
Abstract
The sample size of a randomized controlled trial is typically chosen in order for frequentist operational characteristics to be retained. For normally distributed outcomes, an assumption for the variance needs to be made which is usually based on limited prior information. Especially in the case of small populations, the prior information might consist of only one small pilot study. A Bayesian approach formalizes the aggregation of prior information on the variance with newly collected data. The uncertainty surrounding prior estimates can be appropriately modelled by means of prior distributions. Furthermore, within the Bayesian paradigm, quantities such as the probability of a conclusive trial are directly calculated. However, if the postulated prior is not in accordance with the true variance, such calculations are not trustworthy. In this work we adapt previously suggested methodology to facilitate sample size re-estimation. In addition, we suggest the employment of power priors in order for operational characteristics to be controlled.
Keywords
1 Introduction
A frequentist approach is typically employed for the design and analysis of a randomized controlled trial (RCT). The sample size is thus chosen in order for frequentist operational characteristics to be retained. This is done by specifying the power (1 − β) with which to detect a clinically relevant treatment effect (δ*), given a type I error (α). For an RCT with two groups of equal size being compared on a normally distributed outcome with common unknown variance (σ
2
), δ is commonly measured as the difference between the two groups’ means. If we are interested in testing H0: δ = 0 versus H1: δ > 0 with δ* > 0, the sample size is determined by finding the first even integer solution to satisfy the following inequality

The assumption for the variance is usually based on limited prior information. Especially in the case of small or sensitive populations such as the ones defined by rare diseases or pediatric patients, the prior information might consist of only one small pilot study. Calculating the sample size can therefore be subject to considerable uncertainty. 1 Overestimation of the variance can result in committing to more resources than necessary, while underestimation can lead to inconclusive results. Both situations are undesirable when available research participants are limited.
A vast amount of methods have been developed to deal with such situations.2–5 These methods have in common that they monitor the interim estimates of parameters within a trial, and respond to these estimates by re-calculating the required sample size to meet the design characteristics. Methods that only monitor nuisance parameters, such as the variance, are generally well accepted, but methods responding to interim estimates of the treatment effect can introduce bias. 6 However, in the frequentist framework, quantification of the uncertainty about the estimate of the variance remains an obstacle. The variability of this (interim) estimate is dependent on the amount of data collected and is substantial if only a small amount of subjects have been recruited. 7 In addition, if the variance is monitored only once, its estimator will be negatively biased by the end of the trial. 1 This is because an underestimation of the true variance at interim causes the required sample size to be re-estimated downwards. It is thus increasingly difficult to correct this erroneous estimate in the remaining sample size. 2 On the other hand, when the true variance is overestimated at interim, the sample size is re-estimated upwards, allowing enough time to adjust the estimate by the end of the trial. Friede and Miller 1 suggest continuous monitoring and re-estimation as a preferred solution for these issues. However, continually altering the original design based on an unstable estimate can come at great costs. Repeated sample size re-estimation (SSR) limits the amount of times the sample size can be re-estimated, 1 but still fails to clearly recommend when it is appropriate to do so. This is especially important when dealing with RCTs with a small available study population.
A Bayesian approach formalizes the aggregation of prior information on the variance with newly collected data, potentially alleviating some of the issues mentioned above. 8 Calculating the sample size necessary for a Bayesian RCT depends on the decision scheme that is to be followed after completion of the trial. Several different methods have been proposed, including hybrid frequentist-Bayesian,9–12 fully decision theoretic13–16 and interval-length based approaches.17–19 Whitehead et al. 8 have advocated a variant of the latter which is comparable in simplicity to the frequentist sample size calculation (equation (1)) and includes an analogy to frequentist type I and II errors. This design requires the formulation of two hypotheses: (1) δ > 0, indicating that the experimental group performs better than the control, and (2) δ < δ*, concluding that the experimental treatment fails to improve upon control by a defined clinically relevant difference. 8 The sample size needs to be large enough to provide convincing evidence that either (1) or (2) is the case. Even though the same notation is used for δ* to point out the similarity in this approach and the standard frequentist one, the two effect sizes are not necessarily equivalent conceptually.
When the variance is unknown, the sample size is calculated using a belief about the variance in the form of a prior distribution. If this belief is in agreement with the actual data-generating mechanism, the calculated sample size ensures that the design characteristics will be fulfilled by the end of the trial. If this is not the case, recruiting the original sample size might not be enough to satisfy either of the hypotheses, leading to an inconclusive trial. Just as in the frequentist context, monitoring the variance during the trial can facilitate interim SSR. Several approaches have been proposed using external information for sample size adjustment in a Bayesian framework.20–23 In particular, Zhong et al. 24 discuss SSR for RCTs with a binary outcome, but a similar approach has not been considered for RCTs with a continuous outcome.
Moreover, when there is conflict between the prior and the data, Bayesian procedures can have unpredictable, and likely undesirable, frequentist characteristics. The power prior approach
25
can be employed in order to discard the influence of prior information on posterior inference; this is achieved by employing a power parameter
In light of the above, the goal of the present research is to explore the operational characteristics of the sample size determination method proposed inWhitehead et al. 8 in the case of misspecified variance and to demonstrate the effects of SSR by interim variance monitoring. We employ the power prior approach introduced in Nikolakopoulos et al. 29 to synthesize prior and new data in order for operational characteristics (in this case the probability of having a conclusive trial) to be calibrated.
The paper is organized as follows: in the following section, the sample size determination procedure described in Whitehead et al. 8 is outlined and adapted to allow for SSR. The adaptive power prior, based on predictive distributions and termed Prior-Data conflict calibrating power prior (PDCCPP) in Nikolakopoulos et al., 29 is then briefly described and applied in the variance re-estimation problem. Subsequently, the proposed approach is demonstrated for a clinical trial in the field of pediatrics. The paper ends with a discussion.
2 Bayesian sample size determination
We consider the case where an RCT is designed to evaluate an experimental treatment (E) against a control (C) on a normally distributed outcome (
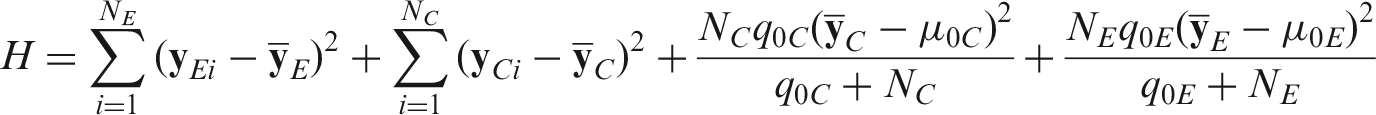
The posterior of
The sample size should be large enough to either provide convincing posterior evidence that E is better than C (a successful result), or that E is not better than C by some clinically relevant treatment effect (


However, β1 is dependent on the data and therefore a random variable. Thus, equation (2) is required to be true with high probability (ξ).
Furthermore, given ν,

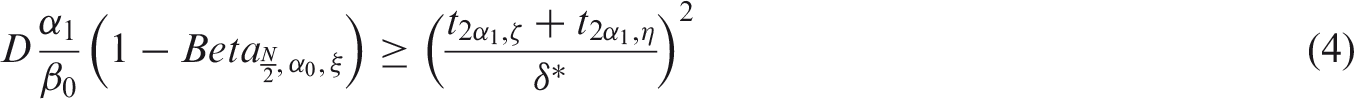
2.1 Sample size re-estimation
To facilitate interim SSR, the design described in the above section can be adapted. The required sample size (N) is now gathered in K stages. Let
At each interim, distributions of the precision (ν) and the means (μj) are updated with the collected data. The prior value of a parameter at the kth interim will now be referred to with subscript k − 1. Consequently, the subscript for the posterior, updated value can be denoted by k. This value is equal to the prior for the k + 1th interim. Note that k = 0 corresponds to the design phase and subscript K refers to the posterior value of the parameter if all the required sample size is recruited.
The posterior of
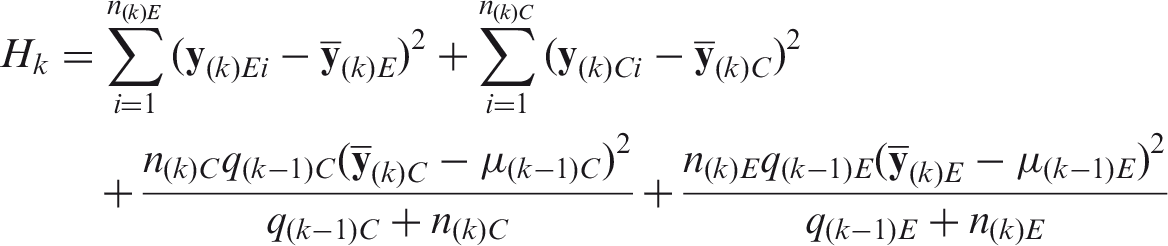
The posterior of
As the trial progresses, the relative influence of the trial data increases, and that of the initial prior belief decreases. This reflects the inherent updating nature of the Bayesian methodology. At interim k, the additional sample size required to obtain the design characteristics (Nk) now depends on the last posterior value of α and D
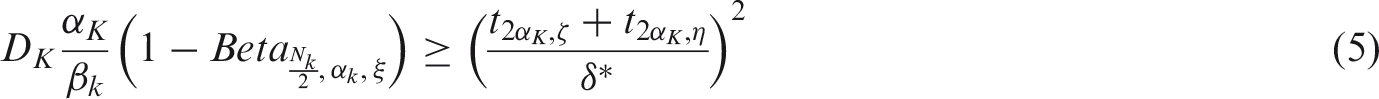
2.2 ξ Calculation
As mentioned earlier, ξ represents the probability of a conclusive decision by the end of the trial. By solving equations (4) and (5) for ξ, we can calculate this probability, given the prior, the data so far, and the remaining sample size.
When equation (4) is solved for ξ, we obtain
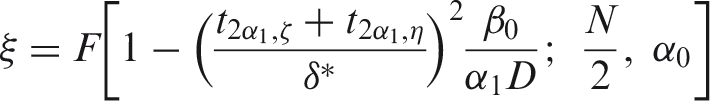
By applying the same steps to equation (5), we can also find an expression for ξk in a setting with multiple interims
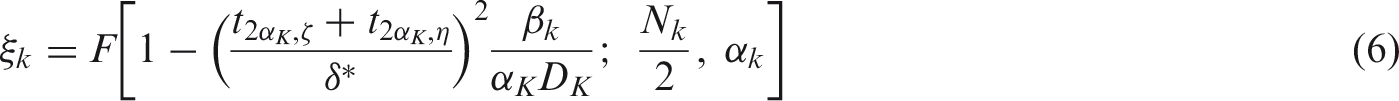
In the case of limited available sample units, if the required sample size cannot be recruited, ξk can be used to evaluate the consequences of continuing the trial with the maximum available subjects. Moreover, the benefit of putting in the extra effort to recruit more subjects can now be quantified. In the following section, the operational characteristics of ξ are evaluated and the impact of a misspecified prior for the variance is assessed and shown to be substantial. The application of PDCCPP’s is demonstrated, as well as how they can be used as a remedy.
The importance of SSR for such a Bayesian approach is stressed. In addition to the reasons sketched for the frequentist case (i.e. the variance being poorly described by the prior distribution due to systematic differences in the two populations), the uncertainty about the variance is now, unlike in the frequentist case, directly incorporated in the sample size calculation. This results in larger sample sizes required for similar decision thresholds (as can be seen when comparing equation 4 with equation 1 for
Sample size required for frequentist and Bayesian procedures for δ* = 0.6, η = 1 − α = 0.95, ζ = 1 − β = 0.8, ξ = 0.9.

Note: NI denotes the sample size at which the interim analysis takes place (or the size of the prior if NI > NBayes – see text for details) while the mean of
Here we mention that comparison of Bayesian and frequentist sample sizes is by no means straightforward. Nevertheless the mathematical resemblance of equation (1) with equation (2) allows us to make such a comparison and note that the frequentist paradigm is similar to the Bayesian approach described here, if it were to assume that the mean of the posterior of ν is known and equal to
3 Frequentist properties of Bayesian SSR
3.1 Variance misspecification
From now on, even though modelling takes place in terms of precision (ν), we describe dispersion by the standard deviation σ for purposes of standardization and clarity. As shown in the previous section, Bayesian SSR can aid to mitigate the inflation on the initial sample size calculation imposed by modeling the uncertainty about σ. However, if the true σ, σR is different than the one observed in the historical data
For our illustrative case, when design parameters are as introduced in the previous section, Figure 1 shows the sample size estimated when the mean of the prior is Sample sizes estimated with Bayesian SSR, with their 95% confidence intervals, for different true σ’s (σR), for assumed σ = 1 and δ* = 0.6, η = 1 − α = 0.95, ζ = 1 − β = 0.8, ξ = 0.9, q0
E
= q0
C
= 0. The prior distribution is based on either 10 (left) or 20 (right) patients.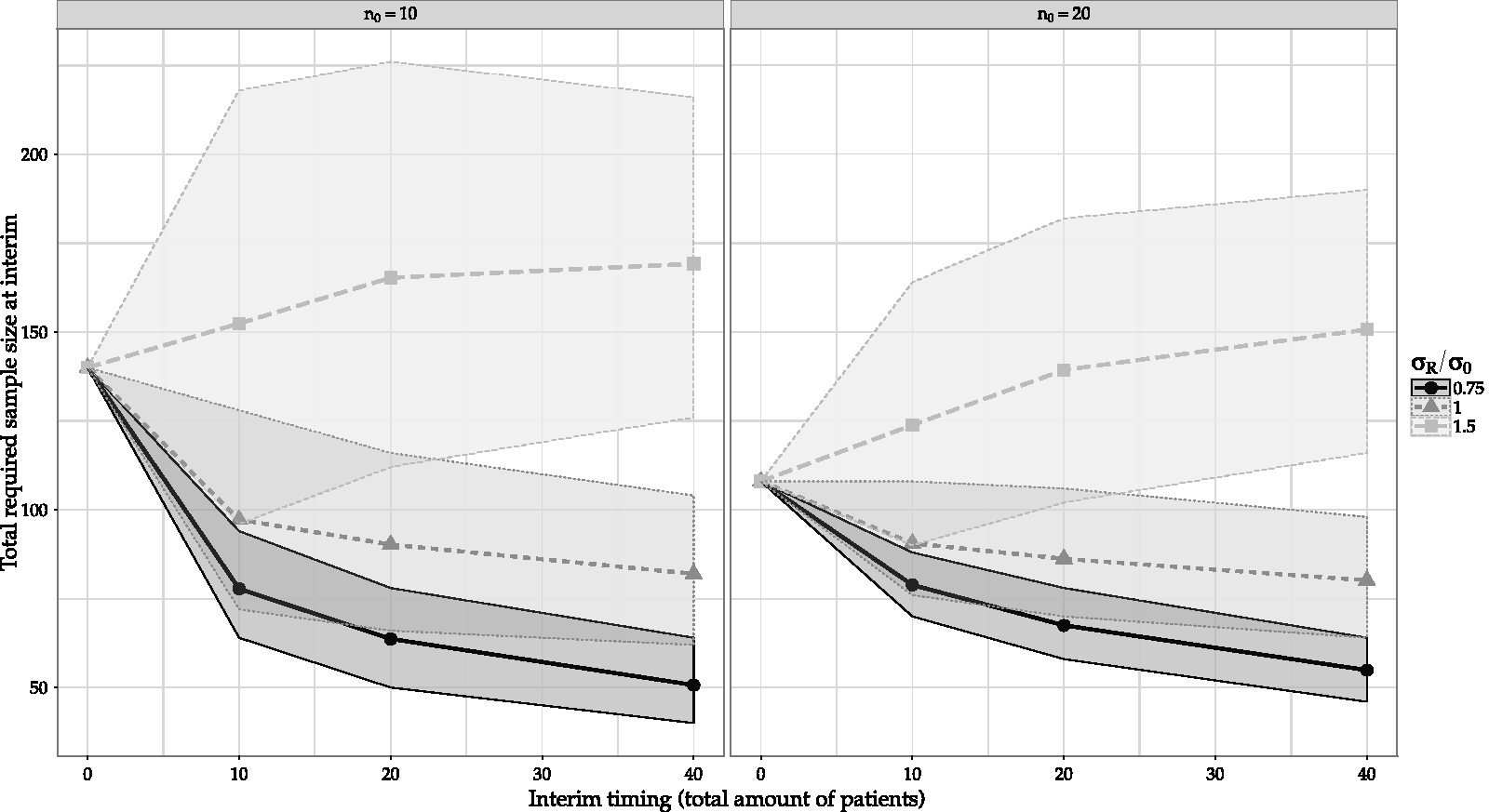
These issues become more apparent when the frequentist properties of ξ are studied. The top two panes of Figure 2 shows the empirical ξ (ξemp), that is the empirical probability of equation (2) being satisfied (calculated using equation (6)), as a function of the ratio of the (re-)estimated sample size (i.e. the collected sample size divided by the sample size (re-)estimated at interim that is required to obtain the design characteristics ( Empirical probabilities of making a decision (ξemp) when sample size is (re-)estimated without (top) or with (bottom) calibration using PDSCCPP’s for different ratios of true σ (σR) over assumed at design stage (σ0), for assumed σ = 1 and δ* = 0.6, η = 1 − α = 0.95, ζ = 1 − β = 0.8, ξ = 0.9, q0
E
= q0
C
= 0. The prior distribution is based on either 10 (left) or 20 (right) patients.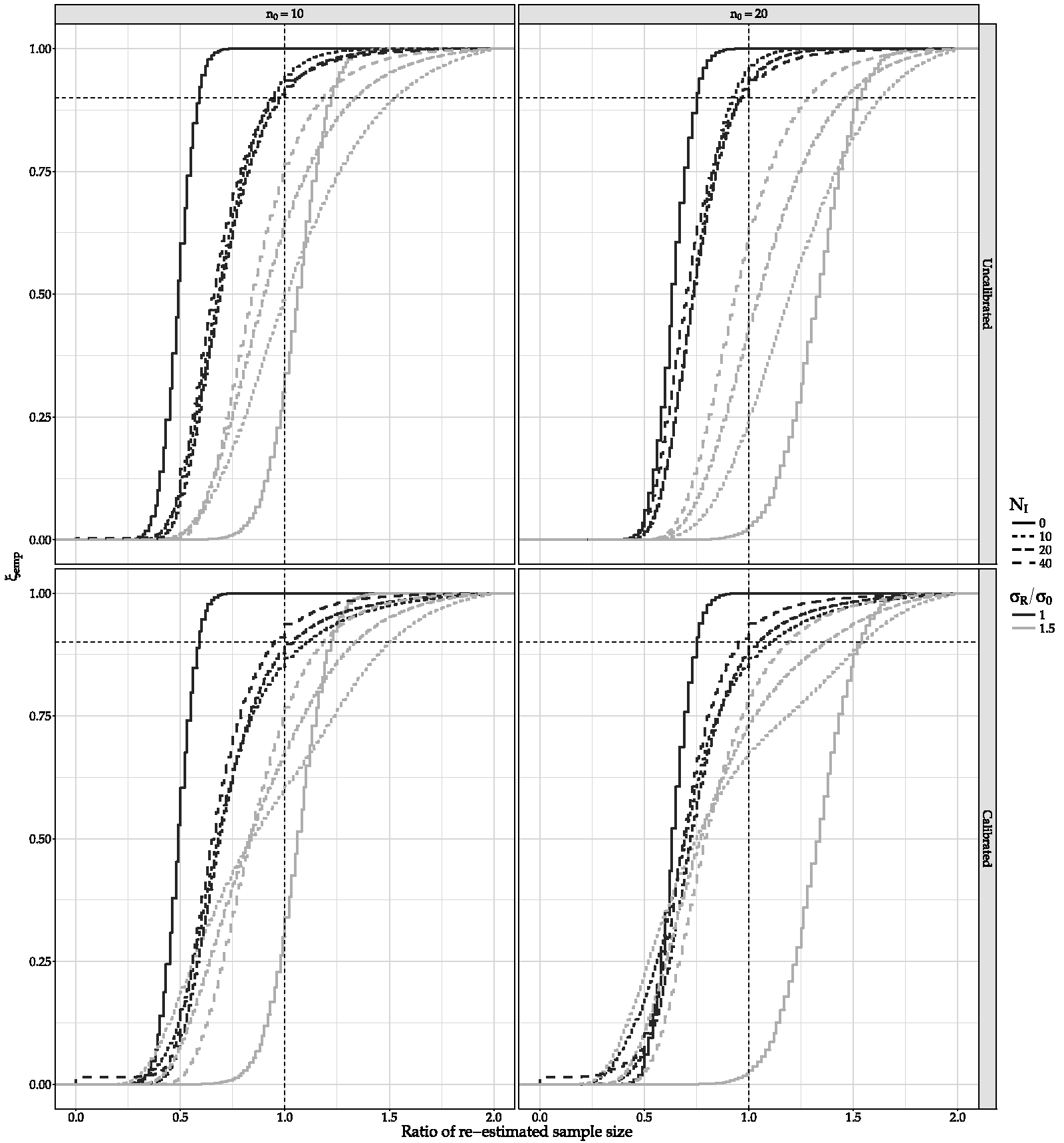
The problem is only partially remedied by re-estimation and/or increasing the interim size and even then, when the true variance is larger than expected by the prior, ξemp is deviating considerably from its 90% assumed value for the sample size (re-)estimated. When
Clearly, deviations from assumptions imposed by the prior distribution can cause calculations which are very relevant for the planning of such a Bayesian RCT, to be untrustworthy. A remedy is suggested by using adaptive power priors which calibrate the prior distribution in light of the new data, thus circumventing the problem.
4 Prior data conflict calibrated power priors
If the data of a current study is denoted by D1 with respective likelihood function 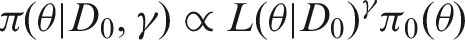
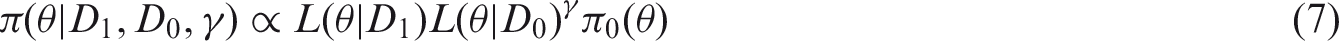
The γ parameter, 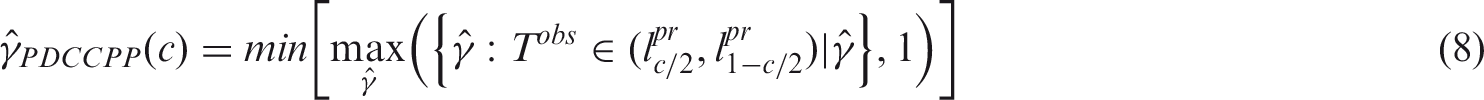
Thus, the prior is calibrated in such a way so that the 100(1 − c)% predictive credible interval for T includes the observed value Tobs. Or, in other words the
4.1 Application of PDCCPP in Bayesian SSR
In order to apply the PDCCPP methodology in the Bayesian SSR problem, we use the predictive distribution for M (see equation (3)). It can be shown that, if the initial priors before the historical study are assumed flat and only information for the variance is used at the design stage, such an empirical power prior formulation is equivalent to using a prior
Analytical derivation of
The choice of c should be such that the frequentist characteristics of interest are controlled. In this case, a predefined probability of making a decision with the estimated sample size is the key characteristic to satisfy. Note that the larger c is, the narrower the credible interval in equation (8) and consequently, the less probable to use the prior in full. In Nikolakopoulos et al., 29 it is discussed how c has to be larger, the smaller N1 is relative to the historical sample size (2α0 in this case), for a procedure based on PDCCPP to preserve the same operational characteristics. Thus, all else being equal, for larger historical sample sizes, larger c’s should be employed in order for the same operational characteristics to be met. We make this choice heuristically here, based on this principle, and elaborate further in section 5.
Figure 2 shows how the operational characteristics of Bayesian SSR turn out to be when PDCCPP are employed. The sample sizes (re-)estimated are now less sensitive to the prior distribution. Calculation of ξ is also more robust as the lines move closer together, with a higher ξ reached in most cases when all of the re-estimated sample size is collected. For example, for the case of N1 = 40, n0 = 20, and σR/σ0 = 1.5, empirical ξ goes from 59% without calibration to approximately 80% when calibrated through PDCCPP. Here 1 − c/2 was set to 0.2, 0.4, 0.6 and 0.8 for a ratio of the interim location over the prior of 0.5, 1, 2 and 4, respectively, a heuristic choice as discussed above. In general, c must be such that the empirical ξ does not depend heavily on the true value of the variance and is relatively close to the intended value (here 90%). The implemented value of c will depend on the location and precision of the prior, the true value of the variance and the required robustness of ξ. Since these dependencies are not straightforward to quantify, a simulation-based approach must be implemented. Currently, simulation-based choices for parameters are increasingly applied when designing clinical trials. In the following section, by means of an example, we show how such choices can be more refined.
SSR with or without PDCCPP did not affect operational characteristics such as the probability of showing efficacy or futility (see supplementary material). R code used for the procedure and simulations described in this section as well as the analyses presented in section 5 can be found at https://github.com/timobrakenhoff/BayesianSSRwithPDCCPP.
5 Example
The following example is from a multicentre, double-blind, prospective, randomized, placebo-controlled trial that evaluated the efficacy of dexamethasone in very young patients mechanically ventilated for lower respiratory infection caused by respiratory synctial virus (RSV-LRTI). 32 Eighty-five children younger than 24 months on mechanical ventilation were randomized to receive either dexamethasone (E) or placebo (C). The primary outcome measure was the duration of mechanical ventilation in days which was assumed normally distributed in the original trial.
Even though no adequate treatment has yet been identified for severe RSV-LRTI, a previous RCT by van Woensel et al. 33 found a potential beneficial effect of corticosteroids. Treatment with prednisolone as compared to placebo reduced the duration of mechanical ventilation in a small subgroup of patients on mechanical ventilation by 1.6 days. This result was based on seven patients in the prednisolone group and seven patients in the placebo group, for which the estimate for the standard deviation was σ0 = 4.23.
In order to illustrate the design approach suggested by combining SSR and PDCCPP’s, we discuss the situation where the RCT at hand was to be designed in the Bayesian manner described in Whitehead et al., 8 when only prior information on the variance were to be used. Thus, by assuming α0 = 7, β0 = 125.3, δ* = 1.5, η = 0.95, ζ = 0.8 and ξ = 0.9, a sample size of 352 is deemed necessary for a Bayesian RCT that will declare efficacy based on posterior probabilities. This sample size is considerably larger than the 198 patients required by the frequentist approach since the uncertainty about the variance is also modelled. However, as discussed, SSR can reduce the sample size required (if the variance is as assumed). But, if the variance is not as expected by the prior, calculations are not to be trusted. Thus PDCCPP is employed as a remedy.
Figures 3 and 4 show the type of exploration that could be of help in deciding the value of c and the interim timing. The ratio of the (re-)estimated sample size to have a ξ = 90% probability of making a decision as dictated by design, is explored. This ratio can alternatively be expressed as the total number of subjects actually required to reach ξ = 90% divided by the total (re-)estimated number of subjects that were expected to be required at interim. In Figure 3 it is plotted as a function of the ratio of σR/σ0, for different widths of the predictive distribution’s credible interval (PI) and sample sizes at which the interim analysis takes place. In Figure 4 it is plotted as a function of the width of the PI, for different σR/σ0 and interim sample sizes.
Ratio of (re-)estimated sample size required to reach ξ = 0.9 without (upper) and with (lower) use of PDCCPP. Shown as a function of the true variance for different widths of the prior predictive intervals (1 − c/2) and different sample sizes at which the (re-)estimation takes place NI = {0, 20, 50}. Ratio of (re-)estimated sample size required to reach ξ = 0.9 without (upper) and with (lower) use of PDCCPP. Shown as a function of the width of the prior predictive interval (1 − c/2), for different values of the true variance and different sample sizes at which the (re-)estimation takes place NI = {0, 20, 50}.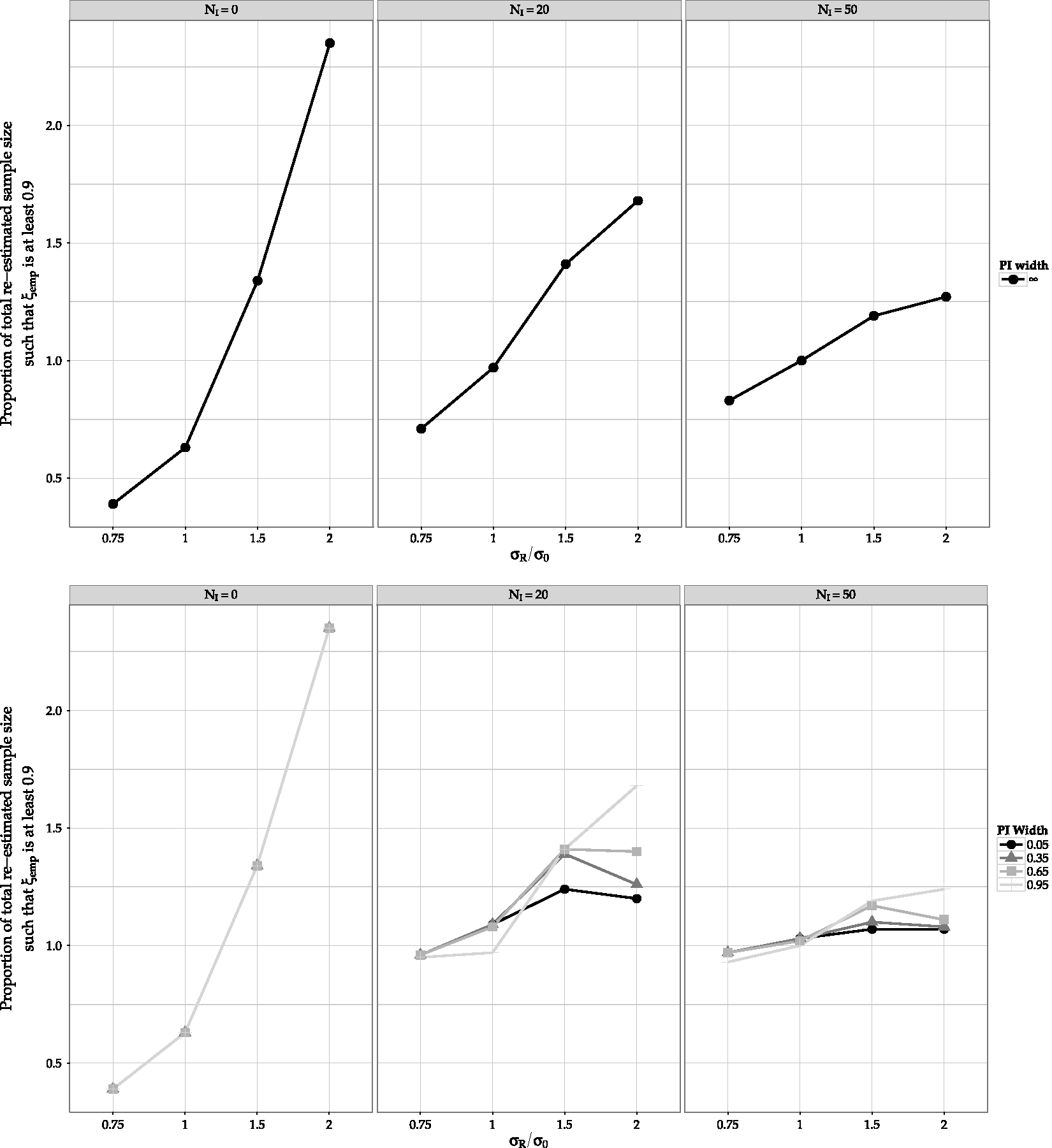
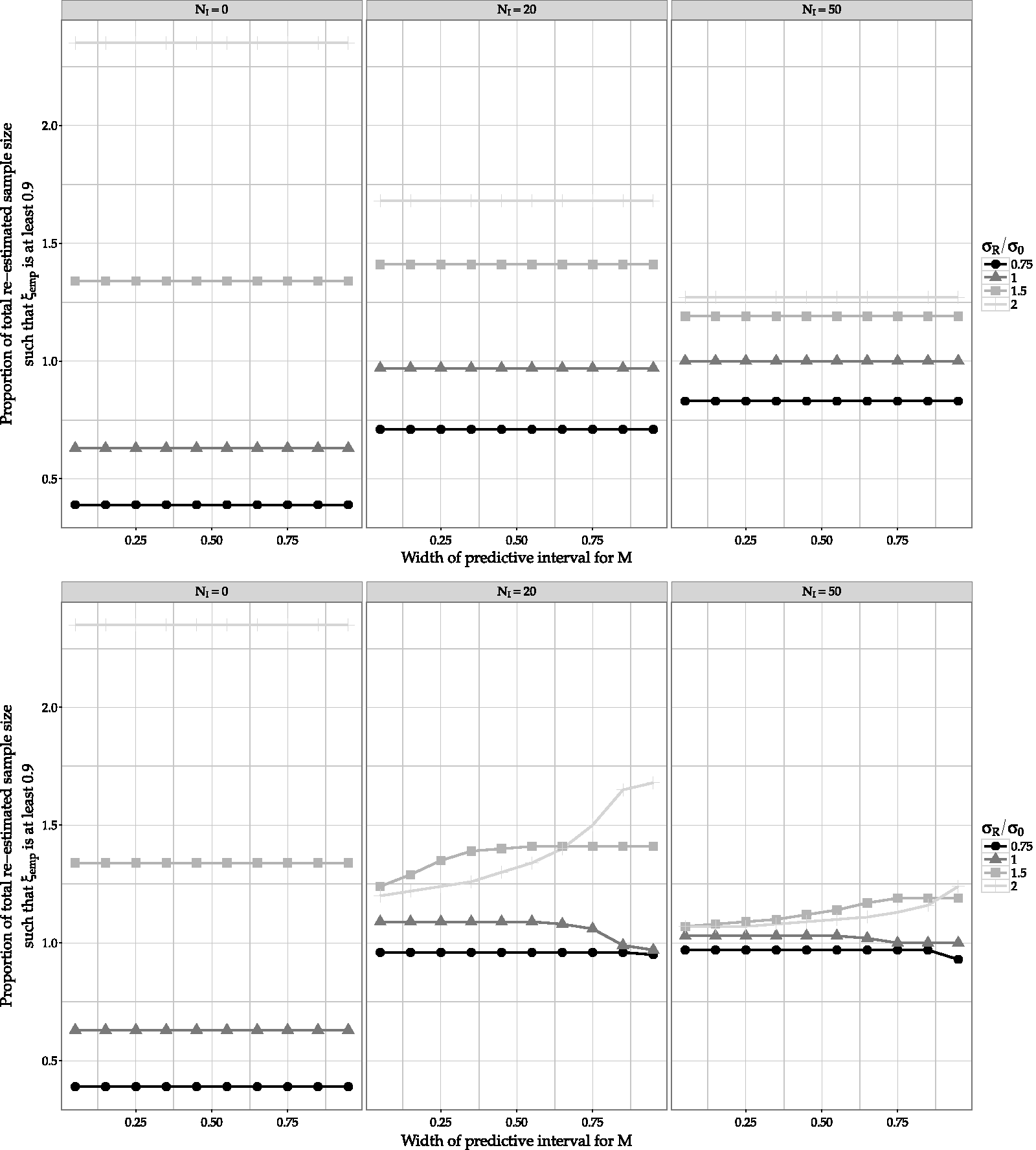
In both figures it is shown how these factors affect the frequentist performance of ξ. The wider the PI is, the less the weight of the prior is adapted. This leads to more biased calculation of ξ (sample size required for 90% probability of making a decision is considerably different). The narrower the PI is, the less the frequentist performance of ξ depends on the true value of the variance (lines in both graphs are closer to each other). Note that at the lower middle plane of Figure 4, when σR = 2σ0, smaller PI widths lead to better ξ estimation than when σR = 1.5 σ0. This happens because the discrepancy between the prior and σR (when σR = 2σ0) is such that there is small overlap between the sampling and predictive distributions, leading to higher chances of considerably down-weighting the prior. When the width of the PI becomes large enough, the effect of the large discrepancy takes over, leading to more biased estimation of ξ than when σR = 1.5 σ0.
Such explorations could lead to a choice of PI width and interim timing should result in a required balance between variability in sample size calculation and robustness of the calculation of ξ. This can be done alongside considerations about the maximum sample size available in the case of an RCT in small populations.
6 Discussion
In this paper, the sample size determination procedure described in Whitehead et al. 8 has been adapted to facilitate interim SSR based on the variance of the observed data. Furthermore, the frequentist properties of such a procedure were shown to be heavily dependent on the prior-data disagreement. A power prior method that calibrates the prior in case of conflict is suggested as a solution. It is also discussed how the interplay between the desired similarity and the ratio of the sample sizes of the prior and new data affect those frequentist properties.
As frequentist properties we considered the probabilities of making a decision within the Bayesian decision scheme suggested in Whitehead et al. 8 Robustness of calculations can be of importance in research conducted in small populations where recruitment difficulties can result to very long clinical trials. Feasibility of such an ongoing trial is of interest.
We did not dwell into probabilities of correct or wrong decisions (the analogues of type I and II errors). However, as shown in the supplementary material, such probabilities were only marginally affected by the SSR suggested here. This does not come as a surprise since our method is monitoring only the variance and not the treatment effect. Methods that facilitate SSR by monitoring the variance are generally more well accepted by regulators. 6 It should be noted that the current method requires unblinding, at least of the statistician.
We also encourage further research on the performance of this method when multiple interim looks are taken sequentially and the allocation of sample size is not 1:1. While the sample size re-estimation method proposed here is explored for multiple interims, we would advise the detailed attention of a statistician at the end of each interim (which can be considered best practice). If this is not possible, we propose to perform no more than 1 interim when interested in performing Bayesian sample size re-estimation with PDCCPP. Limited increase in efficiency, risk of unintended bias, and other logistical concerns may also be reasons to restrict the number of interims. In addition, the allocation of sample size in this paper is assumed to be 1:1. However, as the original Bayesian sample size estimation approach proposed by Whitehead et al. 8 does not require equal allocation, this assumption can likely be relaxed in the re-estimation approach proposed here.
The Bayesian method explored here results in considerably larger sample sizes than the frequentist ones for seemingly similar decision criteria. We show how SSR can partly remedy this. Assuming that the uncertainty in any variance estimate (prior distribution or fixed assumption) is acknowledged, and SSR is part of the design of a new trial, the Bayesian and frequentist approaches suggest two different strategies: Let us consider the case where a two-stage SSR is planned (thus one interim analysis for SSR) for a trial with very limited prior information, for example one small pilot study. A frequentist would start small, bearing considerable uncertainty concerning the sample size estimate of the second stage. The amount of this uncertainty depends on the sample size of the pilot study. Furthermore this uncertainty is not incorporated in the assumed value for the variance thus the sample sizes calculated might be deemed as unrealistic in small populations RCTs.
A Bayesian would start large, thus being prepared in terms of commitment of resources, and then reduce the sample size if the true variance was indeed equal to the point estimate of the pilot study – the same estimate the frequentist would use. The PDCCPP approach is fairly robust against variance misspecification; a robustness all more important in RCTs in populations where repetition of a trial that was subject to misspecification is rather unlikely. The Bayesian would also have a different decision scheme as posterior inference as described in Whitehead et al. 8 could also conclude futility whereas “acceptance of H0” is not very popular amongst frequentists.
In both the frequentist and Bayesian approaches, one can think of intuitively awkward issues. In the frequentist approach, the sample size is calculated under the assumption of a value for the unknown variance. In the Bayesian one, empirical ξ is far from the one calculated. This is not surprising as a single value for ν is not the data generating mechanism assumed in the Bayesian model. This discrepancy reduces the larger the new data is relatively to the old. It is hard to imagine a data-generating mechanism that depends on how much knowledge one has for its parameters.
We try to bridge these gaps by an application of the PDCCPP. Essentially an Empirical Bayes methodology, it facilitates both the Bayesian belief and the frequentist operational characteristics in the design and analysis of a clinical trial. We argue that these are both features that could be of interest in conducting research in small or sensitive populations.
Supplemental Material
Supplemental material for Bayesian sample size re-estimation using power priors
Supplemental material for Bayesian sample size re-estimation using power priors by TB Brakenhoff, KCB Roes and S Nikolakopoulos in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the European Union’s seventh framework programme (FP7-HEALTH-2013-INNOVATION-1, Grant-Agreement No. 603160, ASTERIX).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.