
Abstract
In this article, we introduce a new command,
Keywords
1 Introduction
In this article, we introduce a new command,
Stochastic frontier models (Aigner, Lovell, and Schmidt 1977; Meeusen and van den Broeck 1977) are central to the identification of inefficiencies in the production (and production costs) of continuously distributed outputs. In labor, industrial, and health economics, production frontiers have also been adopted to explain deviations from maximum or minimum levels of nontangible and nonpecuniary outcomes. However, in these latter domains, outcomes are often measured as counts (for example, the number of patents obtained by a firm or the number of infant deaths in a region). Although these latter fields of inquiry have not emphasized the idea of inefficiency in the “production” of nontangible and nonpecuniary outcomes, recent contributions (for example, Fé [2013]; Fé and Hofler [2013]) suggest that inefficiencies are also present in these domains.
The need for specific count-data models for stochastic frontiers arises because this results in more efficient estimation (for example, Greene [2018]) and, more critically, inefficiency is typically not nonparametrically identified from data alone. Therefore, researchers have to make specific assumptions regarding the distribution of inefficiency in the sample or the population. These assumptions define the class of admissible distribution underlying outcomes. Standard continuous data models attribute any negative (positive) skewness in the sample to inefficiencies in the production of economic goods (bads). However, the distributions of discrete outcomes are typically skewed even in the absence of inefficiencies (for example, the Poisson distribution), and the sign of skewness is generally independent of whether one is studying an economic good or an economic bad. Thus, standard stochastic frontier models can fail to detect any inefficiency in production when the outcome of interest is a count—even when the underlying inefficiency is substantial.
The core count-data stochastic frontier model is based on a mixed Poisson distribution with a log-half-normal mixing parameter (or a Poisson log-half-normal [PHN] in the parlance of Fé and Hofler [2013]). Although the motivation behind this model was the estimation of stochastic frontiers under discrete valued outcomes, the PHN can be used for modeling underreported counts as well as overreported counts. These situations are pervasive when studying worker’s absenteeism (Winkelmann 1996), consumer data (Fader and Hardie 2000), drug abuse (Brookoff, Campbell, and Shaw 1993), or traffic accidents (Alsop and Langley 2001), among others. Among the models traditionally used for modeling these events, the beta-binomial and Poisson-lognormal models have been widely used. The PHN is a complement to these specifications.
The code presented here extends the catalog of Stata commands pertaining to the stochastic frontier literature, including the original Stata commands
2 Methods
To introduce the PHN model, we adopt the stochastic frontier terminology in Fé and Hofler (2013). The relationship to underreported or overreported count models will be apparent from the context. There is a sample of i = 1,…, n units containing data on a discrete outcome of interest yi ∊ {0, 1, 2,…}. The mean production frontier of y is determined by the mapping

where

Because we are modeling nonnegative count data, we transform the last equation to

Following convention, we assume that y has a Poisson distribution conditional on a set of regressors,

This density has the advantage of allowing some flexibility, thanks to its scale parameter. It also leads to a model whose first-order moments are well defined (a property that is not shared by some popular distributions). 2
If f(ε) is half normal, we can write ε = |u|, where u has a normal distribution. With this notation, and letting h(

where expectations are taken with respect to the standard normal distribution. Fé and Hofler (2013) provide expressions for the moments of f(ε) when this follows a halfnormal density function, as well as expressions for the conditional mean and variance of y. The PHN distribution does not have a closed-form expression; however, the integral in (2) can be approximated by simulation. Specifically, Fé and Hofler (2013) advocate combining maximum simulated likelihood (MSL) estimation of the PHN model with Halton sequences (Gentle 2003). Applying simulation, we approximate the conditional distribution of yi (for i = 1,…, n) by the sum

where θ′ = (β′, σ) and sh are the terms of a Halton sequence, possibly randomized.
The infeasible log likelihood

where
Tests of hypotheses can rely on the Wald score likelihood-ratio trinity. Testing the null hypothesis of no inefficiency is of particular interest. The null hypothesis would be

in which case PHN collapses to a standard Poisson model. A formal test can be computed via a likelihood ratio comparing the resulting value with the quantiles of a χ1 2 distribution.
2.1 Estimating cross-sectional inefficiency
Although the parameters of the frontier are of interest in themselves, the ultimate goal of most stochastic frontier analyses is to obtain approximate efficiency scores (that is, measures of the deviations away from either maximum or minimum values of the outcome) for each individual in the sample. Following Jondrow et al. (1982) cross-sectional inefficiency scores, we can estimate v = exp(±|u|) via E(v|y,

so that

The latter expression does not have a closed form. However, we may still approximate the relevant integral via simulation. The simulated E(v|y,

Two remarks are important here. First, the distributions of v and
Second, in applications, the scores depend critically on the term Poisson{exp(
3 The sfcount command
3.1 Syntax
where
3.2 Options

The default is
3.3 Cross-sectional estimates of inefficiency
The command automatically generates a variable named
3.4 Example: Stochastic frontier
For this example, we generated 1,000 observations from a PHN distribution with mean exp(1 + x 1 + x 2 − v), where xj ∼ uniform[0, 1] and v has a half-normal distribution with σ = 1 (the code to generate the data appears in the discussion of the Monte Carlo simulation below). This yielded the following output:

The output follows standard Stata convention. The first block of results,

The variable
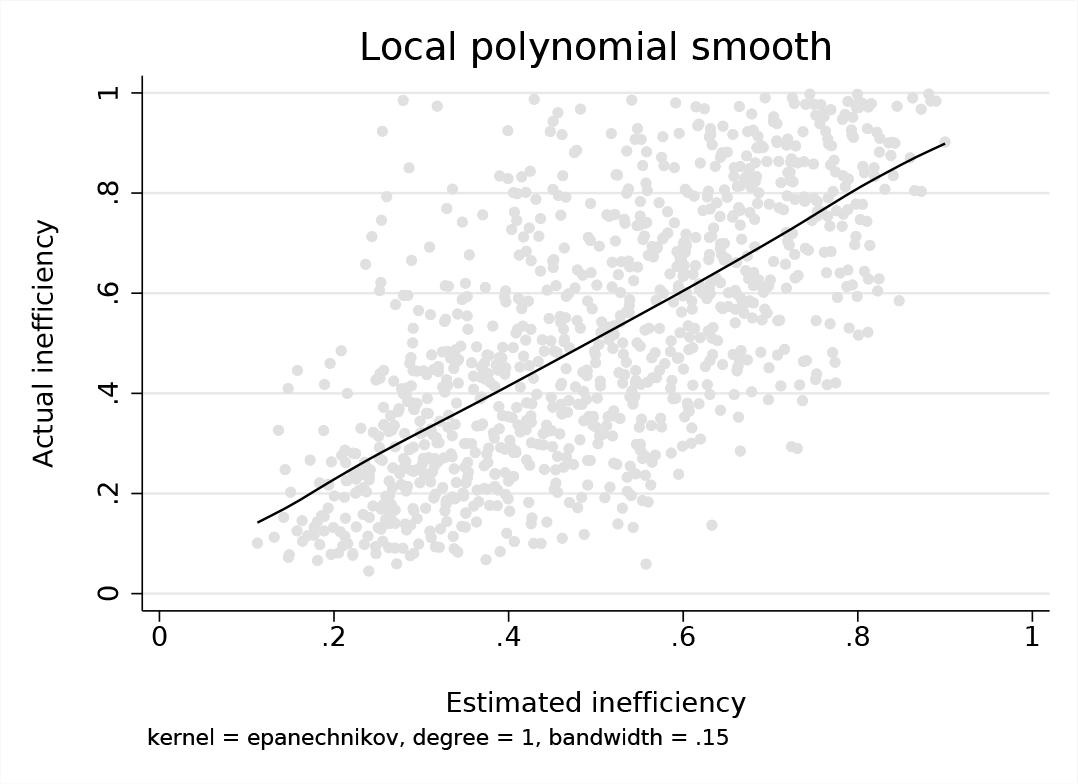
Real versus estimated cross-sectional inefficiency
4 Monte Carlo simulation
To verify the properties of the method and the robustness of the software, we run a Monte Carlo simulation. We drew samples of 100 observations from a PHN model with conditional mean exp(1+x
1 +x
2 −σv), where xj ∼ uniform[0, 1] and v has a half-normal distribution with σ ∊ {0.5, 1, 2}. We estimated the parameters of this model 500 times. We wrote a short ado-file,

Here
What would occur if the standard normal–half-normal model in Aigner, Lovell, and Schmidt (1977) were fit to these data instead? We illustrate the situation through a simulation for both the cost and production frontier cases. We maintain the same design but we will focus on the case σ = 1 for simplicity. Following convention in Aigner, Lovell, and Schmidt (1977), we fit the model

where now, u is the inefficiency term (distributed half-normal) and v is the idiosyncratic, zero-mean error term. The case +u corresponds to the cost function, whereas the case −u corresponds to the production frontier. The code to run this simulation is similar to

The critical quantities in the simulation are

In this case, maximum likelihood failed to converge in two replications. As with the production frontier case, the parameter λ is imprecisely estimated (because all variation tends to be attributed to inefficiency). Yet, paradoxically, the significance of the inefficiency term is rejected only about 38% of the time. The critical aspect of this result is that although the distribution of log Y has the right type of skewness (positive), its magnitude is very small; therefore, the cost stochastic frontier model fails to identify any inefficiency, even though this is prevalent in the data.
An even more problematic example arises when we let σ = 3 and try to estimate a production frontier. Here the skewness of log Y is positive, which presents a violation of one of the assumptions underlying the continuous-data stochastic frontier model. In this instance, the latter method fails to detect any inefficiency at all:

As seen from the above results, the likelihood-ratio test rejects the null hypothesis at the nominal 5% level, whereas λ remains imprecisely estimated.
In summary, the continuous-data stochastic frontier model can be problematic in practice when data are coming from the PHN specification.
5 Example: The distribution of infant deaths in England
We next illustrate the use of the
Infant deaths have a large opportunity cost for societies and constitute a marker of the overall health status of a population. Commonly cited risk factors are parental risk behavior, pollution, economic deprivation, and the quality of health providers, although a large proportion of infant deaths are not attributable to any specific cause (and are cataloged as sudden infant death syndrome). It is unclear, however, if the latter deaths still show systematic variation across different areas even after accounting for the effect of measurable determinants of infant deaths. The PHN can help us to detect which areas overreport infant deaths conditional on the area’s characteristics (that is, which areas are inefficient in the production of infant deaths).
To illustrate the workings of the PHN when addressing this question, we downloaded data on infant deaths by local area for the years 2015 and 2016 from the website of the UK Office for National Statistics. We complemented these data with information on local area characteristics from the 2011 UK Census. The focus of the analysis in this exercise is socioeconomic status and air quality. Socioeconomic status has been shown to correlate with health and wealth. Air pollutants can induce respiratory disease (including bronchitis, pneumonia, allergies, or asthma). Among these pollutants, nitrogen oxides (by-products of fuel consumption and the production of electricity) are thought to be important determinants of respiratory diseases.
We proxy each area’s socioeconomic status with, first, the number of people claiming income benefits per 1,000 of the population and, second, the area’s employment rate. Low birthweight is a risk factor for infant mortality; therefore, in our model we also incorporate the percentage of babies born at a gestational age of greater than or equal to 37 weeks and with a birthweight of less than 2,500g. Our indicator of air quality is the area’s average nitrogen oxide emissions intensity score, NO x . This is an 8-point scale with higher scores indicating higher emissions. We found a few discrepancies between the names and geographic boundaries in the 2011 UK Census and the Office for National Statistics’ most recent data files containing the counts of infant deaths. Given the limited scope of this example, we opted to discard those areas for which data on the covariates were not available for that reason. This leaves us with full data for 309 local areas. For the purposes of this analysis, we pooled the 2015 and 2016 data, while areas’ characteristics were imputed from the 2011 Census.
Descriptive statistics of our limited sample are provided in table 1. The average number of deaths across England was 6.9; however, the distribution is skewed, with a long right tail, as can be seen in figure 2 (the maximum number of deaths observed was 62, in the city of Manchester; note that London has been disaggregated in 31 subareas). The average population in each area is 139,680 inhabitants, whereas the average proportion of underweight births is 7.2%. On average, 12.9% of the population was claiming income benefits, whereas the average employment rate was 77%. The average NO x score in the sample was 4.1. However, variation is vast, ranging from 1.1 to 8.
Descriptive statistics


Distribution of infant deaths in England. Years 2015 and 2016.
Before undertaking our analysis, and in view of the results presented in section 4, we studied the empirical distribution of the logarithm of the count of infant deaths. This variable would be sitting at the core of any stochastic frontier analysis using the benchmark continuous-data models (for example, the normal–half-normal model). The mean of this variable is based on 584 observations instead of 618 (5.5% of the areas report 0 deaths) and equals 1.642. Importantly, its skewness equals −0.0444. Parametric cost stochastic frontier models, however, expect the dependent variable to exhibit positive skewness. Indeed, the distribution of the log-deaths variable does not seem to be skewed at all, and a standard test of normality based on the third and fourth moments of the variable did not reject the null hypothesis (
Having discarded the continuous-data stochastic frontier model, we proceeded to fit a battery of PHN models under nested conditioning sets. Table 2 presents the estimated coefficients of these models. As expected, population size is an important determinant of infant deaths, with larger populations seeing a higher number of deaths. Importantly, we observe that socioeconomic status is negatively associated with infant deaths. Specifically, higher employment rates are strongly associated with a lower count of deaths; however, we found that income benefits and infant deaths are negatively correlated. However, the significance of this contradictory result is sensitive to the structure of the model, which casts some doubts about the reliability of this finding. We did not find any significant association between low birthweight and infant deaths. The most striking result, however, is the very strong association between air pollution and infant deaths. Specifically, higher levels of nitrogen oxides are associated with higher infant deaths.
PHN model (conditional mean)

NOTES: t statistics in parentheses.
∗ p < 0.05, ∗∗ p < 0.01, ∗∗∗ p < 0.001
All models except (2) return a statistically significant log σ, which suggests that there is substantial “inefficiency” in the sample in the form of higher levels of deaths given the levels predicted by our model. Table 3 summarizes the estimated inefficiency in each of the nine constituent areas. The average value of νb for the whole sample is 1.9. There is substantial variation across regions. Inefficiency is lowest in the West Midlands (1.8). However, while the average estimated inefficiency score for most other regions sits at 1.8–1.9, the estimated inefficiency score for Yorkshire and the Humber is 2.3. Yorkshire and the Humber has the second-largest employment rate in the sample and the second-lowest NO x emissions score; however, it has the relatively highest level of benefit claimants and underweight births. Given the prominence of employment rate and NO x scores in our model, it would appear that Yorkshire is underperforming compared with other equally well-off areas of England. In particular, this area seems to exhibit levels of infant death that more than double their predicted levels, given the area’s socioeconomic and environmental credentials.
Inefficiency by region

We conclude this illustration of the
6 Conclusion
We introduced a new command,
Supplemental Material
Supplemental Material, st0607 - sfcount: Command for count-data stochastic frontiers and underreported and overreported counts
Supplemental Material, st0607 for sfcount: Command for count-data stochastic frontiers and underreported and overreported counts by Eduardo Fé and Richard Hofler in The Stata Journal
Footnotes
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.