
Abstract
In this article, I describe several updates to
Keywords
1 Introduction
Estimation of long-run relationships is important in empirical applications of economic models, particularly macroeconomic models. Long-run relationships describe how one or more variables react to changes in the steady state. An example would be the relationships between macroeconomic variables, such as gross domestic product (GDP) and inflation. Another would be the effects of investments, exchange rates, educational progress, or technological progress on economic growth.
With pure time-series data, the autoregressive distributed lag (ARDL) model is widely used to estimate long-run relationships. ARDL models estimate the short-run coefficients and then back out the long-run coefficients. They were implemented by the communitycontributed
The estimation of unit-specific coefficients requires datasets with many observations across time periods and cross-sectional units. Such datasets often exhibit cross-sectional dependence (CD). It implies that cross-sectional units depend on each other, for instance, by sharing a common factor. If this dependence is ignored, estimation results can be biased and inconsistent. Therefore, the extent of CD needs to be understood, and the estimation method chosen accordingly. The literature proposes two methods to identify CD. The first is to estimate the strength of the dependence (Bailey, Kapetanios, and Pesaran 2016), and the other is to test for CD (Pesaran 2015). The communitycontributed command
After one establishes the existence of strong CD, it can be approximated or controlled for by either principal components (Bai and Ng 2002; Bai 2009) or adding cross-sectional averages (Pesaran 2006). For a comparison, see Westerlund and Urbain (2015). Because of its simplicity, the approach using cross-sectional averages is very popular and started its own literature; Everaert and De Groote (2016), Chudik, Pesaran, and Tosetti (2011), and Chudik and Pesaran (2015a) provide overviews. The estimation method, called the common-correlated effects (CCE) estimator, applies to static (Pesaran 2006) and dynamic panel models (Chudik and Pesaran 2015b and Karabiyik, Reese, and Westerlund 2017), as well as pooled- (Juodis, Karabiyik, and Westerlund 2021) and mean-group estimators (Chudik and Pesaran 2019). The idea of the estimator is to add cross-sectional averages of the independent and dependent variables that approximate the CD. This estimator was implemented into Stata in the static version by the community-contributed command
Neither of the commands was able to estimate long-run relationships directly. In this article, I introduce an extended version of
The remainder of the article is structured as follows. The next section introduces the panel model, CD, and CCE estimator. Then, I discuss three different methods to estimate the long-run coefficients, first from a theoretical perspective and then from an applied perspective. I give examples on how to fit the models using
2 Panel model and CCE estimators
For this section, assume a dynamic ARDL(1,1) panel model with heterogeneous coefficients in the form of 2
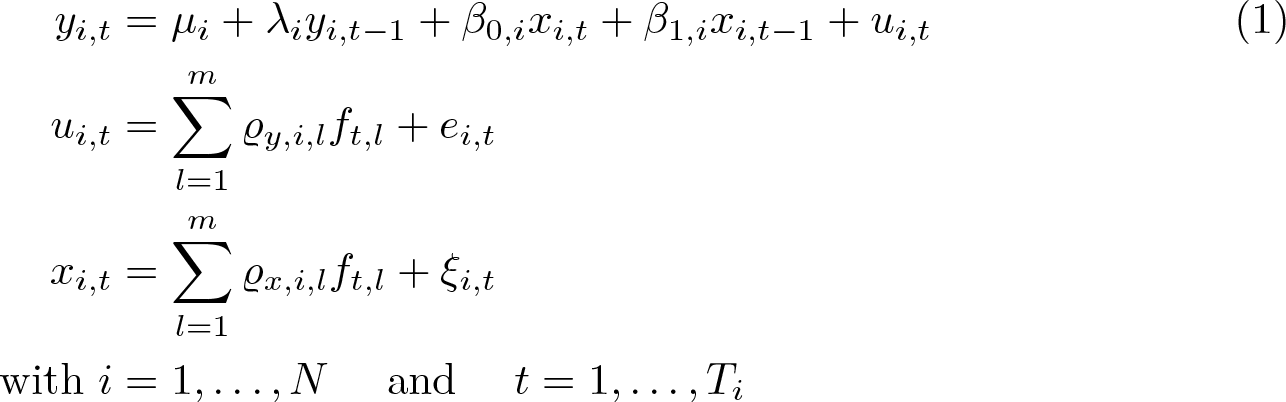
where yi,t is the dependent variable and xi,t an observed independent variable that includes m unobserved common factors ft,l . The estimation of the long-run effect of x on y is the main point of interest. ei,t is a cross-section unit-specific independent and identically distributed error term. The factor loadings ϱx,i,l and ϱy,i,l are heterogeneous across units, and µi is a unit-specific fixed effect. The heterogeneous coefficients are randomly distributed around a common mean, such that βi = β + vi , and λi = λ + ai , where vi and ai are random deviations with mean zero, independent of the error term and the common factors. λi lies strictly inside the unit circle to ensure a nonexplosive series.
2.1 Estimating and testing for CD
The strength of the factors can be measured by a constant 0 ≤ α ≤ 1, the so-called exponent of CD. Depending on its limiting behavior, Chudik, Pesaran, and Tosetti (2011) propose four types of CD: weak (α = 0), semiweak (0 < α < 0.5), semistrong (0.5 ≤ α < 1), and strong (α = 1) CD. (Semi)weak CD can be thought of as the following: even if the number of cross-sectional units increases to infinity, the sum of the effect of the common factors remains constant. In the case of strong CD, the sum of the effect of the common factors becomes stronger with an increase in the number of cross-sectional units.
Bailey, Kapetanios, and Pesaran (2016) propose a method for the estimation of the exponent of a variable under semistrong and strong CD. They derive a bias-adjusted estimator for α and its standard error based on auxiliary regressions using principal components and cross-sectional averages. In the case of estimating the exponent of CD in residuals, Bailey, Kapetanios, and Pesaran (2019) propose to use significant pairwise correlations of the residuals after multiple tests. A closed-form solution for standard errors is not available, and confidence intervals are constructed using a simple bootstrap. The community-contributed command
Another possibility to determine the strength of CD is to test for (semi)weak CD (Pesaran 2015). Thus, the so-called CD test indirectly tests for α < 0.5. The test statistic is the sum across all pairwise correlations and under the null asymptotically standard normal distributed. For a further theoretical discussion of the CD test, see Pesaran (2015). The CD test is implemented in Stata by the community-contributed command
2.2 Common correlated effects estimator
Given the model in (1), leaving the factor structure unaccounted for leads to an omittedvariable bias, and ordinary least squares becomes inconsistent (Everaert and De Groote 2016). Pesaran (2006) and Chudik and Pesaran (2015b) propose an estimator to estimate (1) consistently by approximating

where
3 Estimating long-run relationships
Dynamic models allow the estimation of long-run relationships. They measure the effect of an explanatory variable on the steady state value of the dependent variable. Following the notation from (1) and assuming that the model is in its steady state with

The long-run effect in (3) can be estimated by an ARDL, distributed lag (DL), and ECM approach. All three can be augmented by cross-sectional averages to approximate CD.
3.1 CS-ECM
The cross-sectionally augmented error-correction approach (CS-ECM) follows on the lines of Lee, Pesaran, and Smith (1997) and Pesaran, Shin, and Smith (1999). Equation (2) is transformed into an ECM: 4

Δ is the first-difference operator, θi is defined as in (3),

is the error-correction speed of the adjustment parameter, and (yi,t− 1 − θ 1,i xi,t ) is the error-correction term. A long-run relationship exists if ϕi ≠ 0 (Pesaran, Shin, and Smith 1999). β 0,i captures the immediate or short-run effect of xi,t on yi,t . The long-run or equilibrium effect is captured by θi . The long-run effect measures how the equilibrium changes, and ϕi represents how fast the adjustment occurs.
In the case without CD and homogeneous long-run coefficients (θi = θ ∀ i), the model can be fit by the PMG estimator (Pesaran, Shin, and Smith 1999).
3.2 CS-ARDL
An alternative to the CS-ECM is the cross-sectionally augmented ARDL (CS-ARDL) approach (Chudik et al. 2016). First, the short-run coefficients are estimated, and then the long-run coefficients are calculated. The advantage of this approach is that a full set of estimates for the long- and short-run coefficients is obtained. An ARDL model can be rewritten as an ECM, and therefore the long-run estimates from the CS-ECM and CS-ARDL approaches are numerically equivalent.
Equation (1) can be generalized to an ARDL(py, px ) model:

The individual long-run coefficients are calculated as

The coefficients can be directly estimated by the mean-group or pooled estimator. The mean-group variance estimator can be applied (Chudik et al. 2016) if the mean-group estimator is used.
3.3 CS-DL
Under the assumption that λi lies in the unit circle, the general representation of an ARDL(py, px ) model can be written in DL form: 5

Chudik et al. (2016) show that (5) can be directly estimated by the CCE estimator, named the cross-sectionally augmented DL (CS-DL) approach. The regression is augmented with the differences of the explanatory variables (x), their lags, and the crosssectional averages. Following Pesaran (2006), the estimation is consistent even if the errors are serially correlated.
For a general ARDL(py, px ) model with added cross-sectional averages to take out strong CD, the CS-DL estimator is based on the equation
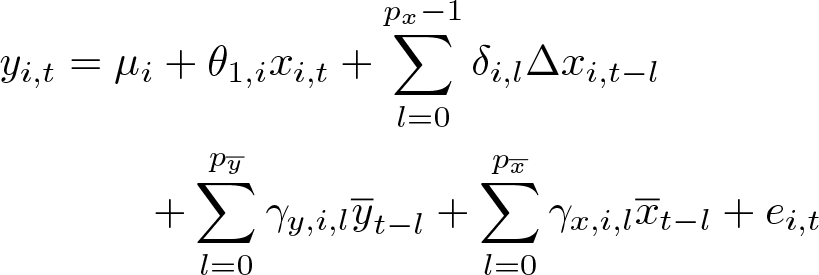
where
4 Updates to the xtdcce2 command
4.1 Syntax
The updated syntax is described below. New and updated options compared with the version explained in Ditzen (2018) are described in section 4.2.
4.2 New and updated options
In the following, the updated or new options are explained. For a full explanation, see Ditzen (2018, 2019) and the help file for
4.2.1 New stored results
The new version stores the following two additional results:

5 The xtcse2 command
5.1 Syntax
5.2 Options
5.3 Stored results

6 Empirical examples
6.1 Estimating and testing for CD
Blackburne and Frank (2007) explain the use of

ci,t is the log of consumption per capita, yi,t is the log of real per capita income, and πi,t is the inflation rate.
Before fitting the model, one must evaluate whether the variables inhibit CD.

The CD test rejects the null of weak CD for all variables, and the estimated exponent of CD is well above 0.5. This is evidence that an estimation method accounting for CD is necessary. All remaining examples are dynamic models. Following Chudik and Pesaran (2015b), the contemporaneous levels of the dependent and independent variables and the floor of T 1/3 lags of the cross-sectional averages will be added to approximate strong CD. After each regression, the residuals are tested for strong CD using the CD test, and the exponent of CD is estimated.
6.2 CS-ECM
The ECM representation of (6) is

Blackburne and Frank (2007) and Ditzen (2018) fit a PMG model without and with contemporaneous cross-sectional averages using
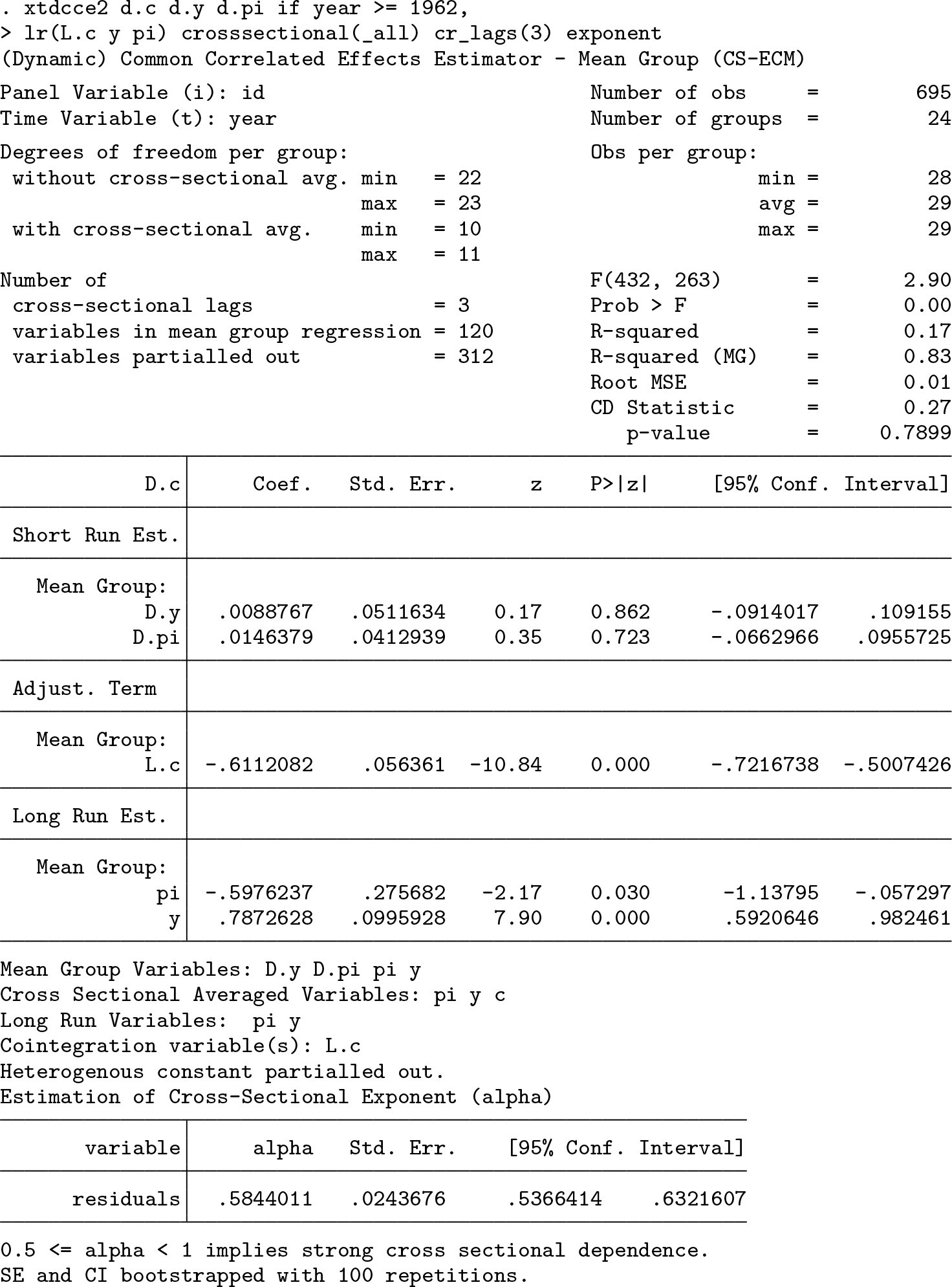
The mean-group estimate of the partial adjustment coefficients is
There are some notable differences between

using ordinary least squares with κ
1,i
= −θ
1,i
ϕi
and κ
2,i
= −θ
2,i
ϕi
. The long-run coefficients and the mean-group coefficients are estimated in three steps, and the variances are calculated using the delta method. First, the cross-section–specific coefficients µi
, ϕi
, κ
1,i
, κ
2,i
, β
1,i
, and β
2,i
are estimated. Then, the cross-section–specific long-run coefficients are calculated. Lastly, the mean-group coefficients are calculated as the unweighed average over the unit-specific long-run coefficients. As an example, the average long-run unit-specific coefficient for
The PMG estimator assumes homogeneous long-run and heterogeneous short-run coefficients.
The option
6.3 CS-ARDL
The ECM in (7) can be transferred into an ARDL(1,1,1) model:
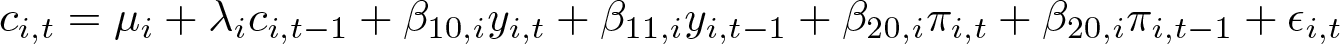
Using
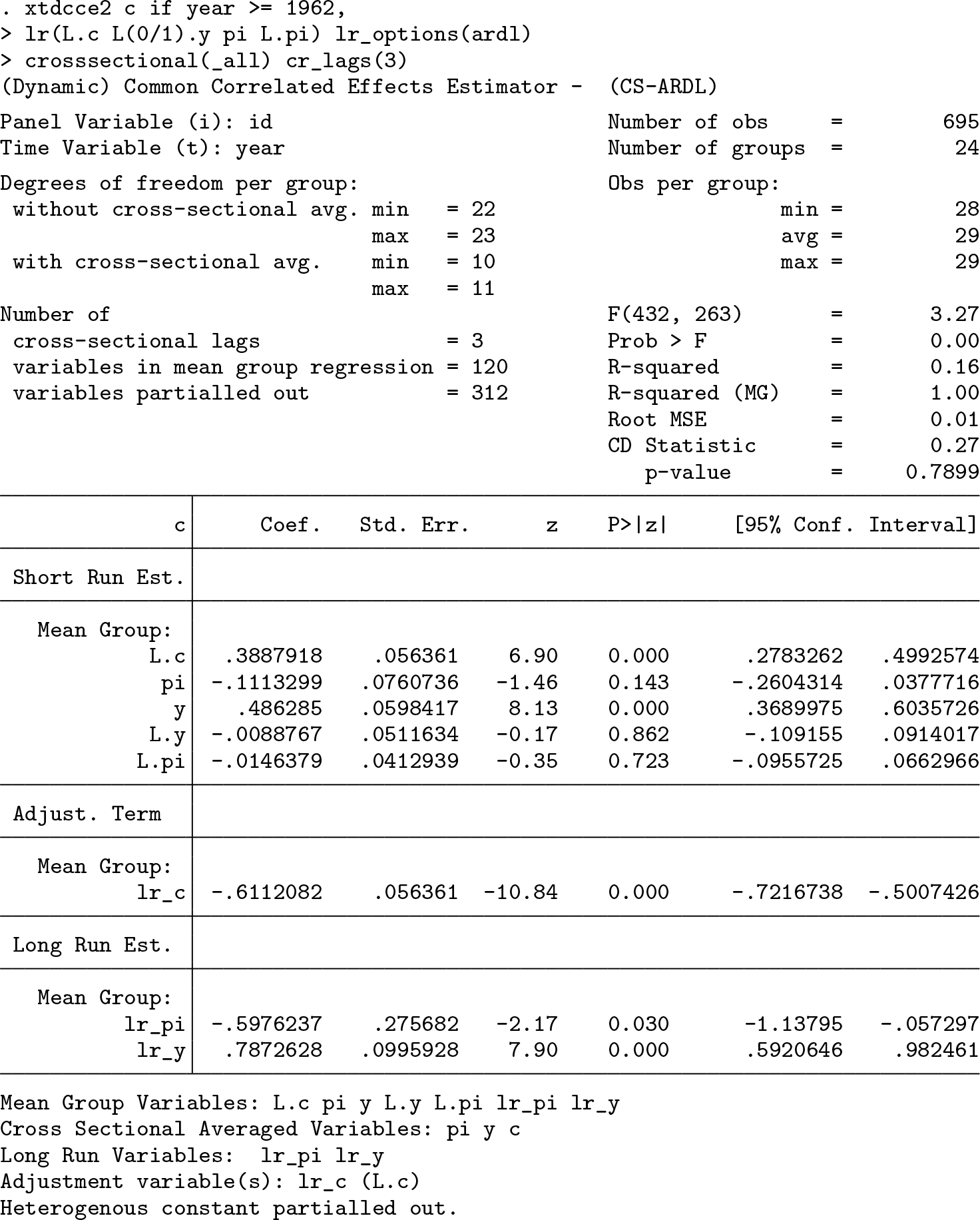
As expected, the regression results are the same as above for the CS-ECM model. In the output, the long-run coefficient estimates have the prefix
For the remaining examples, the results in Chudik et al. (2013) will be replicated. The authors estimate the long-run effect of public debt on output growth with the following equation:

yi,t
is the logarithm of real GDP, and Δyi,t
is its growth rate.
The degree of CD is checked with

All variables are strongly CD with
Next we can turn to fit the ARDL model. As before, three lags of the cross-sectional averages are added to take out any strong CD. To replicate the results of the ARDL(1,1,1) model from Chudik et al. (2013, table 17), we add the first lag of the dependent and the base and the first lag of the dependent variables:

The long-run coefficients for the logarithm of debt to GDP ratio and inflation are both significant and negative. A decrease in the debt burden and inflation will increase GDP growth. A 1% decrease of the debt to GDP growth is associated with an increase of the GDP growth rate of 0.16%. A 1% decrease in the inflation rate leads to an increase of the GDP growth rate of 0.087%. The partial adjustment to the long-run equilibrium appears to be very quick; 95% of the gap is closed within one year.
For the ARDL(3,3,3), the three lags of the explanatory variables and the dependent variable are added. To improve readability, we enclose the different bases in parentheses:

6.4 CS-DL
Besides the ARDL model, Chudik et al. (2013) fit a CS-DL model. Equation (8) in CS-DL form is

The results from Chudik et al. (2013, table 18) with 1 lag (p = 1) in the form of an ARDL(1,1,1) model can be replicated as follows:
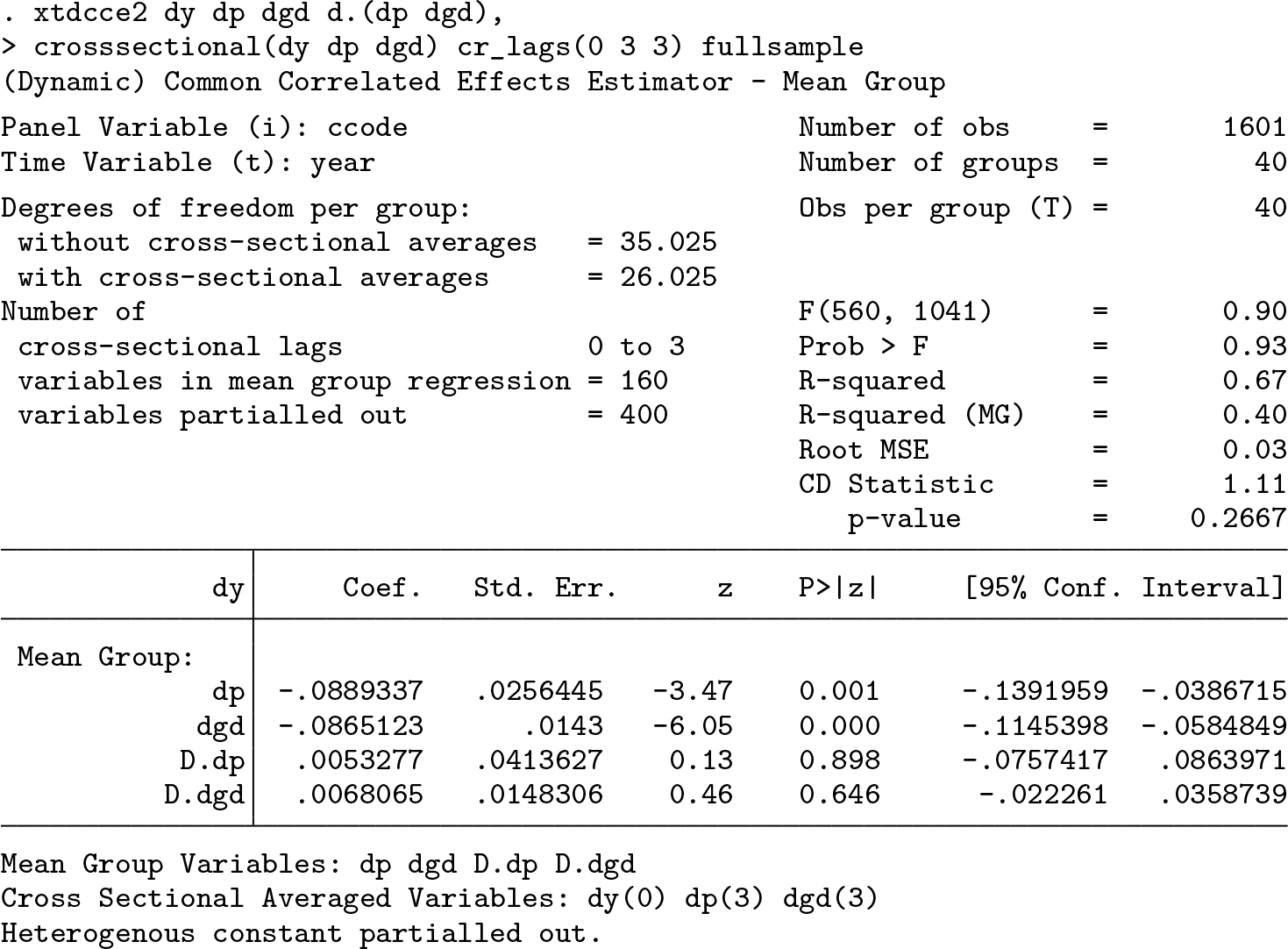
The first differences as part of the vector Δ
An ARDL(3,3,3) model is fit using three rather than one lag for the differences, and

The first two variables (
7 Conclusion
In this article, I explained how to test for CD and estimate the exponent of CD using the community-contributed command
Supplemental Material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211045560 - Estimating long-run effects and the exponent of cross-sectional dependence: An update to xtdcce2
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211045560 for Estimating long-run effects and the exponent of cross-sectional dependence: An update to xtdcce2 by Jan Ditzen in The Stata Journal
Footnotes
8 Acknowledgments
I am grateful to all participants of the Stata User Group Meeting in Zürich in 2018 and in London in 2019, particularly Achim Ahrens and David Drukker, for valuable comments and feedback. I am grateful for help and comments from an anonymous referee and from Tore Bersvendsen, Sebastian Kripfganz, Kamiar Mohaddes, Mark Schaffer, Gregorio Tullio, and plenty of users of
I acknowledge financial support from Italian Ministry MIUR under the PRIN project Hi-Di NET—Econometric Analysis of High Dimensional Models with Network Structures in Macroeconomics and Finance (grant 2017TA7TYC).
9 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.