
Abstract
Interaction analyses are useful tools to examine complex socioeconomic outcomes in which the effect of one variable depends on the presence or values of another variable. Interaction effects capture simultaneous changes in two (or more) covariates, and their computation is especially challenging in nonlinear models. For such models, a statistically significant interaction-term coefficient does not necessarily indicate significant interactive effects. For analyses in which the interaction effect cannot be inferred from the model estimates, I introduce
Keywords
1 Introduction
Interaction analyses are used to examine complex socioeconomic outcomes in which the effect of one variable depends on the presence or values of another variable.
1
For example, to assess whether the 2008 financial crisis had a more pronounced effect on minorities, in a regression analysis, we would interact (that is, multiply) the indicator of minority status with that of the before- and after-2008 periods. In linear models, the coefficient on the interaction term can be used to infer whether the effect of the treatment variable is statistically different at alternative values of the moderating variable. For instance, if the interaction coefficient were to reach the conventional levels of statistical significance, we would conclude that the 2008 crisis had a statistically different effect on majority and minority groups. In nonlinear models, however, the coefficient on the interaction term does not tell us the direction, magnitude, or significance of the interaction effect (Ai and Norton 2003). For analyses in which the interaction effect cannot be inferred from the model estimates, I introduce
2 What is an effect and how do we calculate it?
Broadly speaking, the interaction effect is the change in the effect of a given variable as another variable also changes. Before considering two simultaneous changes, I briefly review what an unconditional effect is and how it is computed. Let us say our dependent variable y depends on the independent variable of interest, x, and a vector of other covariates plus the constant term,
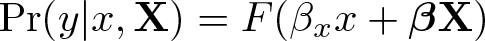
where F (·) is the (possibly nonlinear) link function of model predictors. 2 The effect of x on y is the change in Pr(y) attributable to a change in x. There are two general approaches to computing the effect of x, which I denote by Δ(x). One alternative is to calculate the first difference, which is the change in Pr(y) associated with an n-unit increase in x (frequently a one-unit increase), Δ(x) = {Pr(y|x + n) − Pr(y|x)}. This is the default approach for factor variables, in which case the effect is the discrete change from the base level. For example, if x is a dummy variable, the discrete difference is Δ(x) = Pr(y|x = 1) − Pr(y|x = 0).
For continuous variables, researchers can alternatively compute the instantaneous rate of change, which is the partial derivative with respect to x, Δ(x) = {∂Pr(y)}/(∂x). This estimate can then be used to calculate the impact on y of a very small increase, say, 0.001, in x. 3 In this case, Pr(y) would increase by about 0.001 × Δ(x). In practice, however, many analysts extrapolate and interpret the value of Δ(x) as representing the change in y associated with a one-unit increase in x. In many (but not all) instances, this is a good approximation. In nonlinear models, there is no guarantee that a one-unit increase in x would lead to a change in y of 1 × Δ(x). In fact, substantive deviations are likely when x is measured in large units (Williams 2012, 2021).
Turning to interactions, let us say we have a multiplicative model where two independent variables, x 1 and x 2, are interacted. In this case, the predicted value of y is

One can use either the partial derivative or the first difference to compute the simultaneous changes in x 1 and x 2. Specifically, the interaction effect can be computed as the cross-partial derivative with respect to both variables, {∂ 2Pr(y)}/(∂x 1∂x 2), or as the discrete difference between two first differences, {Pr(y|x 1 + n 1; x 2 + n 2) − Pr(y|x 1; x 2 + n 2)} − {Pr(y|x 1 + n 1; x 2) − Pr(y|x 1; x 2)}. Technically, they are both valid approaches. From a purely practical perspective, the first-difference approach has several advantages. First, it does not require complex math, because we need to compute predicted probabilities only for alternative values of x 1 and x 2. By contrast, taking the cross-partial derivative is a challenging task even for relatively simple likelihood functions and may be intractable for complex ones. Second, it is easier to explain what the interaction effect represents in substantive terms when using clearly defined increments (for example, a one-unit increase). By contrast, partial effects reference an undefined “very small” amount. 4
3 The ginteff command
3.1 Description
3.2 Syntax

3.3 Options
Short descriptions of the
The

3.4 Stored results

4 The ginteffplot command
4.1 Description
4.2 Syntax
4.3 Options
Short descriptions of the
The

5 What is new or different with ginteff?
In this section, I first compare and contrast
5.1 Comparing ginteff with community-contributed commands
There are two community-contributed commands for calculating interaction effects, that is,
This said,
Technicalities aside, the substantive difference between
Each approach comes with its own advantages and disadvantages. The case-level approach entails computing the interaction effect separately for each individual observation. Because it reveals the heterogeneity of individual effects, this approach can prevent gross generalizations. The alternative approach is to aggregate the individual effects and report the average. The advantage is that we can make inferences about a variable’s effect in the population or specific subgroups. This approach is particularly useful when individual cases are anonymous and do not carry special meaning. For example, when examining the effect of an initiative to increase voter turnout, it is the average response that is of immediate interest. In fact, a report that focuses on individuals’ idiosyncratic responses may be of little practical relevance to policymakers.
It is beyond the scope of this article to compare the two approaches. In practice, their usefulness depends on the research question and type of data (for example, the voting record of the nine U.S. Supreme Court justices or a large population survey). Importantly,
5.2 Comparing ginteff with Stata’s official commands
Most
Ultimately, having a specialized command to compute interaction effects minimizes mistakes.
6 Interpreting interaction effects
Before showing how
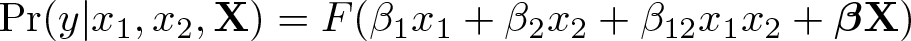
For dummy variables, the marginal effect is the first difference, that is, the change in Pr(y) in the presence and absence of that variable. In practice, this means calculating F(β
1x
1 + β
2x
2 + β
12x
1x
2 + β

What does the interaction effect, {Δ2Pr(y)}/(Δx
1Δx
2), mean in substantive terms? To answer this question, we need to understand what each of the four elements on the right-hand side of (1) represents. To make the interpretation more concrete, let us assume we want to assess the effect of gender and race on health. Among other determinants, one’s health is a function of both gender (
For our example, we can write the probability of being in good health as

where h is the health indicator, f stands for female, and r stands for race. When we replace y with h, x 1 with f, x 2 with r, and F(·) with Λ(·), the four right-hand-side elements of (1) become

To help with the interpretation, I note in curly braces what each element means in terms of predicted probabilities. For example, (2) captures the probability of being in good health (h = 1) for a woman (f = 1) who is a member of a racial minority (r = 1). Similarly, (3) captures the probability of being in good health for a woman who is a member of the majority group (r = 0), and so on. For convenience, I will reference the respective probabilities by the corresponding equation number (that is, PrEq. (2), PrEq. (3), PrEq. (4), and PrEq. (5)).
Without altering the result, we can rearrange the four probabilities as the difference between two distinct differences: (PrEq. (2) − PrEq. (4)) − (PrEq. (3) − PrEq. (5)). The first parenthetical statement, (PrEq. (2) − PrEq. (4)), captures the difference in the probability of being healthy between a minority female and a minority male. Put differently, this is the effect of gender on health for racial minorities. The second parenthetical statement, (PrEq. (3) − PrEq. (5)), captures the difference in the probability of being healthy between a woman and a man from the majority group. Thus, this is the effect of gender on health for the racial majority. Finally, the difference in the effect of gender between the minority and majority groups is the interaction effect. Substantively, it captures the relative strength of the two gender effects. For instance, a positive value on the interaction effect would indicate that the effect of gender on well-being is more pronounced for minorities than for the majority group. 9
The interpretation of the interaction effect would be similar if gender were interacted with a continuous variable such as age. In this case, the interaction effect would capture the relative strength of the two gender effects attributable to an n-unit increase in age. More specifically, we would compare the effect of gender between the current group of respondents and a counterfactual group where respondents were one year older (assuming the standard one-unit increase in x).
Last, we could also have an interaction between two continuous variables, say, age and income (measured in thousands of dollars). In this example, the interaction effect would capture the effect on health of a one-unit increase in income (that is, $1,000) attributable to a one-unit change in respondents’ age. More specifically, we would compare the effect of increasing the respondents’ income by $1,000 with the effect of the same income bump for a counterfactual group where respondents were one year older. 10
7 Computing interaction effects with ginteff
I illustrate the capabilities of the
7.1 A binomial logit example
For this exercise, I use a dichotomous indicator of health coded 1 if the respondent’s health is above average and 0 otherwise. Specifically, the dummy DV is obtained by collapsing the poor, fair, and average levels into one category and the good and excellent levels into another category.
After getting the data, I first fit an additive logit model with no interactions as a reference point. The coefficient on

I plot the
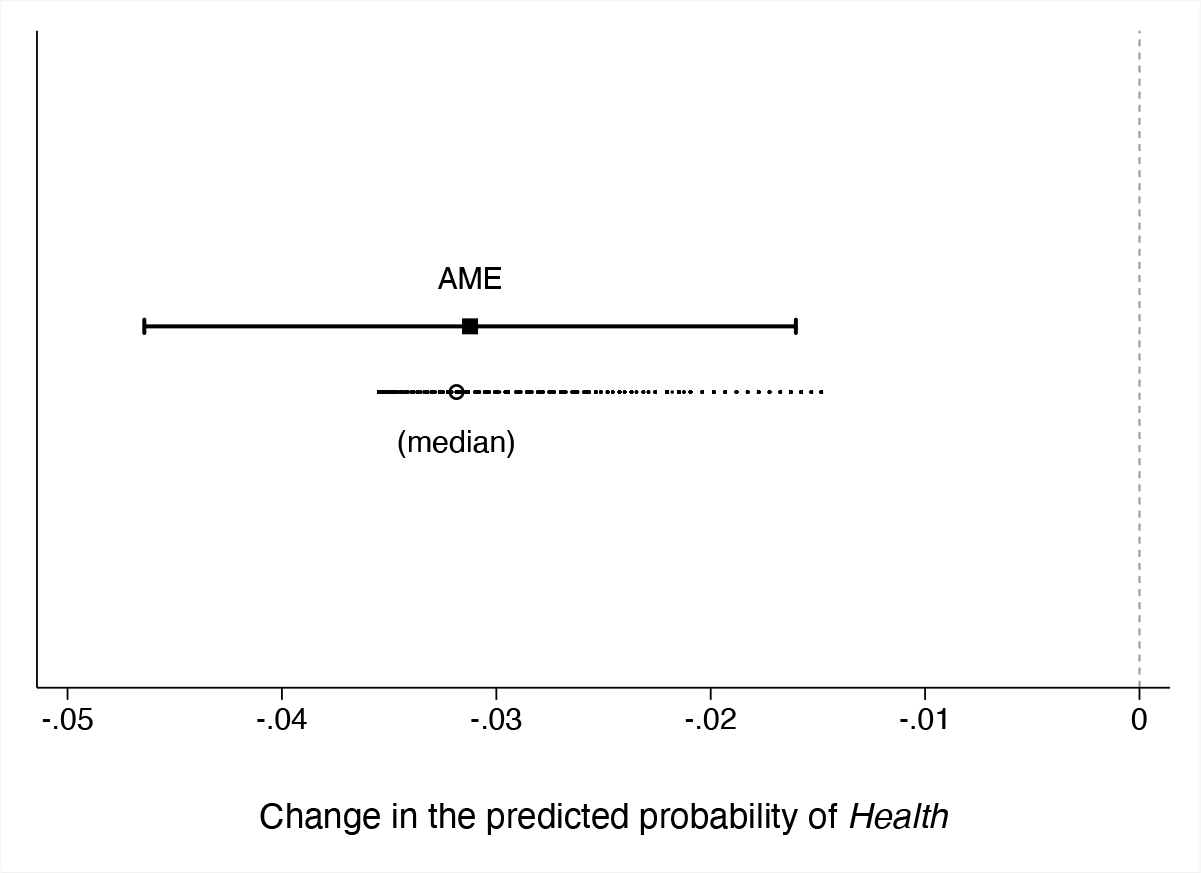
The marginal effect of gender on health (dichotomous indicator)
Next I fit a new model where

Before moving to interpreting and presenting the results, let us examine the
The next lines introduce the interacted variables, x
1 and x
2. (For three-way interactions, there will also be an x
3 variable.) For each individual variable, the associated line lists its full name and details how its effect, Δ(x
∗), is computed. Let us consider x
2, which corresponds to variable
The next line of the output notes the number of observations used in the calculation. The last part of the output header spells out the expression of the response for which the effect is calculated. For our example, this is the probability of a positive outcome, Pr(
When the analyst calculates the interaction effect for multiple
The results table shows the value of four estimates: the average interaction effect, its standard error, and the lower and upper limits of the associated CI. These are the table columns. Each row is associated with a distinct interaction effect, and the respective label clarifies the specific scenario. In our example, there are two outputs, one for each contrast of
In figure 2a, I graph the estimated average and individual interaction effects separately for both outcomes. Plotting the
The
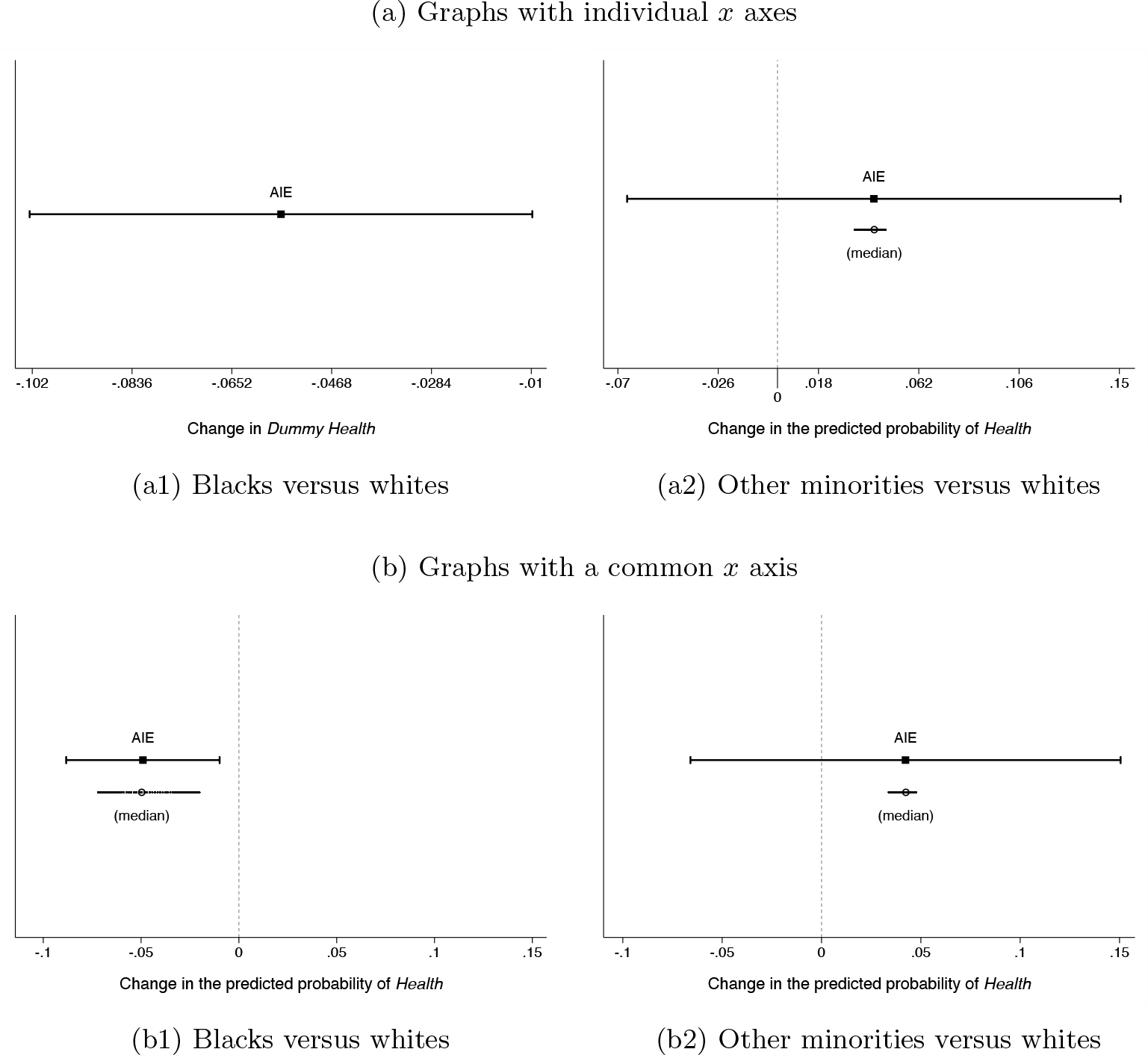
The interaction effect between gender and race on health (dichotomous indicator)
By contrast, women from racial groups other than black seem to fare better than white women. Specifically, the positive estimate in figure 2a2 indicates that the negative effect of gender on health is smaller for minority respondents. However, this effect is not statistically significant. Compared with figure 2a1, this graph has several extra features. First, the x title is more informative because it spells out what the outcome metric is, namely, predicted probability. Second, the plot displays a vertical line at the zero value to more easily judge whether the interaction effect is statistically significant. Third, it reports the full range of individual effects for all cases in the data with the median value superimposed. Because the individual effects are clustered and the median and mean values are very similar, the average represents a good measure of central tendency in this case. The command line to produce the enhanced figure 2a2 is

Option
By default, the

Having the graphs on the same scale facilitates comparisons across outcomes and scenarios, but this should not be taken as a definitive significance of differences test. Specifically, when the CIs of two point estimates overlap, the estimates may or may not be different from one another (Goldstein and Healy 1995; Radean Forthcoming; Schenker and Gentleman 2001). Importantly, this is the case even if the point estimates have different signs and only one of them is statistically significant (Gelman and Stern 2006). This is the situation in our example because the two interaction effects are −0.056 [−0.102, −0.010] and 0.042 [−0.066, 0.151]. When the CIs overlap, the solution is to conduct a standard significance of differences test. For that, we need to first save the results, along with the estimated variance–covariance matrix in
To illustrate this procedure, I reissue the previous

7.1.1 An ordered logit example
One of the advantages of


Let us consider the same two-way interaction between
Figure 3 graphs the
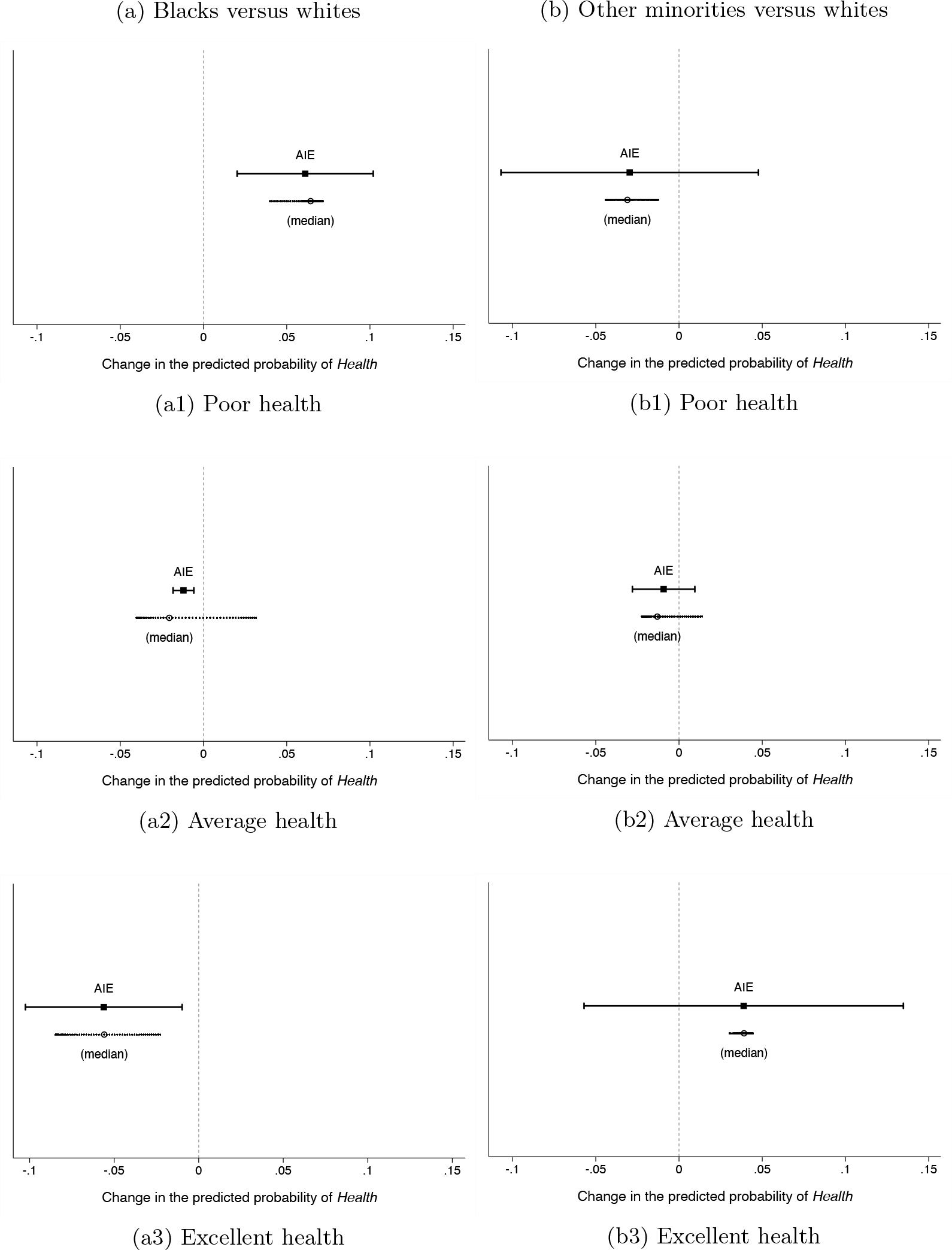
The interaction effect between gender and race on health (three-level indicator)
8 The interaction effect in practical applications
When assessing conditional hypotheses, researchers are typically interested in whether the treatment effect is constant across the levels of the moderator. The quantity of interest in such analyses is the interaction effect because it can provide the answer to the research question for linear and nonlinear models alike. Because of theoretical confusion or a lack of knowhow to compute the interaction effect, many analysts try to get at the interaction without computing the interaction effect. Resorting to heuristics or work-arounds, however, invites mistakes.
A common misconception is that we can draw valid inferences about the significance status of the interaction effect from the statistical significance level of the interaction term coefficient. In nonlinear models, however, a statistically significant interaction term is neither necessary nor sufficient for significant interactive effects. Conflating the interaction effect with the coefficient on the interaction term is another frequent misunderstanding. This is partly because, in a linear regression, the interaction effect is equal to the coefficient on the product term; that is, {∂Pr(y)}/(∂x 1∂x 2) = β x 1 x 2 . But this is not the case for nonlinear models.
Because of the erroneous association, questions about the coefficient on the interaction term are often misguided questions about the interaction effect. The many Statalist entries on this topic attest to how acute the problem is (for example, Statalist thread [2016, 2017a,b] to reference a few). Specifically, “[p]eople often ask what the ME [marginal effect] of an interaction term is […even though] there is not one” (Williams 2012, 329) and are willing to go to great lengths to obtain it. 15 For example, to force an estimate for “the average marginal effect of the interaction,” one user proposed forgoing the Stata operator for interactions and manually generating the product between the interacted variables. Thus, instead of running the proper command

the user suggested the following work-around:

By defrauding
With respect to the practical challenges of computing the interaction effect, some struggle to account for the simultaneous change in the second interacted variable. Let us look at a concrete example. Radean (2019) examines the interaction effect between office benefits and ideological preferences on the probability of party switching in Brazil. The dependent variable is coded 1 if a legislator who is a member of party A affiliates midterm with party B and 0 otherwise.
Because
The solution to all the problems discussed above is to compute the interaction effect—a task made easy by the
8.1 Replication of a previous study
In this section, I illustrate one type of substantive findings that could be missed if researchers overlook the interaction effect. To do so, I replicate an analysis from Heller and Mershon (2005) on the effect of the electoral system and party discipline on party switching.
16
The electoral system is made operational in terms of partyversus candidate-centered electoral rules. While the electorates vote for an individual candidate in candidate-centered electoral systems, they cast a party vote in party-centered systems (implicitly voting for all candidates on that party’s list). The
Furthermore, the degree of party-label clarity (that is, information about the party’s policy stance) is used as a proxy for party discipline (that is, the control that party leaders exercise over the rank-and-file members). When party labels are clear, there is less uncertainty about the policy preference of party leadership. When the labels are blurry, legislators may sometimes find themselves at odds with their party’s position. Thus, leaders of parties with blurry labels have to enforce party discipline more frequently, which increases a legislator’s incentives to switch.
In terms of theoretical expectations, representatives elected under candidate-centered rules should be less likely to switch. Because voters can single them out on the ballot at the next election, they have higher incentives to keep faith with the electorate. By contrast, legislators elected on (closed) party lists are to some extent insulated from voter retribution. The underlying assumption here is that the electorate prefers loyal representatives, who do not jump ship when a better offer comes along. The negative effect of candidate-centered rules on the probability of party switching should be more pronounced in the context of clear party labels because the costs of strict party discipline are less onerous in this context (Heller and Mershon 2005, 538–539).
The output below replicates the logistic regression from Heller and Mershon (see model 3, table 4, 550). With a p-value of 0.274, the coefficient on the interaction term is far from the conventional levels of statistical significance. Based on this information, the authors infer that there is little empirical support for the conditional hypothesis and do not investigate further. Specifically, they do not compute either the marginal effect of the electoral system or the interaction effect. 17
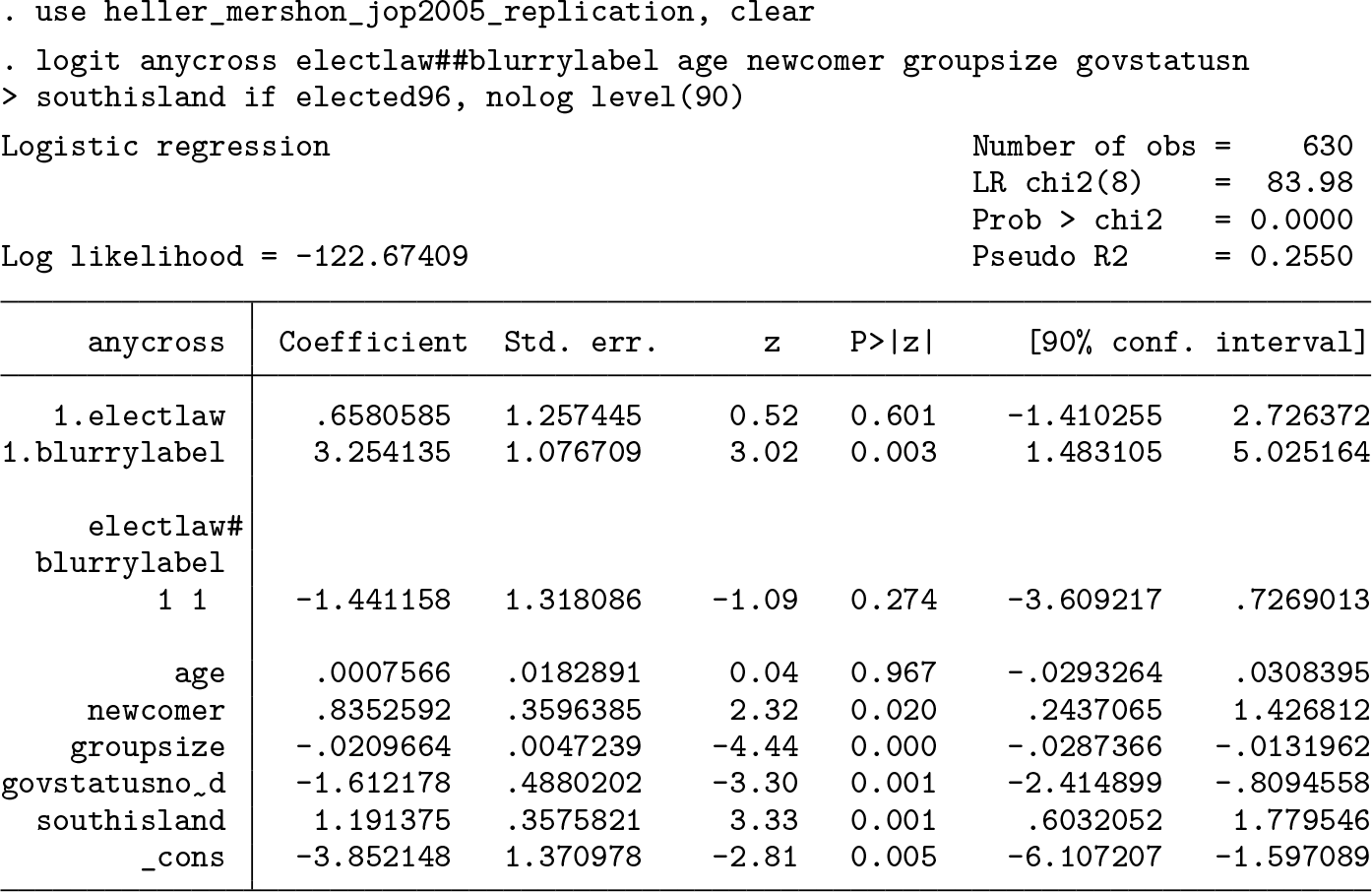
But, in a logit model, a statistically significant interaction term is not necessary for significant interactive effects (Ai and Norton 2003; Berry, DeMeritt, and Esarey 2010). To elucidate the matter, I first compute the marginal effect of the electoral system for both types of party labels using the

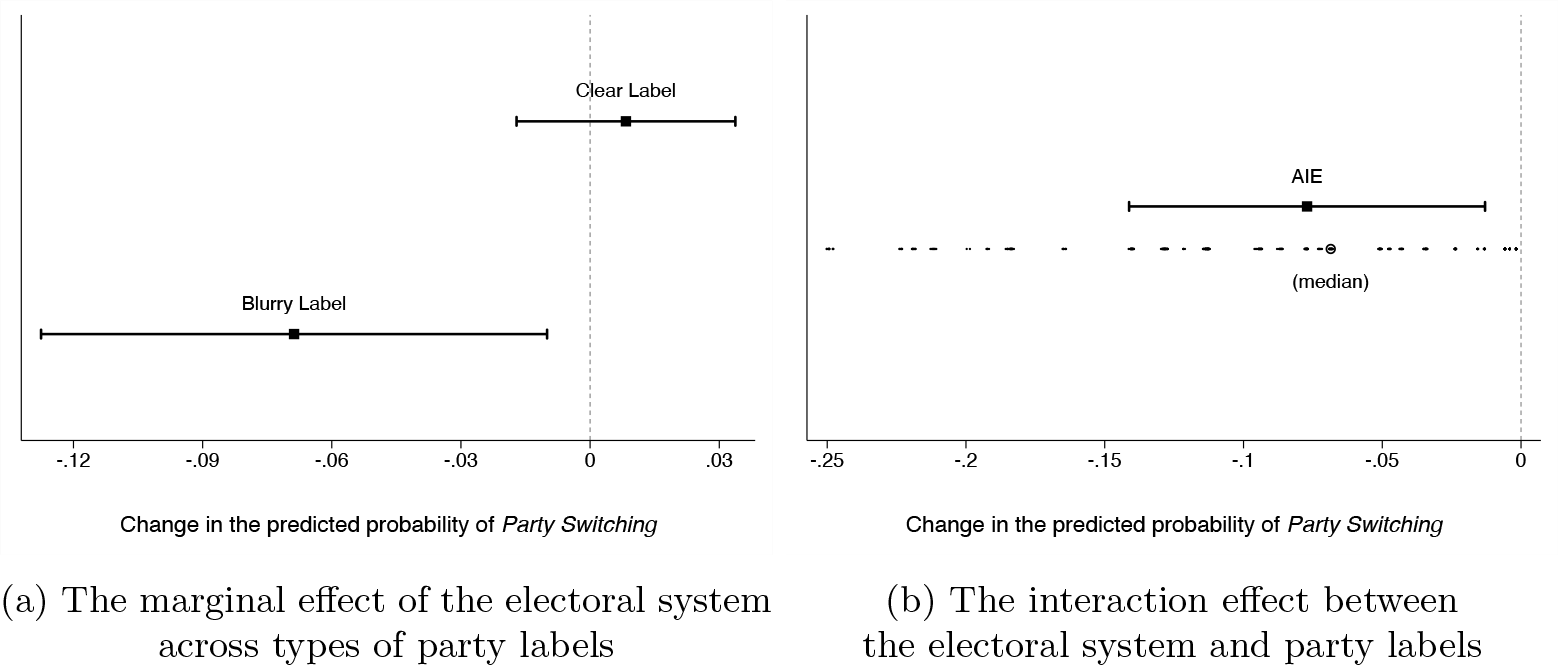
The effect of the electoral system on party switching
The statistically significant interaction effect (graphed in figure 4b) indicates that the effect of the electoral system on party switching is in fact distinct between clear and blurry party-label scenarios. Thus, the authors were too quick to dismiss the idea that party-label clarity conditions the effect of electoral rules. This is a piece of information that cannot be gleaned from either the logit coefficients or the conditional effects. More generally, there are cases where only by computing the interaction effect can we ascertain whether the treatment effect varies significantly with the levels of the moderator. In sum, by overlooking the interaction effect, we ignore crucial evidence for testing conditional hypotheses, which can lead to us either understating or, more problematically, overstating the extent of the empirical support for our theories.
8.2 Alternative approaches for continuous-by-continuous interactions
Besides computing the interaction effect, there are other options to explore how two continuous variables interact. One alternative is to plot the marginal effect of x 1 across the range of the moderating variable x 2, [Pr(y|x 1 + n; x 2 = min) − Pr(y|x 1; x 2 = min)] ,…, [Pr(y|x 1 + n; x 2 = max)] − Pr(y|x 1; x 2 = max) (see Brambor, Clark, and Golder [2006]). Marginal-effect graphs are useful for outlining the trajectory of the conditional effect but are not designed to compare the effect of x 1 at alternative values of x 2. Specifically, if there is overlap between the CIs of the effect of x 1 at the minimum and maximum values of x 2, we cannot tell whether the effect changes significantly with x 2.
To illustrate the problem, let us consider a logistic regression with a dummy health indicator and a continuous-by-continuous interaction between

Examining continuous-by-continuous interactions
Heat maps are another popular approach to examine continuous-by-continuous interactions (see Huber [2017]). This type of plot graphs the predicted probability of y across the range of both x
1 and x
2. The benefit of such graphs is that they cover a wide range of feasible values. Because no individual probabilities are identified, though, heat maps do not typically reveal the estimated uncertainty. Thus, we cannot judge whether a given change in predicted probability is statistically significant. Illustrating this problem, figure 5b graphs the predicted probability of being healthy across the range of both
Unlike other empirical approaches, the interaction effect allows us to directly assess whether the change in the effect of x 1 due to x 2 also changing is statistically significant. Thus, it can be used to assess interactive theories. In fact, establishing whether the treatment effect is distinct at different values of the moderator is the crux of conditional hypothesis testing.
9 Conclusion
Interaction analyses are useful tools to examine complex socioeconomic outcomes where the effect of one variable depends on the presence or levels of another variable. Interaction effects capture the simultaneous change in two (or more) covariates, and their computation is challenging for models with a nonlinear link function (for example, binomial logit or probit) or models involving auxiliary parameters (for example, the correlation parameter in bivariate probit, the cutpoints in ordered logit, etc.). To complicate matters, in nonlinear analyses, the coefficient on the interaction term does not tell us the direction, magnitude, or significance of the interaction effect. For analyses where the interaction effect cannot be inferred from the model estimates, I introduce a new command that automatically computes two- and three-way interaction effects.
Last, it is important to acknowledge that
Concerning unmodeled terms, Beiser-McGrath and Beiser-McGrath (2020) show that omitted product terms can bias the included terms.
19
As a possible solution, the study considers a suite of parametric and nonparametric estimators (that is, the adaptive lasso, kernel regularized least squares, and Bayesian additive regression trees). The advantage of these estimators is that they can select the covariates that belong in the model from a very large set of potential controls without leading to overfitting. One drawback is that they are more conservative; that is, the CI of relevant terms more frequently includes zero (729). Based on Monte Carlo simulations, the authors conclude that, on average, the adaptive lasso is the best approach. If using an alternative estimator, the analyst has to compute the interaction effect by hand while accounting for any constraints associated with that estimator.
20
If the results from the alternative estimator and those from the standard model are substantively similar (that is, there are no omitted relevant terms), researchers may use
Many researchers take for granted that model assumptions hold in their particular application without assessing the validity of these assumptions. But, when this is not the case, the estimates may be fragile and model dependent. This in turn can lead to incorrect inferences. Hainmueller, Mummolo, and Xu (2019) show that this is so even for the more innocuous case of linear regression. Specifically, the authors consider two common assumptions: 1) the linear interaction effect changes at a constant rate with the moderator, and 2) there is sufficient common support in the data to compute valid conditional effects. Based on a literature survey, they find that these assumptions often fail in practice, so they propose some diagnostics. A binning estimator (where a continuous moderator is broken into several bins) can provide a sense of the effect heterogeneity. It may also alert the analyst if the data are sparse. Another diagnostic tool is the kernel smoothing estimator. This estimation strategy relaxes the linearity assumption and estimates a flexible functional form of the treatment effect across the moderator’s range. If the diagnostic tests reveal that model assumptions hold, the research can compute the interaction effect using
Even if we have the appropriate research design and our model is correctly specified, we still need to exercise caution when computing substantive quantities of interest. We often make assumptions not only at the estimation stage but also in the postestimation phase. The latter type of assumption may be underappreciated but is equally important to obtain practically meaningful estimates. As an example, consider the oft-used fixed-effects logit model, which can be easily fit in Stata via the

where (eβ)/(1 + eβ) is the standard logistic cumulative distribution function, αi is the individual effect, i indexes individuals, and Ti is the number of observations on each individual. Fixed-effects models are attractive because they can account for time-invariant, unobserved individual characteristics. This in turn minimizes the risk that the coefficients on the observed predictors (the βs) are affected by the omitted variable bias. The downside is that we cannot make valid inferences about quantities of interest that require estimates of the fixed effects. The problem is that it is not possible to estimate αi consistently when Ti is fixed (for a formal discussion, see Greene [2004, 106]). Providing the intuition for why adding more data cannot solve the problem, Wooldridge (2020, 467) explicates that “as we add each additional cross-sectional observation, we add a new αi. No information accumulates on each αi when T is fixed.”
This means we cannot compute predicted probabilities or partial effects unless we choose an arbitrary value for α. There is no optimal a priori value “[b]ecause the distribution of αi is unrestricted—in particular, E(αi) is not necessarily zero” (Wooldridge 2010, 558).
21
But this is exactly what is typically assumed. Case in point, the
11 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231175253 - ginteff: A generalized command for computing interaction effects
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231175253 for ginteff: A generalized command for computing interaction effects by Marius Radean in The Stata Journal
Footnotes
10 Acknowledgments
The author thanks Daina Chiba, the editor of the Stata Journal, and an anonymous reviewer for helpful comments and suggestions.
11 Programs and supplemental materials
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.