
Abstract
In this article, we present a new command,
1 Introduction
The effect of policy variables on distributional outcomes are of fundamental interest in empirical economics and of importance for policymakers. The treatment-effects (TE) literature has been extensively used in economics to analyze how treatments or social programs affect selected outcomes of interest. On the binary TE models, Hahn (1998); Heckman et al. (1998); Hirano, Imbens, and Ridder (2003); Abadie and Imbens (2006); and Li, Racine, and Wooldridge (2009) study efficient estimation of the average TE. The Stata
There is also literature on estimation of multivalued TE, which can be implemented with the package
Galvao and Wang (2015) and Alejo, Galvao, and Montes-Rojas (2018) derive a twostep estimator for practical estimation and inference for quantile TE with continuous treatment. A parameter of interest in the presence of continuous treatment is the entire curve of quantile potential outcomes or quantile dose–response functions (QDRF). The QDRF summarizes the potential responses of each dose of magnitude t ∊ [texmath]T[/texmath] on a specified outcome of interest at the unconditional quantile τ ∊ (0, 1). Another parameter of interest is the quantile continuous treatment effect (QCTE), which corresponds, for any fixed quantile, to the difference between two QDRF at given levels of treatment. Identification of the parameters of interest is based on the ignorability or weak unconfoundedness assumption (see, for example, Rubin [1977], Heckman et al. [1998], or Dehejia and Wahba [1999]), applying the methodology of Galvao and Wang (2015). The estimators are implemented as two-step estimators. In the first step, one estimates a ratio of conditional densities. In the second step, one performs a simple weighted quantile regression estimation where the weights are given by the ratio of conditional density functions. Alejo, Galvao, and Montes-Rojas (2018) propose a flexible Box–Cox density estimation procedure. This approach has important advantages. The first advantage is that the first step of the Box–Cox procedure is simple to implement in practice. The second advantage is that the Box–Cox procedure allows for many covariates and satisfies the required convergence rates for the first step. The Box–Cox procedure is thus flexible to accommodate empirical settings where the ignorability assumption is valid only after conditioning on a rich (possibly large) set of covariates. The numerical simulations show that the Box–Cox procedure is a flexible procedure that correctly estimates QDRF and QCTE functions for alternative data-generating processes.
In this article, we present a new command,
We evaluate the finite-sample performance of the proposed estimator in two ways. First, we implement Monte Carlo simulation exercises. In particular, we evaluate location shift and scale-location shift data-generating processes. Second, to illustrate the methods, we estimate the effects of nonlabor income changes on labor earnings. We use the survey of Massachusetts lottery winners and estimate the effect of the prize amount, as a proxy of exogenous nonlabor income changes, on subsequent labor earnings (from U.S. Social Security records). This database was originally used by Imbens, Rubin, and Sacerdote (2001) and then by Hirano and Imbens (2004). The lottery prize, being unrelated with labor market performance, conditional on a rich set of observables, serves as an income shock that may be used to measure the income effect on labor market decisions. In this example, we have interest in identifying the effect of the lottery prize, which is a continuous variable, on labor earnings, and as such in estimating the QDRF and QCTE curves. That is, rather than studying the effect on a treatment group (that is, with income shock) with respect to a comparable control group, we are interested in the curve linking labor market variables with the size of the shock. We focus on yearly income size years after the prize was received. The quantile process shows important heterogeneity in the marginal effects of the lottery prize. In particular, higher quantiles of future labor market earnings are less responsive to an increment in the lottery prize than lower quantiles. These results are important for analyzing the effect of general income transfers as conditional cash transfer programs in developing countries because the quantile heterogeneity reveals that those that are more likely to opt out of the labor market are the ones in the lower part of the income distribution.
The remainder of the article is organized as follows. In section 2, we review the QCTE estimator of Alejo, Galvao, and Montes-Rojas (2018). In section 3, we describe the
2 Continuous treatment effects
We want to learn how an outcome variable changes as the dose of some treatment variable varies. The dose is denoted by t, where
An important parameter of interest when the treatment is continuous is the QDRF, which is defined as
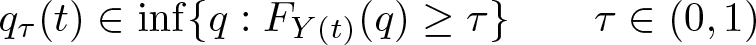
the unconditional τth QDRF, where FY
(t) is the distribution function of Y (t). Thus, the QDRF summarizes the potential responses of each dose of magnitude
From the QDRF, one can learn about another interesting parameter, the QCTE, which is defined as

for t′ < t. The QCTE, as defined in (1), captures the difference of the τth quantile at two given different levels of treatment, t and t′. This QCTE function is the same as defined in Lee (2018) and describes the difference between the two potential responses of Y (t) at doses of magnitude t and t′, at a given unconditional quantile τ. Note that in this article, the QCTE is defined as the difference of the τth quantile at different levels of treatment. This definition does not require the assumption of rank preservation, and it is regarded as a convenient way to summarize interesting aspects of marginal distributions of the potential outcomes. However, if rank preservation holds, then the QCTE defined above has a causal interpretation, that is, the effect of changing the level of the treatment for any particular subpopulation. See Firpo (2007) and Cattaneo (2010) for detailed discussions on rank preservation in quantile TE and definitions of concepts. Of particular interest is analyzing the QCTE for a fixed change in the dose, say, δ > 0, over the doses
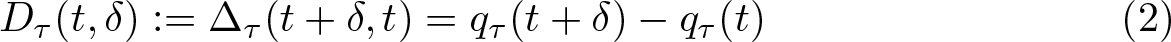
Unfortunately, as is usual in the TE literature, one cannot observe Y (t) for all
Define m{Y (t); qτ
(t)} = τ −

Thus, qτ (t) is defined as the solution to the moment condition given by (3). If this problem has a unique solution, the identification result relies on the following equality,
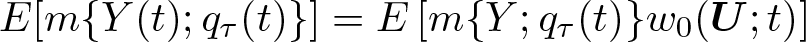
for each
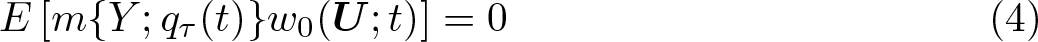
if and only if qτ (t) = qτ 0(t).
This result is a direct application of theorem 1 in Galvao and Wang (2015), who extended the propensity-score method to general dose–response functions in a setting with continuous treatment. The intuition behind the result is that Y (t) being unobserved is replaced with observables (
As in the TE literature, the identification induces an estimating equation with two pieces, the function m(·) with a weighting function w
0(·). In our case, the weights are given by {fT
|
Finally, because the QCTE is the difference between the QDRF at two different treatment doses, identification of QCTE, Δ τ (t, t′), is as straightforward as the previous result.
2.1 Two-step estimator
Using the identification expression (4), Alejo, Galvao, and Montes-Rojas (2018) propose a two-step estimator for both QDRF and QCTE, in (1) and (2), respectively, as in Firpo (2007), Cattaneo (2010), and Galvao and Wang (2015). In the first step, one estimates the weights, that is, the ratio of densities, w(
We have a random sample of units (
First step: Estimation of w 0
To implement the estimator, we need an estimator for w
0. In practice, one estimates fT
|
To estimate the conditional density fT
|
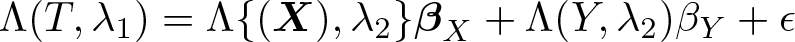
where
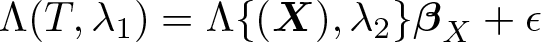
The Box–Cox transformation applies only to variables in a positive domain (excluding zero). Nevertheless, this could be implemented if we define, for a given variable x, x ∗ = ex , where we could thus have negative, zero, and positive values of x, and we allow the Box–Cox parameters to transform x ∗. In this case, if the estimated parameter λ is indeed zero, then the variable would require no transformation. Note that the normality assumption is a simplifying condition. The Monte Carlo simulations in Alejo, Galvao, and Montes-Rojas (2018) show that the Box–Cox Gaussian model performs well for a large family of distributions.
As noted by an anonymous referee, the QDRF and QCTE models rely on the assumption that the true conditional density fT
|
Second step: Estimation of qτ 0 and Δ τ 0
Following (3), the identification condition for qτ
0(t) is
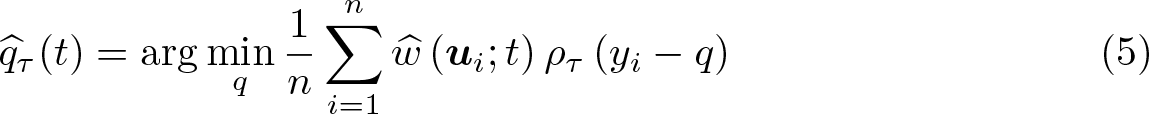
where ρτ
(·) := ·(τ −
Estimation of the QCTE parameter, Δ
τ
0(t, t′), is also easy. Given the QDRF
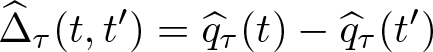
for any
2.2 Inference procedures
Alejo, Galvao, and Montes-Rojas (2018) show uniform consistency and weak convergence of this two-step estimator. In this section, we turn our attention to inference on both the QDRF and QCTE. First, for testing QDRF, we consider the general null hypothesis
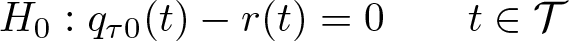
uniformly, where r(t) is assumed to be known, continuous in t over T, and
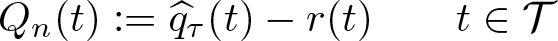
General hypotheses on the vector qτ (t) can be accommodated through functions of Qn (·). We consider the Kolmogorov–Smirnov and Cramér–von Mises test statistics, Tn = f{Qn (·)}, where f(·) represents the functionals for those two test statistics, as
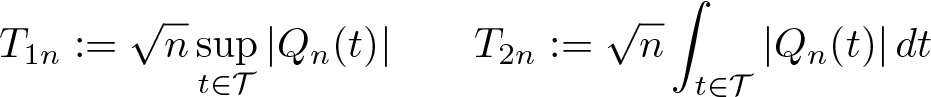
These statistics and their associated limiting theory provide a natural foundation for testing the null hypothesis. It is possible to formulate many tests using variants of the proposed tests. Note that inference for a single point estimation for a fixed level of treatment can be seen as a particular case of uniform inference with r(t) = q
0 and
For uniform inference for QCTE, we consider general null hypothesis
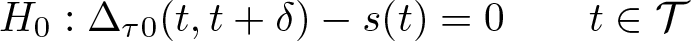
uniformly, where δ is a fixed treatment increment, s(t) is assumed to be known (continuous in t over T), and
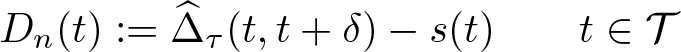
As before, we consider Kolmogorov–Smirnov and Cramér–von Mises test statistics, Tn = f{Dn (·)}, where f(·) represents the functionals for those two test statistics, as
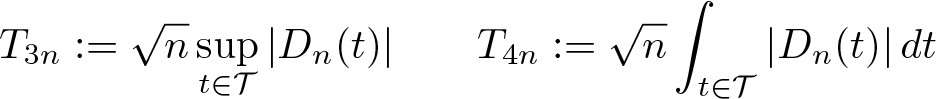
Note that point inference for two different treatment values, say, t and t′, can be stated as a particular case with δ = t′ − t, r(t) = Δ0, and
In practice, the procedure is implemented in a discretized subset, most conveniently on intervals of equal size,
3 The qcte command
3.1 Syntax
The command syntax is
3.2 Options
3.3 Stored results

Matrices
4 Examples
In this section, we present the syntax of the
4.1 Example 1: Simulations
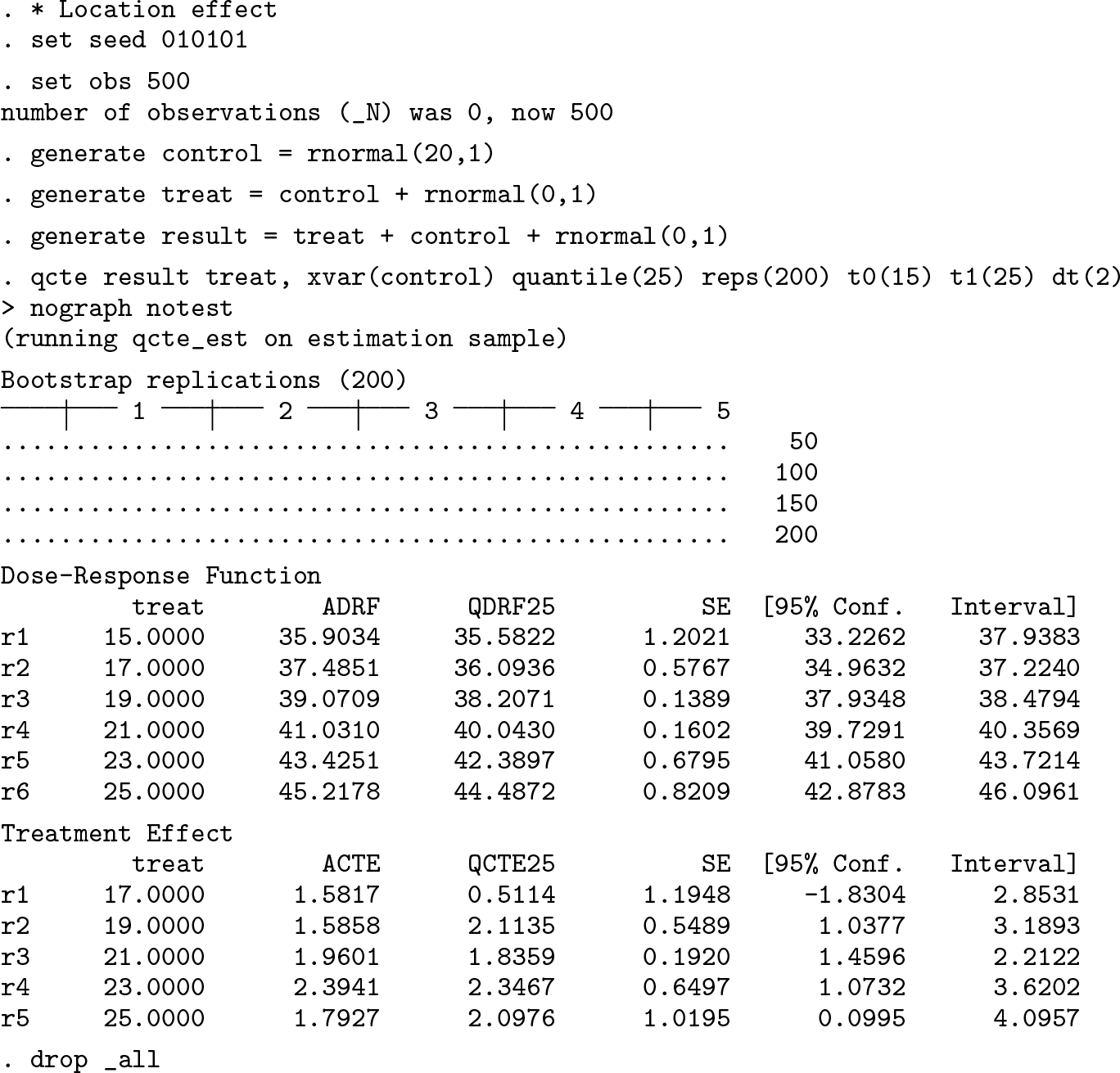
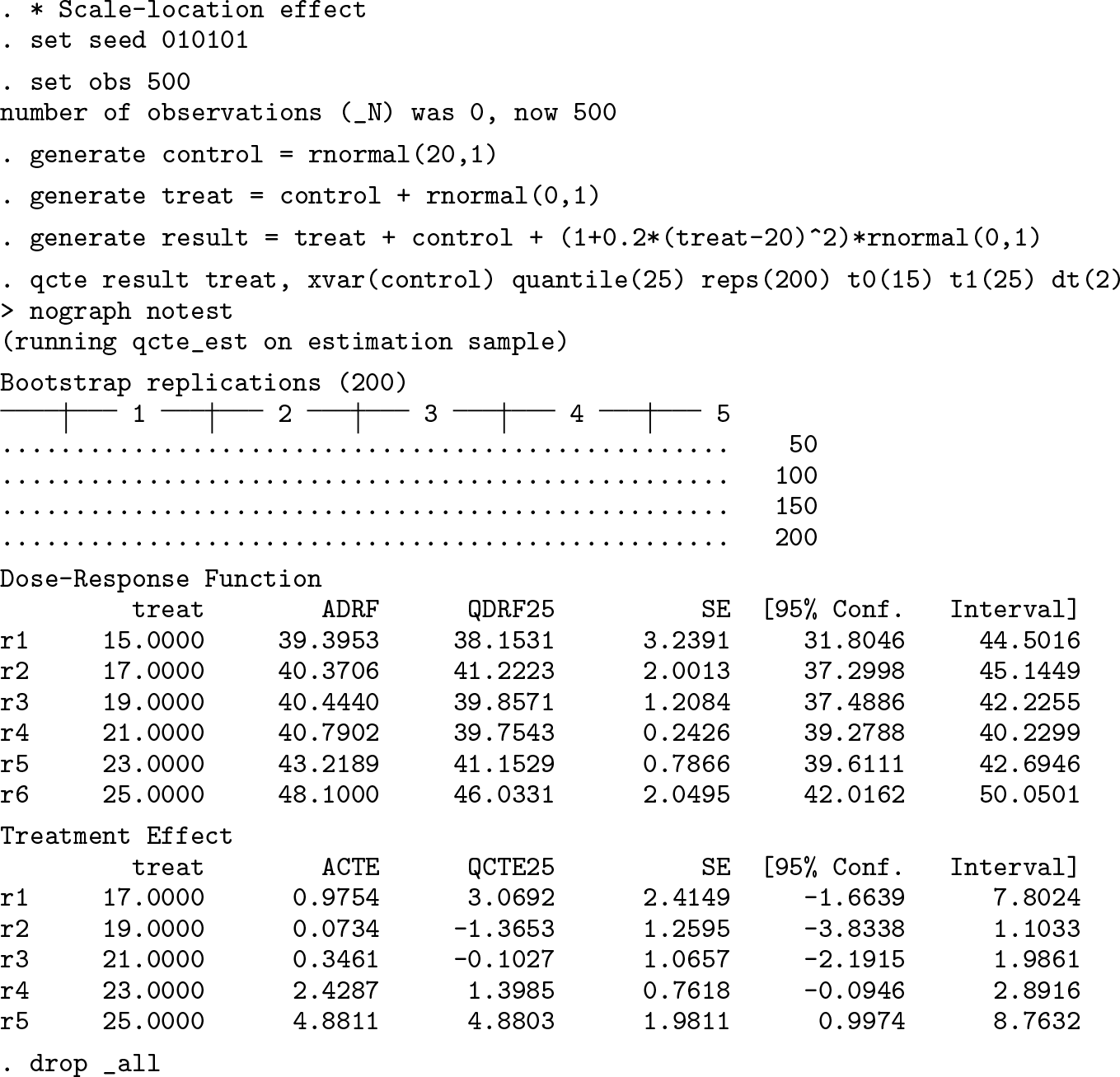
For comparison, we develop some examples in Alejo, Galvao, and Montes-Rojas (2018) by drawing random samples from data-generating processes: X = 20 + v 1, T = X + v 2, and Y = T + X + {1 + α(20 − t)2}v 3 with v 1, v 2, and v 3 independent random variables. The parameter α determines whether the treatment effect is a pure location shift (α = 0) or a scale-location shift α ≠ 0.
First, we evaluate the performance for a location shift treatment effect with standard normal distributions for v 1, v 2, and v 3:
Second, we consider a random sample from a scale-location shift (α = 1/5) of the treatment with standard normal distributions for v 1, v 2, and v 3:
Third, we consider a scale-location shift model (α = 1/5) with a standardized
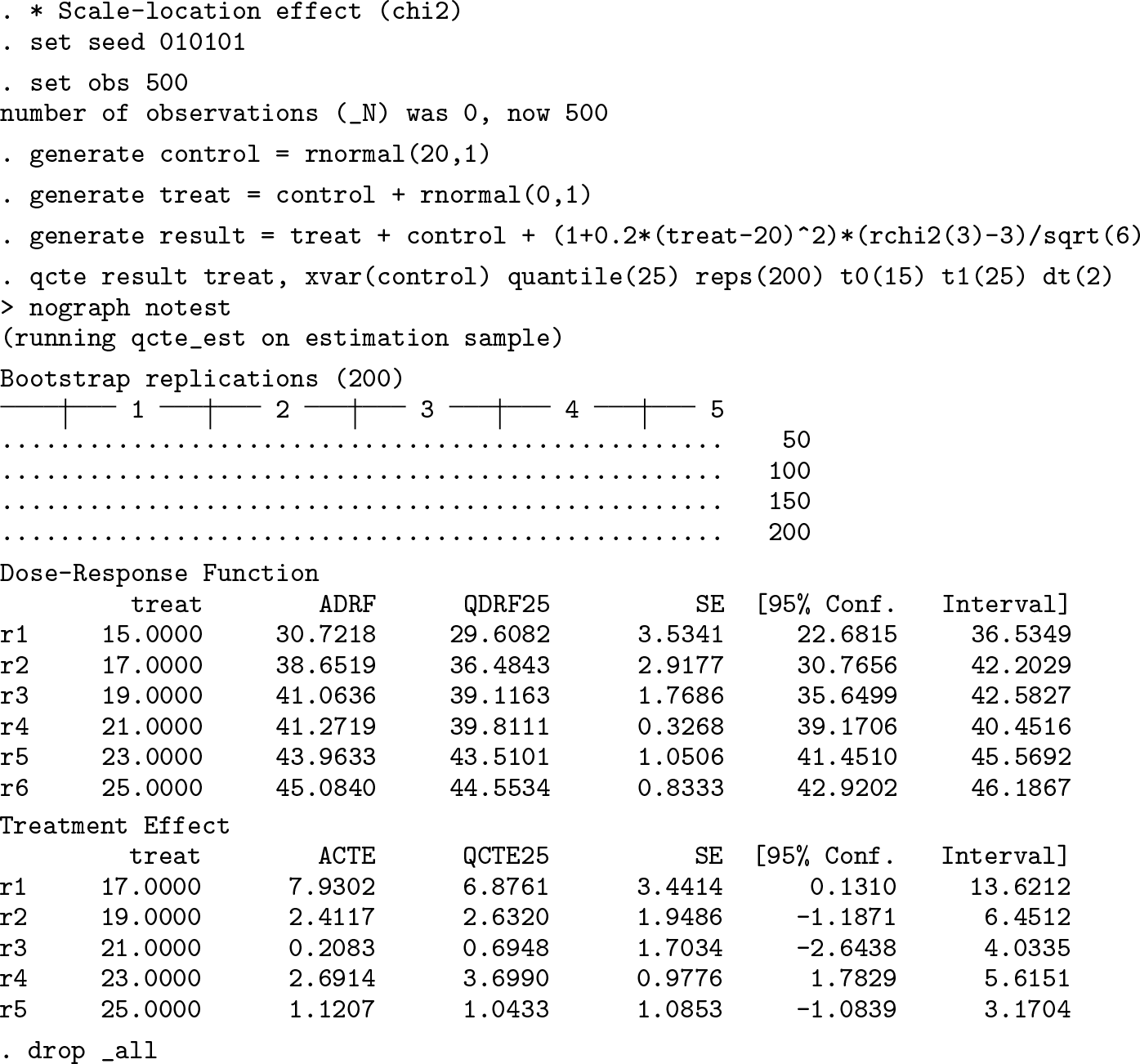
The output shows two tables: the top with the estimates for the dose–response function and the bottom for TE. Each treatment value is shown with its standard errors and the 95% confidence intervals computed via bootstrap. Note that in the three examples, we have set a grid of values for
4.2 Example 2: Real data
We illustrate the
Although the lottery prize is obviously randomly assigned, there is substantial correlation between some of the background variables and the lottery prize in our sample. The main source of potential bias is the unit and item nonresponse. In the survey, unit nonresponse was about 50%. To remove such biases, we make the weak unconfoundedness assumption that, conditional on covariates, the lottery prize is independent of the potential outcomes.
The sample we use in this analysis is the “winners” sample of 237 individuals who won a major prize in the lottery. For each individual, we observe social security earnings for six years before the lottery and six years after. The outcome of interest is
As noted above, the correct estimation of the QDRF and QCTE models requires that the Box–Cox implementation in the first step produce consistent estimators of the conditional densities. After each model, the proposed command stores the Akaike information criterion and Bayesian information criterion values after each Box–Cox estimation. The user can use these goodness-of-fit measures as a guide to select a model specification. Appendix A.3 shows an example of model selection comparing some usual specifications with these goodness-of-fit measures. Below, we use the specification that emerges from that simple algorithm.
A feature of the data to be considered is that about half the sample has Y = 0 (52%, which corresponds to 47% for male and 59% for female). That is, about half the sample is not working and receives no income six years after winning the lottery. We follow Hirano and Imbens’s (2004) and Bia and Mattei’s (2008) approach, who consider that a zero value corresponds to an observed level of income and it requires no truncation analysis. We find that for low quantiles, that is, τ < 0.5, QDRF
τ
(t) = 0,
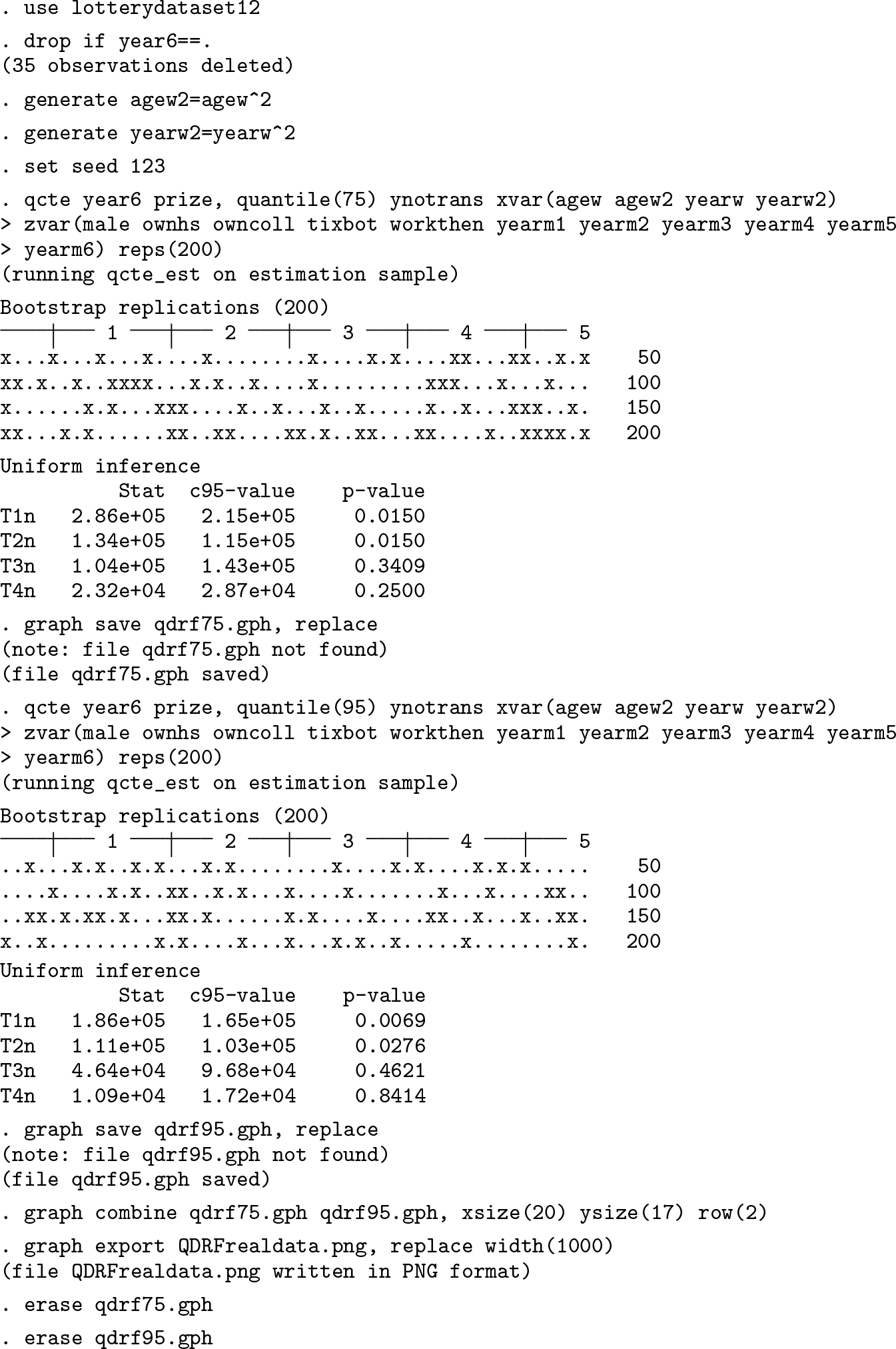
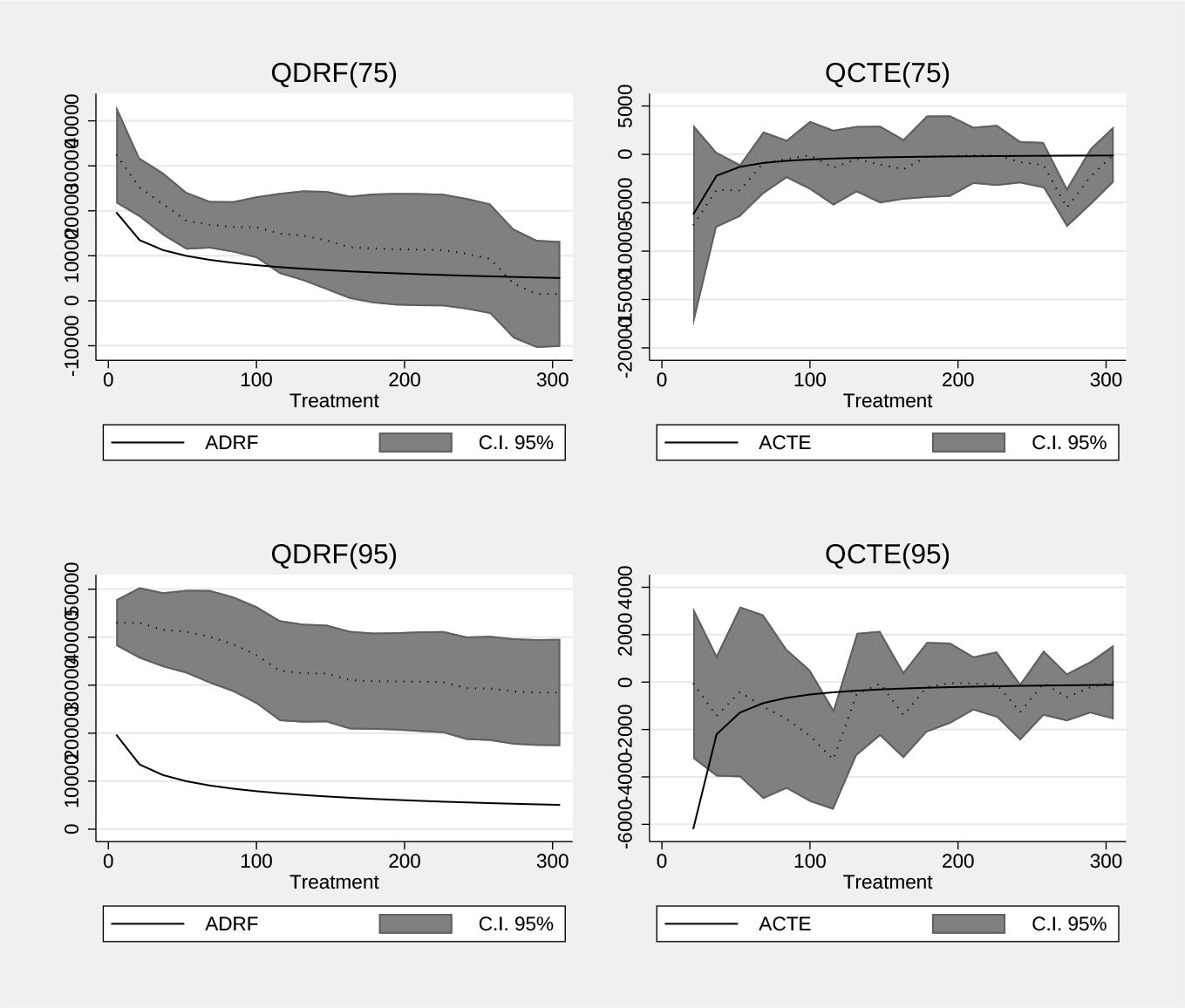
Figure 1 reports the ADRF with the QDRF for selected quantiles. The upper plot on the left corresponds to τ = 0.75 QDRF estimates, and the bottom plot on the left corresponds to τ = 0.95. The graph shows that Y (t) is a decreasing function of t, and the quantile analysis has the same shape as the average effects. As in Imbens, Rubin, and Sacerdote (2001), the effects show a convex relationship suggesting a marginally decreasing effect of the lottery prize on labor earnings.
Empirical application: The Imbens–Rubin–Sacerdote lottery sample
Now consider inference on the point estimates and uniformly over the range of treatment values. The QDRF graph for τ = 0.75 shows that the estimates are different from 0 up to a treatment value of approximately 150 (that is, for those values of t, 0 is not included in the constructed confidence interval). The QDRF for τ = 0.95 and its 95% confidence interval are always above 0 for the entire treatment range. When we look at the uniform inference (
Finally, we compare the ADRF and ACTE estimated by our
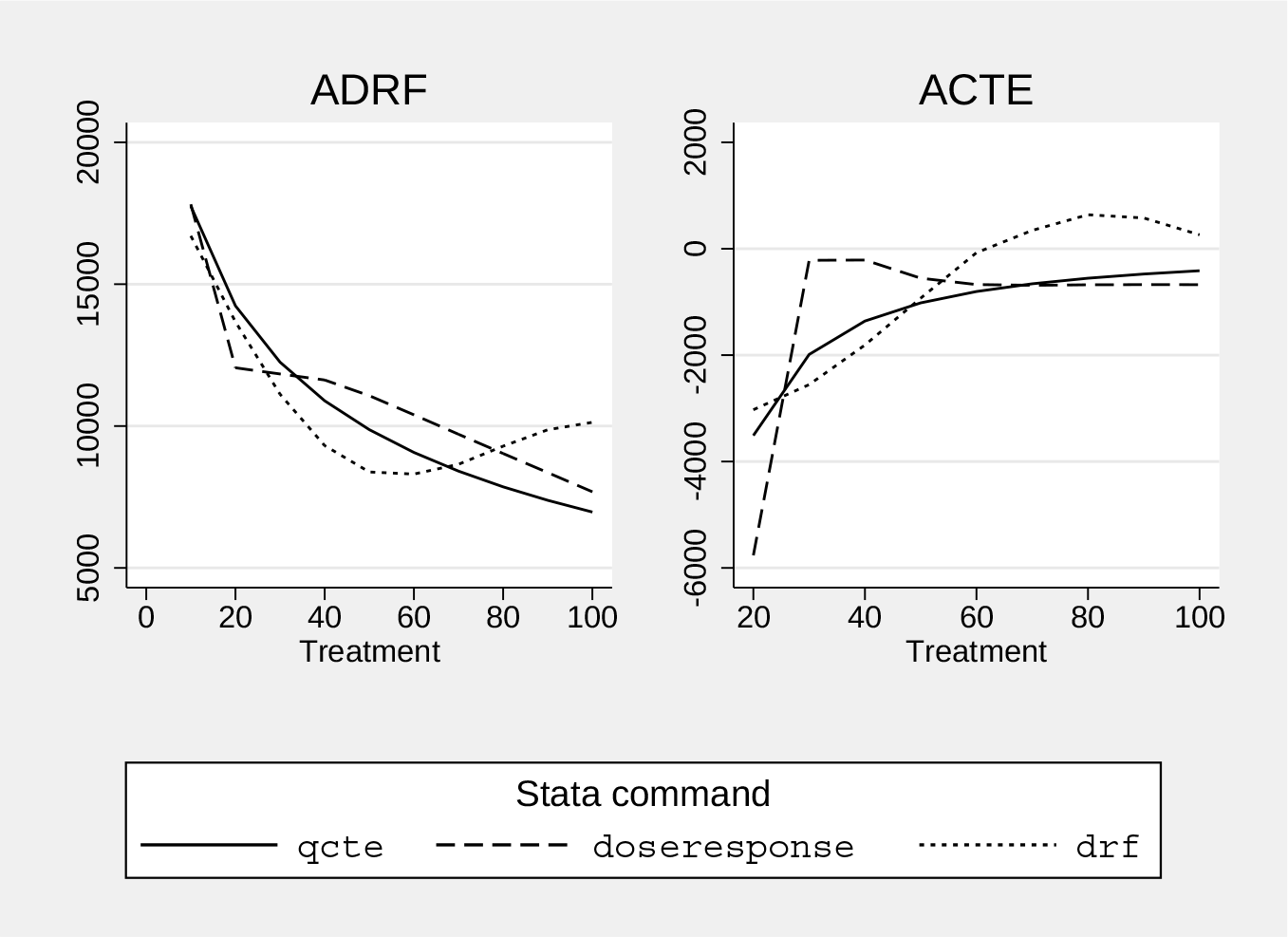
Command comparison: Average values
5 Conclusion
In this article, we presented a new command,
Our estimates replicated the results of Alejo, Galvao, and Montes-Rojas (2018) and showed that this convexity is homogeneous in the rest of the labor earnings distribution and then showed that the threshold value was monotonic in the quantiles. The application illustrated that this method is an important tool to study continuous TE. The quantile analysis also revealed that larger prizes produce lower labor earnings, but a larger prize is required for individuals in the upper part of the distribution of unobservables. The command also provided a graphical alternative to explore heterogeneity of a continuous treatment variable.
6 Programs and supplemental materials
Supplemental Material, st0597 - A practical generalized propensity-score estimator for quantile continuous treatment effects
Supplemental Material, st0597 for A practical generalized propensity-score estimator for quantile continuous treatment effects by Javier Alejo, Antonio F. Galvao and Gabriel Montes-Rojas in The Stata Journal
Footnotes
6 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
A Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.