
Abstract
In this article, I propose a new test for power-law behavior. The statistical test,
1 Introduction
A continuous random variable is said to have a power-law (PWL) behavior if it has a probability density of the form

where α > 0 is the shape parameter that determines the tail of the distribution and µ > 0 is the location parameter where the “heavy tail” starts. 1 The law given above is due to Pareto (1897), but in the particular case of α = 1, it is occasionally named after Zipf (1949).
The surveys by Brock (1999), Mitzenmacher (2004), and Newman (2005) make clear that the assumption of PWL behavior has been routinely made over the years by many authors in a number of disciplines. Also, in most of that literature, the use of PWL distributions is typically defended by simply pointing out the approximate linear nature of a doubly logarithmic plot or by reporting a simple regression. However, as noted by, for example, Clauset, Shalizi, and Newman (2009) and Urzúa (2011), those arguments are flawed.
Fortunately, there are also in the literature better procedures to test for PWL behavior. The most common, which can be traced back at least to Quandt (1964), is to estimate, for a given dataset, not only the Paretian law but also some competing alternative distributions. Once those estimations are made, the resulting fits are ranked according to some statistical criteria. For instance, in their rather influential article on the empirics of PWL behavior, Clauset, Shalizi, and Newman (2009) suggest as alternatives to that distribution four others: the lognormal, the exponential, the stretched exponential, and the PWL with cutoff.
Other testing procedures have been proposed as well. In particular, using a methodology that is quite common in the econometrics literature, Urzúa (2000) presents a test for Zipf’s law that is derived after considering a more general distribution that nests the density given in (1). Afterward, a locally optimal test for Zipf’s law is derived by means of Rao’s (1948) score test, also known in econometrics as the Lagrange multiplier test. 2
The more general density posited in that article is of the form

where, aside from the two parameters introduced earlier, σ > 0 is the scale parameter. This distribution is known in the literature by several names, but here it will be simply called Pareto (II), following the terminology of Arnold (see the reference in Arnold [2015]); likewise, Pareto’s basic law, given in (1), will be called from now on Pareto (I).
Using the Pareto (II) distribution, Urzúa (2000) derives a test for Zipf’s law by testing the statistical hypothesis H 0 : σ = µ, α = 1. Rao’s score test is used because it requires estimation only under the null hypothesis. Note that if the null is reduced to H 0 : σ = µ, then, as Goerlich (2013) shows, one can even produce a test for the Pareto (I) distribution. Nevertheless, that test would not be appropriate in the case of testing for PWL behavior, because, as I will show in the next section, the densities (1) and (2.1) have a similar heavy-tail behavior.
2 A test for PWL distributions
Following again the terminology in Arnold (2015), this article assumes that the alternatives to the Pareto (I) distribution belong more generally to the Pareto (IV) family, whose density is given by

where γ > 0 is the inequality parameter. Note that (2.1) is obtained from (2.1) when σ = µ and γ = 1 and that the Pareto (IV) distribution function is given by

For purposes of this article, the parameter µ, which is present in the three densities given above, is assumed to be fixed by statistical design. This assumption is quite reasonable from a practical point of view, aside from the fact that it is theoretically required. 3 Thus, after defining w = x − µ, we can rewrite the Pareto (IV) density in a more compact form as

Note that the tail behavior of a Pareto (IV) distribution is determined not only by α, as is the case for the Pareto (I) and (II) distributions, but also by the new parameter γ. This is so because, using L’Hôpital’s rule and (2),

Thus, the Pareto (IV) family can be approximated, on the right tail, by w−α/γ . This implies that, for a given PWL parameter α, the tail of the distribution can become as short as desired by reducing the value of γ from one to some small but positive value. Likewise, for a given α, the tail can be made even heavier by setting the value of γ greater than one.
Let θ = (θ
1
, θ
2
, θ
3) = (σ, γ, α) be the vector of parameters, and let
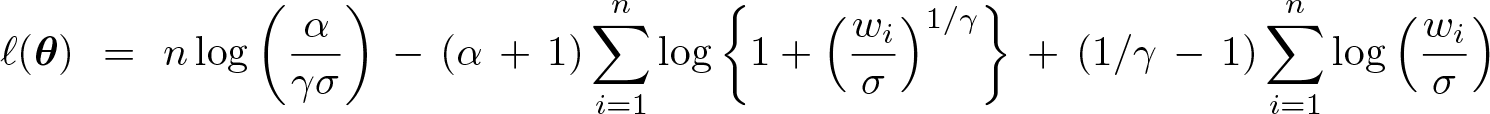
For later use, it is necessary to find its gradient and the expected value of its Hessian. The elements of the gradient are given by



The second-order derivatives are also easy to find, but they are omitted here for lack of space. A less obvious task is to calculate their expected values. Fortunately, they have already been derived in the meticulous article by Brazauskas (2002). Thus, the elements of the information matrix

are also known.
The stage is now set to devise a test for the PWL distribution. This is accomplished here by employing Rao’s score test in the case of the null hypothesis H 0 : σ = µ, γ = 1. As a first step to that end, we find the restricted maximum-likelihood estimate for the nuisance parameter α by equating (8) to zero and replacing wi with xi − µ:

Consequently, the restricted score vector is given by


Before presenting the corresponding information matrix, I need to introduce some notation. Let

Finally, keeping in mind that

Under the null, PWL is asymptotically distributed as a chi-squared with two degrees of freedom. The statistic can be readily computed using the
Note that the program automatically drops any xi ≤ µ.
How well does the test statistic behave in the case of small samples? Table 1 presents evidence that the asymptotic critical values can be safely used when 1 ≤ α ≤ 3, the typical range for the shape parameter, and n ≥ 100, as is the case for most applications. Otherwise, the significance points in table 1 can be used as approximations, or for sharper results, the
Significance points for PWL

NOTE: Simulations using 100,000 replications.
3 Applications
We now exemplify the use of the PWL test in the case of four interesting datasets studied by Newman (2005) and Clauset, Shalizi, and Newman (2009).
4
They are listed in table 2, together with seven values associated with each of them. Regarding the columns, note that although x
max is clearly the maximum value in each sample,
Tests of PWL behavior

The first dataset in table 2 refers to the number of times that unique words occur in a classical piece of English literature, the novel Moby Dick by Herman Melville. Our statistic can be computed with the command
The second case corresponds to the human populations of U.S. cities as recorded by the U.S. Census Bureau in 2000. As shown in the table, and according to the proposed test, there is convincing evidence of PWL behavior. This result is in line with most of the literature on the size of cities. Note also that this finding does not contradict the claim in Urzúa (2000) that U.S. cities do not follow Zipf’s law, because the latter is just an extreme case of a PWL distribution (when α = 1).
The third sample is made of the frequencies of U.S. family names in the 1990 U.S. Census. As reported in the table, there is moderate evidence of PWL behavior, because the null hypothesis would not be rejected at the typical significance levels. A very similar finding is reported by Clauset, Shalizi, and Newman (2009).
Finally, the fourth sample listed in table 2 is made of the peak gamma-ray intensity of solar flares, measured from orbit between 1980 and 1989 (see Newman [2005] for more details). Given the p-value reported in the table, there is good evidence of PWL behavior in this case. Note that a theoretical model that renders precisely that behavior is due to Lu and Hamilton (1991).
4 Concluding remark
The Pareto (IV) distribution used in this article belongs to the Feller–Pareto family (see Arnold [2015]), whose general density is of the form
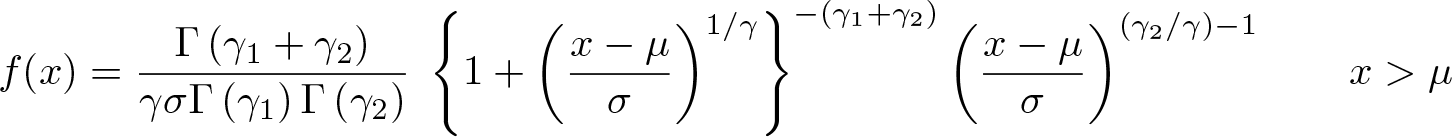
where γ 2 > 0 and, to use the notation given earlier, γ 1 = α. Thus, following the same procedure given before, we can derive a new, more general test statistic. But because of its algebraic intricacy, it is not presented here. In any case, the gain from that generalization is not totally apparent, because, as can be checked in the same way as in (3), the Feller–Pareto and Pareto (IV) distributions have similar tail behavior.
Supplemental Material
Supplemental Material, st0610 - A simple test for power-law behavior
Supplemental Material, st0610 for A simple test for power-law behavior by Carlos M. Urzúa in The Stata Journal
Footnotes
5 Acknowledgments
I appreciate the very helpful comments made by a referee on an earlier version of the article. I also thank Erick Rosas for his research assistance.
6 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.