
Abstract
How can social and health researchers study complex dynamic systems that function in nonlinear and even chaotic ways? Common methods, such as experiments and equation-based models, may be ill-suited to this task. To address the limitations of existing methods and offer nonparametric tools for characterizing and testing causality in nonlinear dynamic systems, we introduce the
Keywords
1 Introduction
How can researchers study complex dynamic systems that may not fulfill the assumptions of classic methods such as experiments or model-based regressions? Causal identification is a difficult task in many contexts, including when studying complex dynamic systems wherein experiments or model-based regressions may not be available or appropriate. Dealing with the complexity of real-world phenomena requires tools that can characterize and test causality in nonlinear dynamic systems.
One promising method is called empirical dynamic modeling (EDM) (for an introduction, see Chang, Ushio, and Hsieh [2017]). This novel approach from the natural sciences allows 1) characterizing a dynamic system, including its complexity, predictability, and nonlinearity, as well as 2) distinguishing causation from mere correlation, while 3) making minimal assumptions about nonlinearity, stability, and equilibrium (see Sugihara and May [1990], Sugihara [1994], Sugihara et al. [2012]).
To complement approaches that are more classic, including experiments or model-based regressions, in what follows we offer an overview of the conceptual logic of EDM and then describe the new Stata command
2 Method
The logic of EDM is based on the fact that a dynamic system producing observed time series or panel data can be modeled by reconstructing the states of the underlying system as it evolves over time (Takens 1981). Consider a system that is characterized by D variables over time, such as a national economy that changes along gross domestic product, unemployment, and inflation, or a person characterized by evolving health and well-being states. Over time, the D variables chart a trajectory of system states as they change, as in figure 1 for D = 3 (showing the Lorenz or “butterfly” attractor and a measure of it as x). As the national economies or individuals evolve, the trajectories of the D variables will trace a D-dimensional “manifold”
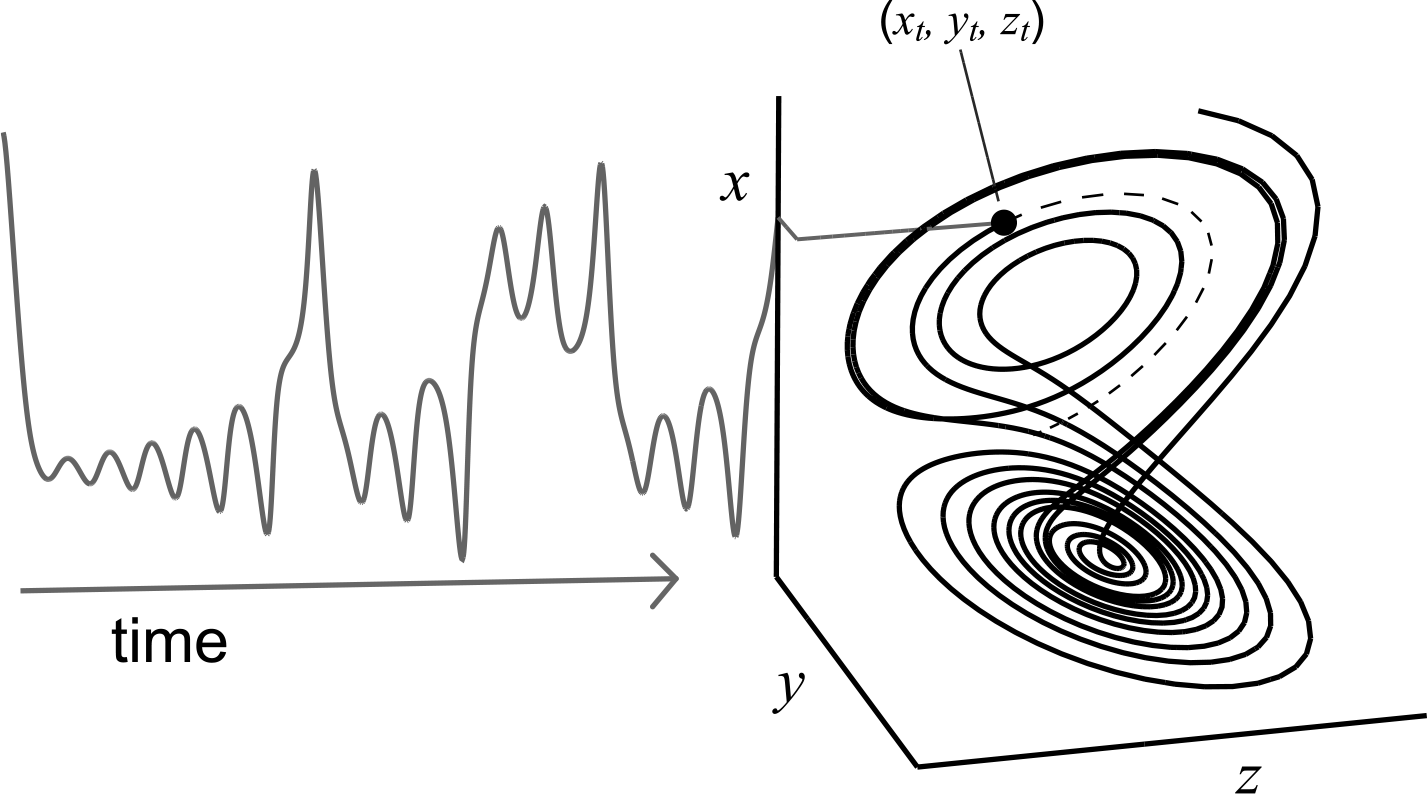
An example of a dynamic system and its corresponding manifold
If the underlying equations of the attractor manifold
This logic also applies to the multivariate case, such as if a stochastic input is also needed to reconstruct a system (Deyle and Sugihara 2011). Figure 2 illustrates this reconstruction process using E = 3 lags of X from figure 1. As figure 2 illustrates, a set of E-length vectors formed by E lags of X are used to reconstruct the original manifold as the shadow manifold

An example of manifold reconstruction
Notably, this can also be done using panel data, and in our Stata implementation this case is by default treated using the multispatial method of Clark et al. (2015), wherein E-length vectors of lags on X are taken for each panel separately (so any given point on
Using lags to reconstruct a manifold is a delay embedding or lagged coordinate embedding approach to state-space reconstruction, wherein E-length vectors of lags on X define points on
This general approach to reconstructing
The
2.1 Simplex projection
Simplex projection is a method for investigating the dimension of
The other half of the data form a “prediction” or test and validation set, which contains E-length target vectors falling somewhere on
A weight wi associated with each neighbor i is determined by the Euclidean distance of the target to each neighbor and a distance decay parameter θ. Specifically, the weight wi can be written as
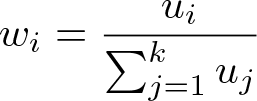
where

and the Euclidean distance measure is denoted ||·||, and
The quality of predictions is evaluated by the correlation ρ of the future realizations of the targets in the prediction set with the weighted means of the projected simplexes. The mean absolute error (MAE) of the predictions, a measure that focuses more on the absolute gap between observed and predicted data instead of the overall variations like ρ, can also be used as a complement to ρ with the inverse property (that is, higher value indicates poorer prediction) and will range between 0 and 1 when variables are prestandardized (we implement a special
To simplify prediction, only the first observation in each target vector’s future realization (at t + 1) is used for ρ and MAE (rather than, for example, a multivariate correlation using the entire set of E observations). The resulting ρ and MAE offer insight into how well the reconstructed manifold
To infer about the underlying system (for example, its dimensionality D), ρ and MAE are evaluated at different values of E, and the functional form of the ρ –E and MAE–E relationships can be used to infer about the extent to which the system appears to be deterministic within the studied time frame (Sugihara and May 1990). Unlike typical regression methods, increasing the dimensionality of a reconstructed manifold by adding additional lags (that is, larger E) will hurt predictions when this adds extraneous information, thus making maximum ρ and minimum MAE useful for choosing E. In low-dimensional systems, adding additional lags by increasing E will add extraneous information that hurts predictions so that ρ is maximized at a moderate E and falls as E increases. In high-dimensional or stochastic systems with autocorrelation, this will not be the case, and ρ may increase with E or appear to approach an asymptote as E increases, which is why the E–ρ and E–MAE relationship is diagnostically useful.
Ideally, a system can be described by fewer than 10 factors (dimensions), such that prediction is maximized when E < 10. In this case, the system may be considered low-dimensional and deterministic to the extent that predictive accuracy is high (for example, ρ > 0.7 or 0.8). In other words, deterministic low-dimensional systems should make good predictions that are maximized when E is relatively small. If prediction continues to improve or improves and then stabilizes as E increases, the system may be tentatively considered stochastic. This may be due to either stochasticity with autocorrelation (for example, an autoregressive process) or high-dimensional determinism that, practically speaking, may be treated as stochastic. To describe such systems parsimoniously, an E may be chosen that does not lose too much information compared with an E that maximizes predictions (for example, by hypothesis tests we describe later), because “it is also important not to overfit the model, and in some cases it may be prudent to choose a smaller embedding dimension that has moderately lower predictive power than a higher dimensional model…We do this both to prevent overfitting the model, and to retain a longer time series” (Clark et al. 2015, s3–s16).
Finally, this general approach can also be made multivariate by including additional observations from different variables in each embedding vector (see Deyle et al. [2013, 2016a,b ], Deyle and Sugihara [2011], and Dixon, Milicich, and Sugihara [1999, 2001]). This is useful when an attractor manifold cannot be fully reconstructed with a single variable, such as with external forces stochastically acting on a system (Stark 1999; Stark et al. 2003). In such a case, simplex projection can be conducted by adding additional variables to the embedding and testing for improved predictive ability—with special considerations for producing similar prediction conditions noted in the work cited here, specifically by using the same number of nearest neighbors when including versus excluding the additional variable in the lagged embedding. Conveniently, if an additional variable participates in an alternative deterministic system, then only a single observation from the alternative system may need to be included in the embedding. If prediction does not improve, then no new information is being provided by the additional variable (as Takens’s theorem implies for coupled deterministic systems). Notably, in any multiple-variable case, standardizing the variables helps ensure an equal weighting for all variables in the embedding (for example, using z scores).
2.2 S-maps
S-maps or “sequential locally weighted global linear maps” are tools for evaluating whether a system evolves in linear or nonlinear ways over time (Sugihara 1994; Hsieh, Anderson, and Sugihara 2008). This is useful because linear stochastic systems such as vector autoregressions (VARs) can be predictable because of autocorrelation, which would appear as a high-dimensional system with ρ > 0 using simplex projection. Therefore, a tool is needed to evaluate whether the system is actually predictable because of deterministic nonlinearity, even if it is high-dimensional. S-maps function as this tool.
A nonlinear system evolves in state-dependent ways, such that its current state influences its trajectory on a manifold
Although we use the term “autoregression”, we are not describing a time-series or panel-data model equation, and instead, the S-map procedure should be interpreted as reconstructing and interrogating a manifold (rather than modeling a series of predictor variables). As with simplex projection, S-maps use a 50/50 split of data into library and prediction sets of E-length embedding vectors by default. The library set represents a reconstructed manifold
Numerically, the predicted value y at point t (from the prediction set) is calculated as
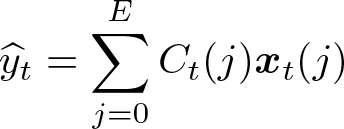
The coefficient vector

When θ = 0 in the weight function, there is no differential weighting of neighbors on
Again, using ρ and MAE, and looking at the functional form of the ρ–θ and MAE–θ relationships, the nature of a system can be evaluated. If state-dependence is observed in the form of larger ρ and smaller MAE when θ > 0, then EDM tools can be used to model the nonlinear dynamic behavior of the system. If nonlinearity is not observed, EDM tools can still be used to evaluate causal relationships in a nonparametric fashion by using CCM (although CCM may be less efficient than more traditional methods in this case). Here again, S-maps may be useful diagnostically because a linear stochastic system with autocorrelation should show optimal predictions when θ = 0, if for no other reason than increasing local weighting because θ > 0 may increase sensitivity to local noise.
As with simplex projection, S-mapping can also be done in a multivariate fashion (see Deyle et al. [2013], Deyle et al. [2016a], Deyle et al. [2016b], and Dixon, Milicich, and Sugihara [1999, 2001]). Here the interest is in determining whether additional information about a system is contained in other variables because of external forces acting on the system, and tests for improved predictions are possible to evaluate this (with information on how to conduct and interpret such tests described in the work just cited). In the multivariate case, S-maps are more similar to autoregressive-distributed lag or dissipative particle dynamics models, but strictly only when θ = 0. As θ increases, it becomes a more local regression wherein neighbors are identified and predictions increasingly rely on the local information in a reconstructed manifold. Again, standardization can help ensure an equal weighting for the different variables in the model, but remember that the S-map is not a traditional regression model, and instead, is a reconstructed attractor manifold
2.3 CCM
CCM is a nonparametric method for evaluating causal association among variables, even if they take part in nonlinear dynamic systems (Sugihara et al. 2012). This method is based on the fact that if X is a deterministic driver of Y , or X → Y , then the states of Y must contain information that can contribute to recovering or “cross-mapping” the states of X (Schiff et al. 1996). This method is an extension of simplex projection, such that an attractor manifold
To elaborate, CCM is based on the fact that if variables X and Y participate in the same dynamic system with manifold
This is counterintuitive because in typical time-series or panel-data methods, causes are used to explain or predict outcomes rather than the reverse. However, in CCM, the outcome Y cross-maps or “xmaps” the causal variable X, with a shadow manifold
The term “convergent” in CCM describes the criterion by which causality is assessed. This term reflects that if X → Y causality exists then prediction accuracy (for example, a correlation ρ among X and X
b) will improve as the library size L of points on
2.4 Missing data and sample-size considerations
Missing data are currently treated in a way that may aid in a general understanding of EDM. Currently, missing data are by default dealt with using a deletion method, such that a single missing datum causes up to E missing points on a reconstructed manifold
Thus, because the manifold exists in E dimensions, any points on the manifold that would include a missing datum cannot be used for computations. Therefore, similar to time-series and panel-data models with lagged regressors wherein the lag order dictates the amount of information lost in the regression, current EDM implementations lose information as a function of E and, of course, the missing-data patterns. Optimally, missing-data rates are low and missing data are missing adjacently in time rather than spread throughout a dataset.
In cases where significant missing values are present, appropriate imputations could help the reconstruction of the manifold as shown in van Dijk et al. (2018). However, we caution the reader to carefully consider typical multiple-imputation or interpolation methods for missing data. The problem with imputation is that typical methods are not sensitive to the nonlinear dynamics that EDM is meant to allow studying. When linear associations are assumed or parametric nonlinear approaches are used, then this can obscure a dynamic signal. The study of how to impute missing values in nonlinear dynamic systems is beyond the scope of our article, but the reader should know that it is not trivial and we are considering various options. 2
Many readers may next be considering required sample sizes for EDM analysis. There is no simple cutoff in terms of sample size, but one assumption for EDM is that a dynamic system of interest has been observed across a relevant range of its states over time, by which we mean it has evolved through relevant regions of its state space over time. Preferably, the system will have been observed evolving through these locations more than once to help in the process of determining its proper dimensionality during simplex projection and maximizing predictability in CCM (see Sugihara et al. [2012] and Ye et al. [2015b]). For example, if a system tends to dynamically fluctuate over a 10-year period in terms of some substantive phenomena of interest, then measuring the system over at least a period of 10 years and preferably 20 with adequate resolution would be needed to capture its dynamic behavior patterns—this can be understood as a typical concern about generalizability when considering sampling issues. When describing the
3 Syntax
The
The first main subcommand,
The second main subcommand,
Both main subcommands support the if qualifier. The options are detailed in the next section, and additional options will be introduced while the package is under active development.
Additionally, the
3.1 Options
The number specified within the
In the newly created variables, the first number immediately after the prefix is
Variables starting with
Following the
The final term,
4 Output and stored results
Typical output from using the

The output includes the selected range of system dimensions E and θ values, and it reports the corresponding mapping/prediction accuracies in the form of ρ (correlation coefficient) and MAE. By prestandardizing the variables used, MAE can be understood as the conceptual inverse of ρ (that is, 1−MAE), and these can then be plotted together.
Typical output from using the
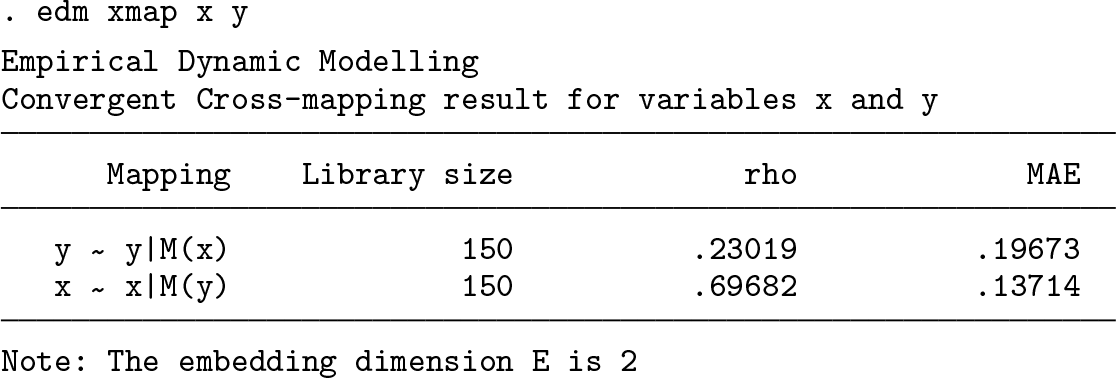
The output shows a table listing the direction of the mapping. The notation
In addition to the table output, the
5 Examples
5.1 Creating a dynamic system
The logistic map has often been used to demonstrate a nonlinear dynamic system, displaying regular periodic behavior as well as deterministic chaos (May 1976). This particular system has been widely cited in EDM literature (see Perretti, Munch, and Sugihara [2013], Ye and Sugihara [2016], and Mønster et al. [2017]). Here we create an arbitrary dynamic system with two logistic maps coupled through linear coefficients to illustrate the use of the

A logistic map is well known to exhibit chaotic patterns with a specific combination of parameters (Jackson and Hübler 1990). The values in the equations were chosen to exploit this property, creating a dynamic system. The two variables x and y both depend on their own past values and are coupled with each other through the last term of the equation. In this case, x is set to be determined by its own past values only, while y is determined by past values of both y and x.
Figure 3 plots the values for x and y over time, when x 1 and y 1 are set to 0.2 and 0.3, respectively. Observations with a t smaller than 300 were burned to allow the dynamics to mature. 3 The pairwise correlation coefficient between x and y is 0.15, and it is not significant at the 0.05 level, giving the appearance of two unrelated variables. Indeed, the plot from figure 3 shows that the variables could appear positively or negatively correlated depending on the temporal window in which data were collected from the system. This case mimics a potentially common scenario wherein “mirage correlations” can exist in a dataset and, more importantly, causation can be inferred without the presence of a linear correlation (which, using typical linear indices such as correlation coefficients, would be missed).

Plot of a nonlinear dynamic system
5.2 Exploring the system’s dimensionality
The first step in EDM analysis is to establish the dimensionality of the system, which can be understood as approximating the number of independent variables needed to reconstruct the underlying attractor manifold
Using the
In this example, we explore all dimensions between 2 and 10 using simplex projection to identify the optimal E.
4
Because the library set is randomly selected, we replicated the method 50 times through the option

The standard deviations are bias-corrected, using N − 1 in the denominator. Note that the reported standard deviation values are summary statistics instead of the standard error of the ρ and MAE estimates. The
The results show that ρ drops and MAE increases as E increases. This suggests that the optimal E is 2, which is the exact number of independent variables we used to create the dynamic system. The result can also be plotted using the contents of the stored

ρ –E plot of variable y
5.3 Nonlinearity detection using S-map
We next evaluate the system for nonlinearity by using S-maps or “sequentially locally weighted global linear maps” (Sugihara 1994; Hsieh, Anderson, and Sugihara 2008). Linearity exists if the trajectory on a manifold
When θ = 0 in the option
Both the

The result from the command above can also be plotted graphically using the return matrix

Nonlinearity diagnosis (ρ–θ plot) of variable y
5.4 Causality detection using CCM
In the earlier steps, the analysis suggests that the optimal E for this example is 2, which is what we expect given the data generation. We now use the
In CCM, the causal link between variables is evaluated by predicting values of one variable—the potential cause—using the reconstructed manifold of another—the potential outcome—which is based on Sugihara et al. (2012). In essence, this is a kind of two-variable simplex projection wherein the library set is formed using one variable and contemporaneous predictions are made for another variable. Using the predicted versus observed values, ρ and MAE are calculated. It should be noted that bivariate cross-mapping captures the overall causal effect, combining both the direct effect (X → Y ) and the possible indirect effects (X → Z → Y ). 5
Simplex projection may show that different E values characterize different variables. If this were the case, the E chosen for reconstructing a manifold can be used with the
The

Without specifying a value for
The example below estimates ρ at library sizes between 5 and 150, and repeats the process 10 times (taking a random draw to form the manifold 10 times at each library size). Multiple repeats are used to ensure enough point estimates (number of repeats for each step in library size) to clearly identify any trends in predictability ρ as the library size increases, as well as differences in these trends between both directions for the mappings (both x–y and y–x; see figure 6). For the maximum library size, this replication process does not produce different results because all observations are used. Because this maximum library size is the most computationally demanding, with large datasets it may be prudent to separately run the

The detailed results are stored in two return matrices,

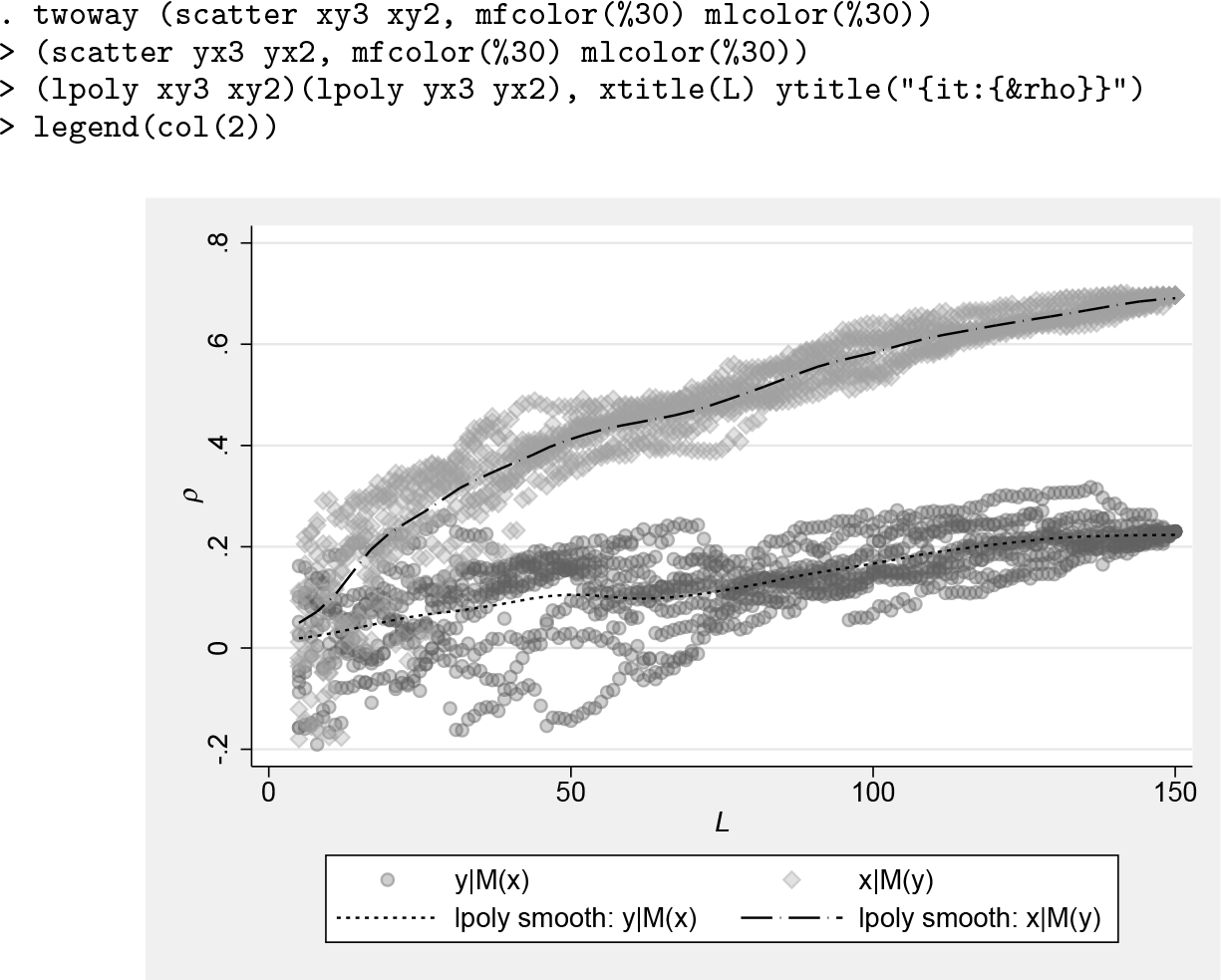
ρ –L convergence diagnosis
The ρ –L diagnosis figure suggests that the predicted x from the manifold constructed from y (that is, x|
5.5 Hypothesis testing with CIs and null distributions
There are three primary ways to test hypotheses about causal effects and dominant causal direction in our
One way to estimate the standard error of the estimates due to the resampling process is with the jackknife prefix, which generates estimates for ρ. A CCM example is as follows:

This is particularly useful in CCM because it offers a CI around ρ at the maximum library size, which is arguably the best estimate of ρ in CCM applications. The
To evaluate convergence for CCM at library sizes smaller than the maximum and for any result from the
We randomly sample the dataset 100 times using the
Also relying on the
In the example below, the
Similar tests are possible using
Finally, rather than forming intervals around specific ρ or MAE, a third approach forms a null distribution for ρ or MAE by using permutation-based randomization. Typically called a surrogate-data method, this procedure shuffles the data across a time variable (that is, randomizes the time variable) and reestimates the model each time (for example, see Deyle et al. [2016a], Hsieh, Anderson, and Sugihara [2008], and Tsonis et al. [2015]). This is a useful approach because it keeps the observed data intact but ruins its temporal aspects that are essential for modeling system evolution in EDM. With this method, a null distribution can be generated for ρ and MAE in simplex projection, S-mapping, or CCM by simply generating a random sequence of numbers, sorting the data by them, and then generating a new
As an example, we can compare figure 6 with the ρ –L convergence in figure 7, which is derived from a permutation test using the original
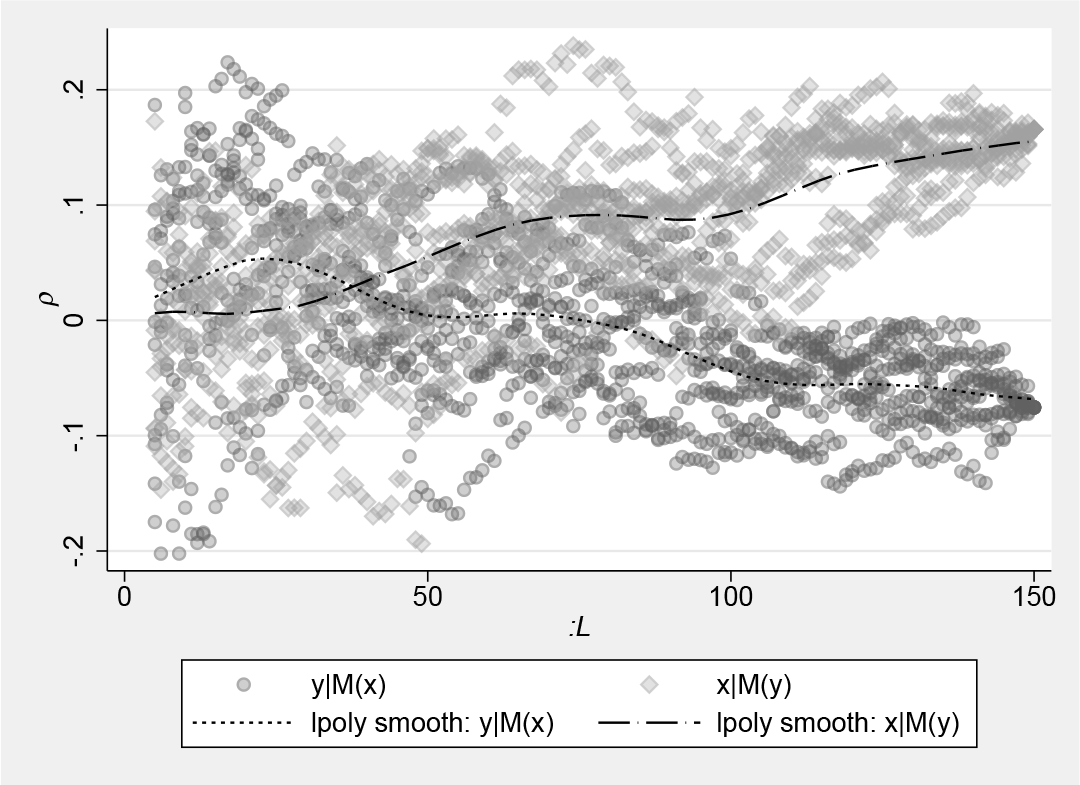
ρ -L convergence diagnosis in a permutation test
Using this same basic logic, if seasonality or other periodic effects are a concern, permutation can be done in ways that reflect such periodic coupling to test whether these are biasing results (see Deyle et al. [2016a] and Deyle et al. [2016b]).
Beyond these three methods, it is also possible to implement a more traditional nonparametric bootstrap with replacement (see Clark et al. [2015] and Ye et al. [2015c]). Yet, care must be taken in the resampling process because the data must be in a valid time-series or panel format to form the proper E-length vectors without creating missingness. The
5.6 Evaluating time-delayed causal effects
Another interest when investigating causality is to test for time-delayed causal effects over a specific time frame. Ye et al. (2015b) proposed an extension of CCM to determine whether a driving variable acts with some time delay on a response variable by explicitly considering different lags for cross-mapping. In this approach, one implication is that direct effects among variables should have the highest cross-map skill (that is, largest ρ and smallest MAE) and the most immediate effects (no or few lags). On the other hand, indirect effects should be weaker and have longer time delays. Furthermore, and rather curiously, in cases where bidirectional causality appears to exist because of what is actually strong unidirectional forcing, an impossible positive lag showing a maximum effect can indicate false convergence (see Ye et al. [2015b])—in this case, the test for time-delayed effects is thus an assumption test.
The

which is a function of its own past values and the lagged values from y, thus forming an indirect x → y → z effect. We use
As shown in the cross-mapping results 7 in figure 8, x → y and y → z seem to exhibit higher ρ values and fewer delays. The link between x and z has much weaker cross-map skill and longer delays in observing the peak ρ, suggesting an indirect time-delayed causal effect that by design exists in our model: x → y → z.

Time-delayed causal detection
5.7 Visualizing the strength of causation
To demonstrate the usefulness of EDM in estimating the impact of causal variables, in this section we use a real-world dataset (available with the article files) that reflects daily temperature and crime levels in Chicago. Compared with the previous logistic map example, where the marginal effects of the two variables are highly unstable over time by construction, this example showcases how
We first use the steps we recommended above: explore the data series 1) using simplex projection to find optimal E and 2) using S-maps to examine for nonlinearity. Then 3) use the
In the exploration phase,
Figure 9 shows the ρ –L convergence plot derived from the

ρ –L convergence plot for Chicago crime dataset (10 replications)
To estimate the size of causal effects in addition to predictive ability in CCM, we proceed with cross-mapping using the S-map algorithm and the

In addition to the standard reporting, this command generates new variables named with the prefix
As explained earlier, the S-map process uses what can be thought of as a locally weighted distributed lag model with E predictors (and a constant term c), and each of the coefficients can be stored as variables with the
Figure 10 plots the contemporaneous effect of temperature on crime (
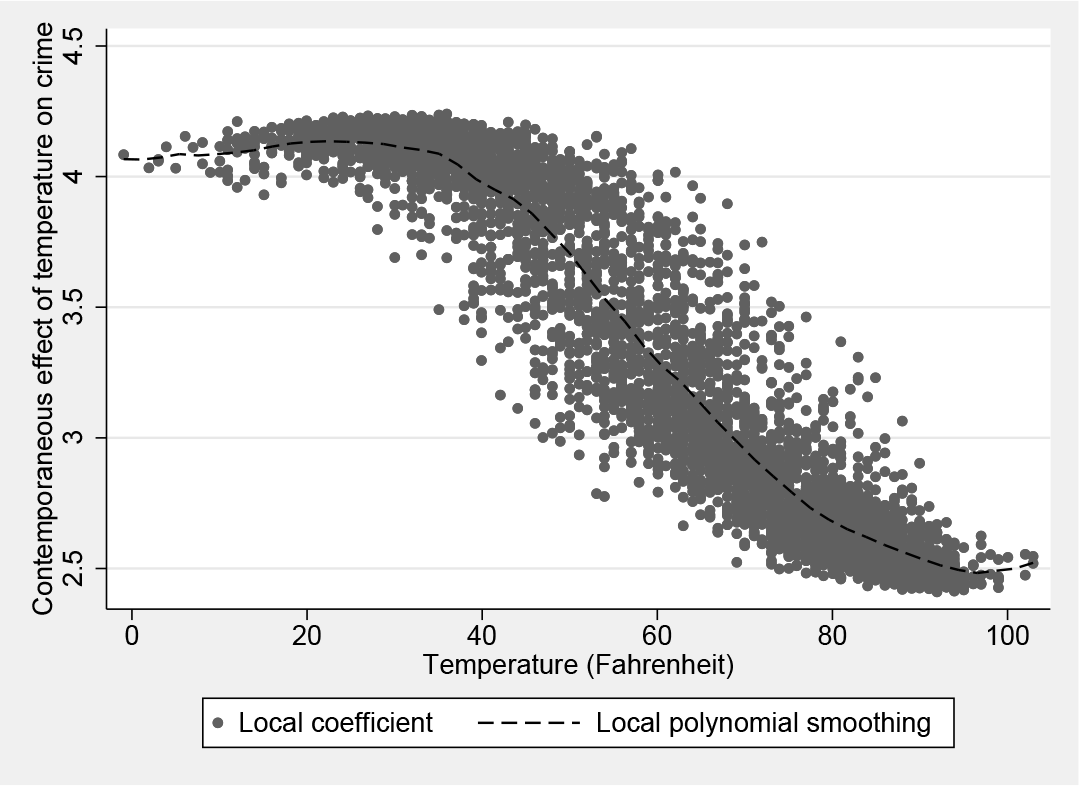
Scatterplot of the S-map coefficient (contemporaneous effect)
Depending on the context of the analysis, it could also be important to emphasize the dynamic nature of the model, because any change at t−τ would affect the observations at time t. To predict the impact of a lagged temperature shock, one may consider running the prediction iteratively over time (a step-ahead prediction) to estimate its long-term impact on crime rate. The prediction via this dynamic process may be different than the reported coefficients because of the nonlinear nature of the system. The more common practice in autoregressive or VAR models of using the sum of the average effects across all E lags may ignore the nonlinear dynamics in the marginal effects over time.
To illustrate the use of the command, we also provide three template do-files as part of the supplementary materials for the article. These cover three common analysis types for time-series data, “multispatial” panel data (a shared dynamic system using the default multispatial approach), and “multiple EDM” panel data (distinct dynamic systems where each panel is analyzed separately; similar to van Berkel et al. [Forthcoming]). These do-files automatically analyze data using the primary EDM tools of simplex projection, S-maps, and CCM but also produce various plots and automate additional postprocessing, including hypothesis tests of various types. These do-files will also be updated over time to include additional features and fix bugs.
6 Concluding remarks
The new
This is an important addition to Stata’s existing capabilities for multiple reasons, including checking the assumptions that underlie many existing time-series and panel-data methods. For example, most of these methods assume stability or stationarity in random residuals, but tests for these conditions are typically based on assumptions of linearity and therefore may not be sensitive to nonlinear dynamics. To evaluate this, residuals from typical approaches can be subjected to the methods we propose here to check for structure from nonlinear dynamic systems (Dixon, Milicich, and Sugihara [2001]; see also Glaser et al. [2011]). Specifically, simplex projection can be used to test for low-dimensional determinism that may masquerade as random noise, and S-maps can be used to test for nonlinearity. Furthermore, residuals and observed predictors can be used in CCM to test for causal effects missed in other approaches, whereas all residuals from VAR models can be used in CCM for the same purpose. This allows for more robust tests of assumptions regarding residual dynamic structures.
Like many community-contributed programs,
Supplemental Material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211000030 - Beyond linearity, stability, and equilibrium: The edm package for empirical dynamic modeling and convergent cross-mapping in Stata
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211000030 for Beyond linearity, stability, and equilibrium: The edm package for empirical dynamic modeling and convergent cross-mapping in Stata by Jinjing Li, Michael J. Zyphur, George Sugihara and Patrick J. Laub in The Stata Journal
Footnotes
7 Acknowledgments
This research was supported partially by the Australian Government through the Australian Research Council’s Discovery Projects and Future Fellowship funding scheme (projects DP200100219 and FT140100629). The views expressed herein are those of the authors and are not necessarily those of the Australian Government or Australian Research Council.
8 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.