
Abstract
In this article, we introduce the
In addition, the
We show that when one imposes zero factors, the
Keywords
1 Introduction
The common factor approach is highly popular among panel-data practitioners because it offers a wide scope for controlling for omitted variables and rich sources of unobserved heterogeneity, including models with cross-sectional dependence; see, for example, Chudik and Pesaran (2015), Juodis and Sarafidis (2018), and Sarafidis and Wansbeek (2012, 2021).
For panels where both of the cross-sectional and time-series dimensions (N and T, respectively) tend to be large, popular estimation approaches have been developed by Pesaran (2006) and Bai (2009) known in the literature as common correlated effects (CCE) and iterative principal components (IPC). Both methods involve least squares and project out the common factors using either cross-sectional averages of observables or principal-components analysis (PCA). To date, CCE and IPC have been applied to a large range of empirical areas and have been extended to several additional theoretical settings; see, for example, Su and Jin (2012), Moon and Weidner (2015, 2017), Baltagi, Ka, and Wang (2021), Harding, Lamarche, and Pesaran (2020), Kapetanios, Serlenga, and Shin (2021), and Li, Cui, and Lu (2020), among others.
Recently, Norkute et al. (2021) and Cui et al. (2020) developed a general instrumental-variables (IV) approach for estimating panel regressions with unobserved common factors when N and T are both large. The underlying idea is to project out the common factors from exogenous covariates using PCA and to construct instruments from defactored covariates. This first-stage IV (1SIV) estimator is consistent. In a second stage, the entire model is defactored based on factors extracted from the first-stage residuals, and IV regression is implemented again using the same instruments.
The resulting two-stage instrumental-variables (2SIV) approach combines features from both Pesaran (2006) and Bai (2009). In particular, following Pesaran (2006), the covariates of the model are assumed to be subject to a linear common factor structure. However, following Bai (2009), the common factors are projected out using PCA rather than cross-sectional averages. A major distinctive feature of 2SIV is that it eliminates the common factors from the error term and the regressors separately in two stages. In comparison, CCE eliminates the factors from the error and the regressors jointly, whereas IPC eliminates only the factors in the error.
2SIV is appealing for several reasons. First, CCE and IPC suffer from incidental parameters bias because an increasing number of parameters needs to be estimated as either T or N grows; see Westerlund and Urbain (2015) and Juodis, Karabiyik, and Westerlund (2021). Therefore, bias correction is required to ensure that inferences remain valid asymptotically. In contrast, 2SIV does not require bias correction in either dimension. This property is important because approximate procedures aiming to recenter the limiting distribution of particular estimators may not be able to fully eliminate all bias terms, especially those of high order; in such cases, substantial size distortions can occur in finite samples. Second, the CCE approach requires the so-called rank condition, which assumes that the number of factors does not exceed the rank of the (unknown) matrix of cross-sectional averages of the unobserved factor loadings. 2SIV does not require such a condition because the factors are estimated using PCA rather than cross-sectional averages. Third, the 2SIV objective function is linear in the parameters, and therefore the method is robust and computationally inexpensive. 1 In comparison, IPC relies on nonlinear optimization, and therefore convergence to the global optimum might not be guaranteed (Jiang et al. Forthcoming). Fourth, 2SIV shares a major attractive feature of CCE over IPC because it permits estimation of panels with heterogeneous slope coefficients. Last, 2SIV allows for endogenous regressors, so long as external instruments are available.
In this article, we introduce a new command,
We show that when one imposes zero factors and requests the 1SIV estimator, the
We illustrate the method with two examples. First, we use a panel dataset consisting of 300 U.S. financial institutions, each one observed over 56 time periods. We attempt to shed some light on the determinants of banks’ capital adequacy ratios. The results are compared with those obtained by using popular panel methods, such as the fixed-effects and 2SLS estimators, as well as the CCE estimator of Pesaran (2006). In the second example, we use macrodata used by Eberhardt and Teal (2010) for the estimation of cross-country production functions in the manufacturing sector. The dataset is unbalanced, containing observations on 48 developing and developed countries during the period 1970 to 2002.
The remainder of the article is organized as follows. Section 2, outlines the 2SIV approach developed by Norkute et al. (2021) and Cui et al. (2020) and discusses implementation with unbalanced panel data. Section 3 describes the syntax of the
2 IV estimation of large panels with common factors
2.1 Models with homogeneous coefficients
We consider the following autoregressive distributed lag panel-data model with homogeneous slopes and a multifactor error structure: 2

and

|α| < 1,
The vector of regressors

Stacking the T observations for each i yields
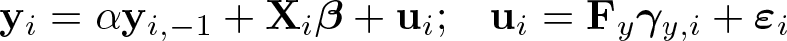
where

where
Let

The 2SIV approach involves two stages. In the first stage, the common factors in
In the second stage, the entire model is defactored based on estimated factors extracted from the first-stage residuals, and another IV regression is implemented using the same instruments as in stage one.
2.1.1 First-stage IV estimator
Define
Consider the following empirical projection matrices:
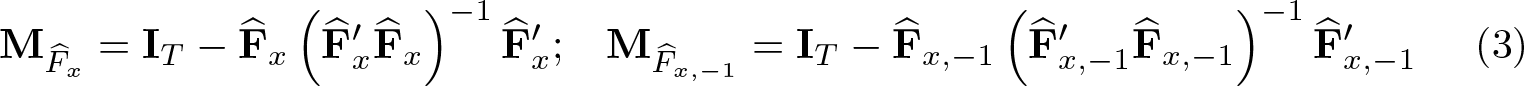
In this case, the matrix of instruments can be formulated as

which is of dimension T × 2K. Thus, the degree of overidentification of the model is 2K − (K + 1).
The 1SIV estimator of θ is defined as

where

The 1SIV estimator is

as N and T grow jointly to infinity, that is,

2.1.2 Second-stage IV estimator
To implement the second stage, extract estimates of the space spanned by

Subsequently, the entire model is defactored, and a second IV regression is run using the same instruments as in stage one.
In particular, let

where
The (optimal) second-stage IV estimator is defined as

where

and

As shown by Norkute et al. (2021),
normally distributed, such that

as
Notice that the limiting distribution of

In this case, proposition 3.2 in Cui et al. (2020) reveals that the second-stage estimator is asymptotically equivalent to a least-squares estimator obtained by regressing

The overidentifying restrictions J-test statistic associated with the second-stage IV estimator is given by

where
The overidentifying restrictions test is particularly useful in this approach. First, it is expected to pick up a violation of the exogeneity of the defactored covariates with respect to the idiosyncratic error in the equation for
2.2 Models with heterogeneous coefficients
We now turn our focus on models with heterogeneous coefficients. Let

where
The IV estimator of θi is defined as

where
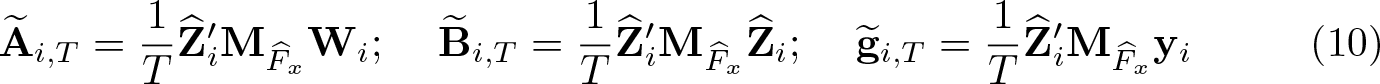
The mean-group instrumental-variables (MGIV) estimator of θ is

As shown by Norkute et al. (2021), as

and

where

Note that the overidentifying restrictions test statistic is not valid for the model with heterogeneous coefficients. 9

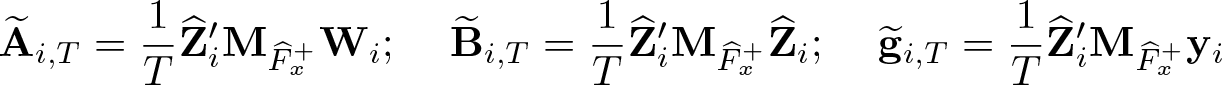
where
2.3 Unbalanced panels
When the panel-data model is unbalanced, that is, some observations are missing at random, our procedure needs to be modified to control for the unobserved common factors. Following Stock and Watson (1998) and Bai, Liao, and Yang (2015), we may distinguish between
Let
In the first iteration, the values of the regressors are set such that

The factors in the first iteration,

where
Subsequent iterations are based on
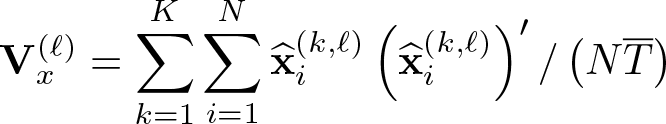
for ℓ > 1, until convergence. The convergence criterion is defined with respect to the objective function

where
The initial factor values are determined using a similar eigenvalue problem as outlined previously, this time based on

with the (j 1 , j 2) entry being divided by the number of summands used when this number is larger than zero.
The same procedure is followed when extracting factors from lagged values of
3 The xtivdfreg command
3.1 Syntax
3.2 Options
display_options:
3.3 Stored results

4 Examples
4.1 Example 1: Estimation of the determinants of banks’ capital adequacy ratios
In this example, we illustrate the
We focus on the model

where i = 1,…, 300 and t = 2,…, 56. All data are publicly available, and they have been downloaded from the Federal Deposit Insurance Corporation website.
13
CAR
it
stands for “capital adequacy ratio”, which is proxied by the ratio of tier 1 (core) capital over risk-weighted assets. size
it
is proxied by the natural logarithm of banks’ total assets. ROA
it
stands for the “return on assets”, defined as annualized net income expressed as a percentage of average total assets. liquidity
it
is proxied by the loan-to-deposit ratio. Note that higher values of this variable imply a lower level of liquidity.
Finally, the error term is composite; ηi
and τt
capture bank-specific and time-specific effects,
Some discussion on the interpretation of the parameters that characterize (12) is useful. The autoregressive coefficient, α, reflects costs of adjustment that prevent banks from achieving optimal levels of capital adequacy instantaneously. βk , for k = 1,…, K(= 3), denote the slope coefficients of the model. β 1 measures the effect of size on capital adequacy behavior. Under the “too-big-to-fail hypothesis”, large banks may count on public bailout during periods of financial distress, knowing that they are systematically very important (for example, Cui, Sarafidis, and Yamagata [2020b]). Essentially, this hypothesis reflects the classic moral hazard problem, where one party takes on excessive risk, knowing that it is protected against the risk and that another party will incur the cost. Under such a scenario, β 1 is expected to be negative.
β 2 measures the effect of profitability on capital adequacy. Standard theory suggests that higher bank profitability dissuades a bank’s risk taking, and thus it is associated with larger capital reserves because profitable banks stand to lose more shareholder value if downside risks realize (Keeley 1990). On the other hand, more profitable banks can borrow more and engage in risky activities on a larger scale under the presence of leverage constraints (Martynova, Ratnovski, and Vlahu 2020). A positive (negative) value of β 2 is consistent with the former (latter) interpretation. Lastly, the direction of the effect of liquidity, β 3, is ultimately an empirical question as well. For instance, a positive value indicates that lower liquidity levels force banks to increase their capital reserves, arguably to reduce risk exposure.
We start by running the
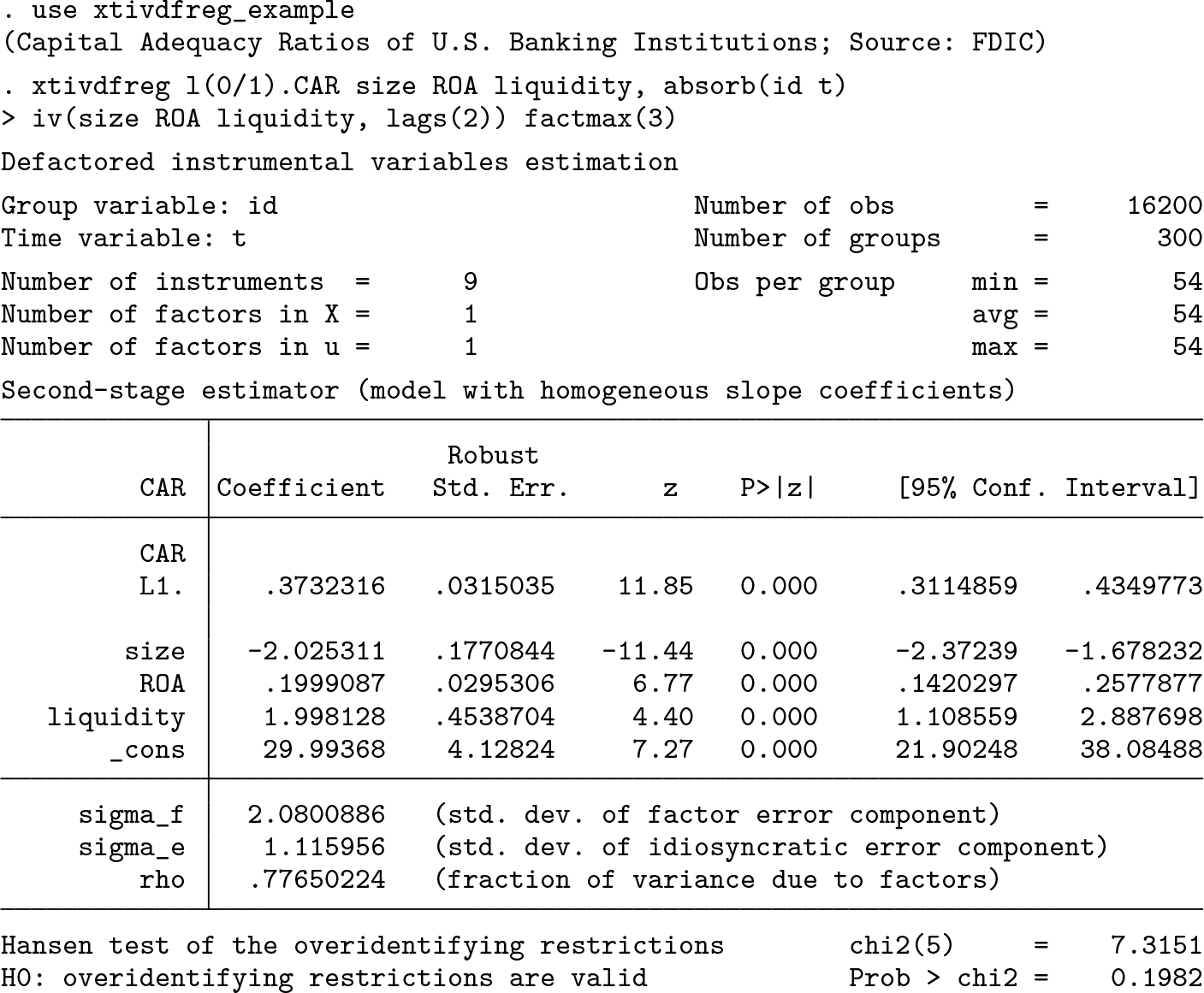
To illustrate the specification of the command in terms of the notation used in the article, let

which is of dimension T × 3K, with
All coefficients are statistically significant at the 1% level. Moreover, the p-value of the J-test statistic suggests that the overidentifying restrictions (instruments) are valid. The estimated number of factors in the first and second stages equals 1 in both cases; that is,
The estimated autoregressive coefficient equals about 0.373, which suggests medium persistence in the
Finally, note that
Next we fit the same model, except that the slope coefficients are allowed to be heterogeneous:

uit
has the same structure as before. This regression is computed by adding the option

As we can see, the estimated coefficients are similar to those obtained from the model that pools the data and imposes slope parameter homogeneity. This is not surprising, because otherwise failure to account for slope parameter heterogeneity would invalidate the overidentifying restrictions, thus likely leading to a rejection of the null hypothesis for the J statistic. Thus, conditional on common factors, bank-specific and time-specific effects, slope parameter heterogeneity does not appear to be relevant in the present sample.
In what follows, we examine alternative specifications for
Estimation results
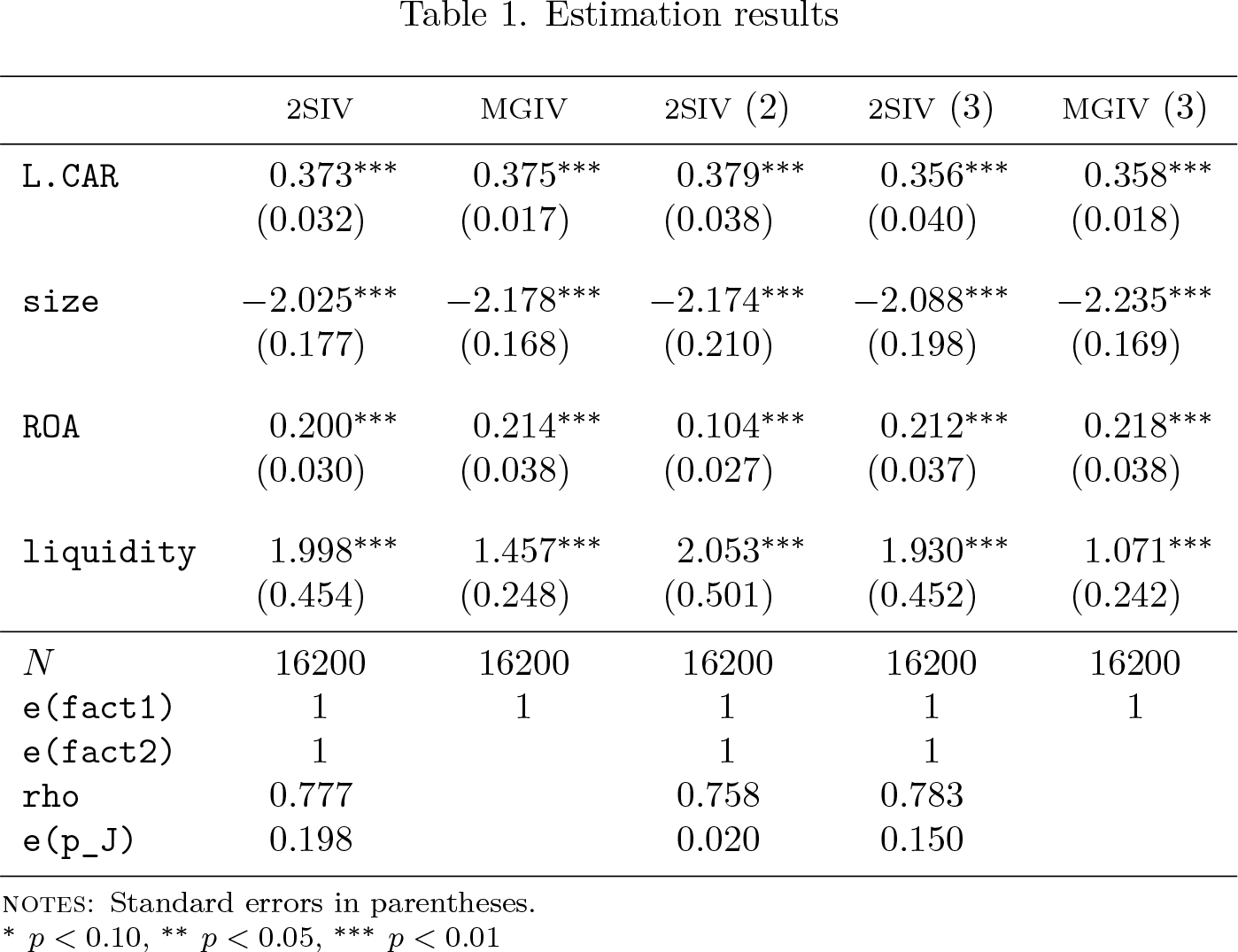
NOTES: Standard errors in parentheses.
∗ p < 0.10, ∗∗ p < 0.05, ∗∗∗ p < 0.01
Columns 3–5 illustrate examples of IV estimators that allow for a more flexible specification of instruments than the baseline regression. In particular, column 3 shows results for a second-stage IV estimator that involves dropping

The results in column 3 are similar to the baseline specification in column 1, except for the coefficient of
Column 4 corresponds to a second-stage IV estimator that we can compute by typing

In this specification, {

As we can see, the output of columns 4–5 is similar to that reported in columns 1–2, respectively. Therefore, the estimates appear to be fairly robust to different choices of instruments.
In terms of the notation used in the article, the choice of instruments corresponding to columns 4–5 is given by

where
In practice, users can avoid extracting factors jointly from the matrix of all covariates. For motivation, suppose that

Defactoring of
The columns in table 2 report results for several alternative popular estimators. To begin with, columns 1–2 correspond to the standard fixed-effects and 2SLS estimators, both of which accommodate a two-way error-components model, but they do not allow for common shocks:

Estimation results (continued)

notes: Standard errors in parentheses.
∗ p < 0.10, ∗∗ p < 0.05, ∗∗∗ p < 0.01
It is apparent that the estimated coefficients differ substantially compared with those obtained based on the 2SIV approach. In particular, the autoregressive coefficient appears to be biased upward, and—for the case of 2SLS (column 2)—the standard error of the estimate is much larger compared with the second-stage IV (see column 1 of table 1). On the other hand, the coefficients of
Column 3 reproduces the results of 2SLS using the

Thus, the popular 2SLS estimator can be viewed as a special case of the 2SIV approach and arises by imposing zero number of factors (that is, setting

Finally, the last two columns correspond to the CCE estimator of Pesaran (2006). CCEP in column 5 denotes the pooled CCE estimator, and CCEMG in column 6 is the mean-group CCE version. These have been computed using the

As we can see, the estimates of CCEP are smaller than those obtained by the secondstage IV estimator (columns 1 and 4 of table 1), and the differences are statistically significant. On the other hand, the estimates of CCEMG are fairly close to those of the MGIV estimator in most cases. The main exception is the coefficient of

Hence, one can also use leads by typing

where

To achieve equivalence in that case, exclude the lags or leads from the second defactorization, as follows:

4.2 Example 2: Estimation of cross-country production functions
To illustrate additional features of the

Following Eberhardt and Teal (2010), we focus on the following model, which imposes constant returns to scale:

The dependent and independent variables denote the log value added per worker and the log capital stock per worker, respectively, for i = 1,…, 48, with each country observed over Ti observations.
We start by running the

Because the panel is unbalanced, the
The estimated coefficient of ln(K/L) is approximately equal to 0.5 and is statistically significant. The p-value of the J-test statistic indicates that the overidentifying restrictions are supported by the data. Moreover,
Note that the number of lines of dots not only is a function of the number of lags used as instruments but also depends on whether factors are extracted jointly or individually for each regressor separately. For illustration, consider a similar model as in (13) but without imposing constant returns to scale:

We specify the

This time, the number of dotted lines corresponding to factor estimation from the covariates has doubled. This is because the factors are extracted separately for ln (L) and ln (K), and therefore the algorithm performs twice the number of iteration loops.
MGIV estimation of the baseline regression in (13) is computed by typing

As we can see, the estimate of the coefficient of ln(K/L) is similar to that of the homogeneous model. 17 For further analysis using this example, see Eberhardt and Teal (2010).
5 Conclusion
Supplemental Material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211045558 - Instrumental-variable estimation of large-T panel-data models with common factors
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211045558 for Instrumental-variable estimation of large-T panel-data models with common factors by Sebastian Kripfganz and Vasilis Sarafidis in The Stata Journal
Footnotes
6 Acknowledgments
We are grateful to an anonymous referee for providing useful comments and suggestions. Vasilis Sarafidis gratefully acknowledges financial support from the Australian Research Council under research grant number DP-170103135.
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
To update the
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.