
Abstract
Differences-in-differences evaluates the effect of a treatment. In its basic version, a “control group” is untreated at two dates, whereas a “treatment group” becomes fully treated at the second date. However, in many applications of this method, the treatment rate increases more only in the treatment group. In such fuzzy designs, de Chaisemartin and D’Haultfœuille (2018b, Review of Economic Studies 85: 999–1028) propose various estimands that identify local average and quantile treatment effects under different assumptions. They also propose estimands that can be used in applications with a nonbinary treatment, multiple periods, and groups and covariates. In this article, we present the command
Keywords
1 Introduction
Differences-in-differences (DID) is a method to evaluate the effect of a treatment when experimental data are not available. In its basic version, a “control group” is untreated at two dates, whereas a “treatment group” becomes fully treated at the second date. However, in many applications of the DID method, the treatment rate increases more in some groups than in others, but there is no group that goes from fully untreated to fully treated, and there is also no group that remains fully untreated. In such fuzzy designs, a popular estimator of treatment effects is the Wald DID, which is the DID of the outcome divided by the DID of the treatment.
As shown by de Chaisemartin and D’Haultfœuille (2018b), the Wald DID identifies a local average treatment effect (LATE) if two assumptions on treatment effects are satisfied. First, the effect of the treatment should not vary over time. Second, when the treatment increases both in the treatment and in the control group, treatment effects should be equal in these two groups. de Chaisemartin and D’Haultfœuille (2018b) also propose two alternative estimands of the same LATE. These estimands do not rely on any assumption on treatment effects, and they can be used when the share of treated units is stable in the control group. The time-corrected (TC) Wald ratio relies on common trends assumptions within subgroups of units sharing the same treatment at the first date. The changes-in-changes (CIC) Wald ratio generalizes the CIC estimand introduced by Athey and Imbens (2006) to fuzzy designs. Under the same assumptions as those used for the Wald CIC, local quantile treatment effects (LQTE) are also identified.
In this article, we describe the
The identification results mentioned above hold with a control group where the share of treated units does not change over time, a binary treatment, no covariates, two groups, and two periods. Nonetheless, they can be extended in several directions. First, under the same assumptions as those underlying the Wald TC estimand, the LATE of treatment group switchers can be bounded when the share of treated units changes over time in the control group. Second, nonbinary treatments can be easily handled by modifying the parameter of interest. Third, when the assumptions are more credible conditional on some controls, one can modify the Wald DID, Wald TC, and Wald CIC estimands to incorporate such controls. The
Finally, results can be extended to applications with multiple periods and groups that are prevalent in applied work. Researchers then estimate treatment effects via linear regressions, including time and group fixed effects. de Chaisemartin and D’Haultfœuille (2018a) show that around 19% of all empirical articles published by the American Economic Review between 2010 and 2012 use this research design. They also show that these regressions are extensions of the Wald DID to multiple periods and groups and that they identify weighted averages of LATEs with possibly many negative weights.
1
Thus, they do not satisfy the no-sign reversal property: the coefficient of the treatment variable in those regressions may be negative even if the treatment effect is positive for every unit in the population. On the other hand, the Wald DID, Wald TC, and Wald CIC estimands can be extended to applications with multiple groups and periods, and they then identify a LATE under the same assumptions as in the two groups and two periods case. Again, the
The remainder of the article is organized as follows. Section 2 presents the estimands and estimators considered by de Chaisemartin and D’Haultfœuille (2018b) in the simplest setup with two groups and periods, a binary treatment, and no covariates. Section 3 discusses the various extensions covered by the
2 Setup
2.1 Parameters of interest, assumptions, and estimands
We seek to identify the effect of a treatment D on some outcome. In this section, we assume that D is binary.
2
Y (1) and Y (0) denote the two potential outcomes of the same individual with and without treatment, while Y = Y (D) denotes the observed outcome. We assume the data can be divided into time periods represented by a random variable
We use the following notation hereafter. For any random variable R, S(R) denotes its support. Rgt
and Rdgt
are two other random variables such that Rgt
∼ R| G = g, T = t and Rdgt
∼ R| D = d, G = g, T = t, where ∼ denotes equality in distribution. For any event or random variable A, FR
and FR
|A
denote the cumulative distribution function (CDF) of R and its CDF conditional on A, respectively. Finally, for any increasing function F on the real line, we let F −1(q) = inf {x ∈ ℝ: F (x) ≥ q}. In particular,
We maintain assumptions 1–3 below in most of this article.
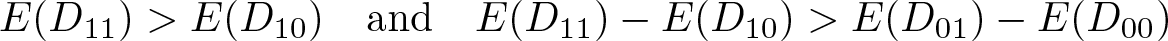
For all d ∈ S(D), P (D 01 = d) = P (D 00 = d) ∈ (0, 1).
There exist

In standard “sharp” designs, we have D = G × T , meaning that only observations in the treatment group and in period 1 get treated. With assumption 1, we consider instead “fuzzy” settings where D ≠ G × T in general but where the treatment group experiences a higher increase of its treatment rate between periods 0 and 1. Assumption 2 requires that the treatment rate remain constant in the control group and be strictly included between 0 and 1. This assumption is testable. Assumption 3 is equivalent to the latent index model
We consider the subpopulation S = {D(0) < D(1), G = 1}, hereafter called the treatment group switchers. Our parameters of interest are their LATE and LQTE, which are, respectively, defined by

We introduce the main estimands in de Chaisemartin and D’Haultfœuille (2018b). We start by considering the three estimands of Δ. The first is the Wald DID defined by
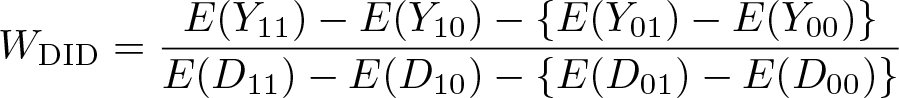
W DID is the coefficient of D in a two-stage least-squares regression of Y on D with G and T as included instruments and G × T as the excluded instrument.
The second estimand of Δ is the Wald TC ratio defined by

where δd
= E(Yd
01) − E(Yd
00), for d ∈ S(D). Without the
The third estimand of Δ is the Wald CIC defined by

where
Finally, we consider an estimand of τq . Let

and
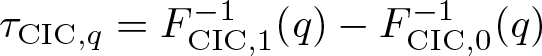
The estimands above identify Δ or τq under combinations of the following assumptions:
For all
For all d ∈ S(D) and all
For all d ∈ S(D) and all
Y (d) = hd (Ud, T ), with Ud ∈ ℝ and hd (u, t) strictly increasing in u for all (d, t) ∈ S(D) × S(T ). Moreover, Ud ⫫T |G, D(0).
Assumption 4 is the usual common trends condition, under which the DID estimand identifies the average treatment effect on the treated in sharp designs where D = G×T . Assumption 4’ is a conditional version of this common trend condition, which requires that the means of Y (0) and Y (1) among untreated and treated units at period 0 follow the same evolution in both groups, respectively. Assumption 5 requires that in each group, the average treatment effect among units treated in period 0 remains stable between periods 0 and 1. Assumption 6 requires that potential outcomes be strictly increasing functions of a scalar and stationary unobserved term, as in Athey and Imbens (2006). Assumption 7 is a testable restriction on the distribution of Y that is necessary only for the Wald CIC and τq, CIC estimands.
If assumptions 4 and 5 also hold, then W
DID = Δ. If assumptions 4’ also hold, then W
TC = Δ. If assumptions 6–7 also hold, then W
CIC = Δ and τq,
CIC = τq
.
Theorem 1 gives several sets of conditions under which we can identify Δ using one of the three estimands above. It also shows that τq can be identified under the same conditions as those under which the Wald CIC identifies Δ. Compared with the Wald DID, the Wald TC and Wald CIC do not rely on the stable treatment-effect assumption, which may be implausible. The choice between the Wald TC and the Wald CIC estimands should be based on the suitability of assumptions 4’ and 6 in the application under consideration. Assumption 4’ is not invariant to the scaling of the outcome, but it restricts only its mean. Assumption 6 is invariant to the scaling of the outcome, but it restricts its entire distribution. When the treatment and control groups have different outcome distributions conditional on D in the first period, the scaling of the outcome might have a large effect on the Wald TC. The Wald CIC is less sensitive to the scaling of the outcome, so using this estimand might be preferable. On the other hand, when the two groups have similar outcome distributions conditional on D in the first period, using the Wald TC might be preferable.
To test the assumptions underlying those estimands, one can test whether they are equal. If they are not, at least one of those assumptions must be violated. An alternative approach is to perform placebo tests. For instance, if three time periods are available (T = −1, 0, or 1) and if the treatment rate remains stable in both groups between T = −1 and 0, then the numerators of the Wald DID, Wald TC, and Wald CIC estimands for those two periods should be equal to 0.
2.2 Estimators
We now turn to the estimation of Δ and τq, CIC using plugin estimators of the estimands above. Let (Yi, Di, Gi, Ti ) i =1…n denote an independent and identically distributed sample of (Y, D, G, T ) and define I gt = {i : Gi = g, Ti = t} and I dgt = {(i : Di = d, Gi = g, Ti = t}. Let ngt and ndgt denote the size of I gt and I dgt for all d, g, t) ∈ S(D) × {0, 1}2.
First, let

be the estimator of the Wald DID. Second, for any d ∈ S(D), let

be the estimator of the Wald TC. Third, for all (d, g, t) ∈ S(D) × {0, 1}2, let
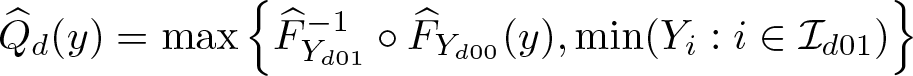
be the estimator of the quantile–quantile transform Qd , and let

be the estimator of the Wald CIC. Finally, let
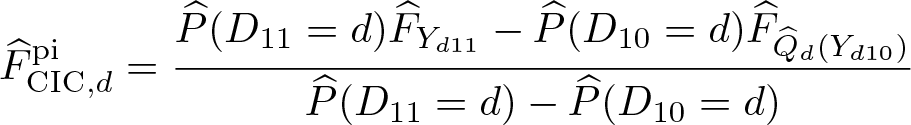
The function

With this proper CDF at hand, let

be the estimator of τq .
de Chaisemartin and D’Haultfœuille (2018b) show that
3 Extensions
3.1 Including covariates
The basic setup can be extended to include covariates. Let

In their article’s supplement, de Chaisemartin and D’Haultfœuille (2018b) show that
Let us turn to estimators of
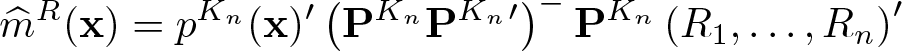
where (.)− denotes the generalized inverse and Kn
is an integer. We then estimate

where
Second, we consider semiparametric estimators of
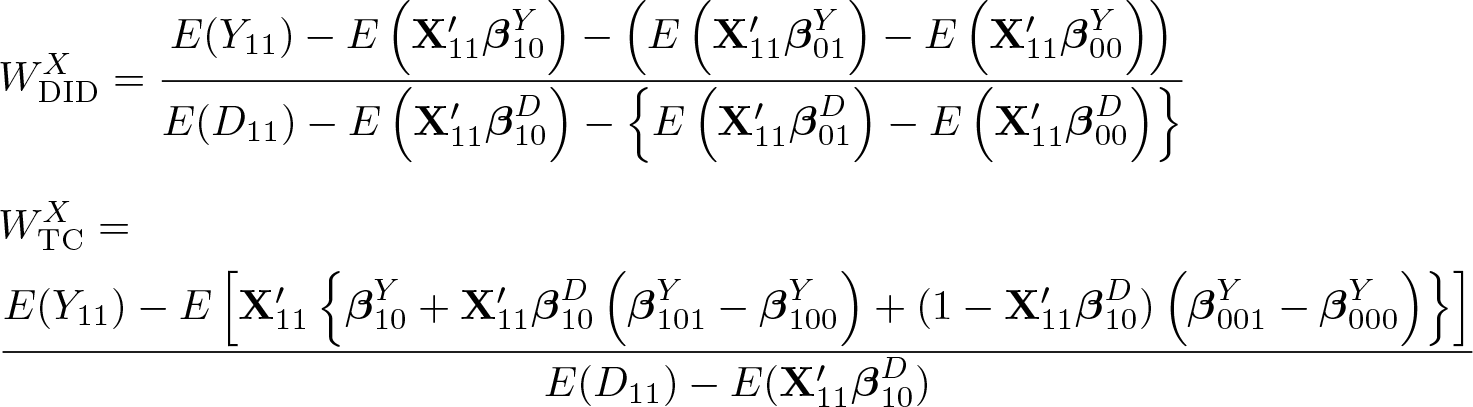
Then, semiparametric estimators of

where for (d, g, t) ∈ {0, 1}3,
Finally, researchers may sometimes wish to include a large set of controls in their estimation, which may lead to violations of the common support assumptions S(
3.2 Multiple periods and groups
We now extend our initial setting to multiple periods and groups. We first define, at each period

Let T = t ∈ {1,…, t} : P (

When
Let us then introduce the following weights,

where again we set

Finally, we consider the following assumption, which replaces assumption 2.

Theorem 2 below shows that under our previous conditions plus assumption 8, the three estimands point identify Δ. This theorem is proved for the Wald DID and Wald TC in de Chaisemartin and D’Haultfœuille (2018a) and can be proved along the same lines for the Wald CIC. 6
If assumptions 4 and 5 are satisfied, If assumption 4’ is satisfied, If assumptions 6 and 7 are satisfied,
To estimate
Let us focus on the estimator of

where I
g
∗
t,t
′ = {i : G
∗
ti
= g, Ti
= t
′} and ng
∗
t,t
′ is the size of

We then estimate

3.3 Other extensions
We now briefly review some other extensions, for which more details can be found in de Chaisemartin and D’Haultfœuille (2018b) and its supplement.
Special cases
When P (D
00 = d) = P (D
01 = d) = 0 for d ∈ {0, 1}, W
TC, W
CIC, and τ
CIC,q
are not defined, because δd
and Qd
are not defined, respectively. In such cases, we can simply suppose that δ
0 = δ
1 and Q
0 = Q
1, respectively, and modify the estimators accordingly. Then the Wald TC becomes equal to the Wald DID, while the modified CIC estimands identify Δ and τq
under the same assumptions as above and if
No “stable” control group
In some applications (see, for example, Enikolopov, Petrova, and Zhuravskaya [2011]), the treatment rate increases in all groups, thus violating assumption 2. Then, we can still express the Wald DID as a linear combination of the LATEs of treatment and control group switchers. Specifically, let S ′ = {D(0) ≠ D(1), G = 0} be the control group switchers and Δ′ = E{Y (1)−Y (0)|S ′ , T = 1} be their LATE. Under assumptions 1, 3, 4, and 5, we have
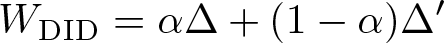
where α = {E(D 11) − E(D 10)}/[E(D 11) − E(D 10) − {E(D 01) − E(D 00)}]. Hence, the Wald DID identifies a weighted sum of Δ and Δ′. Note, however, that if the treatment rate increases in the control group, E(D 01) > E(D 00) and α > 1, so Δ′ enters with a negative weight. In this case, we may have Δ > 0 and Δ′ > 0 and yet W DID < 0. We will have only W DID = Δ if Δ = Δ′.
We can also bound Δ under assumption 4’ if assumption 2 fails. We refer to de Chaisemartin and D’Haultfœuille (2018b) for such bounds and to de Chaisemartin and D’Haultfœuille’s (2018b) supplement for their corresponding estimators.
Nonbinary treatment
The Wald DID, Wald TC, and Wald CIC still identify a causal parameter if D is not binary but is ordered and takes a finite number of values, as shown in de Chaisemartin and D’Haultfœuille (2018b). When the treatment takes many values, its support may differ in the treatment and control groups, and there may be values of D in the treatment group for which δd
or Qd
are not defined because no unit in the control group has that value of D. This situation particularly includes the special cases discussed above. We can then slightly modify W
TC and W
CIC. Namely, let us consider a recategorized treatment

We then replace
Finally, there may also be instances where the treatment has the same support in the treatment and in the control groups but where bootstrap samples do not satisfy this requirement. For such bootstrap samples, W
TC and W
CIC cannot be estimated, and the
4 The fuzzydid command
The
4.1 Syntax
The syntax of

Y is the outcome variable.
G is the group variable or variables. When the data bear only two groups and two periods, G merely corresponds to the variable G defined in section 2, an indicator for units in the treatment group. Outside of this special case, G should list the variables
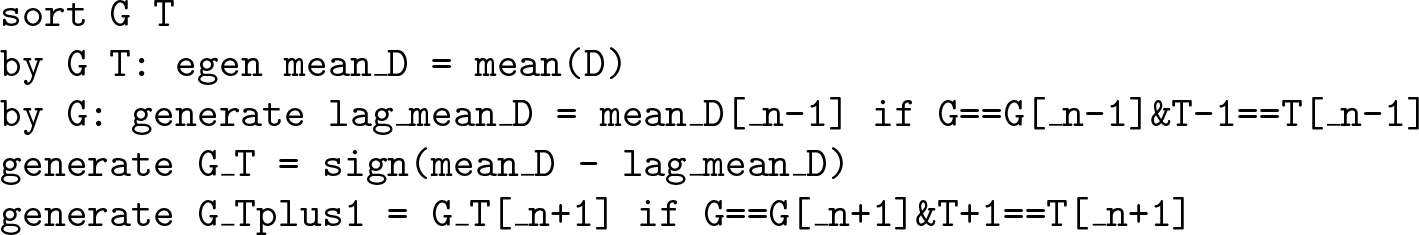
Sometimes, there may not be groups where the treatment is perfectly stable between consecutive periods, thus implying that the Wald DID, Wald TC, and Wald CIC estimators cannot be computed with the

where ε is a positive number small enough to consider that the mean treatment did not really change in groups where it changed by less than ε. See section 2.1 in de Chaisemartin and D’Haultfœuille’s (2018b) supplement for one possible method to choose ε.
T is the time-period variable with values in {0,…, t}.
D is the treatment variable. It can be any ordered variable.
4.2 Description
4.3 Options
General options
At least one of the four options above is required. If several of these options are specified, the command computes all the estimators requested by the user.
Options specific to estimators with covariates
When covariates are included in the estimation, and neither
4.4 Stored results
If the user specifies at least one of the If the user specifies the If the user specifies the
5 Example
To illustrate the use of

The average turnout in the 1868 to 1928 presidential elections across counties is 65.01%. The number of newspapers ranges from 0 to 45 and is on average equal to 1.46.
Second, we use

The columns of the output table show, respectively, the value of each estimator, its bootstrap standard error, its t statistic, its p-value, and the lower and upper bounds of its 95% confidence interval. All point estimates are positive, but none are statistically significant, presumably because this restricted sample with two time periods is too small. In this simple example with two periods and no controls, the computation of the estimators and of 200 bootstrap replications takes only about 3 seconds on a Dell Optiplex 9020 with an Intel Core i7-4790 CPU 3.60 GHz processor and 16 GB of RAM, using Stata/MP with 4 cores.
Third, we compute estimators of the LQTEs, again using the 1868 and 1872 elections. We use a binary treatment variable

To preserve space, we report only
Fourth, we compute

The Wald DID is equal to 0.0038. According to that estimator, increasing the number of newspapers available in a county by one increases voters’ turnout in presidential elections by 0.38 percentage points. This estimator is significantly different from 0 at the 5% level. The Wald TC is larger (0.0053) and significantly different from the Wald DID (t statistic = −4.51). The Wald CIC lies in between (0.0042), and this estimator is not significantly different from the other two. In this more complicated example with 16 periods and almost 17,000 observations, computing the estimators and 200 bootstrap replications still takes only around two minutes.
Gentzkow, Shapiro, and Sinkinson (2011) allow for state-specific trends in their specification, so we compute

With those controls,
Finally, we compute a placebo Wald DID or Wald TC estimator to assess if assumptions 4 and 5 or assumption 4’, respectively, is plausible in this application. Instead of using the turnout in county g and election-year t as the outcome variable, our placebo estimators use the turnout in the same county in the previous election. Moreover, only counties where the number of newspapers did not change between t − 2 and t − 1 are included in the estimation. Therefore, our placebo estimators compare the evolution of turnout from t−2 to t−1, between counties where the number of newspapers increased or decreased between t − 1 and t and counties where that number remained stable, restricting the sample to counties where the number of newspapers remained stable from t − 2 to t − 1.

The placebo Wald DID is negative, indicating that the actual Wald DID may be downward biased because of a violation of assumptions 4 and 5. However, this placebo estimator is not statistically significant. The placebo Wald TC is also negative and not statistically significant. It is twice smaller than the placebo Wald DID, thus indicating that assumption 4’ may be more plausible than assumptions 4 and 5 in this application.
6 Monte Carlo simulations
This section exhibits the finite sample performance of the estimators of W DID, W TC, W CIC, and τ CIC,q . For that purpose, we consider the following data-generating process (DGP). Let (G, T ) be uniform on {0, 1}2. Let {U(0), U(1), V } ∼ N (0, Σ), with Σ ii = 1 for i ∈ {1, 3}, Σ22 = 1.2, Σ12 = 0, Σ13 = 0.5, and Σ23 = −0.5 and with {U(0), U(1), V }⫫(G, T ). Then, we let
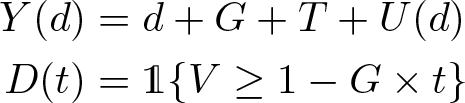
In this DGP, all the assumptions in section 2 hold. Therefore, W DID, W TC, and W CIC all identify Δ, while τ CIC,q identifies τq . We focus on the bias, mean square error, and coverage rate of estimators of Δ and τq for q ∈ {0.25, 0.5, 0.75} and for sample sizes equal to 400, 800, and 1,600. In this DGP, Δ ≃ 0.540, τ 0.25 ≃ 0.481, τ 0.5 ≃ 0.536, and τ 0.75 ≃ 0.595.
The results are displayed in table 1. Even with small samples, the Wald DID and Wald TC estimators do not exhibit any systematic bias. Their root mean squared errors (RMSE) are also similar. The Wald CIC, conversely, is more biased and has an RMSE that is 5 to 15% larger. This is probably due to the estimator of the nonlinear transform Qd
. This estimator is likely biased and imprecise in the tails, which may also explain the bias and high RMSE of
Results of the Monte Carlo simulations

NOTES: “Cov. rate” stands for coverage rates of (percentile bootstrap) confidence intervals, with a nominal level of 95%. The results are based on 1,000 samples, and for each, 500 bootstrap samples are drawn to construct the confidence intervals. With our DGP, Δ ≃ 0.540, τ 0.25 ≃ 0.481, τ 0.5 ≃ 0.536, and τ 0.75 ≃ 0.595.
7 Conclusion
We have discussed how to use
Supplemental Material
Supplemental Material, st0560 - Fuzzy differences-in-differences with Stata
Supplemental Material, st0560 for Fuzzy differences-in-differences with Stata by Clément de Chaisemartin, Xavier D’Haultfœuille and Yannick Guyonvarch in The Stata Journal
Footnotes
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.