tiffin is Professor of Health Services and Workforce Research at the University of York, UK, and a practicing adolescent psychiatrist.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.