
Abstract
We describe a new command,
Keywords
1 Introduction
The power of a randomized controlled trial or similar experiment is the probability that the primary analysis will show a statistically significant result in favor of the studied treatment (or other intervention). Designers of randomized controlled trials (which we henceforth simply call “trials”) typically aim to have 80% or 90% power for a given true treatment effect. Sample-size calculations are used to determine either the sample size required to give a specified power or the power implied by a specified sample size. Various formulas are in wide use (Julious 2009).
The most common sample-size calculation is for comparing two groups, treatment and control, also called “arms”. Multiarm trials improve efficiency by evaluating several new treatments in one trial (Parmar et al. 2017) and are usually designed using a two-group sample-size calculation, assuming that each treatment group will be compared with the control group. Sample-size calculations for general tests of heterogeneity between treatment groups are rarely used and are not discussed in this article.
In Stata, several standard sample-size calculations are available in the built-in
However, none of these packages allows for an ordered categorical outcome, sometimes called an ordinal outcome. Such outcomes have been used, for example, in a trial evaluating treatments for influenza, where a six-category outcome was defined as 1) death, 2) in intensive care, 3) hospitalized but requiring supplemental oxygen, 4) hospitalized and not requiring supplemental oxygen, 5) discharged but unable to resume normal activities, or 6) discharged with full resumption of normal activities (Davey et al. 2019).
The present work was motivated by the need to consider the use of ordered categorical outcomes in a proposed trial of treatments for COVID-19, for example, a three-level outcome of death, in hospital, or alive and not in hospital. Other trials of treatments for COVID-19 have used various outcome scales, typically with six to eight ordered categories.
In this article, we introduce a new command,
2 Methods
2.1 General sample-size formulas
Suppose the benefit of treatment is captured by an estimand θ (for example, a risk difference or log odds-ratio) so that the analysis of a superiority trial involves a significance test of the null hypothesis θ = 0. The designers of the trial want to ensure a high power, defined as the probability of a significant result, under the assumption that θ = d. Sample-size formulas relate the type II error (β = 1 − power) to the sample size n when the type I error is set to α. A general sample-size formula relates the required variance of an estimator

where zp
is the standard normal deviate with cumulative density p. Because var(

The formula above implicitly assumes that the variance is the same under the null and alternative hypotheses, and this is not true for categorical outcomes. For example, for binary data, binomial variation follows distributions with different probabilities in the two groups, but under the null hypothesis, the average probability is assumed for both groups. We refine (1) by letting var(

Let var(

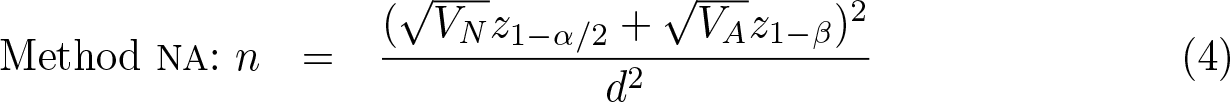

For binary data, these formulas are commonly used with the estimand θ defined as the risk difference.
2.2 Whitehead’s method
We use the equations above in the specific case of an ordered categorical outcome Y and randomized treatment Z. Let the distribution of Y in the control group be p(Y = i|Z = c) = pci , and let the distribution of Y in the experimental (research) group be p(Y = i|Z = e) = pei , for i = 1,…, I. We initially assume for definiteness that outcome level 1 is the least favorable and level I is the most favorable and that the aim of the study is to demonstrate lower probabilities of the worse outcomes in the experimental group.
Whitehead (1993) considered the case where the n participants are randomized to control and experimental groups in the ratio a: 1 and the distributions of the outcome in the two groups obey a proportional-odds model,

for any k = 1,…, I−1 (McCullagh 1980). Here θ is the log odds-ratio, which is assumed common across levels k. θ < 0 indicates lower probabilities of the less favorable outcomes in the experimental group and hence a beneficial treatment. This led to the formula

where
This is a good and widely known formula. However, it has three limitations. First, it requires a common odds ratio to be specified at the design stage. In our experience, clinicians sometimes propose that treatments will reduce the risk of adverse outcomes by a fixed risk ratio so that pei /pci is the same for all i < I. This does not provide a value θ. Second, the expression used for the variance V is valid only under the null, so (7) represents method NN, and other methods may be more accurate; Whitehead (1993) discussed alternatives. Third, the formula does not cover noninferiority trials (see section 2.4 below). Our new proposal addresses these limitations.
2.3 New proposal
We propose a new method of sample-size determination that is valid for arbitrary sets of (pci, pei
) that may not obey the proportional-odds model. The idea is to evaluate VN
and VA
by constructing a dataset of expected outcomes and fitting the proportional-odds model with the
We construct a dataset containing the expected outcomes per participant recruited. This contains two records for each outcome level: one for the experimental group and one for the control group. For each record, we compute the probability that a participant is randomized to that group and has his or her outcome at that level. For the control group, for outcome level i, this probability is p(Z = c)p(Y = i|Z = c) = apci /(a + 1). For the experimental group, this probability is p(Z = e)p(Y = i|Z = e) = pei /(a + 1). These probabilities sum to 1.
We perform an
For methods NN and NA, we change the weights to their values under the null,
2.4 Noninferiority trials
In a noninferiority trial, the null hypothesis is that the experimental treatment is worse than the control treatment by a prespecified amount m, termed the margin. The margin typically represents a small degree of worsening of the primary outcome that is judged to be acceptable because of other advantages of the experimental treatment that are not captured by the primary outcome. In the setting of a categorical outcome ordered from least (1) to most (I) favorable outcome, the margin is expressed as an odds ratio greater than 1, and m > 0 is the log odds-ratio. The null hypothesis is then θ = m, and the alternative hypothesis is θ < m. Typically, the investigators expect the true treatment effect to be 0, so that pei = pci for all i and d = 0, but some noninferiority trials are designed under the expectation that the experimental treatment is somewhat beneficial and so d < 0 (for example, Nunn et al. [2019]).
The expected (alternative) variance of the estimate is given in the same way as for a superiority trial, but the test (null) variance must be calculated differently to reflect the noninferiority null. This is easily done in the

Steps 1 and 2 are unchanged. At step 3, we fit model (6) to the dataset of expected results per participant under the null θ = m by using the
These methods also apply without modification to a substantial-superiority trial, in which the aim is to show that the experimental treatment is substantially superior to the control; this is implemented by setting the margin m < 0. A substantial-superiority trial requires a larger sample size than a superiority trial with the same expected treatment effect.
2.5 Risk difference, risk ratio, or odds ratio
The odds ratio is often a sensible estimand for an ordered categorical outcome because it is plausibly constant across different levels [k in (6)], unlike the risk difference and risk ratio. For a binary outcome, this issue does not arise, and the risk difference or risk ratio is usually preferred because of its simpler interpretation (Altman, Deeks, and Sackett 1998).
In the binary outcome case, we may ask how sample-size calculations with the different estimands compare. In a superiority trial, all estimands imply the same null hypothesis—that the two treatments are equal. Sample-size calculations with different estimands then address the same question but use different approximations:
3 Syntax
3.1 Options
3.2 Favorable and unfavorable outcomes
The user is recommended to specify whether the leftmost levels of the outcome are favorable or unfavorable. However, the program also works this out for itself. In a superiority trial, an expected odds ratio smaller (larger) than 1 implies an unfavorable (favorable) outcome. If the margin is specified, then the criterion is whether the expected odds ratio is smaller or larger than the margin. If the user has specified the
4 Examples
4.1 Six-level outcome
We reproduce the sample-size calculation for the FLU-IVIG trial (Davey et al. 2019). The control arm is expected to have a 1.8% probability of the least favorable outcome (death), a 3.6% probability of the next worst outcome (admission to an intensive care unit), and so on. The trial is designed to have 80% power if the treatment achieves an odds ratio of 1.77 for a favorable outcome. We invert this to match the assumption above of an unfavorable outcome.
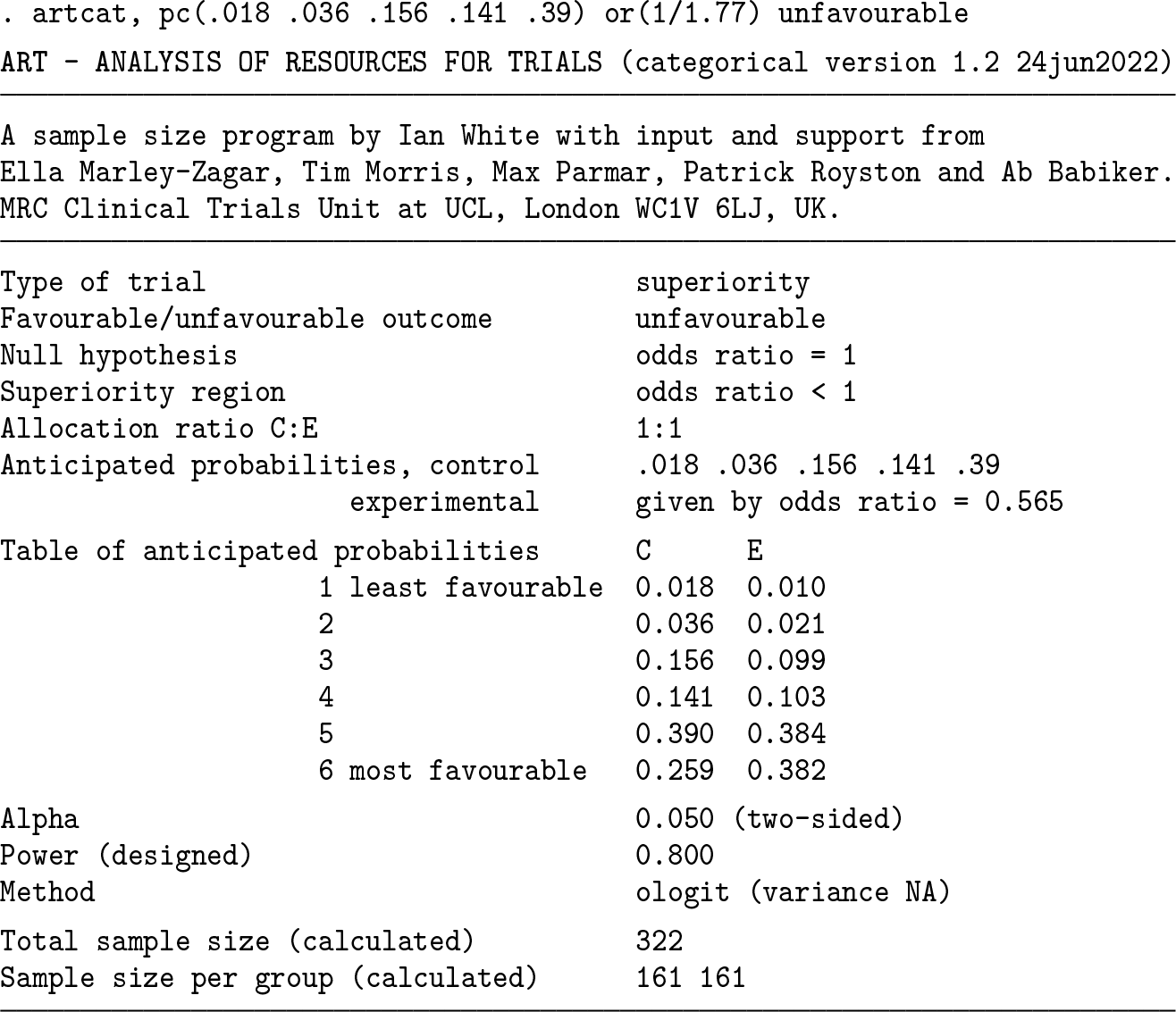
A total sample size of 322 participants (in both trial arms combined) is required. Below, we get the same answer by reversing the order of levels and hence focusing on favorable outcomes. The last probability could be omitted in the syntax. We use the
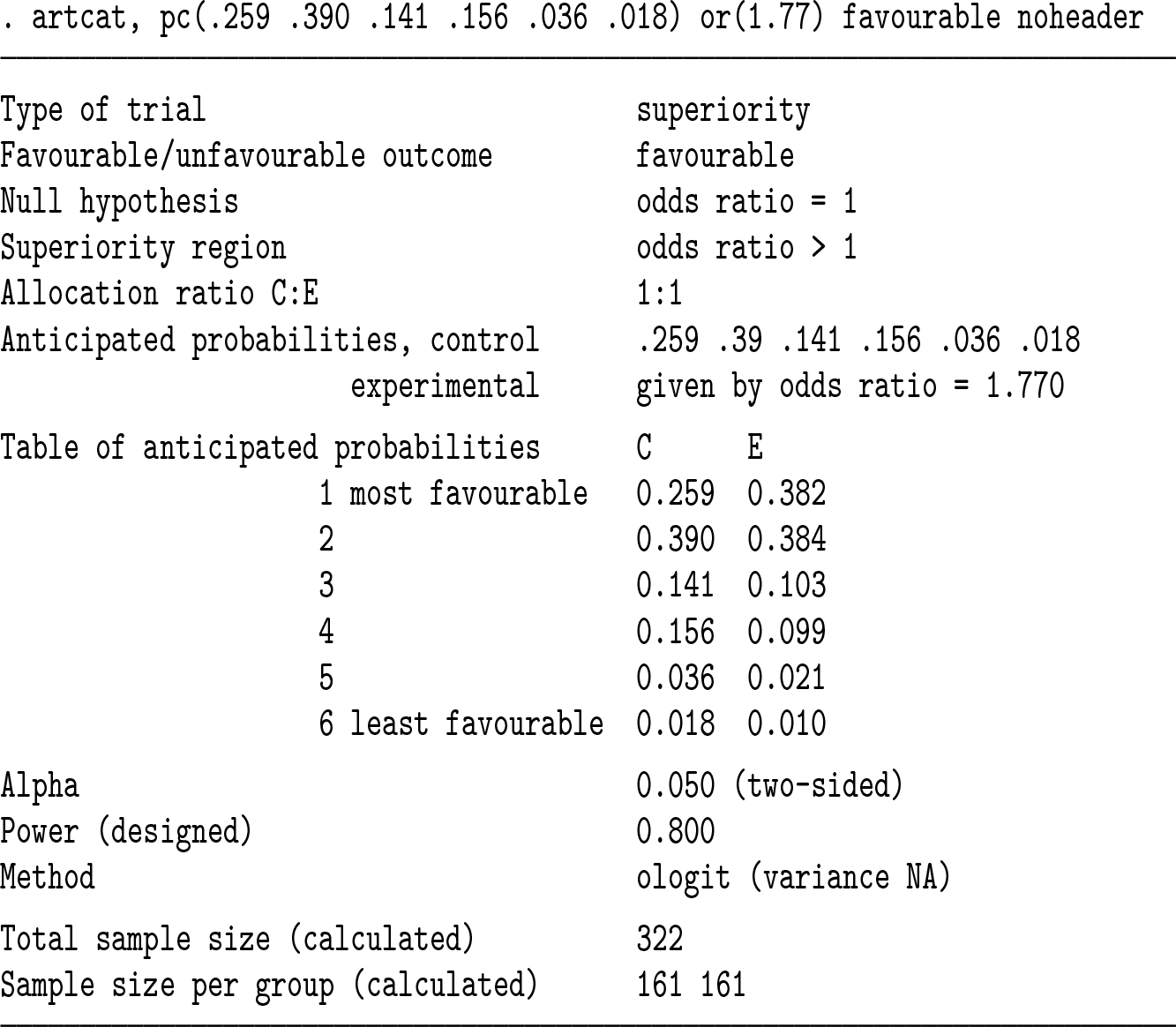
We can also check the power if we recruit 322 participants; in principle, we expect this to be exactly 80%, but because the sample size above is rounded to the next largest integer, the power is slightly more than 80%. We use the

We next compare the new methods with the Whitehead method.

The Whitehead method gives a sample size just 2 less than the
Suppose that the FLU-IVIG trial found that the experimental treatment worked exactly as proposed and that a further noninferiority trial is designed to show that a second new treatment has an odds ratio no worse than 1.33 compared with the first new treatment. We can design this trial using

The noninferiority trial requires a sample size of 1,314.
4.2 Binary outcome and comparison with artbin
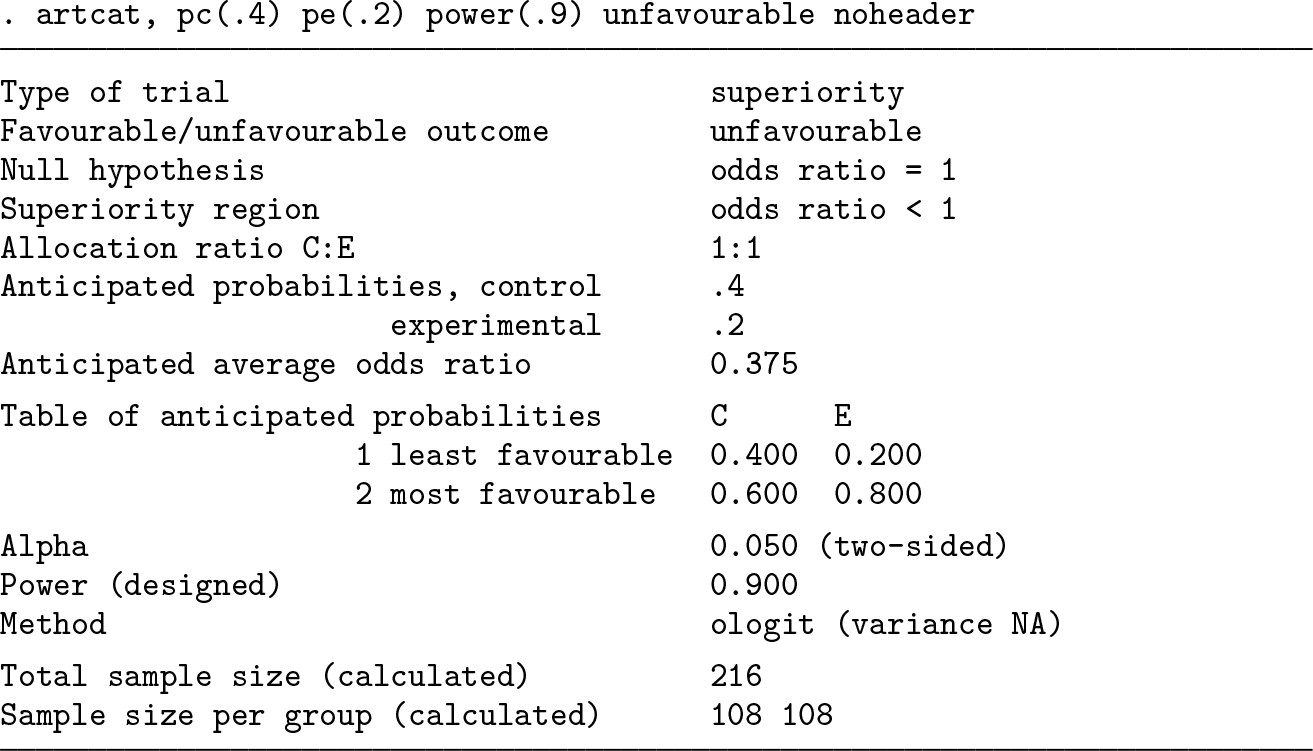

4.3 Effect of subdividing the categories
We finally explore the value of subdividing the unfavorable outcome level of section 4.2, assuming a common odds ratio of (0.2/0.8)/(0.4/0.6) = 0.375 at all levels. We first add an outcome level of control probability 0.01 and then another of control probability 0.09.


We see that adding an outcome level of low prevalence has a negligible effect on sample size. The biggest gains in sample size are achieved when a large outcome level is split, for example, if the healthy category with control probability 0.6 can be subdivided:

However, in practice, subdividing a healthy category may mean that the most important clinical differences are swamped by less important differences, which is a concern if the proportional-odds assumption may not hold. For example, suppose category 1 is death or disability, category 2 is hospitalization and healthy discharge, and category 3 is healthy without hospitalization. If treatment reduces the risk of hospitalization but not the risk of death or disability, then the treatment may be estimated to be beneficial, and it may therefore wrongly be seen as preventing death or disability.
5 Evaluations
5.1 Evaluation 1: Six-level outcome based on the FLU-IVIG study
We explore the difference between methods for the FLU-IVIG setting across a range of odds ratios. Data are assumed to follow the control outcome distribution as proposed, and the common odds ratio is fixed at values from 0.2 to 0.8. Sample sizes to give 90% power, estimated by the different methods, are shown in table 1. Differences are consistently about 10. The relative difference between methods is therefore greater at more extreme odds ratios.
Sample sizes required to give 90% power for the FLU-IVIG setting, estimated by the Whitehead and new sample-size formulas

We next evaluate the methods by simulation to gauge the accuracy of the estimated powers. We simulate data assuming that exactly half the sample is assigned to each group, using the FLU-IVIG control outcome distribution and a common odds ratio fixed at values from 0.2 to 0.8. The sample size is determined from the same parameters by the Whitehead method to give 90% power. We test the null hypothesis of no treatment effect using a Wald test in the
Results (table 2) show moderate differences between methods at extreme odds ratios and negligible differences at large odds ratios. Simulation results are closest to those for the “new NA” method, which is slightly conservative (that is, it slightly underestimates power). The Whitehead and “new NN” methods are anticonservative, and the “new AA” method is conservative and the least accurate.
Power for the FLU-IVIG setting, estimated by the Whitehead and new samplesize formulas and by simulation. Sample sizes are chosen to give 90% power under the Whitehead method. Monte Carlo standard error in the simulation results is 0.1%.

5.2 Evaluation 2: Two levels
We compare
Sample sizes required to give 90% power for an unfavorable outcome, estimated by

Given the differences between the methods shown in table 3, we use simulation to evaluate the methods in this setting. We fix pc
= 0.2 and use the same range of odds ratios. We fix the sample size for each odds ratio at that chosen to give 90% power by
The results (table 4) show that all methods perform accurately for odds ratios of 0.7 or 0.8; that is, their estimated powers are very close to those found by simulation. For smaller (more extreme) odds ratios, new methods NN and AA are inaccurate, respectively overestimating and underestimating power.
Power with an unfavorable binary outcome, estimated by

In sensitivity analysis, we varied pc 1 to 0.1 and 0.4, and results (not shown) showed similar patterns.
6 Software testing
This software is for use in the design of randomized trials, so we have been careful to test it extensively. The program was written by Ian R. White and tested by Ella Marley-Zagar. Here we report these testing methods.
We compared results with those given by Whitehead (1993). Exact agreement was achieved.
We compared results for a binary outcome in a superiority trial with those given by
We checked error messages in several impossible cases, for example, a negative odds ratio.
We compared results with those given by the R package
We reran the test scripts, implementing the above tests in Stata 13 and 16, with the default variable types (
We did various tests of internal consistency of the program. We compared different ways of stating the same problem (for example, interchanging C and E groups or reversing the order of the categories) and verified that the same answer was achieved. We calculated the power p for a sample size n, calculated the sample size for power p, then checked that this equaled the original n. We changed options that should change the sample size and verified that they did change the sample size.
The simulations reported in section 5 also test the software.
7 Conclusions
We have provided software to facilitate sample size and power calculation using Whitehead’s method and also proposed a new method, the
Surprisingly, we have also shown for a binary outcome that the new NA method may outperform the standard method implemented in
A useful future extension will be to allow covariate adjustment, and this can be straightforwardly implemented using the
9 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231161934 - artcat: Sample-size calculation for an ordered categorical outcome
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231161934 for artcat: Sample-size calculation for an ordered categorical outcome by Ian R. White, Ella Marley-Zagar, Tim P. Morris, Mahesh K. B. Parmar, Patrick Royston and Abdel G. Babiker in The Stata Journal
Footnotes
8 Acknowledgments
This work was supported by the Medical Research Council Unit Programme numbers MC_UU_12023/29 and MC_UU_00004/09. We thank Clifford Silver Tamaro and Oliva Safari for help in testing the program.
9 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
You can get the latest version of
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.