
Abstract
In this article, we introduce the
1 Introduction
A fundamental concern when conducting evaluations using observational data is that unmeasured confounding—one or more additional factors that cause both the treatment assignment and the outcome—might be mistaken for a treatment effect. For this reason, researchers endeavor to adjust for all variables considered to influence these associations when performing analyses. However, in observational research, it is unlikely that data for all potential confounding variables will be available. Thus, one should conduct a postestimation sensitivity analysis to assess how strong a relationship would have to be between an unmeasured confounder and the treatment assignment, as well as between the unmeasured confounder and the outcome, to explain away an observed treatment effect.
Several sensitivity analyses have been developed for different statistical models (see, for example, Cornfield et al. [1959]; Rosenbaum and Rubin [1983]; Manski [1990]; Lin, Psaty, and Kronmal [1998]; Rosenbaum [2002, 2010]; Brumback et al. [2004]; Vander-Weele and Arah [2011]; Imbens [2003]; Imbens and Rubin [2015]; Ding and VanderWeele [2016]; and VanderWeele and Ding [2017]). Four community-contributed packages are currently available for conducting sensitivity analysis in Stata:
In this article, we introduce the
2 Methods
The E-value is computed on the RR scale, so results of statistical models other than the RR must be converted to the RR scale. In this section, we present the methods involved in computing the E-value for various model types.
2.1 E-value for RR and rate ratio
The basic formula for computing an E-value for any outcome type on the RR scale (and its confidence limit closest to the null) is as follows (VanderWeele and Ding 2017): 1
If RR > 1:
E-value (point estimate)
E-value (lower limit [LL]) = 1 if LL ≤ 1, else
If RR < 1:
E-value (point estimate)
E-value (upper limit [UL]) = 1 if UL ≥ 1, else
2.2 E-value for odds ratio
When the outcome is relatively rare (for example, < 15% prevalence by the end of follow-up), the odds ratio (OR) approximates the RR, so the basic E-value formula (in section 2.1) should be used. In a case–control study, the outcome needs to be rare only in the underlying population, not in the study sample (the same considerations hold when the outcome prevalence is instead approximately > 85% by the end of follow-up because the variable coding can simply be reversed). When the outcome is not rare (between 15% and 85% prevalence at the end of follow-up), an approximate E-value may be obtained by replacing the RR with the square root of the OR (VanderWeele 2017); that is,
2.3 E-value for hazard ratio
When the outcome is relatively rare as described above, the basic E-value formula (in section 2.1) should be used. When the outcome is common, an approximate E-value may be obtained (VanderWeele 2017) by applying the approximation
2.4 E-value for standardized mean difference
With standardized effect sizes d (mean of the outcome variable divided by the pooled standard deviation [SD] of the outcome) and a standard error for this standardized effect size SD, an approximate E-value may be obtained (Lipsey and Wilson 2001; Vander-Weele 2017; Linden 2019) by applying the approximation RR ≈ e [0 . 91 × d ] in the E-value formula. Similarly, an approximate confidence interval (CI) for the RR may be obtained by using the approximation (e [0 . 91 × d − 1 . 78 × SD], e [0 . 91 × d +1 . 78 × SD]). This approach relies on additional assumptions and approximations. Other sensitivity analysis techniques have been developed for this setting (Lin, Psaty, and Kronmal 1998; Imbens 2003; VanderWeele and Arah 2011), but they generally require additional assumptions, and the variables do not necessarily have a corresponding E-value.
2.5 E-value for risk difference
If the adjusted risks for the treated and untreated are p 1 and p 0, then the E-value may be obtained by replacing the RR with p 1 /p 0 in the E-value formula. The E-value for the CI on a risk-difference (RD) scale is complex, requiring the computation of several measures and then the use of a grid search to find the corresponding bias factor that, when transformed to the RR scale, will elicit the E-value of the lower confidence limit (see Ding and VanderWeele [2016] for a comprehensive discussion). Alternatively, if the outcome probabilities p 1 and p 0 are not small or large (for example, if they are between 0.20 and 0.80), then the approximate approach for differences in continuous outcomes given in section 2.4 may be used. Other sensitivity analysis techniques have been developed for this setting (Lin, Psaty, and Kronmal 1998; Imbens 2003; VanderWeele and Arah 2011) but generally require additional assumptions and do not provide a corresponding E-value.
2.6 E-values for nonnull hypotheses
Thus far, we have described how to calculate E-values to assess the minimum strength of the association an unmeasured confounder would need to have with both the treatment assignment and the outcome to move the point estimate, or one limit of the CI, to the null. However, a similar procedure can be used to assess the minimum magnitude of both confounder associations that would be needed to move an estimate to some other value of the RR. If we have an observed RR of RR and want to assess the minimum strength of both associations that would be needed to shift the estimate to some other value RR T , then we first take the ratio of the two values, RR/RR T , and then apply the E-value formula presented in section 2.1 to this ratio. We encourage investigators to read the original article introducing the E-value (VanderWeele and Ding 2017) to aid in understanding and interpretation prior to using the package.
3 The evalue package
This section describes the syntax of the commands in the
3.1 Syntax
E-value for RR and rate ratio:
E-value for OR:
E-value for hazard ratio (HR):
E-value for standardized mean difference (SMD):
E-value for RD:
In the syntax for
3.2 Options
4 Examples
4.1 E-value for a RR
In a population-based case–control study, Victora et al. (1987) examined associations between breastfeeding and infant death by respiratory infection. After adjusting for age, birthweight, social status, maternal education, and family income, the authors found that infants fed only with formula were 3.9 (95% CI, 1.8 to 8.7) times more likely to die of respiratory infections than those who were exclusively breastfed. The investigators controlled for markers of socioeconomic status but not for smoking, and smoking may reduce breastfeeding and increase risk for respiratory death.
To compute the E-value for this relative risk, we type in the point estimate (3.9) and the lower and upper confidence limits (1.8 and 8.7, respectively). We also apply the

As shown in the output and figure, the E-value for the point estimate is 7.26. This E-value can be interpreted as follows: “The observed risk ratio of 3.9 could be explained away by an unmeasured confounder that was associated with both the treatment and the outcome by a risk ratio of 7.2-fold each, above and beyond the measured confounders, but weaker confounding could not do so” (VanderWeele and Ding 2017). Similarly, the E-value for the lower confidence limit (that is, the confidence limit closest to the null) is 3.0, which can be interpreted as “[a]n unmeasured confounder associated with respiratory death and breastfeeding by a risk ratio of 3.0-fold each could explain away the lower confidence limit, but weaker confounding could not” (VanderWeele and Ding 2017). The evidence for causality from these E-values thus looks reasonably strong because substantial unmeasured confounding would be needed to reduce the observed association or its CI to null (VanderWeele and Ding 2017).
4.2 E-value for an OR
In this example, we perform sensitivity analysis for a rare outcome rate (that is, < 15% of cases) by not specifying the

As shown, the E-value for the point estimate is 3.41 and 1.81 for the CI. The point estimate seems moderately robust, but confounder associations with breastfeeding and ovarian cancer of this magnitude could potentially move the CI to the null.
4.3 E-value for a HR
In this example, we use the official Stata command

We see from the
4.4 E-value for a SMD
In this example, we illustrate how to convert a treatment-effects estimate derived from a linear regression model fit with a binary exposure to an SMD and how to then pass that estimate (and its standard error) to
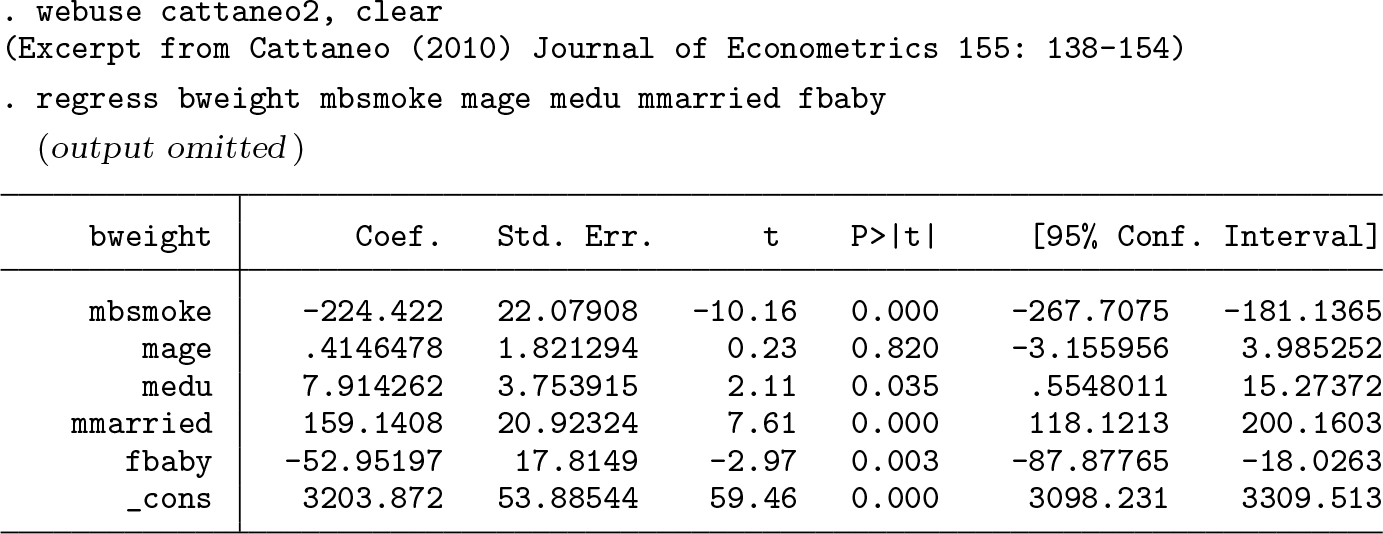
We see that the average birthweight of babies born to mothers who smoked is 224 grams less than babies whose mothers had not smoked. To convert this point estimate into an SMD, we implement the community-contributed command

Next, we plug the estimate and standard error into

4.5 E-value for an RD
In this example, we illustrate how to compute the E-value for an RD of a binary outcome. Unlike the other
Hammond and Horn (1958a,b) report associations between smoking and lung cancer deaths from a cohort study of 187,783 men, of which 42% were classified as having a history of regular cigarette smoking (exposed) versus others (no smoking or only occasional smoking). We could compute the RD and CI using
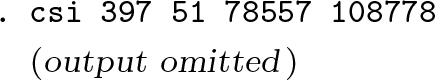
Using

These results can be interpreted as follows: “With an observed risk difference of RD = 0.00456, an unmeasured confounder that was associated with both regular smoking and lung cancer death by a risk ratio of 20.95-fold each, above and beyond the measured confounders, could explain away the estimate, but weaker confounding could not; to move the CI to include the null, an unmeasured confounder that was associated with both regular smoking and lung cancer death by a risk ratio of 15.96-fold each could do so, but weaker confounding could not” (VanderWeele and Ding 2017).
4.6 E-values for nonnull hypotheses
To this point, we described how to calculate E-values to assess the minimum strength of the association an unmeasured confounder would need to have with both the treatment and the outcome to move the point estimate, or one limit of the CI, to the null. However, we can use a similar procedure to assess the minimum magnitude of both confounder associations that would be needed to move an estimate to some other value of the RR. In
As an example, a study by the Agency for Healthcare Research and Quality (Ip et al. 2007) reported an RR between breastfeeding and childhood leukemia as 0.80 (95% CI: [0.71, 0.91]). Computing E-values for the null effect gives us 1.81 and 1.43 for the point estimate and CI, respectively.

Assume that we were interested in assessing how large both unmeasured confounding associations would need to be to shift the RR estimate from 0.80 to 0.90. We simply specify

As shown, we obtain an E-value for the point estimate of 1.50, which describes the magnitude of the associations an unmeasured confounder would need to have with breastfeeding and childhood leukemia to move the observed RR from 0.80 to 0.90. The interpretation of this nonnull E-value is that “for an unmeasured confounder to shift the observed estimate of RR = 0.80 to an estimate of RR T = 0.90, an unmeasured confounder that was associated with both breastfeeding and childhood leukemia by a risk ratio of 1.5-fold each could do so, but weaker confounding could not” (VanderWeele and Ding 2017). Because the CI already includes the value of 0.90, no additional unmeasured confounding is needed for the interval to include that value, and thus the E-value for the CI to include 0.90 is just E-value = 1.0.
We may also calculate E-values for the values of the RR on the other side of the null hypothesis. Thus, if we wanted to assess the minimum strength of both confounder associations that would be needed to move the RR estimate of 0.80 to an RR estimate of 1.20, we would simply specify

As shown, to shift estimates to an RR of 1.20, we obtain an E-value of 2.37 for the point and an E-value of 1.97 for the upper limit of the CI. The interpretation of these nonnull E-values would then be that for an unmeasured confounder to shift the observed RR estimate of 0.80 to an RR of 1.20, an unmeasured confounder that was associated with both breastfeeding and childhood leukemia by an RR of 2.37-fold each could do so, but a weaker confounder could not. Similarly, to shift the upper confidence limit of 0.91 to 1.20, an unmeasured confounder that was associated with both breastfeeding and leukemia by an RR of 1.97-fold each could do so, but a weaker confounder could not (VanderWeele and Ding 2017).
5 Discussion
In this article, we introduced the
In conclusion, we have provided a convenient package for conducting sensitivity analysis following treatment-effects estimation in observational studies. We advocate the reporting of E-values in such studies to assist investigators and others in weighing the evidence for robustness to confounding and thus ultimately for causality.
Footnotes
6 Acknowledgments
We thank the anonymous reviewer and chief editor for their thoughtful reviews.
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type