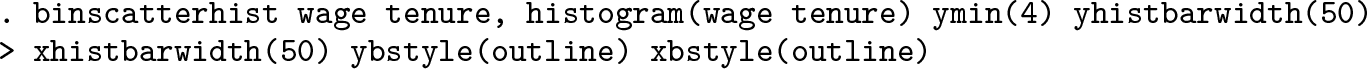3.2 Options
3.2.1 Main
by(
varname
) plots a separate series for by-value. Both numeric and string by-variables are supported, but numeric by-variables will have faster run times.
There are two ways in which binscatterhist does not condition on by-values:
1. When combined with controls() or absorb(), the command residualizes using the restricted model in which each covariate has the same coefficient in each byvalue sample. It does not run separate regressions for each by-value. If you wish to control for covariates by using a different model, you can residualize your x and y variables beforehand with your desired model and then run binscatterhist on the residuals you constructed.
2. When not combined with discrete or xq(), the command constructs a single set of bins using the unconditional quantiles of the x variable. It does not bin the x variable separately for each by-value. If you wish to use a different binning procedure (such as constructing equal-sized bins separately for each by-value), you can construct a variable containing your desired bins beforehand and then run binscatterhist with xq().
medians creates the binned scatterplot using the median x and y values within each bin rather than the mean. This option only affects the scatter points; it does not, for instance, cause linetype(lfit) to use quantile regression instead of ordinary least squares when drawing a fit line.
3.2.2 Bins
nquantiles(
#
) specifies the number of equal-sized bins to be created. This is equivalent to the number of points in each series. The default is nquantiles(20). If the x variable has fewer unique values than the number of bins specified, then discrete will be automatically invoked and no binning will be performed. nquantiles() may not be combined with discrete or xq().
Binning is performed after residualization when combined with controls() or absorb(). Note that the binning procedure is equivalent to running Stata’s xtile command, which in certain cases will generate fewer quantile categories than specified. (For example, sysuse auto; xtile temp = mpg, nq(20); and tab temp.)
genxq(
varname
) creates a categorical variable containing the computed bins. genxq() may not be combined with discrete or xq().
discrete specifies that the x variable is discrete and that each x value be treated as a separate bin. binscatterhist will therefore plot the mean y value associated with each x value. discrete may not be combined with nquantiles(), genxq(), or xq().
In most cases, discrete should not be combined with controls() or absorb(), because residualization occurs before binning and, in general, the residual of a discrete variable will not be discrete.
xq(
varname
) specifies a categorical variable that contains the bins to be used instead of having binscatterhist generate them. This option is typically used to avoid recomputing the bins needlessly when binscatterhist is being run repeatedly on the same sample and with the same x variable; it may be convenient to use genxq() in the first iteration and specify xq() in subsequent iterations. Computing quantiles is computationally intensive in large datasets, so avoiding repetition can reduce run times considerably. xq() may not be combined with nquantiles(), genxq(), or discrete.
Take care when combining xq() with controls() or absorb(). Binning takes place after residualization, so if the sample or the control variables change, the bins should be recomputed as well.
3.2.3 Residuals computation
regtype(
string
) specifies the type of regression to use to compute the residuals. string may be reghdfe or areg. regtype() requires absorb() to be specified. When reghdfe is specified, absorb() allows for more than one varname; however, interactions are not allowed, including tricks like, for example, one##control, to include controls in the absorb. Such controls must be included in the controls() option. reghdfe drops singleton observations with regard to the included fixed effects; therefore, sample size might differ between reghdfe and areg. The default is regtype(reghdfe).
3.2.4 Standard errors/robust
cluster(
varname
) specifies the variable that identifies clusters. Clustered standard errors affect both the sample for residualization and the computation of standard errors for slope reporting.
vce(robust) specifies to calculate robust standard errors, which affect both the sample for residualization and the computation of standard errors for slope reporting.
3.2.5 Controls
controls(
varlist
) residualizes the x and y variables on the specified controls before binning and plotting. To do so, binscatterhist runs a regression of each variable on the controls, generates the residuals, and adds the sample mean of each variable back to its residuals.
absorb(
varlist
) absorbs fixed effects in the categorical variable from the x and y variables before binning and plotting. To do so, binscatterhist runs an areg of each variable with absorb() and any controls() specified. It then generates the residuals and adds the sample mean of each variable back to its residuals.
noaddmean prevents the sample mean of each variable from being added back to its residuals when combined with controls() or absorb().
3.2.6 Fit line
linetype(
string
) specifies the type of line plotted on each series. The default is linetype(lfit), which plots a linear fit line. Other options are linetype(qfit) for a quadratic fit line, linetype(connect) for connected points, and linetype(none) for no line.
Linear or quadratic fit lines are estimated using the underlying data, not the binned scatter points. When combined with controls() or absorb(), the fit line is estimated after the variables have been residualized.
rd(
numlist
) draws a dashed vertical line at the specified x values and generates regression discontinuities when combined with linetype(lfit) or linetype(qfit). Separate fit lines will be estimated below and above each discontinuity. These estimations are performed using the underlying data, not the binned scatter points.
The regression discontinuities do not affect the binned scatter points in any way. Specifically, a bin may contain a discontinuity within its range and, therefore, may include data from both sides of the discontinuity.
reportreg displays in the Results window the regressions used to estimate the fit lines.
3.2.7 Coefficient and sample reporting
coefficient(
#
) reports the slope of the fitted line with its standard error, rounded at # using round(coefficient, #
). See help round().
ci(#) reports the #% confidence interval, rounded as the coefficient().
pvalue reports the p-value of the regression on residualized variables.
sample reports the sample size of the regression on residualized variables.
stars(
string
) reports the p-value using stars. string may be nostars, 1 (*5% **1%), 2 (+10% *5% **1%), 3 (+10% *5% **1% ***0.1%), or 4 (*5% **1% ***0.1%). The default is stars(1).
3.2.8 Graph style
colors(
colorstyle
) specifies an ordered list of colors for each series.
mcolors(
colorstyle
) specifies an ordered list of colors for the markers of each series, which overrides any list provided in colors().
lcolors(
colorstyle
) specifies an ordered list of colors for the lines of each series, which overrides any list provided in colors().
msymbols(
symbolstyle
) specifies an ordered list of symbols for each series.
twoway_options controls the graph titles, legends, axes, added lines and text, regions, name, aspect ratio, etc.; see [g-3]
twoway_options
.
3.2.9 Histogram
histogram(
varlist
) plots a histogram for each of the selected variables (max = 2). Selected variables have to be the scattered ones.
xmin(
value
) sets the base position of the y histogram in terms of the x axis. Option xmin() is only allowed with histogram().
ymin(
value
) sets the base position of the x histogram in terms of the y axis. Option ymin() is only allowed with histogram().
xhistbarheight(
value
) sets the height of the x histogram as a percentage. The default is xhistbarheight(10).
yhistbarheight(
value
) sets the height of the y histogram as a percentage. The default is yhistbarheight(10).
xhistbarwidth(
value
) sets the width of the x histogram as a percentage. The default is xhistbarwidth(100).
yhistbarwidth(
value
) sets the width of the y histogram as a percentage. The default is yhistbarwidth(100).
xhistbins(
#
) sets the number of bins to be created in the x histogram. The default is xhistbins(20).
yhistbins(
#
) sets the number of bins to be created in the y histogram. The default is yhistbins(20).
The following options require the axis to be specified as x or y, for example, xcolor() or ylpattern().
axis
color(
colorstyle
) sets the outline and fill color and opacity. The defaults are xcolor(teal%50) and ycolor(maroon%50).
axis
fcolor(
colorstyle
) sets the fill color and opacity.
axis
fintensity(
intensitystyle
) sets the fill intensity.
axis
lcolor(
colorstyle
) sets the outline color and opacity.
axis
lwidth(
linewidthstyle
) sets the thickness of the outline.
axis
lpattern(
linepatternstyle
) sets the outline pattern (solid, dashed, etc.).
axis
lalign(
linealignmentstyle
) sets the outline alignment (inside, outside, or center).
axis
lstyle(
linestyle
) sets the overall look of the outline.
axis
bstyle(
areastyle
) sets the overall look of the bars, all settings above.
axis
pstyle(
pstyle
) sets the overall plot style, including area style.
3.2.10 Save output
savegraph(
filename
) saves the graph to a file. The format is automatically detected from the extension (for example, .gph, .jpg, or .png), and either graph save or graph export is run. By default, .gph is assumed.
savedata(
filename
) saves filename
.csv containing scatter point data and filename
.do to process the data into a graph.
replace specifies that files be overwritten if they already exist.
3.2.11 fastxtile options
nofastxtile forces the use of xtile instead of fastxtile to compute bins. There is no situation where this should be necessary or useful. The fastxtile command generates identical results to xtile but runs faster on large datasets and has additional options for random sampling that may be useful to increase speed.
fastxtile is built into the binscatterhist code but may also be installed separately for use outside of binscatterhist. It is available from the Statistical Software Components Archive.
randvar(
varname
) requests that varname be used to select a sample of observations when computing the quantile boundaries. Sampling increases the speed of the binning procedure but generates bins that, because of sampling error, are only approximately equal sized. It is possible to omit this option and still perform random sampling from U[0, 1], as described below in randcut() and randn().
randcut(
#
) specifies the upper bound on the variable contained in randvar(). Quantile boundaries are approximated using observations for which randvar()
≤ #. If no variable is specified in randvar(), a standard uniform random variable is generated. The default is randcut(1). randcut() may not be combined with randn().
randn(
#
) specifies an approximate number of observations to sample when computing the quantile boundaries. Quantile boundaries are approximated using observations for which a uniform random variable is ≤ #/N. The exact number of observations sampled may therefore differ from #, but it equals # in expectation. When this option is combined with randvar(), varname should be distributed U[0, 1]. Otherwise, a standard uniform random variable is generated. randn() may not be combined with randcut().