
Abstract
Missing values are common in real datasets, and what to do about them is a large and challenging question. This column focuses on the easiest problems in which a researcher is clear, or at least highly confident, about what missing values should be instead, implying a deterministic replacement. The main tricks are copying values from observation to observation and using the
Keywords
1 Introduction
Missing values are common in real datasets, especially those with many variables or observations. There are just so many reasons why a value may not be on hand. An entry in a data cell of “not available” would often be a euphemism of some kind for (say) person refused to answer, patient too ill, true conditions in that country are a matter of guesswork, firm ceased trading, machine broke, gauge overtopped by flood, observer forgot to write it down, or whatever. What to do about missing values is thus a difficult and challenging question, with answers varying in complexity up to multiple imputation. This column focuses on the easiest problems, in which a researcher knows, or at least is highly confident about, what the answer should be as a nonmissing value. The operations needed all have deterministic flavor, without a whiff of probabilistic variation.
There are two main devices at this easy end to fill in missing values: copying down or forward from observation to observation and using interpolation in its simplest form, namely, linear interpolation as supported by
These problems arise commonly from the very start of anybody’s research with data yet are rarely discussed in statistics texts or courses. One reason for that could be a cultural divide between statistics and numerical analysis making it so that interpolation as a deterministic problem is seen as beyond statistics. Early texts on combination or calculus of observations (for example, Whittaker and Robinson [1924]) and a few statistical texts (for example, Bowley [1901]; Yule [1911]; Davis [1973]; and Pollard [1977]) do bridge the gap in various ways. Another reason could be that details about data quality are somewhere between mildly irritating and highly embarrassing but either way not of central interest. Yet another reason could be that the technique needed seems too obvious or trivial to deserve discussion—once it is understood!
Three simple general points deserve emphasis right now.
Think about infilling graphically. Plotting the data and the results of replacement can give an idea of what to do and of whether what you did makes sense.
Copy original data and work on a clone. When doing this for real with serious datasets, work with copies of the original variables.
Fix any problem with absent values first. The methods here do not themselves fix implicit gaps in the data, a problem better described as one of absent values. Concretely, suppose you have annual values for 2016 and 2020 and wish to infill values for 2017, 2018, and 2019. Then first use a suitable command such as
Related columns include Cox (2002, 2011) and Cox and Schechter (2019).
2 Copying within blocks
A good place to start is when observations occur in blocks but some variable, often an identifier or category variable, is given only for the first observation in each block. Here “observation” in Stata, as usual, means what in other software or from other points of view is regarded as a record, row, or case. In, say, a spreadsheet, it can be tacit that a value applies to rows below until the next such value. In Stata, and in statistical software generally, such values need to be present explicitly.
Working backward, the technique to be explained can be exploited in advance, especially if you or someone working for you is typing in data.
Let’s assume that we are typing in data for some females and some males in blocks of each. We have decided in advance that we will code the difference as 1 for female and 0 for male and will use

In short, each nonmissing value is to be copied to replace the missing values below, stopping at the next nonmissing value or at the end of the dataset. Here is a good answer for this specific problem:

Note that

would have been a better way to start. This method, however, does not generalize well. The problem can be seen by imagining any more complicated setup with several such blocks, so the same remedy would mean typing several such commands. That could be error prone, tedious, and repetitive.
Now and henceforth: If your taste runs to abbreviating command names that can be abbreviated, then you do not have to type out the full command name,
There is a better and more general solution:

In this kind of statement,
An advantage of the
Let’s back up. How does that command work? In the data segment just given, the first missing value is in observation 2, so
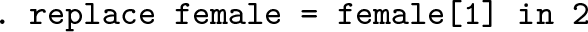
So

But we just changed the value of
3 Panel data or other group data
The structure seen in the previous section is quite common, as is some kind of simple twist on it in which observations are for a set of panels or other groups. Panel or longitudinal datasets often have structures defined jointly by an identifier variable and a time or sequence variable. Similar problems often arise with spatial data with one spatial dimension—going up into the atmosphere, down below the surface, or along a profile or transect. Other kinds of grouped data often have identifiers at two or more distinct levels, say, family and individual.
Our structure might resemble that from

If the problem is to copy the first value forward within each group, we need something more like

or indeed

The tool of choice here is the
What may look to be a different problem—copying one particular value to the rest of a group—turns out to have a very similar solution. We just need to sort that value to a known position, say, so that it becomes the first or last observation in each group. Then we have an easier problem. Suppose that we have family data and want to copy the mother’s age to all observations for a family; we might want to find out how much older or younger everyone else is. A good step forward is to have or get an indicator variable for being a mother.
To make this concrete, consider this toy dataset with family identifier

First, get an indicator with values 0 and 1:

If we

Look at the results:

The code gestures toward more complicated setups by adding
If you are puzzled here by the use of
A trick you may prefer is to have an indicator with values −1 for true and 0 for false. Then, on sorting, the “true” observations go first. Alternatively, you might like to think about using
Naturally, there are yet other ways to solve the problem. From Cox (2011), you can see that

gets you there in one. Other way round, we stop short here of what to do if there are two or more mothers in each family.
4 Reversing time or other order: Negate the key variable
Occasionally, the reverse problem arises—wanting to carry the last value back in time or backward in some other order. At first sight, this goal is frustrated by Stata’s default of implementing commands in observation order—until you realize that reversing time just needs a negated time or sequence variable used temporarily in sorting the data, as in
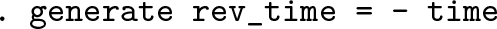
If this seems a little puzzling, we will see an example shortly. The device is obvious once you know but is worth the flag of a section title.
5 Adding caution
The spirit of this column is that a researcher knows, or at least is highly confident, what a missing value should be. Confidence is often tempered with caution, as when you want to fill in values if (and only if) known values on either side of a gap are equal or only within a relatively short interval after the last known value. Let’s take these variations in turn.
5.1 Interpolating only between equal known values
Wanting to build a bridge only between equal values implies that a sequence 1 … 1 should be filled in with values of 1, while 1 … 2 should be left as is. Here dots or periods once more represent missing values. The example best fits, but is not quite limited to, variables that encode categories. The sequence 1 … 2 implies—or leads us to guess—that at some point between the first and the last value, the state jumped from 1 to 2, but we cannot say certainly when that happened.
Here you need contextual information on what is possible, or what is likely, to guide a decision on whether what you do is defensible. If someone was reported as a university graduate in 2016 and in 2020, it is safe to assume that such a person was a graduate in between. We rule out some bizarre scenario in which someone was first stripped of a degree but then got another one anyway. If someone was reported as employed, or employed by a particular company, in 2016 and 2020, but values are missing in between, filling in the gaps is a riskier change. The same would apply to, say, owning a car in between.
Suppose we decided to fill in anyway, so long as values are the same on either side of a gap. One way to do this is to interpolate forward and backward and use the interpolated values only if methods agree. That is, 1 … 1 is interpolated as 1 1 1 1 1 either way, but 1 … 2 is mapped to 1 1 1 1 2 by forward copying and to 1 2 2 2 2 by backward copying, so methods disagree. Another way to do it is to use linear interpolation as well as forward copying and again to accept interpolated values if and only if methods agree.
Let’s make that concrete. Like much in school mathematics, these problems characteristically appear trivial when solved but tricky before you have gotten there. If you wish to experiment yourself, the dataset is bundled with the media for this column.

This worked example raises some crucial points.
Most pertinently here,
Note that needing to interpolate separately within groups or blocks of observations is only a little more challenging than if the dataset is in effect one group or block. Both
A historical aside:
More importantly, you will see that
In sum, checking that interpolation is acceptable only when it yields constants can be done by checking copying forward, either with copying backward or with linear interpolation. Either way, if the results are the same, you are good, as with

or

5.2 Interpolating only for shorter periods
Caution often exercised is to fill in missing values only if the last known value was close in time or close as measured some other way. In homely terms, the notion is that one might stretch evidence but only so far. Quite what the cutoff or threshold should be is up to the researcher and can be anything from a wild guess to something reflecting knowledge or understanding of a process. Let’s revisit our previous example and invoke a rule that we will copy for at most two years. That is, we have to tell Stata when to stop the cascade of replacements.
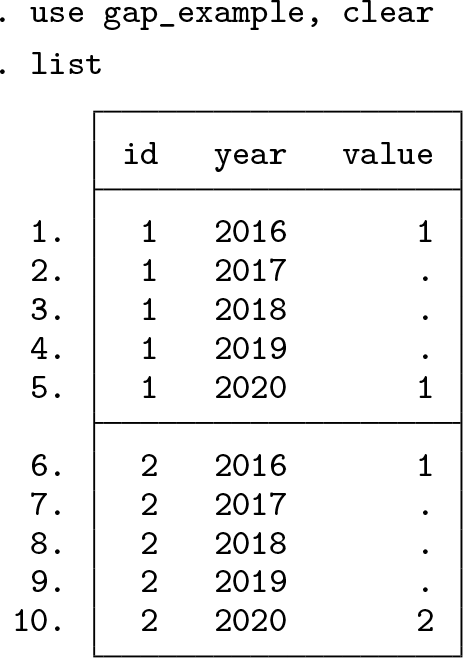
A solution grows out of keeping track of when we last knew a value. Again, this can be calculated using our trick of copying forward.

Now we copy downward within our cautious limit:


A little thought shows that this method also works with an irregularly spaced time or other position or sequence variable, as would be typical of much data on patients seen at various times and indeed in many other examples.
Modification to copy backward once more just requires a reversing of time or of the relevant variable.
6 Increasing or decreasing linear sequences
A different case in which we can be clear what the missing value should be is when a variable should increase linearly. If we wanted to type in a sequence of years, we could type

and follow with

That will be recognized as just a variation on the now familiar trick of copying downward. Adding 1 is what to do if you need it; adding 10 could make sense for a series of census years given the common practice of holding a census once a decade.
This solution does not exclude others, naturally, such as
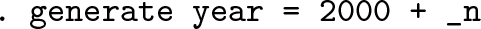
or use of the
All of these devices extend naturally to datasets with group structure, such as panel or longitudinal data.
A related problem has to do with people’s ages, which unsurprisingly (should) increase by 1 each year. Hence, missing values on age can be interpolated with reference to a yearly date variable. There can be small stuff to reckon with, such as people forgetting or being less than candid on how old they are or survey waves being implemented at differing times of year and so before or after people’s birthdays in each year. For these and other reasons, plotting age against year is often a good idea, although doing that for many different people can be a challenge.
The section title mentions decreasing sequences, just a variation in principle, if less common in practice.
7 Conclusion
Missing values are common in real datasets. What to do about them is a large and challenging question. This column has surveyed the easiest problems in which a researcher is clear, or at least highly confident, about what missing values should be instead, implying a deterministic replacement.
Major tricks and tips include copying values from observation to observation, exploiting the fact that using a being willing to negate time or some other position or sequence values to copy backward in a dataset; satisfying constraints that interpolation is confined to filling gaps between known equal values or to observations within a certain distance between known values in time or some other sequence or position variable; and adapting these ideas to increasing or decreasing sequences to be used in infill.
Supplemental Material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231196519 - Speaking Stata: Replacing missing values: The easiest problems
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231196519 for Speaking Stata: Replacing missing values: The easiest problems by Nicholas J. Cox in The Stata Journal
Footnotes
8 Acknowledgments
Many questions on Statalist and Stack Overflow helped to identify common problems and to indicate that something like this might be helpful.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.