
Abstract
When considering multiple-hypothesis tests simultaneously, standard statistical techniques will lead to overrejection of null hypotheses unless the multiplicity of the testing framework is explicitly considered. In this article, we discuss the Romano–Wolf multiple-hypothesis correction and document its implementation in Stata. The Romano–Wolf correction (asymptotically) controls the familywise error rate, that is, the probability of rejecting at least one true null hypothesis among a family of hypotheses under test. This correction is considerably more powerful than earlier multiple-testing procedures, such as the Bonferroni and Holm corrections, given that it takes into account the dependence structure of the test statistics by resampling from the original data. We describe a command,
Keywords
1 Introduction
Advances in computational power and statistical programming languages such as Stata mean that, typically, the testing of multiple hypotheses in an empirical analysis is easy and quick to carry out. This often leads to a situation in which existing data sources or experiments are used to examine a number of hypotheses. Although the computational costs of such a situation are generally very low, there is a well-known statistical cost in cases of multiple-hypothesis testing. Namely, as the number of hypotheses considered in a given analysis grows, so too does the probability of falsely rejecting true null hypotheses. Starting from Bonferroni (1935), there has been considerable development of techniques that account for multiplicity in hypothesis testing.
In this article, we discuss the implementation of one such procedure, the Romano–Wolf multiple-hypothesis correction, described in Romano and Wolf (2005a,b, 2016). This procedure uses resampling methods, such as the bootstrap, to control the familywise error rate (
In this article, we focus on the control of the FWER, but this is certainly not the only error rate that can be considered in multiple-hypothesis testing. For example, a series of alternative procedures focus on controlling the false discovery rate, defined as the expected proportion of true null hypotheses rejected among all hypotheses rejected. Details of many such procedures, such as Benjamini and Hochberg’s (1995) procedure, as well as earlier, less powerful techniques to control the FWER and their implementation in Stata can be found in Newson and the ALSPAC Study Team (2003) and Newson (2010). In general, false discovery-rate techniques are less conservative than FWER techniques, and are particularly common in genetic or biochemical applications where often a huge number of null hypotheses are considered (in the thousands or even tens of thousands). An illustrative applied discussion is provided in Anderson (2008).
The Romano–Wolf procedure is increasingly used in a range of fields, given the recognition of its relative power, computational efficiency, and generalizability. This multiple-hypothesis correction can be found in settings as diverse as finance (Liu, Patton, and Sheppard 2015), early childhood interventions (Gertler et al. 2014), and the evaluation of conditional cash transfers (Attanasio et al. 2014), to name but a few. Work by List, Shaikh, and Xu (2019) intended for an applied audience details how to implement the general Romano–Wolf methodology for specific applications in experimental economics. In line with the frequency of use of this procedure, this article provides a program,
In what remains of this article, we first provide a brief description of multiplehypothesis testing and the basic notation used here before defining corrections for multiple hypotheses, and the Romano–Wolf procedure in particular, in section 2. We then define the syntax of the
2 Procedures
2.1 Multiple-hypothesis testing procedures and definitions
Consider inference for a generic parameter θ. In what follows, we will refer to data used to estimate this parameter as X and the value estimated using these data as

The test could be a two-sided test, such as H : θ = θ 0 versus H′ : θ ≠ θ 0, or it could be a one-sided test, such as H : θ ≤ θ 0 versus H′ : θ > θ 0. The quantity θ 0 refers to the null value of interest defined by the researcher and is often θ 0 = 0. 3 The type I error is defined when the null hypothesis is true, and as such, Pr θ 0 refers to the probability of (falsely) rejecting the null when θ 0 is the actual value of the parameter. If the probability in (1) is bounded above by a value α, then α is the significance level at the test. Often, a particular value of α is chosen in advance, such as α = 0.05, and the testing procedure is designed to meet this criterion. Alternatively, to avoid somewhat arbitrary criteria, one can report a p-value, here p, that fulfills (at least asymptotically)

for every 0 ≤ α ≤ 1 and is defined as the smallest value of α at which H would be rejected. Smaller values of p provide more evidence in favor of the alternative hypothesis H′.
The validity of this error rate of α assumes that a single null hypothesis is tested. We now extend the setting to a family of S null hypotheses

To account for multiple-hypothesis testing, we seek to control the FWER at level α. By definition, if all the null hypotheses are false, the FWER is equal to 0.
A traditional solution has been to implement the Bonferroni procedure, which consists of rejecting any Hs for which the corresponding p-value, ps , satisfies ps ≤ α/S. This procedure provides strong control 5 of the FWER (see, for example, Lehmann and Romano [2005a, 350]); however, it often has low power to detect false null hypotheses, particularly when the number of hypotheses is large. A procedure that has greater power, while still maintaining control of the FWER was described in Holm (1979). This is a stepdown procedure that begins by ordering the individual p-values such that p ( 1 ) ≤ p ( 2 ) ≤ · · · ≤ p ( S ), corresponding to hypotheses H ( 1 ) , H ( 2 ) ,…, H ( S ); in this way, the hypotheses are ordered according to their significance. H ( 1 ) is rejected if and only if (iff) p ( 1 ) ≤ α/S, just as would be the case for Bonferroni. But if it is rejected, then H ( 2 ) is rejected if p ( 2 ) ≤ α/(S − 1), which is a more lenient criterion. The procedure proceeds in this manner until at some step s, p ( s ) > α/(S −s+1), and then it stops. (If the stopping criterion is never met, the procedure rejects all S hypotheses.) The Holm procedure rejects all hypotheses rejected by the Bonferroni procedure but potentially also rejects other hypotheses.
Both the Bonferroni and the Holm procedures are easy to implement and only require the list of individual p-values
We now illustrate this point with a simple example. Let’s say there are S = 100 hypotheses under test, and one wants to control the FWER at level α = 0.05. The p-values ps are based on test statistics Ts that have a joint normal distribution with common variance 1 and common pairwise correlation ρ. The mean of all test statistics Ts for which Hs is true is equal to 0. The tests are one-sided in the sense that
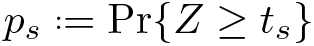
where Z ∼ N(0, 1) and ts is the observed realization of Ts . We consider the following single-step procedure: Reject Hs iff ps ≤ cρ , where cρ is a common cutoff allowed to depend on ρ. The Bonferroni procedure uses cρ ..= 0.05/100 = 0.0005, irrespective of ρ. But as a function of ρ, the following, less conservative, cutoffs suffice to guarantee control of the FWER:

(Apart from ρ = 0 and ρ = 1, the cutoffs cρ need to be determined by numerical simulations and are, therefore, subject to some small simulation error.) In particular, when ρ = 1, all p-values are perfectly correlated, meaning that there really is only a single shared hypothesis under test, in which case it is allowed to use the naïve cutoff α = 0.05 itself. In general, the larger is ρ, the larger is the cutoff cρ , and thus, the easier it becomes to reject false hypotheses, which increases power. Similar considerations carry over to the more general case when pairwise correlations are not constant and to stepwise procedures.
Hence, as described above, if there exists noticeable dependence among the p-values, it would be possible to maintain control of the FWER while increasing power at the same time. To this end, resampling-based multiple-testing procedures have been proposed in the literature. By resampling from the observed data, one can mimic the true dependence structure of the p-values (or, equivalently, among the test statistics) and thus account for it (in an implicit fashion). An early such proposal goes back to Westfall and Young (1993), who use the bootstrap to account for the dependence structure of the p-values. This procedure (described in Westfall and Young [1993, algorithm 2.8] and summarized in appendix A of this article), assumes a certain subset pivotality condition, which is used in establishing FWER control. Roughly speaking, this condition means the following: Take any nonempty, strict subset of hypotheses (out of all hypotheses under test) and look at the random vector of corresponding test statistics. Then the joint distribution of this random vector is unique in the sense that it does not depend on whether the remaining hypotheses (not under test) are true or false. For a precise definition, see Romano and Wolf (2005b, example 2).
Subset pivotality can be violated in certain applications and is thus undesirable, because in such instances the Westfall–Young procedure only guarantees weak control of the FWER. An example where this condition is violated is given by jointly testing the entries of a correlation matrix. Take the case of independent and identically distributed multivariate observations of dimension three. The multiple-testing problem concerns the three (distinct) pairwise correlations

where ρij
denotes the correlation between components i and j of any of the observations. The individual test statistics are the sample correlations, denoted by
Having said this, the procedure of Westfall and Young (1993) is available for Stata, as provided in Reif (2017), with additional discussion in Jones, Molitor, and Reif (2019).
More recently, the Romano–Wolf multiple-hypothesis correction has been proposed, as described in Romano and Wolf (2005a,b) as well as in the subsection below. This procedure also uses resampling and stepdown procedures to gain additional power by accounting for the underlying dependence structure of the test statistics. However, and crucially, this procedure does not require the subset pivotality condition and is thus more broadly applicable than the Westfall–Young procedure.
2.2 The Romano–Wolf procedure(s)
Romano and Wolf (2005b) propose a procedure that controls the FWER at a given level α; hence, this procedure leads to a decision to reject or not reject for each null hypothesis Hs
considered, for s = 1,…, S. In follow-up work, Romano and Wolf (2016) describe how to compute p-values adjusted for multiple testing, which is a more flexible approach. Having adjusted p-values, one immediately knows which hypotheses to reject for any level α, as opposed to just for a specific level α. In other words, if one were to consider a different level α compared with a prior analysis, one would have to rerun the procedure of Romano and Wolf (2005b) with the new value of α; on the other hand, having adjusted p-values at hand, no new analysis is needed. The
Prior to describing the p-value adjustment algorithm implemented in
As above, suppose we wish to test S hypotheses, using data X. Each hypothesis Hs
is associated with a parameter of interest θs
, an estimator of this parameter

Next consider M resampled data matrices of X, denoted by

These statistics
In case the alternative hypotheses are two-sided of the type

Finally, as above, we will relabel hypotheses in order of significance—but now based on their test statistics ts
instead of their p-values ps
, as was done before by the Holm procedure—such that H
(
1
) refers to the hypothesis with the largest corresponding test statistic [labeled t
(
1
)], and H
(
S
) refers to that with the smallest [labeled t
(
S
)]. In what follows, we denote by

For a given j, we denote by
denotes the maximum value of
Based on the above, the principal stepdown multiple-testing procedure at level α (based on algorithm 3.1 from Romano and Wolf [2016]) can be summarized as follows. For s = 1,…, S, reject H
(
s
) iff t
(
s
) > ĉ(1 − α, 1). Denote by R
1 the number of hypotheses rejected. If R
1 = 0, stop; otherwise, let j = 2. For s = Rj
−
1 + 1,…, S, reject H
(
s
) iff t
(
s
) > ĉ(1 − α, Rj
−
1 + 1).
If no further hypotheses are rejected, stop. Otherwise, denote by Rj
the number of hypotheses rejected so far, and afterward let j = j + 1. Then return to step 3.
As was the case with the procedure of Holm (1979), this correction is a stepdown procedure: ĉ(1 − α, j) is weakly decreasing in j and, as such, the criterion for rejection is more demanding for more significant hypotheses and becomes less demanding for less significant hypotheses. Given that the null distributions based on
The above algorithm leads to a decision whether to reject or not reject for each null hypothesis Hs at a given significance level α. However, additionally and perhaps more conveniently, a multiple-testing-adjusted p-value can be directly computed for each Hs , as described in the algorithm below. This algorithm is a generalization of a resample-based p-value for a single null hypothesis, which can be defined as (Romano and Wolf 2016; Davison and Hinkley 1997, 158).

Note that other definitions exist.
11
To generalize this to a situation where multiple hypotheses are considered,

Either option can be implemented in the Define
For s = 2,…, S, first let
and then enforce monotonicity by defining
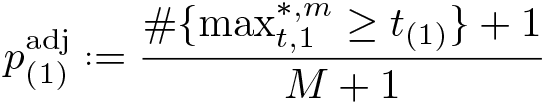


3 The rwolf command
The Romano–Wolf multiple-hypothesis correction is implemented using the following syntax, returning the adjusted p-values described above, as well as the unadjusted p-values according to (6) [or (7), if

where depvars refers to the multiple outcome variables that are being considered. There are two ways for this command to be used. First,
The first of these cases is provided for situations in which a single type of regression model is implemented with a range of outcome variables. In this case,
3.1 Options
Standard options
other_options are any additional options that correspond to the baseline regression model. All options permitted by the indicated method are allowed.
Options specific to cases where resampled estimates are user provided
3.2 Stored results
4 Some examples
4.1 Regression-based examples and performance
We begin by presenting a particularly simple case. Consider the following linear model, in which 10 outcome variables ys
are regressed on a single independent variable,

for observation i. For each observation i, the 10 stochastic error terms

with ρ ≥ 0, and the independent variable of interest,
We consider a series of simulations based on N = 100 observations. Each null hypothesis is that
In the simulation below, each of the 10


Once we have simulated the N × S matrix
The command returns a list of p-values associated with each of the multiple outcomes. The column
The simulated example above provides one example of a multiple-hypothesis correction based upon a known DGP. To examine the performance of the
In these tables, we consider 1) a series of models where all of the β 1 s terms are equal to 0 (presented in panel A of table 1), 2) a series where half of the β 1 s terms are equal to 0 and the other half are equal to 0.5 (presented in panel B of table 1 when considering FWERs and panel A of table 2 when considering power), 14 and 3) a series where all of the β 1 s terms are equal to 0.5 (presented in panel B of table 2). Case 1 is not considered in table 2 given that all null hypotheses are true and so cannot be “correctly rejected”. Similarly, case 3 is not considered in table 1 given that all null hypotheses are false and so the FWER is trivially equal to 0 given that they cannot be “incorrectly rejected”. Across columns, we vary the degree of correlation between outcomes, from ρ = 0 in the first two columns, to ρ = 0.75 in the final two columns. The nominal levels for the FWER are set at α = 0.05 and α = 0.10, respectively.
Simulated error rates

Simulated rejection rates

Here we briefly discuss the performance of the
In panel A of table 1 (where all values for
With the Holm correction, we observe that the FWER is controlled at both the 5% and 10% levels. This is observed regardless of the degree of correlation considered, between ρ = 0 and ρ = 0.75. Similar control is observed with the Romano–Wolf procedure. Indeed, in each case the empirical FWER is very close to the desired nominal rate of 0.05 or 0.10, respectively. In panel B of table 1 (where 5 of the 10 hypotheses should not be rejected), we again observe that the FWER without multiple-hypothesis correction still substantially exceeds desired error rates but is successfully controlled at no more than α with both the Holm and Romano–Wolf procedures.
In table 2, we can examine the relative power of the Holm and Romano–Wolf procedures for rejecting false null hypotheses. In panel A of table 2, we return to the case considered in panel B of table 1, here considering the power of the tests instead. In this setting, the naïve case of no multiple-hypothesis correction allows us to reject a large proportion of false null hypotheses (at the cost of the FWER documented in table 1).
In the case of Holm and Romano–Wolf, we observe relatively similar rates of correct rejection when the correlation between outcomes is 0, but as expected, as the correlation between outcomes grows, the Romano–Wolf procedure substantially improves relative to Holm’s procedure. For example, in the final column of panel A, we reject 59.4% of false null hypotheses using the Romano–Wolf procedure versus only 46.8% using Holm’s procedure, a 27% improvement in rejection rate. A similar pattern is observed in table 2, panel B (where all null hypotheses are false). Initially, when the correlation between outcomes is 0, Holm’s and Romano–Wolf’s procedures have similar power; however, to the degree that ρ increases, the Romano–Wolf procedure becomes relatively more powerful.
In table 2, we consider the relative power of testing procedures for rejecting false null hypotheses with a particular value for β
1
s
, in this case,
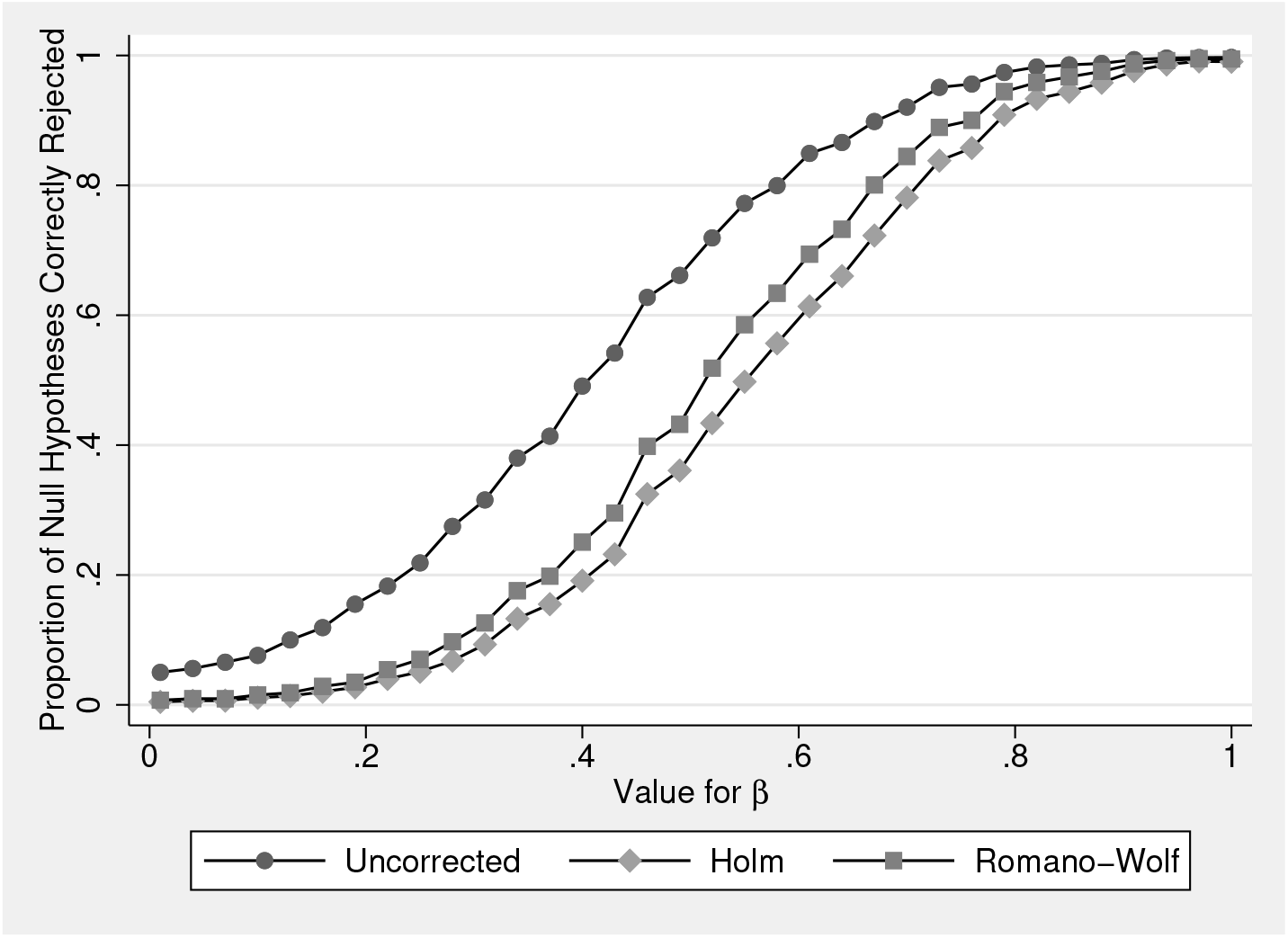
Comparative power to reject false null hypotheses.
For each value of β
1, we run 1,000 simulations, in each case calculating the unadjusted p-values, and the Holm and Romano–Wolf p-values using the
Of interest is the relative performance of Romano–Wolf’s versus Holm’s correction. Here, given that ρ = 0.5, the power of the Romano–Wolf correction dominates the power of the Holm correction across each value for β 1. This difference is particularly notable at values of β 1 between 0.4 and 0.6, and all disappear as β 1 becomes large, implying sufficient power to reject all null hypotheses regardless of the correction procedure. When β 1 = 1, each of the procedures results in rejection rates of around 100%.
The simulated examples based on
We begin with a (default) two-sided test, where we follow the implementation of the two-stage least-squares estimate from the
The setup and output of this Romano–Wolf correction is displayed below. In this example, the p-values from the original IV models are quite low, suggesting evidence against the null that each coefficient on the variable
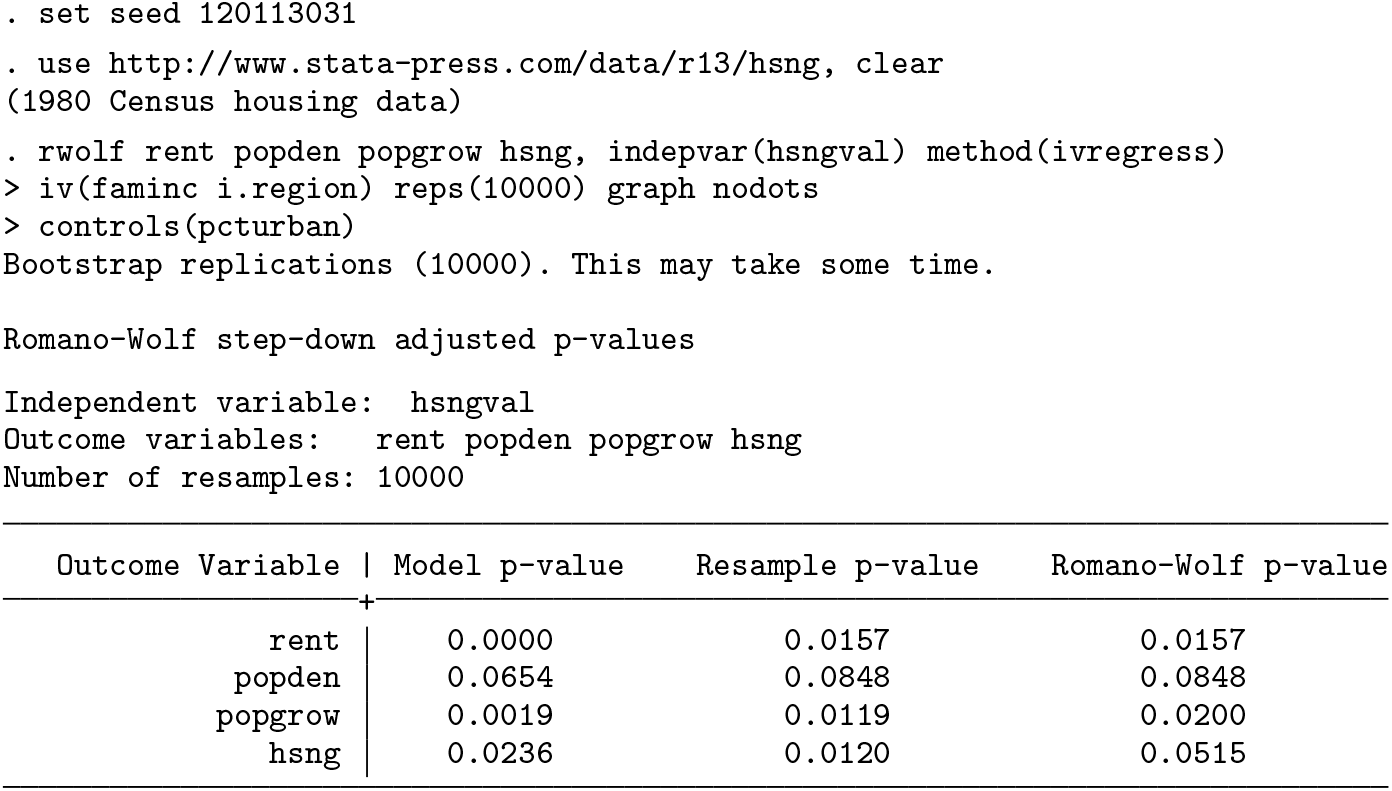
Below, we document the same procedure but here conducting one-sided hypothesis tests. In each case, the null hypothesis in these tests will be of the form H
0 : β
1 ≤ 0, versus the alternative H
1 : β
1 > 0, where β
1 is the coefficient on

In each example, we specified the
In figure 2 panel (a), we display these distributions in the two-sided case. Here the histogram presents the absolute value of each (Studentized) estimate from the bootstrap replications where the null is imposed, and the black dotted line presents an exact half-normal distribution. The actual Studentized value of the regression coefficient is displayed as a solid vertical line. In the top left panel, the first null distribution is considerably more demanding than the theoretical distribution, given that it accumulates the maximum coefficient estimated across each outcome. These null distributions become increasingly less demanding in the top right and bottom left panels because previously tested variables are removed from the pool to form the null distributions. Finally, in the bottom right corner (for the least significant variable), the null distribution is based on bootstrap replications from only this variable, and as such, the null distribution closely approximates the theoretical half-normal distribution.

Null distributions for one- and two-sided tests with IV models.
In figure 2 panel (b), we present the same null distributions but now based on the one-sided tests. Here the histogram documents the maximum values across the multiple variables in each bootstrap replication, and the black dotted line presents the theoretical normal distribution. Once again, when we consider outcomes for which more significant relationships are observed, the empirical distribution used to calculate the corrected p-value is considerably more demanding than the black dotted distribution, which would be used under no correction and a normality assumption. In the case of the least significant variable (
4.2 A nonstandard Studentized example
Each previous example has been based on the simple
We use an example and data documented in Westfall and Young (1993), which was also previously used to demonstrate the effectiveness of the Romano–Wolf procedure in Romano and Wolf (2005a). Although we refer to this as a nonstandard example, it is only nonstandard in the way it interacts with the syntax of
This example considers pairwise correlations between state-average standardized Scholastic Aptitude Test (SAT) scores and several other state-level measures for the 48 mainland U.S. states plus Hawaii. These data—consisting simply of state-level measures of several variables of interest—are provided in table 6.4 of Westfall and Young (1993, 197) as well as in the replication materials for this article. The variables considered are
In this case, the statistics of interest refer to simple correlations between pairs of variables of interest, and p-values will be corrected for the fact that we are testing 10 hypotheses. To construct null distributions following (4) and (5), the

To generate the various components that

A bootstrap procedure is then implemented based on 5,000 resamples. We initially expand the dataset to have 5,000 observations to store each of the bootstrap estimates; however, prior to calculating the correlations and standard errors in each replicate, we work only with the 49 state-level observations with SAT data. Each replicate is implemented in the main

Once we have stored the original estimates plus their standard errors and have variables containing resampled estimates along with their resampled standard errors, we can simply request the multiple-hypothesis correction from
We pass to

In this nonstandard implementation, no
In figure 3, we present the graph of null distributions, based on (5), for each hypothesis. As implied by the multiple-hypothesis testing algorithm, the null distributions become less demanding while moving from the most significant variable (top left-hand panel) to the least significant variable (left-hand panel in the final row).

Null distributions and original t statistics from the SAT-deviation data.
5 Conclusions
In this article, we described the Romano–Wolf multiple-hypothesis correction, a flexible and versatile procedure to (asymptotically) control the FWER when testing a family of hypotheses at the same time, which occurs frequently in applied work in economics, finance, and many other fields. The article documented the
We documented the syntax of the command and provided several illustrative examples, with both simulated data and real data. We documented how this command can be easily used in cases where multiple dependent variables are regressed on a single independent variable (in a broad class of regression models). In this case, implementing the Romano–Wolf multiple-hypothesis correction in Stata is a one-line endeavor, because the command interacts directly with Stata’s estimation commands to implement the p-value adjustment. We also documented a more complex case, where the statistics of interest are not based on regression models and where multiple independent variables are also considered.
We envision this code being used in a variety of circumstances where multiplehypothesis testing occurs, avoiding the well-known and undesirable pitfalls of the phenomenon interchangeably called “data mining”, “cherry picking”, or “p-hacking”.
Supplemental Material
Supplemental Material, st0618 - The Romano–Wolf multiple-hypothesis correction in Stata
Supplemental Material, st0618 for The Romano–Wolf multiple-hypothesis correction in Stata by Damian Clarke, Joseph P. Romano and Michael Wolf in The Stata Journal
Footnotes
6 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
A Westfall and Young’s “Free Stepdown Resampling Method”
For background related to the multiple-hypothesis testing procedures discussed in section 2 of this article, we describe the stepdown resampling procedure of Westfall and Young (1993) here. This procedure is described as algorithm 2.8 in ![]() , 66–67), and we largely follow their notation but adapt it to fit the notation laid out in section 2 of this article.
, 66–67), and we largely follow their notation but adapt it to fit the notation laid out in section 2 of this article.
This procedure begins with S multiple hypotheses, each associated with its own (unadjusted) p-value. These p-values are labeled such that p
1 ≤ p
2 ≤ · · · ≤ pS
. It then proceeds as described below. Begin with a counter, COUNT
s
= 0 for each s = 1,…, S. Using a bootstrap sample, generate a vector of analogous p-values,. Define the successive minimums:
If Repeat steps 2–4 N times, and compute Enforce monotonicity using successive maximization:
The adjusted p-values
B Regression-based examples
Below, we replicate the example from section 4.2, except that here we estimate the regressions rather than calculating correlations directly (see, for example, line 2 of the first loop, and line 8 of the final principal loop). Given that t statistics calculated from each regression are identical to those calculated using the estimate of the correlation and its standard error in (9), the Studentization can be similarly performed by regression. This is documented below, where, apart from the regressions themselves, all other details follow those described in section 4.2.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.