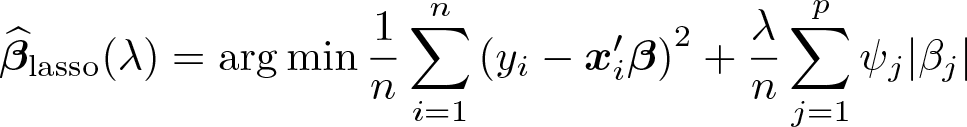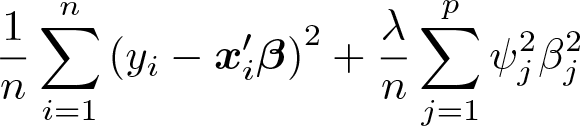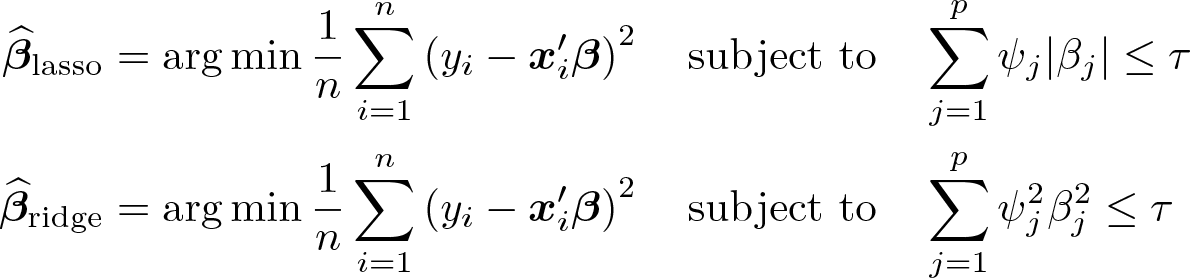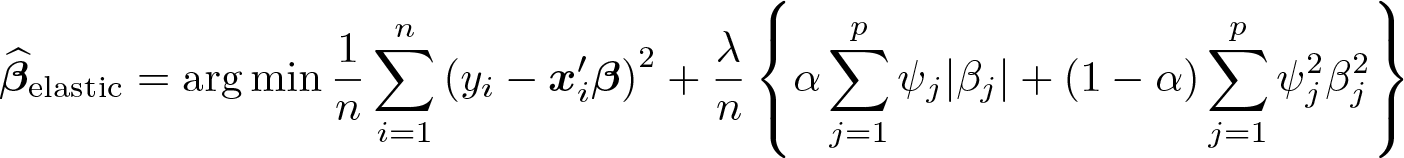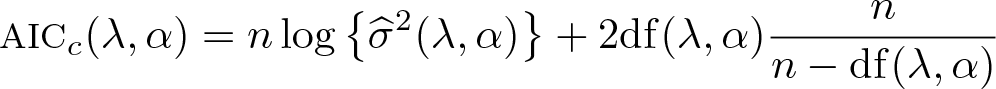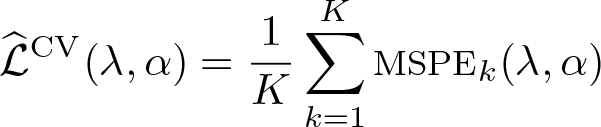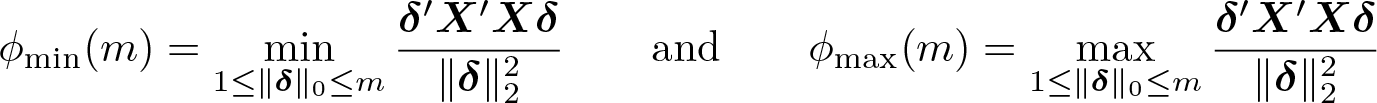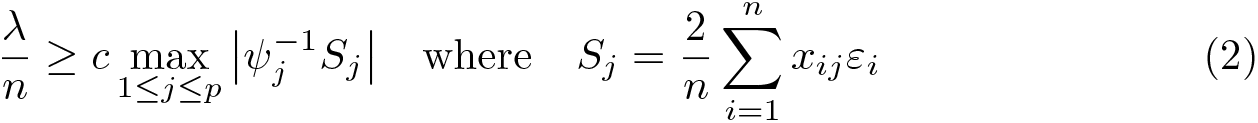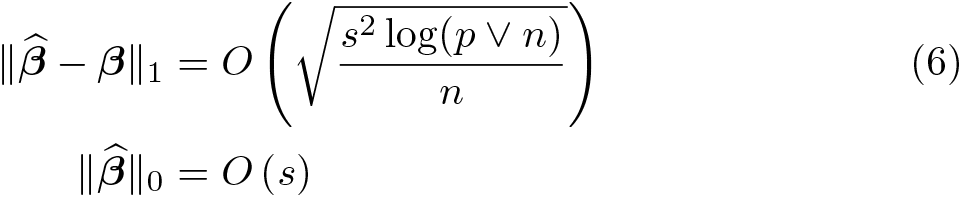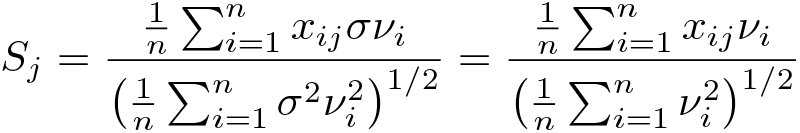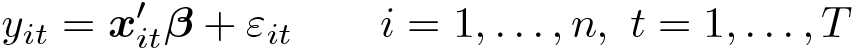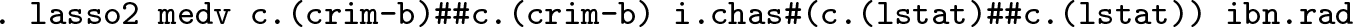In this article, we introduce lassopack, a suite of programs for regularized regression in Stata. lassopack implements lasso, square-root lasso, elastic net, ridge regression, adaptive lasso, and postestimation ordinary least squares. The methods are suitable for the high-dimensional setting, where the number of predictors p may be large and possibly greater than the number of observations, n. We offer three approaches for selecting the penalization (“tuning”) parameters: information criteria (implemented in lasso2), K-fold cross-validation and h-step-ahead rolling cross-validation for cross-section, panel, and time-series data (cvlasso), and theory-driven (“rigorous” or plugin) penalization for the lasso and square-root lasso for cross-section and panel data (rlasso). We discuss the theoretical framework and practical considerations for each approach. We also present Monte Carlo results to compare the performances of the penalization approaches.
Machine learning is attracting increasing attention across many scientific disciplines. Recent surveys explore how machine-learning methods can be used in economics and applied econometrics (Varian 2014; Mullainathan and Spiess 2017; Athey 2019; Kleinberg et al. 2018; Athey and Imbens 2019). At the time of writing, Stata offers only a limited set of machine-learning tools. lassopack is an attempt to extend this set by providing easy-to-use and flexible methods for regularized regression in Stata.1
While regularized linear regression is only one of many methods in the toolbox of machine learning, it has some properties that make it attractive for empirical research. To begin with, it is a straightforward extension of linear regression. Like ordinary least squares (OLS), regularized linear regression minimizes the sum of squared deviations between observed and model-predicted values but imposes a regularization penalty aimed at limiting model complexity. The most popular regularized regression method is the lasso—which this package is named after—introduced by Frank and Friedman (1993) and Tibshirani (1996), which penalizes the absolute size of coefficient estimates.
The primary purpose of regularized regression, as with supervised machine-learning methods more generally, is prediction. Regularized regression typically does not produce estimates that can be interpreted as causal, and statistical inference on these coefficients is complicated.2 While regularized regression may select the true model as the sample size increases, this is generally the case only under strong assumptions. However, regularized regression can aid causal inference without relying on the strong assumptions required for perfect model selection. The post-double-selection methodology of Belloni, Chernozhukov, and Hansen (2014) and the postregularization approach of Chernozhukov, Hansen, and Spindler (2015) can be used to select appropriate control variables from a large set of putative confounding factors and thereby improve robustness of estimation of the parameters of interest. Likewise, the first stage of two-step least squares is a prediction problem, and lasso or ridge can be applied to obtain optimal instruments (Belloni et al. 2012; Carrasco 2012; Hansen and Kozbur 2014). We implemented these methods in our sister package pdslasso (Ahrens, Hansen, and Schaffer 2018), which builds on the algorithms developed in lassopack.
The strength of regularized regression as a prediction technique stems from the bias-variance tradeoff. The prediction error can be decomposed into the unknown error variance reflecting the overall noise level (which is irreducible), the squared estimation bias, and the variance of the predictor. The variance of the estimated predictor increases with the model complexity, whereas the bias tends to decrease with model complexity. By reducing model complexity and inducing a shrinkage bias, regularized regression methods tend to outperform OLS in terms of out-of-sample prediction performance. In doing so, regularized regression addresses the common problem of overfitting: high in-sample fit (high R2) but poor prediction performance on unseen data.
Another advantage is that the regularization methods of lassopack—with the exception of ridge regression—set some coefficients to exactly zero, thereby excluding predictors from the model. In this way, regularized regression can serve as a modelselection technique. Model selection is challenging, especially when there are many putative predictors. Iterative testing procedures, such as the general-to-specific approach, typically induce pretesting biases, and hypothesis tests often lead to many false positives. At the same time, high-dimensional problems where the number of predictors is large relative to the sample size are a common phenomenon, especially when the true model is treated as unknown. Regularized regression allows for identification even when the number of predictors exceeds the sample size under the sparsity assumption, which requires that the true model include only a few predictors or, more generally, that only a few predictors are necessary to approximate the true model sufficiently well.
Regularized regression methods rely on tuning parameters that control the degree and type of penalization. lassopack offers three approaches to select these tuning parameters. The classical approach is to select tuning parameters using cross-validation (CV) to optimize out-of-sample prediction performance. CV methods are universally applicable and generally perform well for prediction tasks but are computationally expensive. The second approach relies on information criteria, such as the Akaike information criterion (AIC) (Zou, Hastie, and Tibshirani 2007; Zhang, Li, and Tsai 2010). Information criteria are easy to calculate and have attractive theoretical properties but are less robust to violations of the independence and homoskedasticity assumptions (Arlot and Celisse 2010). The third approach is rigorous penalization for the lasso and squareroot lasso. The tuning parameters are chosen to theoretically provide good prediction performance and control overfitting in the presence of heteroskedastic, non-Gaussian, and cluster-dependent errors (Belloni et al. 2012; Belloni, Chernozhukov, and Wang 2014; Belloni et al. 2016). The rigorous approach places a high priority on controlling overfitting, thus often producing parsimonious models. This strong focus on containing overfitting is practically and theoretically beneficial for selecting control variables or instruments in a structural model but also implies that the approach may be outperformed by CV techniques for pure prediction tasks. Which approach is most appropriate depends on the type of data at hand and the purpose of the analysis. To guide applied researchers, we discuss the theoretical foundation of all three approaches and present Monte Carlo results that assess their relative performance.
This article proceeds as follows. In section 2, we present the estimation methods implemented in lassopack. In sections 3–5, we discuss the aforementioned approaches for selecting the tuning parameters: information criteria in section 3, CV in section 4, and rigorous penalization in section 5. In section 6, we present the three commands, which correspond to the three penalization approaches. In section 7, we demonstrate the commands. In section 8, we present Monte Carlo results. Further technical notes are in section 9.
Notation. We briefly clarify the notation used in this article. Suppose a is a vector of dimension m with typical element aj for j = 1,…, m. The ℓ1 norm is defined as , and the ℓ2 norm is . The “ℓ0 norm” of a is denoted by ||a||0 and is equal to the number of nonzero elements in a. denotes the indicator function. We use the notation b ∨ c to denote the maximum value of b and c, that is, max(b, c).
2 Regularized regression
Here we introduce the regularized regression methods implemented in lassopack. We consider the high-dimensional linear model
where the number of predictors, p, may be large and even exceed the sample size, n. The regularization methods introduced in this section can accommodate large-p models under the assumption of sparsity: out of the p predictors, only a subset of s ≪ n is included in the true model, where s is the sparsity index
We refer to this assumption as exact sparsity. It is more restrictive than required, but we use it here for illustration. We will later relax the assumption to allow for nonzero but “small” βj coefficients. We also define the active set Ω = {j ∊ {1,…, p} : βj ≠ 0}, which is the set of nonzero coefficients. p, s, Ω, and β may generally depend on n, but we suppress the n subscript for notational convenience.
We adopt the following convention throughout the article: unless otherwise noted, all variables have been mean centered such that and , and all variables are measured in their natural units; that is, they have not been prestandardized to have unit variance. By assuming the data have already been mean centered, we simplify the notation and exposition. Leaving the data in natural units, however, allows us to discuss standardization in the context of penalization.
Penalized regression methods rely on tuning parameters that control the degree and type of penalization. The estimation methods implemented in lassopack, which we will introduce in the following subsection, use two tuning parameters; λ controls the general degree of penalization. Setting λ to zero corresponds to no penalization and is equivalent to OLS, while a sufficiently large value of λ yields an empty model, where all coefficients are zero. The second tuning parameter, α, determines the relative contribution of ℓ1 (lasso-type) versus ℓ2 (ridge-type) penalization. We will discuss the merits and properties of ℓ1 and ℓ2 penalization in the following subsection. In section 2.2, we introduce the three approaches offered by lassopack for selecting λ and α.
2.1 The estimators
Lasso
The lasso takes a special position because it provides the basis for the rigorous penalization approach (see section 5) and has inspired other methods such as elastic net and square-root lasso, which we introduce later in this section. The lasso minimizes the mean squared error subject to a penalty on the absolute size of coefficient estimates:
The tuning parameter λ controls the overall penalty level, and ψj are predictor-specific penalty loadings.
Tibshirani (1996) motivates the lasso with two major advantages over OLS. First, because of the nature of the ℓ1 penalty, the lasso sets some of the coefficient estimates exactly to zero and, in doing so, removes some predictors from the model. Thus, the lasso serves as a model-selection technique and facilitates model interpretation. Second, lasso can outperform least squares in prediction accuracy because of the bias-variance tradeoff.
The lasso coefficient path, which constitutes the trajectory of coefficient estimates as a function of λ, is piecewise linear with changes in slope where variables enter or leave the active set. The change points are referred to as knots.
Unlike OLS, the lasso is not invariant to linear transformations, which is why scaling matters. If the predictors are not of equal variance, the most common approach is to prestandardize the data such that and set ψj = 1 for j = 1,…, p. Alternatively, we can set the penalty loadings to . The two methods yield identical results.
The interpretation and choice of the penalty loadings ψj is the same as above. As with the lasso, we need to account for uneven variance either through preestimation standardization or by appropriately choosing the penalty loadings ψj.
In contrast with estimators relying on ℓ1 penalization, the ridge does not perform variable selection. At the same time, it also does not rely on the assumption of sparsity. This makes the ridge attractive in the presence of dense signals, that is, when the assumption of sparsity does not seem plausible. Dense high-dimensional problems are more challenging than sparse problems; for example, Dicker (2016) shows that, if p/n → ∞, it is not possible to outperform a trivial estimator that includes only the constant. If p, n → ∞ jointly, but p/n converges to a finite constant, the ridge has desirable properties in dense models and tends to perform better than sparsity-based methods (Hsu, Kakade, and Zhang 2014; Dicker 2016; Dobriban and Wager 2018).
Ridge regression is closely linked to principal component regression. Both methods are popular in the context of multicollinearity because of their low variance relative to OLS. Principal component regression applies OLS to a subset of components derived from principal component analysis, thereby discarding a specified number of components with low variance. The rationale for removing low-variance components is that the predictive power of each component tends to increase with the variance. The ridge can be interpreted as projecting the response against principal components while imposing a higher penalty on components exhibiting low variance. Hence, the ridge follows a similar principle, but rather than discarding low-variance components, it applies a more severe shrinkage (Hastie, Tibshirani, and Friedman 2009).
Comparing lasso and ridge regression provides further insights into the nature of ℓ1 and ℓ2 penalization, so it is helpful to write lasso and ridge in constrained form as
and to examine the shapes of the constraint sets. The above optimization problems use the tuning parameter τ instead of λ. Note that there exists a data-dependent relationship between λ and τ.
Figure 1 illustrates the geometry underpinning lasso and ridge regression for the case of p = 2 and ψ1 = ψ2 = 1 (that is, unity penalty loadings). The gray elliptical lines represent residual sums of squares contours, and the black lines indicate the lasso and ridge constraints. The lasso constraint set, given by |β1| + |β2| ≤ τ, is diamond shaped with vertices along the axes, from which it immediately follows that the lasso solution may set coefficients exactly to 0. In contrast, the ridge constraint set, , is circular and will thus (effectively) never produce a solution with any coefficient set to 0. Finally, in the figure denotes the solution without penalization, which corresponds to OLS. The lasso solution at the corner of the diamond implies that, in this example, one of the coefficients is set to zero, whereas ridge and OLS produce nonzero estimates for both coefficients.
Behavior of ℓ1 and ℓ2 penalties in comparison. The gray lines represent residual sum of squares contour lines, and the black lines represent the lasso and ridge constraints, respectively. denotes the OLS estimates. and are the lasso and ridge estimates. The illustration is based on Tibshirani (1996, fig. 2).
While there exists no closed-form solution for the lasso, the ridge solution can be expressed as
Here X is the n × p matrix of predictors with typical element xij, y is the response vector, and Ψ = diag(ψ1,…, ψp) is the diagonal matrix of penalty loadings. The ridge regularizes the regressor matrix by adding positive constants to the diagonal of X′X. The ridge solution is thus generally well defined as long as all the ψj and λ are sufficiently large, even if X′X is rank deficient.
Elastic net
The elastic net of Zou and Hastie (2005) combines some of the strengths of lasso and ridge regression. It applies a mix of ℓ1 (lasso-type) and ℓ2 (ridge-type) penalization:
The additional parameter α determines the relative contribution of ℓ1 versus ℓ2 penalization. In the presence of groups of correlated regressors, the lasso typically selects only one variable from each group, whereas the ridge tends to produce similar coefficient estimates for groups of correlated variables. However, the ridge does not yield sparse solutions, impeding model interpretation. The elastic net can produce sparse solutions for some α that are greater than zero and retains or drops correlated variables jointly.
Adaptive lasso
The irrepresentable condition is shown to be sufficient and (almost) necessary for the lasso to be model-selection consistent (Zhao and Yu 2006; Meinshausen and Bühlmann 2006). However, the irrepresentable condition imposes strict constraints on the degree of correlation between predictors in the true model and predictors outside the model. Motivated by this nontrivial condition for the lasso to be variable-selection consistent, Zou (2006) proposed the adaptive lasso. The adaptive lasso uses the penalty loadings of , where is an initial estimator. The adaptive lasso is variable-selection consistent for a fixed p under weaker assumptions than the standard lasso. If p < n, OLS can be used as the initial estimator. Huang, Ma, and Zhang (2008) prove variable-selection consistency for a large p and suggest using univariate OLS if p > n. The idea of adaptive penalty loadings can also be applied to elastic net and ridge regression (Zou and Zhang 2009).
Square-root lasso
The square-root lasso,
is a modification of the lasso that minimizes the root mean squared error (rmse) while also imposing an ℓ1 penalty. The main advantage of the square-root lasso over the standard lasso becomes apparent if theoretically grounded, data-driven penalization is used. Specifically, the score vector, and thus the optimal penalty level, is independent of the unknown error variance under homoskedasticity as shown by Belloni, Chernozhukov, and Wang (2011), resulting in a simpler procedure for choosing λ (see section 5).3
Postestimation OLS
Penalized regression methods induce an attenuation bias that can be alleviated by postestimation OLS, which applies OLS to the variables selected by the first-stage variable-selection method, that is,
where is a sparse first-step estimator such as the lasso. Thus, postestimation OLS treats the first-step estimator as a genuine model-selection technique. For lasso with theory-driven regularization, Belloni and Chernozhukov (2013) have shown that postestimation OLS, also referred to as postlasso, achieves the same convergence rates as the lasso and can outperform the lasso in situations where consistent model selection is feasible (see also Belloni et al. [2012]). Similar results hold for the square-root lasso (Belloni, Chernozhukov, and Wang 2011, 2014).
2.2 Choice of the tuning parameters
Because coefficient estimates and the set of selected variables depend on λ and α, a central question is how to choose these tuning parameters. Which method is most appropriate depends on the objectives and setting, particularly the aim of the analysis (prediction or model identification), computational constraints, and if and how the independent and identically distributed (i.i.d.) assumption is violated. lassopack offers three approaches for selecting the penalty level of λ and α:
1. Information criteria: The value of λ can be selected using information criteria. lasso2 implements model selection using four information criteria. See section 3.
2. CV: The aim of CV is to optimize the out-of-sample prediction performance. CV is implemented in cvlasso, which allows for CV across both λ and the elastic-net parameter α. See section 4.
3. Theory driven (“rigorous”): Theoretically justified and feasible penalty levels and loadings are available for the lasso and square-root lasso via rlasso. The penalization is chosen to dominate the noise of the data-generating process (represented by the score vector), which allows derivation of theoretical results with regard to consistent prediction and parameter estimation. See section 5.
3 Tuning parameter selection using information criteria
Information criteria are closely related to regularization methods. The classical aic (Akaike 1974) is defined as −2 × log likelihood + 2p. Thus, the AIC can be interpreted as penalized likelihood, which imposes a penalty on the number of predictors included in the model. However, this form of penalization, referred to as the ℓ0 penalty, has an important practical disadvantage. To find the model with the lowest AIC, we need to estimate all different model specifications. In practice, it is often not feasible to consider the full model space. For example, with only 20 predictors, there are more than 1,000,000 different models.
The advantage of regularized regression is that it provides a data-driven method for reducing model selection to a one-dimensional problem (or two-dimensional problem in the case of the elastic net) where we need to select λ (and α). Theoretical properties of information criteria are well understood, and they are easy to compute once coefficient estimates are obtained. Thus, it seems natural to use the strengths of information criteria as model-selection procedures to select the penalization level.
Information criteria can be categorized based on two central properties: loss efficiency and model-selection consistency. A model-selection procedure is loss efficient if it yields the smallest averaged squared error attainable by all candidate models. Model-selection consistency requires that the true model be selected with probability approaching 1 as n → ∞. Accordingly, which information criteria is appropriate in a given setting also depends on whether the aim of analysis is prediction or identification of the true model.
We first consider the most popular information criteria, AIC and Bayesian information criterion (Schwarz 1978, BIC):
and are the residuals. df(λ, α) is the effective degrees of freedom, which is a measure of model complexity. In the linear regression model, the degrees of freedom is simply the number of regressors. Zou, Hastie, and Tibshirani (2007) show that the number of coefficients estimated to be nonzero, sb, is an unbiased and consistent estimate of df(λ) for the lasso (α = 1). Tibshirani and Taylor (2012) confirm that the result also holds if p > n. More generally, the degrees of freedom of the elastic net can be calculated as the trace of the projection matrix; that is,
where is the matrix of selected regressors. The unbiased estimator of the degrees of freedom provides a justification for using the classical AIC and BIC to select tuning parameters (Zou, Hastie, and Tibshirani 2007).
The BIC is known to be model-selection consistent if the true model is among the candidate models, whereas AIC is inconsistent. Clearly, the assumption that the true model is among the candidates is strong; even the existence of the “true model” may be problematic, so loss efficiency may become a desirable second best. The AIC is loss efficient, in contrast with the BIC. Yang (2005) shows that the differences between AIC-type information criteria and BIC-type information criteria are fundamental: a consistent model-selection method such as the BIC cannot be loss efficient, and vice versa. Zhang, Li, and Tsai (2010) confirm this relation in the context of penalized regression.
Both AIC and BIC are not suitable in the large-p–small-n context, where they tend to select too many variables (see Monte Carlo simulations in section 8). It is well known that the AIC is biased in small samples, which motivated the bias-corrected AIC (Sugiura 1978; Hurvich and Tsai 1989),
The bias can be severe if df is large relative to n, and thus the AICc should be favored when n is small or with high-dimensional data.
The BIC relies on the assumption that each model has the same prior probability. This assumption seems reasonable when the researcher has no prior knowledge, yet it contradicts the principle of parsimony and becomes problematic if p is large. To see why, consider the case where p = 1000 (following Chen and Chen [2008]): There are 1,000 models for which one parameter is nonzero (s = 1), while there are 1000 × 999/2 models for which s = 2. Thus, the prior probability of s = 2 is greater than the prior probability of s = 1 by a factor of 999/2. More generally, because the prior probability that s = j is greater than the probability that s = j − 1 (up to the point where j = p/2), the BIC is likely to overselect variables. To address this shortcoming, Chen and Chen (2008) introduce the extended BIC (EBIC), defined as
which imposes an additional penalty on the size of the model. The prior distribution is chosen such that the probability of a model with dimension j is inversely proportional to the total number of models for which s = j. The additional parameter, ξ ∊ [0, 1], controls the size of the additional penalty.4Chen and Chen (2008) show in simulation studies that the EBICξ outperforms the traditional BIC, which exhibits a higher false-discovery rate when p is large relative to n.
4 Tuning parameter selection using CV
The aim of CV is to directly assess the performance of a model on unseen data. To this end, the data are repeatedly divided into a training and a validation dataset. The models are fit to the training data, and the validation data are used to assess the predictive performance. In the context of regularized regression, CV can be used to select the tuning parameters that yield the best performance, for example, the best out-of-sample mean squared prediction error. Many methods for CV are available. For an extensive review, we recommend Arlot and Celisse (2010). The most popular method is K-fold CV, which we introduce in section 4.1. In section 4.2, we discuss methods for CV in the time-series setting.
4.1 K-fold CV
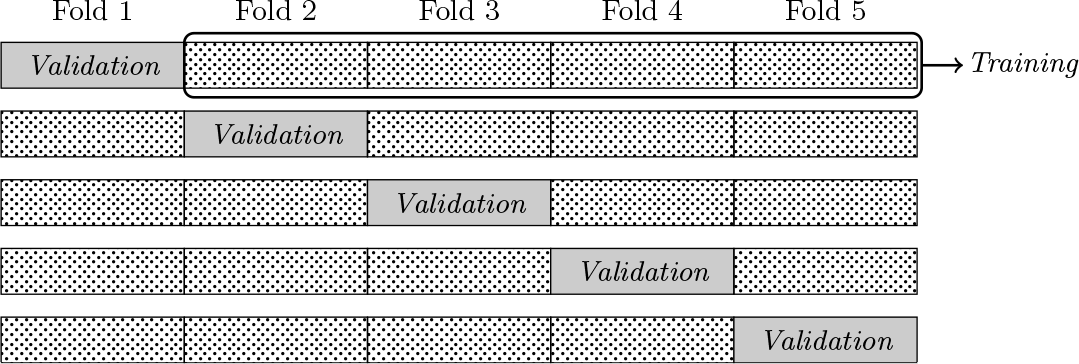
For K-fold CV, proposed by Geisser (1975), the data are split into K groups of approximately equal size that are referred to as folds. Let Kk denote the set of observations in the kth fold, and let nk be the size of data partition k for k = 1,…, K. In the kth step, the kth fold is treated as the validation dataset, and the remaining K − 1 folds constitute the training dataset. The model is fit to the training data for a given value of λ and α. The resulting estimate, which is based on all the data except the observations in fold k, is . The procedure is repeated for each fold, as illustrated in figure 2, so that every data point is used for validation once. The mean squared prediction error (MSPE) for each fold is computed as
Data partition for five-fold CV. Each row corresponds to one step, and each column corresponds to one data partition (“fold”). In the first step, fold 1 constitutes the validation data, and folds 2–5 are the training data.
The K-fold CV estimate of the MSPE, which serves as a measure of prediction performance, is
This suggests selecting λ and α as the values that minimize . An alternative common rule is to use the largest value of λ that is within one standard deviation of the minimum, which leads to a more parsimonious model.
CV can be computationally expensive. It is necessary to compute for each value of λ on a grid if α is fixed (for example, when using the lasso) or, in the case of the elastic net, for each combination of values of λ and α on a two-dimensional grid. In addition, the model must be fit K times at each grid point such that the computational cost is approximately proportional to K.5
Standardization adds another layer of computational cost to K-fold CV. An important principle in CV is that the training dataset should not contain information from the validation dataset. This mimics the real-world situation where out-of-sample predictions are made despite the true response being unknown. The principle applies not only to individual observations but also to data transformations such as mean centering and standardization. Specifically, data transformations applied to the training data should not use information from the validation data or full dataset. Mean centering and standardization using sample means and sample standard deviations for the full sample would violate this principle. Instead, when in each step the model is fit to the training data for a given λ and α, the training dataset must be recentered and restandardized, or if standardization is built into the penalty loadings, the must be recalculated based on the training dataset.
The choice of K is a practical problem, but it also has theoretical implications. The variance of decreases with K and is minimal (for linear regression) if K = n, which is referred to as LOO CV. Similarly, the bias decreases with the size of the training dataset. Given computational constraints, K values between 5 and 10 are often recommended, arguing that the performance of CV rarely improves for K values greater than 10 (Hastie, Tibshirani, and Friedman 2009; Arlot and Celisse 2010).
If the aim of the researcher’s analysis is model identification rather than prediction, the theory requires training data to be “small” and the evaluation sample to be close to n (Shao 1993, 1997). The reason is that more data are required to evaluate which model is the “correct” one rather than to decrease bias and variance. This is referred to as the CV paradox (Yang 2006). However, because K-fold CV sets the size of the training sample to approximately n/K, K-fold CV is necessarily ill suited for selecting the true model.
Regarding the K-fold cross-validated lasso, Chetverikov, Liao, and Chernozhukov (2019) demonstrate that the estimation error converges at a near-optimal rate to zero. For example, if the errors are Gaussian, then the convergence rate is slower by a “small logarithmic factor” of relative to the theory-driven approach of regularization (to be discussed in section 5). The authors also confirm through simulations and deriving sparsity bounds that choosing the tuning parameter by CV tends to yield more predictors than are in the true model and than when theory-driven regularization is used.
4.2 CV with time-series data
Serially dependent data violate the principle that training and validation data are independent. That said, standard K-fold CV may still be appropriate in certain circumstances. Bergmeir, Hyndman, and Koo (2018) show that K-fold CV remains valid in the pure autoregressive model if one is willing to assume that the errors are uncorrelated. A useful implication is that K-fold CV can be used on autoregressive models that include a sufficient number of lags and are not otherwise badly misspecified, because such models have uncorrelated errors.
Rolling h-step-ahead CV is an intuitively appealing approach that directly incorporates the ordered nature of time-series data (Hyndman and Athanasopoulos 2012).6 The procedure builds on repeated h-step-ahead forecasts. The procedure is implemented in lassopack and illustrated in figures 3–4.
Rolling h-step-ahead CV with expanding training window. T and V denote that the observation is included in the training and validation samples, respectively. A dot (·) indicates that an observation is excluded from both training and validation data.
Rolling h-step-ahead CV with fixed training window
Figure 3(a) corresponds to the default case of one-step-ahead CV. T denotes the observation included in the training sample, and V refers to the validation sample. In the first step, observations 1–3 constitute the training dataset, and observation 4 is the validation point, whereas the remaining observations are unused as indicated by a dot (·). Figure 3(b) illustrates the case of two-step-ahead CV. In both cases, the training window expands incrementally, whereas figure 4 displays rolling CV with a fixed estimation window.
4.3 Comparison with information criteria
Because information-based approaches and CV share the aim of model selection, one might expect that the two methods share some theoretical properties. Indeed, AIC and LOO CV are asymptotically equivalent, as shown by Stone (1977) for fixed p. Because information criteria require the model to be fit only once, they are computationally much more attractive, which might suggest that information criteria are superior in practice. However, some advantages of CV are its flexibility and that it adapts better to situations where the assumptions underlying information criteria, for example, homoskedasticity, are not satisfied (Andrews 1991; Arlot and Celisse 2010). If the aim of the analysis is identifying the true model, BIC and EBIC provide a better choice than K-fold CV, because there are strong but well-understood conditions under which BIC and EBIC are model-selection consistent.
5 Rigorous penalization
This section introduces the “rigorous” or plugin approach to penalization. Following Chernozhukov, Hansen, and Spindler (2016), we use the term “rigorous” to emphasize that the framework is grounded in theory in that it provides penalization parameters that guarantee optimal rate of convergence for prediction and parameter estimation. The approach also yields models whose size is of the same order as the true model. Rigorous penalization is of special interest because it provides the basis for methods to facilitate causal inference in the presence of many instruments, many control variables, or both; these methods are the instrumental-variables lasso (Belloni et al. 2012), the post-double-selection estimator (Belloni, Chernozhukov, and Hansen 2014), and the postregularization estimator (Chernozhukov, Hansen, and Spindler 2015), all of which are implemented in our sister package pdslasso (Ahrens, Hansen, and Schaffer 2018).
We discuss the conditions required to derive theoretical results for the lasso in section 5.1. Sections 5.2–5.5 present feasible algorithms for rigorous penalization choices for the lasso and square-root lasso under i.i.d., heteroskedastic, and cluster-dependent errors. Section 5.6 presents a related test for joint significance testing.
5.1 Theory of the lasso
There are three main conditions required to guarantee that the lasso is consistent in terms of prediction and parameter estimation.7 The first condition relates to sparsity. Sparsity is an attractive assumption in settings where we have a large set of potentially relevant regressors or consider various model specifications but assume that only one true model exists that includes few regressors. We have introduced exact sparsity in section 2, but the assumption is stronger than needed. For example, some true coefficients may be nonzero but small in absolute size, in which case it might be preferable to omit them, so we use a weaker assumption:
The elementary regressors wi are linked to the dependent variable through the unknown and possibly nonlinear function f(·). The aim of lasso (and square-root lasso) estimation is to approximate f(wi) using the target parameter vector β0 and the transformations xi := P (wi), where P (·) denotes a dictionary of transformations. The vector xi may be large relative to the sample size either because wi itself is high dimensional and xi := wi or because many transformations such as dummies, polynomials, or interactions a re considered to approximate f(wi).
The assumption of approximate sparsity requires the existence of a target vector β0, which ensures that f(wi) can be approximated sufficiently well while using only few nonzero coefficients. Specifically, the target vector β0 and the sparsity index s are assumed to meet the condition
and the resulting approximation error, , is bounded such that
where C is a positive constant. To emphasize the distinction between approximate and exact sparsity, consider the special case where f(wi) is linear with but where the true parameter vector β⋆ violates exact sparsity so that ||β⋆||0 > n. If β⋆ has many elements that are negligible in absolute size, we might still be able to approximate β⋆ using the sparse target vector β0 as long as is sufficiently small as specified in (1).
Restricted sparse eigenvalue condition. The second condition relates to the Gram matrix, n−1X′X. In the high-dimensional setting where p is larger than n, the Gram matrix is necessarily rank deficient, and the minimum (unrestricted) eigenvalue is zero, that is,
Thus, to accommodate a large p, the full-rank condition of OLS needs to be replaced by a weaker condition. In the context of sparse models, we instead assume that “small” submatrices of size m, where m is slightly larger than s, are well behaved. This is in fact the restricted sparse eigenvalue condition (RSEC) of Belloni et al. (2012). The RSEC formally states that the minimum sparse eigenvalues
are bounded away from zero and from above. The requirement φmin(m) > 0 implies that all small submatrices of size m have to be positive definite.8
Regularization event. The third central condition concerns the choice of the penalty level λ and the predictor-specific penalty loadings ψj. The idea is to select the penalty parameters to control the random part of the problem in that
with high probability. Here c > 1 is a constant slack parameter, and Sj is the jth element of the score vector , which is the gradient of at the true value β. The score vector summarizes the noise associated with the estimation problem.
Denote by the maximal element of the score vector scaled by n and ψj, and denote by qΛ(·) the quantile function for Λ.9 In the rigorous lasso, we choose the penalty parameters λ and ψj and confidence level γ so that
A simple example illustrates the intuition behind this approach. Consider the case where the true model has βj = 0 for j = 1,…, p; that is, none of the regressors appears in the true model. It can be shown that for the lasso to select no variables, the penalty parameters λ and ψj need to satisfy .10 This is because none of the regressors appears in the true model, yi = εi. We can therefore rewrite the requirement for the lasso to correctly identify the model without regressors as , which is the regularization event in (2). We want this regularization event to occur with a high probability of at least (1 − γ). If we choose values for λ and ψj such that λ ≥ qΛ(1−γ), then by the definition of a quantile function, we will choose the correct model (no regressors) with a probability of at least (1 − γ). This is simply the rule in (3).
The chief practical problem in using the rigorous lasso is that the quantile function qΛ(·) is unknown. There are two approaches to addressing this problem proposed in the literature, both of which are implemented in rlasso. The rlasso default is the “asymptotic” or X-independent approach: theoretically grounded and feasible penalty level and loadings are used that guarantee that (2) holds asymptotically, because n → ∞ and γ → 0. The X-independent penalty-level choice can be interpreted as an asymptotic upper bound on the quantile function qΛ(·). In the “exact” or X-dependent approach, the quantile function qΛ(·) is directly estimated by simulating the distribution of qΛ(1− γ|X), the (1−γ)-quantile of Λ conditional on the observed regressors X. We first focus on the X-independent approach and introduce the X-dependent approach in section 5.5.
under homoskedasticity and heteroskedasticity, respectively. c is the slack parameter from above, and the significance level γ is required to converge toward 0. rlasso uses c = 1.1 and γ = 0.1/ log(n) as defaults.11,12
Homoskedasticity. We first focus on the case of homoskedasticity. In the rigorouslasso approach, we standardize the score. But because under homoskedasticity, we can separate the problem into two parts: the regressor-specific penalty loadings standardize the regressors, and σ moves into the overall penalty level. In the special case where the regressors have already been standardized such that , the penalty loadings are ψj = 1. Hence, the purpose of the regressor-specific penalty loadings in the case of homoskedasticity is to accommodate regressors with unequal variance.
The only unobserved term is σ, which appears in the optimal penalty level λ. To estimate σ, we can use some initial set of residuals and calculate the initial estimate as . A possible choice for the initial residuals is as in Belloni et al. (2012) and Belloni, Chernozhukov, and Hansen (2014). rlasso uses the OLS residuals , where D is the set of five regressors exhibiting the highest absolute correlation with yi.13 The procedure is summarized in algorithm A:
□ Algorithm A: Estimation of penalty level under homoskedasticity
1. Set k = 0, and define the maximum number of iterations, K. Regress yi against the subset of d predictors exhibiting the highest correlation coefficient with yi, and compute the initial residuals as . Calculate the homoskedastic penalty loadings in (4).
2. If k ≤ K, compute the homoskedastic penalty level in (4) by replacing σ with , and obtain the rigorous lasso or postlasso estimator . Update the residuals . Set k ← k + 1.
3. Repeat step 2 until k > K or until convergence by updating the penalty level.
□
The rlasso default is to perform one further iteration after the initial estimate (that is, K = 1), which in our experience provides good performance. Both lasso and postlasso can be used to update the residuals. rlasso uses postlasso to update the residuals.14
Heteroskedasticity. The X-independent choice for the overall penalty level under heteroskedasticity is . The only difference from the homoskedastic case is the absence of σ. The variance of ε is now captured via the penalty loadings, which are set to . Hence, the penalty loadings here serve two purposes: accommodating both heteroskedasticity and regressors with uneven variance. To help with intuition, we consider the case where the predictors are already standardized. It is easy to see that, if the errors are homoskedastic with σ = 1, the penalty loadings are (asymptotically) just ψj = 1. If the data are heteroskedastic, however, the standardized penalty loading will not be 1. In most practical settings, the usual pattern will be that for some j. Intuitively, heteroskedasticity typically increases the likelihood that the term takes on extreme values, thus requiring a higher degree of penalization through the penalty loadings.15
The disturbances εi are unobserved, so we obtain an initial set of penalty loadings from an initial set of residuals
, similarly to the i.i.d. case above. We summarize the algorithm for estimating the penalty level and loadings as follows:
□ Algorithm B: Estimation of penalty loadings under heteroskedasticity
1. Set k = 0, and define the maximum number of iterations, K. Regress yi against the subset of d predictors exhibiting the highest correlation coefficient with yi, and compute the initial residuals as . Calculate the heteroskedastic penalty level λ in (4).
2. If k ≤ K, compute the heteroskedastic penalty loadings using the formula given in (4) by replacing εi with , and obtain the rigorous lasso or postlasso estimator . Update the residuals . Set k ← k + 1.
3. Repeat step 2 until k > K or until convergence by updating the penalty loadings.
□
Theoretical property. Under the assumptions of sparse eigenvalue condition and approximate sparse model, and if penalty level λ and the penalty loadings are estimated by algorithm A or B, the lasso and postlasso obey16
The first relation in (5) provides an asymptotic bound for the prediction error, and the second relation in (6) bounds the bias in estimating the target parameter β. Belloni et al. (2012) refer to the above convergence rates as near-oracle rates. If the identity of the s variables in the model were known, the prediction error would converge at the oracle rate . Thus, the logarithmic term log(p ∨ n) can be interpreted as the cost of not knowing the true model. The final relation is a sparsity bound that shows that the size of the fit model does not diverge relative to the true model.
For comparison, the rates of the rigorous lasso are faster than the convergence rates of the K-fold cross-validated lasso derived in Chetverikov, Liao, and Chernozhukov (2019). Furthermore, the sparsity bound in Chetverikov, Liao, and Chernozhukov (2019) does not rule out situations where , implying that the model fit using CV may be much larger than the true model because the penalty level chosen by K-fold CV cannot be guaranteed to satisfy the regularization event in (2). Indeed, Chetverikov, Liao, and Chernozhukov (2019) confirm in simulations that the cross-validated penalty is often smaller than (2) requires.
5.3 Rigorous square-root lasso
The theory of the square-root lasso is similar to the theory of the lasso (Belloni, Chernozhukov, and Wang 2011; 2014). The jth element of the score vector is now defined as
To see why the square-root lasso is of special interest, we define the standardized errors νi as νi = εi/σ. The jth element of the score vector becomes
and is thus independent of σ. For the same reason, the optimal penalty level for the square-root lasso in the i.i.d. case,
is independent of the noise level σ.
Homoskedasticity. The ideal penalty loadings under homoskedasticity for the squareroot lasso are given by formula (iv) in table 1, which provides an overview of penaltyloading choices. The ideal penalty parameters are independent of the unobserved error, which is an appealing theoretical property and implies a practical advantage. Because both λ and ψj can be calculated from the data, the rigorous square-root lasso is a onestep estimator under homoskedasticity. Belloni, Chernozhukov, and Wang (2011) show that the square-root lasso performs similarly to the lasso with infeasible ideal penalty loadings.
Ideal penalty loadings for the lasso and square-root lasso under homoskedasticity, heteroskedasticity, and cluster dependence
lasso
square-root lasso
homoskedasticity
(i)
(iv)
heteroskedasticity
(ii)
(v)
cluster dependence
(iii)
(vi)
note: Formulas (iii) and (vi) use the notation .
Heteroskedasticity. In the case of heteroskedasticity, the optimal square-root lasso penalty level remains (7), but the penalty loadings, given by formula (v) in table 1, depend on the unobserved error and need to be estimated. Note that the updated penalty loadings using the residuals
use thresholding: the penalty loadings are enforced to be greater than or equal to the loadings in the homoskedastic case. The rlasso default algorithm used to obtain the penalty loadings in the heteroskedastic case is analogous to algorithm B.17 While the ideal penalty loadings are not independent of the error term if the errors are heteroskedastic, the square-root lasso may still have an advantage over the lasso because the ideal penalty loadings are pivotal with respect to the error term up to scale, as pointed out above.
5.4 Rigorous penalization with panel data
Belloni et al. (2016) extend the rigorous framework to the case of clustered data, which accommodates a limited form of dependence—within-group correlation—as well as heteroskedasticity. They prove consistency of the rigorous lasso using this approach in the large-n–fixed-T and large-n–large-T settings. The authors present the approach in the context of a fixed-effects panel-data model, , and apply the rigorous lasso after the within transformation to remove the fixed effects µi. The approach extends to any clustered-type setting and to balanced and unbalanced panels. For convenience, we ignore the fixed effects and write the model as a balanced panel:
The intuition behind the Belloni et al. (2016) approach is similar to that behind the clustered standard errors reported by various Stata estimation commands: observations within clusters are aggregated to create “superobservations” that are assumed independent, and these superobservations are treated similarly to cross-sectional observations in the nonclustered case. Specifically, define for the ith cluster and jth regressor the superobservation . Then the penalty loadings for the clustered case are
which resembles the heteroskedastic case. The rlasso default for the overall penalty level is the same as in the heteroskedastic case, , except that the default value for γ is 0.1/ log(n); that is, we use the number of clusters n rather than the number of observations nT. lassopack also implements the rigorous square-root lasso for panel data, which uses the overall penalty in (7) and the penalty loadings in formula (vi) in table 1.
5.5 X-dependent lambda
The X-dependent penalty is an alternative, sharper choice for the overall penalty level. Recall that the asymptotic, X-independent choice in (4) can be interpreted as an asymptotic upper bound on the quantile function of Λ, which is the scaled maximum value of the score vector. Instead of using the asymptotic choice, we can estimate by simulation the distribution of Λ conditional on the observed X and use this simulated distribution to obtain the quantile qΛ(1 − γ|X).
In the case of estimation by the lasso under homoskedasticity, we simulate the distribution of Λ using the statistic W, defined as
where ψj is the penalty loading for the homoskedastic case,
is an estimate of the error variance using some previously obtained residuals, and gi is an i.i.d. standard normal variate drawn independently of the data. The X-dependent penalty choice is sharper and adapts to correlation in the regressor matrix (Belloni and Chernozhukov 2011).
Under heteroskedasticity, the lasso X-dependent penalty is obtained by a multiplier bootstrap procedure. In this case, the simulated statistic W is defined as in formula (ii) in table 2. The cluster–robust X-dependent penalty is again obtained analogously to the heteroskedastic case by defining superobservations, and the statistic W is defined as in formula (iii) in table 2. Note that the standard normal variate gi varies across but not within clusters.
Definition of W statistic for the simulation of the distribution of Λ for the lasso and square-root lasso under homoskedasticity, heteroskedasticity, and cluster dependence
lasso
square-root lasso
homoskedasticity
(i)
(iv)
heteroskedasticity
(ii)
(v)
cluster dependence
(iii)
(vi)
note:gi is an i.i.d. standard normal variate drawn independently of the data; . Formulas (iii) and (vi) use the notation .
The X-dependent penalties for the square-root lasso are similarly obtained from quantiles of the simulated distribution of the square-root lasso Λ and are given by formulas (iv), (v), and (vi) in table 2 for the homoskedastic, heteroskedastic, and clustered cases, respectively.18
5.6 Significance testing with the rigorous lasso
Inference using the lasso, especially in the high-dimensional setting, is a challenging and ongoing research area (see footnote 2). A test that has been developed and is available in rlasso corresponds to the test for joint significance of regressors using F or χ2 tests that is common in regression analysis. Specifically, Belloni et al. (2012) suggest using the Chernozhukov, Chetverikov, and Kato (2013, app. M) sup-score test to test for the joint significance of the regressors; that is,
As in the preceding sections, regressors are assumed to be mean centered and in their original units.
If the null hypothesis is correct and the rest of the model is well specified, including the assumption that the regressors are orthogonal to the disturbance εi, then yi = εi and hence E(xiεi) = E(xiyi) = 0. The sup-score statistic is
where . Intuitively, the ψj in (8) plays the same role as the penalty loadings do in rigorous-lasso estimation.
The p-value for the sup-score test is obtained by a multiplier bootstrap procedure simulating the distribution of SSS by the statistic W, defined as
where gi is an i.i.d. standard normal variate drawn indep endently of the data and ψj is defined as in (8).
The procedure above is valid under both homoskedasticity and heteroskedasticity but requires independence. A cluster–robust version of the sup-score test that accommodates within-group dependence is
where and .
The p-value for the cluster version of SSS comes from simulating
where again gi is an i.i.d. standard normal variate drawn independently of the data. Note again that gi is invariant within clusters.
rlasso also reports conservative critical values for SSS using an asymptotically justified upper bound: CV = cΦ−1{1 − γSS/(2p)}. The default value of the slack parameter is c = 1.1, and the default test level is γSS = 0.05. These parameters can be varied using the c() and ssgamma() options, respectively. The simulation procedure to obtain p-values using the simulated statistic W can be computationally intensive, so users can request reporting only of computationally inexpensive conservative critical values by setting the number of simulated values to zero with the ssnumsim(int) option.
6 The commands
The package lassopack consists of three commands: lasso2, cvlasso, and rlasso. Each command offers an alternative method for selecting the tuning parameters λ and α. We discuss each command in turn and present its syntax. We focus on the main syntax and the most important options. Some technical options are omitted for the sake of brevity. For a full description of syntax and options, see the help files.
6.1 lasso2: Base command and information criteria
The primary purpose of lasso2 is to obtain the solution of (adaptive) lasso, elastic net, and square-root lasso for a single value of λ or a list of penalty levels, that is, for λ1,…, λr,…, λR, where R is the number of penalty levels. The basic syntax of lasso2 is as follows:
lasso2depvar indepvars [if] [ in ] [ ,options ]
We omit the full list of options for the sake of brevity. Selected options are discussed below; see the help file for a full list of options.
Estimation methods
alpha(real) controls the elastic-net parameter, α, which controls the degree of ℓ1-norm (lasso-type) to ℓ2-norm (ridge-type) penalization. alpha(1) corresponds to the lasso (the default estimator), and alpha(0) corresponds to ridge regression. The real value must lie in the interval [0, 1].
sqrt specifies the square-root lasso estimator. Because the square-root lasso does not use any form of ℓ2 penalization, the option is incompatible with alpha(real).
adaptive specifies the adaptive lasso estimator. The penalty loading for predictor j is set to , where is the OLS estimate or univariate OLS estimate if p > n. θ is the adaptive exponent and can be controlled using the adatheta(real) option.
adaloadings(matrix) is a matrix of alternative initial estimates, , used for calculating adaptive loadings. For example, this could be the vector e(b) from an initial lasso2 estimation. The absolute value of is raised to the power −θ (note the minus).
adatheta(real) is the exponent for calculating adaptive penalty loadings. The default is adatheta(1).
ols specifies that postestimation OLS estimates are displayed and returned in e(betas) or e(b).
The options alpha(real), sqrt, adaptive, and ols can be used to select elastic net, square-root lasso, adaptive lasso, and postestimation OLS, respectively. The default estimator of lasso2 is the lasso, which corresponds to alpha(1). The special case of alpha(0) yields ridge regression.
Options relating to lambda
lambda(numlist) controls the penalty level or levels, λr, used for estimation. numlist is a scalar value or list of values in descending order. Each λr must be greater than zero. By default, the default list is used, which is defined using Mata syntax by lambda(exp(rangen(log(lmax),log(lminratio*lmax),lcount))), where lcount, lminratio, and lmax are defined below; exp() is the exponential function; log() is the natural logarithm; and rangen(a,b,n) creates a column vector going from a to b in n-1 steps (see the mf_range help file). Thus, the default list ranges from lmax to lminratio*lmax, and lcount is the number of values. The distance between each λr in the sequence is the same on the logarithmic scale.
lcount(integer) is the number of penalty values, R, for which the solution is obtained. The default is lcount(100).
lminratio(real) is the ratio of the minimum penalty level, λR, to the maximum penalty level, λ1. real must be between 0 and 1. The default is lminratio(0.001).
lmax(real) is the maximum-value penalty level, λ1. By default, λ1 is chosen as the smallest penalty level for which the model is empty. If the regressors are mean centered and standardized, then λ1 is defined as for the elastic net and for the square-root lasso (see Friedman, Hastie, and Tibshirani [2010, sec. 2.5]).
The behavior of lasso2 depends on whether the numlist in lambda(numlist) is a scalar or of length greater than 1. If numlist is a list of more than one value, the solution is a matrix of coefficient estimates that are stored in e(betas). Each row in e(betas) corresponds to a distinct value of λr, and each column corresponds to one of the predictors in indepvars. The “path” of coefficient estimates over λr can be plotted using plotpath(method), where method controls whether the coefficient estimates are plotted against lambda (lambda), the natural logarithm of lambda (lnlambda), or the ℓ1 norm (norm). If the numlist in lambda(numlist) is a scalar value, the solution is a vector of coefficient estimates that is stored in e(b). The default behavior of lasso2 is to use a list of 100 values.
Information criteria
lic(string) specifies that, after the first lasso2 estimation using a list of penalty levels, the model that corresponds to the minimum information criterion will be fit and displayed. aic, bic, aicc, and ebic (the default) are allowed. However, the results are not stored in e().
postresults is used in combination with lic(string). postresults stores estimation results of the model selected by information criterion in e().19
ic(string) controls which information criterion is shown in the output of lasso2 when lambda() is a list. aic, bic, aicc, and ebic (the default) are allowed.
ebicgamma(real) controls the ξ parameter of the EBIC. ξ needs to lie in the [0, 1] interval. ξ = 0 is equivalent to the BIC. The default choice is ξ = 1 − log(n)/{2 log(p)}.
In addition to obtaining the coefficient path, lasso2 calculates four information criteria (AIC, AICc, BIC, and EBIC). These information criteria can be used for model selection by choosing the value of λr that yields the lowest value for one of the four information criteria. The ic(string) option controls which information criterion is shown in the output, where string can be replaced with aic, aicc, bic, or ebic. lic(string) displays the estimation results corresponding to the model selected by an information criterion. Note that lic(string) will not store the results of the estimation. This has the advantage that the user can compare the results for different information criteria without the need to refit the full model. To save the estimation results, specify the postresults option in combination with lic(string).
Penalty loadings and standardization
notpen(varlist) sets penalty loadings to zero for predictors in varlist. Unpenalized predictors are always included in the model.
partial(varlist) specifies that variables in varlist are partialed out prior to estimation.
ploadings(matrix) is a row vector of penalty loadings and overrides the default standardization loadings. The size of the vector should equal the number of predictors (excluding partialed-out variables and excluding the constant).
unitloadings specifies that penalty loadings be set to a vector of ones; this option overrides the default standardization loadings.
prestd specifies that the dependent variable and predictors are standardized prior to estimation rather than standardized “on the fly” using penalty loadings. See section 9.2 for more details. By default, the coefficient estimates are unstandardized (that is, returned in original units).
stdcoef returns coefficients in standard deviation units, that is, not unstandardized. This option is supported only with the prestd option.
Fixed effects and intercept
fe specifies that the within transformation is applied prior to estimation. The option requires the data in memory to be xtset.
noconstant suppresses the constant from estimation. The default behavior is to partial the constant out (that is, to center the regressors).
Plotting
plotpath(string) plots the coefficients path as a function of the ℓ1 norm (norm), lambda (lambda), or the log of lambda (lnlambda).
plotvar(varlist) specifies the list of variables to be included in the plot.
plotopt(string) specifies additional plotting options passed to line. For example, to turn the legend off, use plotopt(legend(off)).
plotlabel displays the variable labels in the plot.
Replay syntax
The replay syntax of lasso2 allows for plotting and changing display options without the need to rerun the full model. It can also be used to fit the model using the value of λ selected by an information criterion. The syntax is given by
predict [ type ] newvar [ if ] [ in ] [ , xb residuals ols lambda(real) lid(int) approx noisily postresults ]
xb computes predicted values (the default).
residuals computes residuals.
ols specifies that postestimation OLS will be used for prediction.
If the previous lasso2 estimation uses more than one penalty level (that is, R > 1), the following options are applicable:
lambda(real) specifies the lambda value used for prediction.
lid(int) specifies the index of the lambda value used for prediction.
approx specifies that linear approximation is used instead of reestimation. This is faster but only exact if the coefficient path is piecewise linear.
noisily shows estimation output if reestimation is required.
postresults stores estimation results in e() if reestimation is used.
6.2 CV with cvlasso
cvlasso implements K-fold and h-step-ahead rolling CV. The syntax of cvlasso is
cvlassodepvar indepvars [ if ] [ in ] [, options ]
We discuss only selected options; see the help file for a full list of options.
Options for K-fold CV
alpha(numlist) is a scalar elastic-net parameter or an ascending list of elastic-net parameters. Note that the alpha() option of cvlasso accepts a numlist, while lasso2 accepts only a scalar. If numlist is a list longer than 1, cvlasso cross-validates over λr with r = 1,…, R and αm with m = 1,…, M.
nfolds(int) is the number of folds used for K-fold CV. The default is nfolds(10), or K = 10.
foldvar(varname) can be used to specify what fold (data partition) each observation lies in. varname is an integer variable with values ranging from 1 to K. By default, the fold variable is randomly generated such that each fold is of approximately equal size.
savefoldvar(varname) saves the fold variable in varname.
seed(real) sets the seed for the generation of a random fold variable.
Options for h-step-ahead rolling CV
rolling uses rolling h-step-ahead CV. The option requires the data to be tsset or xtset.
h(int) changes the forecasting horizon. The default is h(1).
origin(int) controls the number of observations in the first training dataset.
fixedwindow ensures that the size of the training dataset is constant.
Options for selection of lambda
lopt specifies that, after CV, lasso2 fits the model with the value of λr that minimizes the mean squared prediction error. That is, the model is fit with .
lse specifies that, after CV, lasso2 fits the model with the largest λr that is within one standard deviation from . That is, the model is fit with .
postresults stores the lasso2 estimation results in e() (to be used in combination with lse or lopt).
Plotting
plotcv plots the estimated mean squared prediction error as a function of ln(lambda).
plotopt(string) additional plotting options passed to line. For example, to turn the legend off, use plotopt(legend(off)).
Storing estimation results for each fold
saveest(string) saves lasso2 results from each step of the CV in string1,…, stringK, where K is the number of folds. Intermediate results can be restored with estimates restore.
Like lasso2, cvlasso also provides a replay syntax that helps to avoid time-consuming reestimations. The replay syntax of cvlasso can be used for plotting and to fit the model corresponding to or .
Predict syntax
predict [ type ] newvar [ if ] [ in ] [ , xb residuals lopt lse noisily ]
6.3 rlasso: Rigorous penalization
rlasso implements theory-driven penalization for lasso and square-root lasso. It allows for heteroskedastic, cluster-dependent, and non-Gaussian errors. Unlike lasso2 and cvlasso, rlasso estimates the penalty level λ using iterative algorithms. The syntax of rlasso is given by
rlassodepvar indepvars [ if ] [ in ] [ weight ] [ ,options ]
aweights and pweights are allowed; see [U] 11.1.6 weight. pweights is equivalent to aweights + robust.
As above, we discuss only selected options; see the help file for a full list of options.
pnotpen(varlist) specifies that variables in varlist are not penalized.20
robust specifies that the penalty loadings account for heteroskedasticity.
cluster(var) specifies that the penalty loadings account for clustering on variable var.
center centers moments in heteroskedastic and cluster–robust loadings.21
lassopsi specifies to use lasso or square-root lasso residuals to obtain penalty loadings. The default is postestimation OLS.22
corrnumber(int) specifies the number of high-correlation regressors used to obtain initial residuals. The default is corrnumber(5), and corrnumber(0) implies that depvar is used in place of residuals.
prestd standardizes data prior to estimation. The default is standardization during estimation via penalty loadings.
Options relating to lambda
xdependent specifies that the X-dependent penalty level is used; see section 5.5.
numsim(int) is the number of simulations used for the X-dependent case. The default is numsim(5000).
lalternative specifies the alternative, less sharp penalty level, which is defined as (for the square-root lasso, 2c is replaced with c). See footnote 12.
gamma(real) is the γ in the rigorous penalty level [default γ = 1/log(n); the cluster-lasso default is γ = 1/log(nclust)]. See (4).
c(real) is the c in the rigorous penalty level. The default is c(1.1). See (4).
Sup-score test
supscore reports the sup-score test of statistical significance.
testonly reports only the sup-score test without lasso estimation.
ssgamma(real) is the test level for the conservative critical value for the sup-score test. The default is ssgamma(0.05), that is, a 5% significance level.
ssnumsim(int) controls the number of simulations for the sup-score test-multiplier bootstrap. The default is ssnumsim(500), while 0 implies no simulation.
Predict syntax
predict [ type ] newvar [ if ] [ in ] [ , xb residuals lasso ols ]
xb generates fitted values (default).
residuals generates residuals.
lasso uses lasso coefficients for prediction. The default is to use estimates posted in the e(b) matrix.
ols uses OLS coefficients based on lasso-selected variables for prediction. The default is to use estimates posted in the e(b) matrix.
7 Demonstrations
In this section, we demonstrate the use of lasso2, cvlasso, and rlasso using one cross-section example (in section 7.1) and one time-series example (in section 7.2).
7.1 Cross-section
For demonstration purposes, we consider the Boston Housing Dataset available on the UCI Machine Learning Repository.23 The dataset includes 506 observations and 14 variables.24 The purpose of the analysis is to predict house prices using a set of census-level characteristics.
Estimation with lasso2
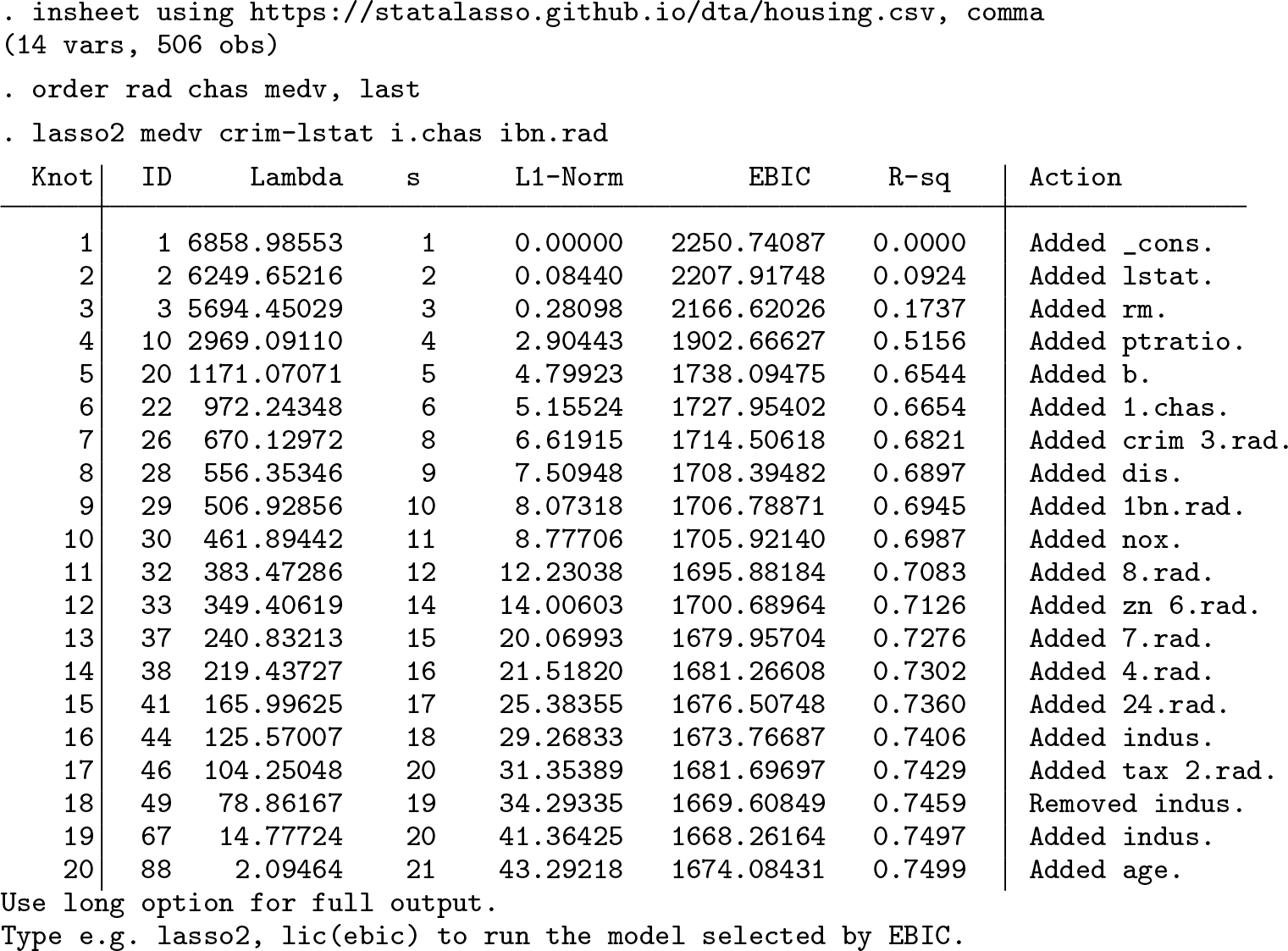
After importing the data and changing the variable order (to simplify the syntax), we use the lasso estimator by regressing the outcome variable (medv) against 11 continuous predictors (crim-lstat), the binary Charles River dummy variable chas, and the highway accessibility index rad, which we treat as categorical.
The lasso2 output above shows the following columns:
Knot is the knot index. Knots are points at which predictors enter or leave the model. The default output shows one line per knot. If the long option is specified, one row per λr value is shown.
ID shows the λr index, that is, r. By default, lasso2 uses a descending sequence of 100 penalty levels.
s is the number of predictors in the model.
L1-Norm shows the ℓ1 norm of coefficient estimates.
The sixth column (here labeled EBIC) shows one out of four information criteria. The ic() option controls which information criterion is displayed, where string can be replaced with aic, aicc, bic, and ebic (the default).
R-sq shows the R2 value.
The final column shows which predictors are entered or removed from the model at each knot. The order in which predictors are entered into the model can be interpreted as an indication of the relative predictive power of each predictor.
Because lambda(real) is not specified, lasso2 obtains the coefficient path for a default list of λr values. The largest penalty level is 6858.99, in which case the model does include only the constant.
We use the ibn. prefix for rad instead of the i. prefix commonly used in regression analysis. The i. prefix makes Stata omit the (automatically selected) base category from the estimation to avoid perfect collinearity (see help fvvarlist). In contrast with OLS, the lasso does not require the full-rank condition, allowing us to include one dummy for every category without removing the base category dummy. In this way, we let the lasso choose the base category automatically as the categories omitted from the selected model.
Figure 5 shows the coefficient path of the lasso for selected variables as a function of ln(λ). The graph illustrates how the lasso shrinks coefficients toward zero as the penalty level increases (from left to right). We can also infer the order in which predictors leave the model. The figure was created using the following command:
The coefficient path of the lasso for selected variables as a function of ln(λ)
The plotpath() option passes settings to Stata’s line command and is used here to switch the legend off. Instead of a standard legend, we specify plotlabel to show variable names on the left-hand side of the graph.
The commands of lassopack support Stata’s factor-variable notation. This is especially useful when the relationship between the outcome variable and predictors is suspected to be nonlinear. For demonstration purposes, we add squared terms and interaction effects. We also allow the effect of lstat to depend on whether the binary Charles River dummy variable (chas) takes the values 1 or 0.
lasso2 supports model selection using information criteria. To this end, we use the replay syntax with the lic() option, which avoids fitting the full model again. The lic() option can also be specified in the first lasso2 call. In the following example, the replay syntax works similarly to a postestimation command:
Two columns are shown in the output: one for the lasso estimator and one for postestimation OLS, which applies OLS to the model selected by the lasso.
K-fold CV with cvlasso
Next, we consider K-fold CV:
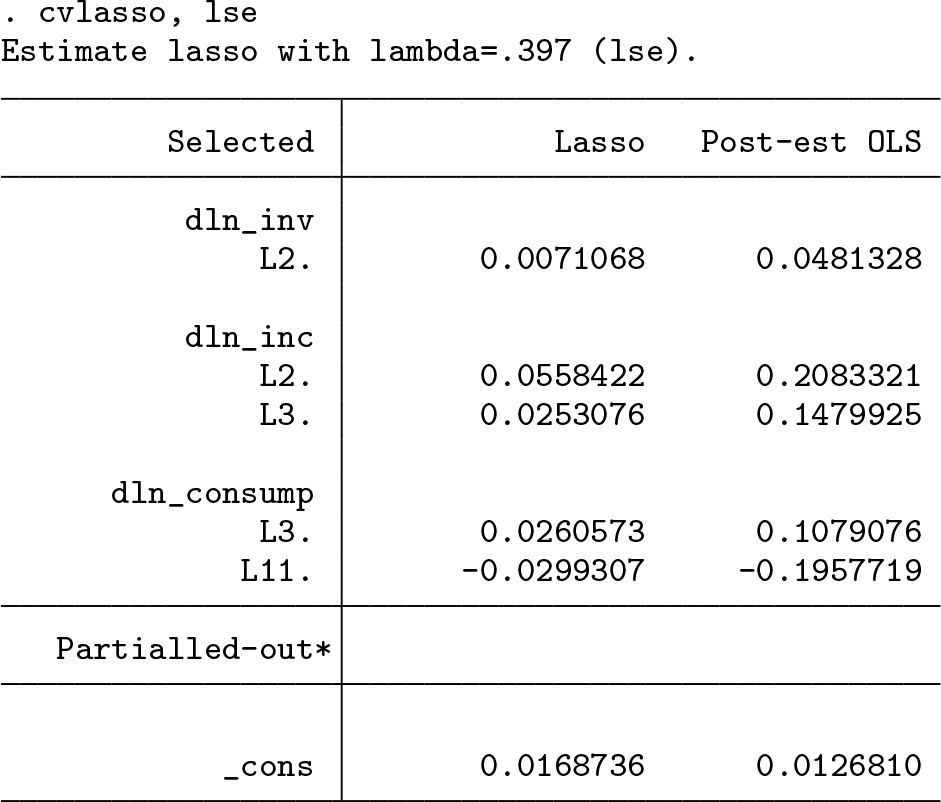
The cvlasso output displays four columns: the index of λr (that is, r), the value of λr, the estimated mean squared prediction error, and the standard deviation of the MSPE. The output indicates the value of λr that corresponds to the lowest MSPE with an asterisk (*). We refer to this value as . In addition, the symbol ⁁ marks the largest value of λ that is within one standard error of , which we denote as .
The mean squared prediction is shown in figure 6, which was created using the plotcv option. The graph shows the mean squared prediction error estimated by CV along with ± one standard error. The continuous and dashed vertical lines correspond to and , respectively.
The MSPE estimated by CV along with ± one standard error. The continuous and dashed vertical lines correspond to lopt and lse, respectively.
To fit the model corresponding to either or , we use the lopt or lse option, respectively. Similarly to the lic() option of lasso2, lopt and lse can be specified either in the first cvlasso call or after estimation using the replay syntax as in this example:
Rigorous penalization with rlasso
Lastly, we consider rlasso, which runs an iterative algorithm to estimate the penalty level and loadings. In contrast with lasso2 and cvlasso, it reports the selected model directly.
The supscore option prompts the sup-score test of joint significance. The p-value is obtained through multiplier bootstrap. The test statistic of 16.15 can also be compared with the asymptotic 5% critical value (here 3.75).
7.2 Time-series data
A standard problem in time-series econometrics is to select an appropriate lag length. In this subsection, we show how lassopack can be used for this purpose. We consider Stata’s built-in dataset lutkepohl2.dta, which includes quarterly (log-differenced) consumption (dln_consump), investment (dln_inv), and income (dln_inc) series for West Germany from quarter 1 1960–quarter 4 1982. We demonstrate both lag selection via information criteria and by h-step-ahead rolling CV. We do not consider the rigorous penalization approach of rlasso because of the assumption of independence, which seems too restrictive in the time-series context.
Information criteria
After importing the data, we run the most general model with up to 12 lags of the variables dln_consump, dln_inv, and dln_inc using lasso2 with the lic(aicc) option.
The output consists of two parts. The second part of the output is prompted because lic(aicc) is specified. lic(aicc) asks lasso2 to fit the model selected by AICc, which in this case corresponds to λ11 = 0.207.
h-step-ahead rolling CV
In the next step, we consider h-step-ahead rolling CV.
The output indicates how the dataset is partitioned into training data and the validation point. For example, the shorthand 13-80 (81) in the output above indicates that observations 13 to 80 constitute the training dataset in the first step of CV, and observation 81 is the validation point. The options fixedwindow, h(), and origin() can be used to control the partitioning of data into training and validation data. h() sets the parameter h. For example, h(2) prompts 2-step-ahead forecasts (the default is h(1)). fixedwindow ensures that the training dataset is the same size in each step. If origin(50) is specified, the first training partition includes observations 13 to 50, as shown in the next example:
The option plotcv creates the graph of the estimated mean squared prediction in figure 7. To fit the model corresponding to , we can—as in the previous examples—use the replay syntax:
CV plot. The graph uses Stata’s built-in dataset lutkepohl2.dta and 1-stepahead rolling CV with origin(50).
Take care when setting the parameters of h-step-ahead rolling CV. The default settings have no particular econometric justification.
8 Monte Carlo simulation
We have introduced three alternative approaches for setting the penalization parameters in sections 3–5. In this section, we present the results of Monte Carlo simulations, which assess the performance of these approaches in terms of in-sample fit, out-of-sample prediction, model selection, and sparsity. To this end, we generate artificial data using the process
with n = 200. We report results for p = 100 and for the high-dimensional setting with p = 220. The predictors xij are drawn from a multivariate normal distribution with corr(xij, xir) = 0.9|j−r|. We vary the noise level σ between 0.5 and 5; specifically, we consider σ = {0.5, 1, 2, 3, 5}. We define the parameters as for j = 1,…, p with s = 20, implying exact sparsity. This simple design allows us to gain insights into the model-selection performance in terms of false-positive frequency (the number of variables falsely included) and false-negative frequency (the number of variables falsely omitted) when relevant and irrelevant regressors are correlated. All simulations use at least 1,000 iterations. We report additional Monte Carlo results in appendix A.1, where we use a design in which coefficients alternate in sign.
Because the aim is to assess in-sample and out-of-sample performance, we generate 2n observations and use the data i = 1,…, n as the estimation sample and the observations i = n + 1,…, 2n for assessing out-of-sample prediction performance. This allows us to calculate the rmse and root mean squared prediction error (RMSPE) as
where are the predictions from fitting the model to the first n observations.
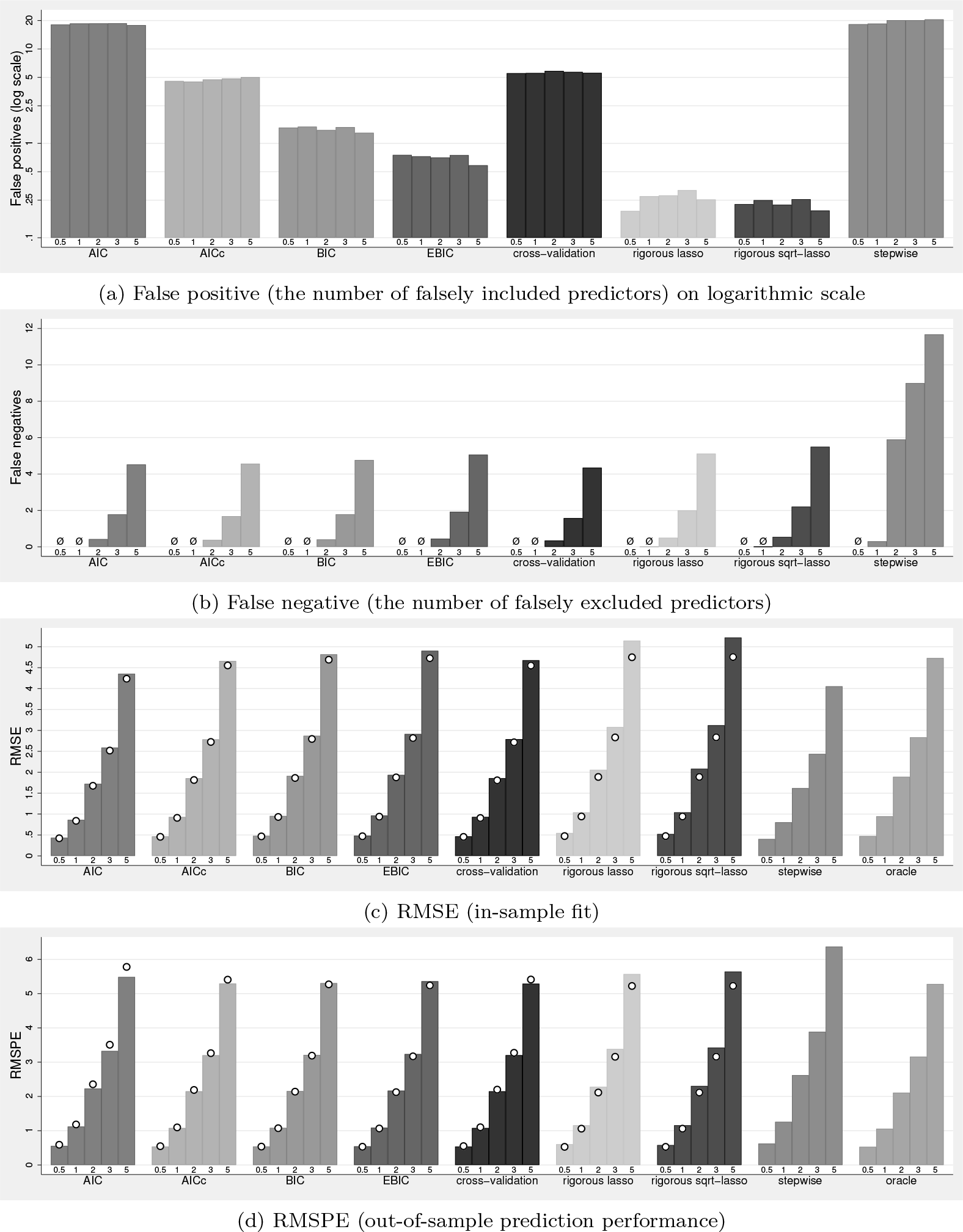
Figures 8 and 9 illustrate results for the following estimation methods implemented in lassopack: the lasso with λ selected by AIC, BIC, EBICξ, and AICc (as implemented in lasso2); the rigorous lasso and the rigorous square-root lasso (implemented in rlasso) using the X-independent penalty choice; and the five-fold cross-validated lasso using the penalty level that minimizes the estimated MSPE (implemented in cvlasso). In addition, we report postestimation OLS results (denoted by dots).
Monte Carlo simulation for an exactly sparse parameter vector with p = 100 and n = 200
Monte Carlo simulation for an exactly sparse parameter vector with p = 220 and n = 200
For comparison, we also show results of stepwise regression (for p = 100 only) and the oracle estimator. Stepwise regression starts from the full model and iteratively removes regressors if the p-value is above a predefined threshold (10% in our case). Stepwise regression is known to suffer from overfitting and pretesting bias. However, it still serves as a relevant reference point because of its connection with ad hoc model selection using hypothesis testing and the general-to-specific approach. The oracle estimator is OLS applied to the predictors included in the true model. Naturally, the oracle estimator is expected to show the best performance but is not feasible in practice because the true model is not known. The results of figures 8 and 9 are also reported in tabular form in tables 5 and 6 in appendix A.2 along with additional information, including results for the rigorous lasso and rigorous square-root lasso with an X-dependent penalty choice.
We first summarize the main results in figure 8 for the case where p = 100. AIC and stepwise regression exhibit the worst selection performance, with around 18–20 falsely included predictors on average. While AIC and stepwise regression achieve the lowest rmse (best in-sample fit), the out-of-sample prediction performance is among the worst—a typical symptom of overfitting. Note that in-sample fit of AIC and stepwise even exceed the fit of the oracle estimator. The corrected AIC improves upon the standard AIC in terms of both false-positive rate and prediction performance.
Compared with AICc, the BIC-type information criteria show similar out-of-sample prediction and better selection performance. While the EBIC performs only marginally better than BIC in terms of false positives, we expect the relative performance of BIC and EBIC to shift in favor of EBIC as p increases relative to n. Five-fold CV with the lasso behaves very similarly to the AICc across all measures. The rigorous lasso, rigorous square-root lasso, and EBIC exhibit overall the lowest false-positive rates, whereas rigorous methods yield slightly higher rmse and RMSPE than information criteria and CV-based methods.
Postestimation OLS generally exhibits better in-sample fit, indicating that the shrinkage bias from penalization can be alleviated by applying OLS to the selected model. In terms of out-of-sample prediction, postestimation OLS performs worse than first-step lasso when variable-selection performance is poor (particularly for the AIC) but leads to performance improvements for rigorous methods.
We also present simulation results for the high-dimensional setting in figure 9. Specifically, we consider p = 220 instead of p = 100, while keeping the estimation sample size constant at n = 200. With between 164 and 195 included predictors on average, the AIC suffers from overfitting. The RMSPE of the AIC exceeds the rmse by a factor of 5 or more. In comparison, aicc and five-fold cv perform better as model selectors, with a false-positive frequency between six and eight predictors.
Despite many predictors to choose from, EBIC and rigorous methods perform generally well in recovering the true structure. The false-positive frequency is below 1 across all noise levels, and the false-negative rate is zero if σ is 1 or smaller. While the BIC performs similarly to the EBIC for σ = 0.5 and σ = 1, its performance resembles the poor performance of AIC for larger noise levels. The Monte Carlo results in table 6 in appendix A.2 highlight that EBIC and rigorous methods are well suited for the high-dimensional setting where p > n, while AIC and BIC are not appropriate.
The computational costs of each method are reported in table 3. rlasso with X-independent penalty is the fastest method considered. The runtimes of lasso and square-root lasso with p = 100 are 0.1s and 0.4s, respectively. The computational cost increased only slightly if p is increased to p = 220. rlasso with an X-dependent penalty simulates the distribution of the maximum value of the score vector. This process increases the computational cost of the rigorous lasso to 5.9 seconds for p = 100 (12.7 seconds for p = 220). With an average runtime of 3.1 seconds, lasso2 is slightly faster than rlasso with X-dependent penalty if p = 100 but slower in the high-dimensional setup. Unsurprisingly, K-fold CV is the slowest method because it requires the model to be fit K times for a range of tuning parameters.
Runtime with p = 100 and p = 220
Method
Call
Secondsp = 100
p = 220
Rigorous lasso
rlasso y x
0.09
0.24
with X-dependent penalty
rlasso y x, xdep
5.92
12.73
Rigorous square-root lasso
rlasso y x, sqrt
0.39
0.74
with X-dependent penalty
rlasso y x, sqrt xdep
3.34
7.03
CV
cvlasso y x, nfolds(5) lopt
23.50
293.93
Information criteria
lasso2 y x
3.06
44.06
Stepwise regression
stepwise, pr(.1): reg y x
4.65
–
note: PC specification: Intel Core i5-6500 with 16 GB RAM, Windows 7.
9 Technical notes
9.1 Pathwise coordinate-descent algorithms
lassopack implements the elastic net and square-root lasso using coordinate-descent algorithms. The algorithm—then referred to as “shooting”—was first proposed by Fu (1998) for the lasso and by Van der Kooij (2007) for the elastic net. Belloni, Chernozhukov, and Wang (2011, 2014) use the coordinate descent for the square-root lasso and have kindly provided MATLAB code.
Coordinate-descent algorithms repeatedly cycle over predictors j = 1,…, p and update single-coefficient estimates until convergence. Suppose the predictors are centered and standardized to have unit variance, and the penalty loadings are ψj = 1 for all j. In that case, the update for coefficient j is obtained using univariate regression of the current partial residuals (that is, excluding the contribution of predictor j) against predictor j. More precisely, the update for the elastic net is calculated as
where denotes the current coefficient estimate and is the predicted value without the contribution of predictor j. Thus, because the predictors are standardized, is the OLS estimate of regressing predictor j against the partial residual . The function S(a, b), referred to as the soft-thresholding operator, is
and it sets some of the coefficients equal to zero. The coordinate-descent algorithm is spelled out for the square-root lasso in Belloni, Chernozhukov, and Wang (2014, supplementary material).25
The algorithm requires an initial beta estimate for which the ridge estimate is used. If the coefficient path is obtained for a list of λ values, lasso2 starts from the largest λ value and uses previous estimates as initial values (“warm starts”). See Friedman et al. (2007) and Friedman, Hastie, and Tibshirani (2010) and references therein for further information.
9.2 Standardization
Because penalized regression methods are not invariant to scale, it is common practice to standardize the regressors xij such that before computing the estimation results and then to unstandardize the coefficients after estimation. We refer to this approach as preestimation standardization. An alternative is to standardize on the fly by adapting the penalty loadings. The results are equivalent in theory. In the case of the lasso, setting yields the same results as dividing the data by before estimation. Standardization on the fly is the default in lassopack because it tends to be faster. Preestimation standardization can be used with the prestd option, which can lead to improved numerical precision or more stable results in the case of difficult problems; the cost is (a typically small) computation time required to standardize the data. The unitloadings option can be used if the researcher does not want to standardize data. If the preestimation-standardization and standardizationon-the-fly results differ, the user can compare the values of the penalized minimized objective function saved in e(pmse) (the penalized mean squared error for the elastic net) or e(prmse) (the penalized rmse for the square-root lasso).
9.3 Zero penalization and partialing out
In many applications, theory suggests that specific predictors affect the outcome variable. Hence, it might be desirable to always include these predictors in the model to improve finite-sample performance. Typical examples are the intercept, a time trend, or any other predictor that the researcher has prior knowledge of. lassopack offers two approaches for such situations:
Zero penalization: The notpen() option of lasso2 and cvlasso allows one to set the penalty for specific predictors to 0; that is, ψℓ = 0 for some ℓ ∊ {1,…, p}. Those variables are not subject to penalization and will always be included in the model. rlasso supports zero penalization through the pnotpen() option, which accommodates zero penalization in the rigorous-lasso penalty loadings; see below.
• Partialing out: We can also apply the penalized regression method to the data after the effect of certain regressors has been partialed out. Partialing out is supported by lasso2, cvlasso, and rlasso using the partial() option. The penalized regression does not yield estimates of the partialed-out coefficients directly. Instead, lassopack recovers the partialed-out coefficients by postestimation OLS.
The two methods—zero penalization and partialing out—are numerically equivalent. Formally, suppose we do not want to subject predictors ℓ with to penalization. The zero-penalization and partialed-out lasso estimates are defined, respectively, as
where and are the residuals of regressing y and the penalized regressors against the set of unpenalized regressors. The equivalence states that for all . The result is spelled out in Yamada (2017) for the lasso and ridge but holds for the elastic net more generally.
The partial() or notpen() option can be used for variables that should not be penalized by the lasso. The options are equivalent in theory (see above), but their numerical results can differ in practice because of the different calculation methods used. Partialing out variables can lead to improved numerical precision or more stable results in the case of difficult problems compared with zero penalization but may be slower in terms of computation time.
The estimation of penalty loadings in the rigorous lasso introduces an additional complication that necessitates the rlasso-specific option pnotpen(). The theory for the rlasso penalty loadings is based on the penalized regressors after partialing out the unpenalized variables. The pnotpen() option guarantees that the penalty loadings for the penalized regressors are the same as if the unpenalized regressors had instead first been partialed out.
The fe (fixed-effects) option is equivalent to (but computationally faster and more accurate than) specifying unpenalized panel-specific dummies. The fixed-effects (within) transformation also removes the constant and the fixed effects. The panel variable used by the fe option is the panel variable set by xtset. If installed, the within transformation uses the fast ftools package by Correia (2016).
The prestd, notpen(), and pnotpen() options can be used as simple checks for numerical stability by comparing results that should be equivalent in theory. The values of the penalized minimized objective function saved in e(pmse) for the elastic net and e(prmse) for the square-root lasso may also be used for comparison.
9.4 Treatment of the constant
By default, the constant (if present) is not penalized; this is equivalent to mean centering prior to estimation. The partial() option also partials out the constant (if present). To partial out the constant only, we can specify partial(_cons). Both partial() and fe mean-center the data; the noconstant option is redundant in this case and may not be specified with these options. If the noconstant option is specified, an intercept is not included in the model, but the estimated penalty loadings are still estimated using mean-centered regressors (see the center option).
11 Programs and supplemental materials
Supplemental Material, st0594 - lassopack: Model selection and prediction with regularized regression in Stata
Supplemental Material, st0594 for lassopack: Model selection and prediction with regularized regression in Stata by Achim Ahrens, Christian B. Hansen and Mark E. Schaffer in The Stata Journal
Footnotes
10 Acknowledgments
We thank Alexandre Belloni, who provided MATLAB code for the square-root lasso, and Sergio Correia for supporting us with the use of ftools. We also thank Christopher F. Baum, Jan Ditzen, David M. Drukker, Martin Spindler, participants of the 2018 London Stata Conference, and participants of the 2018 Swiss Stata Users Group meeting for many helpful comments and suggestions. We have received excellent comments from an anonymous referee that have improved the article. We are also grateful to the many users that have provided feedback. All remaining errors are our own.
11 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
To get the latest stable version of lassopack from our website, check the installation instructions at .
Notes
A Appendix
References
1.
AhrensA.HansenC. B.SchafferM. E.2018. pdslasso: Stata module for post-selection and post-regularization OLS or IV estimation and inference. Statistical Software Components S458459, Department of Economics, Boston College. https://ideas.repec.org/c/boc/bocode/s458459.html.
AndrewsD. W. K.1991. Asymptotic optimality of generalized CL, cross-validation, and generalized cross-validation in regression with heteroskedastic errors. Journal of Econometrics47: 359–377. https://doi.org/10.1016/0304-4076(91)90107-O.
4.
ArlotS.CelisseA.2010. A survey of cross-validation procedures for model selection. Statistics Surveys4: 40–79. https://doi.org/10.1214/09-SS054.
5.
AtheyS.2019. The impact of machine learning on economics. In The Economics of Artificial Intelligence: An Agenda, ed. AgrawalA.GansJ.GoldfarbA., 507–547. Cambridge, MA: National Bureau of Economic Research.
6.
AtheyS.ImbensG.2019. Machine learning methods economists should know about. ArXiv Working Paper No. arXiv:1903.10075. https://arxiv.org/abs/1903.10075.
7.
BelloniA.ChenD.ChernozhukovV.HansenC.2012. Sparse models and methods for optimal instruments with an application to eminent domain. Econometrica80: 2369–2429. https://doi.org/10.3982/ECTA9626.
8.
BelloniA.ChernozhukovV.2011. High dimensional sparse econometric models: An introduction. In Inverse Problems and High-Dimensional Estimation, ed. AlquierP.GautierE.StoltzG., chap. 3. Vol. 203 of Lecture Notes in Statistics. Berlin: Springer.
9.
BelloniA.ChernozhukovV.2013. Least squares after model selection in high-dimensional sparse models. Bernoulli19: 521–547. https://doi.org/10.3150/11-BEJ410.
10.
BelloniA.ChernozhukovV.HansenC.2014. Inference on treatment effects after selection among high-dimensional controls. Review of Economic Studies81: 608–650. https://doi.org/10.1093/restud/rdt044.
11.
BelloniA.ChernozhukovV.HansenC.KozburD.2016. Inference in highdimensional panel models with an application to gun control. Journal of Business & Economic Statistics34: 590–605. https://doi.org/10.1080/07350015.2015.1102733.
12.
BelloniA.ChernozhukovV.WangL.2011. Square-root lasso: Pivotal recovery of sparse signals via conic programming. Biometrika98: 791–806. https://doi.org/10.1093/biomet/asr043.
13.
BelloniA.ChernozhukovV.WangL.2014. Pivotal estimation via square-root Lasso in nonparametric regression. Annals of Statistics42: 757–788. https://doi.org/10.1214/14-AOS1204.
14.
BergmeirC.HyndmanR. J.KooB.2018. A note on the validity of crossvalidation for evaluating autoregressive time series prediction. Computational Statistics & Data Analysis120: 70–83. https://doi.org/10.1016/j.csda.2017.11.003.
15.
BickelP. J.RitovY.TsybakovA. B.2009. Simultaneous analysis of Lasso and Dantzig selector. Annals of Statistics37: 1705–1732. https://doi.org/10.1214/08-AOS620.
ChenJ.ChenZ.2008. Extended Bayesian information criteria for model selection with large model spaces. Biometrika95: 759–771. https://doi.org/10.1093/biomet/asn034.
21.
ChernozhukovV.ChetverikovD.KatoK.2013. Gaussian approximations and multiplier bootstrap for maxima of sums of high-dimensional random vectors. Annals of Statistics41: 2786–2819. https://doi.org/10.1214/13-AOS1161.
22.
ChernozhukovV.HansenC.SpindlerM.2015. Post-selection and postregularization inference in linear models with many controls and instruments. American Economic Review105: 486–490. https://doi.org/10.1257/aer.p20151022.
23.
ChernozhukovV.HansenC.SpindlerM.2016. High-dimensional metrics in R. ArXiv Working Paper No. arXiv:1603.01700. https://arxiv.org/abs/1603.01700.
24.
ChetverikovD.LiaoZ.ChernozhukovV.2019. On cross-validated Lasso. ArXiv Working Paper No. arXiv:1605.02214. http://arxiv.org/abs/1605.02214.
25.
CorreiaS.2016. ftools: Stata module to provide alternatives to common Stata commands optimized for large datasets. Statistical Software Components S458213, Department of Economics, Boston College. https://ideas.repec.org/c/boc/bocode/s458213.html.
26.
DickerL. H.2016. Ridge regression and asymptotic minimax estimation over spheres of growing dimension. Bernoulli 22: 1–37. https://doi.org/10.3150/14-BEJ609.
27.
DobribanE.WagerS.2018. High-dimensional asymptotics of prediction: Ridge regression and classification. Annals of Statistics46: 247–279. https://doi.org/10.1214/17-AOS1549.
28.
FrankI. E.FriedmanJ. H.1993. A statistical view of some chemometrics regression tools. Technometrics35: 109–135. https://doi.org/10.2307/1269656.
29.
FriedmanJ.HastieT.H¨oflingH.TibshiraniR.2007. Pathwise coordinate optimization. Annals of Applied Statistics1: 302–332. https://doi.org/10.1214/07-AOAS131.
30.
FriedmanJ. H.HastieT.TibshiraniR.2010. Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software33(1): 1–22. https://doi.org/10.18637/jss.v033.i01.
GeisserS.1975. The predictive sample reuse method with applications. Journal of the American Statistical Association70: 320–328. https://doi.org/10.2307/2285815.
33.
HansenC.KozburD.2014. Instrumental variables estimation with many weak instruments using regularized JIVE. Journal of Econometrics182: 290–308. https://doi.org/10.1016/j.jeconom.2014.04.022.
34.
HastieT.TibshiraniR.FriedmanJ.2009. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2nd ed. New York: Springer.
35.
HastieT.TibshiraniR.WainwrightM.2015. Statistical Learning with Sparsity: The Lasso and Generalizations. Boca Raton, FL: CRC Press.
HsuD.KakadeS. M.ZhangT.2014. Random design analysis of ridge regression. Foundations of Computational Mathematics14: 569–600. https://doi.org/10.1007/s10208-014-9192-1.
HyndmanR. J.AthanasopoulosG.2012. Forecasting: Principles and Practice. OTexts. https://www.otexts.org/fpp.
41.
JingB.-Y.ShaoQ.-M.WangQ.2003. Self-normalized Cramér-type large deviations for independent random variables. Annals of Probability31: 2167–2215. https://doi.org/10.1214/aop/1024404289.
42.
KleinbergJ.LakkarajuH.LeskovecJ.LudwigJ.MullainathanS.2018. Human decisions and machine predictions. Quarterly Journal of Economics 133: 237–293. https://doi.org/10.1093/qje/qjx032.
43.
LockhartR.TaylorJ.TibshiraniR. J.TibshiraniR.2014. A significance test for the lasso. Annals of Statistics42: 413–468. https://doi.org/10.1214/13-AOS1175.
44.
MeinshausenN.BühlmannP.2006. High-dimensional graphs and variable selection with the lasso. Annals of Statistics34: 1436–1462. https://doi.org/10.1214/009053606000000281.
45.
MeinshausenN.MeierL.BühlmannP.2009. p-values for high-dimensional regression. Journal of the American Statistical Association104: 1671–1681. https://doi.org/10.1198/jasa.2009.tm08647.
46.
MullainathanS.SpiessJ.2017. Machine learning: An applied econometric approach. Journal of Economic Perspectives 31: 87–106. https://doi.org/10.1257/jep.31.2.87.
47.
RaninenE.OllilaE.2017. Scaled and square-root elastic net. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 4336–4340. New Orleans, LA: IEEE.
ShaoJ.1993. Linear model selection by cross-validation. Journal of the American Statistical Association88: 486–494. https://doi.org/10.2307/2290328.
50.
ShaoJ.1997. An asymptotic theory for linear model selection. Statistica Sinica7: 221–242.
51.
StoneM.1977. An asymptotic equivalence of choice of model by cross-validation and Akaike’s criterion. Journal of the Royal Statistical Society, Series B39: 44–47. https://doi.org/10.1111/j.2517-6161.1977.tb01603.x.
52.
SugiuraN.1978. Further analysts [sic] of the data by Akaike’s information criterion and the finite corrections. Communications in Statistics—Theory and Methods7: 13–26. https://doi.org/10.1080/03610927808827599.
TibshiraniR. J.TaylorJ.2012. Degrees of freedom in lasso problems. Annals of Statistics40: 1198–1232. https://doi.org/10.1214/12-AOS1003.
55.
TikhonovA. N.1963. On the solution of ill-posed problems and the method of regularization. Doklady Akademii Nauk151: 501–504.
56.
Van der KooijA.2007. Prediction accuracy and stability of regression with optimal scaling transformations. PhD thesis, Department of Data Theory, University of Leiden.
WeilenmannB.SeidlI.SchulzT.2017. The socio-economic determinants of urban sprawl between 1980 and 2010 in Switzerland. Landscape and Urban Planning157: 468–482. https://doi.org/10.1016/j.landurbplan.2016.08.002.
60.
YamadaH.2017. The Frisch–Waugh–Lovell theorem for the lasso and the ridge regression. Communications in Statistics—Theory and Methods46: 10897–10902. https://doi.org/10.1080/03610926.2016.1252403.
61.
YangY.2005. Can the strengths of AIC and BIC be shared? A conflict between model indentification and regression estimation. Biometrika92: 937–950. https://doi.org/10.1093/biomet/92.4.937.
62.
YangY.2006. Comparing learning methods for classification. Statistica Sinica16: 635–657.
63.
ZhangY.LiR.TsaiC.-L.2010. Regularization parameter selections via generalized information criterion. Journal of the American Statistical Association105: 312–323. https://doi.org/10.1198/jasa.2009.tm08013.
64.
ZhaoP.YuB.2006. On model selection consistency of lasso. Journal of Machine Learning Research7: 2541–2563.
ZouH.ZhangH. H.2009. On the adaptive elastic-net with a diverging number of parameters. Annals of Statistics37: 1733–1751. https://doi.org/10.1214/08-AOS625.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.