
Abstract
In this article, we describe the
Keywords
1 Introduction
Chorus, Arentze, and Timmermans (2008) proposed an alternative to random utility maximization (RUM) (Manski 1977) discrete choice behavior by introducing a family of models rooted in regret theory (Loomes and Sugden 1982; Bell 1982) called random regret minimization (RRM). Intuitively, RRM claims that individuals base their choices between alternatives on the desire to avoid the situation where a nonchosen alternative ends up being more attractive than the chosen one, which would cause regret. Therefore, individuals are assumed to minimize anticipated regret when choosing among alternatives, in contrast to utility maximization.
2 Early model
The model proposed in Chorus, Arentze, and Timmermans (2008) assumes that decision makers (referred to as n) face a set of J alternatives (referred to as i or j indistinctly), each alternative being described in terms of the value of M attributes (referred to as m). Therefore, the value of attribute m of alternative i of individual n is denoted by ximn
. When the decision maker n is choosing between alternatives, he or she aims to minimize the anticipated random regret of a given alternative i. Consequently, the regret of alternative i on attribute m of individual n will be described by

Finally, the anticipated random regret

3 Classical model
The major contribution made by Chorus (2010) is an elegant way to get rid of the two max operators on the attribute-level regret of the original version (Chorus, Arentze, and Timmermans 2008), which results in a nonsmooth likelihood function and triggers the need for customized optimization routines. Instead, in Chorus (2010), the new attributelevel regret is redefined by Ri↔j,mn = ln [1 + exp {βm × (xjmn − ximn )}]. Therefore, the deterministic part of the regret of alternative i of individual n is now described by (3):

The two most important differences are as follows. First, the exterior max operator is replaced by a summation over all the alternatives, meaning that the choice maker’s systematic regret considers not only the best nonchosen alternative as in Chorus, Arentze, and Timmermans (2008) but also the aggregate regret of all the others. Particularly, when the choice set is large, it does not seem quite reasonable to consider just one nonchosen alternative. Second, the replacement of the inner max operator has a mathematical justification because it is a continuously differentiable function that approximates the original max operator and will generate a smooth likelihood.
Following the same idea as in Chorus, Arentze, and Timmermans (2008), assuming that the random regret function (RR in ) also includes an additive i.i.d. extreme-value type I error term that captures the pure random noise and impact of omitted attributes in the regret: RR in = Rin +εin . Finally, we obtain the same well-known and convenient closed-form logit formula for the choice probability given by (4). The last model is referred to as the classical RRM and is one of the models implemented in the command.

3.1
as an approximation of
To illustrate how those two definitions of the regret differ from each other, a graph is presented in figure 1. The x axis represents the difference on an attribute m of two alternatives i and j for individual n, (xjmn − ximn ), and the y axis represents the regret (r) that this difference generates conditional on βm = 1.

Comparison of
In figure 1, we can see that Ri↔j,mn
is a smooth version of
Additionally, when two alternatives have the same level for some attribute, the corresponding regret is not 0 but is equal to ln(2) ≈ 0.69. Though counterintuitive at first glance, note that only differences in regret or utility matter for choice probabilities (Train 2009). Hence, they remain unchanged regardless of the inclusion of this constant in the systematic regret. This can be easily checked in (4).
4 Differences between RUM and RRM models
Before we introduce three different models that generalize the underlying paradigm of the classical RRM model, we describe some essential differences between RRM and RUM while getting more insights into the RRM model.
4.1 Semicompensatory behavior and the compromise effect
Probably the most remarkable difference with the RUM model is the semicompensatory behavior that is described by RRM models. To illustrate this, we show the Ri↔j,mn function with βm = 1 in figure 2, which describes the regret generated by attribute m when a considered alternative i is being compared with alternative j, as a function of the difference between the attribute values, that is, xjmn − ximn . Segments (A) and (B) in the figure represent the magnitude of rejoice and regret, respectively, on an equal difference of attribute levels of 2.5 units. As shown in figure 2, the regret is much larger than the rejoice at an equal difference in the attribute levels. We can also see that this discrepancy becomes larger for differences with higher attribute values due to the regret function’s convexity.

Semicompensatory behavior of Ri↔j,mn (3) conditional on βm = 1. Adapted from van Cranenburgh, Guevara, and Chorus (2015); reprinted with permission.
Conversely, in RUM models, linear specification of utility leads to a fully compensatory model, where the poor performance of one attribute could be compensated easily with a better performance in another attribute.
A consequence of the semicompensatory behavior of RRM models is the so-called compromise effect. Given that having an inferior performance in one attribute causes a large regret, RRM models tend to predict that alternatives with a relatively good performance in all the attributes will be preferred to alternatives with a fairly good performance in almost all attributes but a rather poor performance in just one attribute. The compromise effect has been discussed in detail by Chorus and Bierlaire (2013) and by Chorus, Rose, and Hensher (2013).
4.2 Taste parameter interpretation in RRM models
When it comes to interpretation of the RRM parameters, note that they cannot be compared with the utilitarian counterpart of RUM models. On one hand, parameters of RUM models are interpreted as the change in utility caused by an increase of a particular attribute level. On the other hand, parameters of RRM models represent the potential change in regret associated with comparing a considered alternative with another alternative in terms of the attribute, caused by one unit change in a particular attribute level. For instance, an attribute that exhibits a positive and significant coefficient suggests that regret increases as the level of that attribute increases in a nonchosen alternative compared with the level of the same attribute in the chosen one.
5 Extensions of the classical RRM model
5.1 Generalized RRM
The generalization proposed by Chorus (2014), namely, the generalized random regret minimization (GRRM) model, replaces the number 1 in the attribute-regret function (3) with a new estimable parameter γ m ∊ [0, 1], which represents the regret weight for a particular attribute. Chorus (2014) proves that depending on the value of the parameter γ m
, we can recover RUM behavior (γ m
= 0) or the classical RRM behavior (γ m
= 1), showing that GRRM is a generalization not only of the classical RRM model but also of RUM models. In our
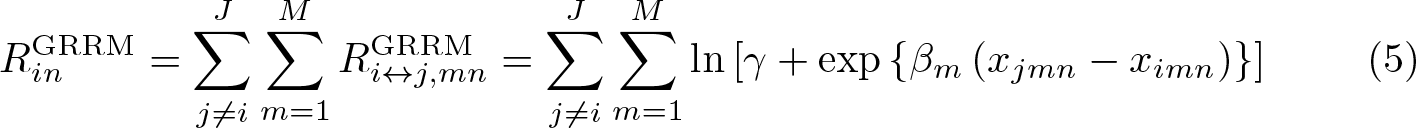
When an additive type I extreme-value i.i.d. error is added to the systematic regret function in (5), we obtain the random regret expression for the GRRM model:

An illustration of how different values of γ affect the shape of the attribute-level regret function

As before, we have asymmetries regarding regret and rejoice produced by the difference in an attribute level. However, in the GRRM model, γ controls the convexity of
5.2 µRRM
van Cranenburgh, Guevara, and Chorus (2015) present a new generalization of the classical RRM model that is linked to the scale parameter of the RRM model. They show that the classic regret function (3) is not scale-invariant. This property, which at first seems unfortunate, has been shown potentially useful to obtain more flexibility and also, as we will see later, for providing insights related to the observed regret in the data.
The first model proposed by van Cranenburgh, Guevara, and Chorus (2015) is the socalled µRRM model. In particular, this model is capable of estimating the scale parameter µ, which is linked to the error variance as var(εi
) = (π
2
µ
2
/6). In this new model,the attribute-level regret function is described by

Interestingly, in this model, we can estimate the scale parameter µ, which is well known to be nonidentifiable in the RUM context because only differences in utility matter. However, as we mentioned earlier, RRM models can describe a semicompensatory behavior, meaning that regret and rejoice do not cancel out entirely, allowing identification of the µ parameter.
As before, an additive type I extreme-value i.i.d. error term is added to the systematic regret function in (7) to obtain the random regret expression for the µRRM:

van Cranenburgh, Guevara, and Chorus (2015) claim that the size of µ in the µRRM model is informative of the degree of regret imposed by the model or, stated otherwise, how much semicompensatory behavior we are observing in the decision maker’s choice behavior. Given that the taste parameter βm
is divided by the scale parameter µ, then the larger the value of µ, the smaller the ratio βm/µ and therefore the smaller the regret. Conversely, the smaller the value of µ, the bigger the ratio βm/µ and therefore the larger the regret. This behavior is illustrated in figure 4, below, where we plotted different
Figure 4 shows that for arbitrarily large values of µ, the regret function becomes flatter, with the obvious consequence that the semicompensatory behavior of the model vanishes when µ tends to infinity. A formal proof of such a behavior is provided by van Cranenburgh, Guevara, and Chorus (2015), where the authors show that the µRRM model collapses into a linear RUM model when µ goes to infinity.

On the other hand, when the value of µ is arbitrarily small, the µRRM model represents the strongest semicompensatory behavior possible among the RRM family models. This scheme is explained in the following section.
Finally, in this model, note that the convexity of the attribute-level regret function
5.3 Pure RRM
The second model proposed by van Cranenburgh, Guevara, and Chorus (2015) is a particular case of the µRRM model that is generated by arbitrarily small values of µ in the µRRM model. As explained earlier, small values of µ mean that the ratio βm/µ is very large, causing the regret function to yield very strong differences between regrets and rejoices. This can be seen graphically in figure 4, where the smaller the value of µ, the larger the slope of the regret function within the regret domain.
Interestingly, the authors formally proved that for µ going to 0 in the µRRM model in (7), the model collapses into a linear specification (van Cranenburgh, Guevara, and Chorus 2015, appendix D). The authors call the resulting model the pure-RRM (hereafter PRRM) model, which describes the strongest semicompensatory behavior of all RRM models. The specification of systematic regret imposed by the PRRM model is presented in (9) and (10):


From (10), we can see that the PRRM model can be understood as a traditional logit model using transformed attribute levels. Notice here that to estimate the PRRM, we need to know the sign of the attributes a priori. In some situations, this requisite is not very restrictive. For instance, in transport contexts where the alternatives are mainly described in terms of its travel time (tt) and total cost (tc), we can expect the coefficients β tc and β tt to have negative signs, given that cheaper and faster routes are preferred to costlier and slower ones. The negative sign can be understood in terms of regret as follows: when the total time (total cost) in nonchosen alternatives increases, our regret decreases, given that the chosen alternative becomes relatively faster (cheaper).
Finally, adding the usual additive i.i.d. type I extreme-value error as in the previous models to the systematic regret in (9), we obtain the random regret of the model:

6 Alternative-specific constants
The inclusion of alternative-specific constants (ASC) in the presented models is possible by simply adding them into the systematic part of the regret. To exemplify this, let

7 Relationships among the different models
In figure 5, we present the relationships among all the presented models. Solid arrows state that a model collapses onto another model for a specific value of some parameter. For instance, we can see the connection between the classical RRM model and the GRRM model when γ = 1. On the other hand, dotted arrows indicate that the choice probabilities and the likelihood of two models are the same, but not necessarily the estimated parameters. For instance, Chorus (2014) showed that the relationship among RUM and RRM parameters is described by

Interrelationship among the models based on parameters
The relationships in figure 5 allow us to use a likelihood-ratio (LR) test to compare nested models and check which model fits the data best. In particular, table 1 lists the relevant hypotheses with the corresponding LR statistic and the asymptotic distribution of the test. The first column lists the models that we can compare based on a particular parameter. The second column lists the formal hypotheses for the relevant parameter. The third column presents the LR statistic in each case, where ℓ(·) represents the log likelihood of the model and
LR test for model comparison

The
Additionally, it is worth mentioning that the presented asymptotic distributions of the LR test are only valid when no robust or cluster corrected variance–covariance matrices are applied. If said corrections are used, a Wald test should be applied instead. This test can be straightforwardly implemented using the postestimation command
8 Robust standard errors
The use of robust standard errors corrected by cluster in discrete choice models is a common practice given the panel structure that is created when an individual answers multiple-choice situations in state-preference surveys. To illustrate this, we can write our maximum-likelihood estimation equations as in (13). Where θ is the full set of parameters,

We can compute the robust variance estimator of θ using (14), where D = −

Equation (14) is appropriate only if the observations are independent. However, when the same individual answers several choice situations, we can expect some degree of dependency. When such a structure is present in the data, a more appropriate robust variance estimate is given by (15), where Ck contains the indices of all observations belonging to the same individual k for k = 1, 2,…, nc , with nc being the total number of different individuals present in the dataset.

Appendix A provides details on the analytical form of the scores by each model presented in this article. Additionally, the
9 Commands
9.1 randregret
9.1.1 Syntax
9.1.2 Description
9.1.3 Options
maximize_options:
9.2 randregret_pure
9.2.1 Syntax
9.2.2 Description
9.2.3 Options
9.3 randregretpred
9.3.1 Syntax
9.3.2 Description
9.3.3 Options
10 Examples
To show the use of the
English translation of first choice situation

The following variables will be used in our specifications of
The data setup for

Given that


After the data manipulation, we can fit the four different RRM models that the command
We start with the classical RRM that uses (3) as systematic regret. To obtain such a model, we need to specify

However, given that we observe multiple answers from each individual in the presented data, we need to correct our standard errors considering this panel structure. We can easily cluster our standard errors across individuals by using the

To fit the GRRM model, we simply need to declare
Because γ must lie between 0 and 1, the optimization uses an ancillary parameter with a logistic transformation during the optimization procedure: γ = exp(γ*)/{1 + exp (γ*)} = logit
−
1(γ*) = invlogit(γ*), where γ* is an unbounded ancillary parameter. Normally, γ* is hidden from the output, but it can be shown using the option


Finally, using

From the

On the other hand,

Even though both ways are asymptotically equivalent, in finite samples they are likely to differ. Moreover, the way used by
Additionally,
The µRRM model can be obtained by typing

The resulting

Additionally,
Finally, the PRRM model can be fit using the

As mentioned in the footnote of the output,
Additionally, for the sake of illustration, we will also fit the PRRM model using
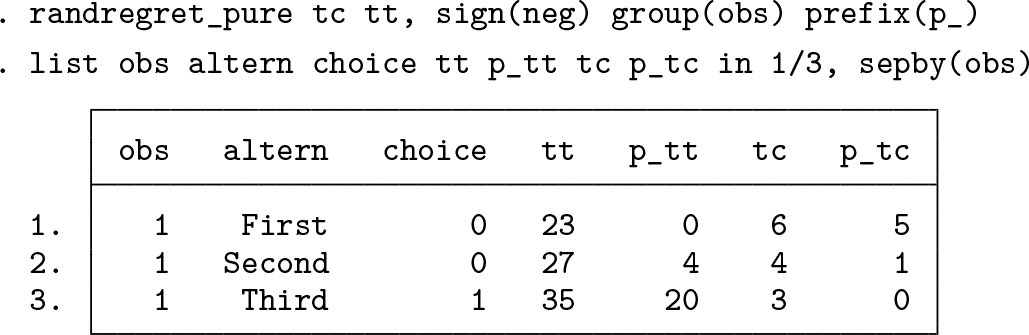
To further illustrate the process of generating the new attributes, we will follow the calculations in (10) to obtain the transformed attribute (
The new transformed attribute

It is worth mentioning that
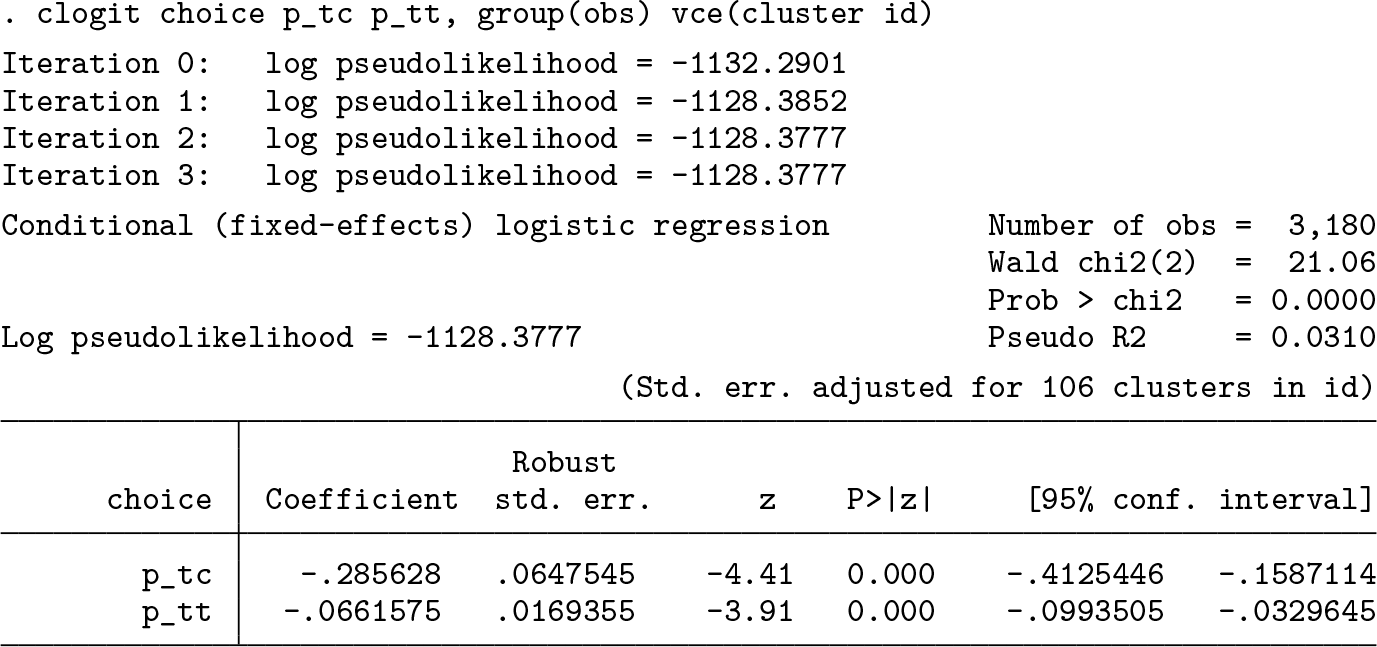
As we mentioned earlier,

To generate predictions, we can invoke

11 Conclusions
We presented the
Supplemental Material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211045538 - randregret: A command for fitting random regret minimization models using Stata
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211045538 for randregret: A command for fitting random regret minimization models using Stata by Álvaro A. Gutiérrez-Vargas, Michel Meulders and Martina Vandebroek in The Stata Journal
Footnotes
12 Acknowledgments
We thank Caspar Chorus, Sander van Cranenburgh, and an anonymous referee for helpful comments and constructive suggestions. We also thank the participants from the 2020 London Stata Conference and 2020 Swiss Stata Users Group meeting for many useful comments and suggestions. Additionally, special thanks from the first author to Valeria Córdova and Mauricio Armijo for their valuable comments on earlier stages of this project. Much of the code, particularly the combination of a Mata evaluator together with the ![]() ).
).
12.1 Funding
This work was produced while Álvaro A. Gutiérrez-Vargas was a PhD student at the Research Centre for Operations Research and Statistics (ORSTAT) at KU Leuven funded by Bijzonder Onderzoeksfonds KU Leuven (Special Research Fund KU Leuven).
12.2 Contribution
Álvaro A. Gutiérrez-Vargas developed the command and drafted the article. Michel Meulders and Martina Vandebroek critically commented on both the article and the command’s functionality.
12.3 Conflict of interest
Álvaro A. Gutiérrez-Vargas, Michel Meulders, and Martina Vandebroek declare no conflicts of interest.
13 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
A Technical appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.