
Abstract
Despite constituting a major theoretical breakthrough, the quantile selection model of Arellano and Bonhomme (2017, Econometrica 85: 1–28) based on copulas has not found its way into many empirical applications. We introduce the command
Keywords
1 Introduction
Ever since the contributions by Gronau (1974) and Heckman (1974), economists and researchers from other disciplines have been aware of the possibility that measured relationships may suffer from selection bias. The classic example is the determinants of pay (that is, wages) and the selectivity through participation in employment. If one is interested in measuring how individuals with certain characteristics are paid, one has to deal with the possibility that some of them may actually not take up employment, especially if their potential pay is too low (in comparison with their alternative options). If these individuals differ in terms of unobservables from the general population, omitting them from wage regressions will yield biased estimates of regression coefficients.
Following Heckman (1979), a large literature has studied generalized models of sample selection for regression models, for example, Ahn and Powell (1993); Andrews and Schafgans (1998); Chen and Khan (2003); and Das, Newey, and Vella (2003). This literature initially focused on correcting regressions for the mean outcome (for example, the mean wage). An even more challenging case is to correct entire outcome distributions for selection bias. In an influential contribution, Buchinsky (1998, 2001) proposed a control function approach to correcting quantile regressions for selection bias. However, it was later shown by Huber and Melly (2015) that the proposed correction was based on restrictive assumptions that are unlikely to hold in general (conditional independence and additivity). It was not until the contribution by Arellano and Bonhomme (2017) that the selection problem for entire distributions was solved in some generality. In particular, Arellano and Bonhomme (2017) showed that, in the general case, sample selection corrections may not be additive but nonlinearly “rotate” observed distributional ranks.
Despite representing a theoretical breakthrough, Arellano and Bonhomme’s (2017) method has not yet found its way into many empirical applications (recent exceptions include Maasoumi and Wang [2019] and Bollinger et al. [2019]). The purpose of this article is to provide an implementation of their method that is easy to use by practitioners. We also provide some replications of original analyses in Arellano and Bonhomme (2018, 2017). More generally, Arellano and Bonhomme’s (2017) contribution is part of an active recent literature that addresses the problem of correcting entire distributions for selection with potential applications in many fields (for example, Albrecht, van Vuuren, and Vroman [2009]; Picchio and Mussida [2011]; Fernández-Val, van Vuuren, and Vella [2018]; D’Haultfoeuille et al. [2020]; and Biewen, Fitzenberger, and Seckler [2020]).
The rest of this article is organized as follows. Section 2 describes the Arellano and Bonhomme (2017) selection model and estimation method. Section 3 introduces and describes the command
2 The Arellano and Bonhomme (2017) method
2.1 Model
Although they consider more general versions in theoretical parts of their analysis, the practical version of the Arellano and Bonhomme (2017) quantile regression model with selection correction takes the form



where Y * is the potential outcome, D the selection indicator, and Y the observed outcome (available only for individuals with D = 1). The vectors
Equation (1) is a linear quantile regression model for the potential outcome Y * defining the value of Y * that an individual with rank U would get if he or she was selected (for example, the Uth quantile in a distribution of wage offers for individuals with characteristics
The interest lies in uncovering the coefficients β(U) characterizing the conditional distribution Y *|

where
2.2 Estimation
Based on an independent and identically distributed sample (Yi, Di,
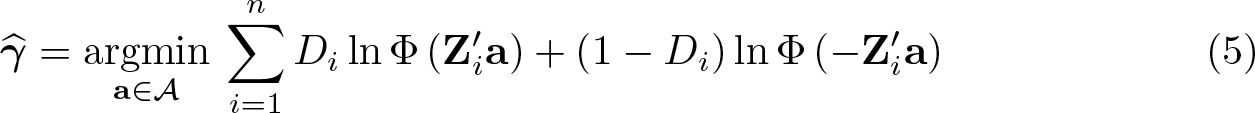

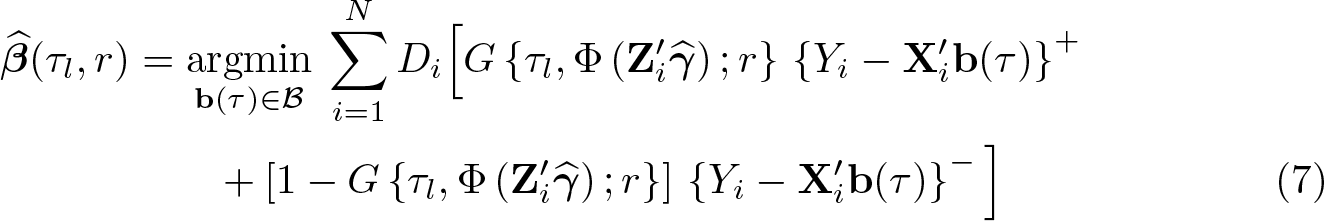

Step 1 estimates the probit parameters of the propensity score. Step 2 is a generalized method of moments estimating equation for the copula parameter ρ, which is identified by the conditional moment condition

[following from (4)]. As an instrumental variable for estimating ρ in (6), one can use a suitable function φ(

Note that, if one is interested only in β(τ
1),…, β(τL
), step 3 is not necessary, because these are already estimated in step 2. However, for computational reasons and for reasons of flexibility, it may be useful to separate steps 2 and 3. For example, one may already have obtained individual specific copula estimates
2.3 Inference
Arellano and Bonhomme (2017) showed that the estimators defined in (6), (7), and (8) are asymptotically normal. However, the resulting form of the asymptotic variance matrix is very complex. This makes the use of resampling techniques attractive. In their empirical application, Arellano and Bonhomme (2017) used subsampling (Politis, Romano, and Wolf 1999). An alternative is the bootstrap (for example, Shao and Tu [1995]). The bootstrap draws independent and identically distributed resamples of size N from the original sample and repeats the estimation for several bootstrap replications. The empirical distribution of the bootstrap replications then serves as an estimate of the asymptotic distribution. Subsampling draws subsamples of size m < N without replacement from the original sample and repeats the estimation on the subsamples to obtain an estimate of the asymptotic distribution (after rescaling by m/N). A related method is the m-out-of-n bootstrap, which also draws subsamples of size m < N from the original sample but with replacement. Subsampling and the m-out-of-n bootstrap require that N → ∞ and m/N → 0; that is, the subsamples are required to be small in relation to the sample size N. 1
Subsampling and the m-out-of-n bootstrap work under more general conditions than the bootstrap. In particular, they do not require that the asymptotic distribution be normal. It suffices that a suitably normalized version of the estimator has a limit distribution (Politis, Romano, and Wolf 1999). The bootstrap is guaranteed to work if the limit distribution is normal (Shao and Tu 1995). In the given case, both methods will work because the limit distribution is known to be normal. Subsampling and the m-out-of-n bootstrap are attractive for computational reasons if the sample size is very large because estimations have to be repeated on smaller portions of the data only. However, subsampling and the m-out-of-n bootstrap have to deal with the difficult issue of determining the subsample size (for example, Politis, Romano, and Wolf [1999]; Chernozhukov and Fernández-Val [2005]; Bickel and Sakov [2008]). Based on Chernozhukov and Fernández-Val (2005), Arellano and Bonhomme (2017) used a subsample size of a constant plus the square root of the sample size, where the constant is chosen such that the subsamples are large enough to ensure a reasonable finite sample performance of the estimator (Arellano and Bonhomme 2017, footnote 19).
Our version of Arellano and Bonhomme’s (2017) estimator implements the m-outof-n bootstrap as well as the conventional bootstrap.
2.4 Algorithms
It is well known that quantile regression problems such as (9) can be solved using linear programming techniques. However, the rotated versions (7) and (8) cannot be handled with standard implementations of quantile regression such as
Our implementation allows sampling weights (as used in the empirical application of Arellano and Bonhomme [2018], which we replicate in section 4.2). If sampling weights are specified, we premultiply observations Yi,
2.5 Copula functions
Our implementation allows the user to choose among four copula functions, as shown in table 1 (for an overview of copula functions and their properties, see Joe [2015]). An important feature of all of these copulas is that they contain as limit cases the extreme forms of positive (or negative) dependence described by the comonotonicity (countermonotonicity) copula. Not restricting the strength of dependence between U and V (and therefore the strength of selection) appears to be important to avoid imposing restrictions that are not compatible with the data. Out of the four copulas listed in table 1, the Frank, Gaussian, and Plackett copulas can represent only symmetrical patterns, while the Joe and Ma (2000) copula can also accommodate asymmetrical patterns (Joe 2015).
Copula functions C(u, v; ρ)

SOURCE: Joe (2015). F Γ(·, a) is the cumulative Gamma distribution with shape parameter a.
Because the value of the copula parameter ρ typically has no direct interpretation, our estimation command reports standard measures of bivariate concordance as listed in table 2. These represent generalized measures of correlation between U and V, which are a function of the copula and the copula parameter (Joe 2015). The concordance measures describe the association between the rank in the latent outcome distribution U and that in the distribution of resistance toward selection V . For example, if high values of U are associated with low values of V, then individuals who get selected tend to have higher outcomes than those who do not (positive selection). Note that positive (or negative) selection will be represented by negative (or positive) concordance measures because of the definition of V as the resistance toward selection.
Bivariate concordance measures

SOURCE: Joe (2015).
The interpretation of the different concordance measures is as follows. Spearman’s rank correlation measures the (ordinary) correlation between the ranks U and V . Kendall’s tau is positive if it is more likely that ranks go into the same rather than into opposite directions, and it is negative otherwise. Blomqvist’s beta is positive if it is more likely that both ranks U and V lie on the same side of the median rank (which is one half) than on opposite sides.
3 The arhomme command
3.1 Syntax
3.2 Options
3.2.1 Selection
If depvars is specified, it should be coded as 0 or 1, with 0 indicating an observation not selected and 1 indicating a selected observation. If depvars is not specified, observations for which depvar is not missing are assumed selected and those for which depvar is missing are assumed not selected.
3.2.2 Grid tuning
3.2.3 Standard errors/subsampling
3.2.4 Instrument/copula parameter
3.2.5 Reporting
4 Empirical examples
4.1 Comparison with Heckman selection model
Our first empirical illustration uses the example in the Stata manual for the command
The result of using

We then use
A first step is

We then use a refined grid:

So far, we have used the option
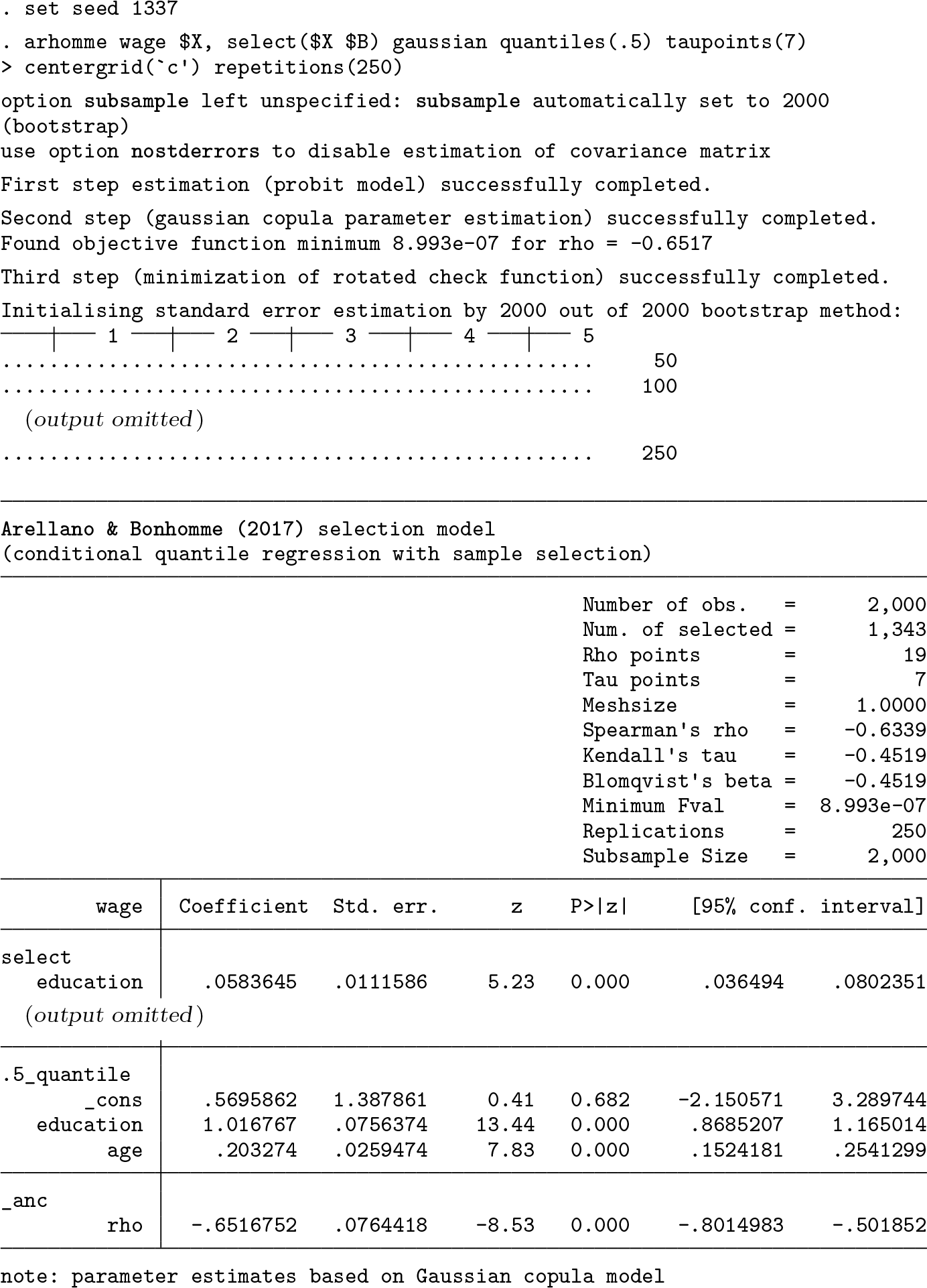
Both
Finally, we illustrate the postestimation features of

4.2 Replication of Arellano and Bonhomme (2018)
This section replicates the empirical example in Arellano and Bonhomme (2018). The data are from Huber and Melly (2015) and can be downloaded from the Journal of Applied Econometrics data archive (http://qed.econ.queensu.ca/jae/2015-v30.7/hubermelly/). The application refers to the returns to education and experience for women in the United States using data from the 2011 Current Population Survey. The sample covers white non-Hispanic women aged between 25 and 54 years. Individuals who are self-employed or work for the military, public, or agricultural sector are excluded. Working is defined as having worked for more than 35 hours in the week preceding the survey. The application uses the Current Population Survey sampling weights.
We first load the data and modify some of the variable names to make them conform to those used in Arellano and Bonhomme (2018):

We now apply

The results for the selection-corrected quantile regression coefficients are almost identical to those reported by Arellano and Bonhomme (2018, table 1). Standard-error estimates are also very similar. The point estimate for the copula parameter and its standard error also come close to those reported by Arellano and Bonhomme (2018) (
4.3 Partial replication of Arellano and Bonhomme (2017)
Our last empirical example replicates selected results in Arellano and Bonhomme (2017).
To replicate a selected quantile regression for the subgroup of single females, we first run some preparatory steps (taken from the file

We then start with a first crude estimation attempt:


Plot of objective function over crude grid
Refine grid:
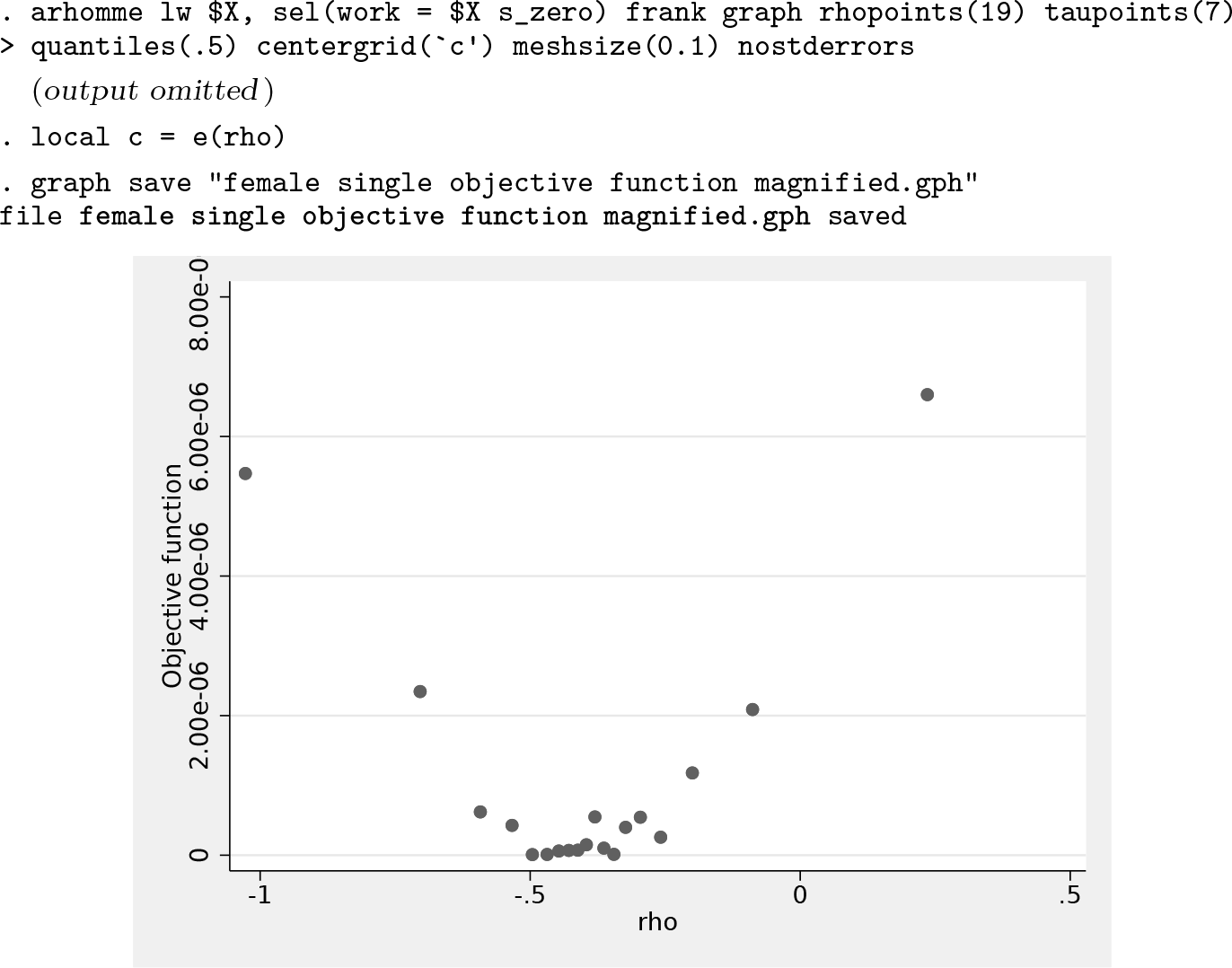
Plot of objective function over refined grid
Finally, we estimate the preferred specification with standard errors based on subsampling (using the same subsample size as in Arellano and Bonhomme [2017]):

Arellano and Bonhomme (2017) do not document their estimated selectivity-corrected regression coefficients (they are used only in their later calculations), but they do report estimated copula parameters for different population subgroups. For the group of single females, they report an estimated Spearman rank correlation of −0.080 (Arellano and Bonhomme 2017, 16) and an estimated parameter for the Frank copula of −0.4820 (documented in replication file
5 Conclusion
In this article, we described a command,
Supplemental Material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211045516 - arhomme: An implementation of the Arellano and Bonhomme (2017) estimator for quantile regression with selection correction
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211045516 for arhomme: An implementation of the Arellano and Bonhomme (2017) estimator for quantile regression with selection correction by Martin Biewen and Pascal Erhardt in The Stata Journal
Footnotes
6 Acknowledgments
We thank Michael Wolf (University of Zürich) for discussions and advice on subsampling. We also thank Ben Jann, Blaise Melly, Philippe Van Kerm, and the participants of the Swiss Stata Conference 2020 for many helpful comments and suggestions. Financial support through the DFG Priority Program 1764 and DFG project BI 767/3-1 is gratefully acknowledged.
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.