
Abstract
In this article, we describe the use of
1 Introduction
There are many settings where a researcher would like to understand the mechanism that underlies an estimated effect of a treatment T on an outcome Y . For example, Becker and Woessmann (2009) are interested in the Weber hypothesis that religion, specifically Protestantism, affects economic growth. Because Protestantism promoted reading of the Bible, 1 they establish that an underlying mechanism M of the effect of religion on economic growth works through human capital accumulation, especially literacy. Given that the prevalence of religion across regions is likely not random, they introduce an instrumental variable (IV) and show that Protestantism caused higher literacy rates and thus economic growth. They derive plausible bounds for the range of a mediation effect but lack a formal framework to causally estimate the indirect effect of religion on economic growth that works through literacy.
Such an exercise of unpacking mechanisms is called mediation analysis, where a treatment T and one of its outcomes M, that is, the mediator, jointly cause a final outcome of interest Y . Mediation analysis has long been used in settings where T can be assumed to be randomly assigned. However, when T is systematically nonrandom and therefore needs to be instrumented by a variable Z,
2
there has been a lack of frameworks for undertaking mediation analysis in such IV settings without having separate instruments for both T and M.
3
The command
Table 1 illustrates the identification challenge described above. As a starting point, we show the standard IV estimations of the causal effect of T on M (model I) and the causal effect of T on Y (model II). In model I, T is considered endogenous (that is,
The identification problem of mediation analysis with IV


NOTES: (a) Model I is the standard IV model, which enables the identification of the causal effect of T on M. Model II is the standard IV model that enables the identification of the causal effects of T on Y . Model III is the IV Mediation Model with an instrumental variable Z. (b) Panel A gives the graphical representation of the models. Panel B presents the non-parametric structural equations of each model. Conditioning variables are suppressed for sake of notational simplicity. We use ∐ to denote statistical independence.
To identify what fraction of the TE is explained by the indirect effect, we have to perform a mediation analysis that decomposes the TE of T on Y into 1) the mediated “indirect” effect of T on Y that operates through M and 2) the residual “direct” effect that does not work through M. Model III of table 1 shows the main identification challenge in combining the two IV models into a general mediation model. Equations M = fM
(T, εM
) and Y = fY
(T, M, εY
) imply that T causes Y indirectly through M as well as directly, which is graphically represented by the arrow directly linking T to Y . In a regression of Y on both T and M, there are two potentially endogenous regressors (that is,
To overcome the underidentification problem, we do not assume away endogeneity in any of the key relationships in model III (
Dippel et al. (2020) show that this assumption alone is sufficient to unpack the causal channels in model III, therefore allowing us to identify the extent to which T causes Y through M. Under linearity, the resulting identification framework is straightforward to estimate using three separate two-stage least squares (2SLS) regressions; these estimate i) the effect of T on M, ii) the effect of T on Y , and iii) the effect of M on Y conditional on T .
In the following section, we will briefly explain the underlying econometric theory before we explain the estimation procedure in section 3. There, we also provide further guidance on the interpretation of results and issues regarding weak identification that are typical concerns for applied researchers. Section 4 describes the syntax and options of
2 Causal mediation analysis in IV models
Under linearity and with an instrument Z, the causal relations in model III in table 1 can be written as




Equations (1)
–(4) can be compactly expressed as

Equation (6) presents the covariance matrix ΣX of observed variables
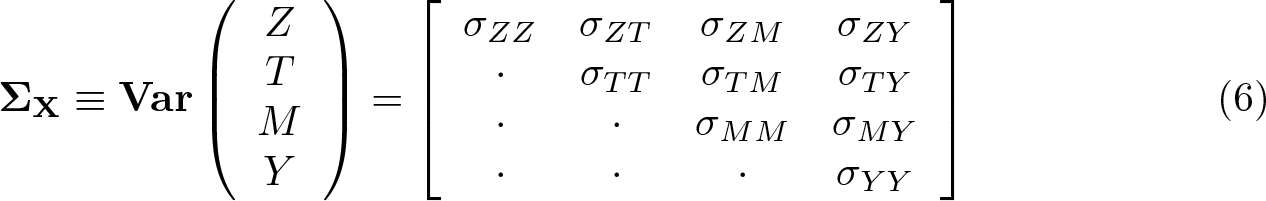
Let Σ ε denote the covariance matrix of unobserved error terms ε. Because Z is an IV, it implies that εZ is statistically independent of εT , εM , and εY . Thus, Σ ε is given by
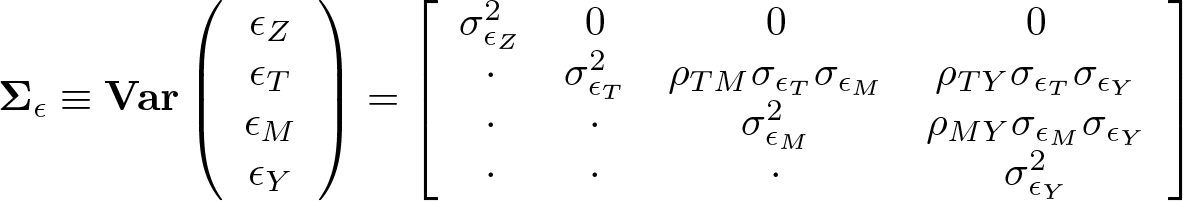
The identifying assumption in Dippel et al. (2020) is that T is endogenous in a regression of Y on T , but endogeneity cannot arise from confounders that jointly influence T and Y , only from confounders that jointly affect T and M (for example, Protestantism and literacy in Becker and Woessmann [2009]). The framework also allows for confounders that jointly influence M and Y (for example, literacy and economic growth in Becker and Woessmann [2009]). Formally, the identifying assumption is ρTY = 0 in Σ ε , while allowing ρTM ≠ 0 and ρMY ≠ 0.
In section 5.1, we describe how to generate a simulated dataset with these dependent relations.
3 Estimation
3.1 Estimation procedure
The estimation equations to identify all linear coefficients are associated with well-known econometric estimators as follows (control variables are suppressed for notational simplicity and without loss of generality):
1. Parameter
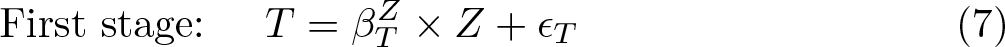

where 2. Dippel et al. (2020) show that the identifying assumption ρTY
= 0 yields a new exclusion restriction, which allows for the use of Z as an instrument for M when conditioned on T (but not unconditionally). This implies that


where
The estimation procedure associated with (7) and (8) is the standard IV approach. By contrast, the estimation procedure associated with (9) and (10) is novel and a property of the framework laid out in Dippel et al. (2020).
There are two first stages here in (7) and (9) for which
In section 5.1, we compare the unbiased estimates resulting from (7)–(10) with the associated OLS estimates.
3.2 Interpretation
There is another explicit link between (7)–(10) and the direct estimation of the TE in model II of table 1. Model II is obtained from model III by substituting (8) into (10):

Equation (11) shows that the direct estimate of TE produced by model II is algebraically identical to the product of estimates
It is also worth noting that, in the mediation framework, either
3.3 Weak identification with two first-stage regressions
Applied researchers are now well aware of the bias introduced by weak identification in an IV setting (Bound, Jaeger, and Baker 1995). A rule of thumb is that an F test of the excluded instrument(s) in the first stage should yield an F statistic of 10 or more (Stock and Yogo 2005). How does this apply to the IV mediation setting with two first stages? Currently, there is no theory to guide applied researchers. Instead, we apply the code from section 5.1 to simulate the behavior of the estimator under different instrument strengths in the treatment and the mediator first stages. This is done by varying the amount of noise in εT and εY .
Figure 1 plots the coefficient values of the total, direct, and indirect effects over different values of the first-stage F statistic. The left panel manipulates the strength of the instrument in the treatment first stage, and the right panel manipulates that in the mediation first stage. The instrument is only ever weak in one of the two first stages but not in both at the same time. Samples were simulated according to (1)–(4) with 1,000 observations for each value of the error variance. The values increase from 1 to 15 in increments of 0.5. In the example, the true values of the direct and indirect effects are both 1, summing up to a true TE of 2. The

Coefficient values under differing IV strengths in either first stage. NOTE: The left panel simulated data for different values of Var(εT ), and the right simulated data for different values of Var(εY ) ranging from 1 to 15. The value of Var(εT ) increases in steps of 0.5, and at each step, 100 random samples were drawn according to (1)–(4) with 1,000 observations. Both panels show binned scatter plots of coefficient values of the total, direct, and indirect effects over different values of the corresponding first-stage F statistics where the strength of the instrument was manipulated. The true TE is 2, and the true direct and indirect effects are equal to 1.
The left panel shows that, as the treatment first-stage F statistic approaches the rule of thumb value of 10, all effects begin to center on their true values. This is also the case for the right panel, however, here the direct effect takes longer to center on its true value. It only begins to center on the true value from a mediation first-stage F statistic of 30. A conservative approach would therefore require a stronger instrument in the mediator first stage to accurately identify all three effects. If interest only lies on the indirect effect, the commonly used approximation rule for a reasonably strong instrument seems applicable.
4 The ivmediate command
4.1 Syntax
4.2 Description
4.3 Options
the IV regression of Y on T (instrumented with Z) the IV regression of M on T (instrumented with Z), for which the first-stage F statistic is reported as the IV regression of Y on M (instrumented with Z) and controlling for T, for which the first-stage F statistic is reported as
The TE is the coefficient on T in the first table; the direct effect is the coefficient on T in the third table; the indirect effect is the product of the coefficient on T in the second table and the coefficient on M in the third. The mediation effect as percentage of the TE is therefore the indirect effect divided by the TE times 100.
4.4 Stored results

Empirical example
5.1 Simulation exercise
A simulated dataset with the assumed dependent relations can be straightforwardly generated in the following way:
Separately generate error terms εT
and εY
that are normally distributed with mean 0 and variance 1, N(0, 1). These are statistically independent, that is, εT
∐ εY
. Let error term εM
be defined as
The correlation between εM
and εT
is g
It is instructive to investigate the bias generated by a misspecified model where T and M are assumed to be exogenous, that is, the mutual independence of εT
, εM
, and εY
is wrongly assumed. Let the data be generated by (1)–(4) and the model coefficients be normalized to equal 1, that is,
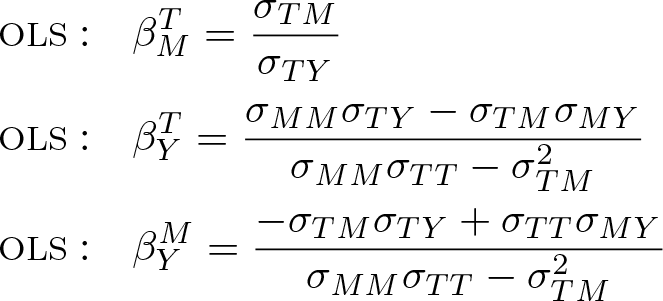
While the true parameters are set to be 1, the OLS estimators may range from 0 to 2 depending on the error correlations. Because a high ω implies pronounced bias in the relation between T and M (a high ρTM
), the OLS estimate of

Given the model parameters, the TE of
5.2 Applied example using the Becker and Woessmann (2009) data
The example below uses data from Becker and Woessmann (2009), who estimate the effect of Protestantism on economic prosperity in Prussian counties. To obtain exogenous variation in the share of Protestants in these counties, they used the fact that Protestantism spread concentrically around Wittenberg, the city where Martin Luther taught and preached. Following their example, we use distance to Wittenberg (
According to Becker and Woessmann (2009), Protestantism promoted reading of the Bible, which led to human capital accumulation and therefore promoted economic development. They are interested in estimating

though they note that the “problem with such a model is that not only Protestantism but also literacy may be endogenous in this setting” (p. 570). Because they have no additional instrument for literacy, they use different types of bounding exercises using estimates from previous literature on the returns to education (see section VI.C in the original study). Using

As in the original study, we condition on further covariates in the estimation of (12), which are the share of Jewish population, female population, individuals aged below 10, the share of population of Prussian origin, average household size, population size of the county, the percentage population growth between 1867 and 1871, and the share of the population with missing information on literacy. 7
The TE estimates that every 1 percentage point increase in the share of Protestants increases per capita income tax revenues by 0.83 Marks. Under the typical IV assumptions, this effect is causal. The direct effect estimates that only 0.08 Marks of this increase are because of Protestantism itself and it is not statistically significant. However, the indirect effect estimates that 0.75 Marks of this increase are caused by literacy as a mediating factor. This implies that literacy explains 90% of the TE of Protestantism on economic outcomes. This is in line with the findings by Becker and Woessmann (2009), who conclude that “Protestants’ higher literacy can account for roughly the whole gap in economic outcomes between the two denominations [Catholics and Protestants]” (p. 576).
Supplemental Material
Supplemental Material, st0611 - Causal mediation analysis in instrumental-variables regressions
Supplemental Material, st0611 for Causal mediation analysis in instrumental-variables regressions by Christian Dippel, Andreas Ferrara and Stephan Heblich in The Stata Journal
Footnotes
6 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.