
Abstract
In this article, we describe the
Keywords
1 Introduction
McFadden (1974) introduced the conditional logit model to explain individuals’ choice behaviors and to predict market shares of products and services. The conditional logit model forms the basis for most discrete choice models, which assume that individuals use a decision rule based on random utility maximization (RUM) when choosing among alternatives. In contrast, Chorus, Arentze, and Timmermans (2008) proposed an alternative decision rule known as random regret minimization (RRM), which assumes that decision makers aim to minimize regret when making their choices. McFadden and Train (2000) extended the random utility model by allowing the parameters to vary across individuals, leading to the so-called mixed logit model. Similarly, Hensher, Greene, and Ho (2016) extended the RRM models to include random effects, which account for preference heterogeneity and allow for correlation among choices made by the same individual. This article introduces the
There is a growing literature on empirical applications of RRM to various topics, including wildfire evacuation (Wong et al. 2020), students’ travel patterns (Anowar et al. 2019), healthcare choices (Boeri et al. 2013), and consumer choices (Chorus, Koetse, and Hoen 2013). Unfortunately, there is no clear guidance on how to choose between an RRM and a RUM model, and selecting the decision rule is, indeed, still an open question within the discrete choice literature. In practice, the decision rule is often selected using information criteria or the models’ predictive power, depending on the research objectives. Some researchers even tried to combine different decision rules into one model (Hess, Stathopoulos, and Daly 2012; Lim and Hahn 2020), which is a very promising research avenue and also one of the potential extensions of our own
One article that provides theoretical guidance on the effects of regret in the context of consumer psychology is Pieters and Zeelenberg (2007). The authors argue that regret becomes more relevant when consumers find the decision complex, important, or significant to themselves or their peers. Hence, the relevance of the regret is tied to the individuals’ perception of the choices they are making. Additionally, the empirical application of Lim and Hahn (2020) using regulatory focus theory (Higgins 1997, 1998) surveyed the individuals and gave them scores using the chronic regulatory focus index (CRFI), which is a continuous index that has two opposite profiles. On one hand, negative CRFI values are associated with “prevention-focused” consumers who value safety and security and are concerned about potential losses. On the other hand, positive CRFI values are associated with “promotion-focused” consumers who value the existence of positive outcomes and emphasize the rewards, focusing on the potential gains. Using the CRFI, Lim and Hahn (2020) found that “prevention-focused” consumers tended to behave more as regret minimizers and “promotion-focused” individuals tended to behave as utility maximizers. Hence, the individuals’ characteristics might also affect the intensity of the regret they are experiencing.
As mentioned, determining an individual’s decision rule is still an open question and, as of now, is generally selected by examining the model fit. However, regret-based models have additional behavioral components compared with their utility counterparts. For instance, regret-based models exhibit so-called semicompensatory behavior, meaning that the regret experienced by a given difference in attribute levels has more weight than the rejoicing obtained from the same attribute-level difference when comparing the alternatives in the choice set. As a consequence of the semicompensatory behavior of the regret models, the so-called compromise effect (Chorus and Bierlaire 2013) can be observed. Consequently, alternatives with more balanced overall performances across attributes are preferred to high-performing alternatives with potentially only one severely underperforming attribute. This is due to the semicompensatory behavior, by which the regret derived from this poorly performing attribute is not entirely compensated by the rejoicing of the high-performing ones. A detailed description of this behavior and a comparison of the semicompensatory behavior among different regret functions can be found in Gutiérrez-Vargas, Meulders, and Vandebroek (2021)
Both the RRM and the RUM models can be extended by allowing random coefficients to model heterogeneous preferences in the population. By doing so, we can model that not all individuals experience the same magnitude of regret (or utility) for a given attribute. We can estimate the distribution of the population’s regret coefficients, and afterward, using postestimation procedures, we can compute the individual-level regret parameters. This extension of the model results in so-called unobserved preference heterogeneity, where a parametric distribution captures the differences in taste across individuals that are beyond what we can do using the information on the sample (that is, interaction terms with individual characteristics). We refer to this random-coefficient regret model as the mixed RRM model. The mixed RRM has been used by Boeri and Masiero (2014) and Hensher, Greene, and Ho (2016) in the past using transport data. In both articles, the authors find that the mixed RRM has a slightly better model performance than mixed RUM models, which is not to say that this will always be the case, but it does show that in some contexts, regret-based models might outperform their utility-based models and that it is worth investigating them, especially if the modeler considers that the conditions presented in Pieters and Zeelenberg (2007) for a strong regret effect to hold are applicable.
The rest of the article is organized as follows. In section 2, we briefly introduce the classic RRM model, some of its properties, and its corresponding likelihood function. Section 3 introduces the mixed RRM model, which extends the classic RRM model by allowing for random coefficients. This section also comments on how the formulas presented in section 2 are updated to allow the inclusion of random parameters. It also presents the likelihood function of the mixed RRM model and introduces the maximum simulated likelihood estimation procedure that we use to maximize it. Section 4 describes the estimation of individual-level parameters after the estimation of the mixed RRM model, allowing us to find the regret-specific parameters for each individual in the sample. Section 5 describes the syntax of every command included in our package. Section 6 provides a comprehensive example of the usage of the package using discrete choice data from van Cranenburgh (2018), showing how to fit a mixed RRM model using the
2 Classical random regret models
On one hand, RUM models assume that individuals are utility maximizers when selecting an alternative from a discrete set of alternatives. On the other hand, RRM models assume that individuals are regret minimizers. Regret occurs when, compared with other available alternatives, the selected alternative is outperformed by the other alternatives in some attributes (Loomes and Sugden 1982). RRM models assume that individuals will choose the alternative that minimizes the random regret resulting from comparing their relative performance with the other nonchosen alternatives in the choice set. Formally, Chorus, Arentze, and Timmermans (2008) presented an initial model for RRM models, and Chorus (2010) modified the regret function to obtain a smooth likelihood function. Accordingly, he proposed the model in (1) to denote the regret of an individual n when choosing alternative i of the J possible alternatives.
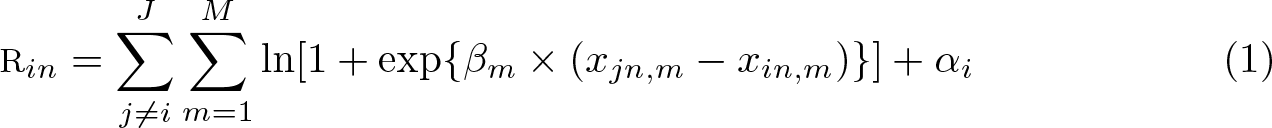
More specifically, (1) represents the regret that an individual (referred to by n) experiences when choosing alternative i out of J alternatives (referred to by j or i). Additionally, each alternative is described in terms of the value of M attributes (referred to by m). Consequently, xin,m represents the values of attribute m of alternative i for individual n, and βm is the taste parameter of attribute m that is shared by every individual n. The parameter βm indicates that with each unit increase in the difference between the attribute level of alternative i and the rest of the alternatives, regret would either increase (if βm is positive) or decrease (if βm is negative). Besides, we can include alternative specific constants (ASC) by simply adding them to the systematic part of the regret. The inclusion of the ASC serves the same purpose as in RUM models: to account for omitted attributes for a particular alternative i. As usual, for identification purposes, we need to exclude one of the ASC from the model specification, so we define
As with RUM models, we can obtain the random regret function, RR in , by adding an independent and identically distributed extreme-value type I error term to the systematic regret function R in to account for pure random noise and the impact of omitted attributes on the regret function: RR in = R in + εin. Mathematically, the minimization of the random regret function is equivalent to maximizing the negative function, which results in the conventional closed-form logit formula for the choice probabilities given in (2).

The log-likelihood (LL) function of the regret model for N individuals is given by (3), where

In the literature, there are several extensions of the classical RRM models. For instance, Chorus (2014) proposed the generalized RRM, which replaces the “1” in the regret function with a new parameter, γm, denoting the regret weight for attribute m. Additionally, van Cranenburgh, Guevara, and Chorus (2015) incorporated a scale parameter into the RRM, which is now referred to as µRRM. The pure RRM was proposed in the same article (van Cranenburgh, Guevara, and Chorus 2015) as a special case of µRRM when µ is arbitrarily small. For a review that compares the different types of RRM models and RUM models, see Gutiérrez-Vargas, Meulders, and Vandebroek (2021). In what follows, we will focus on the classical regret function of Chorus (2010) as described in (1) and allow for random taste parameters as introduced by Hensher, Greene, and Ho (2016). This model will be referred to as the mixed RRM model, which assumes a parametric distribution for the taste parameters.
3 Mixed RRM models
In this section, we describe the mixed RRM model, which has two major differences with respect to the classic RRM model. First, it includes random coefficients that follow a parametric distribution to model taste heterogeneity. Second, as we will explain in this section, the model can accommodate the presence of panel structure in the data. Introducing the parametric distribution for the taste parameters triggers a new subindex to the taste parameters vector,

Similarly, as in the classical RRM model, we add an independent and identically distributed extreme value type I error term to the systematic regret function, and we obtain the choice probabilities given by (5).

The probability of the entire sequence of observed choices of individual n (conditional on knowing

The unconditional choice probabilities of the observed sequence of choices are the conditional choice probabilities [see (6)] integrated over the entire domain of the distribution. Consequently, the LL function of the mixed RRM model is in (7).
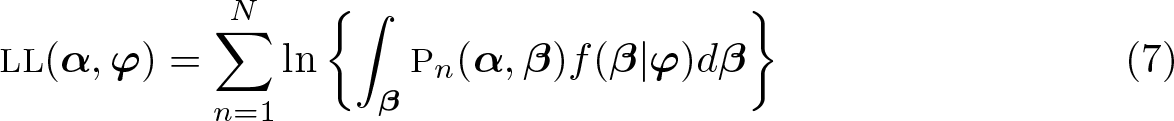
Given that the integral described in (7) does not have a closed-form solution, it is approximated using simulation (Train 2009). Accordingly, we fit the model by maximum simulated likelihood. We approximate the LL function by (8), where R is the number of draws and

4 Individual-level parameters
After maximizing the SLL function to obtain estimates for
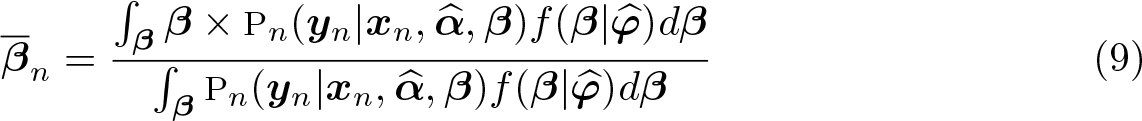
Again, because there is no closed-form solution for the integrals in (9), we approximate them using simulations yielding (10),
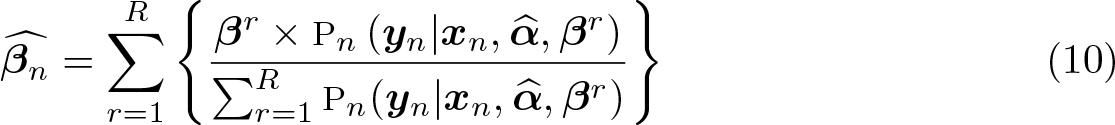
R is the number of draws, and
5 Commands
5.1 mixrandregret
Syntax

depvar equal to 1 identifies the chosen alternative, whereas depvar equal to 0 indicates that the alternative was not selected. There is only one chosen alternative for each choice set.
Description
Options
maximize_options are
5.2 mixrpred
Syntax

Description
Following
Options
5.3 mixrbeta
Syntax

Description
Options
6 Examples
To show how we can fit mixed RRM models using the
We follow the data setup in

Following the data manipulation in Gutiérrez-Vargas, Meulders, and Vandebroek (2021), we transform the dataset using the


We begin by fitting a classical RRM model using the


As expected, both parameter estimates are negative and highly significant, suggesting that regret decreases as the level of travel time or travel cost increases in a nonchosen alternative compared with the same attribute level in the chosen one. The coefficients are saved in
We then fit a mixed RRM model in which we let the coefficient for

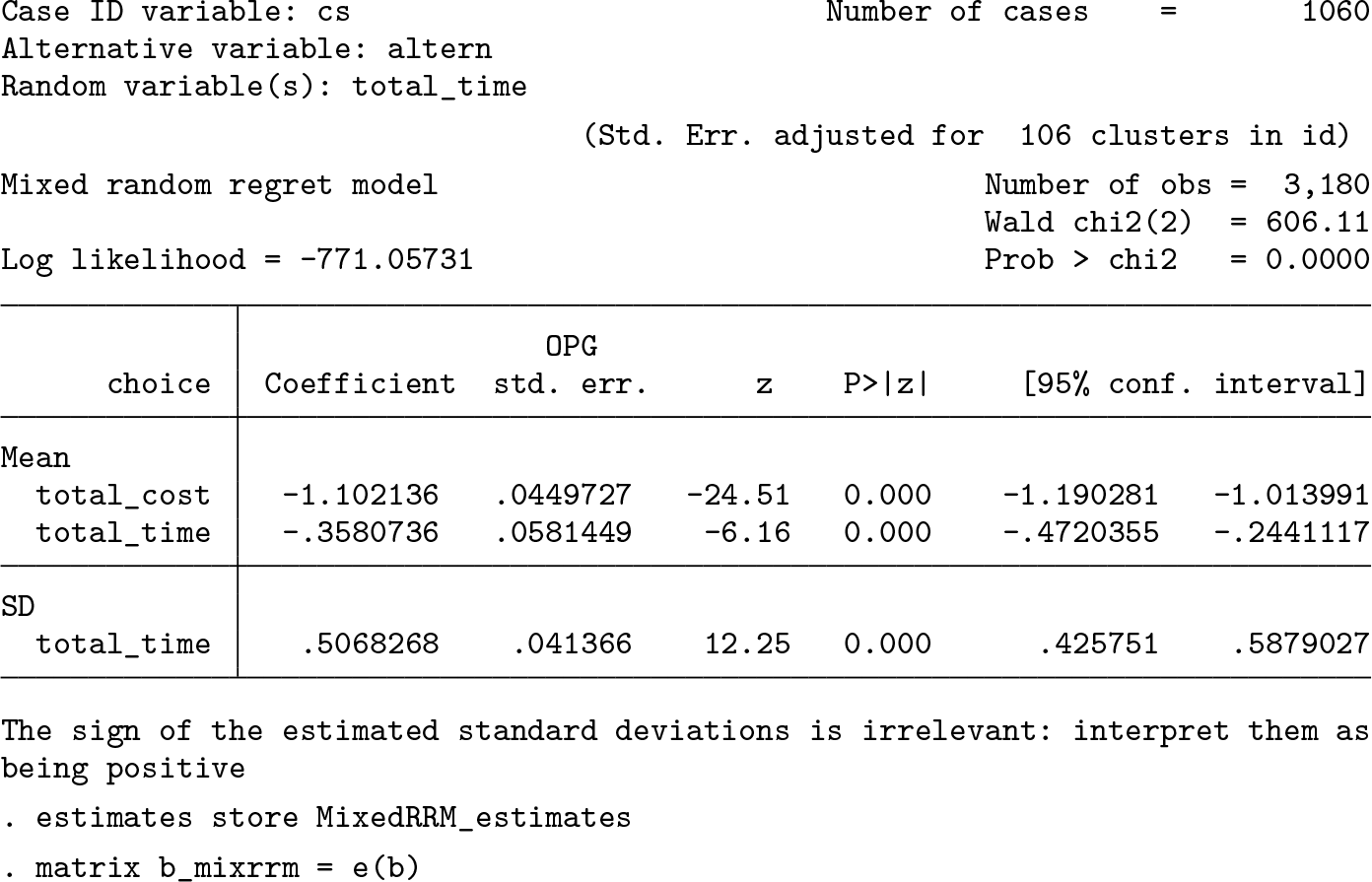
On average, the regret decreases as the total travel time increases in a nonchosen alternative, compared with the same level of travel time in the chosen alternative. The interpretation is similar for the total travel cost attribute. Additionally, we observe that the estimated standard deviation for the normal distribution of total travel time is significantly different from zero, which implies the existence of heterogeneity in the sample.
We can also perform a likelihood-ratio test to see whether the mixed RRM fits the data better than the previously fitted classical RRM model. It is crucial to notice that a standard deviation cannot be negative, and that by testing whether the standard deviation parameter is larger than zero, we are performing a statistical test with a null hypothesis in which the parameter is on the boundary of its parametric space. This is a well-studied problem in the literature of generalized linear mixed models (Verbeke and Molenberghs 2000), and we have to correct the distribution for the statistic under the null hypothesis using a mixture of χ2 distributions in which 50% of the probability mass is at 0 and the other 50% uses the conventionally used (uncorrected) χ2 distribution. This correction implies we must halve the p-values found using the uncorrected distribution. Notably, the correction described here is valid only when testing the inclusion of one extra random coefficient to the utility specification. However, details for the corrections needed when including more than one random coefficient can be found in Stram and Lee (1994) and Verbeke and Molenberghs (2000, sec. 6.3.4). Looking at the results of the likelihood-ratio test, we can see that we reject the null hypothesis even when halving the p-value. 2 Hence, the mixed RRM model does fit the data better than the classic RRM model. As an alternative heuristic procedure, Hensher and Greene (2003) suggested using a model with all attributes included as random and then inspecting whether the standard deviation parameters of the random coefficients are different from zero using t-test statistics.

After fitting the mixed RRM model, we can compute individual-level parameters using

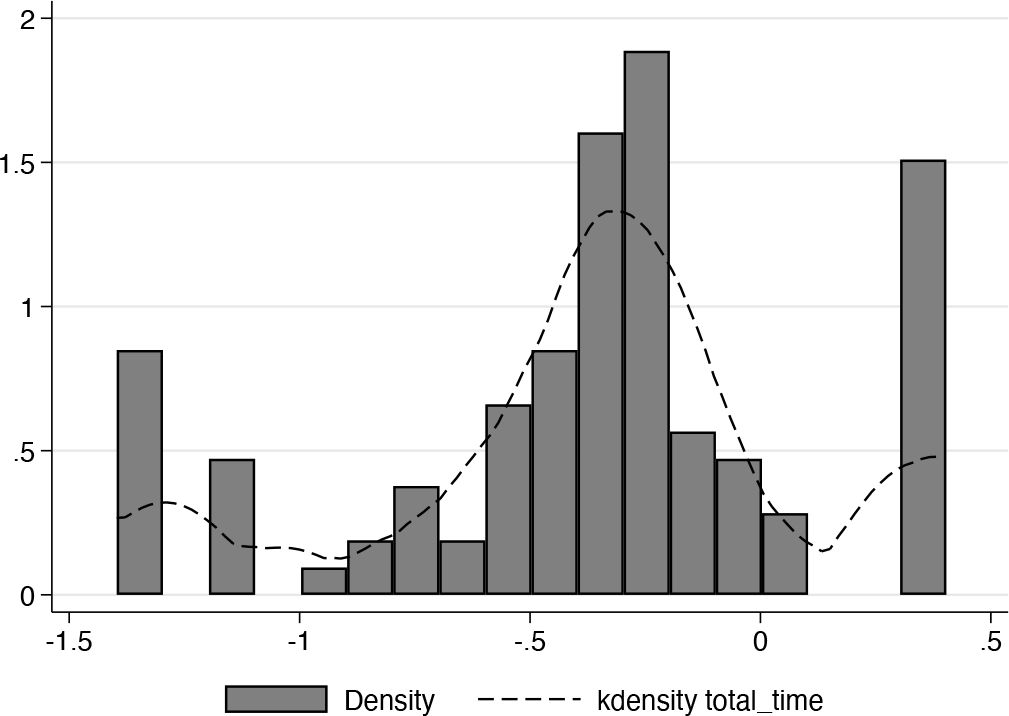
Distribution of total time coefficient (normal)
One solution to obtain nonpositive estimates for the


The estimated parameters correspond to the mean
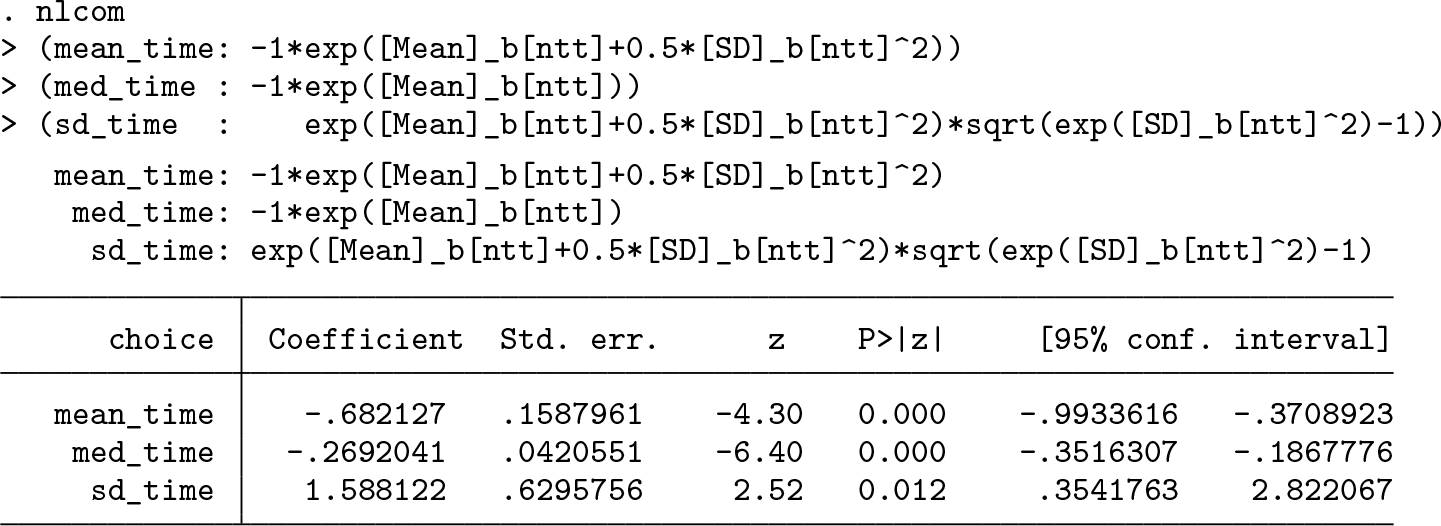
Again, we calculate individual-level parameters. As we can observe in the listed data and distribution presented in figure 2, all individual-level parameters are now negative as we expected.



Distribution of total time coefficient (lognormal)
After running


Additionally,


7 Conclusions
This article presented the
The package we presented in this article still has room for improvement, and the most critical current deficiency is its speed. Given that the model has to compute attribute-level differences, the computation time also increases considerably when the size of the choice set increases. One possible solution to this issue is to use Stata’s C++ plugin, which compiles a portion of the code in the C++ programming language and loads the results into Stata. Several extensions can be implemented to the presented package. First, the package can be extended by implementing mixed versions of the generalizations of the RRM models, namely, the γRRM (Chorus 2014), the µRRM, and the pure RRM models (van Cranenburgh, Guevara, and Chorus 2015). Besides, the package could include more distributions for the random coefficients, such as uniform, triangular, or restricted normals. Another avenue for further extending the command is to combine regret-based models with latent class (LC) models (Bhat 1997). LC models assume that there are several LCs present in the data and each class has different taste coefficients. Utility-based LC models are readily available in Stata using the commands
12 Programs and supplemental material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X241257802 - Fitting mixed random regret minimization models using maximum simulated likelihood
Supplemental Material, sj-zip-1-stj-10.1177_1536867X241257802 for Fitting mixed random regret minimization models using maximum simulated likelihood by Ziyue Zhu, Álvaro A. Gutiérrez-Vargas and Martina Vandebroek in The Stata Journal
Footnotes
8 Acknowledgments
We thank Michel Meulders, Jan De Spiegeleer, and the participants from the 2022 London Stata Conference for their helpful comments and constructive suggestions. Additionally, substantial portions of our programs were inspired by the book Maximum Likelihood Estimation with Stata, Fifth Edition by Jeffrey Pitblado, Brian Poi, and William Gould (2024). Finally, many of the previous checks to the data and the construction of the LL functions were greatly inspired by the ![]() ) commands.
) commands.
9 Funding
This work was produced while Álvaro A. Gutiérrez-Vargas was a PhD student at the Research Centre for Operations Research and Statistics at KU Leuven, funded by Bijzonder Onderzoeksfonds KU Leuven (Special Research Fund KU Leuven).
10 Conflict of interest
Ziyue Zhu, Álvaro A. Gutiérrez-Vargas, and Martina Vandebroek declare no conflicts of interest.
11 Contribution
Ziyue Zhu and Álvaro A. Gutiérrez-Vargas contributed equally to the article by developing the command and drafting the article. Martina Vandebroek critically commented on both the article and the command’s functionality.
12 Programs and supplemental material
To install the software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.