
Abstract
We present a command,
Keywords
1 Introduction
Real-world phenomena are often characterized by complex relationships. Some observed variables might exhibit erratic behavior in the short run but tend to comove in a stable and predictable way over longer time horizons. Attempting to empirically uncover such long-run equilibrium relationships is tantamount to separating them from the overlaid short-run dynamics. This separation allows one to find evidence for or against an equilibrium relationship, which is often at the heart of a research question. It also allows analysis of the short-term fluctuations around the equilibrium, which can be valuable in its own right, for example, when conducting forecasting exercises or dynamic simulations.
When we observe the variables of interest over a sufficiently long stretch of consecutive time periods, multiequation vector autoregressive (VAR) and vector error-correction (VEC) models are commonly used to assess their dynamic relationships. When we have reasons to assume that there is a natural ordering of the variables such that there is no contemporaneous feedback from a response variable to the other variables in the system, a single-equation autoregressive distributed lag (ARDL) model can simplify the analysis and facilitate more efficient inference. 1
ARDL models have many possible applications. They are extensively used in studies analyzing linkages of pollution and energy consumption to economic growth (Fatai, Oxley, and Scrimgeour [2004]; Narayan and Smyth [2005]; Wolde-Rufael [2006]; Ang [2007]; Halicioglu [2009]; Jalil and Mahmud [2009]; Zhang et al. [2015]; Ntanos et al. [2018]; Bekun, Emir, and Sarkodie [2019]; Kirikkaleli, Güngör, and Adebayo [2022]; and many more). Relationships with economic growth have also been investigated for foreign direct investment and trade (Oteng-Abayie and Frimpong 2006; Belloumi 2014), infrastructure (Fedderke, Perkins, and Luiz 2006), immigration (Morley 2006), tourism (Katircioglu 2009; Wang 2009; Song et al. 2011), stock market development (Enisan and Olufisayo 2009), and health expenditures (Murthy and Okunade 2016).
Other examples include the nexus between viral infections and meteorological factors (He et al. 2017; Doğan et al. 2020), childcare availability, fertility, and female labor force participation (Lee and Lee 2014), wages, productivity, and unemployment (Pesaran, Shin, and Smith 2001), savings and investment (Narayan 2005), exchange rates and trade (Bahmani-Oskooee and Brooks 1999; De Vita and Abbott 2004), exchange rates and monetary policy (Frankel, Schmukler, and Servén 2004; Shambaugh 2004; Obstfeld, Shambaugh, and Taylor 2005), financial development and inequality (Ang 2010), bank lending and property prices (Davis and Zhu 2011), financial reforms and credit growth (Adeleye et al. 2018), stock market efficiency and fiscal policy (Stoian and Iorgulescu 2020), democracy and the shadow economy (Esaku 2022), and the interdependencies among stock price indices and commodity prices (Narayan, Smyth, and Nandha 2004; Sari, Hammoudeh, and Soytas 2010; Büyükşahin and Robe 2014), as well as cryptocurrencies (Ciaian, Rajcaniova, and Kancs 2016, 2018), to list only a few.
Recently, the ARDL methodological toolkit was used extensively to analyze adjustment processes during the COVID-19 pandemic, including tourism demand forecasts (Zhang et al. 2021) and the effects on macroeconomic activity (Varona and Gonzales 2021) or energy consumption (Aruga, Islam, and Jannat 2020).
The ARDL model can be conveniently reparameterized in so-called error-correction (EC) form, which disentangles the long-run relationship from the short-run dynamics. When the variables are nonstationary—to be precise, integrated of order 1—the longrun relationship embedded in an EC model corresponds to a cointegrating relationship (Engle and Granger 1987; Hassler and Wolters 2006). Testing for cointegration in such a setup therefore equals testing for the existence of a long-run relationship. However, the latter concept retains its relevance when some of or all the variables are stationary.
Pesaran and Shin (1998) and Hassler and Wolters (2006) highlight some advantages of the ARDL approach over alternative strategies for cointegration analysis—such as the Engle and Granger (1987) two-step procedure implemented in the community-contributed command
Compared with a system-based Johansen (1995) cointegration analysis, which is implemented in Stata’s
Despite its advantages, testing for the existence of a long-run (cointegrating) relationship with the ARDL framework still requires a bit of effort. The test statistic has a nonstandard distribution that depends on various characteristics of the model and the data, including the integration order of the variables. Pesaran, Shin, and Smith (2001) propose a “bounds test”, which involves comparing the values of conventional
This bounds test is implemented as a postestimation feature in our
Closely related, Jordan and Philips (2018) recently introduced the
This article is concerned only with time-series data. For the estimation of ARDL models in a large-T panel-data context, see the community-contributed commands
In section 2, we outline the econometric background for the ARDL approach to the analysis of long-run equilibrium relationships, and we provide guidance for the model specification and bounds-testing procedure. In sections 3 and 4, we describe the syntax and options for the
2 Econometric model and methods
2.1 ARDL model
Suppose we expect the existence of an equilibrium relationship between an outcome variable yt
and a set of

b
0 is the intercept of the regression line, and b
1 is the slope coefficient of a linear time trend. The data are observed at consecutive time points t = 1, 2,…, T . Estimating the regression coefficients in such a static model by ordinary least squares (OLS) might result in spuriously large coefficient estimates even if there is no underlying relationship among the variables. This is known to happen when the error term et
is nonstationary because of the nonstationarity of yt
and
Equation (1) remains a valid regression model if yt
and some of or all the variables
To circumvent the problems associated with fitting a static model, we can augment the regression equation with lags of the dependent and independent variables. We can even include another set of L exogenous variables

t = 1 + p ∗ ,…, T . Leaving aside the variables z t , this is a general ARDL (p, q,…, q) model with intercept c 0, linear trend c 1 t, and lag orders p ∊ [1, p ∗] and q ∊ [0, p ∗]. 4 To ensure that there are enough degrees of freedom available to fit the model’s coefficients with sufficient precision, we may need to choose the maximum admissible lag order p ∗ conservatively. This is especially relevant when the number of observations in the dataset (T ) is relatively small, the number of variables in x t (K) is relatively large, or both. 5
Given the initial observations y
1
, y
2
,…, yp
∗ and the time paths of x
t
and z
t
, (2) describes the dynamic evolution of yt
over time, irrespective of whether an equilibrium relationship—as postulated in (1)—exists. The intercept c
0 and the linear time trend c
1
t may or may not be included in the model, depending on the nature of the variables under consideration.
6
We assume that enough lags have been included in the ARDL model (2) to purge the error term from any remaining serial correlation and to ensure that the variables
While the inclusion of further lags improves the regression fit, this comes at the cost of a higher variance of the coefficient estimates. To balance this tradeoff, we can base a data-driven approach to optimal lag selection on the AIC or the BIC,

where
For the comparability of the model-selection criteria, we must base all regressions on the same estimation sample. This is the reason for initially choosing a fixed maximum lag order p ∗. When both p and q are smaller than p ∗, the estimation of model (2) does not use all the available observations. This is the price we need to pay for consulting the model-selection criteria. Once the optimal lag orders p and q have been found, we can subsequently refit the model, utilizing all available observations by setting p ∗ = max(p, q).
2.2 Error-correction representation
To gain a better interpretability of the model’s coefficients, we can reformulate the ARDL model in EC representation (Hassler and Wolters 2006): 7

The coefficients in (3) can be mapped in a straightforward algebraic way to the coefficients in (2):

Now recall the hypothesized long-run equilibrium relationship between yt
and

From the above model, we can easily recover the so-called speed-of-adjustment coefficient α = −πy
and the long-run coefficients
The speed-of-adjustment coefficient α tells us how fast the process for yt reverts to its long-run relationship when this equilibrium is distorted. α = 1 would imply that—in the absence of any other short-run fluctuations—any deviation from the equilibrium is fully corrected immediately in the period after the distortion occurs. In contrast, α = 0 would imply that the process never returns to its equilibrium path. Values of α between these two boundaries reflect a partial-adjustment process, where the gap to the equilibrium is gradually closed over time. 9
Clearly,
In this context, note that the assumption of

The remaining coefficients ψyi
,
A complication arises if q = 0 for some of or all the long-run forcing variables. In that situation,

It has the same parameter restrictions as defined above. Note that

where the coefficients
2.3 Bounds test
Although we can consistently estimate all coefficients in the ARDL model (2) or its EC representations, testing for the existence of a long-run relationship involves a bit more effort. This is because the process for yt
contains a unit root under the null hypothesis of no long-run relationship; therefore, the test statistics have nonstandard distributions. Moreover, the tests depend on the choice of deterministic model components. In the ARDL model (2)—and its EC representations (3) and (6)—we have allowed for an intercept c
0 and a linear time trend c
1
t. We can distinguish the following five cases: No deterministic model components are included (c
0 = c
1 = 0). A restricted intercept is included (c
0 = αb
0) but no time trend (c
1 = 0). An unrestricted intercept is included (c
0 ≠ 0) but no time trend (c
1 = 0). An unrestricted intercept is included (c
0 ≠ 0) and a restricted time trend (c
1 = αb
1). Both deterministic model components are unrestricted (c
0 ≠ 0 and c
1 ≠ 0).
A decision about the relevant case can often be guided by a visual inspection of the time series. Cases 1 and 2 are in line with a process yt
, which could reasonably be an I(1) process without drift under the null hypothesis of no long-run level relationship. Under the alternative hypothesis, yt
would either be I(0) or cointegrated with
If yt
appears to be trending, it could be an I(1) process with drift under the null hypothesis. This calls for case 3 or 4. Under the alternative hypothesis, yt
would either be trend stationary or cointegrated with
Especially when the sample size is relatively small, it might be difficult to distinguish visually between a mildly drifting unit-root process under the null hypothesis and a stationary process which is fluctuating around a constant mean under the alternative hypothesis. This can be another relevant situation for case 3. Similarly, case 5 could be used to statistically discriminate between a unit-root process with faster—although hardly noticeable—than linear growth (or decline) and a trend-stationary process. For most practical applications, this might be a rather irrelevant scenario.
Note that the restrictions on the intercept or linear trend under cases 2 and 4 do not affect the estimation of the ARDL model because it is irrelevant whether we treat c
0 (c
1) or b
0 (b
1) as a free parameter to be estimated. Under case 1, (2) is estimated without intercept and trend. Under cases 2 and 3, an intercept is included in the regression. Under cases 4 and 5, an intercept and linear time trend are included. However, the restrictions are incorporated into step 1 of the bounds testing procedure, which we describe in the following: First, we test the joint null hypothesis
versus the alternative hypothesis
The hypotheses are not directly formulated in terms of the long-run coefficients If the null hypothesis from step 1 is rejected, we need to rule out the special case that yt
is I(1) but not cointegrated with any variable in
The test statistic is a conventional t statistic for statistical insignificance of the negative speed-of-adjustment estimate with a one-sided rejection region. As in step 1, the distribution is nonstandard, and the usual CVs do not apply. If the null hypothesis is not rejected, we conclude again that there is no statistical evidence of a long-run level relationship. Otherwise, we proceed with step 3. If the null hypotheses in steps 1 and 2 are both rejected, we eventually consider the degenerate case that yt
is (trend) stationary but not part of a long-run relationship with
We base this test on the long-run coefficients




The rejection of the null hypotheses from all three steps is necessary to conclude that there is statistical evidence in favor of a long-run relationship; that is, (α > 0)∩(
For the test statistics in steps 1 and 2, Pesaran, Shin, and Smith (2001) derive the asymptotic distributions under two scenarios. In the first scenario, all long-run forcing variables
Note that the distributions and CVs are obtained under the assumption of independent and identically normally distributed errors ut . As mentioned earlier, a standard procedure for dealing with suspected serial correlation is to increase the lag orders p, q, or both in the ARDL model. While the p + Kq short-run terms in the EC representation do not affect the asymptotic distributions of the test statistics, they are relevant for the finite-sample distributions. Consequently, different CVs are needed for each combination of T ∗, K, and p + Kq, separately for the lower and upper bounds. Instead of tabulating vast amounts of CVs, Kripfganz and Schneider (2020) estimated response-surface regressions, which can predict CVs for any desired sample size, number of long-run forcing variables, and lag order. This includes asymptotic CVs. Another important advantage of this approach is the ability to compute approximate p-values, which facilitate statistical inference.
2.4 Practical guidelines
The following stages characterize a stylized ARDL approach to testing for the existence of a conditional long-run level relationship: Decide about the candidate variables Decide about the deterministic model components to be included in the model and whether the constant or linear trend coefficient should be restricted; that is, choose one of the five cases above. If in doubt, choose a more flexible model.
17
Choose a maximum lag order p
∗, ensuring that sufficiently many degrees of freedom are available.
18
Keeping the estimation sample fixed, use the AIC or BIC to obtain the optimal lag orders p and q. To assert that the model is dynamically complete, a serial-correlation test could be of assistance. If there is concern about remaining serial correlation, the AIC might be preferred over the BIC because it tends to select less parsimonious models. Additional specification tests—for example, tests for heteroskedasticity and normality of the errors—could be used to check whether the assumptions underlying the bounds test are met. Check the plausibility of the coefficient estimates in the EC representation. For example, an implausible estimate of α, which is clearly outside of the interval [0, 2), might give rise to concern about the correct model specification or a potential overparameterization of the model. Follow the three steps of the bounds test procedure. For steps 1 and 2, do not reject the null hypothesis if the value of the test statistic is below—that is, closer to zero—the lower bound of the Kripfganz and Schneider (2020) CVs. Reject the null hypothesis (and proceed with the next testing step) if the test statistic exceeds the upper-bound CV. If there is conclusive statistical evidence in favor of a long-run relationship, consider refitting a more parsimonious model with lag orders selected by the BIC. If there is evidence against a long-run level relationship, consider refitting an ARDL model in first differences to obtain more efficient estimates,
which is a restricted version of (7) with πy
= 0 and
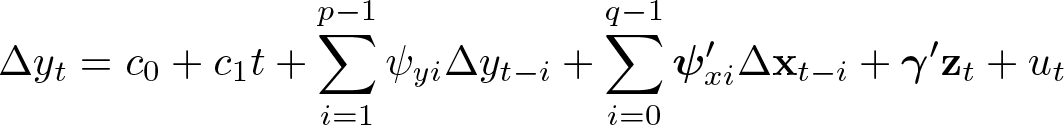
To avoid pretesting problems, keep model simplifications—like those at stage 6—to a minimum before the bounds test is performed. Also note that there is no need to separately fit a static model in levels if the bounds test provides evidence in favor of a long-run relationship. As discussed earlier, the respective long-run coefficients can be inferred directly from the EC representation (3) or (6).
3 The ardl command
3.1 Syntax
3.2 Options
display_options:
3.3 Stored results

4 Postestimation commands
Many standard postestimation commands for the
The Pesaran, Shin, and Smith (2001) bounds test for the existence of a long-run level relationship with Kripfganz and Schneider (2020) CVs and approximate p-values—as discussed in section 2.3—is implemented in the postestimation command
4.1 Syntax
4.2 Options
5 Example
We illustrate the
The motivation for the key variables in our dataset follows Ciaian, Rajcaniova, and Kancs (2016). If a long-run equilibrium exists, the Bitcoin price is expected to be inversely proportional to its supply, which can be approximated by the historical number of mined Bitcoins (variable
Because Bitcoin is predominantly priced in USD, a depreciation of the dollar makes it cheaper to carry out Bitcoin transactions for investors in the rest of the world, therefore increasing demand. For simplicity, following Ciaian, Rajcaniova, and Kancs (2016), we just include the USD/EUR exchange rate (
We start with a visual inspection of the key variables.
26
In the left panel of figure 1, the evolution of the log Bitcoin price and its supply are shown. The latter largely follows a deterministic path, which is prescribed by the underlying Bitcoin protocol. The Bitcoin price shows all signs of a nonstationary variable. While it shares a similar upward trend with the supply, the quasideterministic nature of the mining process precludes that the two series could be cointegrated. To avoid distorting the bounds test, it is thus advisable to exclude the supply from the long-run relationship for testing purposes. It can still enter the regression model as an exogenous price determinant—a

Time-series graphs for the main regression variables
The right panel of figure 1 depicts the demand side factors. The USD/EUR exchange rate is clearly nonstationary, while coin days destroyed look fairly stationary. The picture is less clear about the daily Bitcoin transactions series, which appears to follow different time trends at different periods in our sample and therefore is likely nonstationary. We could verify these assessments with conventional unit-root tests, but this is not necessary for ARDL estimation and bounds testing. It is one of the latter’s advantages that it can deal with mixtures of I(0) and I(1) variables. We will confirm our initial assessment further below in the context of fitting a VEC model, where pretesting for the order of integration is required.
There is no apparent reason to believe that the observed time trend in the Bitcoin price is entirely attributable to the underlying time trend in the other variables. This calls for the inclusion of a restricted time trend—case 4—in the EC model. Under the null hypothesis of the bounds test, the log Bitcoin price would then follow a random walk with drift. Alternatively, if α ≠ 0, it can be either cointegrated or trend stationary.
Given that we have daily data, we choose a maximum lag order p
∗ = 7, such that the lags can cover up to one week. Thanks to the large number of observations, we do not have to be conservative with the degrees of freedom and therefore select the optimal lag combination with the AIC rather than the BIC. This reduces the risk of misspecifying the model dynamics, which in turn might invalidate the bounds test. We therefore add the
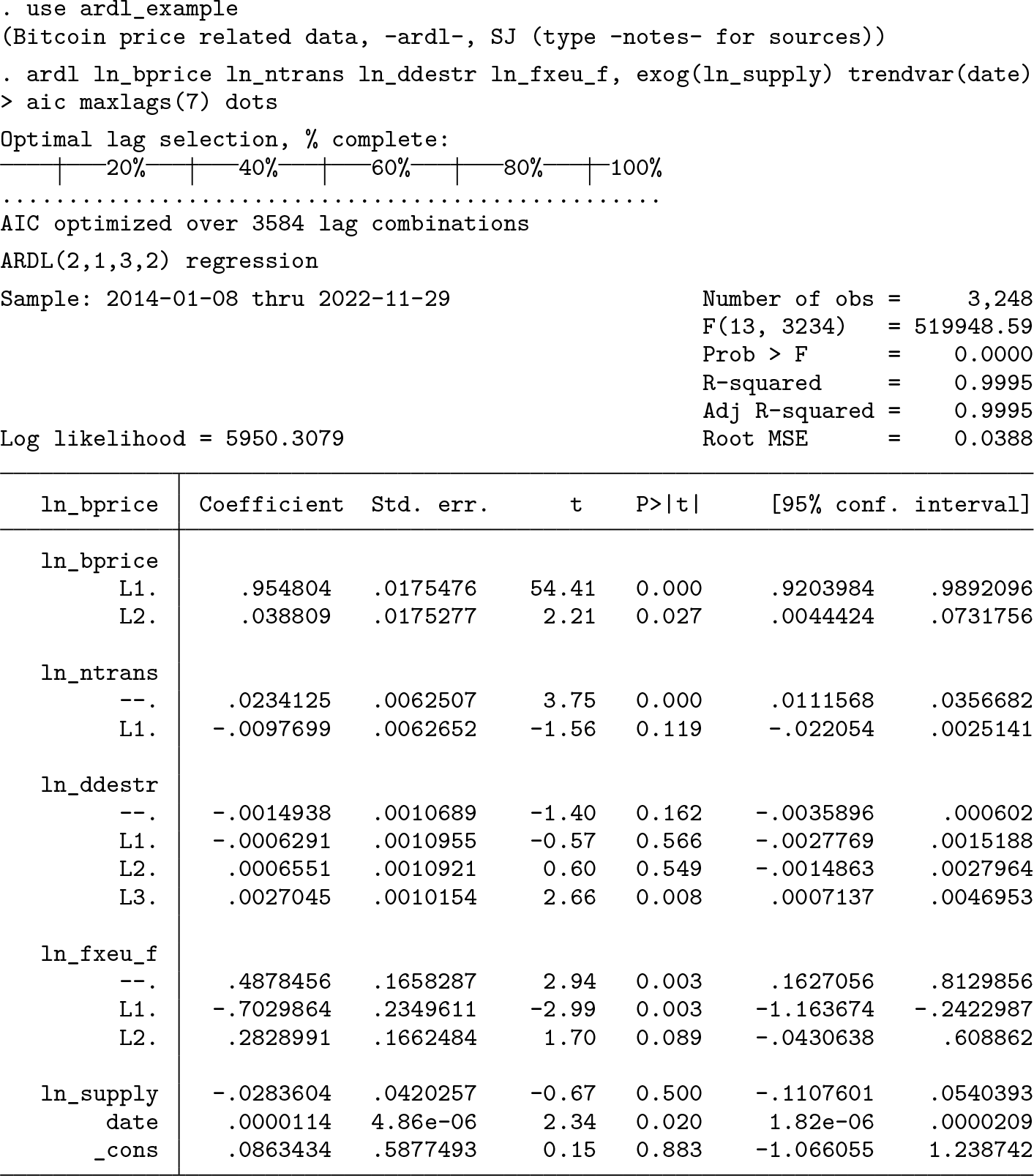
The optimal model chosen by the AIC is an ARDL(2,1,3,2) model.
28
The supply of Bitcoin has no statistically significant effect, which could justify removing this regressor at a later stage. In contrast, the linear time trend, represented by the variable

The Lagrange multiplier test does not provide reason for concern about residual serial correlation. We now refit the model in error-correction form—(6)—using the
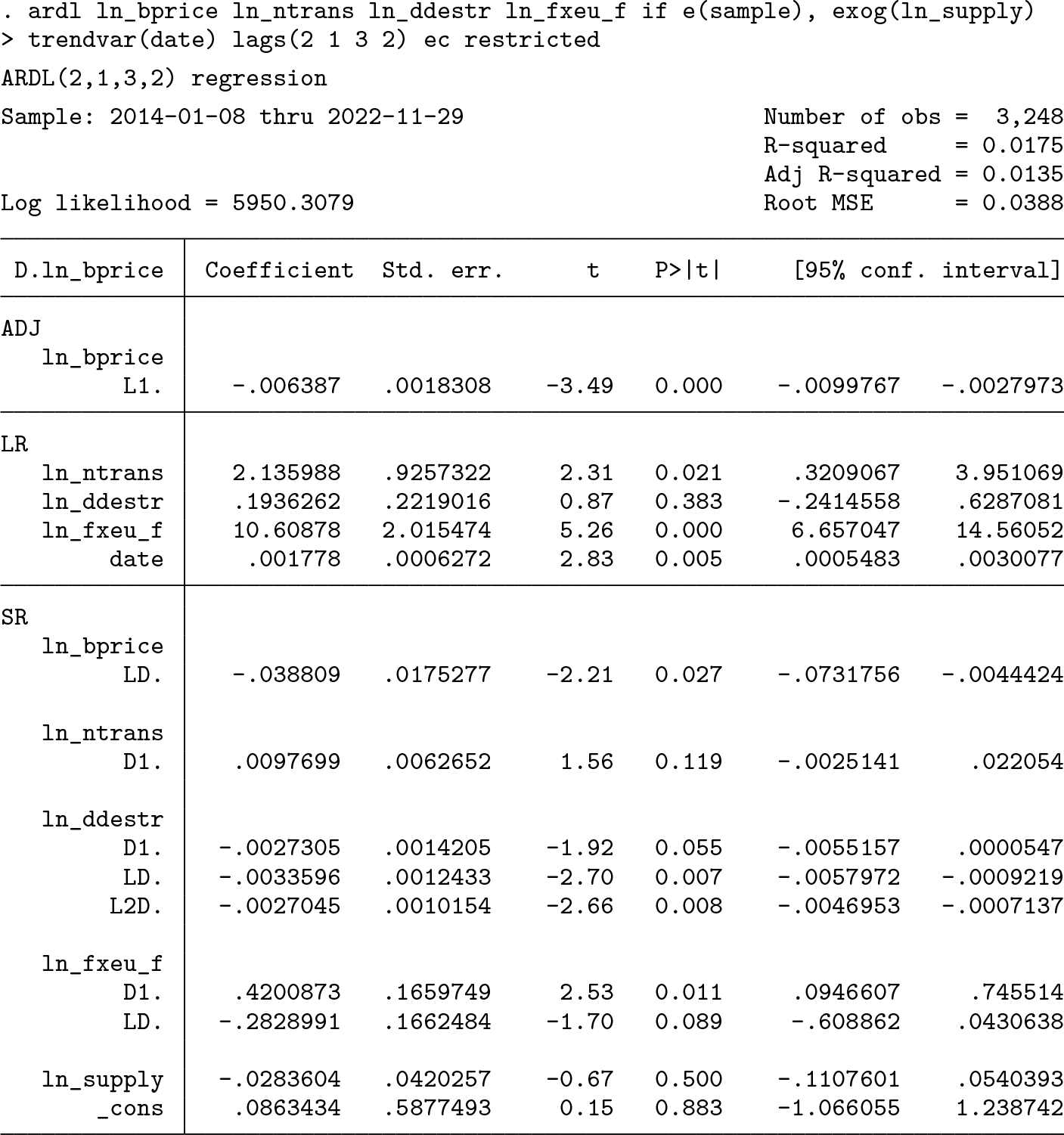
The first coefficient in the

In the top-right corner, the bounds-test output displays the test statistics for the first two testing steps, as outlined in section 2.3. The command reports the Kripfganz and Schneider (2020) CVs for finite samples. However, because of the large sample size, they are virtually identical with the asymptotic CVs.
30
First, we consider the F statistic for the joint null hypothesis πy
= 0,
Second, we need to consider the individual null hypothesis πy
= 0. The test statistic is the same as in the
As we move to a more relaxed stance on the risk of committing a type-I error—rejecting the null hypothesis when it is actually true—the bounds test becomes inconclusive at the 5% significance level. Here the value of the t statistic falls inside the two bounds, although it exceeds the lower bound only narrowly. Given the presence of I(1) independent variables, the evidence still points more strongly toward not rejecting the null hypothesis. When we move further to the 10% level, the test statistic remains within the two bounds. Because the long-run coefficient of the only I(0) variable, coin days destroyed, is statistically insignificant, the upper-bound CV carries much more weight than the lower bound. As a way of resolving this inconclusiveness, we can redo the bounds test for a model without coin days destroyed:

Assuming that all integration orders are known to be I(1), the bounds test still fails to reject the null hypothesis because the t statistic is less negative than the upper-bound CV at all significance levels. At the 5% level, it now even falls short of the lower bound. Consequently, the statistical significance of the long-run coefficients is not informative. Evidence of a cointegrating relationship could not be established. 31
We can cross-check results with the Johansen (1995) framework using the

The t statistic from the bounds test equals the Dickey and Fuller (1979) test statistic. The CVs also virtually coincide.
33
The F test reported by
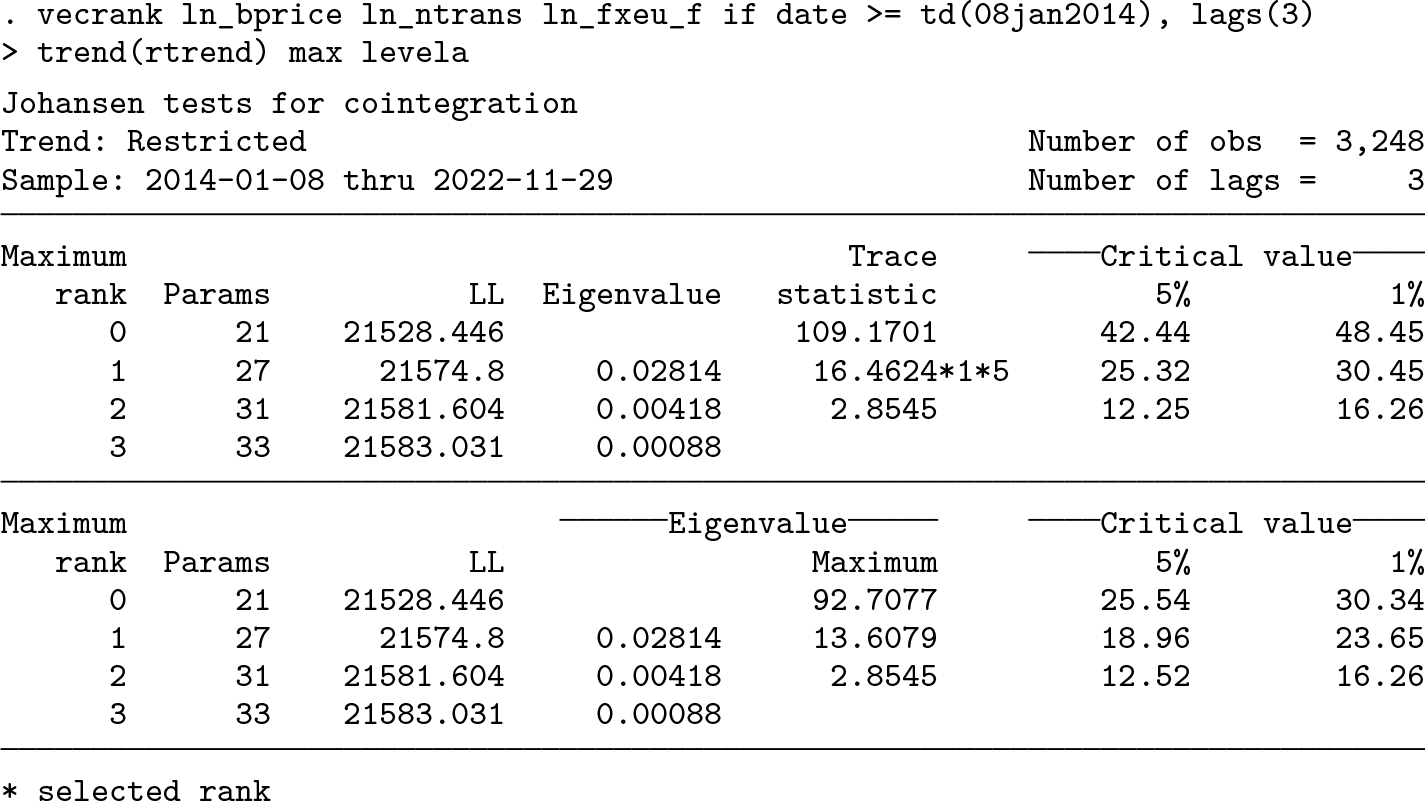
The Johansen (1995) trace and maximum-eigenvalue tests both indicate a cointegration rank of one. However, this is only a necessary but not sufficient condition for the presence of an error-correction mechanism in the process of the log Bitcoin price. 34 In the next step, we fit the VEC model:

Clearly, according to the bottom table for the speed-of-adjustment coefficients, the USD/EUR exchange rate is not loading onto the cointegrating relationship. The respective coefficient for the Bitcoin price is also very small. For practical matters, the Bitcoin price hardly reacts to deviations from the equilibrium relationship. Thus, the statistical question of whether there exists a long-run relationship should not bear too much weight in the final assessment, because it would take a very long time for the Bitcoin price to return to such an equilibrium. Somewhat problematic is the wrong sign of the statistically significant adjustment coefficient for the number of transactions. This points toward an instability in the system. By focusing only on the equation for the Bitcoin price, the ARDL approach avoids this issue. Another disadvantage of the
So far, there is no convincing evidence in favor of a long-run relationship of the Bitcoin price with traditional supply and demand side characteristics. However, the demand for Bitcoin may generally depend on other or additional factors than those for well-established currencies and investment assets. For example, it may depend on how well the cryptocurrency market is understood and trusted by potential investors. Furthermore, macrofinancial developments can affect the willingness to invest in highrisk assets. Ciaian, Rajcaniova, and Kancs (2016) therefore include the number of views of Bitcoin’s Wikipedia page (

To economize on space, we summarize the results for the speed-of-adjustment coefficient (
ARDL long-run estimation results in EC representation

NOTE: Stars indicate the significance level (∗
p < 0.1; ∗∗
p < 0.05; ∗∗∗
p < 0.01.) Conventional p-values for the
In column 3, we exclude the irrelevant oil prices from the model. Despite their insignificant long-run coefficients, we keep the stock market index and coin days destroyed because they still have significant short-run effects. The estimates hardly differ from the previous specification.

Over time, Bitcoin (and cryptocurrencies in general) became more and more accessible to a wider audience and also attracted the interest of professional investors. This may have lead to a gradual change in the fundamental relationship between the Bitcoin price and its determinants. In econometric terms, we may have to worry about parameter instability. Stata offers several diagnostics for structural breaks, which we can use here because the



CUSUM plots
The CUSUM test based on OLS residuals does not trigger a warning sign. In contrast, the test based on recursive residuals rejects the null hypothesis of parameter stability at the 5% significance level. However, because the recursive CUSUM process travels beyond the 95% confidence bounds only very briefly, we may not have to worry too much. Figure 2 shows that the drift away from zero occurs rather gradually over time. This does not suggest a specific date for a structural break, other than that it may have occurred relatively early during our sample period. However, potential break points can be spotted in figure 1. While the Bitcoin supply did not turn out to be a relevant predictor in the earlier regressions, the discrete slowdowns in the mining of new Bitcoin at July 10, 2016, and May 12, 2020—so-called “halving dates” 36 —could possibly have wider repercussions.

Indeed, a parameter stability test with these known structural-break dates rejects the null hypothesis. However, if we restrict the test to the speed-of-adjustment and long-run coefficients, no instability is found. The latter is reassuring regarding our earlier results. Accounting for structural breaks in the short-run coefficients would become a potential issue if we were interested in a more detailed analysis of the short-run dynamics. Nevertheless, as a robustness check, we refit the model by considering only the observations after the first halving date. In another specification, we further curtail the sample with the second halving date.

The main results are shown in columns 4 and 5 of table 1. The effect sizes hardly changed, especially for the speed of adjustment, which is instrumental for existence of an equilibrium correction mechanism. Interestingly though, the bounds test now does conclusively not reject the null hypothesis of no level relationship at least at the 5% significance level. Compared with the specifications in columns 2 and 3, this is mainly driven by the larger standard error of the speed-of-adjustment coefficient, partly because of the smaller sample size. Turning the argument around, the large size of the unrestricted sample—daily observations for almost nine years—previously enabled us to statistically detect (at the 10% significance level) an economically insignificant effect.
As a word of caution, the reliability of the bounds test could be hampered by the nonnormality of the regression errors. Heteroskedasticity and normality tests with the postestimation commands
Overall, based on the results presented here, there do not seem to be strong forces in place that keep the log Bitcoin price in an equilibrium relationship with the candidate long-run forcing variables. Even if we accept column 2 or 3 as our preferred specification and take a liberal stand on the type-I error probability, the economic relevance of the rejected bounds test remains negligible because of the slow speed of adjustment. It appears that the price of Bitcoin is hardly driven by the underlying fundamentals but might be following the path of a predominantly speculative asset. If we accept the statistical conclusion from one of the other specifications that there is no significant long-run relationship present, we could proceed by refitting a more parsimonious version of the model purely in first differences, potentially also using the BIC instead of the AIC as a lag order selection criterion. This could then be used for forecasting purposes or further analyses of the dynamic adjustment processes. For the purpose of this article, however, our curiosity shall end here. 38
6 Conclusion
In this article, we have described the
8 Programs and supplemental material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231212434 - ardl: Estimating autoregressive distributed lag and equilibrium correction models
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231212434 for ardl: Estimating autoregressive distributed lag and equilibrium correction models by Sebastian Kripfganz and Daniel C. Schneider in The Stata Journal
Footnotes
7 Acknowledgments
We thank Michael Binder for his support and guidance during early stages of this project. Moreover, we are grateful for numerous comments and suggestions from the Stata community that helped to improve our
8 Programs and supplemental material
To install the software files as they exist at the time of publication of this article, type