
Abstract
In this article, I discuss the method of relative distribution analysis and present Stata software implementing various elements of the methodology. The relative distribution is the distribution of the relative ranks that the outcomes from one distribution take on in another distribution. The methodology can be used, for example, to compare the distribution of wages between men and women. The presented software,
Keywords
1 Introduction
Although earlier work on relative distributions and related approaches can be found in the statistical literature (for example, Ćwik and Mielniczuk [1989, 1993]), the methodology has not been popular in applied work before Mark S. Handcock, Martina Morris, and coauthors introduced it to the social sciences in some influential applied (Morris, Bernhardt, and Handcock 1994; Bernhardt, Morris, and Handcock 1995; and Bernhardt et al. 2001) and methodological contributions (Handcock and Morris 1998, 1999; Handcock and Janssen 2002) in the mid 1990s and early 2000s. Even today, however, relative distribution methods do not seem to experience very widespread use, which might partly be because of lack of user-friendly statistical software supporting such analyses (apart from an R package by Handcock and Aldrich [2002]; see Handcock [2016]).
Nevertheless, I believe that relative distribution analysis is a valuable complement to other approaches for distributional comparisons, which typically look at differences in (counterfactual) density, distribution, or quantile functions (for example, DiNardo, Fortin, and Lemieux [1996] and Chernozhukov, Fernández-Val, and Melly [2013]). A key feature of relative distribution analysis is that it focuses on positions within distributions rather than on absolute outcome values. The methodology can be used, for example, to study how wage distributions differ by gender or ethnic groups or how income polarization changed over time. A few examples from the literature illustrate the scope of potential applications: Alderson, Beckfield, and Nielsen (2005) studied changes in income inequality in several countries; Bliege Bird et al. (2008) analyzed the anthropogenic influence on vegetational diversity in Australia; Del Giudice (2011) looked at gender differences in adult romantic attachment; Eggers and Spirling (2016) studied cohesive party voting in the British House of Commons between 1836 and 1910; Clementi, Molini, and Schettino (2018) analyzed changes in the consumption distribution over time in Ghana; and Panek and Zwierzchowski (2020) studied changes in household income polarization in Poland.
In an attempt to improve the accessibility of the methodology to applied researchers, I provide an overview of relative distribution methods in this article, and I present software that makes the methodology available in Stata. The software, called
The article is structured as follows. In the next section, I give an overview of the main concepts of relative distribution analysis, including definitions of relative ranks and the relative distribution, as well as elements such as location and shape decompositions, distributional divergence and relative polarization summary measures, and covariate adjustment approaches. Most of the discussed material is also covered in Handcock and Morris (1999), but I focus on elements I consider most relevant from an applied perspective, and I use a somewhat different notation. Furthermore, I introduce reweighting as an additional strategy for covariate adjustment. In section 3, I then discuss the computational details involved in the estimation of the quantities presented in section 2. I cover different variants of how to compute relative ranks, the relative cumulative distribution, the relative density, the relative histogram, summary measures, and covariate balancing, and I distinguish between continuous and categorical outcomes when relevant. Again, many of the relevant issues are also addressed by Handcock and Morris (1999), but my exposition is more focused on specific implementation. Section 4 then introduces the software and its options, and section 5 provides several worked examples.
The article further contains an appendix covering the estimation of sampling variances by means of influence functions (IFs). The appendix is rather technical and can safely be ignored by readers who are only interested in the practical application of the methods; it is not needed for obtaining an understanding of relative distribution methods and for being able to correctly apply the software and interpret the results. Nonetheless, I consider the appendix an important and original contribution providing results that cannot be found elsewhere in the literature. I first illustrate how IFs can be obtained by analogy to the method of moments and then derive specific expressions for all relative distribution quantities of interest, including possible covariate adjustment. One virtue of an IF-based approach is that it leads to expressions that are compatible with complex survey estimation.
2 Theory
In this section, I summarize the main statistical concepts that are relevant for relative distribution analysis. For an in-depth treatment of the topic, see Handcock and Morris (1999). For a more recent introduction, also see chapter 5 in Hao and Naiman (2010).
2.1 CDF and density
Let Y be a continuous outcome variable of interest. Y is assumed to be a random variable with CDF
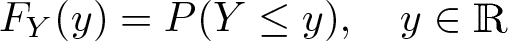
That is, for any value y, the CDF provides the probability of Y taking on a value that is smaller than or equal to y. The PDF of Y is then defined as the first derivative of the CDF, that is,

Hence, the integral of the density from −∞ to y is equal to the value of the CDF at value y:

Likewise, the integral of the density between values a and b provides the probability that Y falls into interval (a, b]:

Finally, let
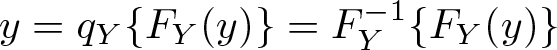
2.2 Relative ranks
Define

as the “relative rank” of outcome y in distribution FY . Because FY is a CDF, r lies between 0 and 1. Handcock and Morris (1999) call r the “relative data”, and Ćwik and Mielniczuk (1989) speak of the “grade transformation”.
Relative ranks have a distribution themselves that depends on the distribution of the y values at which rY (y) is evaluated. For example, if the y values are distributed according to FY , then r has a uniform distribution.
2.3 The relative distribution
Let FX
be a comparison distribution and FY
be a reference distribution. In relative distribution analysis, we are interested in how FX
is distributed relative to FY
. The relative CDF of FX
with respect to FY
is defined as the distribution of the relative ranks that outcome values distributed according to FX
take on in distribution FY
. That is, we are interested in the distribution of rY
(y) for y values distributed according to FX
, which can be obtained by inverting r to y using

Stated differently, for each value of r = FY (y), the relative CDF obtains the corresponding value of FX (y), keeping y fixed, which leads to the tuples
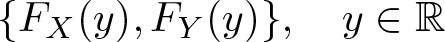
Plotted in a diagram with

Illustration of the relative distribution
2.4 The relative density
Because G(r) is a CDF, we can take the first derivative to obtain the density. Employing the chain rule, the relative PDF of FX with respect to FY can be written as

As can be seen, the relative density is equal to the ratio of the densities of the two distributions at a specific y value [that is, g(r) is equal to the ratio of the two densities at the y value equal to quantile r of FY ]. Nonetheless, g(r) is a proper PDF because it is positive and integrates to 1.
If the two compared distributions are identical, g(r) will be equal to 1 for all r, as is easy to see in (2). If the comparison distribution tends to have lower values than the reference distribution, the relative density will be larger than 1 at low values of r and smaller than 1 for large r (and vice versa). Likewise, assuming similar locations of the two distributions, if the comparison distribution is more polarized than the reference distribution, the relative density will be larger than 1 at small and large values of r and below 1 in between (and vice versa). An illustration of different situations is provided in the right panel of figure 1.
2.5 Location and shape decomposition
Distributions can have different “locations,” meaning that they differ, say, in their mean or median. If a large location difference exists, the relative CDF and PDF will be dominated by this difference. In many applications, it may thus be informative to distinguish between a “location effect” and the difference in distributional shape, net of location.
As shown by Handcock and Morris (1999), the overall relative density can be decomposed into a “location effect” and a “shape effect” by constructing a location-adjusted distribution and then using this counterfactual distribution in place of either FX or FY . For example, let

be a location-adjusted variant of Y , where µ is a location measure such as the median or the mean. In general, if

is a location-adjusted reference distribution that has the same location as the comparison distribution. The overall relative density can then be written as

The first factor, the location effect, is equal to the ratio between the density of the location-adjusted reference distribution and the unadjusted reference distribution. The second factor, the shape effect, is the ratio between the density of the (unadjusted) comparison distribution and the location-adjusted reference distribution. However, note that

is not a proper density, because it is evaluated over y values distributed according to FY
instead of

or the corresponding adjusted relative CDF

Instead of adjusting FY , the decomposition could also be defined by adjusting the comparison distribution. That is, we could use

such that

As above, one of the components is not a proper density. To describe the location effect, we may thus prefer

instead of
So far, an additive location shift has been used to adjust the comparison or reference distribution. For variables that can only be positive (for example, wages), it may be more natural to use a multiplicative shift and hence rescale the data proportionally. A multiplicative location adjustment of the reference distribution is given by

The comparison distribution could be adjusted analogously. Furthermore, besides the location, we could also adjust the scale of the distributions. An (additive) location and scale adjustment of the reference distribution could be accomplished using

where s is a scale measure such as the interquartile range (IQR) or the standard deviation. For the multiplicative adjustment, there is no natural way to take account of the scale. However, using logarithms we can implement a proportional location and scale adjustment as
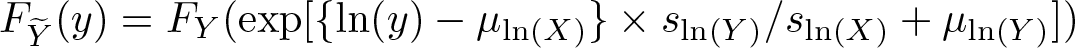
2.6 Summary measures
2.6.1 Divergence
Handcock and Morris (1999) suggest Pearson’s χ 2 divergence and the Kullback–Leibler divergence (relative entropy) as measures for distributional divergence, that is, as summary measures for the overall difference between the comparison distribution and the reference distribution. The χ 2 divergence between FX and FY is defined as

The equality between the first and second expressions follows from the substitution rule for integrals, noting that

For both measures, the divergence of FX with respect to FY is not generally equal to the divergence of FY with respect to FX . That is, the direction from which we look at the problem matters. An example for a symmetric divergence measure 2 is the total variation distance (TVD)

which is equal to half the area between the relative density curve and the parity line. Besides being symmetric, the TVD has an intuitive interpretation: it quantifies the proportion of data mass that would have to be redistributed in one of the distributions to make it equal to the other distribution. In the case of categorical data, the TVD is equal to the dissimilarity index by Duncan and Davis (1953), which is often used in analyses of segregation (for Stata implementations, see, for example, Jann [2004] or Reardon and Townsend [1999]).
For all three measures, in a location and shape decomposition, the location-effect divergence and the shape-effect divergence do not add up to the overall divergence. For example, we could location-adjust the reference distribution as in (3) and then obtain the location-effect divergence from


This suggests that, in practice, it may make sense to identify the location-effect divergence as the difference between the overall divergence and the shape-effect divergence. An advantage of such an approach is also that results will not depend on whether we adjust the reference distribution or the comparison distribution.
2.6.2 Polarization
To compare the degree of inequality between the comparison distribution and the reference distribution, Handcock and Morris (1999) suggest the median relative polarization index (MRP). The index is positive if the comparison distribution is more unequal than the reference distribution; if the reference distribution is more unequal than the comparison distribution, the index will be negative. The MRP is defined as

where EX
is the expectation over the comparison distribution and
The MRP can be decomposed into a lower polarization index (LRP) and an upper polarization index (URP) that quantify the relative polarization in the lower or upper half of the distribution, respectively:

Because the conditional expectations in the definitions of LRP and URP each cover half the distribution of the location-adjusted relative ranks, the total polarization index is equal to the average of the lower and upper indices, that is,
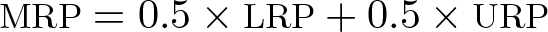
2.6.3 Other summary measures
Descriptive statistics of the relative ranks compose a further class of relative distribution summary measures. Quantities of interest may be, for example, the mean or median of the relative ranks, their standard deviation, or their IQR.
Note that the mean of the relative ranks is equivalent to the Gastwirth index, which measures the “probability that a randomly selected woman earns at least as much as a randomly chosen man” (Gastwirth 1975, 33). 3
2.7 Covariate balancing
2.7.1 Integrating over conditional distributions
Handcock and Morris (1999) discuss covariate adjustment in terms of conditional distributions integrated over covariates. I will slightly change notation for the following exposition. Let D ∊ {0, 1} be an indicator distinguishing between a comparison group (D = 1) and a reference group (D = 0), and let Y be an outcome variable available in both groups. The comparison distribution is FY | D =1, that is, the distribution of Y in group D = 1; the reference distribution is FY | D =0. Furthermore, let Z be a continuous covariate. Our goal is to obtain the relative distribution of FY | D =1 with respect to FY | D =0 while adjusting for possible differences in the distribution of Z between the two groups.
The marginal distribution of Y in group d can be written as

where fZ (z) is the density of Z and FY | Z (y|z) is the conditional distribution of Y given Z. A counterfactual distribution can now be constructed by replacing one of the components. For example,

is the marginal distribution of Y that we would expect in the reference group if it had the same covariate distribution as the comparison group. That is, we can obtain the counterfactual distribution by integrating the conditional distribution of Y in the reference group over the covariate distribution of the comparison group. The covariateadjusted relative distribution can then be obtained by comparing FY
|
D
=1 with
The approach can be generalized to multiple covariates by integrating over the joint distribution of all covariates or to discrete covariates by taking weighted sums instead of integrals.
2.7.2 Reweighting
An equivalent but more attractive approach from an applied perspective is to conceptualize covariate adjustment as reweighting in the spirit of DiNardo, Fortin, and Lemieux (1996). Define

as the conditional probability of belonging to the comparison group given Z. Furthermore, define

We can then write the counterfactual distribution of Y in the reference group as
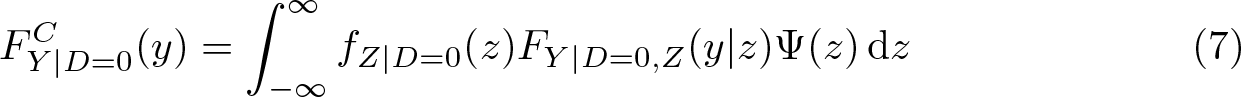
This indicates that the counterfactual distribution can be estimated by simply reweighting the data by an estimate of Ψ(z). 5 Mathematically, (7) is equivalent to (6) because
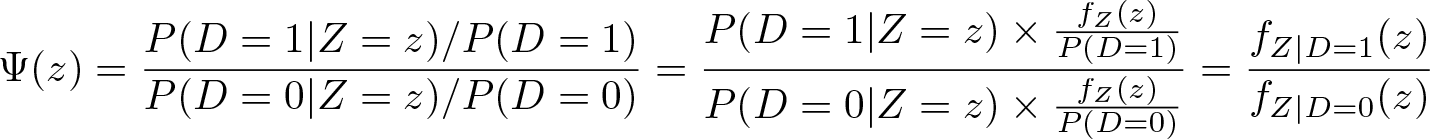
(using Bayes’ theorem in the last step). The practical advantage of reweighting over integrating is that Pr(D = 1|Z = z), and therefore, Ψ(z) is relatively easy to estimate using binary choice models even if Z is a vector of several covariates (for example, logistic regression). 6
In any case, whether we integrate over conditional distributions or we use reweighting, constructing counterfactual distributions in such a way assumes that the conditional distribution of Y is “stable”, that is, that the covariate distribution can be modified without changing the conditional distribution. However, even if such an exogeneity assumption is unrealistic in a given application, the “as if” scenarios based on counterfactual distributions can still be informative.
Furthermore, note that reweighting can be used as an alternative approach to identify location and shape effects (instead of applying adjustments as described in section 2.5) by modeling Ψ as a function of Y . This is particularly useful if the analyzed outcome is categorical.
3 Estimation
For the following discussion, assume that there is a random sample of size n for which we observe two variables, X and Y . Furthermore, there is information on sampling weights w as well as a (possibly empty) vector of covariates Z. That is, the data are (Yi, Xi, wi, Zi ), i = 1,…, n. Set wi = 1 for all i in case there are no sampling weights.
We intend to analyze the relative distribution of X with respect to Y between two subsamples. Let D be an indicator for the comparison subsample (Di = 1 if observation i belongs to the comparison subsample, 0 if it does not), and let D = {i|Di = 1} be the set of indices for which Di = 1. Likewise, let R be an indicator for the reference subsample (Ri = 1 if observation i belongs to the reference subsample, 0 if it does not), and let R = {i|Ri = 1} be the set of indices for which Ri = 1. That is, we want to compare the distribution of X in subsample D with the distribution of Y in subsample R.
We will use FX
|
D
to denote the former, that is, the conditional distribution of X given D = 1, and FY
|
R
to denote the latter. In general, we will use letter “D” for quantities related to D and letter “R” for quantities related to R. For example,
Note that Y and X may be the same and that D and R do not have to be distinct nor exhaustive. I use such a general setup to cover all possible cases. For example, if the subsamples are distinct and Y = X, then we are in a setting in which a single variable is compared between two groups (for example, a comparison of wages from a sample of females to wages from a sample of males). Likewise, if D = R and Y ≠ X, we compare two variables within the same sample (for example, a comparison of data on wages for the same individuals between two time points). Furthermore, if X = Y and D is included in R, then we compare the distribution of a variable in a subsample with the pooled distribution of that variable. Finally, if the union of D and R does not cover the whole sample (that is, if there are observations for which D = R = 0), we are in a subpopulation estimation setting. Taking account of the observations that do not belong to the subpopulation may be important for standard error estimation.
3.1 The relative CDF
To obtain an estimate for the relative CDF
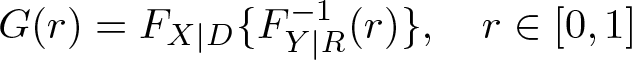
one can compute the relative rank of Xi in distribution FY | R for each i ∊ D and then take the value of the empirical CDF of these relative ranks at value r. That is, first compute

where

An issue with this simple computation is that it leads to a step function with jumps at distinct values of
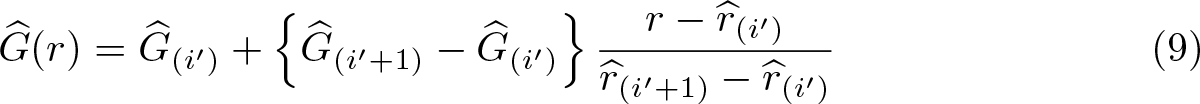
with

where i′ is selected such that
Equation (9) improves on (8) in that it uses interpolation in regions where (8) is flat. It does not, however, take into account that flat regions in (8) may include outcome values that only exist in FY
|
R
, nor does it take into account that there might be regions where the true G(r) is upright because of outcome values that only occur in FX
|
D
. To handle these issues and obtain an estimate that exactly traces the observed data pattern, we can compute the empirical CDF for FX
|
D
and FY
|
R
at each observed value in the data and then use linear interpolation to obtain

for all j = 1,…, J, add origin

where jr
and jr
denote the smallest and largest value of j, respectively, for which
If all values in Y exist in both distributions, (10) will lead to the same results as (9). Furthermore, for continuous data, at least if the dataset is not very small, results from the two approaches will be very similar. Equation (10), however, leads to more appropriate results than (9) if the data are discrete.
3.2 Computing relative ranks
Relative density estimation and the estimation of summary measures of the relative distribution are typically implemented by analyzing the relative ranks of Xi , i ∊ D in distribution FY | R . A naïve approach is to compute the relative ranks using the values of the empirical CDF of FY | R , that is,

A problem with this approach is that the empirical CDF is a step function. This is particularly troublesome if there is heaping in the data such that there are large steps in the CDF, as is often the case with discrete data. One improvement is to use the so-called middistribution function instead of the regular CDF that deducts half a step size from the ranks in regions where the CDF is upright. 7 Let

be the relative frequency of outcome y in FY | R (that is, the step size in the CDF at value y). The relative ranks computed according to the middistribution function then are

Note that (12) differs from (11) only for observations that have ties in FY
|
R
(that is, observations that hit a step). For all other observations,
Using the midrank adjustment removes the bias in the relative ranks. Heaping, however, will still lead to undesirable results such as arbitrary spikes in the relative density estimate. A solution to this second issue is to break ties randomly and hence smooth out the step sizes of the CDF across tied observations. These broken relative ranks (including midrank adjustment) can be written as

where

which simplifies to δi = ki/Ki if the weights are constant. 8
To obtain broken relative ranks without midrank adjustment, set 0.5wi in (13) to 0.Whereas the midrank adjustment can have a strong effect on results if relative ranks are computed without breaking ties [(11) versus (12)], the adjustment is only of minor importance in (13) because breaking ties makes the individual step sizes small (unless there is large variation in weights).
For location-adjusted relative ranks, the same equations can be applied to appropriately transformed input variables. For example, to compute the relative ranks based on a location-adjusted reference distribution, use

instead of Y in the above equations, where
In contrast, for shape adjustment, one of the distributions has to be swapped. For example, to compute the relative ranks based on a shape-adjusted comparison distribution (that is, a comparison distribution that has the same shape as the reference distribution but a different location), use
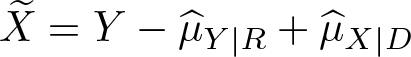
instead of X, and then set the comparison sample to
3.3 The relative PDF
3.3.1 Kernel density estimation for continuous data
Estimation of the relative density can be implemented by applying a univariate density estimator to the relative ranks [preferably as defined in (13)]. Compared with a standard density estimation problem, there are two specific complications that should be accounted for. First, the support of the relative density is bounded at 0 and 1. Standard density estimators, however, are designed such that they smoothly approach 0 outside the support of the observed data, which leads to an underestimation of the density at the boundaries. Second, automatic bandwidth selection should be adapted to take account of the specific nature of relative data.
Given an evaluation point r ∊ [0, 1], a kernel density estimate of the relative density can be written as

where

where K(x) is a standard kernel function such as the Gaussian kernel. The logic of the procedure is to rescale the density estimate by the inverse of the area of the kernel function that lies within the support of r. For some alternative boundary correction techniques, see Jann (2007).
The bandwidth h that determines the degree of smoothing (larger values for h lead to a smoother PDF) can either be set manually or be determined automatically from the data. Various suggestions for automatic bandwidth selectors exist in the literature, some based on crude rules of thumb and some employing more sophisticated procedures (see Jann [2007] for an overview of some of the suggestions). For relative density estimation, these standard bandwidth selectors should be adapted to take account of the specific nature of relative data. Suggestions for appropriate modifications are given by Ćwik and Mielniczuk (1993). The
3.3.2 Histogram density estimation
A complement to kernel density estimation is to obtain a histogram of the relative density. Let (a, b ] be an interval on the support of r. The histogram density estimate for that interval can then be obtained as
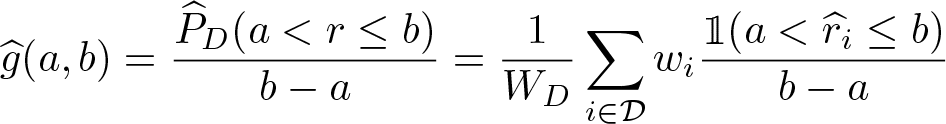
(with a modification in the case of a = 0 such that the interval includes the lower bound). A convenient setup is to split the support of r into K evenly sized bins defining the intervals
The histogram density has an intuitive interpretation. For example, a value of 2 means that the fraction of the comparison distribution that falls into the bin is twice as large as the fraction of the reference distribution. In other words, the comparison distribution is overrepresented in the bin by a factor of 2. A value of 0.5 means that the proportion of the comparison distribution is only half the proportion of the reference distribution. A kernel density estimate of the relative ranks has, in principle, the same meaning (it shows the relative overrepresentation or underrepresentation multiplier at each level of r), but the explicit binning may make the histogram more easy to interpret.
3.3.3 Discrete relative density for categorical data
For categorical data, the relative density can be computed directly from the relative probabilities across the levels of the data. Without loss of generality, let k = 1,…, K be these levels. The relative density for level k is then estimated as
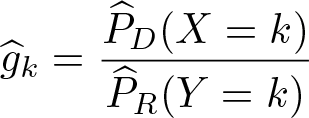
with

Discrete relative density
When plotting the relative density for categorical data,
3.4 Divergence
3.4.1 Continuous data
To estimate the χ 2, Kullback–Leibler, and dissimilarity measures, obtain an estimate of the relative density over a grid of evaluation points and then “integrate” the result. For example, let rk = k/K − 1/(2K), k = 1,…, K, be a regular grid of evaluation points spanning the support of r from 1/(2K) to 1 − 1/(2K). The divergence measures can then be estimated as

where
An alternative is to obtain the divergence measures from a histogram of the relative density. Assuming K evenly sized bins covering the whole range of r, the histogrambased estimates of the divergence measures can be obtained using (15) with
3.4.2 Categorical data
Divergence measures for categorical data can be defined in terms of the categorical relative density as introduced above. Let k = 1,…, K be the levels of the data. The divergence estimates then are

where
3.5 MRP
For the polarization indices, first compute location-adjusted relative ranks using one of the above methods, where the median is used as the location measure. Let

Furthermore, using

as estimates for LRP and URP ensures that

Note that, in theory, the MRP of FX | D with respect to FY | R is equal to −MRP of FY | R with respect to FX | D . In practice, however, heaping in the data may cause the median of the location-adjusted relative ranks to differ from 0.5 and hence cause this relation to be violated. Applying middistribution correction and breaking ties when computing the ranks typically reduces the discrepancy but may not entirely remove it.
3.6 Covariate balancing
Assume that D and R are distinct and exhaustive, such that D is an indicator for the comparison group (D = 1) versus the reference group (D = 0). A simple approach for covariate adjustment by reweighting is to run a logistic regression of D on Z and obtain predictions

where

with
4 The reldist command
The command

4.1 Syntax
4.1.1 Estimation
The command
Syntax 1 (two-sample relative distribution):
where groupvar identifies two groups to be compared.
Syntax 2 (paired relative distribution):
where varname and refvar specify two variables to be compared.
In both cases,

4.1.2 Creating a graph after estimation
After applying
4.1.3 Storing IFs after estimation
The command
where stub specifies a common prefix for the names of the generated variables; alternatively, newvarlist specifies an explicit list of variable names to be used. Option
The command
4.2 Options for reldist
4.2.1 Main options
logit_options are options to be passed through to
adjust [, options]
where adjust specifies the desired adjustments. adjust may contain any combination of at most two of the following keywords:
By default, the specified adjustments are applied to the comparison distribution. However, a colon may be included in adjust to distinguish between distributions: Keywords before the colon affect the comparison distribution; keywords after the colon affect the reference distribution. For example, type
rank_options specify the details about the computation of relative ranks. These options are irrelevant for
4.2.2 Additional options for reldist pdf
density_options set the details of kernel density estimation. The options are as follows:
By default, if estimating the density of the relative data, all bandwidth selectors include a correction for relative data based on Ćwik and Mielniczuk (1993). Specify suboption
4.2.3 Additional options for reldist histogram
4.2.4 Additional options for reldist cdf
4.2.5 Additional options for reldist divergence
density_options set the details of the kernel density estimation. This is only relevant if option
are not allowed if
4.2.6 Additional options for reldist mrp
4.2.7 Additional options for reldist summarize

4.2.8 Variance estimation options
The default is
If a replication technique is used for standard error estimation (that is,
Simulation results suggest that the IF-based standard errors work well in most situations. They may be severely biased, however, if there is heaping in the data. Replication-based techniques may yield more valid results in this case.
4.2.9 Reporting options
4.3 Options for reldist graph
4.3.1 Main graph options
4.3.2 Additional options after reldist pdf
cline_options affect the rendition of the PDF line. See [G]
barlook_options affect the rendition of the histogram bars. See [G]
4.3.3 Additional options after reldist histogram
barlook_options affect the rendition of the histogram bars. See [G]
4.3.4 Additional options after reldist cdf
cline_options affect the rendition of the CDF line. See [G]
4.3.5 Confidence intervals
4.3.6 Outcome labels
[
suboptions are as described in [G]
Option [
[
numlist
where numlist specifies the outcome values for which ticks are to be generated and suboptions are as described in [G]
[
where numlist specifies the outcome values for which added lines be generated and suboptions are as described in [G]
[
Technical note: The positions of the outcome labels, ticks, or lines are computed from information stored by
where

4.3.7 General graph options
twoway_options are any options other than
4.4 Stored results
5 Examples
5.1 Wage mobility in two eras
I illustrate some of the features of

Wage growth has been somewhat larger in the original cohort than in the recent cohort. The outcome variable is defined as the difference in (constant dollar) log hourly wages, so a value of 1.085 for the original cohort corresponds to a real wage growth of {exp(1.085)−1}×100 = 196%. For the recent cohort, the average is only 0.878 (141%). We can also see that inequality in wage growth has been more pronounced in the recent cohort than in the original cohort because the standard deviation of log wage gains is larger. Looking at the median and IQR instead of the mean and standard deviation leads to qualitatively similar findings.
5.1.1 The relative CDF
The relative CDF of log wage gains between the recent cohort and the original cohort can be obtained as follows, with the graph displayed in figure 0.2:
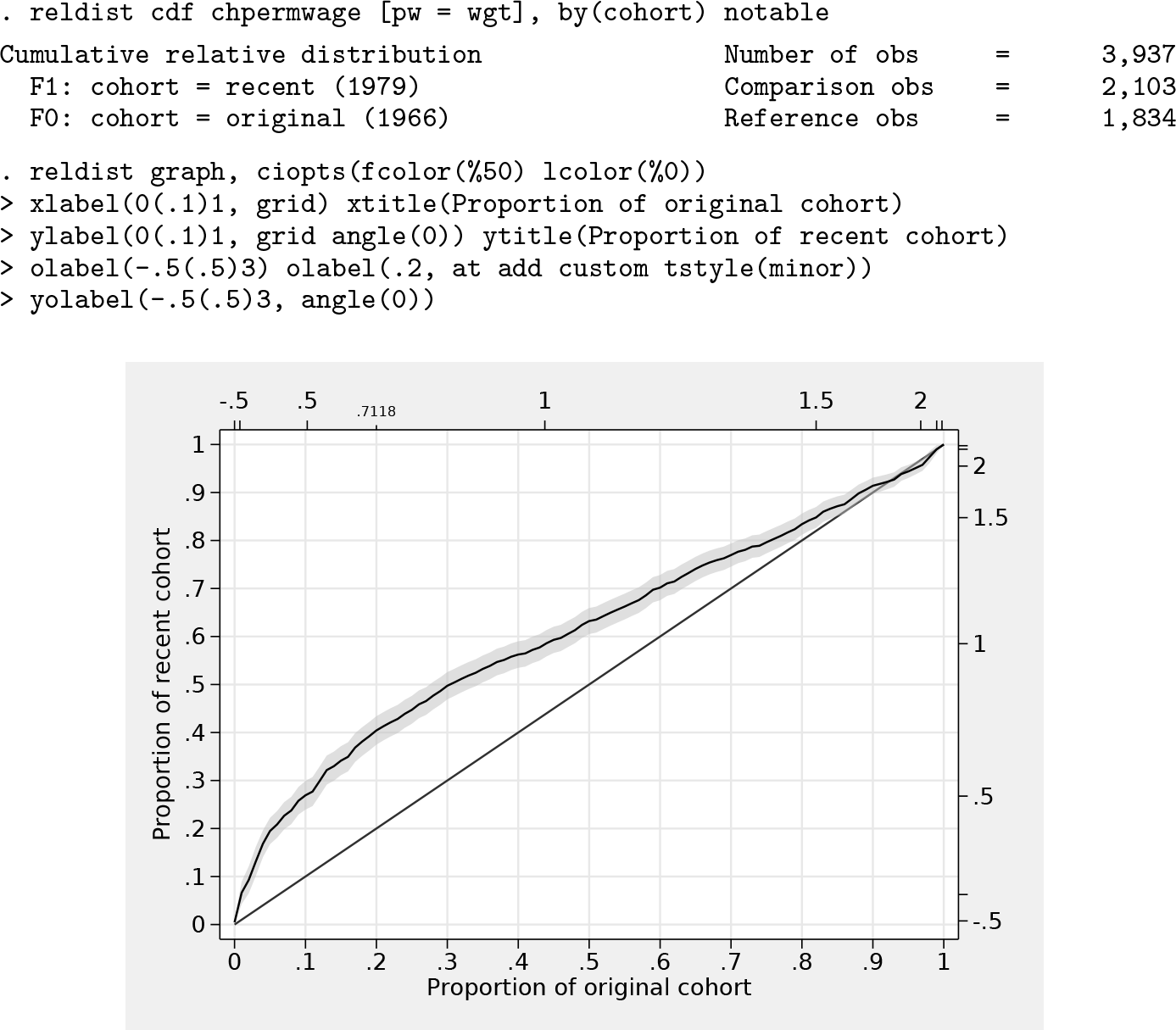
The horizontal axis of the graph corresponds to cumulative proportions of the original cohort, and the vertical axis corresponds to cumulative proportions of the recent cohort; both are ordered by the size of wage growth. Each point on the curve maps quantiles of the two distributions. For example, the value of the 20% quantile in the original cohort is equal to the 40% quantile in the recent cohort because the curve crosses point (0.2, 0.4). The 20% quantile in the original cohort corresponds to a log wage growth of 0.7118, that is, a wage growth of about 104%. In the original cohort, 20% experienced a wage growth of at most 104%; in the recent cohort, this proportion increased to 40%. That is, relative to the original cohort, wage growth of 104% or less is overrepresented by factor 2 in the recent cohort.
Comments on the used commands: Option

Coefficient
Furthermore, the graph has been produced by first estimating the CDF using
5.1.2 The relative PDF
Relative overrepresentation and underrepresentation of the recent cohort with respect to the distribution of wage growth in the original cohort can be seen more directly in the relative PDF. The relative PDF can be obtained as follows, with the graph displayed in figure 3:
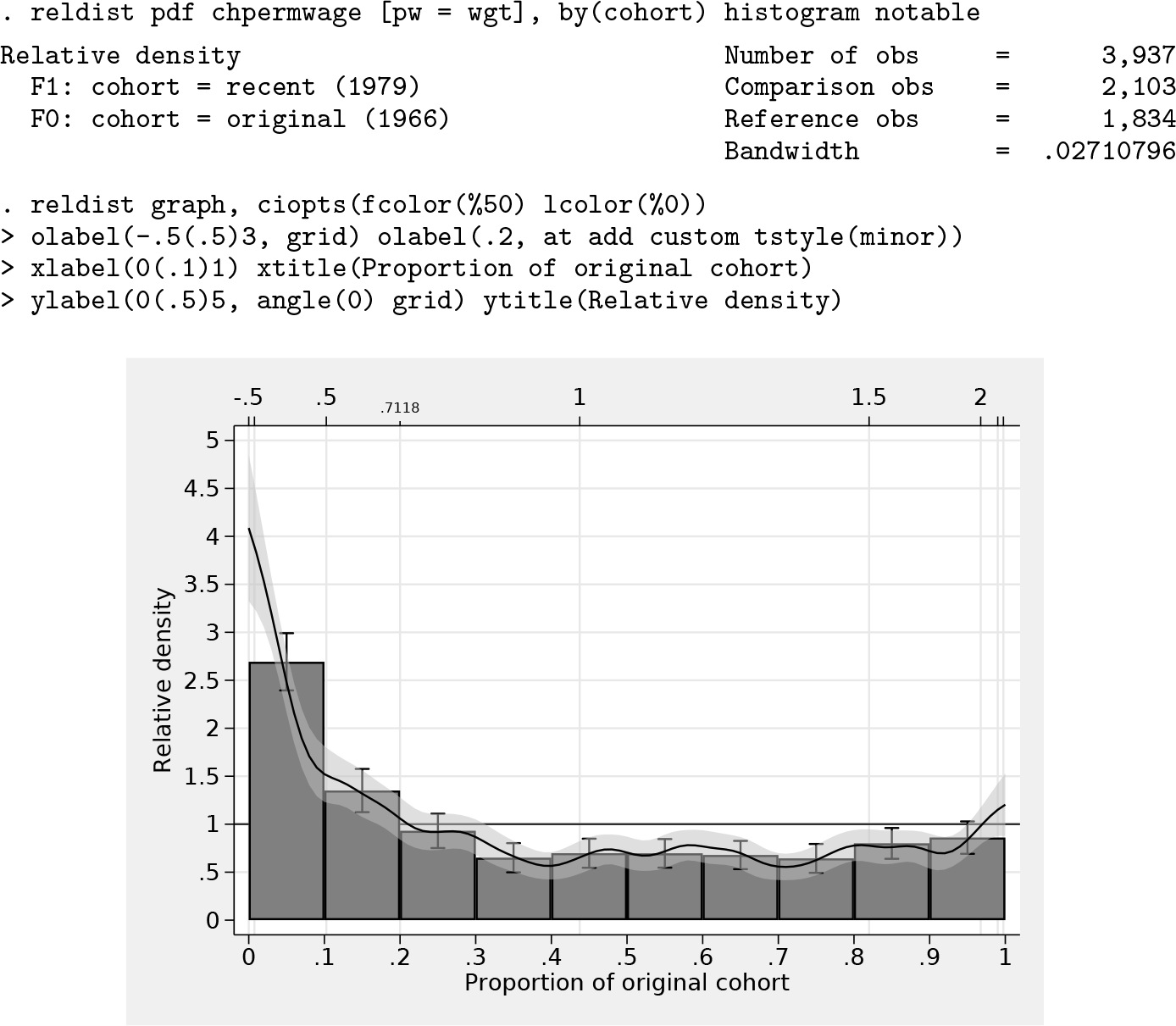
A relative density larger than 1 means the recent cohort is overrepresented at the corresponding level of wage gains, and values lower than 1 mean the recent cohort is underrepresented relative to the original cohort. We can now directly see that the largest distributional differences are at the bottom of the distribution. The recent cohort has a much larger density than the original cohort in regions below the 10% quantile of the original cohort (overrepresentation factor of 1.5 to 4) and generally a larger density below about the 20% quantile. At quantiles above that, the recent cohort is underrepresented, although there is some evidence for a reduced discrepancy at the top of the distribution (above the 80% quantile) or even a reversal at the very top (above, say, the 97% quantile; although the confidence interval includes the parity line in this region, which means that the relative density is not significantly different from 1).
5.1.3 Location and shape decomposition
The difference in the distribution of wage gains between the original cohort and the recent cohort may have various reasons. As indicated above, wage gains have been larger on average in the original cohort than in the recent cohort, which may be because of a general difference in economic growth between the two eras that affected all population members similarly. In such a case, the distribution of wage gains in the recent cohort would differ from the distribution in the original cohort only in its location. However, the structure of wage gains might also have changed, for example, because of rising returns on education, leading to more polarization of wage gains in the recent cohort. In this case, the shape of the two distributions would also be different. To separate location effects from effects of distributional differences net of location, so-called location and shape decompositions can be useful.
The following commands produce a graph containing three panels, shown in figure 4.
12
The first panel shows the overall (unadjusted) relative density (same as above). The second panel shows how the relative density looks if we only allow a difference in location but keep the distributional shape fixed. This is achieved by applying option


The results indicate that the difference between the recent cohort distribution and the original cohort distribution is not only a matter of location; there is also a substantial difference in distributional shape. In particular, the recent cohort distribution appears more polarized than the original cohort (also see below).
5.1.4 Distributional divergence
To determine the relative contributions of location and shape differences to the overall distributional divergence between the two cohorts, Handcock and Morris (1999) suggest comparing the entropy (Kullback–Leibler divergence) of the unadjusted and adjusted relative distributions. Such an analysis can be obtained by
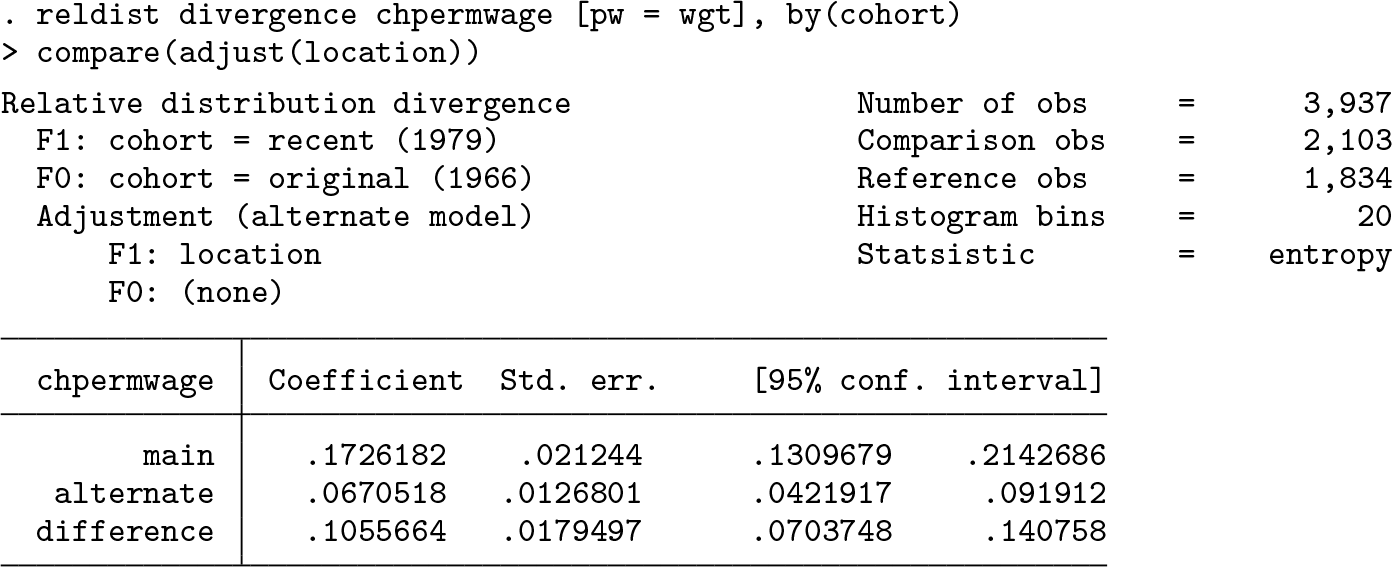
Three divergence values are reported in the above output: the divergence of the unadjusted relative distribution (labeled as

We see that in this example, the difference in location appears to be more relevant (60%) than the difference in shape (40%). Qualitatively, the results are similar to the ones reported by Handcock and Morris (1999), but note that the precise values are different. Handcock and Morris performed a slightly different decomposition (see footnote 15). More importantly, however, the Kullback–Leibler divergence is quite sensitive to the details of the computation of the underlying relative density. By default,
5.1.5 Polarization analysis
As stated above, the recent cohort distribution appears more polarized than the original cohort distribution. A measure to quantify the polarization is the MRP computed by

The results indicate that the recent cohort distribution is indeed more polarized because the value of the MRP is positive, of substantial magnitude (the possible range of the MRP is between −1 and 1), and significantly different from 0. Furthermore, the breakup into polarization of the lower half (LRP) and the upper half (URP) of the distribution suggests that the degree of relative polarization is similar in both tails.
5.1.6 Covariate balancing
Education may be one important determinant of the wage distribution as well as the distribution of wage gains over an occupational career. Hence, if the educational distribution changed between the original cohort and the recent cohort, we may be comparing apples with oranges. That is, one reason for the difference in the distribution of wage gains in the two cohorts may be that the cohorts have a different educational composition. This indeed seems to be the case if we look at the relative density of educational levels between the cohorts. 16 The resulting graph is shown in figure 5.

Lower educational levels appear to be more frequent in the recent cohort than in the original cohort (relative density mostly larger than 1), and higher educational levels appear to be less frequent (relative density below 1). Looking at the table, we see that in many cases the confidence interval does not include 1, meaning that these differences between the cohorts are statistically significant.
The question now is whether these differences in educational composition affect the relative distribution of wage gains. Similarly to above in the context of location and shape effects, we can identify the contribution of compositional differences by comparing unadjusted and adjusted relative distributions. The adjustment, however, is now accomplished by reweighting one of the distributions such that its educational composition becomes equal to the educational composition in the other cohort. Option

Adjusting the educational composition does seem to make the distribution of wage gains somewhat more equal between the two cohorts. The comparison between the raw recent cohort and the reweighted recent cohort (middle panel) shows that low (high) wage gains are more (less) frequent in the raw data than in the reweighted data. That is, as expected, reweighting the recent cohort generally shifts the distribution of wage gains upward, thus making it more equal to the distribution of wage gains in the original cohort (the effect of the reweighting is statistically significant, as can be inferred from the confidence intervals that have been included for the histogram). Overall, however, the contribution of the difference in educational composition only seems to be of minor importance: there is only a small difference between the overall relative distribution (left panel) and the education-adjusted relative distribution (right panel).
5.1.7 Location adjustment by means of covariate balancing
Note that reweighting can be used as an alternative method for location adjustments. The default method, provided by option


The two approaches lead to qualitatively similar results. 17 One advantage of the reweighting approach, however, is that heaping in the data will have fewer adverse effects on the results. 18
5.2 Processing results from reldist
5.2.1 Postestimation hypothesis testing
I use the National Longitudinal Study of Young Women 1988 data shipped with Stata to analyze wages of unionized and nonunionized workers. For example, we might be interested in relative wage polarization. An obvious hypothesis is that wages are more polarized among nonunionized workers than among the unionized, but the pattern may be different depending on education. Here are the results for the MRP between nonunionized and unionized workers for different levels of qualification:

Option

The test is negative; that is, we cannot reject the null hypothesis that the two MRP estimates are the same (p-value of 0.229). The same result could also be obtained using
5.2.2 Creating graphs from multiple results
When comparing wages between unionized and nonunionized workers, it may be relevant to make the two groups more comparable by taking background characteristics into account. Possibly, some of the difference in the wage distributions is because of differential composition with respect to these characteristics and not because of unionization status per se. Here is how you could plot the relative density curves based on raw data and on balanced data in a single graph (figure 8) using
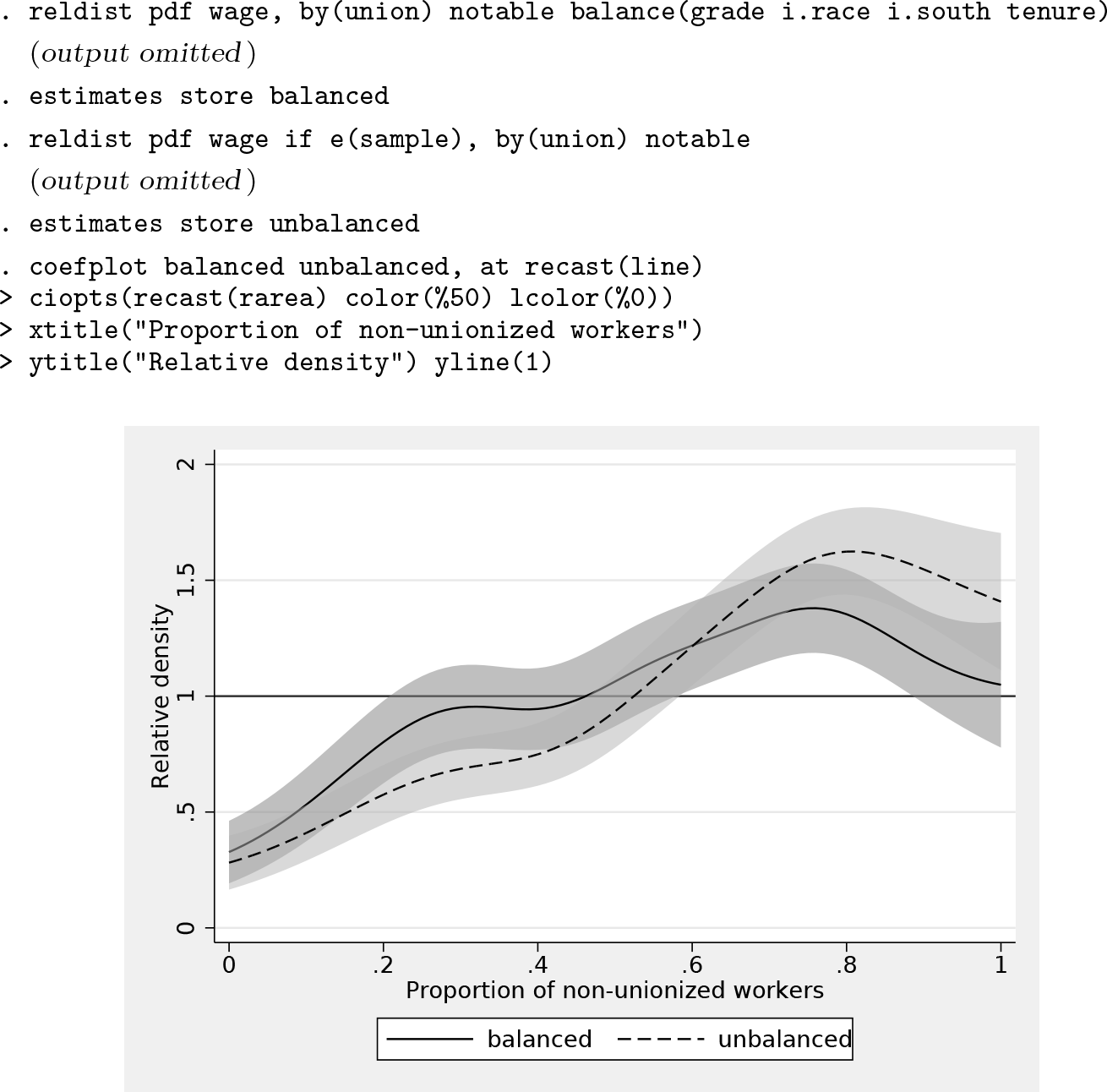
We see that the wage distributions of unionized and nonunionized workers become more similar once we control for background characteristics, especially in the upper part of the distribution.
5.2.3 Working with IFs
The
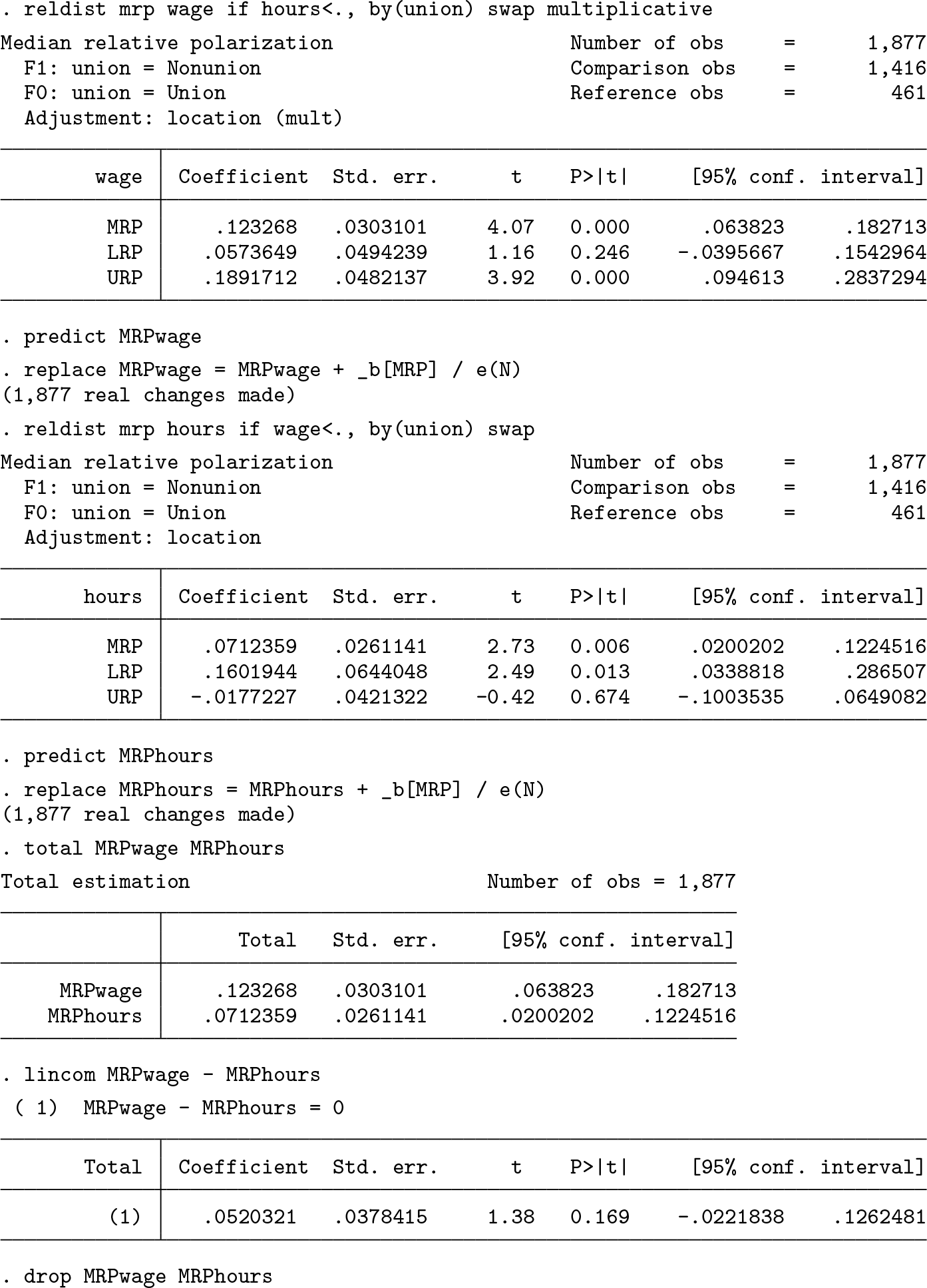
The MRP is higher for wages than for working hours, but the difference does not appear to be statistically significant. In the example, I first stored the IFs and then recentered them by adding the point estimates back in (on the use of recentered IFs, see, for example, Firpo, Fortin, and Lemieux [2009] and Rios-Avila [2020]). The IFs returned by
This is why I divided the point estimate by N before adding it back in. Alternatively, multiply the IF by N, add the point estimate as is, and then use
5.3 Survey estimation

Results indicate that the birthweight distribution is somewhat less polarized for girls (
7 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211063147 - Relative distribution analysis in Stata
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211063147 for Relative distribution analysis in Stata by Ben Jann in The Stata Journal
Footnotes
6 Acknowledgments
I thank Eric Melse for valuable comments on earlier versions of the software that helped improve the command, Blaise Melly for a nudge on how to obtain the IFs for quantiles of relative ranks, and Philippe Van Kerm for pointing me to the work by Joseph Gastwirth. Furthermore, I thank an anonymous reviewer for comments that helped improve the article.
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type