
Abstract
Recognizing a dose–response pattern based on heterogeneous tables of contrasts is hard. Specification of a statistical model that can consider the possible dose–response data-generating mechanism, including its variation across studies, is crucial for statistical inference. The aim of this article is to increase the understanding of mixed-effects dose–response models suitable for tables of correlated estimates. One can use the command
Keywords
1 Introduction
Investigating dose–response relationships underlying tables of empirical findings has become extremely popular in several research disciplines such as oncology, cardiology, endocrinology, nutrition, and public environmental health. The number of published dose–response meta-analyses increased exponentially over the last 15 years. Scatterplots of collected data are frequently used to inform the specification of the dose–response model. It is unlikely, however, that naked eyes can recognize a clear dose–response pattern. The meta-analyst has to face a limited number of estimates within each study, positive covariance of these estimates, diverse modeling choices of the quantitative dose, and sampling errors that may vary considerably across studies. Also, innumerable assumptions arise from the research environment of each study. In most applications, it is unreasonable to expect that a single dose–response mechanism operates equally in all the studies.
To be concrete, I present an example of data available to the meta-analyst in table 1. Distinct features of these types of data are that estimated contrasts within each study are relative to a common referent; the common referent may change across studies; estimated variances (standard errors) of the contrasts are available from the confidence intervals (CIs), but their covariances are missing; the single value of the dose corresponding to each estimated contrast is the typical dose observed in the sample (that is, the sample mean and median); the reference value of the dose can be far away from zero; and some descriptive statistics are usually available for each dose (that is, the sample standard deviation of the outcome, sample size, and number of cases).
Example of summarized dose–response data (mean dose within each quantile, estimated mean outcome difference and its standard error, sample standard deviation, and sample size) arising from five experimental studies

Traditionally, these types of data are analyzed using a two-stage approach (Orsini and Spiegelman 2020). A dose–response model is first fit within each study using generalized least squares (GLS) (Berrington and Cox 2003; Orsini, Bellocco, and Greenland 2006), and then estimates are combined across studies using multivariate random-effects meta-analysis (White 2009; Jackson, Riley, and White 2011). A one-stage approach for dose–response meta-analysis has been proposed to avoid exclusions of studies that do not provide enough data points to estimate the hypothesized functional relationship (Crippa et al. 2019).
Although any attempt to find a clear dose–response signal in the noisy estimates may appear worthless, the aim of this article is to increase the understanding of a one-stage approach, essentially a mixed-effects framework for meta-analysis (Sera et al. 2019), to evaluate what dose–response mechanism might be underlying multiple tables of correlated contrasts.
The article is organized as follows: explanation of weighted mixed-effects dose– response models including estimation, hypothesis testing, and predictions (section 2); description of the syntax of the
2 Methods
Depending on the study design and regression model used to analyze individual data, the dependent variable
2.1 Weighted mixed-effects dose–response model
A weighted (linear) mixed-effects dose–response model (Crippa et al. 2019) can be specified as

where
for the ith study. The fixed-effects β define the average or summary dose–response relationship of the population of studies of which I occurred to be observed. A distinct feature of this mixed model is the absence of an intercept in
Suggestions on how to model the dose–response relationship are presented in section 2.2. When modeling the dose with transformations such as fractional polynomials or splines, there will be p transformations of the dose defining the design matrix.
The random-effects
The residual error term ϵi
follows MVN (
The marginal model of (1) can be written as

with
2.2 Possible dose–response functions
The quantitative dose should be modeled according to the possible dose–response datagenerating mechanism and the questions the meta-analyst is willing to ask in light of the available knowledge. For example, questions about the extent to which data are compatible with a threshold effect may be articulated differently: Compared with doses below the value k, what is the change in response for values of the dose above k? What is the rate of change in response below and above the value of k? What is the value of the dose k associated with the lowest response without imposing any specific functional relationship on the data?
The meta-analyst can imagine a variety of dose transformations to capture the main features of the true dose–response mechanism and at the same time answer the specified research questions. Below, we specify a few possible dose–response functions involving only one or two regression coefficients.
Linear function
The question is, What is the constant change in response associated with every one-unit increase of the dose? The weighted mixed-effects model using a linear function (Ml ) can be written as follows:

Piecewise constant function
The question is, What is the sudden change in response after the knot k? A degree-0 spline of the dose xij is defined by the location of the knot k. The weighted mixed-effects model using a constant spline function (Mc ) can be written as
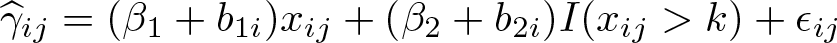
where the regression coefficient of the degree-0 spline β 2 is the vertical shift in response after the knot k.
Piecewise cubic spline function
The question is, What is the smooth change in response along the range of the observed dose without imposing any specific shape? Linearity constraints are usually placed before the first knot and above the last knot to reduce the number of regression coefficients and increase stability at the tails of the dose distribution (Harrell 2001, Orsini and Greenland 2011).
The weighted mixed-effects model using a restricted cubic spline function (Ms ) can be written as
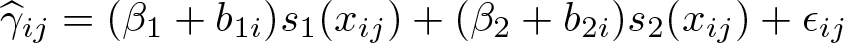
with three knots (k 1 , k 2 , k 3) typically located at fixed percentiles of the dose distribution. The two splines are
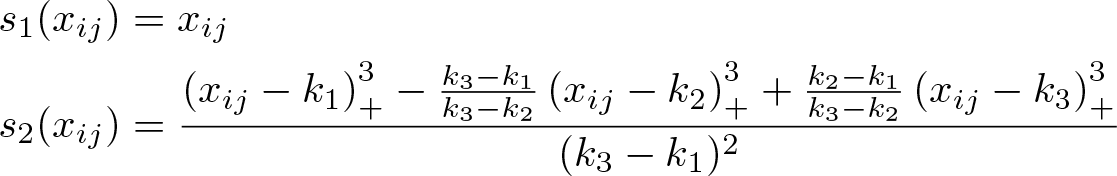
A visualization of the fitted model is necessary to interpret the dose–response relationship.
Piecewise linear function
The question is, What is the constant change in response associated with every one-unit increase in the dose before and after the knot k? The weighted mixed-effects model using a linear spline function (Mp ) can be written as

where the regression coefficient of the degree-1 spline β 2 is the change in linear trend after the knot k.
2.3 Estimation
We consider estimation methods based on maximum likelihood (ML). The marginal log likelihood of the weighted mixed-effects model (1) to be maximized with respect to the parameters of interest [p fixed effects plus q = p(p + 1)/2 variances–covariances of the random effects] given the I tables of aggregated data is defined as

where
ML estimates of the variance components have been shown to be biased downwards because of estimation of the fixed-effects β. An alternative is provided by restricted maximum-likelihood (REML) estimation that maximizes the likelihood

where
2.4 Hypothesis testing
Hypothesis testing and CIs for linear combinations of regression coefficients and data can be constructed using standard large-sample statistical inference from mixed models. The average dose–response curve is defined by the regression coefficients β. A test of the hypothesis H 0 : β = 0 versus HA : β ≠ 0 can be based on the Wald-type statistic

using the estimated
Depending on the functional form specified, testing part of the regression coefficients may detect specific characteristics of the shape (that is, nonlinearity, shift in level, change in slope). This can be done by testing H
0 : β∗
=
2.5 Prediction
Estimating the average or summary dose–response relationship is an important step, particularly when moving beyond straight lines, to present the results in tabular and in graphical form. Let

with pointwise 100(1 − α)% CIs obtained as follows:

The estimated values of
An advantage of the mixed-effects model is that it allows estimation of study-specific dose–response relationships. The best linear unbiased prediction (BLUP) of

The conditional study-specific dose–response relationships are obtained by adding the fixed effects and BLUPs as follows:

Overlaying the average
3 The commands
3.1 drmeta
Syntax
After
Options
reconstruct the covariances of depvar. At each exposure level, varname1 is the number of subjects (controls plus cases) if depvar is (log) odds ratios; the total person-time if depvar is (log) hazard ratios; or the total number of persons (cases plus noncases) if depvar is (log) risk ratios. The variable varname2 contains the number of cases at each exposure level. If depvar is mean differences and standardized mean differences total, the variable varname1 indicates the total number of persons, and the variable varname2 contains the standard deviation of the outcome at each exposure level. Any missing values in either of the two variables set the covariances to 0.
Stored results

3.2 drmeta_graph
The
Syntax
Options
twoway_options are most of the options documented in [G]
3.3 drmeta_gof
The
Syntax
Options
twoway_options are most of the options documented in [G] twoway_options, including
options for titles, axes, labels, schemes, and saving the graph to disk. However, the
3.4 predict
The postestimation command
Syntax
Options
4 Examples
Weighted mixed-effects models are illustrated using three examples based on tables of mean differences, odds ratios, and hazard ratios estimated from nonlinear and random-effects data-generating mechanisms. Tables are generated using a Monte Carlo simulation. Knowing the values of the parameters that govern the central tendency and spread of the dose–response relationships across studies helps to evaluate the results obtained in any given sample of studies.
4.1 Tables of mean differences
Consider the tables of summarized data from 10 hypothetical studies investigating the association between a quantitative dose and a quantitative outcome. The dose, randomly assigned to each individual, is positive and skewed to the right (χ 2 with 5 degrees of freedom). Each principal investigator has categorized the quantitative dose into quantiles and conducted statistical inference on differences in population mean outcomes across quantiles of the dose using a linear regression model. The 10 studies are sampled from a random-effects nonlinear data-generating mechanism. We simulated a J-shaped [−2(x − 5) + 0.2(x 2 − 52)] dose–response relationship for the average study. Given this shape, the lowest mean outcome is expected to be at the mean dose of x = −(−2)/{2(0.2)} = 5 units. There is no single true dose–response relationship underlying all the studies. Every study provided an estimate of its own true dose–response relationship with a certain sampling error. The inferential objective of the meta-analyst can be to determine the tendency and spread of all of these true dose–response relationships. The empirical estimates and descriptive statistics obtained by the study investigators are useful to the extent they can contribute to the understanding of the features of the distribution of dose–response relationships.
Let’s pretend we do not know the data-generating mechanism described above. The 10 observed studies vary according to sample size, dose categorization, and mean dose of the reference category. A total of 13,500 individuals have been involved in these studies contributing to the estimation of 24 mean outcome differences. Moving away from the bottom category of the dose (about 2 units), some studies estimated a lower mean outcome, some other studies a higher mean outcome, and some studies no substantial change (figure 1). The visual impression is of a large variation in the dose–response association across studies.

Graph of the study-specific estimated mean differences (95% CIs, capped spikes) arising from 10 studies of different sizes. Marker size is inversely related to its variance. The shaded area is the distribution of the dose in the population.
It can be hard for the meta-analyst to imagine what kind of functional relationship might be underlying these tables of empirical estimates if the only knowledge available is the collected data. For simplicity of analysis and interpretation, a common strategy used by meta-analysts is a linear function (Ml ) for the dose.

Every one-unit increase of the dose is estimated to increase, on average, the mean outcome by

The maximized log likelihood of a mixed-effects model using the restricted cubic spline function (ℓs = −49) of the dose is, in absolute terms, about two-fifths of the maximized log likelihood of the linear function (ℓl = −118). Even considering the higher number of estimated parameters of the spline function (two coefficients + three variance–covariance of random effects) relative to the linear function (one coefficient + one variance of random effects), the AIC of the spline function (AIC s = 107) is about half the one of the linear function (AIC l = 240). Assuming the average dose–response function is truly linear, a Wald-type statistic being as or more extreme than observed would rarely occur (H 0 : β 2 = 0, z = 5.24, p-value < 0.001). That said, we still have no idea of the possible shape relating the dose to the mean outcome. Therefore, we next present graphically the estimated summary dose–response relationship using the overall dose of five units as referent (figure 2).

Estimated summary dose–response relationship (solid line) with 95% CIs (short-dashed lines) based on 10 tables of empirical estimates. Data were fit with a weighted mixed-effects model using restricted cubic splines for the dose with three knots located at percentiles (10th, 50th, 90th) of the overall dose distribution. The long-dashed line is the true summary dose–response relationship. The dose value of five units served as a referent.
Based on the spline model, the predicted summary mean outcome difference comparing the generic dose level x∗
versus the reference of five units, compactly indicated with

with x∗
ranging in the plausible range going from 2 to 10 units. The values of the first and second spline at the chosen referent are s
1(5) = 5 and s
2(5) = 0.59. The pointwise uncertainty of

Focusing on the left tail of the dose distribution, we find the mean outcome difference comparing 2 versus 5 units of the dose is given by
The postestimation command

Figure 2 shows how the predicted summary dose–response mechanism based on the spline model is capturing the main features of the mechanism (long-dashed line) underlying the empirical studies, that is, a higher mean outcome at the extremes of the dose distribution and a minimum mean outcome at about five units of the dose. The block-diagonal matrix of weights
4.2 Tables of adjusted odds ratios
Let’s now consider tables of summarized data from 10 hypothetical observational prospective studies investigating the association between the quantitative dose (that is, body mass index [BMI], kg/m2) and the occurrence of a binary outcome (that is, alive/death status during 10 years follow-up time). Baseline age, a potential confounding variable, is associated with a higher mean BMI and is associated with higher mortality odds regardless of the specific values taken by the BMI. Furthermore, the age-adjusted odds ratio relating BMI to mortality is J shaped, that is, e− 2 . 3 ( x − 24 ) +0 . 05 ( x 2 − 24 2 ) (that is, higher mortality at the extremes, particularly on the right tail, of the BMI distribution). Each principal investigator categorized BMI into 2/3 quantiles and conducted statistical inference on age-adjusted mortality odds ratios comparing BMI categories using logistic regression models. The sets of empirical estimates arise from a random-effects data-generating mechanism.
A plot of the study-specific estimates (figure 3), further complicated by the arbitrary reference category, is unlikely to provide clear insights on either the study-specific or the summary dose–response relationship between BMI and mortality odds upon adjustment for age.

Graph of the study-specific estimated age-adjusted mortality odds ratios (95% CIs, capped spikes) according to BMI levels arising from 10 studies of different sizes. The dark-gray symbols indicate the study-specific reference values. Marker size is inversely related to its variance. The shaded area is the distribution of the dose in the population.
We model age-adjusted log odds-ratios as a function of BMI. Using a linear function (Ml ) to model BMI in relation to age-adjusted mortality odds ratios, every increment of 3 kg/m2 in BMI is associated, on average, with a 48%, e 0 . 13 ( 3 ), higher age-adjusted mortality odds.
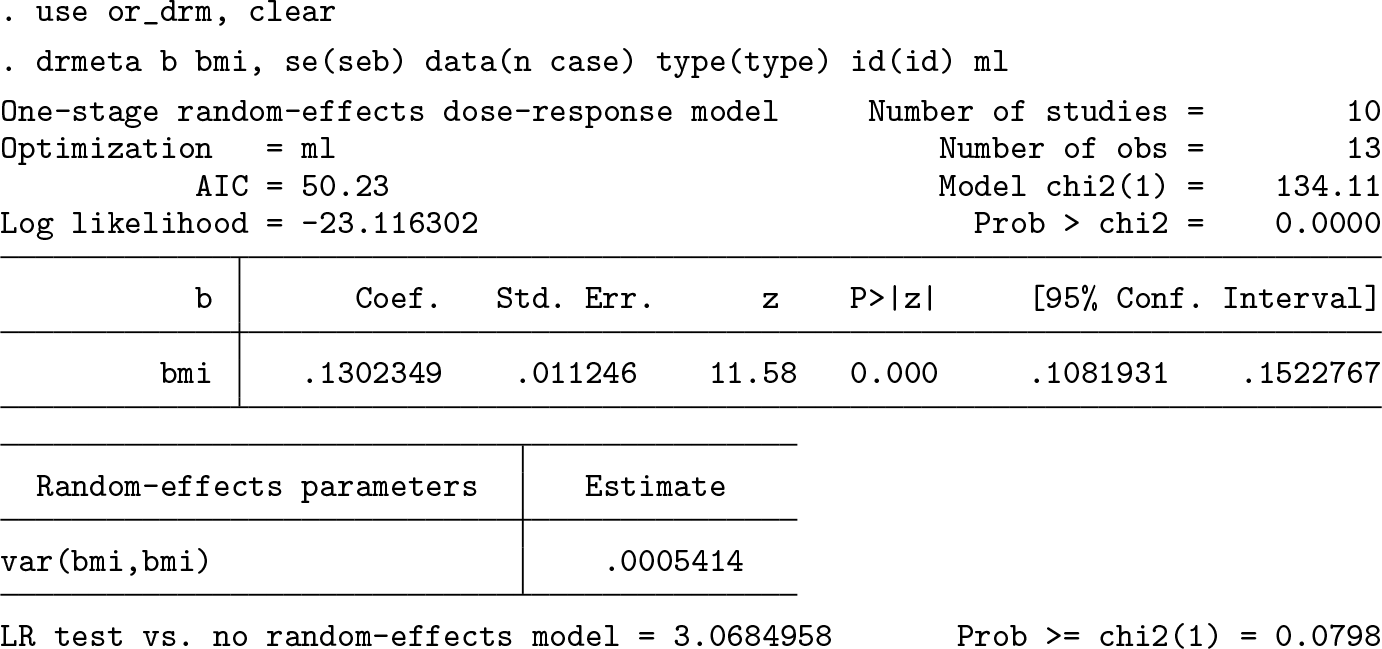
Because a constant change in age-adjusted mortality odds throughout the BMI range can be unrealistic, we next allowed a curvilinear relationship to be detected by using a restricted cubic spline function (Ms ) with three knots at fixed percentiles (10th, 50th, 90th) of the BMI distribution.

The strong reduction in AIC from 50 to -4 and the large value of the Wald-type statistic (H 0 : β 2 = 0, z = 7.71, p-value < 0.001) indicate a departure from a simpler trend. A visualization of the summary dose–response relationship based on the spline function and the true summary dose–response mechanism is presented in figure 4. The predicted dose–response relationship between BMI and age-adjusted mortality odds appear to be J shaped with a minimum at around 23.5–24 kg/m2, which is not far from what the meta-analysts can expect based on the true dose–response mechanism underlying the population of studies.

Estimated summary dose–response relationship (solid line) with 95% CIs (short-dashed lines) based on 10 tables of empirical estimates. Data were fit with a weighted mixed-effects model using restricted cubic splines for BMI with three knots located at percentiles (10th, 50th, 90th) of its distribution. The true summary age-adjusted dose–response mechanism (long-dashed line), e−2.3(x−24)+0.05(x2−242), is shown for comparison. The value of 24 kg/m2 served as the referent.
4.3 Tables of adjusted hazard ratios
Let’s now consider tables of summarized data from 30 hypothetical prospective cohort studies investigating the association between baseline brisk walking, measured in hours/week, and time until death, or end of follow-up (10 years), whichever came first. Age is inversely associated with brisk walking and positively associated with higher mortality rates independently of brisk walking levels. Furthermore, the true summary age-adjusted mortality hazard ratio is decreasing with higher walking levels with a threshold effect at two hours per week; that is e− 0 . 5 ( x − 2 ) +0 . 5 ( x> 2 )( x − 2 ). Principal investigators categorized brisk walking into 2/4 quantiles. Age-adjusted mortality hazard ratios comparing brisk walking categories were estimated using a Cox regression model. Each set of empirical estimates arises from a random-effects data-generating mechanism.
The scatterplot of the estimates shown in figure 5 may suggest an overall inverse association between brisk walking and age-adjusted mortality rates. The threshold effect at two hours per week, however, can be hardly guessed in figure 5. There are not even empirical estimates between 1.5 and 2.4 hours per week, exactly in the range where the leveling off is occurring.

Graph of the study-specific estimated age-adjusted mortality hazard ratios (95% CIs, capped spikes) according to walking levels arising from 30 studies of different sizes. The dark-gray symbols indicate the study-specific reference values. Marker size is inversely related to its variance. The shaded area is the distribution of the dose in the population.
In this example, we directly specify the piecewise linear spline model (Mp
) with a knot at two hours per week to dedicate some attention to useful postestimation commands such as
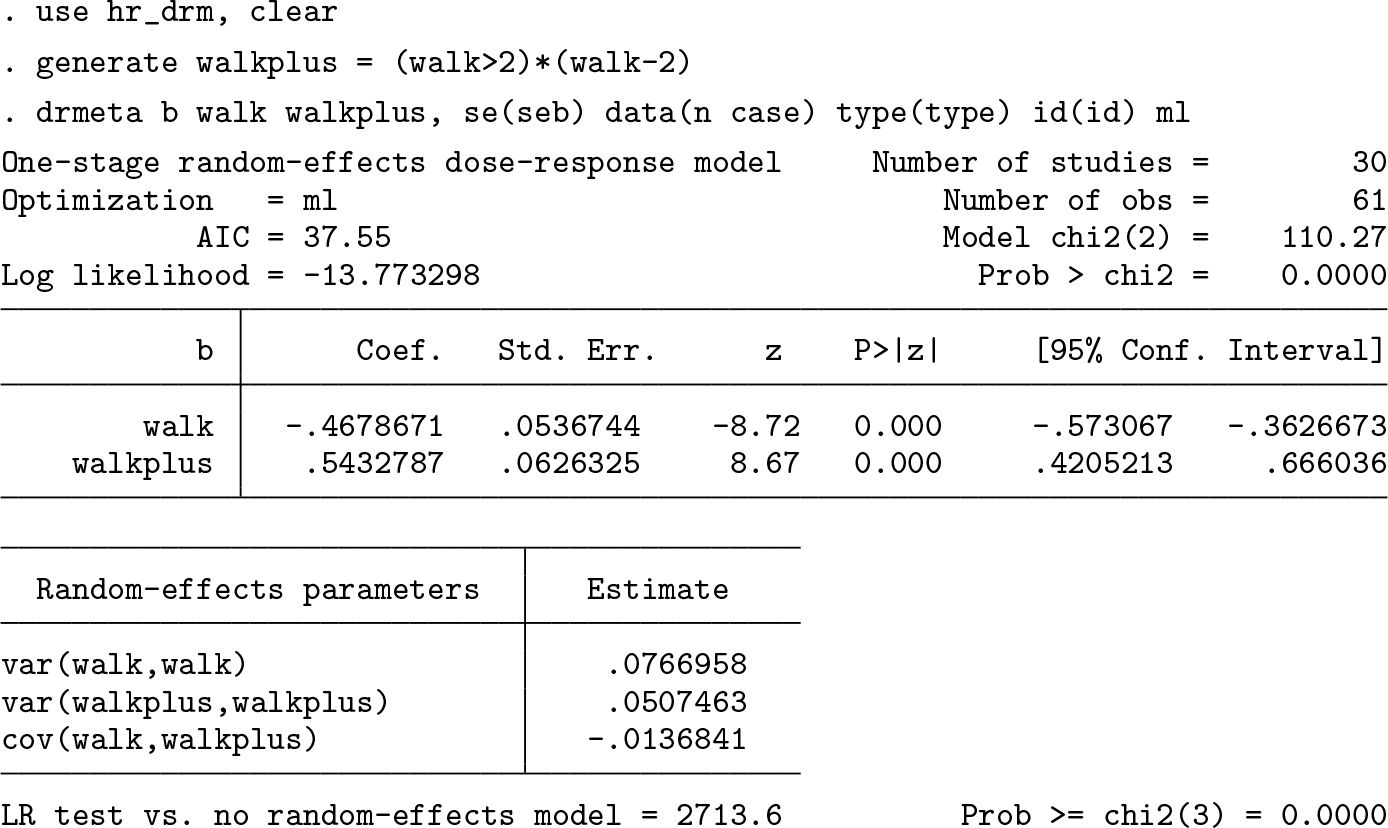
Below 2 hours per week, every increment of 30 minutes per week in brisk walking is estimated to reduce the age-adjusted mortality rate by 21% (HR = e−
0
.
47
(
1
/
2
) = 0.79; 95% CI = e−
0
.
47
(
1
/
2
)±
1
.
96
(
0
.
054
)(
1
/
2
) = [0.75, 0.83]). Above 2 hours per week, every increment of 30 minutes per week in brisk walking is estimated to increase, on average, the age-adjusted mortality rate by 4% [HR = e
(−
0
.
47+0
.
54
)(
1
/
2
) = 1.04]. Statistical inference for a combination of parameters and data, such as e
(β
1+
β
2)(
1
/
2
), can be easily obtained with the

One could be interested in age-adjusted hazard ratios associated with specific levels of brisk walking. For example, those persons who rarely engage in brisk walking (0 hours per week) are expected to have, in an average study, a 2.5-fold increase (95% CI: [2.1, 3.1]) in age-adjusted mortality relative to 2 hours per week.

Various types of predicted values can be obtained after
Overlaying predicted summary and study-specific dose–response relationships can help one to appreciate the central tendency and variation across studies. This is achieved by adding estimated regression coefficients,
For example, study 20, as compared with the average study, is compatible with a stronger (−0.9 > −0.5) inverse linear relationship below 2 hours per week and stronger, because (−0.9 + 0.4) > (−0.5 + 0.5), inverse linear relationship above 2 hours per week.

The 30 study-specific dose–response relationships can be easily plotted using the
Note that the variation of the study-specific dose–response relationships (figure 6) greatly, and correctly, exceeds the uncertainty of the average dose–response response relationship (figure 7). For example, returning to the age-adjusted hazard ratio of 0 versus 2 hours per week (just draw a vertical line at 0), there are two studies compatible with no association (HR ≈ 1) and one study compatible with a very strong positive association (HR = 8). The majority of the studies (28/30 = 0.93) have age-adjusted mortality hazard ratios above 1 when comparing 0 versus 2 hours per week of brisk walking. Considering the variance of the random effects associated with the slope before 2 hours per week, the meta-analyst can expect the middle 95% of the studies to have an age-adjusted mortality hazard ratio comparing 0 versus 2 hours per week between 0.9 and 8;

Estimated summary dose–response relationship (solid line) with 95% CIs (short-dashed lines) based on 30 tables of empirical estimates. Data were fit with a weighted mixed-effects model with piecewise linear splines for brisk walking with one knot located at 2 hours per week. The true summary age-adjusted dose–response mechanism (long-dashed line), e−0.5(x−2)+0.5(x>2)(x−2), is shown for comparison. The value of 2 hours/week served as the referent.
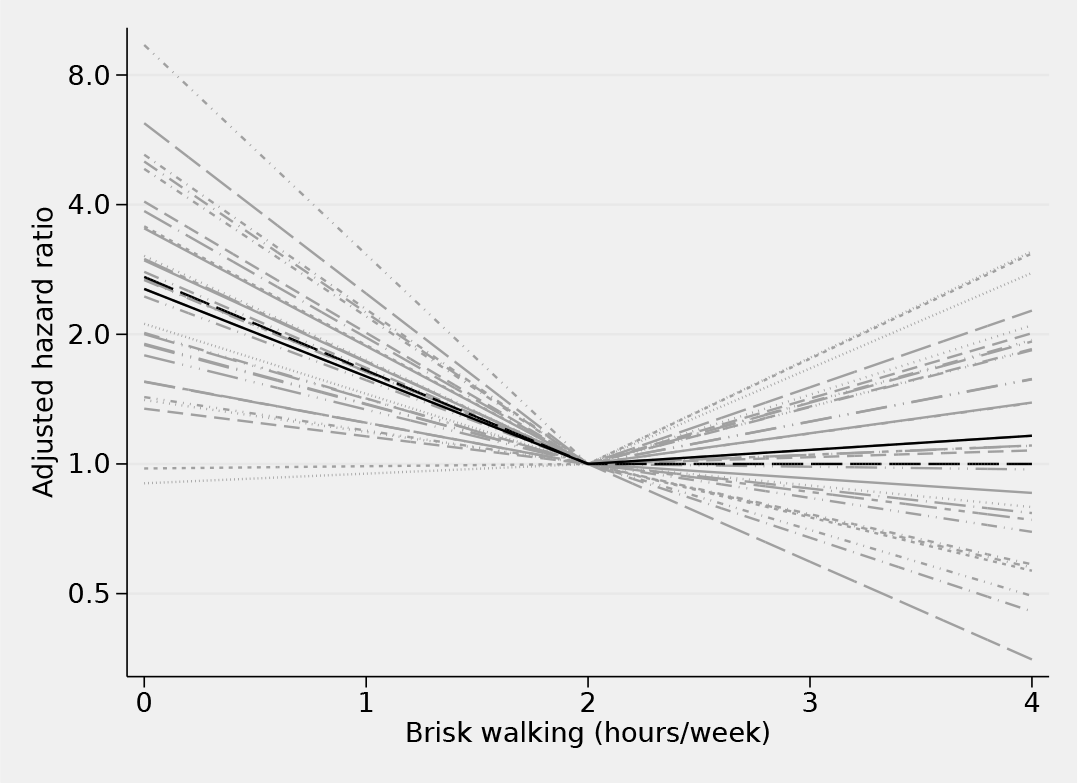
Study-specific dose–response relationships (light gray), summary dose– response relationship (black) based on 30 tables of empirical estimates. Data were fit with a weighted mixed-effects model with piecewise linear splines for brisk walking with one knot located at 2 hours per week. The true summary age-adjusted dose–response mechanism (long-dashed line), e−0.5(x−2)+0.5(x>2)(x−2), is shown for comparison. The value of 2 hours/week served as the referent.
5 Conclusion
In this article, I described the main features of weighted mixed-effects models suitable for statistical inference on dose–response relationships based on tables of empirical estimates. It can be applied to a variety of research fields where additive and multiplicative measures of association for quantitative predictors are consistently summarized in tabular forms. Tables of empirical estimates can arise from either experimental or observational study designs. Different types of dose transformations can be specified according to the research questions the meta-analyst is willing to ask in light of the data. Although the major focus of inference is usually the average dose–response relationship in a population of studies, mixed models allow examination of the spread of the functional relations across studies.
The
Regression splines of a quantitative predictor, such as piecewise constant, linear, and cubic, are flexible tools that can answer a variety of questions. Spline functions are not the only modeling strategy. Applications of the
Although random-effects models are routinely used in quantitative reviews of dose– response data, it is quite rare to see any use of the estimated random effects in applied research. Furthermore, plotting curvilinear relationships is difficult with only few data points available within each study. The
The major challenge for the meta-analyst is to understand that modeling changes in expected responses is not the same as modeling expected responses. Changes in expected responses are themselves the results of a modeling choice by the principal investigator in any given study. The task of using the results of a piecewise constant dose–response function, just another way of calling categorization of the dose, to inform the specification of another dose–response function is unlikely to be straightforward. Although a statistical package can facilitate a variety of calculations and prevent possible mistakes, anyone interested in using the
6 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211025798 - Weighted mixed-effects dose–response models for tables of correlated contrasts
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211025798 for Weighted mixed-effects dose–response models for tables of correlated contrasts by Nicola Orsini in The Stata Journal
Footnotes
6 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.