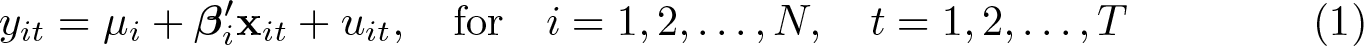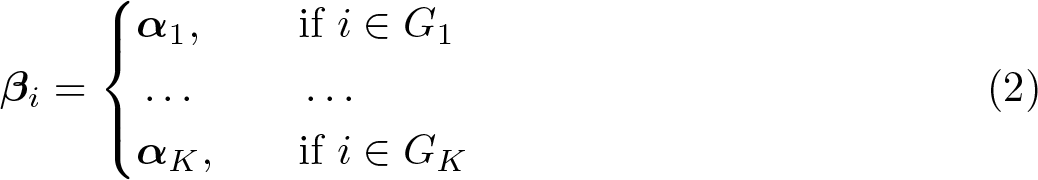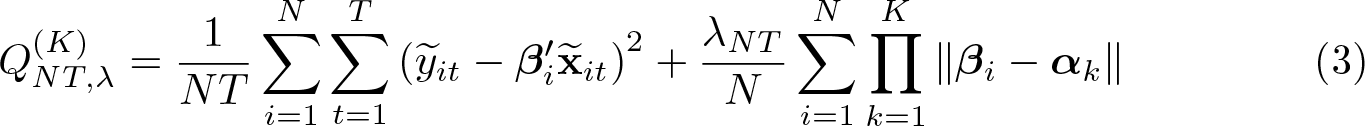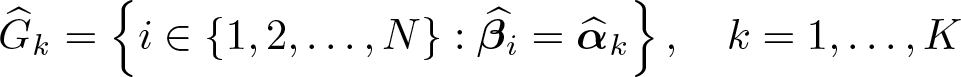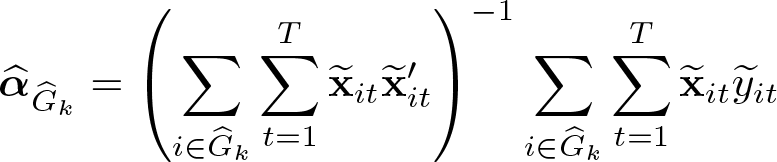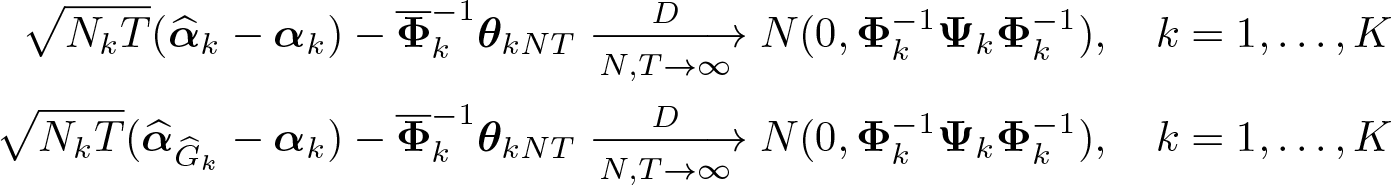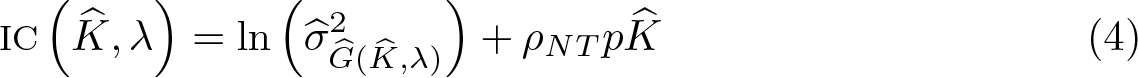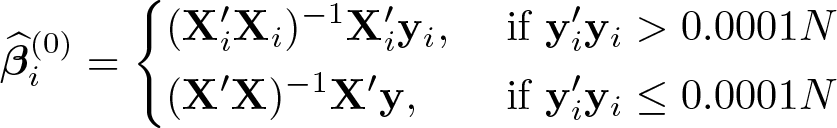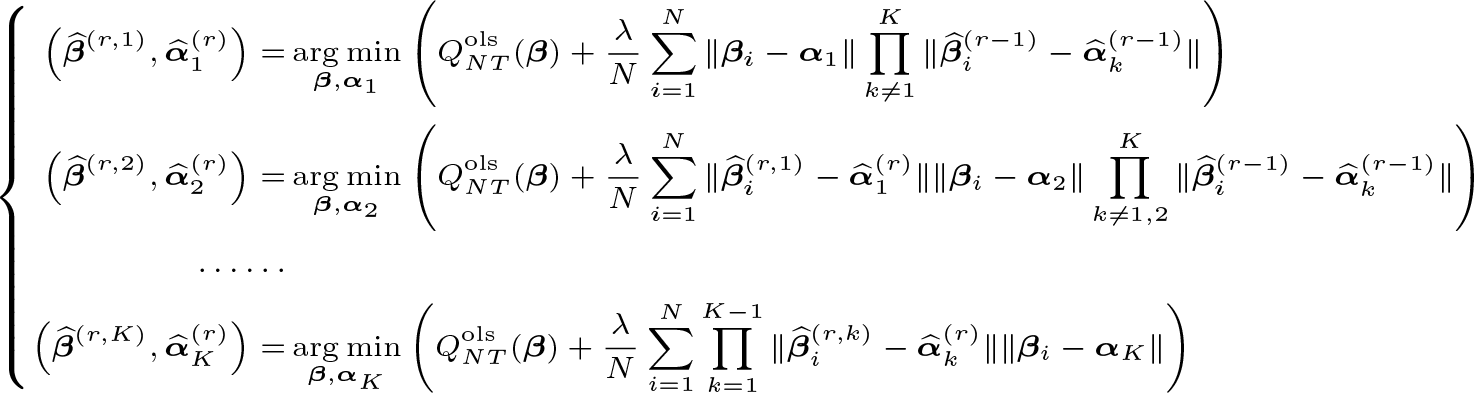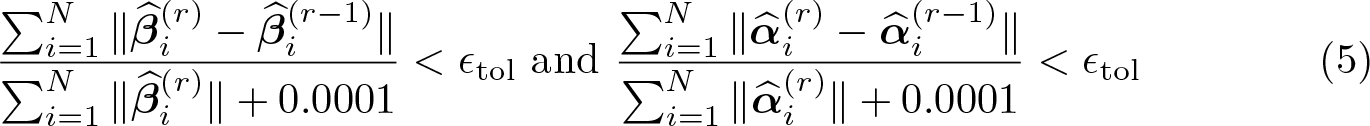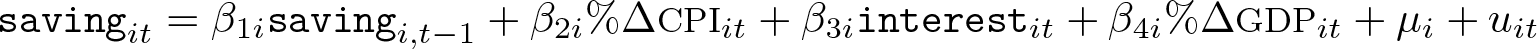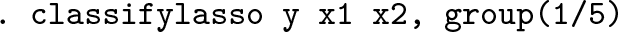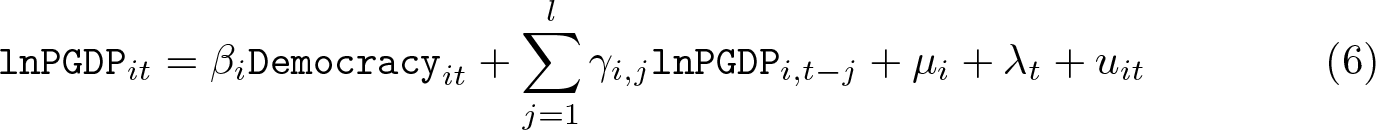In this article, we introduce a new command, classifylasso, that implements the classifier-lasso method (Su, Shi, and Phillips, 2016, Econometrica 84: 2215–2264) to simultaneously identify and estimate unobserved parameter heterogeneity in panel-data models using penalized techniques. We document the functionality of this command, including 1) penalized least-squares estimation of group-specific coefficients and classification of unknown group membership under a certain number of groups; 2) two lasso-type estimators with robust standard errors, namely, classifier-lasso and postlasso; and 3) determination of the number of groups based on an information criterion. We further develop some postestimation commands to display and visualize the estimation results.
Unobserved parameter heterogeneity has received increasing attention in both econometric theory and empirical studies (for example, Bonhomme and Manresa [2015]; Su, Shi, and Phillips [2016]; Eicher and Leukert [2009]; and Campello, Galvao, and Juhl [2019]). Conventional panel-data models assume either common slope coefficients or complete heterogeneity to facilitate estimation and inference. But validating these assumptions requires prior knowledge of economic models, which is most likely unavailable or unknowable to researchers. Therefore, recent theoretical works focus on unobserved parameter heterogeneity of unknown extent. Panel-data models with latent group structures where parameters are homogeneous within a group and heterogeneous across groups stand out. Two main approaches have been proposed to detect such group structures in panel-data models, namely, the clustering algorithm and the shrinkage method (for clustering algorithms, see Phillips and Sul [2007]; Bonhomme and Manresa [2015]; Sarafidis and Weber [2015]; and Carter, Schnepel, and Steigerwald [2017]; for shrinkage methods, see Su, Shi, and Phillips [2016]; Qian and Su [2016]; and Huang, Jin, and Su [2020]).
Several community-contributed commands deal with unobserved heterogeneity in different dimensions for empirical use. For instance, Bersvendsen and Ditzen (2021) introduce the xthst command to test slope heterogeneity; Lee and Steigerwald (2018), Du (2017), and Christodoulou and Sarafidis (2017) provide commands or packages like xtregcluster, clusteff, and psecta to study clustered data with latent group structures. However, all of these commands rely on clustering algorithms, such as the kmeans algorithm, and are sensitive to the initial partition and iterative process. We take the initiative to design a new command based on shrinkage techniques, namely, the classifierlasso (c-lasso) method, to fill the blank of latent group identification and estimation in Stata. This method is available in MATLAB and R (Gao and Shi 2021).
In this article, we illustrate how to fit panel-data models with latent group structures using Su, Shi, and Phillips’s (2016) novel c-lasso estimation method using a new command, classifylasso, that is developed for the Stata environment. The c-lasso method simultaneously identifies and estimates unobserved slope heterogeneity in paneldata models without preassuming any explicit group structures. The core of the c-lasso method is to minimize a penalized objective function that combines an additive multiplication penalized term with the conventional least-squares function. The command classifylasso generates two lasso-type estimators, the c-lasso and postlasso estimators, which enjoy good theoretical properties. Additionally, when the number of groups is unknown, an information criterion is provided to select the number of groups consistently. The practitioners can either select the number of groups using the built-in option provided or determine the number of groups under the guidance of economic theories and treat it as an input. Simulation results show good finite-sample performance of the estimation results generated by classifylasso, which is compatible with the theoretical results in Su, Shi, and Phillips (2016).
We further provide a collection of postestimation commands to display and visualize the estimation results. Specifically, classoselect determines the active result; predict generates new variables containing group membership, fitted values, and residuals; estimates replay displays and exports the coefficient table; classocoef visualizes the coefficients in graphs; and classogroup plots the group selection information. The implementation of these postestimation commands are illustrated in an empirical replication of Su, Shi, and Phillips (2016) and an application motivated by Acemoglu et al. (2019).
The remainder of this article is organized as follows. Section 2 lays out the econometric framework and describes the estimation procedure. Section 3 presents details of the classifylasso command, and section 4 introduces the postestimation commands. Section 5 reports Monte Carlo simulation results. Section 6 empirically studies the potential unobserved group heterogeneity in the relationship between democracy and economic growth using the classifylasso command and compares the results with Acemoglu et al. (2019). Section 7 concludes.
2 Econometric framework
In this section, we lay out the econometric framework of panel-data models with latent group structures and discuss the estimation procedure.
2.1 Panel-data models with latent group structures
Consider the linear panel-data model
where yit is the dependent variable, xit is a p×1 vector of independent variables, uit is the idiosyncratic error term with zero mean, and µi is the individual fixed effect. We further denote and as the dependent and independent variables after concentrating out the fixed effects.
Our main interest is the p × 1 vector of slope parameters, βi, which is assumed to follow an unknown group pattern as follows:
K is the number of latent groups, αk denotes the vector of slope parameters of the kth group satisfying αj ≠αk, j ≠ k, and Gk denotes the set of members in group k satisfying and Gj ∩ Gk = ∅. That is, the coefficients are heterogeneous across groups and homogeneous within a group.
Let and . A penalized least-squares (PLS) objective function is developed to consistently estimate α, β, and the group membership Gk’s.
Before proceeding to the methodology, we emphasize several important assumptions required to achieve good theoretical properties of the estimators. First, both N and T are assumed to be large. Second, each group is assumed to have an asymptotically nonnegligible number of individuals, that is, Nk/N → τk ∊ (0, 1), where is the number of panel units in group Gk.
Moreover, the group-specific parameters satisfy the “beta-min” assumption, which states that min1≤k<l≤K ||αk −αl|| ≥ cα > 0. This assumption indicates that the true coefficients are significantly different across the groups. Leeb and Pötscher (2005, 2006) and Pötscher and Leeb (2009) provide theoretical explanations on the inconsistency and nonnormal distribution of postselection estimators in the absence of the beta-min assumption. Simulation studies, such as the one by Drukker and Liu (2022) using nonlinear lasso models, further demonstrate the importance of this assumption. Belloni, Chernozhukov, and Hansen (2014) and Chernozhukov et al. (2018) discuss postselection estimators that do not require a beta-min assumption, resulting in a shift toward not imposing such an assumption. Recently, several commands have been developed to provide postselection estimators without necessitating the beta-min assumption, such as the dsregress, poregress, and xporegress commands for linear models, along with their counterparts for logit and exponential mean models. Additionally, communitycontributed packages offering causal inference without the beta-min assumption can be found in Ahrens, Hansen, and Schaffer (2020), Ahrens et al. (2024), Drukker and Liu (2023), Drukker and Liu (Forthcoming), and Hirukawa et al. (2023).
The assumptions above ensure uniform classification consistency in large samples and thus the asymptotic behavior of the c-lasso and postlasso estimators. Other regularity conditions are omitted because of the space limitation; see Su, Shi, and Phillips (2016) for a detailed discussion.
2.2 Penalized least-squares estimation
We follow a three-step procedure to estimate α. First, we construct a PLS objective function and obtain the c-lasso estimator given a fixed number of groups. Second, we obtain the postlasso estimator to achieve inference results and conduct bias corrections if needed given the estimated group membership. Lastly, an information criterion is constructed to determine the number of groups. The details are as follows:
Step 1. (C-lasso estimation) Given the number of groups K, the PLS objective function is constructed as
where λNT is a tuning parameter. The penalty term is a novel mixed additive multiplication form that shrinks the parameters of similar individuals to the same group. The c-lasso estimators and are obtained by minimizing the above objective function; see (3). The membership of group k is then given by
According to assumption A2(i) in Su, Shi, and Phillips (2016), the tuning parameter λNT should satisfy TλNT /(ln T )6+2v → ∞ and λNT (ln T )v → 0 for some v > 0 as (N, T ) → ∞. The conditions hold if λNT ∝ T−α for any α ∊ (0, 1/2). In our command, we set λNT = cλT −1/3 with a default cλ = 0.2. The simulation results in Su, Shi, and Phillips (2016) are robust when cλ = {0.1, 0.2, 0.4, 0.8, 1.6}.
Because the objective function in (3) is not convex in β, a numerical algorithm is developed to calculate the estimation result; see details in section 2.3.
Step 2. (Postlasso estimation) Given the estimated group results in step 1, the following postlasso estimators can be obtained:
The c-lasso and postlasso estimators obtained from steps 1 and 2 have the asymptotic properties
where , , and .
The above consistency results strongly rely on the beta-min assumption. In other words, if the group-specific coefficients are different but not distinct enough, many individuals will be inaccurately classified, leading to inconsistent estimation results. In section 5, we discuss the violation of beta-min assumption numerically.
The term is also critical to the consistency of . For example, in the static panels, we presume that xit is strictly exogenous, so θkNT = oP (1) and are consistent. However, in the dynamic panels, xit contains lagged dependent variables, so is inconsistent. In the latter case, we correct the estimation bias through Dhaene and Jochmans’s (2015) half-panel jackknife method.
The theoretical results in Su, Shi, and Phillips (2016) indicate that and are asymptotically equivalent and both enjoy the oracle property. Despite this, in practice the postlasso estimator is commonly favored over the c-lasso estimator because of its superior performance in finite samples, as well as its beneficial smaller bias (as also noted in remark 4 by Su, Shi, and Phillips [2016] and Belloni and Chernozhukov [2013]). Consequently, we advise users to rely primarily on postlasso estimates. We have set the postlasso estimates as the default display in the command and also present these estimates in the subsequent simulation and empirical studies.
Step 3. (Determination of the number of groups) In practice, the number of groups K might be unknown. Replacing K in (3) with , we allow the dependency of , , and on and λ such that , , and , and we obtain the postlasso estimator as . Then the number of groups can be obtained by minimizing the information criterion
where and ρNT is the tuning parameter. Su, Shi, and Phillips (2016) demonstrate that with the beta-min assumption and a proper convergence rate of the tuning parameter, the information criterion determines the correct number of groups with probability approaching 1 (w.p.a.1).
According to assumption A5∗ in Su, Shi, and Phillips (2016), in the case of linear models, the tuning parameter ρNT should satisfy ρNT → 0 and , where δNT = N1/2T1/2 if xit is exogenous and min(N1/2T1/2, T ) otherwise. Monte Carlo simulations in Su, Shi, and Phillips (2016) and Lu and Su (2017) both indicate that ρNT = cρ(NT )−1/2 with cρ = 2/3 works well in the linear models.
2.3 Iterative algorithm
We now introduce the numerical algorithm to be used in the aforementioned step 1 in section 2.2.
Step 1.1. (Initial estimates) The classifylasso command starts with initial and . Here 0pK×1 denotes a pK × 1 zero matrix, and
where yi and Xi are a T × 1 vector and a T × p matrix that denote the dependent and independent variables of individual i and , . If the variation of the dependent variable of individual i is large enough, the initial value is set to its time-series estimation result; otherwise, the pooled panel one is used.
Step 1.2. (Conditional minimization) Suppose we have obtained and at the rth iteration, r ≥ 1. Let , and
We hence obtain and .
Step 1.3. (Convergence criterion) The iterative algorithm ends if r = Rmax or
where Rmax is the maximum number of iterations and ϵtol is the tolerance level. Let R be the largest number that meets the above criterion, so and .
3 The classifylasso command
The command classifylasso estimates (1)–(2) using the c-lasso and selects the number of groups according to (4). The command records the iteration process, displays the estimation table, and stores results in e() form. Postestimation commands are designed to further manipulate these results; see section 4. This section documents the syntax and functionalities of the classifylasso command. The panel structure must be declared by xtset or tsset beforehand. Commands reghdfe (Correia 2014) and ftools (Correia 2016) are required to treat with fixed effects.
3.1 Syntax
The syntax of the classifylasso command is as follows:
where depvar is the dependent variable, that is, yit in (1), and indepvar is a list of independent variables, that is, xit in (1).
3.2 Options
grouplist(numlist) specifies the possible number (list) of latent groups, that is, K in (2) or ’s in (4). The default is grouplist(2).
lambda(#) specifies the constant cλ in the tuning parameter λNT = cλT−1/3 of the PLS objective function in (3). The default is lambda(0.2).
rho(#) specifies the constant cρ in the tuning parameter ρNT = cρ(NT )−1/2 of the information criterion in (4). The default is rho(0.67).
tolerance(#) specifies the tolerance criterion for convergence in the iterative algorithm, that is, εtol in (5). The default is tolerance(0.01).
maxiterations(#) specifies the maximum level of iterations in the iterative algorithm, that is, Rmax in (5). The default is maxiterations(20).
optimize_options control the optimize package. optptol(#), optvtol(#), optnrtol(#), optmaxiter(#), and optignorenrtol(string) determine the convergence criterion; their defaults are 1e-6, 1e-7, 1e-5, 150, and "off", respectively. opttechnique(string) and optsingularHmethod(string) determine the optimization algorithm and singular method; their defaults are "bfgs" and "m-marquardt", respectively. See [M-5] optimize( ) for more details.
absorb(varlist) specifies the categorical variables that identify the fixed effects; the default is to absorb the individual fixed effects identified by the panel (unit) variable.
noabsorb suppresses the fixed effects.
vce(vcetype) specifies the standard error type in postlasso estimation, which includes types that are derived from asymptotic theory (ols, the default), that are robust to some kinds of misspecification (robust), and that allow for intragroup correlations (clusterclustvar); see [R] Estimation options.
dynamic applies Dhaene and Jochmans’s (2015) half-panel jackknife method to conduct bias corrections in dynamic models.
notable suppresses the estimation table.
display_options control the display style. They include noci, nopvalues, noomitted, vsquish, noemptycells, baselevels, allbaselevels, nofvlabel, fvwrap(#), fvwrapon(style), cformat(%fmt), pformat(%fmt), sformat(%fmt), and nolstretch; see [R] Estimation options.
3.3 Stored results
classifylasso stores the following results in e():
3.4 Implementation example
In what follows, we illustrate how to use the classifylasso command to implement estimation in Stata. We show the estimation process here and postpone the postestimation part to section 4.6. The output of our command is the same as that in Su, Shi, and Phillips’ (2016) empirical study of the determinants of savings through a balanced panel of 56 countries from 1995 to 2010.
The regression model is
where i and t denote the country and year indices; the dependent variable saving is the ratio of savings to gross domestic product (GDP); the independent variables include one lag of the dependent variable saving, consumer price index (CPI)-based inflation rate %ΔCPI, real interest rate interest, and GDP growth rate %ΔGDP; µi is the individual fixed effect; uit is the idiosyncratic error. The data used are stored in saving.dta, provided with the article files.
The following codes implement the c-lasso estimation. We first import the data and declare the panel and time variables. Then we use the classifylasso command to identify latent group structures. We follow Su, Shi, and Phillips (2016) to set the tuning parameter cλ = 1.5485, use the dynamic panel, and select the group numbers from 1 to 5.
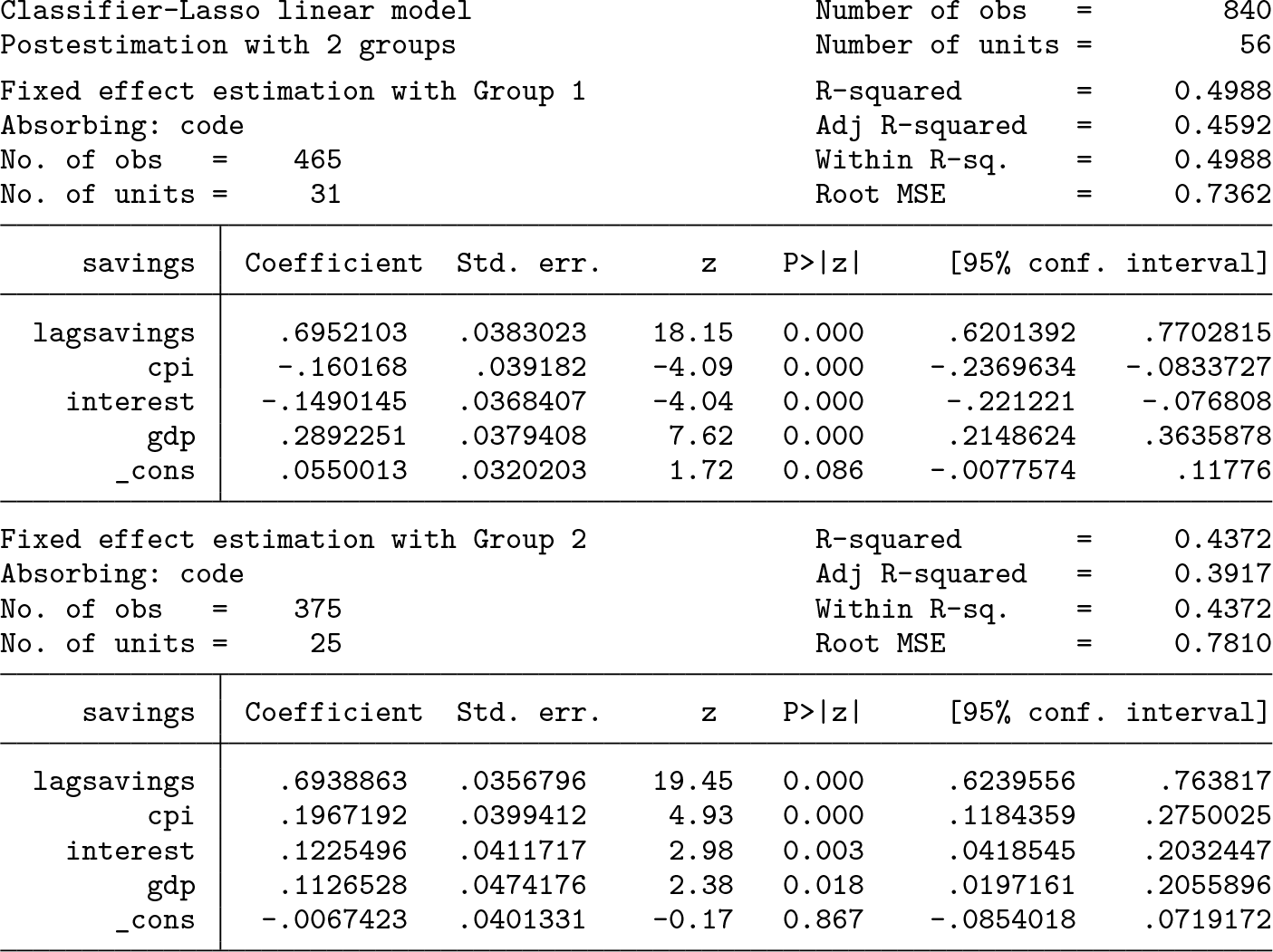
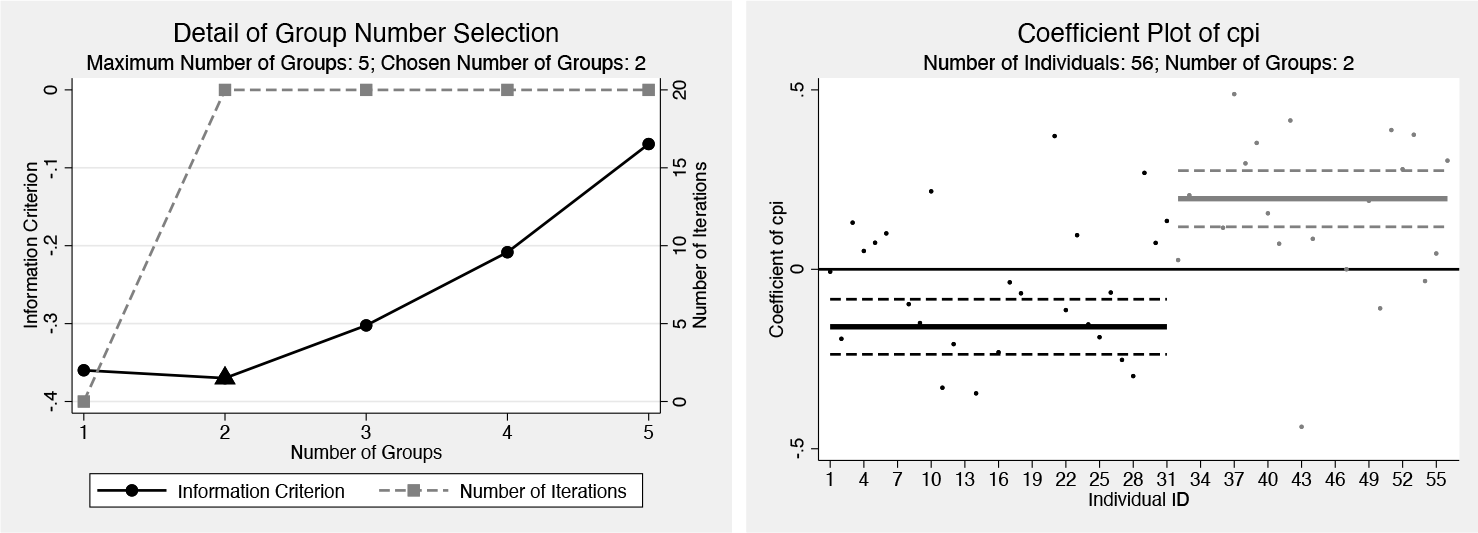
Both the basic information and the iterative process are displayed. Each dot visualizes a complete iteration in step 1.2, as described in section 2.3. The information criterion suggests that the countries cluster into two latent groups. The two coefficient tables are then displayed. First, the coefficients of the inflation rate and the real interest rate become significant in both groups, albeit with opposite signs. Second, the coefficients of the GDP growth rate are significant at the 5% level in both groups, implying a positive correlation between savings rates and income growth across nations. For an extended discussion on this example, please refer to section 5.1 in Su, Shi, and Phillips (2016).
We apply the following codes to store the estimation results in ssp2016.ster. Users can manipulate these results using the postestimation commands as described in section 4. Examples of this are presented in section 4.6.
4 The postestimation commands
We give five postestimation commands—classoselect, predict, estimates replay, classocoef, and classogroup—to select active estimation results, generate new variables, display coefficient tables, and visualize the results after executing classifylasso. The introduction and examples are as follows.
4.1 The classoselect command
The classoselect command decides an alternative estimation result to be used in the following predict, estimates replay, and classocoef commands. It chooses the number of groups and whether the c-lasso or postlasso estimates are used. By default, postlasso coefficients with the information criterion-best number of groups are selected.
group(#) specifies the number of groups used to estimate the coefficients. This number must be included in the list specified by grouplist() in classifylasso.
postselection specifies that postlasso coefficients be used to plot the graph. That is the default. Postlasso coefficients are calculated by regressing the corresponding model for each estimated group.
penalized specifies that penalized coefficients be used to plot the graph. Penalized coefficients are those estimated by c-lasso in the calculation of the additive multiplication penalty.
4.2 The predict command
predict helps users to generate new variables containing the group membership and fitted values from the active estimation results selected by classoselect.
4.2.1 Syntax and options
predictnewvar [if ] [in ] [,statistic ]
gid predicts the group membership, and it is the default.
xb, xbd, d, residuals, and stdp calculate the linear prediction, fixed effects, sum of xb and d, deviation of xbd from the dependent variable, and the standard deviation of linear prediction. The predictions are analogous to reghdfe.
4.3 The estimates replay command
The estimates command displays and exports the coefficient tables from the active estimation results selected by classoselect.
outreg2(filename [,options ]) exports the coefficients to the local disk. Each group forms a column. Because e(b) and e(V) are not stored, this option is the only way to export tables. The default is not to export; see outreg2 (Wada 2005) for details.
display_options control the display style; these options are the same as those in the command classifylasso.
4.4 The classocoef command
The classocoef command uses graph twoway to visualize the coefficient estimates from the active estimation results selected by classoselect. The command generates graphs for all variables by default or for designated variables, with one variable per graph.
In each graph, the y axis and x axis indicate the value of the coefficient and the individual identity, respectively. There are four major elements: the group-specific coefficient line, the confidence interval lines, the scatters of individual-specific timeseries estimates, and the horizontal zero line. This command allows users to visualize one or more of these four elements.
global_twoway_options specify how the overall style looks.
colors(string) specifies the color list for different groups. The default is colors("maroon dkorange sand forest_green navy").
title(tinfo), subtitle(tinfo), legend( [contents] [location] ), ytitle(axis_title), xtitle(axis_title), ylabel(rule_or_values), and xlabel(rule_or_values) control the corresponding titles, legends, and axis; see [G-3] title_options, [G-3] legend_options, and [G-3] axis_options. The defaults are shown in the examples.
name(name_option), saving(saving_option), export(name,options), and scheme(schemename) specify the graph name, the save path, the export name, and the overall look, respectively. Note that if there is more than one graph to be generated, modifying these options may cause an error.
twoptions(twoway_options) specifies additional two-way options; see [G-2] graph twoway.
nowindow suppresses the graph window.
groupcoef_line_options control the group-specific coefficient line, and nocoefplot suppresses the line.
coeflwidth(linewidthstyle) and coeflpattern(linepatternstyle) specify the line style. The default is coeflwidth(1) and coeflpattern(solid).
coefoptions(line_options) specifies additional line options; see [G-2] graph twoway line.
groupci_line_options control the confidence interval lines, and nociplot suppresses the lines.
level(#) controls the significance level as classotable.
cilwidth(linewidthstyle) and cilpattern(linepatternstyle) specify the line style. The default is cilwidth(0.5) and cilpattern(dash).
cioptions(line_options) specifies additional line options; see [G-2] graph twoway line.
tscoef_scatter_options control the scatters of time-series estimates, and notsscatter suppresses the scatters.
tsmsize(markersize) specifies the scatter size. The default is tsmsize(0.5).
tsoptions(scatter_options) specifies additional options; see [G-2] graph twoway scatter.
zero_line_options control the horizontal zero line, and nozeroline suppresses the line.
zerolwidth(linewidthstyle), zerolpattern(linepatternstyle), and zerolcolor(colorstyle) specify the line style. The defaults are zerolwidth(0.5), zerolpattern(solid), and zerolcolor(black).
zerooptions(line_options) specifies additional line options; see [G-2] graph twoway line.
4.5 The classogroup command
The classogroup command uses graph twoway to visualize the group-number selection information. Both information criterion values and numbers of iterations are plotted, which are measured by y-axis(1) and y-axis(2), respectively. The x axis indicates the group number. The selected number of groups is marked by a triangle.
global_twoway_options specify how the overall style looks.
title(tinfo), subtitle(tinfo), ytitle1(axis_title), ytitle2(axis_title), ylabel1(rule_or_values), ylabel2(rule_or_values), xtitle(axis_title), and xlabel(rule_or_values) control the titles and axis.
name(name_option), saving(saving_option), export(name [,options ]), scheme(schemename), twoptions(twoway_options), and nowindow are the same as classocoef.
icplot_options control the information criterion plot, and noicplot suppresses the line.
iclwidth(linewidthstyle), iclpattern(linepatternstyle), iclcolor(colorstyle),icmsize(markersize), icmcolor(colorstyle), icconnect(connectstyle), andiclegend( [contents] [location ]) specify the line width, line pattern, line color, scatter size, scatter color, connect style, and legend, respectively. The defaults are iclwidth(0.5), iclpattern(solid), iclcolor(black), icmsize(2), icmcolor(black), icconnect(direct), and iclegend("Information Criterion").
icoption(scatter_options) specifies additional options; see [G-2] graph twoway scatter.
iterplot_options control the iteration number plot, and noiterplot suppresses the line.
iterlwidth(linewidthstyle), iterlpattern(linepatternstyle), iterlcolor(colorstyle), itermsize(markersize), itermcolor(colorstyle), iterconnect(connectstyle), and iterlegend([contents] [locations ]) specify the line width, line pattern, line color, scatter size, scatter color, connect style, and legend, respectively. The defaults are iterlwidth(0.5), iterlpattern(dash), iterlcolor(blue), itermsize(2), itermcolor(blue), iterconnect(direct), and iterlegend("Number of Iterations").
iteroption(scatter_options) specifies additional options; see [G-2] graph twoway scatter.
4.6 Postestimation of the implementation example
In this section, we illustrate the usage of the postestimation commands. We call the results that are estimated and stored in section 3.4. By default, the postlasso estimates under two groups are active.
First, we predict the group membership and the linear fitted value and store them in the new variables gid and yhat.
Second, we report the estimation results and export them to the disk using the estimates replay command. To save space, we do not display the table, which is the same as in section 3.4.
Additionally, the following codes visualize the group-number selection results and the coefficient estimates in graphs and export them in EPS format.
Figure 1 (left) visualizes the group-number selection information. The black dots report the values of the information criterion against the number of groups. The minimum information criterion is marked by a triangle, indicating the selected number of groups. The gray dots report the numbers of iterations used.
Figure 1 (right) visualizes the coefficient estimates of cpi. Different shades denote different groups. The solid and dash lines plot the group-specific postlasso estimates and the confidence bands. The dots report the individual-specific time-series point estimates with extreme values omitted. This figure indicates CPI has heterogeneous and even opposite effects on saving across different groups.
Visualization of the implementation example
5 Monte Carlo simulation
This section evaluates the finite-sample performance of the estimation results generated by the classifylasso command using Monte Carlo simulations. The results are similar to those in Su, Shi, and Phillips (2016), indicating that the command works well.
We consider linear static panels with latent group structures. We consider sample size N ∊ {100, 200}, time span T ∊ {20, 40}, and number of covariates p ∊ {2, 4}. We run 500 replications for each N, T, p combination. The observations in each datagenerating process (DGP) are drawn from three groups with proportion N1 : N2 : N3 = 0.3 : 0.3 : 0.4. The group membership is random against the identity code. The idiosyncratic errors uit and the fixed effects µi follow independent standard normal distributions.
The exogenous regressors are xit = (0.2µi + eit1, 0.2µi + eit2)′ for p = 2 and xit = (0.2µi + eit1, 0.2µi + eit2, 0.3µi + eit3, 0.3µi + eit4)′ for p = 4, where eitj are mutually independent and independent with µi and uit. The true coefficients are α1 = (0.4, 1.6), α2 = (1, 1), α3 = (1.6, 0.4) for p = 2; and α1 = (0.4, 1.6, −0.4, −1.6), α2 = (1, 1, −1, −1), α3 = (1.6, 0.4, −1.6, −0.4) for p = 4, and for i ∊ Gk.
For the tuning parameters, we use the default values in the command; that is, cλ = 0.2 for λNT = cλT −1/3 and cρ = 2/3 for ρNT = cρ(NT)−1/2. By default, the individual fixed effects are absorbed by demeaning. For each DGP, we select the group size from 1 to 5. The implementation command for two covariates is
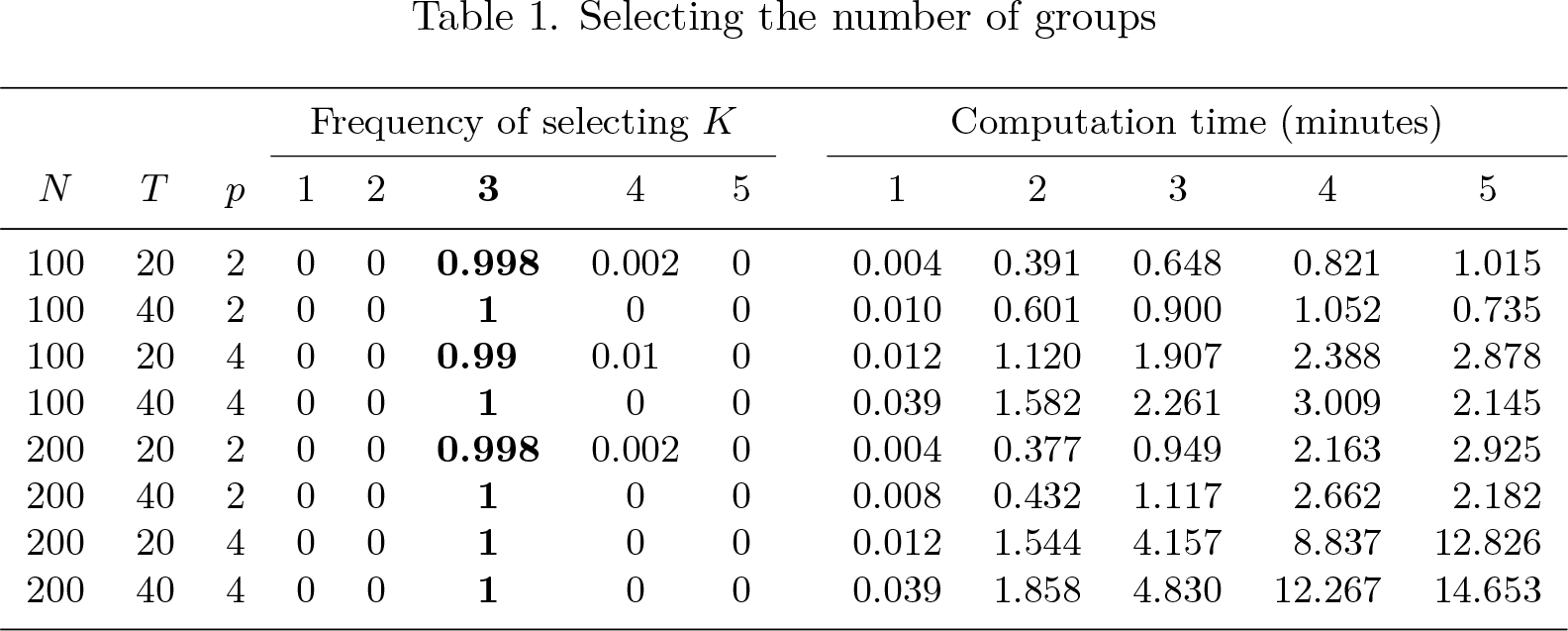
Table 1 (left) reports the frequency of selecting the number of groups when the true number of groups K = 3. It indicates that the information criterion generates perfect selection of the number of groups when N and T increase. These results demonstrate the usefulness of the information criterion and the robustness of the default ρ value.
Table 1 (right) reports the average computation time of different sample sizes, parameter numbers, and group numbers without parallel computation using 3.20 GHz and 8 kernels CPU. Generally, both the capacity of the computer and the attribute of the dataset will affect the computation time. N and p both quadratically increase the computation time, while T does not significantly influence the computation time. In addition, the effect of K on the computation time is nonproportional. Take N = 100, T = 40, and p = 4, for instance; the command requires 12 minutes on average to choose the number of groups from 1 to 5. The computation burden mainly comes from the optimization of step 1.2 in section 2.3. Note that there is a tradeoff between estimation accuracy and computation time. The users can set the “iteration” parameters Rmax and εtol using the options to shorten computation time while maintaining enough estimation accuracy. Besides, after each completion of step 1.2, the command will print a dot.
Selecting the number of groups
Frequency of selecting K
Computation time (minutes)
N
T
p
1
2
3
4
5
1
2
3
4
5
100
20
2
0
0
0.998
0.002
0
0.004
0.391
0.648
0.821
1.015
100
40
2
0
0
1
0
0
0.010
0.601
0.900
1.052
0.735
100
20
4
0
0
0.99
0.01
0
0.012
1.120
1.907
2.388
2.878
100
40
4
0
0
1
0
0
0.039
1.582
2.261
3.009
2.145
200
20
2
0
0
0.998
0.002
0
0.004
0.377
0.949
2.163
2.925
200
40
2
0
0
1
0
0
0.008
0.432
1.117
2.662
2.182
200
20
4
0
0
1
0
0
0.012
1.544
4.157
8.837
12.826
200
40
4
0
0
1
0
0
0.039
1.858
4.830
12.267
14.653
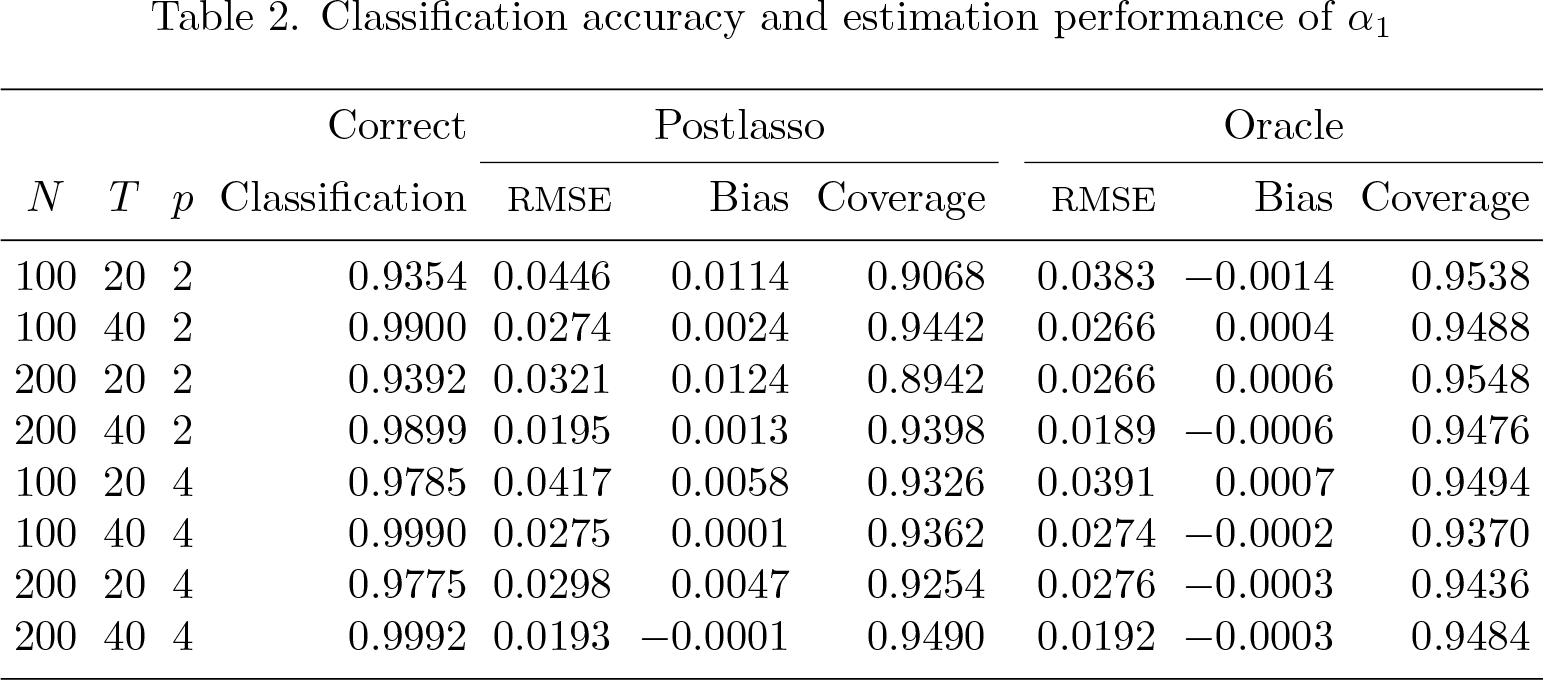
Table 2 reports the performance of the classification of individual units and estimation of the parameters. Column 4 reports the accuracy of individual classification, defined as , averaged over 500 replications. Columns 5–7 report the postlasso estimators’ root mean squared error (RMSE), bias, and coverage probability of the two-sided 95% confidence interval, averaged over 500 replications. Analogously to Su, Shi, and Phillips (2016), the performance of is reported. Because α1 is a K × 1 vector, we averaged over the statistics by their weight Nk/N. For instance, the coverage is defined as . The performances of the other parameters—α2, α3, and α4—are similar. For comparison purposes, the performances of the oracle estimators are reported in columns 8–10. The oracle estimators are estimated using the true group classification Gk, which is not available in practice. These results indicate that as T increases, the individual units are almost perfectly classified, and the performance of the postlasso estimators approaches that of the oracle estimators. It demonstrates good finite-sample performances of the estimators that the classifylasso command generates.
Classification accuracy and estimation performance of α1
Correct
Postlasso
Oracle
N
T
p
Classification
RMSE
Bias
Coverage
RMSE
Bias
Coverage
100
20
2
0.9354
0.0446
0.0114
0.9068
0.0383
−0.0014
0.9538
100
40
2
0.9900
0.0274
0.0024
0.9442
0.0266
0.0004
0.9488
200
20
2
0.9392
0.0321
0.0124
0.8942
0.0266
0.0006
0.9548
200
40
2
0.9899
0.0195
0.0013
0.9398
0.0189
−0.0006
0.9476
100
20
4
0.9785
0.0417
0.0058
0.9326
0.0391
0.0007
0.9494
100
40
4
0.9990
0.0275
0.0001
0.9362
0.0274
−0.0002
0.9370
200
20
4
0.9775
0.0298
0.0047
0.9254
0.0276
−0.0003
0.9436
200
40
4
0.9992
0.0193
−0.0001
0.9490
0.0192
−0.0003
0.9484
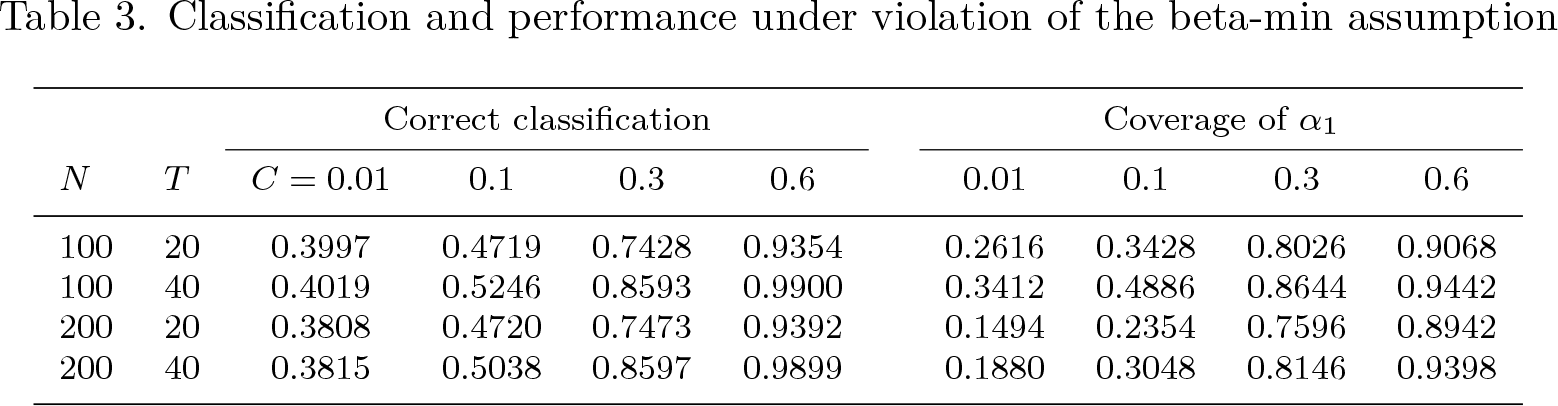
Finally, as we discussed before, the beta-min assumption is crucial for the performance of the classifylasso command. Therefore, we analyze the effect of violation. We stick with the DGP of two covariates, while we substitute the parameters with α1 = (1 − C, 1 + C), α2 = (1, 1), α3 = (1 + C, 1 − C). A smaller constant C represents a more severe violation of the beta-min assumption. We consider values of C ∊ {0.01, 0.1, 0.3, 0.6}.
Table 3 presents the results of group classification and parameter estimation when the beta-min assumption may be violated. Columns 3–6 display the classification accuracy, which reveals that the performance of the classifylasso method is poor in distinguishing between groups when the group-specific coefficients are only slightly different from each other. Columns 7–10 display the coverage probability of the two-sided 95% confidence interval. Similarly, the coverage is far below the nominal rate when the value of C is small. Overall, the group classification and parameter estimation results are poor if the beta-min assumption is violated. We recommend that users justify the beta-min assumption by economic theory or statistical tests (for example, Pesaran and Yamagata [2008], Su and Chen [2013], and Ando and Bai [2015]) before using the classifylasso command.
Classification and performance under violation of the beta-min assumption
Correct classification
Coverage of α1
N
T
C = 0.01
0.1
0.3
0.6
0.01
0.1
0.3
0.6
100
20
0.3997
0.4719
0.7428
0.9354
0.2616
0.3428
0.8026
0.9068
100
40
0.4019
0.5246
0.8593
0.9900
0.3412
0.4886
0.8644
0.9442
200
20
0.3808
0.4720
0.7473
0.9392
0.1494
0.2354
0.7596
0.8942
200
40
0.3815
0.5038
0.8597
0.9899
0.1880
0.3048
0.8146
0.9398
6 An empirical illustration
In this section, we study whether there is unobserved group heterogeneity in the relationship between democracy and economic growth that is still unaccounted for in the existing literature.
6.1 Motivation and data description
Whether democracy benefits economic growth has long been debated. Doucouliagos and Ulubaşoğlu (2008) reviewed 84 studies and found that despite the indirect effect of democracy on many indices, its effect on growth is still inconclusive. Although Acemoglu et al. (2019) recently constructed a new measure of democracy and provided evidence to support positive effects of democracy on economic growth, opposite views are supported by some facts, such as the spectacular economic growth in China, the middle-income trap in South America, and chaos after the Arab Spring.
Considering inconclusive results on the effect, both the signs and the magnitudes, of democracy on economic growth found in the literature, we adopt the c-lasso estimation method in this study and allow for potential group heterogeneity on such effects.
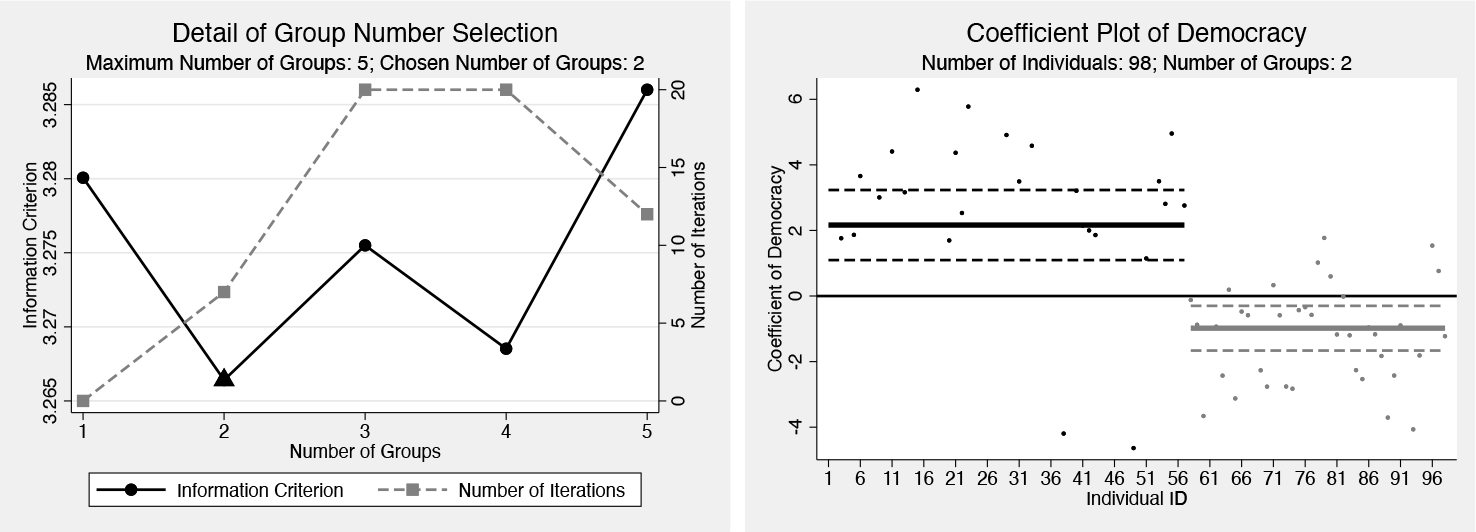
We consider Acemoglu et al.’s (2019) specification as follows:
i and t denote the country and time index; the dependent variable lnPGDPit is the logarithm of GDP per capita; the independent variable of interest, Democracyit, is a dummy variable recording whether country i is a democracy at year t; µi and λt are country-level and year fixed effects; uit is the idiosyncratic error; control variables are the lags of the dependent variable; and l is the maximum number of lags. To obtain robust results, we consider the specifications including 1, 2, 3, and 4 lags.
In contrast to the homogeneity assumption, βi, the coefficient of interest, is allowed to vary across countries because of the underlying group pattern, measuring potentially heterogeneous effects of democracy on economic growth.
The data are stored in democracy.dta, provided with the article files. It is transferred from the original dataset into a balanced one with 98 countries from 1970 to 2010. We first import the data and declare the panel structure:
6.2 Empirical results
We first determine the number of groups in (6). The following codes implement groupnumber selection controlling for one lag of lnPGDP, visualize the estimation results, and store the estimation result in democracy1.ster. Note that because lag variables are included in the regression, we correct the dynamic panel bias using the dynamic option. Commands allowing for more control variables are similar.
Figure 2 visualizes the estimation results. The left subfigure summarizes the groupnumber selection results. It indicates that two groups are selected considering one lag. The right subfigure plots the effects of democracy on economic growth with the 95% confidence bands based on the postlasso estimation results with dynamic bias correction. With more lag controlled, the selected numbers of breaks are consistently greater than 1. Therefore, there is evidence that the effects of democracy on growth are heterogeneous across different countries. To keep the results of different control variables consistent, we set the number of groups to be two in the following analyses.
Heterogeneous effects of democracy on economic growth
In what follows, we study the heterogeneous effects of democracy on growth using the c-lasso estimation method and compare them with the original results. The following code implements Acemoglu et al.’s (2019) fixed-effects model estimation and our c-lasso estimation considering both country and year fixed effects. It also stores the coefficients in coeftable.xls.
Table 4 summarizes the estimation results. The four subtables (1), (2), (3), and (4) report the results considering 1, 2, 3, and 4 lags, respectively. Within each subtable, the column “Pooled” reports the result of the fixed-effects model. Columns “G1” and “G2” report the postlasso estimation results of two different groups. The clustered standard errors are displayed in the parentheses. N, T , and # obs. are the number of panel units, time periods, and observations, respectively.
Heterogeneous effects of democracy on economic growth
lnPGDP
Pooled
(1)G1
G2
Pooled
(2)G1
G2
Pooled
(3)G1
G2
Pooled
(4)G1
G2
Democracy
1.055
2.165
−0.981
0.781
1.622
−0.869
0.763
1.089
−1.462
0.842
1.165
−1.172
(0.370)
(0.545)
(0.348)
(0.263)
(0.339)
(0.365)
(0.259)
(0.314)
(0.305)
(0.258)
(0.313)
(0.303)
lnPGDP−1
0.970
1.033
0.982
1.250
1.309
1.333
1.227
1.335
1.133
1.228
1.347
1.088
(0.006)
(0.007)
(0.009)
(0.062)
(0.075)
(0.126)
(0.055)
(0.066)
(0.057)
(0.057)
(0.068)
(0.056)
lnPGDP−2
−0.284
−0.287
−0.314
−0.194
−0.223
−0.142
−0.214
−0.250
−0.131
(0.061)
(0.074)
(0.122)
(0.051)
(0.063)
(0.073)
(0.052)
(0.065)
(0.072)
lnPGDP−3
−0.069
−0.072
−0.006
−0.006
−0.033
0.082
(0.027)
(0.029)
(0.038)
(0.037)
(0.042)
(0.058)
lnPGDP−4
−0.046
−0.027
−0.042
(0.021)
(0.025)
(0.050)
Country FE
✔
✔
✔
✔
✔
✔
✔
✔
✔
✔
✔
✔
Year FE
✔
✔
✔
✔
✔
✔
✔
✔
✔
✔
✔
✔
N
98
57
41
98
59
39
98
61
37
98
67
31
T
40
40
40
39
39
39
38
38
38
37
37
37
# obs.
3,920
2,280
1,640
3,822
2,301
1,521
3,724
2,318
1,406
3,626
2,479
1,147
The pooled estimation gives a similar result to the within estimator of table 2 in Acemoglu et al. (2019), indicating that transferring the original dataset into a balanced panel does not influence the core relationship between economic growth and democracy. Postlasso estimation results show consistent polarized effects of democracy on economic growth. Democracy does cause economic growth in countries classified in group 1 (G1), while it hinders economic development and even hurts the economy in those classified in group 2 (G2). Compared with the pooled results, our results uncover group heterogeneity in the effects, which somewhat explains the opposite results found in the literature.
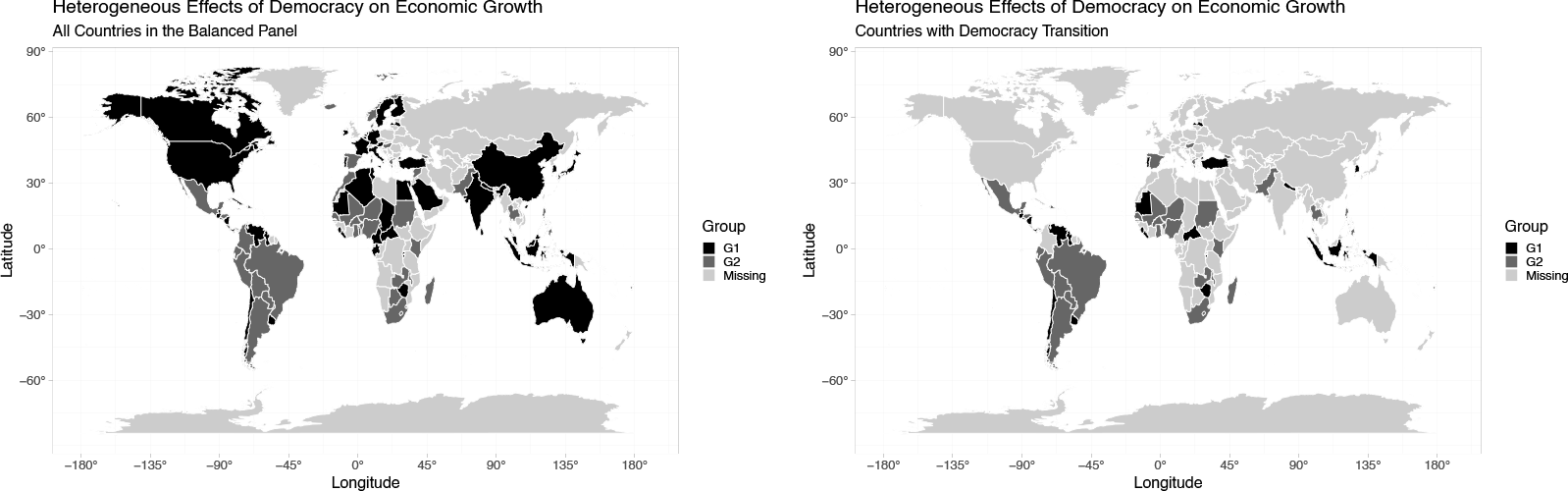
We further analyze the classification results. The results indicate that there are around 60 countries in G1 and around 40 countries in G2. Although the group classification is not completely the same when the number of lags included differs, we find that most disagreement comes from the countries without democratic transitions.1
To visualize the heterogeneous effects of democracy on economic growth, we plot the group classification result considering one lag in figure 3. The left subfigure shows all countries in our panel data, and the right one shows countries with a democratic transition. The pale-gray countries are out of our sample. We find that countries such as Korea and Portugal, or South African countries with higher economic development like Zimbabwe, are classified into the group in which democracy promotes growth, while countries classified into the group in which democracy hinders growth include those suffering from civil wars and chaos like Mexico (see Dell [2015]) and those in the poorest region in the world like Zambia, Sudan, and Malawi.
Heterogeneous effects of democracy in the world
7 Conclusions
In this article, we introduced a new command, classifylasso, that implements the c-lasso method to fit panel-data models with latent group structures in the Stata environment. Postestimation commands are provided to display and visualize the estimation results. The current classifylasso command can be improved in several ways. One possible improvement is to extend the estimation framework to the profile likelihood estimation and the generalized method of moments estimation, as shown in Su, Shi, and Phillips (2016). Another possible improvement is to further speed up the estimation procedure. Although the computation time is acceptable for regular economic datasets, the command may have problems dealing with large financial datasets.
9 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X241233642 - Identify latent group structures in panel data: The classifylasso command
Supplemental Material, sj-zip-1-stj-10.1177_1536867X241233642 for Identify latent group structures in panel data: The classifylasso command by Wenxin Huang, Yiru Wang and Lingyun Zhou in The Stata Journal
Footnotes
8 Acknowledgment
The authors thank the coeditor and the anonymous referee for many constructive comments on the previous version of the article and the command.
9 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
1.
AcemogluD.NaiduS.RestrepoP.RobinsonJ. A.. 2019. Democracy does cause growth. Journal of Political Economy127: 47–100. https://doi.org/10.1086/700936.
2.
AhrensA.HansenC. B.SchafferM. E.. 2020. lassopack: Model selection and prediction with regularized regression in Stata. Stata Journal20: 176–235. https://doi.org/10.1177/1536867X20909697.
AndoT.BaiJ.. 2015. A simple new test for slope homogeneity in panel data models with interactive effects. Economics Letters136: 112–117. https://doi.org/10.1016/j.econlet.2015.09.019.
5.
BelloniA.ChernozhukovV.. 2013. Least squares after model selection in highdimensional sparse models. Bernoulli19: 521–547. https://doi.org/10.3150/11-BEJ410.
6.
BelloniA.ChernozhukovV.HansenC.. 2014. Inference on treatment effects after selection among high-dimensional controls. Review of Economic Studies81: 608–650. https://doi.org/10.1093/restud/rdt044.
BonhommeS.ManresaE.. 2015. Grouped patterns of heterogeneity in panel data. Econometrica83: 1147–1184. https://doi.org/10.3982/ECTA11319.
9.
CampelloM.GalvaoA. F.JuhlT.. 2019. Testing for slope heterogeneity bias in panel data models. Journal of Business and Economic Statistics37: 749–760. https://doi.org/10.1080/07350015.2017.1421545.
10.
CarterA. V.SchnepelK. T.SteigerwaldD. G.. 2017. Asymptotic behavior of a ttest robust to cluster heterogeneity. Review of Economics and Statistics99: 698–709. https://doi.org/10.1162/REST_a_00639.
11.
ChernozhukovV.ChetverikovD.DemirerM.DufloE.HansenC.NeweyW.RobinsJ.. 2018. Double/debiased machine learning for treatment and structural parameters. Econometrics Journal21: C1–C68. https://doi.org/10.1111/ectj.12097.
CorreiaS. 2014. reghdfe: Stata module to perform linear or instrumental-variable regression absorbing any number of high-dimensional fixed effects. Statistical Software Components S457874, Department of Economics, Boston College. https://ideas.repec.org/c/boc/bocode/s457874.html.
14.
CorreiaS. 2016. ftools: Stata module to provide alternatives to common Stata commands optimized for large datasets. Statistical Software Components S458213, Department of Economics, Boston College. https://ideas.repec.org/c/boc/bocode/s458213.html.
EicherT. S.LeukertA.. 2009. Institutions and economic performance: Endogeneity and parameter heterogeneity. Journal of Money, Credit and Banking41: 197–219. https://doi.org/10.1111/j.1538-4616.2008.00193.x.
LeebH.PötscherB. M.. 2006. Can one estimate the conditional distribution of post-model-selection estimators?Annals of Statistics34: 2554–2591. https://doi.org/10.1214/009053606000000821.
29.
LuX.SuL.. 2017. Determining the number of groups in latent panel structures with an application to income and democracy. Quantitative Economics8: 729–760. https://doi.org/10.3982/QE517.
PötscherB. M.LeebH.. 2009. On the distribution of penalized maximum likelihood estimators: The LASSO, SCAD, and thresholding. Journal of Multivariate Analysis100: 2065–2082. https://doi.org/10.1016/j.jmva.2009.06.010.
33.
QianJ.SuL.. 2016. Shrinkage estimation of common breaks in panel data models via adaptive group fused Lasso. Journal of Econometrics191: 86–109. https://doi.org/10.1016/j.jeconom.2015.09.004.
34.
SarafidisV.WeberN.. 2015. A partially heterogeneous framework for analyzing panel data. Oxford Bulletin of Economics and Statistics77: 274–296. https://doi.org/10.1111/obes.12062.
35.
SuL.ChenQ.. 2013. Testing homogeneity in panel data models with interactive fixed effects. Econometric Theory29: 1079–1135. https://doi.org/10.1017/S0266466613000017.
36.
SuL.ShiZ.PhillipsP. C. B.. 2016. Identifying latent structures in panel data. Econometrica84: 2215–2264. https://doi.org/10.3982/ECTA12560.
37.
WadaR. 2005. outreg2: Stata module to arrange regression outputs into an illustrative table. Statistical Software Components S456416, Department of Economics, Boston College. https://ideas.repec.org/c/boc/bocode/s456416.html.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.