
Abstract
The popularity of GitHub is growing, among not only software developers but also statisticians and data scientists. In this article, I discuss why social coding platforms such as GitHub are preferable for developing, documenting, maintaining, and collaborating on statistical software. Furthermore, I
1 Introduction
GitHub 1 is a social coding site that offers plenty of features for collaboration on software such as tracking issues, documentation platform, managing tasks, and version control (Chacon and Straub 2014). Within a few years after its launch in 2008, GitHub became not only the largest host for Git repositories with over 28 million developers (GitHub 2018c) and 29 million public repositories (GitHub 2018b) but also the largest code-hosting site in the world (Gousios et al. 2014b).
Such a sharp-growing trend can also be seen for public Stata repositories on GitHub. As shown in figure 1, from 2013 to 2019, there has been a rapid growth in the number of Stata repositories, and over 4,097 repositories and 749 installable community-contributed packages have been publicly published.
2
The resurgence in GitHub popularity for hosting Stata packages underscores the necessity for a command that facilitates accessing and managing them. In this article, I introduce the

Public Stata repositories and packages on GitHub by year of creation
1.1 Developing statistical software on GitHub
At first glance, GitHub appears to be a multifaceted platform with a variety of industry-standard services that expedite software development, maintenance, and documentation. The preeminent advantage of GitHub, nonetheless, is its social nature (Thung et al. 2013). GitHub is essentially a social network for gregarious developers to broadcast their coding exercise, follow others’ activities, audit a repository, discover recent projects, and collaborate (Dabbish et al. 2012b; Vasilescu, Filkov, and Serebrenik 2013). Subsequently, the pro-social characteristics of GitHub promotes project dissemination by attracting attention and building reputation (Jiang, Zhang, and Li 2013), ergo peer reviewing the code by plenty of programmers.
The question, however, is, How can GitHub turn programming into a collective activity? At its core, GitHub is a combination of Git (Torvalds and Hamano 2010)—a popular distributed version control system—with a social media, which enables code integration (collaboration) through a two-level hierarchical network (Cross, Borgatti, and Parker 2002). Those who have writing privileges to a repository belong to the upper-level hierarchy and can make direct contributions to the project. In contrast, in an indirect involvement, developers who do not have writing privilege, fork (clone) (Jiang et al. 2017) the main repository, rework a part of the code, and then submit a pull request to be reviewed by the project maintainers. If accepted, the change will be incorporated in the repository. Such a practice—known as a pull-based development model (Barr et al. 2012; Gousios, Pinzger, and Van Deursen 2014a)—permits anyone to view, fork, and contribute to any public repository on GitHub (Vasilescu et al. 2014). The pull-based development model relies on distributed version control for monitoring individual inputs, preserving the progress history, supporting backup to any development period or versions, and blending individual contributions into a project (Tichy 1985; Hammack et al. 2002; Fischer, Pinzger, and Gall 2003).
There is a striving for more transparency in scientific computations (Miguel et al. 2014), and GitHub is a step toward this end. On the one hand, the publicly available development history of a project, that is, how it has evolved in time and who committed to it, elevates its transparency (Dabbish et al. 2012a). On the other hand, the project-dissemination aspect of GitHub boosts the transparency, enabling anyone on the Internet to be a potential peer reviewer (Jiang, Zhang, and Li 2013; Dabbish et al. 2012b). Studies have shown that GitHub users account for such information when evaluating a repository (Dabbish et al. 2012a; Jiang et al. 2017; Marlow, Dabbish, and Herbsleb 2013).
Despite the success of open-source software, there are many challenges associated with the open-source software development. For example, a lack of structured documentation and communication, which are required for teamwork (Vasilescu et al. 2014). Moreover, every time a pull request is made to update the project, one of the project’s core team members should review and integrate the suggested changes to the code or documentation (Gousios et al. 2015). Evidently, the more complex the project, the larger such obstacles (El Emam et al. 2001). Nevertheless, generally speaking, such problems are less probable for Stata packages because most do not have an intricate structure. To evaluate this assertion, I mined and analyzed all Stata packages published on the Boston College Statistical Software Components (SSC) Archive and GitHub until January 1, 2019. 3 The resulting datasets comprised 707 installable repositories (some of which included multiple Stata packages) hosted on GitHub and 2,807 packages hosted on the SSC Archive. Analyzing their content revealed that, respectively, 60% and 70% of the commands hosted on GitHub and the SSC Archive are composed of a single script file (that is, an ado-file or a Mata file). In the same vein, roughly 80% of packages on GitHub and 90% of packages on the SSC Archive included up to three script files only. This implies that most Stata packages have a relatively simple structure.
1.2 Hosting statistical software on GitHub
The SSC Archive has been the primary landing point for most Stata packages. Packages published on the SSC Archive are indexed by the The SSC Archive facilitates searching and installing a package. However, there is no way to download a package as a zip file for archiving it in a data-analysis project or inspecting it (see the technical note below). The SSC Archive does not require specifying or report any information about version and license of hosted packages. The SSC Archive hosts only the latest release of the package, without archiving the previous releases. Along with lack of version specification, this can pose threats to research reproducibility. There is no mechanism to cite and install dependencies on the SSC Archive (see section 2.4), which cannot be accomplished without archiving previous releases either. Otherwise, relying on other community-contributed software without declaring
4
the required version would be a sloppy programming practice.
GitHub knows none of these limits. Stata packages hosted on GitHub can be downloaded as 1) a development version, which is often the main branch of the repository, and 2) a stable release. The latter is significant because it is prepared and documented for the installation. Releasing a stable version on GitHub is as simple as a few mouse clicks. More importantly, all previous releases are archived and remain accessible. For every release, the maintainer has to declare a unique version and, optionally, can write a report about that release. In addition, GitHub can host not only the software but also its documentation via a version-controlled Wiki. Users can fork the Wiki, update it, and make a pull request, just as they would do for updating a program.
However, the primary obstacle with retrieving packages from GitHub is that Stata’s
Technical note
The
1.3 Addressing the problem of unique filenames
Stata lacks modularized package loading, in contrast to R or Python. Therefore, all community-contributed script files are stored in shared directories. Thus, there is a possibility of overwriting a script file if an identical filename is used in two installed packages. This problem can be ameliorated by checking whether a particular filename exists in other packages. The
2 The github command
The searching GitHub application programming interface (API), http://www.stata.com, and other web sources for Stata packages. installing a development, a stable, or an archived stable version of a package, along with its dependencies. managing and updating installed packages. introducing a graphical user interface (GUI) and the building of packaging files (that is, the
2.1 Installation
The
The Stata programs that are used for mining GitHub and the SSC Archive are included in the
2.2 Syntax
The general syntax of the
Summary of

Apart from
2.3 Searching Stata repositories
The

The options help narrowing down or expanding the search scope. For example, you may limit the results to repositories where the majority of the code is written in the Stata language
6
(default) or expand the search by including results from Stata’s
The package incorporates a search GUI with all options above that can be launched by typing

Alternatively, one can execute the

The command presents useful information in the search output. For example, it prints the latest update of the package, its homepage (if specified), and its main programming language. It also checks whether the repository is an installable Stata package; if so, an
Another way to look for Stata packages is to search keywords. For example, searching for the

2.4 Installing GitHub repositories
The
The
For example, let us assume you would like to install the

In this example, three Stata packages mention

In the same fashion, with the

Finally, we can use the

The
Technical note
As shown from the returned results of the
By avoiding the
Package dependencies
Package dependency is a somewhat unaddressed problem with Stata, particularly because the SSC Archive does not provide any procedure for declaring and installing dependencies. Thus, developers apply work-around tricks to check whether the required packages are installed. For example, they may search for a script file from the required dependency package. If the file was not found on the machine, an error is returned notifying the user that a dependency is missing. With such a clumsy workflow, developers have no control over the versions of the dependencies, and that can often lead to bigger problems in the long run. From a different perspective, this problem motivates the developers to include all of their codes within a single package and avoid modulating their code into separate packages that can be used by other developers.
The
2.5 Handling installed packages
The
These subcommands require only the packagename. Perhaps the handiest of these subcommands is
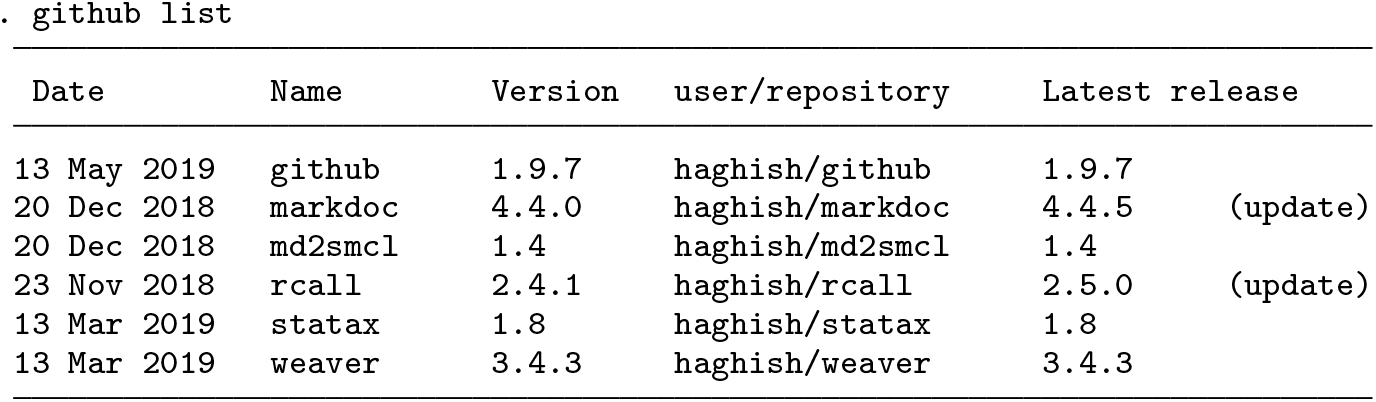
In the output above, the currently installed version and the latest release of the software are shown. If there is a newer release available, a clickable
Finally, to remove the package, type
Technical note
When a package is installed using
3 github for developers
Stata developers can make use of two features of the
3.1 Ensuring unique filenames
As mentioned in section 1.3, Stata community-contributed packages might overwrite one another if they include identical filenames. Having an archive of all known Stata packages and their filenames can guide programmers to check whether their filenames are unique. The mentioned database is named
The

The output shows the files and packages that include “mark” in their name and whether they are hosted on GitHub or the SSC Archive.
3.2 Building package installation files
To install a repository, Stata demands package installation files encapsulating information necessary for installing and managing the package (for instance, package name, list of installation and ancillary files, publication date, author name, software description). This information is stored within two files, named
The Name A short title Version License Author name Email or contact information Installation or ancillary files, or both
The installation files can be script files, help files, or generally any file that should be copied to the user’s machine within the installation. To select the installation or ancillary files, browse to the package directory, and, while holding the CTRL key (Command on Mac), click on the files that should be installed. To launch the GUI, type
The GUI calls the
3.3 Example of building a Stata package
To demonstrate how a Stata package can be built using the
Next, change the working directory to where the forked repository is stored, and launch the

Example of information required for building the package installation
For this example, there are no ancillary files. Nevertheless, we have two installation files, an ado-file and a help file, that should both be selected. Next, executing the GUI will create the package installation files, which are

Creating installation and supplementary files with the
Technical note
The interested reader can inspect the
4 Discussion
In the ‘90s, the emergence of the Internet made collaborations between geographically separated developers possible (Raymond 1999). This was particularly important for open-source software development, which survives on volunteers contributing during their spare time (Hars and Ou 2002; Raymond 1999, 2001). In contrast to the early skepticism (Lewis 1999), collaborating on open-source software has become a social norm, as implied by the enormous community of sites such as GitHub and Stack Overflow (Vasilescu, Filkov, and Serebrenik 2013). Similarly, the community of Stata developers on social coding platforms is growing fast, and GitHub has become a home to hundreds of Stata packages and thousands of Stata repositories.
In this article, I tried to fill the gap between Stata developers on GitHub and the rest of the community by providing a comprehensive software toolbox for searching, building, installing, and managing Stata packages from GitHub. In the same vein, I argued in favor of using GitHub for developing, maintaining, documenting, and even hosting a statistical package. I also warned the reader of some shortcomings of the SSC Archive because of its issues with discarding software versions, licenses, dependency declarations, and, most importantly, lack of archiving previous releases. Unlike the SSC archive, the Comprehensive R Archive Network (CRAN) (Claes, Mens, and Grosjean 2014) archives all the previous stable versions and also includes its hosted packages on Github 12 and archives the different versions via GitHub releases. Such a practice enables users to quickly navigate through different versions of a program and trace the changed codes across stable releases. A similar move from the SSC Archive would be welcomed and effectively solve all the issues I have listed.
The
There is a saying that goes “too many cooks spoil the broth”. In my opinion, however, when it comes to coding and computational transparency, the more chefs involved, the better. I underscored that the primary benefit of GitHub is not its convenient and helpful software tools but its community of experts. Its huge community makes GitHub a good place for developing, maintaining, and hosting statistical software and stepping toward computational transparency.
Footnotes
5 Programs and supplemental materials
The
Notes
A Appendix
The github install haghish/miningtools, stable
The