
Abstract
In this article, we describe
1 Introduction
Nonrandom sample selection is a well-known issue in empirical economics. Since the seminal work of Heckman (1979) addressing this problem, much progress has been made in methods that extend the original model or relax some of its assumptions. For example, Vella (1998) provides a survey of methods for fitting models with sample-selection bias in this line.
Although most of the effort has been focused on models that estimate the conditional mean, the literature in econometrics has also tackled the problem of nonrandom sample selection in the context of quantile regression. For example, Arellano and Bonhomme (2018) offer a survey of recently proposed methods with a focus on a copula-based sample-selection model suggested in Arellano and Bonhomme (2017).
As discussed in Arellano and Bonhomme (2018), the flexible copula-based approach has an advantage over methodologies that are based on the control function approach. The latter impose conditions on the data that may not be compatible with quantile models if the model is nonadditive with nonlinear quantile curves on the selected sample (see Huber and Melly [2015]).
In this article, we briefly discuss the copula-based approach proposed by Arellano and Bonhomme (2017) and present a new community-contributed command called
Reference Manual example for the
This article is organized as follows. Section 2 describes the methodology. Section 3 describes the
2 Methodology
In this section, we briefly review the quantile selection model of Arellano and Bonhomme (2017). The goal is to obtain a consistent estimator when there is sample selection in a nonadditive model such as quantile regression, which precludes the use of the control function approach. The assumption of additive separability of observables and unobservables in the output equation does not hold in general, as argued by Huber and Melly (2015) in the context of testing.
2.1 The model
Sample selection is modeled using a bivariate cumulative distribution function (c.d.f.) or copula of the percentile error in the latent outcome equation and the error in the sampleselection equation. The copula parameters are estimated by minimizing a method-of-moments criterion that exploits variation in excluded regressors to achieve credible identification. Then the quantile regression parameters are obtained by minimizing a rotated check function, which preserves the linear programming structure of the standard linear quantile regression (see Koenker and Bassett [1978]).
Consider a general outcome equation specification where the quantile functions are
linear:

Y ∗
is the latent outcome variable (for example, wage offers), the function Q is the τth conditional quantile of Y ∗
given the covariates

where D takes values equal to 1 when the latent variable is observable (for example, employment) and equal to 0 otherwise,
Under the set of assumptions 2 detailed in Arellano and Bonhomme (2017), we have that the c.d.f. of Y ∗ , conditional on participation and for all τ ∊ (0, 1), is

where Gx ≡ C(τ, p)/p is the conditional copula function, which measures the dependence between U and V . Here Gx
maps rank τ in the distribution of latent outcomes (given
To implement the method, we assume that the copula function is indexed by a single parameter such that

where the numerator is the unconditional copula of (U, V ), the denominator is the propensity score, and ρ is the copula parameter that governs the dependence between the error in the outcome equation and the error in the participation decision.
2.2 Estimation
Arellano and Bonhomme’s (2017) estimation algorithm can be summarized in three steps: estimation of the propensity score; estimation of the degree of selection via the c.d.f. of the percentile error in the outcome equation and the error in the participation decision; and then, using the estimated parameter, the computation of quantile estimates through rotated quantile regression.
The first step consists of estimating the propensity score γ by a probit regression:

The second step is to estimate ρ by minimizing a method-of-moments objective function, which allows us to obtain an observation-specific measure of dependence between the rank error in the equation of interest and the rank error in the selection equation. This is accomplished with a grid search over different values of ρ such that

where ‖ · ‖ is the Euclidean norm, τ
1 < τ
2 < · · · < τL
is a finite grid on (0, 1), and the instrument functions are defined as φ(τ,

where a + = max{a, 0}, a− = max{−a, 0}, and the grid of τ values on the unit interval as well as the instrument function are chosen by the researcher. 3
Finally, using
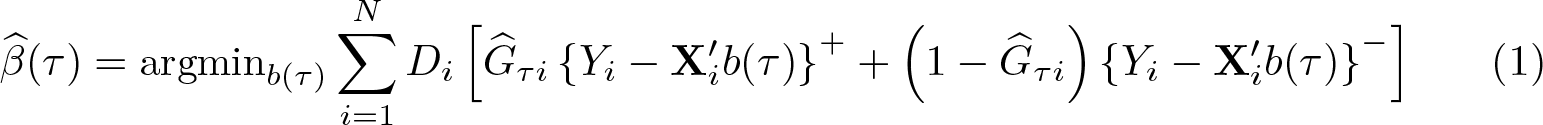
where
Note that the third step is unnecessary if the quantiles of interest are included in the set τ 1 < τ 2 < · · · < τL used in the second step.
2.3 Copulas
The Arellano and Bonhomme (2018) analysis covers the case where the copula is left unrestricted, but for the implementation they focus on the case of identification where the copula depends on a low-dimensional vector of parameters.
In our empirical implementation, we consider only the case of a reduced set of onedimensional copulas. We include the Gaussian and a one-parameter Frank. Table 1 provides their respective functional forms.
Copula functions.

2.4 Measures of dependence
The parameter ρ, which governs the degree of dependence, is not directly comparable across copulas (see Hasebe [2013]). For this reason, researchers often report Kendall’s τ or the Spearman rank correlation coefficient as a measure of the degree of dependence. Both measures take the range of [−1, 1], where a value closer to 1 (−1) indicates a stronger (negative) dependence, and (in the case of our copulas) can be expressed as closed form in terms of ρ (see table 2).
Copula functions and measures of dependence.

NOTE: Dn
(ρ) is a Debye function, where
2.5 Rotated quantile regression
As previously mentioned, the quantile estimates are obtained by minimizing a rotated check function [see (1)]. The minimization problem can be written as the linear programming problem 4

such that

where
This linear programming problem could be solved using the
3 The qregsel command
In this section, we describe the
3.1 Syntax
The syntax of the
3.2 Options
numbers between 0 and 1, exclusive. Numbers larger than 1 are interpreted as percentages.
3.3 Stored results

3.4 Prediction
After the execution of
where newvarlist must contain the names for two new variables: the first one for the counterfactual outcome variable and the second one for a binary indicator of selection.
The counterfactual outcomes are constructed by randomly generating an integer q between 1 and 99 for each individual in the full sample and then using the quantile coefficients associated with each draw of q to produce a prediction of the qth quantile of the outcome distribution. This approach follows the conditional quantile decomposition method of Machado and Mata (2005) and has been recently applied, for example, in Bollinger et al. (2019).
The selection indicator is generated by randomly drawing values of the error in the selection equation V from the conditional distribution of V given U = u, derived from the chosen copula using the estimated copula parameter and the values of U randomly generated to create the counterfactual outcome variable in the previous paragraph. This approach follows the empirical exercise performed in Arellano and Bonhomme (2017).
3.5 Inference
Confidence intervals for any of the parameters can be estimated using methods such as the conventional nonparametric bootstrap or, alternatively, using subsampling (see Politis, Romano, and Wolf [1999]) as done in Arellano and Bonhomme (2017) because of the computational advantage when using large sample sizes.
In our first empirical application, we illustrate how to use bootstrap to create a confidence interval for the estimated coefficients of the quantile regression and the copula parameter.
4 Empirical examples
In this section, we illustrate the use of the command with two empirical examples. First, we use the classic example of wages of women, in which we use the data available from the Stata manual example for the command
4.1 Wages of women
In this application, we use the fictional dataset used in the documentation of the Heckman selection model in the Stata Base Reference Manual (see StataCorp [2021a]) to study wages of women. As in the example, we assume that the hourly wage is a function of education and age, whereas the likelihood of working (and hence the wage being observed) is a function of marital status, the number of children at home, and (implicitly) the wage (via the inclusion of age and education). We do not take the logarithm of wage as it is usually done; however, the variable in the fictional dataset already has a bell-shaped histogram. In addition, we follow the example in the Stata 17 Base Reference Manual by not including squared age because it is standard in this type of regression.
First, we estimate a quantile regression over the quantiles 0.1, 0.5, and 0.9 without corrections for sample selection as a benchmark.

Next, we turn to the estimation of a quantile regression accounting for sample selection by using the command


Grid for minimization
After the estimation, a counterfactual distribution that is corrected for sample selection may be generated with the postestimation command


Corrected versus uncorrected quantiles
Finally, we illustrate the use of the


4.2 Wage inequality in the United Kingdom
In this example, we apply the model to measure market-level changes in wage inequality in the United Kingdom. We compare wages of males and females at different quantiles of the wage distribution, correcting for selection into work. We replicate Arellano and Bonhomme (2017) using the dataset provided by the authors, which originally comes from the Family Expenditure Survey from 1978 to 2000. 6
We model log-hourly wages Y and employment status D. The controls X include linear, quadratic, and cubic time trends, 4 cohort dummies (born in 1919–1934, 1935–1944, 1955–1964, and 1965–1977, omitting 1945–1954), 2 education dummies (end of schooling at 17 or 18 and end of schooling after 18), 11 regional dummies, marital status, and the number of kids split by age categories (6 dummies, from 1 year old to 17–18 years old).
The excluded regressor follows Blundell, Reed, and Stoker (2003) and corresponds to their measure of potential out-of-work (welfare) income interacted with marital status. This variable was constructed for each individual in the sample by using the Institute of Fiscal Studies tax and welfare-benefit simulation model.
Arellano and Bonhomme (2017) fit the sample-selection model independently by gender and marital status. We replicate (see code below) the exercise reported in the article using a Frank copula and find that the copula parameter in the case of married individuals is −1.548 for males and −1.035 for females (the associated rank correlations are −0.250 and −0.170, respectively). For single individuals, the copula parameter is −7.638 for males and −0.421 for females (the respective rank correlations are −0.790 and −0.070). After the estimation using each subsample, we use



Wage quantiles by gender. notes: Quantiles of log-hourly wages, conditional on employment (solid lines) and corrected for selection (dashed). Male wages are plotted in thick lines, while female wages are in thin lines.
5 Concluding remarks
In this article, we introduced a new community-contributed command called
Additional empirical applications of the econometric method here implemented included the analysis of the gender gap between earnings distributions in Maasoumi and Wang (2019) and the analysis of earnings inequality correcting for nonresponse in Bollinger et al. (2019).
7 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211063148 - Implementing quantile selection models in Stata
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211063148 for Implementing quantile selection models in Stata by Ercio Muñoz and Mariel Siravegna in The Stata Journal
Footnotes
6 Acknowledgments
We thank Jim Albrecht, Wim Vijverberg, and the participants of the 2020 Virtual Stata Conference for useful comments and suggestions.
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type