
Abstract
In this article, we describe
1 Introduction
In this article, we present the community-contributed command
This article is organized as follows. Section 2 introduces the econometrics underlying the estimation model and shows a graph of the estimated coefficients. Section 3 explains the rationale underlying parallel-trend tests and shows how to carry them out. Section 4 presents the syntax of
2 The model
We focus on the estimation of treatment effects in the presence of binary time-varying treatment. Such a setting characterizes several economic and social policies and medical trials delivered over time. For example, one could be interested in assessing whether a certain treatment had an impact on a given target variable with some delay and whether anticipatory effects took place. To formalize this setting, let us start by considering a binary treatment indicator for individual i at time t:
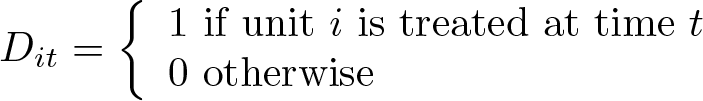
Let us also assume an outcome equation with contemporaneous treatment plus one lag and one lead:

In (1), the β
+1 coefficient measures the impact of the treatment one period before its occurrence, and β
−1 measures the impact of treatment one period after it.
For now, let us assume that treatment can occur only once over the interval [t−1, t+1] so that we can define the following sequences of possible treatments,

where the sequence w
1 is the usual benchmark of no treatment. The generic sequence is denoted as wj
(with j = 1,…, J and J = 4) and the associated potential outcome as

for j, k = 1,…, 4 and j ≠ k.
Under conditional mean independence—that is, conditioning on both

In such a model—with treatment occurring only once out of three periods, plus one lag and one lead of the treatment variable—we can define six possible ATEs that, for ease of reference, we collect in a matrix,

where the generic ATEjk represents the ATE of the sequence j against the counterfactual sequence k. Obviously, ATE jk = −ATE kj . Using (1) and the definition of wj with j = 1,…, 4, we can show that

In general, one obtains a number of ATEs equal to (J 2−J)/2, where J is the number of treatment sequences; in our example, we have (42 − 4)/2 = 6 ATEs. An important advantage of a dynamic treatment model is the ability to graphically plot the evolution of the treatment effects over time. To this end, let us define the predictions of Yit given the sequence of treatments as

Consistently with the econometric practice, to make (3) computable, we assume additive separability; that is, µit
= θi
+ δt
, where θi
and δt
represent individual and time-fixed effects, respectively. It follows that
To keep things simple, let us restrict our attention only to the case of two specific treatment sequences,

where wT indicates the sequence in which treatment occurs only at time t and wC indicates the no-treatment case. By setting Ait = {Dit −1 , Dit, Dit +1 , t} and iterating (3) one period back and one period forward, one obtains the prediction of Y at t − 1, t, and t + 1,

which can be used to calculate the expected outcome over t − 1, t, t + 1 conditional on wT and wC . Thus,
for wT , we have

for wC , we have

We can now plot these predictions over time (figure 1) and depict these situations:

Pre- (t−1) and post- (t+1) treatment effect of a policy delivered at t. Source: Cerulli (2015, 202).
If β +1 ≠ 0, treatment delivered at time t affects the outcome at time t−1. Current treatment has an effect on past outcomes (anticipatory effect). Therefore, the pretreatment period is affected by current treatment.
If β 0 ≠ 0, treatment delivered at time t affects the outcome at time t, generating contemporaneous effects.
If β −1 ≠ 0, treatment delivered at time t affects the outcome at time t + 1. Current treatment has an effect on future outcomes (lagged effect). Therefore, the posttreatment period is affected by current treatment.
3 Testing the parallel-trend assumption
The pattern of the leads is also important to check for causality in the spirit of Granger (1969). Indeed, conditional on

Note that rejecting H 0 invalidates the causal interpretation of the estimates, while not rejecting H 0 implies only a necessary condition for the parallel-trend to hold because the necessary and sufficient condition still remains untestable, being formulated on counterfactual unobservable quantities.
Another approach to test the parallel-trend assumption (still a necessary condition) requires dropping lags and leads from (1) and augmenting it with the time-trend variable t and its interaction with Dit . If the coefficient of the interaction term is statistically not significant, one can reasonably expect the parallel-trend assumption to hold (see Angrist and Pischke [2009, 238–239]).
To provide ground for such a test, let us write down the following potential-outcome model:
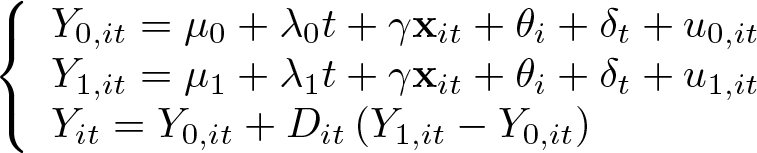
We allow again for an individual fixed effect (θi ) and a time effect (δt ), with the parameters λ 1 and λ 0 being the treated and untreated time trends, respectively. This way, by plugging the first two equations into the third one, we obtain

with ηit = [u 0,it + Dit (u 1,it − u 0,it )]. Equivalently, we can write the previous equation as

which can be consistently estimated by a fixed-effects regression where the significance test for λ = (λ 1 − λ 0) provides a test for the parallel-trend assumption. Accepting the null H 0: λ = 0 implies accepting that the parallel-trend assumption is not violated whenever one assumes no “anticipation effects”).
Finally, note that we can extend the previous test by also considering quadratic or even cubic time trends.
4 The tvdiff command
4.1 Description
4.2 Syntax
The syntax of the command is as follows:
treatment is the binary treatment variable taking a value of 1 for treated units and a
value of 0 for untreated units.
varlist is the set of pretreatment (or observable confounding) variables.
4.3 Options
4.4 Remarks
_
_
Finally, note that i) the treatment has to be a 0/1 binary variable (
4.5 Stored results

5 An application using simulated data in the presence of selection bias
This example shows how to correctly run
For this purpose, we design a simulated DGP allowing for a nonzero correlation between the “selection equation” or “treatment equation” (the D-equation) and the “outcome equation” (the y-equation), due to the presence of unobservable selection as captured by an individual specific effect acting as confounder.
Consider the same treatment setting of (1); that is, only one lead and one lag are included. Exclude, without loss of generality, observable confounders
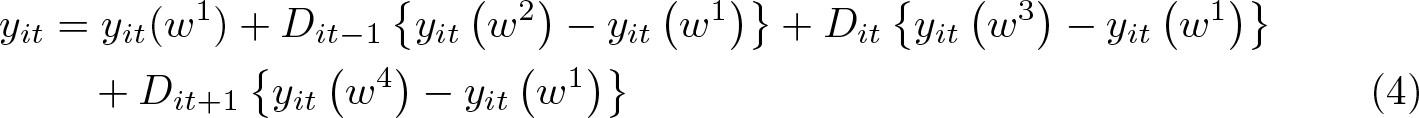
Assume that the potential outcome takes on this form

where

where
Equation (6) is equivalent to (1), apart from
By using the definitions of ATE jk , we can finally rewrite (6) as

We can now perform our simulation experiment showing that

Observe that ci
enters the potential outcomes’ random shocks,

We run

As expected, because of the correlation between the outcome equation and the selection equation entailed by this DGP, OLS estimates are severely biased. The OLS coefficient of the lead—expected to be equal to 30—is in fact equal to about 65, and large biases also arise for the contemporaneous and the lagged coefficients (respectively, about 56 instead of 20 and about 44 instead of 10). On the contrary, the fixed-effects estimator performs well, with all the coefficients close to the true coefficients, thus showing that it effectively solves the selection bias underlying this DGP. Introducing exogenous variables within the previous DGP does not change these results.
6 An application to the effect of public education expenditure on income equality
In this section, we provide an application of
Within these data, public education effort is measured as the (current and capital) total public expenditure on education as a percentage of gross domestic product (GDP) (variable
The binary treatment Dit is defined as follows: consider the “within” median of public expenditure in education over GDP, namely, the median by country of the share of public expenditure in education over GDP for the 1980–2008 period. If in year t, country i performs a public expenditure in education larger than its “within” median, then Dit = 1 (the pair country-year is thus “treated”); otherwise, Dit = 0. In other words, the treatment is defined as the tendency of a country to boost its expenditure in education in a specific year compared with a baseline reference, measured as its median performance over the overall time span. The outcome y is measured as the “total public expenditure in education as a percentage of GDP”.
We do this exercise by running the following code, where

For brevity’s sake, the regression outputs are omitted, ensuring that both parallel-trend tests are passed, and we focus on the graph in figure 2. This figure shows that from the time of treatment (that is, higher than the median education expenditure) onward, the ATE, given by the level of equality in income distribution, increases steeply and remains positive until the seventh year after treatment.

Graph of the pre- and posttreatment pattern for the relation between country investment in public education and income equality
The pattern is a sort of parabola, showing that the effect of one short increase in education expenditure above the median has a transitory effect tending to fade away around seven years after treatment. Considering that significance is relatively high after 3, 4, and 5 years from treatment time (t), this finding shows a quite sensible effect of public investment in education on income equality. More specifically, we see that the (average) equality index difference between treated and untreated reaches a value of around 0.5% three and four years after treatment and then decreases in the subsequent years.
Of course, other possible confounders may be present. However, the use of fixed-effects estimation should mitigate unobservable selection, thus making these results also sufficiently robust to selection on unobservables. This is one of the main strengths of DID that
7 Conclusion
In this article, we presented
Note that one must be cautious when using this command for causal inference because both tests allow for testing only the necessary condition for identification to hold. Hence, if the parallel trend is supported by the tests, the user should validly motivate why the sufficient condition is expected to hold under the specific context of analysis.
We hope readers will find
9 Programs and supplemental materials
Supplemental Material, st0566 - Estimation of pre- and posttreatment average treatment effects with binary time-varying treatment using Stata
Supplemental Material, st0566 for Estimation of pre- and posttreatment average treatment effects with binary time-varying treatment using Stata by Giovanni Cerulli and Marco Ventura in The Stata Journal
Footnotes
8 Acknowledgments
We presented a first draft of this article at the 2017 Italian Stata Users Group meeting held in Florence on November 16–17, 2017. We thank the organizers and all the participants of the meeting for their useful comments.
9 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.